
Augmented-Reality Presentation of Household Sounds for Deaf and Hard-of-Hearing People


Abstract
:1. Introduction
Background and Previous Research
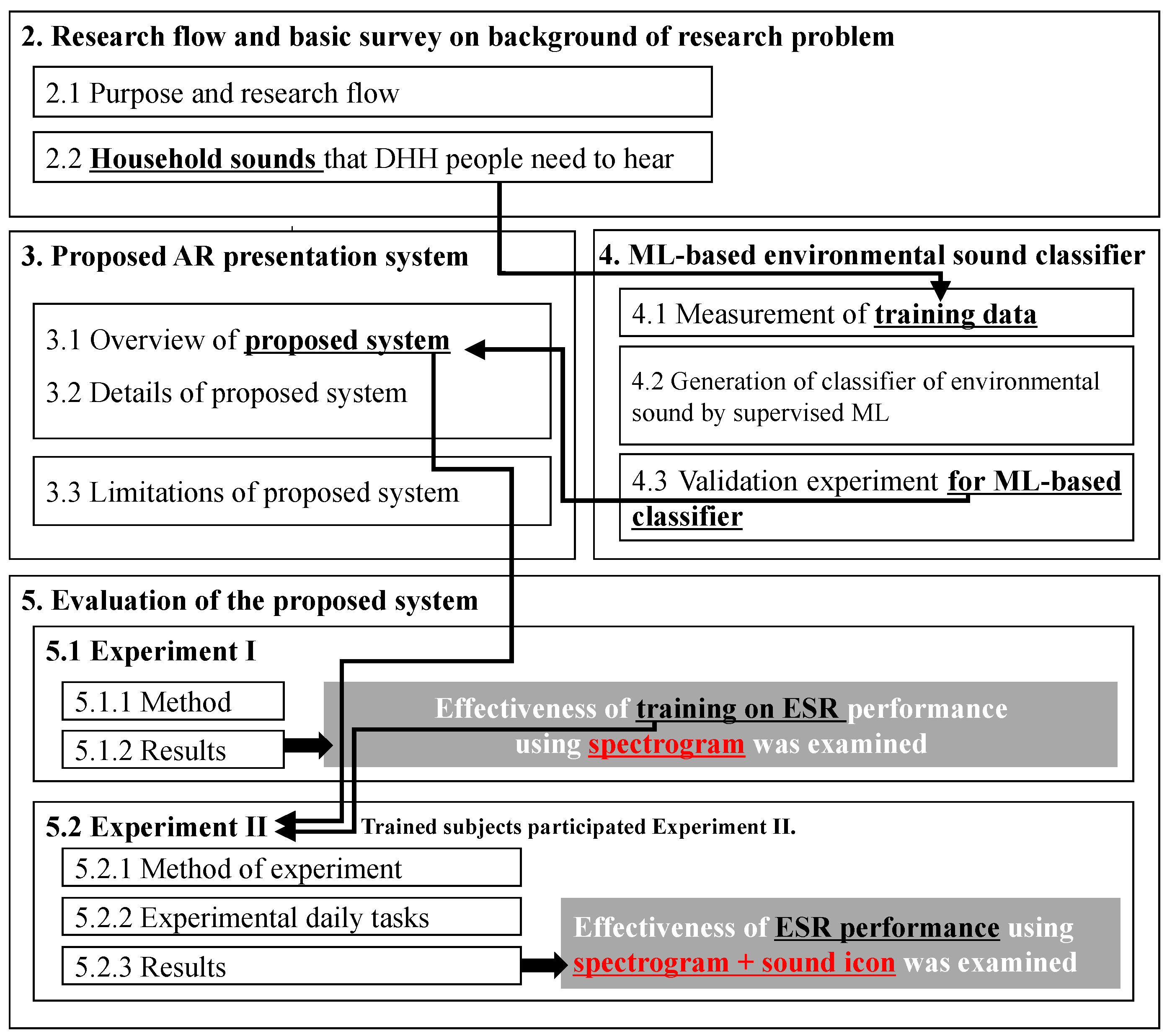
2. Research Flow and Basic Survey on Background of Research Problem
2.1. Purpose and Research Flow
2.2. Survey on Daily Problems of DHH People
- What are the environmental sounds that are difficult to hear in their daily lives?
- What are the problems of not being able to hear the abovementioned sounds?
- How do people obtain or not obtain information on surrounding sounds?
3. Proposed AR Presentation System
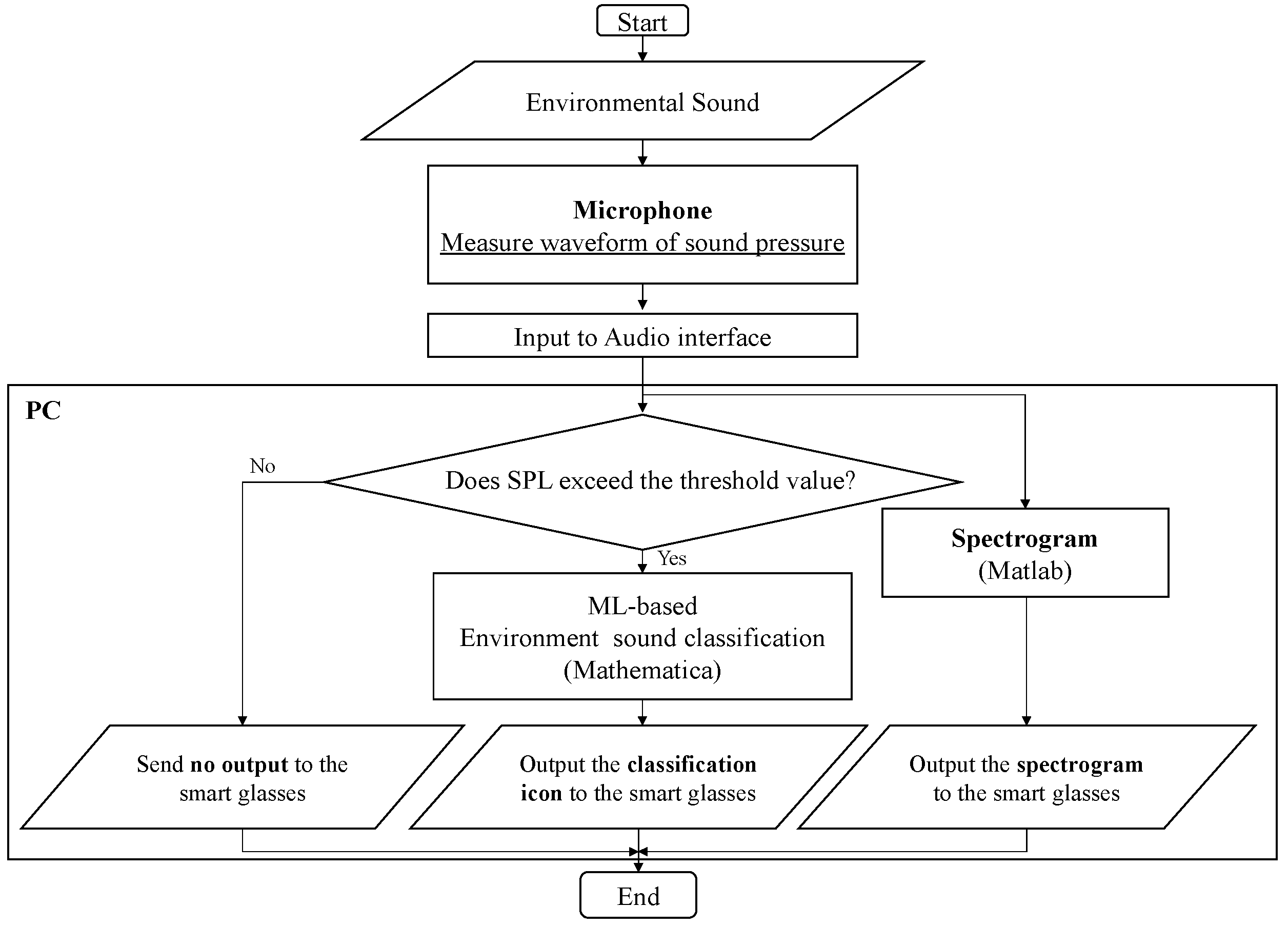
3.1. Overview of Proposed System
3.2. Details of Proposed System
3.3. Limitations of Proposed System
4. ML-Based Environmental Sound Classifier
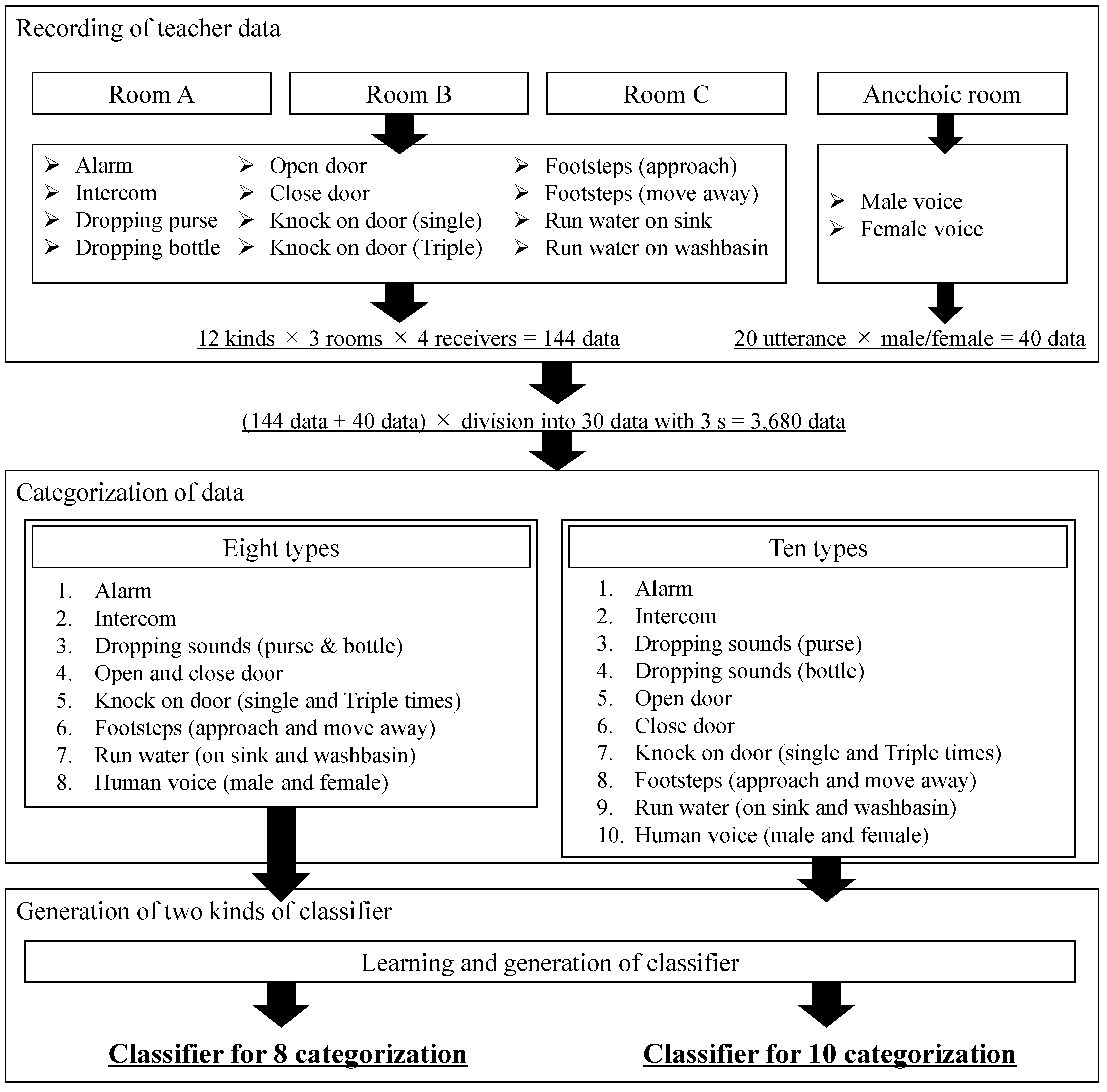
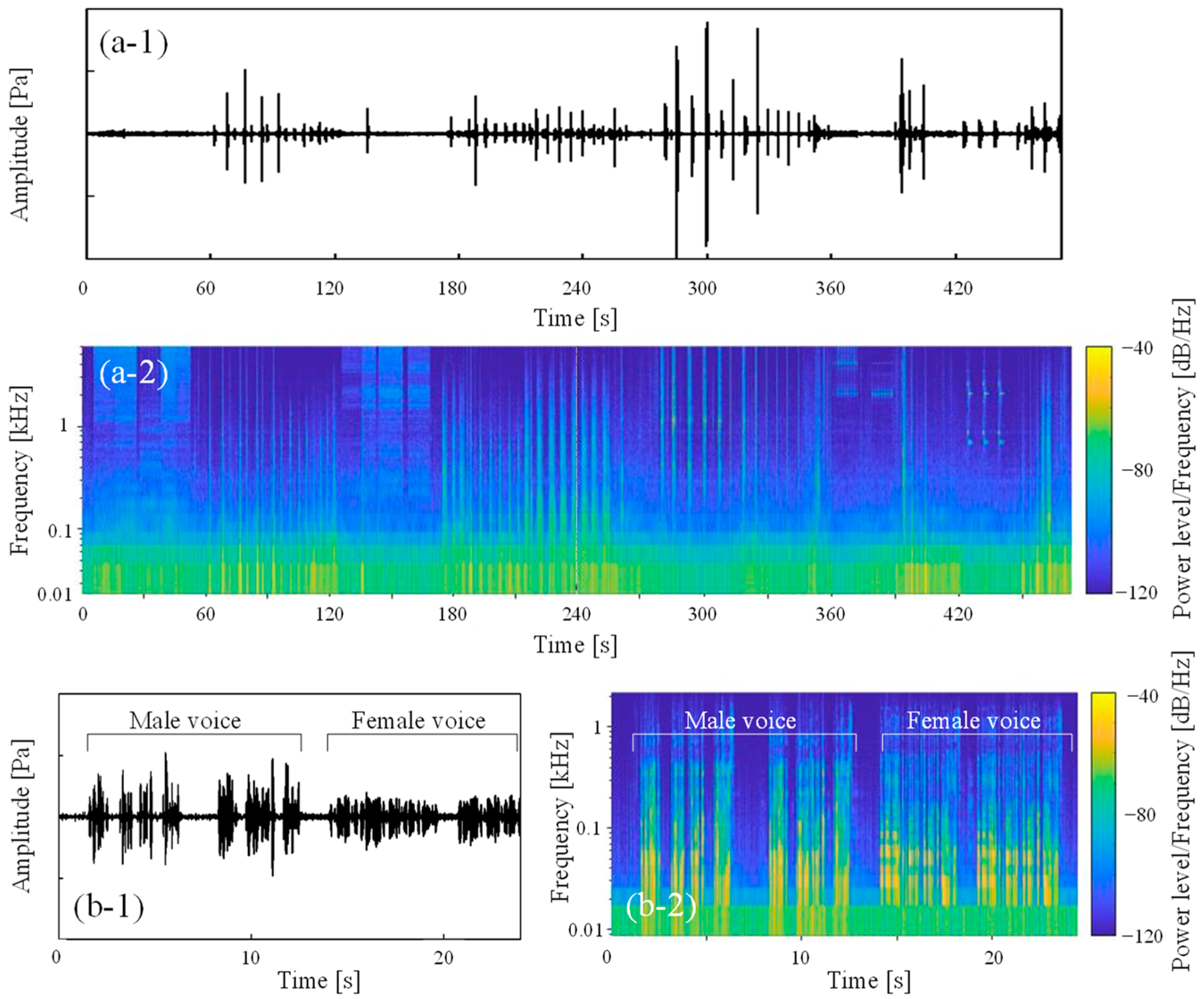
4.1. Measurement of Training Data
4.2. Generation of Classifier of Environmental Sound by Supervised ML
- Sound data for 5 s of each environmental sound were recorded in each of rooms A, B, and C. Here, the sounds of alarm, intercom, dropping a plastic bottle and purse, door opening and closing, and running water in the kitchen sink and washbasin were recorded as four kinds of sound data obtained at four different receiving points. The sounds of footsteps and knocking on a door were recorded as eight kinds of sound data, including two kinds of knocking patterns (single or three times) and two kinds of footsteps (approaching or moving away from the receiver) obtained at four different receiving points. In total, 144 sound data sequences were obtained in the three rooms.
- For the purpose of watering down the sound data, 20 kinds of sound data with a time duration of 3 s were extracted from each of the original sound data sequences by changing the starting point of the extraction in 0.1 s increments.
- By carrying out the process described in step 2 for all of the measured environmental sounds, a total of 144 × 20 = 2880 sets of data were created. However, as the sound data of human voices were measured only in an anechoic room, 40 kinds of voice data, including 20 data sets for each of male and female voices, resulting in 40 × 20 = 800 sets of training data, were prepared and used as the training data for step 1.
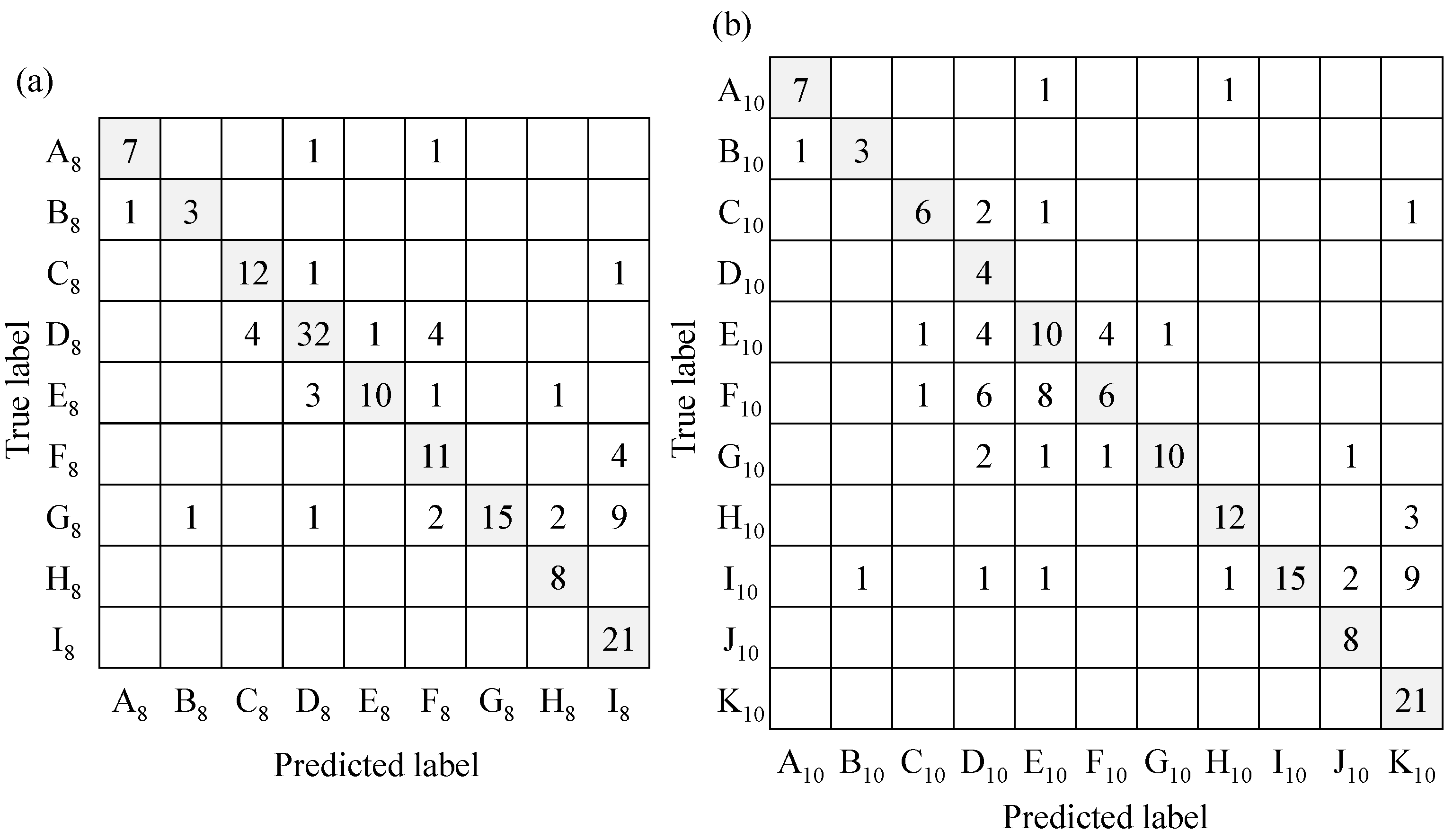
- As a result of following the above steps, 2880 + 800 = 3680 sets of training data were obtained. Using these data, a classifier was generated, and the accuracy of classification with this classifier was verified. It should be noted that there is room for considering whether excessively detailed ESR information should be presented to DHH people. For example, sufficient consideration needs to be given to whether the sound of running water in a sink or a washbasin should be classified and learned as separate categories or as the same category of “running water sound”. From the viewpoint of classifier generation, environmental sounds with similar characteristics are difficult to distinguish from each other, so the balance between what kind of information a DHH person wants to know and how accurately the ML-based classifier can classify the sounds are also important issues. Furthermore, how to set up the categorization of environmental sounds in ML is also important, as the misclassification of environmental sounds was indicated as a problem in a previous study [42]. Based on these considerations, the present study compared and evaluated each case in which a total of 12 types of sounds, including the 10 environmental sounds and 2 male and 2 female voices described above, were learned by categorizing them into 10 or 8 types, as shown in Table 4. Note that, as described in Section 2, if the sound pressure level was below the threshold sound pressure level, then it was judged to be silent and not applied to the classifier; if the sound pressure level was greater than the threshold level, then it was judged to be an environmental sound occurrence and applied to the classifier.
4.3. Validation Experiment for ML-Based Classifier
4.3.1. Method
4.3.2. Evaluation of Classification Results
4.3.3. Recognition Results and Discussion
5. Evaluation of the Proposed System
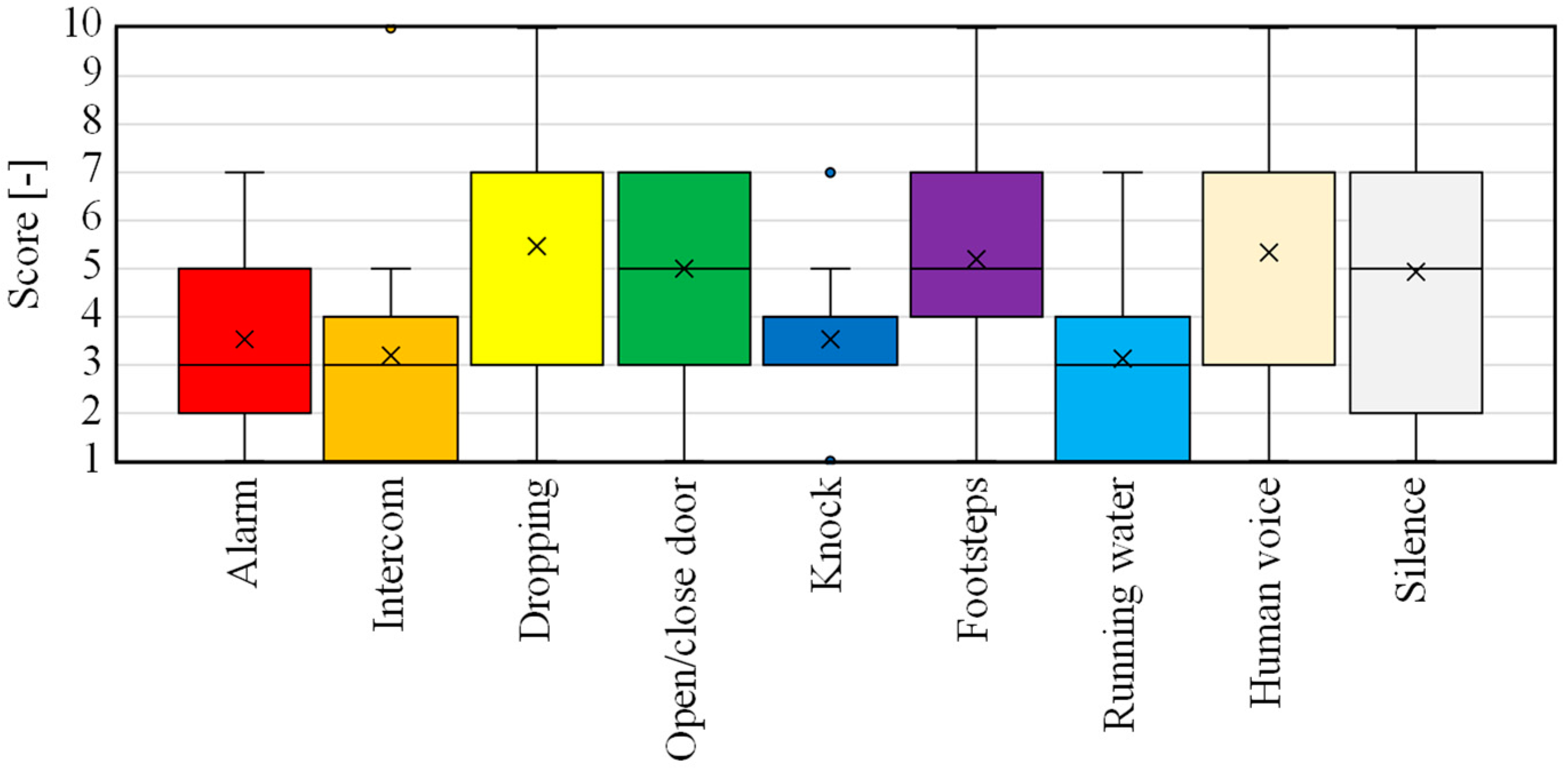
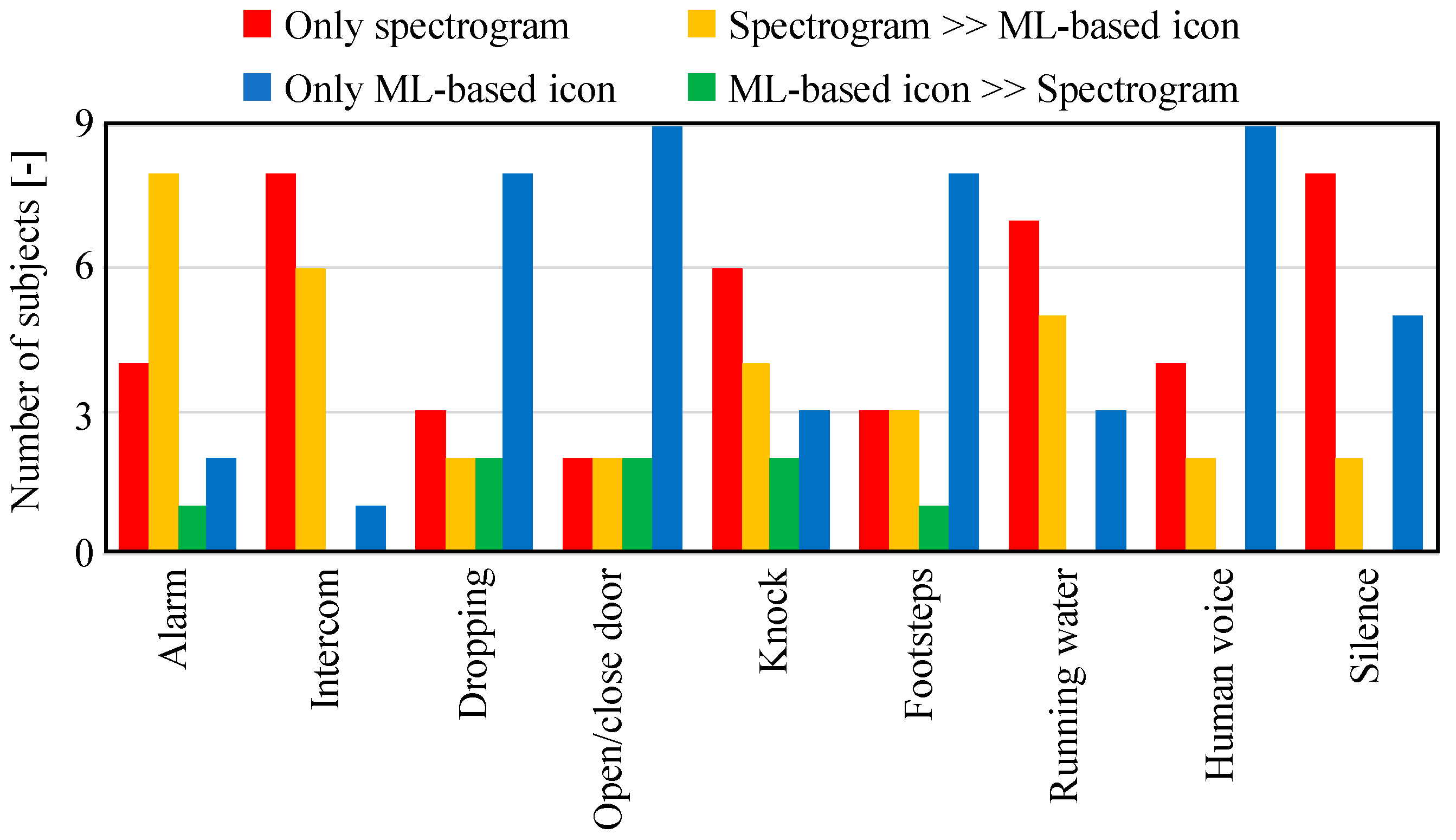
5.1. Experiment I
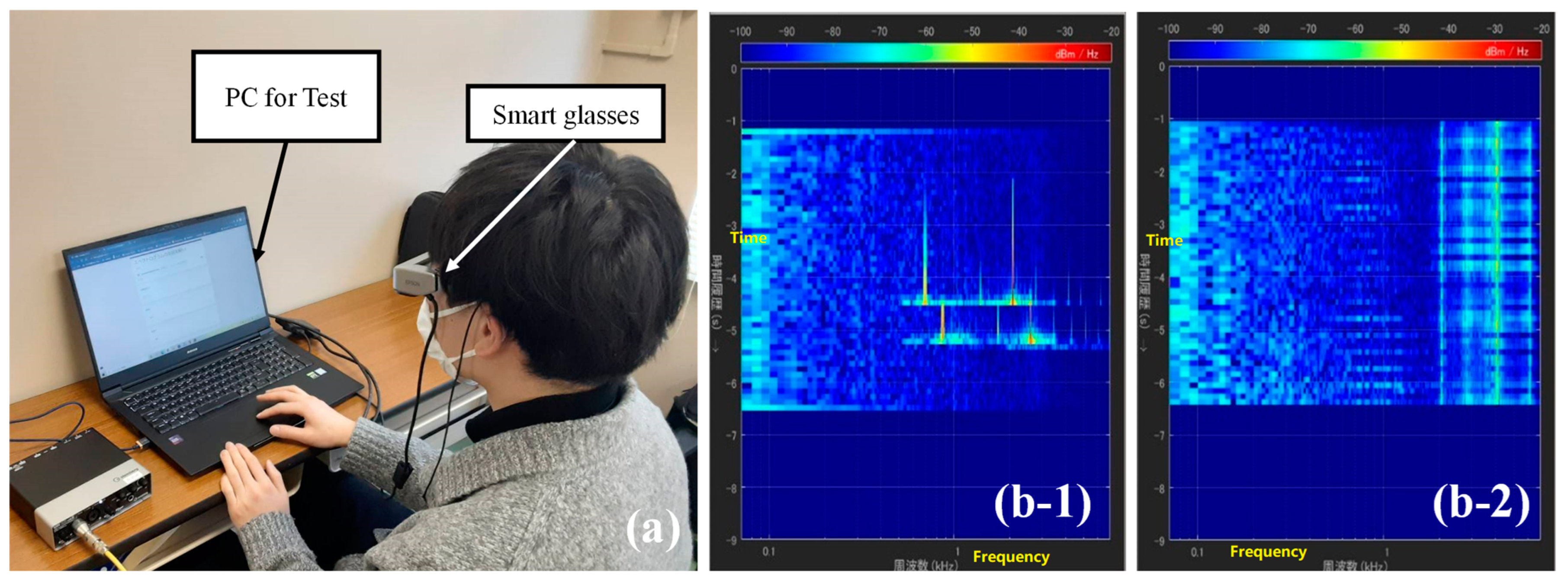
5.1.1. Method
- Each type of environmental sound was shown to the subjects while they watched the spectrogram flowing in real time. On the spectrogram, a 5 s waveform prepared as described above was shown flowing on the time axis from top to bottom. Subjects could ask to see the 5 s spectrogram again.
- The subjects took the first test comprising 24 questions. In the test, the subjects wore smart glasses as in Figure 8a, and the spectrogram was dynamically displayed on the smart glasses. Note that, although the spectrogram could be viewed again during the pre-study, in all three main tests, each spectrogram could be viewed only once.
- After the first test, the spectrogram was again displayed in real time according to the procedure described in step 1, and the subjects were asked to identify the environmental sound while being shown each spectrogram.
- The subjects took the second test, following the same procedure as in step 2.
- The subjects took the third instruction session using the same procedure as in step 1.
- The subjects took the third test, following the same procedure as in step 2.
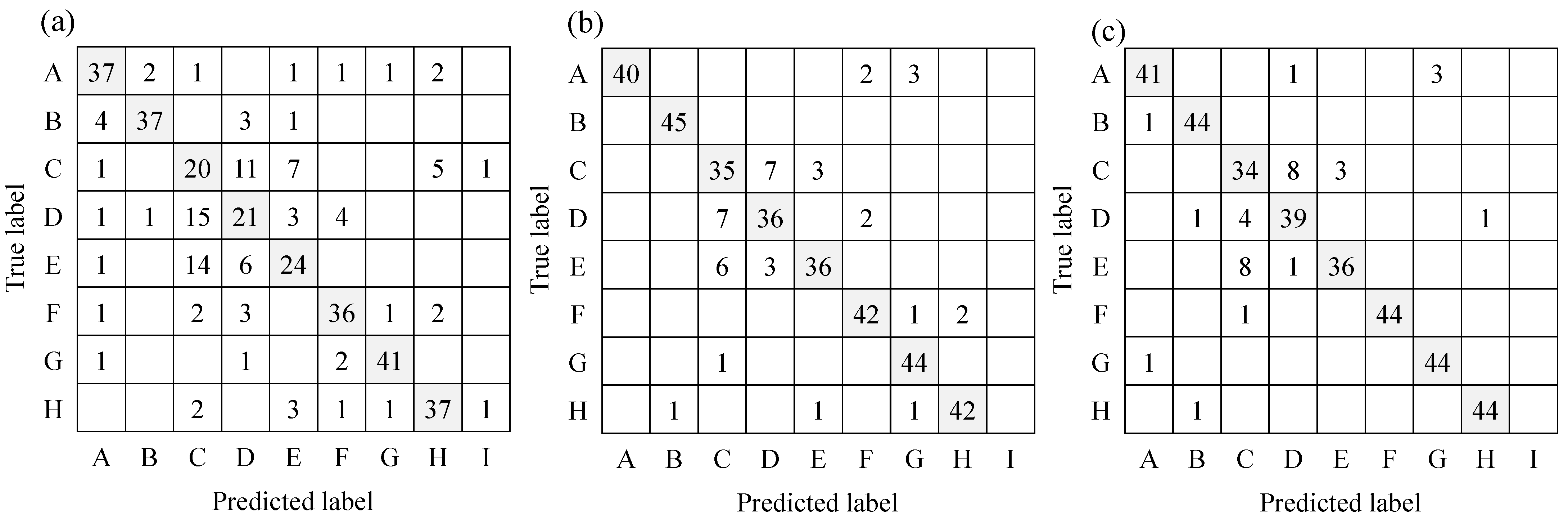
5.1.2. Results
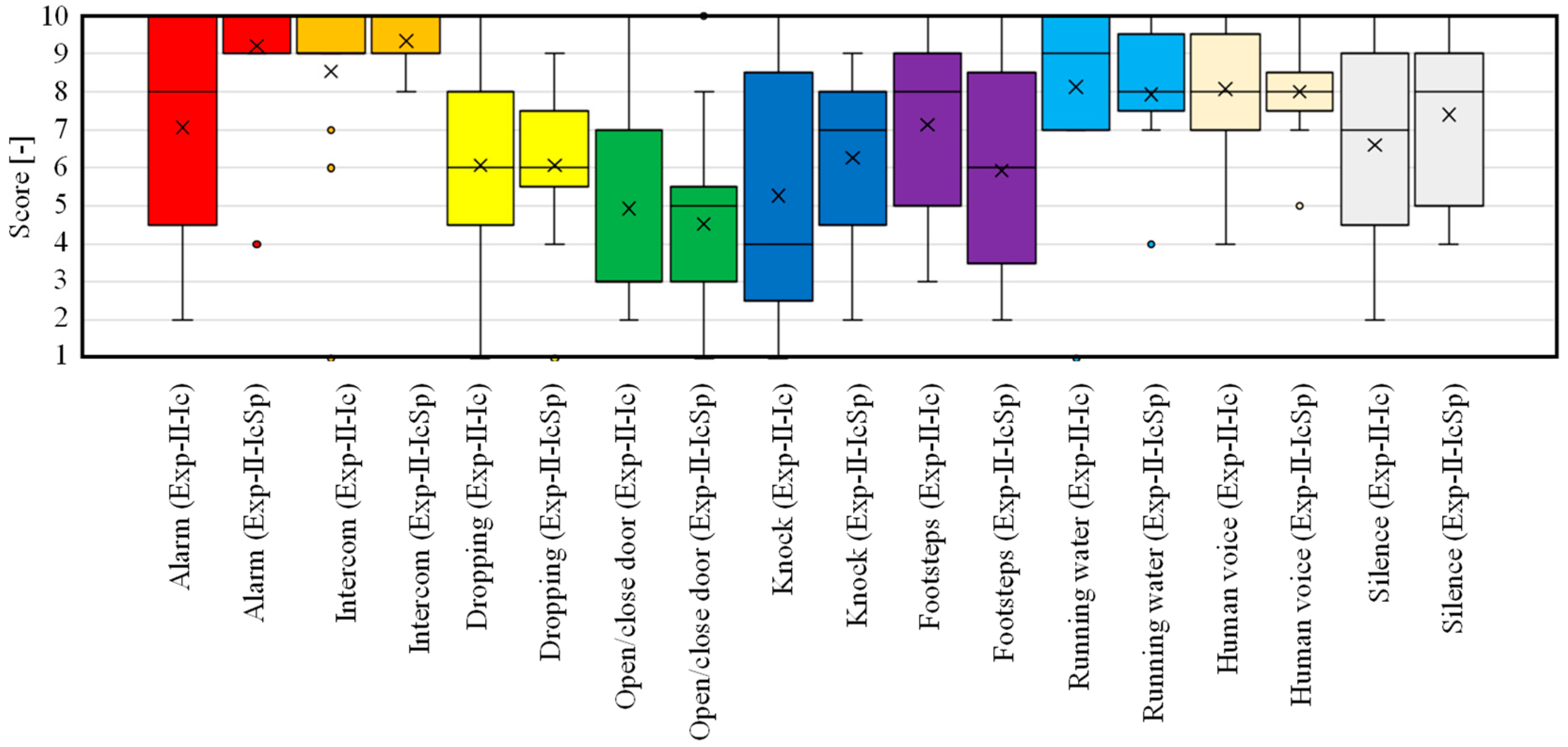
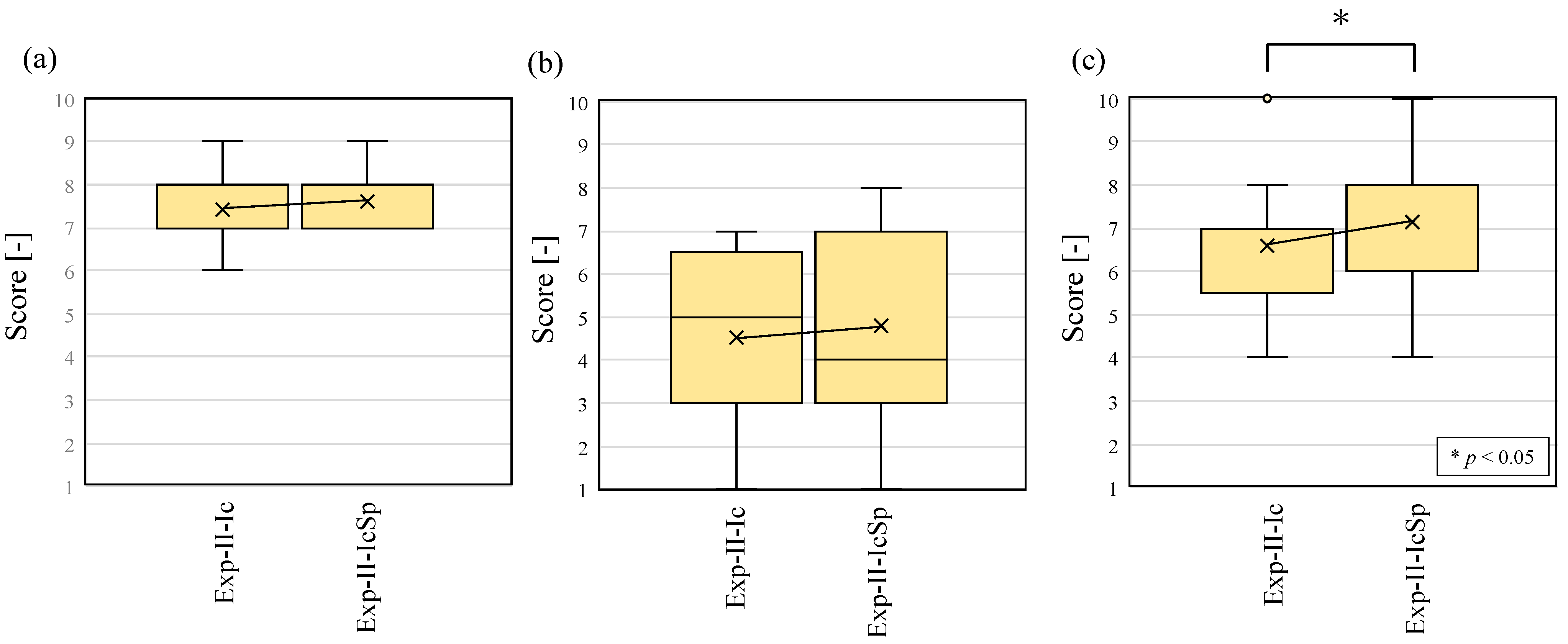
5.2. Experiment II
5.2.1. Method of Experiment
- Exp-II-Ic: Only the ML-based icons were presented on the smart glasses.
- Exp-II-IcSp: A real-time display of the spectrograms and the ML-based icons were presented on the smart glasses.
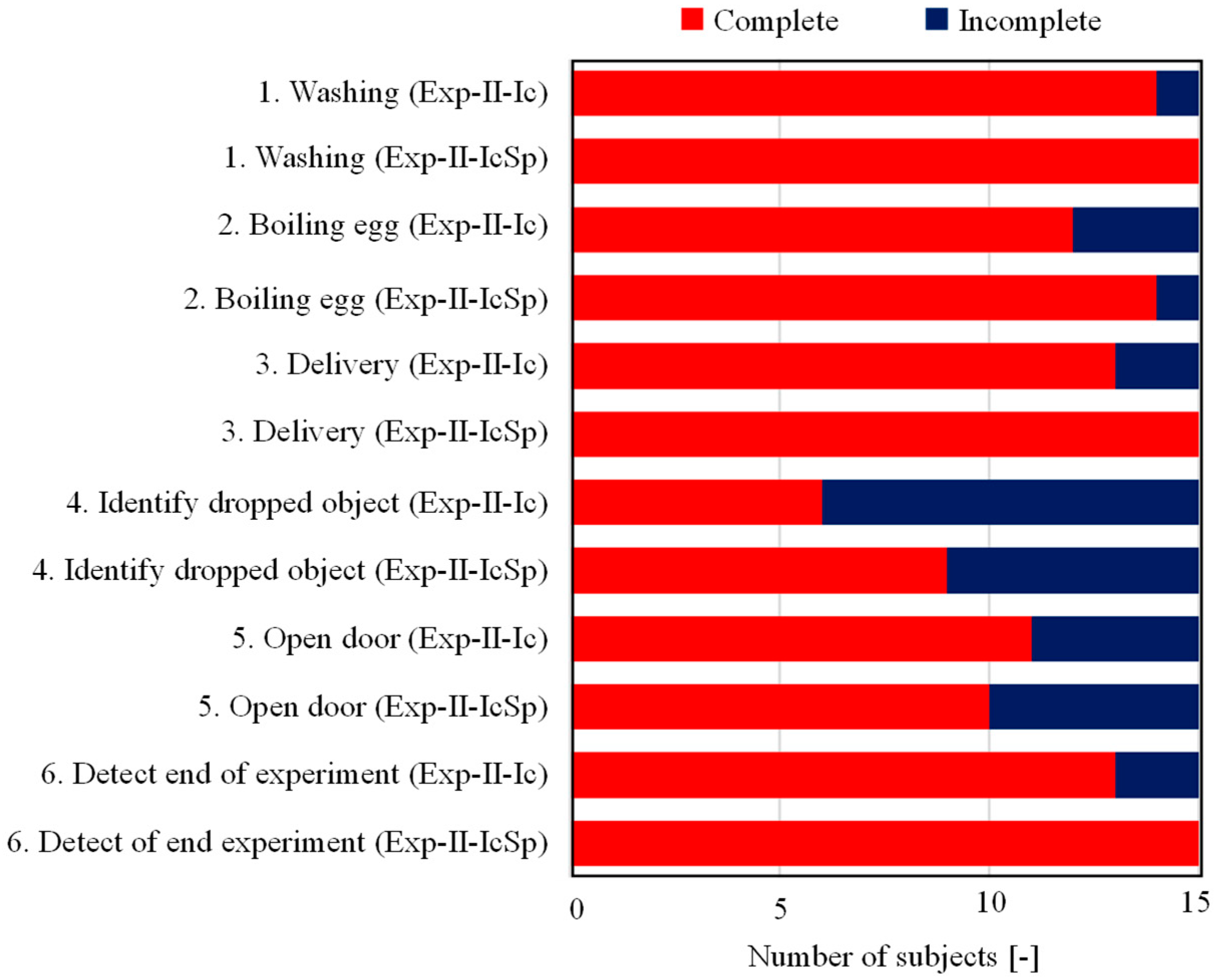
5.2.2. Experimental Daily Tasks
- 1.
- Set an alarm for the washing machine.
- 2.
- Set an alarm to boil eggs.
- 3.
- Interact with delivery staff.
- 4.
- Identify a dropped object.
- 5.
- Open the door in response to a housemate’s knock.
- 6.
- Detect the end of the experiment.
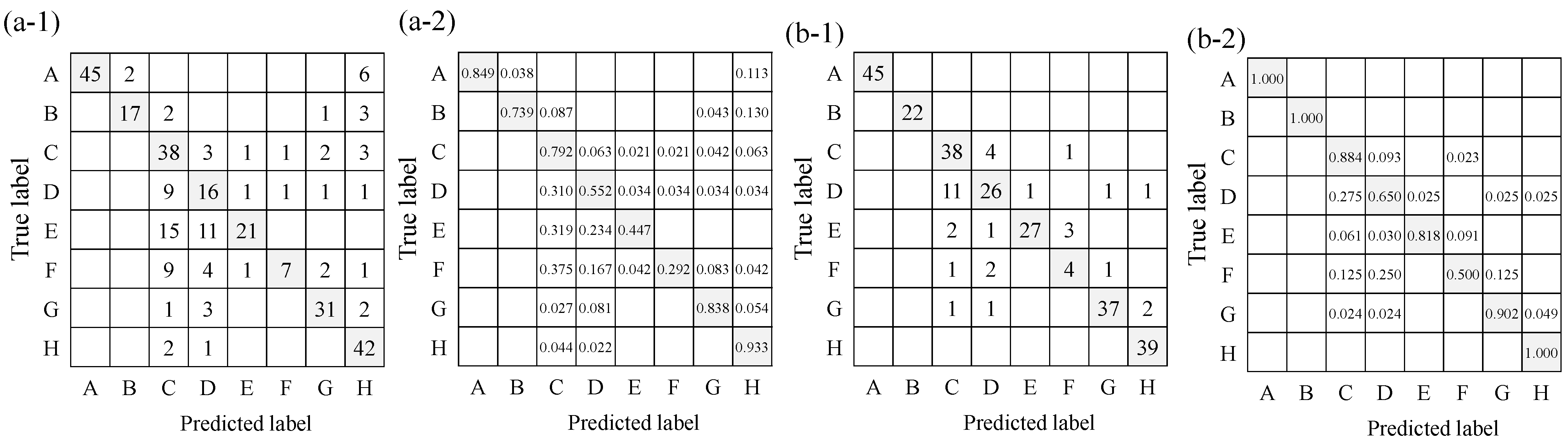
5.2.3. Results and Discussion
6. Conclusions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO. Deafness and Hearing Loss; World Health Organization: Geneva, Switzerland, 2014; Available online: https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (accessed on 15 November 2022).
- Gifford, R.; Ng, C. The relative contribution of visual and auditory cues to environmental perception. J. Environ. Psychol. 1982, 2, 275–284. [Google Scholar] [CrossRef]
- Shafiro, V.; Gygi, B.; Cheng, M.Y.; Vachhani, J.; Mulvey, M. Perception of environmental sounds by experienced cochlear implant patients. Ear Hear. 2011, 32, 511–523. [Google Scholar] [CrossRef] [PubMed]
- Shafiro, V.; Sheft, S.; Kuvadia, S.; Gygi, B. Environmental sound training in cochlear implant users. J. Speech Lang. Hear. Res. 2015, 58, 509–519. [Google Scholar] [CrossRef]
- Namatame, M.; Kanebako, J.; Kusunoki, F.; Inagaki, S. Effectiveness of Multisensory Methods in Learning Onomatopoeia for the Hearing-Impaired. In Computer Supported Education. CSEDU 2018; Springer: Cham, Switzerland, 2019; Volume 1022. [Google Scholar] [CrossRef]
- vom Stein, A.M.; Günthner, W.A. Using Smart Glasses for the Inclusion of Hearing-Impaired Warehouse Workers into Their Working Environment. In HCI in Business, Government, and Organizations: Information Systems. HCIBGO 2016; Springer: Cham, Switzerland, 2016; Volume 9752. [Google Scholar] [CrossRef]
- Bansai, A.; Naresh, K.G. Environmental sound classification: A descriptive review of the literature. Intell. Syst. Appl. 2022, 16, 200115. [Google Scholar] [CrossRef]
- Wang, J.-C.; Wang, J.-F.; He, K.W.; Hsu, C.S. Environmental sound classification using hybrid SVM/KNN classifier and MPEG-7 audio low-level descriptor. IEEE Int. Jt. Conf. Neural Netw. Proc. 2006, 2006, 1731–1735. [Google Scholar] [CrossRef]
- Lavner, Y.; Ruinskiy, D.A. Decision-tree-based algorithm for speech/music classification and segmentation. EURASIP J. Audio Speech Music. Process. 2009, 2009, 239892. [Google Scholar] [CrossRef]
- Couvreur, C.; Fontaine, V.; Gaunard, P.; Mubikangiey, C.G. Automatic classification of environmental noise events by hidden Markov models. Appl Acoust. 1998, 54, 187–206. [Google Scholar] [CrossRef]
- Demir, F.; Abdullah, D.A.; Sengur, A. A new deep CNN model for environmental sound classification. IEEE Access 2020, 8, 66529–66537. [Google Scholar] [CrossRef]
- Jatturas, C.; Chokkoedsakul, S.; Avudhva, P.D.N.; Pankaew, S.; Sopavanit, C.; Asdornwised, W. Feature-based and deep learning-based classification of environmental sound. IEEE Inter. Conf. Consum. Electron. Asia 2019, 2019, 126–130. [Google Scholar] [CrossRef]
- Jatturas, C.; Chokkoedsakul, S.; Ayudhya, P.C.N.; Pankaew, S.; Sopavanit, C.; Asdornwised, W. Recurrent neural networks for environmental sound recognition using Scikit-learn and Tensorflow. In Proceedings of the 2019 16th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Pattaya, Thailand, 10–13 July 2019; pp. 806–809. [Google Scholar] [CrossRef]
- Abdallah, E.E.; Fayyoumi, E. Assistive technology for deaf people based on Android platform. In Proceedings of the 11th International Conference on Future Networks and Communications (FNC 2016), Montreal, QC, Australia, 15–18 August 2016; Volume 94, pp. 295–301. [Google Scholar] [CrossRef]
- Rupasinghe, R.A.D.K.; Ailapperuma, D.C.R.; Silva, P.M.B.N.E.D.; Siriwardana, A.K.G.; Sudantha, B.H. A portable tool for deaf and hearing impaired people. ITRU Res. Symp. 2014, 6, 25–28. Available online: http://dl.lib.mrt.ac.lk/handle/123/12623 (accessed on 7 August 2023).
- Nandyal, S.; Kausar, S. Raspberrypi based assistive communication system for deaf, dumb and blind person. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 2278–3075. [Google Scholar] [CrossRef]
- Yağanoğlu, M.; Köse, C. Real-time detection of important sounds with a wearable vibration based device for hearing-impaired people. Electronics 2018, 7, 50. [Google Scholar] [CrossRef]
- Bragg, D.; Huynh, N.; Ladner, R.E. A personalizable mobile sound detector app design for deaf and hard-of-hearing users. In Proceedings of the 18th International ACM SIGACCESS Conference on Computers and Accessibility, Reno, NV, USA, 23–26 October 2016; pp. 3–13. [Google Scholar] [CrossRef]
- Dabran, I.; Avny, T.; Singher, E.; Danan, H.B. Augmented reality speech recognition for the hearing impaired. In Proceedings of the 2017 IEEE International Conference on Microwaves, Antennas, Communications and Electronic Systems (COMCAS), Tel-Aviv, Israel, 13–15 November 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Ribeiro, F.; Florêncio, D.; Chou, P.A.; Zhang, Z. Auditory augmented reality: Object sonification for the visually impaired. In Proceedings of the 2012 IEEE 14th International Workshop on Multimedia Signal Processing (MMSP), Banff, AB, Canada, 17–19 September 2012; pp. 319–324. [Google Scholar] [CrossRef]
- Findlater, L.; Chinh, B.; Jain, D.; Froehlich, J.; Kushalnagar, R.; Lin, A.C. Deaf and hard-of-hearing individuals’ preferences for wearable and mobile sound awareness technologies. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; Volume 46, pp. 1–13. [Google Scholar] [CrossRef]
- Inoue, A.; Ikeda, Y.; Yatabe, K.; Oikawa, Y. Visualization system for sound field using see-through head-mounted display. Acoust. Sci. Technol. 2019, 40, 1–11. [Google Scholar] [CrossRef]
- Deja, J.A.; Torre, A.D.; Lee, H.J.; Ciriaco, J.F.; Eroles, C.M. ViTune: A visualizer tool to allow the deaf and hard of hearing to see music with their eyes. In Proceedings of the CHI ’20: CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 2April 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Arcos, B.P.; Bakker, C.; Flipsen, B.; Balkenende, R. Practices of fault diagnosis in household appliances: Insights for design. J. Clean. Prod. 2020, 265, 121812. [Google Scholar] [CrossRef]
- Christensen, K.H.; Röhrs, J.; Ward, B.; Fer, I.; Broström, G.; Saetra, Ø.; Breivik, Ø. Surface wave measurements using a ship-mounted ultrasonic altimeter. Methods Oceanogr. 2013, 6, 1–15. [Google Scholar] [CrossRef]
- Hunt, J.W.; Arditi, M.; Foster, F.S. Ultrasound transducers for pulse-echo medical imaging. IEEE Trans. Biomed. Eng. 1983, 8, 453–481. [Google Scholar] [CrossRef]
- Potamitis, I.; Ntalampiras, S.; Jahn, O.; Riede, K. Automatic bird sound detection in long real-field recordings: Applications and tools. Appl. Acoust. 2014, 80, 1–9. [Google Scholar] [CrossRef]
- Bae, W.; Kim, K.; Yoon, J.-S. Interrater reliability of spectrogram for detecting wheezing in children. Pediat. Inter. 2022, 64, 1. [Google Scholar] [CrossRef]
- Ciuha, P.; Klemenc, B.; Solina, F. Visualization of concurrent tones in music with colours. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1677–1680. [Google Scholar] [CrossRef]
- Mardirossian, A.; Chew, E. Visualizing music: Tonal progressions and distributions. ISMIR 2007, 189–194. [Google Scholar] [CrossRef]
- Smith, S.M.; Williams, G.N. A visualization of music. In Proceedings of the Proceedings. Visualization ‘97 (Cat. No. 97CB36155), Phoenix, AZ, USA, 24 October 1997; Volume 97, pp. 499–503. [Google Scholar] [CrossRef]
- Miyazaki, R.; Fujishiro, I.; Hiraga, R. Exploring MIDI datasets. In Proceedings of the ACM SIGGRAPH 2003 Sketches & Applications, San Diego, CA, USA, 27–31 July 2003; p. 1. [Google Scholar] [CrossRef]
- Nanayakkara, S.C.; Wyse, L.; Ong, S.H.; Taylor, E.A. Enhancing musical experience for the hearing-impaired using visual and haptic displays. Hum.–Comput. Interact. 2013, 28, 115–160. [Google Scholar] [CrossRef]
- Varrasi, J. How Visuals Can Help Deaf Children “Hear”. Live Science. 2020. Available online: https://www.livescience.com/47004-visuals-help-deaf-childrenexperience-sound.html (accessed on 15 November 2022).
- Matthews, T.; Fong, J.; Ho-Ching FW-l Mankoff, J. Evaluating non-speech sound visualizations for the deaf. Behav. Inform. Technol. 2006, 25, 333–351. [Google Scholar] [CrossRef]
- Guo, R.; Yang, Y.; Kuang, J.; Bin, X.; Jain, D.; Goodman, S.; Findlater, L.; Froehlich, J. HoloSound: Combining speech and sound identification for deaf or hard of hearing users on a head-mounted display. In Proceedings of the 22nd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual, 26–28 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Peng, Y.-H.; Hsu, M.-W.; Taele, P.; Lin, T.-Y.; Lai, P.-E.; Hsu, L.; Chen, T.-C.; Wu, T.-Y.; Chen, Y.-A.; Tang, H.-H.; et al. SpeechBubbles: Enhancing captioning experiences for deaf and hard-of-hearing people in group conversations. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; Volume 293. [Google Scholar] [CrossRef]
- Jain, D.; Findlater, L.; Volger, C.; Zotkin, D.; Duraiswami, R.; Froehlich, J. Head-mounted display visualizations to support sound awareness for the deaf and hard of hearing. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 241–250. [Google Scholar] [CrossRef]
- Jain, D.; Chinh, B.; Findlater, L.; Kushalnagar, R.; Froehlich, J. Exploring augmented reality approaches to real-time captioning: A preliminary autoethnographic study. In Proceedings of the 2018 ACM Conference Companion Publication on Designing Interactive Systems, Hong Kong, China, 9–13 June 2018; pp. 7–11. [Google Scholar] [CrossRef]
- Jain, D.; Franz, R.; Findlater, L.; Cannon, J.; Kushalnagar, R.; Froehlich, J. Towards accessible conversations in a mobile context for people who are deaf and hard of hearing. In Proceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility, Galway, Ireland, 22–24 October 2018; pp. 81–92. [Google Scholar] [CrossRef]
- Jain, D.; Lin, A.C.; Amalachandran, M.; Zeng, A.; Guttman, R.; Findlater, L.; Froehlich, J. Exploring sound awareness in the home for people who are deaf or hard of hearing. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; Volume 94, pp. 1–13. [Google Scholar] [CrossRef]
- Jain, D.; Mack, K.; Amrous, A.; Wright, M.; Goodman, S.; Findlater, L.; Froehlich, J.E. HomeSound: An iterative field deployment of an in-home sound awareness system for deaf or hard of hearing users. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar] [CrossRef]
- Rahman, M.L.; Fattah, S.A. Smart glass for awareness of important sound to people with hearing disability. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; Volume 9230986, pp. 1527–1530. [Google Scholar] [CrossRef]
- Potter, R.K.; Kopp, G.A.; Green, H.C. Visible Speech; Van Nostrand: New York, NY, USA, 1947. [Google Scholar]
- Zue, V.; Cole, R. Experiments on spectrogram reading. In Proceedings of the ICASSP ‘79. IEEE International Conference on Acoustics, Speech, and Signal Processing, Washington, DC, USA, 2–4 April 1979; pp. 116–119. [Google Scholar] [CrossRef]
- Maki, J.E.; Gustafson, M.S.; Conklin, J.M.; Humphrey-Whitehead, B.K. The speech spectrographic display: Interpretation of visual patterns by hearing-impaired adults. J. Speech Hear. Disord. 1981, 46, 379–387. [Google Scholar] [CrossRef]
- Elssmann, S.F.; Maki, J.E. Speech spectrographic display: Use of visual feedback byhearing-impaired adults during independent articulation practice. Am. Ann. Deaf. 1987, 132, 276–279. [Google Scholar] [CrossRef]
- Greene, B.G.; Pisoni, D.B.; Carrell, T.D. Recognition of speech spectrograms. J. Acoust. Soc. Am. 1984, 76, 32–43. [Google Scholar] [CrossRef] [PubMed]
- Farani, A.A.S.; Chilton, E.H.S.; Shirley, R. Dynamical spectrogram, an aid for the deaf. In Proceedings of the 5th International Conference on Spoken Language Processing, Incorporating (The 7th Australian International Speech Science and Technology Conference), Sydney, Australia, 3 November–4 December 1998. [Google Scholar] [CrossRef]
- Farani, A.A.S.; Chilton, E.H.S.; Shirley, R. Dynamical spectrograms that can be perceived as visual gestures. In Proceedings of the IEEE-SP International Symposium on Time-Frequency and Time-Scale Analysis (Cat. No.98TH8380), Pittsburgh, PA, USA, 9 October 1998; pp. 537–540. [Google Scholar] [CrossRef]
- Hillier, A.F.; Hillier, C.E.; Hillier, D.A. A modified spectrogram with possible application as a visual hearing aid for the deaf. J. Acoust. Soc. Am. 2018, 144, 144–1517. [Google Scholar] [CrossRef] [PubMed]
- Morgan, D.L. Focus Groups and Social Interaction. In The SAGE Handbook of Interview Research: The Complexity of the Craft; Sage: Newcastle upon Tyne, UK, 2001. [Google Scholar] [CrossRef]
- Braun, V.; Clarke, V. Using thematic analysis in psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar] [CrossRef]
- Information and Culture Center for the Deaf. Survey on the Inconvenience Felt by Deaf People from Waking up in the Morning to Going to Bed at Night: Report of a Questionnaire Survey; Translated from Japanese; ICCD: Queens, NY, USA, 1995; Available online: https://www.kyoyohin.org/ja/research/pdf/fubensa_2_hearing_1995_9.pdf (accessed on 16 March 2023).
- Nakagawa, T.; Suto, M.; Maizono, K. A questionnaire survey on the daily use of residual hearing by persons with profound hearing loss. Audiol. Jpn. 2007, 50, 193–202. [Google Scholar] [CrossRef]
- Mielke, M.; Brück, R. A pilot study about the smartwatch as assistive device for deaf people. In Proceedings of the 17th International ACM SIGACCESS Conference on Computers & Accessibility, Lisbon, Portugal, 26–28 October 2015; pp. 301–302. [Google Scholar] [CrossRef]
- John, A.A.; Marschark, M.; Kincheloe, P.J. Deaf students’ reading and writing in college: Fluency, coherence, and comprehension. J. Deaf. Stud. Deaf. Educ. 2016, 21, 303–309. [Google Scholar] [CrossRef]
- Antonakos, E.; Anastasios, R.; Stefanos, A. A survey on mouth modeling and analysis for sign language recognition. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Dell’Aringa, A.H.B.; Adachi, E.S.; Dell’Aringa, A.R. Lip reading role in the hearing aid fitting process. Rev. Bras. De Otorrinolaringol. 2007, 73, 95–99. [Google Scholar] [CrossRef]
- Mayer, C.; Trezek, B.J. Literacy outcomes in deaf students with cochlear implants: Current state of the knowledge. J. Deaf. Stud. Deaf. Educ. 2018, 23, 1–16. [Google Scholar] [CrossRef]
- Nakamura, K. Use of the auditory modality and language acquisition. Jpn. J. Logop. Phoniatr. 2007, 48, 254–262. [Google Scholar] [CrossRef]
- Zhao, W.; Yin, B. Environmental sound classification based on adding noise. In Proceedings of the 2021 IEEE 2nd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 17–19 December 2021; pp. 887–892. [Google Scholar] [CrossRef]
- Hofstad, E.F.; Sorger, H.; Amundsen, T.; Langø, T.; Leira, H.O.; Kiss, G. Bronchoscopy using a head-mounted mixed reality device—A phantom study and a first in-patient user experience. Front. Virtual Real. 2023, 4, 940536. [Google Scholar] [CrossRef]
- Okachi, S.; Ito, T.; Sato, K.; Iwano, S.; Shinohara, Y.; Itoigawa, H.; Hashimoto, N. Virtual bronchoscopy-guided transbronchial biopsy simulation using a head-mounted display: A new style of flexible bronchoscopy. Surg. Innov. 2022, 29, 811–813. [Google Scholar] [CrossRef]
- Kashiwagi, S.; Asano, Y.; Goto, W.; Morisaki, T.; Shibutani, M.; Tanaka, H.; Hirakawa, K.; Ohira, M. Optical see-through head-mounted display (OST-HMD)-assisted needle biopsy for breast tumor: A technical innovation. In Vivo 2022, 36, 848–852. [Google Scholar] [CrossRef] [PubMed]
- Madeira, B.; Alves, P.; Marto, A.; Rodrigues, N.; Gonçalves, A. Integrating a head-mounted display with a mobile device for real-time augmented reality purposes. In Proceedings of the 16th International Joint Conference, Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2021), Virtual, 8–10 February 2021; pp. 313–319. [Google Scholar] [CrossRef]
- Mathworks, Display Frequency Spectrum of Time-Domain Signals. Available online: https://uk.mathworks.com/help/dsp/ref/dsp.spectrumanalyzer-system-object.html (accessed on 7 August 2023).
- Kaufeld, M.; Mundt, M.; Forst, S.; Hecht, H. Optical see-through augmented reality can induce severe motion sickness. Displays 2022, 74, 102283. [Google Scholar] [CrossRef]
- Sprengard, R.; Bachhuber, F. Weight reduction is a key enabler for augmented and mixed reality advances. Inf. Disp. 2022, 38, 8–12. [Google Scholar] [CrossRef]
- Iskandar, A.; Alfonse, M.; Roushdy, M.; El-Horbaty, E.-S.M. Shallow and deep learning in footstep recognition: A survey. In Proceedings of the 2022 5th International Conference on Computing and Informatics (ICCI), Cairo, Egypt, 9–10 March 2022; pp. 364–368. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Sub-Category | Coded Contents | Current Interview | Reference (ICCD 1995) [54] | Other References | |||
|---|---|---|---|---|---|---|---|---|
| Number of Respondent | Answered Contents | |||||||
| General issue | Detecting evenets | Difficulty of detecting events | ✔ | ― | ✔ | Jain et al., 2020 [42] | ||
| Communication | Difficulty in communicating with others | ✔ | ― | ― | ||||
| Reading text | Difficulty in reading text with a natural hearing impairment person | ✔ | ― | ✔ | John et al., 2016 [57] | |||
| Interior issue | Auditory and vibration detection | Difficulty of waking up without alarm | ✔ | ✔ | 45/180 | Feel difficulty in waking up alone | ✔ | Matthews et al., 2006 [35] Bragg et al., 2016 [18] |
| ✔ | 66/180 | Usually wake up by using vibration alarm | ✔ | Jain et al., 2020 [42] | ||||
| Auditory detection | Difficulty in detecting the state of cooking | ― | ✔ | 61/180 | Feel difficulty in detecting boiling | ✔ | Jain et al., 2020 [42] | |
| Auditory detection | Difficulty of detecting status change of home appliances (such as kettles, microwave ovens, and smoke detectors) | ― | ― | ✔ | Matthews et al., 2006 [35] Mielke et al., 2015 [56] Bragg et al., 2016 [18] | |||
| Auditory detection | Difficulty in detecting operation sound (such as vacuum cleaner or running water) | ✔ | ✔ | 23/180 | Feel difficulty in detecting running water | ✔ | Matthews et al., 2006 [35] | |
| ✔ | 41/180 | Feel difficulty in detecting to left washing machine finished | ✔ | Mielke et al., 2015 [56] | ||||
| ✔ | 11/180 | Feel difficulty in detecting to left vacuum cleaner on | ― | |||||
| Auditory detection | Difficulty in detecting rain | ✔ | ― | ― | ||||
| Auditory detection | Difficulty of detecting knocking on doors | ✔ | ― | ✔ | Matthews et al., 2006 [35] Jain et al., 2020 [42] | |||
| Auditory detection | Difficulty of detecting transient sound like dropping things | ✔ | ― | ✔ | Bragg et al., 2016 [18] | |||
| Auditory detection | Difficulty of detecting someone coming to their home | ― | ✔ | 54/180 | Feel difficulty in detecting someone come to home | ✔ | Mielke et al., 2015 [56] Bragg et al., 2016 [18] (detection of doorbell) | |
| Auditory detection | Difficulty of detecting someone’s replying voice | ― | ✔ | 32/180 | Feel difficulty of detecting someone’s replying voice | ✔ | Jain et al., 2020 [42] (difficulty of detecting voices directed to me) | |
| Auditory detection | Difficulty of detectin baby crying | ― | ― | ✔ | Mielke et al., 2015 [56] Jain et al., 2020 [42] | |||
| Visual detection | Alternative methods for event detection; use of visual information such as flashing lights | ✔ | ― | ✔ | Jain et al., 2020 [42] | |||
| Exterior issue | Auditory detection | Difficulty in detecting information such as approaching vehicle sounds or someone’s call | ✔ | ✔ | 72/180 | Feel difficulty in detecting approaching vehicles and someone’s call | ✔ | Nakagawa et al., 2007 [55] Bragg et al., 2016 [18] |
| Auditory detection | Difficulty in detecting platform or internal announcements or emergency broadcasts | ― | ✔ | 82/180 | Feel difficulty in detecting platform or internal announcements or emergency broadcasts | ✔ | Bragg et al., 2016 [18] | |
| Auditory detection | Difficulty in detecting store clerk’s call of his and her name | ― | ✔ | 103/180 | Feel difficulty in detecting hospital clerk’s call | ― | ||
| ✔ | 72/180 | Feel difficulty in detecting clerk’s call of banks or post offices | ― | |||||
| Auditory detection | Difficulty in communicating with doctor in hospital | ✔ | ✔ | 79/180 | Feel difficulty in communicating with doctor in hospital | ― | ||
| Auditory detection | Difficulty in communicating with deriver of taxi | ― | ✔ | 62/180 | Drivers talk while facing forward, so you don’t realise they are talking | ― | ||
| ✔ | 31/180 | Telling the driver where you are going is not understood | ― | |||||
| Auditory detection | Difficulty in hearing the sirens of police cars or ambulances | ― | ✔ | 21/180 | Feel difficulty in hearing the sirens of police cars or ambulances when driving | ✔ | Mielke et al., 2015 [56] Bragg et al., 2016 [18] Jain et al., 2020 [42] | |
| Auditory detection | Difficulty in communicating with store clerk | ― | ✔ | 70/180 | Feed difficulty in hearing the clerk’s explanation of products | ― | ||
| Interior and exterior issues | Auditory detection | Difficulty of detecting the sound of someone’s approaching footsteps | ✔ | ― | ✔ | Jain et al., 2020 [42] | ||
| Auditory detection | Difficulty in using telephone | ― | ✔ | 39/180 | Feel difficulty in using telephone in case of calling ambulances | ― | ||
| Auditory detection | Difficulty in obtaining information in case of disaster | ― | ✔ | 39/180 | Feel difficulty in obtaining information in case of disaster | ― | ||
| Categories | Sounds |
|---|---|
| Tonal sounds | Alarm Intercom Human voice (male) Human voice (female) |
| Transient sounds | Dropping purse Dropping plastic bottle Knocking on door Opening door Closing door Footsteps |
| Steady-state sounds | Running water on the sink Running water on the washbasin |
| Structure of the Building | Area of Space | Measured Sounds | |
|---|---|---|---|
| Room A | Wooden structure | 33. 5 m2 | Alarm Intercom Dropping plastic bottle Dropping purse Opening door Closing door Knocking on door Footsteps Running water from the sink Running water from the washbasin |
| Room B | Reinforce-concrete structure | 9.1 m2 | |
| Room C | Reinforce concrete structure | 30.0 m2 | |
| Anechoic room | Wooden panel structure | 3.8 m2 | Human voice (male) Human voice (female) |
| Sounds | Categorization | |
|---|---|---|
| Eight Types | Ten Types | |
| Alarm | Alarm sounds | Alarm sounds |
| Intercom | Intercom sounds | Intercom sounds |
| Dropping purse | Dropping sound | Sound of a dropping purse |
| Dropping plastic bottle | Sound of dropping a plastic bottle | |
| Opening door | Sound of opening/closing the door | Sound of opening the door |
| Closing door | Sound of closing the door | |
| Knocking on door | Sound of knocking on the door | Sound of knocking on the door |
| Footsteps | Sound of footsteps | Sound of footsteps |
| Running water on the sink | Sound of runnning water | Sound of runnning water |
| Running water on the washbasin | ||
| Human voice (male) | Human voice | Human voice |
| Human voice (female) | ||
| Predicted Class | |||
|---|---|---|---|
| Positive | Negative | ||
| True class | Positive | TP (True Positive) | FN (False Negative) |
| Negative | FP (False positive) | TN (True Negative) | |
| Environmental Sounds | Accuracy | Recall | Precision | F-Score | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 Sub-Categories | 10 Sub-Categories | 8 | 10 | 8 | 10 | 8 | 10 | 8 | 10 | ||||
| A8 | Alarm | A10 | Alarm | 0.70 | 0.59 | 0.78 | 0.78 | 0.88 | 0.88 | 0.82 | 0.82 | ||
| B8 | Intercom | B10 | Intercom | 0.75 | 0.75 | 0.75 | 0.75 | 0.75 | 0.75 | ||||
| C8 | Dropping | C10 | Dropping plastic bottle | 0.86 | 0.6 | 0.67 | 0.75 | 0.75 | 0.67 | ||||
| D10 | Dropping purse | 0.86 | 1 | 0.67 | 0.17 | 0.75 | 0.3 | ||||||
| D8 | Opening/Closing door | E10 | Opening door | 0.78 | 0.5 | 0.8 | 0.43 | 0.79 | 0.47 | ||||
| F10 | Closing door | 0.78 | 0.29 | 0.8 | 0.55 | 0.79 | 0.38 | ||||||
| E8 | Knocking on door | G10 | Knocking on door | 0.67 | 0.67 | 0.91 | 0.91 | 0.77 | 0.77 | ||||
| F8 | Footsteps | H10 | Footsteps | 0.67 | 0.67 | 0.36 | 0.53 | 0.47 | 0.59 | ||||
| G8 | Running water | I10 | Running water | 0.5 | 0.5 | 1 | 1 | 0.67 | 0.67 | ||||
| H8 | Human voice | J10 | Human voice | 1 | 1 | 0.73 | 0.73 | 0.84 | 0.84 | ||||
| I8 | Silence | K10 | Silence | 0.81 | 0.81 | 0.58 | 0.58 | 0.68 | 0.68 | ||||
| Environmental Sounds | Accuracy | Recall | Precision | F-Score | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exp-1st | Exp-2nd | Exp-3rd | Exp-1st | Exp-2nd | Exp-3rd | Exp-1st | Exp-2nd | Exp-3rd | Exp-1st | Exp-2nd | Exp-3rd | |||
| Alarm | 0.70 | 0.89 | 0.91 | 0.82 | 0.89 | 0.91 | 0.80 | 1.00 | 0.95 | 0.81 | 0.94 | 0.93 | ||
| Intercom | 0.82 | 1.00 | 0.98 | 0.93 | 0.98 | 0.96 | 0.87 | 0.99 | 0.97 | |||||
| Dropping | 0.44 | 0.78 | 0.76 | 0.37 | 0.71 | 0.72 | 0.40 | 0.75 | 0.74 | |||||
| Opening/closing door | 0.47 | 0.80 | 0.87 | 0.47 | 0.78 | 0.80 | 0.47 | 0.79 | 0.83 | |||||
| Knocking on door | 0.53 | 0.80 | 0.80 | 0.62 | 0.90 | 0.92 | 0.57 | 0.85 | 0.86 | |||||
| Footsteps | 0.80 | 0.93 | 0.98 | 0.82 | 0.91 | 1.00 | 0.81 | 0.92 | 0.99 | |||||
| Running water | 0.91 | 0.98 | 0.98 | 0.93 | 0.90 | 0.94 | 0.92 | 0.94 | 0.96 | |||||
| Human voice | 0.82 | 0.93 | 0.98 | 0.80 | 0.96 | 0.98 | 0.81 | 0.94 | 0.98 | |||||
| Environmental Sounds | Accuracy | Recall | Precision | F-Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Exp-II-Ic | Exp-II-IcSp | Exp-II-Ic | Exp-II-IcSp | Exp-II-Ic | Exp-II-IcSp | Exp-II-Ic | Exp-II-IcSp | |||
| Alarm | 0.71 | 0.88 | 0.85 | 1.00 | 1.00 | 1.00 | 0.92 | 1.00 | ||
| Intercom | 0.74 | 1.00 | 0.90 | 1.00 | 0.81 | 1.00 | ||||
| Dropping | 0.79 | 0.88 | 0.50 | 0.72 | 0.61 | 0.79 | ||||
| Opening/closing door | 0.55 | 0.65 | 0.42 | 0.77 | 0.48 | 0.70 | ||||
| Knocking on door | 0.45 | 0.82 | 0.88 | 0.96 | 0.59 | 0.89 | ||||
| Footsteps | 0.29 | 0.50 | 0.78 | 0.50 | 0.42 | 0.50 | ||||
| Running water | 0.84 | 0.90 | 0.84 | 0.95 | 0.84 | 0.93 | ||||
| Human voice | 0.93 | 1.00 | 0.72 | 0.93 | 0.82 | 0.96 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asakura, T. Augmented-Reality Presentation of Household Sounds for Deaf and Hard-of-Hearing People. Sensors 2023, 23, 7616. https://doi.org/10.3390/s23177616
Asakura T. Augmented-Reality Presentation of Household Sounds for Deaf and Hard-of-Hearing People. Sensors. 2023; 23(17):7616. https://doi.org/10.3390/s23177616
Chicago/Turabian StyleAsakura, Takumi. 2023. "Augmented-Reality Presentation of Household Sounds for Deaf and Hard-of-Hearing People" Sensors 23, no. 17: 7616. https://doi.org/10.3390/s23177616
APA StyleAsakura, T. (2023). Augmented-Reality Presentation of Household Sounds for Deaf and Hard-of-Hearing People. Sensors, 23(17), 7616. https://doi.org/10.3390/s23177616