
IoTSim: Internet of Things-Oriented Binary Code Similarity Detection with Multiple Block Relations


Abstract
:1. Introduction
- We propose a novel deeply cross-architecture approach using NLP techniques for IoT-oriented binary code similarity detection tasks. To resolve problem P1, we lift assembly code into microcode and propose a newly designed pre-training task to mitigate OOV issues;
- To resolve problem P2, we consider multiple relations between basic blocks to generate DCFGs to capture rich contextual information between basic blocks. We then use a GNN model to integrate basic block embeddings based on DCFGs for generating function embeddings;
- We implement IoTSim which can be used for vulnerability detection and firmware component analysis in the real world. We evaluate IoTSim with extensive experiments. The experiments show that IoTSim outperforms the state-of-the-art approaches such as Trex, SAFE, GMN, and PalmTree.
2. Related Work
3. Problem Definition
4. Design
4.1. Preprocessor
4.2. Block Semantic Model
4.2.1. Language Model
4.2.2. Pre-Training Tasks
4.3. Function Embedding Model
4.3.1. Block Relation Matrix
4.3.2. Function Embedding Generation
4.3.3. Model Training
5. Evaluation
- RQ.1: can IoTSim effectively identify similar function pairs when given functions from different compilers, architectures, and optimization levels?
- RQ.2: how much does DCFG contribute to the performance of IoTSim?
- RQ.3: what are the applications of IoTSim in practice?
5.1. Implementation and Setup
5.1.1. Baselines
- Graph Matching Networks (GMN). Marcelli et al. [63] show that a GMN based on CFGs has natural advantages in cross-architecture scenarios;
- PalmTree [34], one of the state-of-the-art BCSD methods, employs pre-trained models using the BERT model to generate semantic embeddings for binary code (https://github.com/palmtreemodel/PalmTree, accessed on 10 March 2023);
- SAFE [35] uses a word2vec model [51] and a recurrent neural network to generate function embeddings (https://github.com/facebookresearch/SAFEtorch, accessed on 10 March 2023);
- Trex [13], the state-of-the-art BCSD approach, uses transfer-learning-based models that utilize micro-traces to generate function embeddings for comparing similar functions (https://github.com/CUMLSec/trex, accessed on 10 March 2023).
5.1.2. Benchmarks
5.1.3. Metrics
- Recall represents the ratio of correctly matched functions to the total number of function pairs with similar functions. A high recall suggests a low false-negative rate;
- Precision denotes the ratio of correctly matched functions to the total number of function pairs predicted as similar. High precision indicates a low false-positive rate;
- MRR stands for Mean Reciprocal Rank, which is a relative score that calculates the average or mean of the inverse of the ranks at which the first relevant function is retrieved for a set of queries.
5.2. Evaluation on Multiple Scenarios
5.3. Ablation Study
5.4. Applications
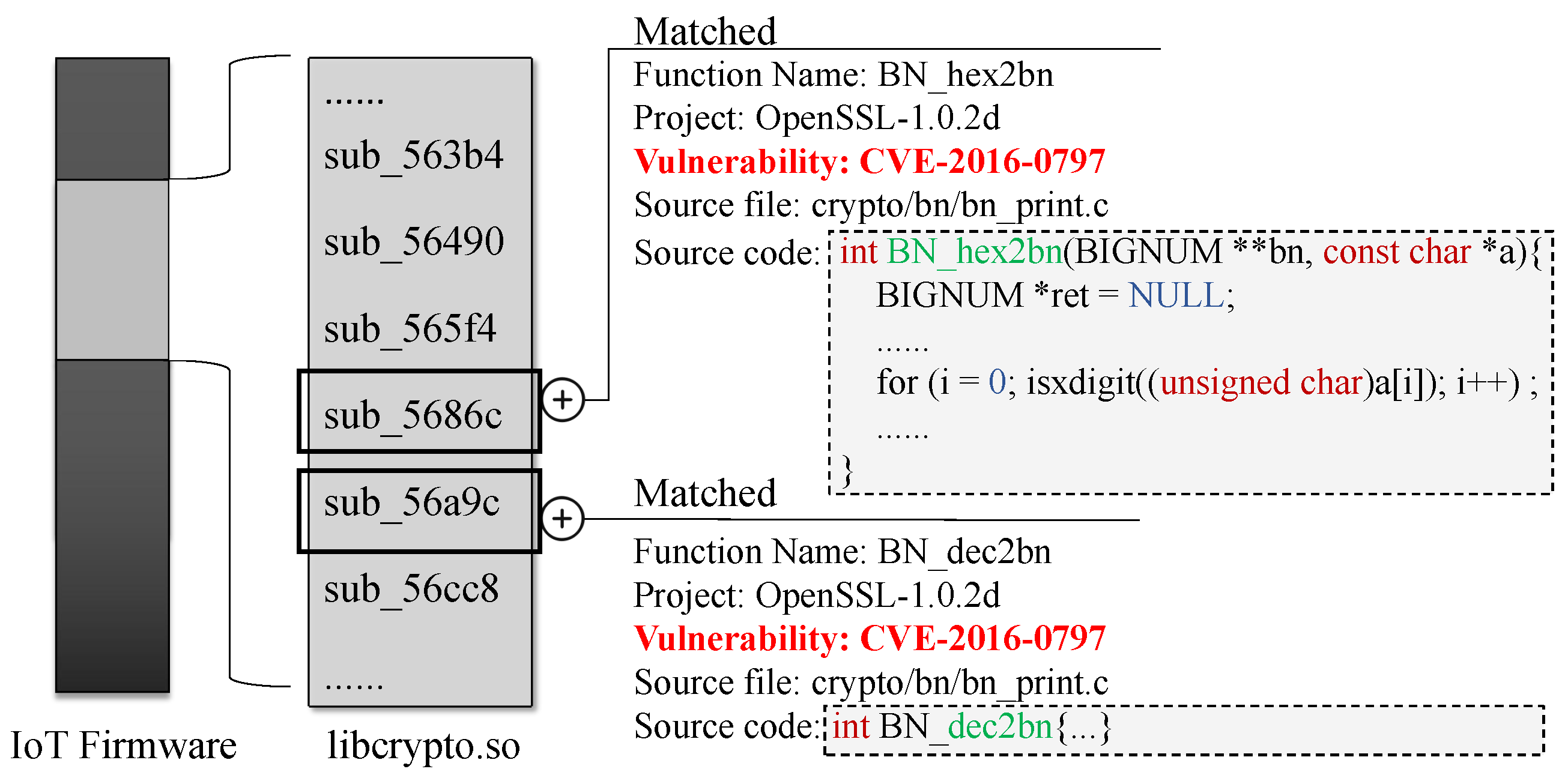
5.4.1. Vulnerability Detection
5.4.2. Component Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BCSD | Binary Code Similarity Detection |
| IoT | Internet of Things |
| OOV | Out-of-Vocabulary |
| TPC | Third-Parity Components |
| ISA | Instruction Set Architecture |
| CVE | Common Vulnerabilities and Exposures |
| ML | Machine Learning |
| CFG | Control Flow Graph |
| IR | Intermediate Representation |
| GNN | Graph Neural Network |
| NLP | Natural Language processing |
| GCN | Graph Convolutional Network |
References
- Lionel Sujay Vailshery. IoT Connected Devices Worldwide 2019–2023. 2023. Available online: https://news.sophos.com/en-us/2022/05/04/attacking-emotets-control-flow-flattening/ (accessed on 3 March 2023).
- Zhao, B.; Ji, S.; Lee, W.H.; Lin, C.; Weng, H.; Wu, J.; Zhou, P.; Fang, L.; Beyah, R. A large-scale empirical study on the vulnerability of deployed iot devices. IEEE Trans. Dependable Secur. Comput. 2020, 19, 1826–1840. [Google Scholar] [CrossRef]
- Wang, Q.; Ji, S.; Tian, Y.; Zhang, X.; Zhao, B.; Kan, Y.; Lin, Z.; Lin, C.; Deng, S.; Liu, A.X.; et al. MPInspector: A Systematic and Automatic Approach for Evaluating the Security of IoT Messaging Protocols. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual, 11–13 August 2021; pp. 4205–4222. [Google Scholar]
- Costin, A.; Zaddach, J. Iot malware: Comprehensive survey, analysis framework and case studies. BlackHat USA 2018, 1, 1–9. [Google Scholar]
- Luo, Z.; Wang, B.; Tang, Y.; Xie, W. Semantic-based representation binary clone detection for cross-architectures in the internet of things. Appl. Sci. 2019, 9, 3283. [Google Scholar] [CrossRef]
- Sun, H.; Wang, X.; Buyya, R.; Su, J. CloudEyes: Cloud-based malware detection with reversible sketch for resource-constrained internet of things (IoT) devices. Softw. Pract. Exp. 2017, 47, 421–441. [Google Scholar] [CrossRef]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. DDoS in the IoT: Mirai and other botnets. Computer 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Feng, Q.; Wang, M.; Zhang, M.; Zhou, R.; Henderson, A.; Yin, H. Extracting conditional formulas for cross-platform bug search. In Proceedings of the 2017 ACM Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 346–359. [Google Scholar] [CrossRef]
- Pewny, J.; Garmany, B.; Gawlik, R.; Rossow, C.; Holz, T. Cross-architecture bug search in binary executables. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015; pp. 709–724. [Google Scholar]
- Gao, J.; Yang, X.; Fu, Y.; Jiang, Y.; Sun, J. Vulseeker: A semantic learning based vulnerability seeker for cross-platform binary. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 896–899. [Google Scholar] [CrossRef]
- Wang, H.; Qu, W.; Katz, G.; Zhu, W.; Gao, Z.; Qiu, H.; Zhuge, J.; Zhang, C. jTrans: Jump-Aware Transformer for Binary Code Similarity. arXiv 2022, arXiv:2205.12713. [Google Scholar]
- Lin, J.; Wang, D.; Chang, R.; Wu, L.; Zhou, Y.; Ren, K. EnBinDiff: Identifying Data-only Patches for Binaries. IEEE Trans. Dependable Secur. Comput. 2021, 20, 343–359. [Google Scholar] [CrossRef]
- Pei, K.; Xuan, Z.; Yang, J.; Jana, S.; Ray, B. Trex: Learning execution semantics from micro-traces for binary similarity. arXiv 2020, arXiv:2012.08680. [Google Scholar]
- Ding, S.H.; Fung, B.C.; Charland, P. Asm2Vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 19–23 May 2019; pp. 472–489. [Google Scholar] [CrossRef]
- David, Y.; Partush, N.; Yahav, E. Statistical similarity of binaries. In Proceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation, Santa Barbara, CA, USA, 13–17 June 2016; pp. 266–280. [Google Scholar]
- Yang, S.; Cheng, L.; Zeng, Y.; Lang, Z.; Zhu, H.; Shi, Z. Asteria: Deep Learning-based AST-Encoding for Cross-platform Binary Code Similarity Detection. In Proceedings of the 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Taipei, Taiwan, 21–24 June 2021; pp. 224–236. [Google Scholar]
- David, Y.; Partush, N.; Yahav, E. Firmup: Precise Static Detection of Common Vulnerabilities in Firmware. In Proceedings of the ACM SIGPLAN Notices, Mumbai, India, 15–17 January 2018; ACM: New York, NY, USA, 2018; Volume 53, pp. 392–404. [Google Scholar]
- Shirani, P.; Collard, L.; Agba, B.L.; Lebel, B.; Debbabi, M.; Wang, L.; Hanna, A. Binarm: Scalable and efficient detection of vulnerabilities in firmware images of intelligent electronic devices. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Hamburg, Germany, 12–14 July 2018; Springer: Cham, Switzerland, 2018; pp. 114–138. [Google Scholar]
- Feng, Q.; Zhou, R.; Xu, C.; Cheng, Y.; Testa, B.; Yin, H. Scalable Graph-based Bug Search for Firmware Images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security—CCS’16, Vienna, Austria, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 480–491. [Google Scholar] [CrossRef]
- Pewny, J.; Schuster, F.; Bernhard, L.; Holz, T.; Rossow, C. Leveraging semantic signatures for bug search in binary programs. In Proceedings of the 30th Annual Computer Security Applications Conference, New Orleans, LA, USA, 8–12 December 2014; pp. 406–415. [Google Scholar]
- Chandramohan, M.; Xue, Y.; Xu, Z.; Liu, Y.; Cho, C.Y.; Kuan, T.H.B. BinGo: Cross-Architecture cross-os binary search. In Proceedings of the ACM SIGSOFT Symposium on the Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016; pp. 678–689. [Google Scholar] [CrossRef]
- Ahn, S.; Ahn, S.; Koo, H.; Paek, Y. Practical Binary Code Similarity Detection with BERT-based Transferable Similarity Learning. In Proceedings of the 38th Annual Computer Security Applications Conference, Austin, TX, USA, 5–9 December 2022; pp. 361–374. [Google Scholar]
- Ming, J.; Xu, D.; Jiang, Y.; Wu, D. Binsim: Trace-based semantic binary diffing via system call sliced segment equivalence checking. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; pp. 253–270. [Google Scholar]
- Cesare, S.; Xiang, Y.; Zhou, W. Control flow-based malware variantdetection. IEEE Trans. Dependable Secur. Comput. 2013, 11, 307–317. [Google Scholar] [CrossRef]
- Hu, X.; Chiueh, T.C.; Shin, K.G. Large-scale malware indexing using function-call graphs. In Proceedings of the 16th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 9–13 November 2009; pp. 611–620. [Google Scholar]
- Bayer, U.; Comparetti, P.M.; Hlauschek, C.; Kruegel, C.; Kirda, E. Scalable, behavior-based malware clustering. In Proceedings of the NDSS, Citeseer, San Diego, CA, USA, 8–11 February 2009; Volume 9, pp. 8–11. [Google Scholar]
- Farhadi, M.R.; Fung, B.C.; Charland, P.; Debbabi, M. Binclone: Detecting code clones in malware. In Proceedings of the 2014 Eighth International Conference on Software Security and Reliability (SERE), San Francisco, CA, USA, 30 June–2 July 2014; pp. 78–87. [Google Scholar]
- Jang, J.; Woo, M.; Brumley, D. Towards automatic software lineage inference. In Proceedings of the 22nd USENIX Security Symposium (USENIX Security 13), Washington, DC, USA, 14–16 August 2013; pp. 81–96. [Google Scholar]
- Xu, Z.; Chen, B.; Chandramohan, M.; Liu, Y.; Song, F. SPAIN: Security patch analysis for binaries towards understanding the pain and pills. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 462–472. [Google Scholar]
- Huang, H.; Youssef, A.M.; Debbabi, M. Binsequence: Fast, accurate and scalable binary code reuse detection. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 155–166. [Google Scholar]
- Kargén, U.; Shahmehri, N. Towards robust instruction-level trace alignment of binary code. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Urbana-Champaign, IL, USA, 30 October–3 November 2017; pp. 342–352. [Google Scholar]
- Zynamics. BinDiff. 2021. Available online: https://www.zynamics.com/bindiff.html (accessed on 20 February 2023).
- Gao, D.; Reiter, M.K.; Song, D. Binhunt: Automatically finding semantic differences in binary programs. In Proceedings of the International Conference on Information and Communications Security, Chongqing, China, 19–21 November 2021; Springer: Berlin/Heidelberg, Germany, 2008; pp. 238–255. [Google Scholar]
- Li, X.; Yu, Q.; Yin, H. PalmTree: Learning an Assembly Language Model for Instruction Embedding. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 15–19 December 2021; pp. 3236–3251. [Google Scholar]
- Massarelli, L.; Di Luna, G.A.; Petroni, F.; Baldoni, R.; Querzoni, L. Safe: Self-attentive function embeddings for binary similarity. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Hamburg, Germany, 12–14 July 2019; Springer: Cham, Switzerland, 2019; pp. 309–329. [Google Scholar]
- Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; Song, D. Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security—CCS’17, Dallas, TX, USA, 30 October–3 November 2017; pp. 363–376. [Google Scholar] [CrossRef]
- Zuo, F.; Li, X.; Young, P.; Luo, L.; Zeng, Q.; Zhang, Z. Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs. In Proceedings of the 2019 Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar] [CrossRef]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-enhanced bert with disentangled attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Khoo, W.M.; Mycroft, A.; Anderson, R. Rendezvous: A search engine for binary code. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; pp. 329–338. [Google Scholar] [CrossRef]
- Myles, G.; Collberg, C. K-gram based software birthmarks. In Proceedings of the 2005 ACM Symposium on Applied Computing, Santa Fe, NM, USA, 13–17 March 2005; pp. 314–318. [Google Scholar]
- David, Y.; Yahav, E. Tracelet-based code search in executables. In Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), Edinburgh, UK, 9–11 June 2014; pp. 349–360. [Google Scholar] [CrossRef]
- Egele, M.; Woo, M.; Chapman, P.; Brumley, D. Blanket execution: Dynamic similarity testing for program binaries and components. In Proceedings of the 23rd USENIX Security Symposium (USENIX Security 14), San Diego, CA, USA, 20–22 August 2014; pp. 303–317. [Google Scholar]
- Luo, L.; Ming, J.; Wu, D.; Liu, P.; Zhu, S. Semantics-based obfuscation-resilient binary code similarity comparison with applications to software and algorithm plagiarism detection. IEEE Trans. Softw. Eng. 2017, 43, 1157–1177. [Google Scholar] [CrossRef]
- Duan, Y.; Li, X.; Wang, J.; Yin, H. DeepBinDiff: Learning Program-Wide Code Representations for Binary Diffing. In Proceedings of the 27rd Symposium on Network and Distributed System Security (NDSS), San Diego, CA, USA, 24–27 February 2020. [Google Scholar] [CrossRef]
- Yu, Z.; Cao, R.; Tang, Q.; Nie, S.; Huang, J.; Wu, S. Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1145–1152. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Eschweiler, S.; Yakdan, K.; Gerhards-Padilla, E. discovRE: Efficient Cross-Architecture Identification of Bugs in Binary Code. In Proceedings of the 2016 Network and Distributed System Security Symposium, San Diego, CA, USA, 21–24 February 2016; pp. 21–24. [Google Scholar] [CrossRef]
- David, Y.; Partush, N.; Yahav, E. Similarity of binaries through re-optimization. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, Barcelona, Spain, 18–23 June 2017; pp. 79–94. [Google Scholar]
- Luo, Z.; Wang, P.; Wang, B.; Tang, Y.; Xie, W.; Zhou, X.; Liu, D.; Lu, K. VulHawk: Cross-architecture Vulnerability Detection with Entropy-based Binary Code Search. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium, San Diego, CA, USA, 27 February–3 March 2023; Volume 2023. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Ding, S.H.; Fung, B.C.; Charland, P. Kam1n0: MapReduce-based Assembly Clone Search for Reverse Engineering. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD’16, San Francisco, CA, USA, 13–17 August 2016; pp. 461–470. [Google Scholar] [CrossRef]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Rays, H. IDA Pro. 2021. Available online: https://www.hex-rays.com/products/ida/ (accessed on 20 February 2023).
- Song, Q.; Zhang, Y.; Wang, B.; Chen, Y. Inter-BIN: Interaction-based Cross-architecture IoT Binary Similarity Comparison. IEEE Internet Things J. 2022, 9, 20018–20033. [Google Scholar] [CrossRef]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Ming Chen, Z.W.; Zengfeng Huang, B.D.; Li, Y. Simple and Deep Graph Convolutional Networks. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics, Virtual, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. In Proceedings of the ICLR Workshop on Representation Learning on Graphs and Manifolds, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Marcelli, A.; Graziano, M.; Ugarte-Pedrero, X.; Fratantonio, Y.; Mansouri, M.; Balzarotti, D. How Machine Learning Is Solving the Binary Function Similarity Problem. In Proceedings of the Usenix Security 2022, San Diego, CA, USA, 20–22 August 2022; pp. 83–101. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CVE | Vulnerable Function | Confirmed # |
|---|---|---|
| CVE-2016-6303 | MDC2_Update | 10 |
| CVE-2016-2182 | BN_bn2dec | 14 |
| CVE-2021-23840 | EVP_DecryptUpdate | 17 |
| CVE-2015-1789 | X509_cmp_time | 3 |
| CVE-2016-0798 | SRP_VBASE_get_by_usr | 4 |
| Recall@1 | MRR | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | XO | XA | XC | XO + XC | XO + XA | XA + XC | All | XO | XA | XC | XO + XC | XO + XA | XA + XC | All |
| SAFE | 0.942 | 0.100 | 0.937 | 0.920 | 0.090 | 0.103 | 0.085 | 0.965 | 0.287 | 0.963 | 0.952 | 0.278 | 0.293 | 0.278 |
| PalmTree | 0.892 | - | 0.866 | 0.814 | - | - | - | 0.934 | - | 0.919 | 0.886 | - | - | - |
| GMN | 0.473 | 0.516 | 0.349 | 0.301 | 0.333 | 0.374 | 0.296 | 0.616 | 0.655 | 0.525 | 0.488 | 0.506 | 0.542 | 0.479 |
| Trex | 0.895 | 0.800 | 0.938 | 0.872 | 0.680 | 0.744 | 0.624 | 0.930 | 0.877 | 0.964 | 0.916 | 0.791 | 0.842 | 0.753 |
| IoTSim | 0.980 | 0.986 | 0.969 | 0.972 | 0.980 | 0.962 | 0.963 | 0.988 | 0.991 | 0.981 | 0.983 | 0.987 | 0.977 | 0.978 |
| IoTSim | 0.948 | 0.956 | 0.922 | 0.930 | 0.945 | 0.912 | 0.899 | 0.965 | 0.972 | 0.950 | 0.954 | 0.965 | 0.944 | 0.936 |
| Recall@1 | MRR | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | XO | XA | XC | XO + XC | XO + XA | XA + XC | All | XO | XA | XC | XO + XC | XO + XA | XA + XC | All |
| SAFE | 0.839 | 0.014 | 0.806 | 0.745 | 0.010 | 0.008 | 0.006 | 0.886 | 0.056 | 0.866 | 0.821 | 0.051 | 0.053 | 0.050 |
| PalmTree | 0.732 | - | 0.638 | 0.545 | - | - | - | 0.800 | - | 0.738 | 0.660 | - | - | - |
| GMN | 0.279 | 0.319 | 0.142 | 0.106 | 0.132 | 0.164 | 0.113 | 0.359 | 0.405 | 0.230 | 0.190 | 0.218 | 0.250 | 0.197 |
| Trex | 0.750 | 0.521 | 0.790 | 0.681 | 0.376 | 0.426 | 0.316 | 0.811 | 0.639 | 0.859 | 0.764 | 0.499 | 0.559 | 0.448 |
| IoTSim | 0.948 | 0.947 | 0.909 | 0.921 | 0.946 | 0.906 | 0.912 | 0.962 | 0.963 | 0.935 | 0.941 | 0.960 | 0.931 | 0.936 |
| IoTSim | 0.890 | 0.903 | 0.830 | 0.846 | 0.871 | 0.808 | 0.803 | 0.913 | 0.926 | 0.872 | 0.881 | 0.901 | 0.854 | 0.848 |
| Recall@1 | MRR | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | XO | XA | XC | XO + XC | XO + XA | XA + XC | All | XO | XA | XC | XO + XC | XO + XA | XA + XC | All |
| SAFE | 0.687 | 0.002 | 0.618 | 0.523 | 0.001 | 0.001 | 0.001 | 0.749 | 0.010 | 0.702 | 0.616 | 0.007 | 0.007 | 0.007 |
| PalmTree | 0.590 | - | 0.406 | 0.335 | - | - | - | 0.648 | - | 0.497 | 0.424 | - | - | - |
| GMN | 0.193 | 0.190 | 0.066 | 0.042 | 0.053 | 0.073 | 0.038 | 0.230 | 0.237 | 0.098 | 0.071 | 0.085 | 0.112 | 0.070 |
| Trex | 0.627 | 0.280 | 0.603 | 0.465 | 0.186 | 0.198 | 0.133 | 0.673 | 0.375 | 0.678 | 0.549 | 0.263 | 0.286 | 0.208 |
| IoTSim | 0.901 | 0.903 | 0.833 | 0.849 | 0.905 | 0.812 | 0.832 | 0.922 | 0.924 | 0.868 | 0.880 | 0.926 | 0.851 | 0.867 |
| IoTSim | 0.823 | 0.825 | 0.740 | 0.744 | 0.781 | 0.688 | 0.684 | 0.851 | 0.858 | 0.782 | 0.789 | 0.818 | 0.739 | 0.734 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Z.; Wang, P.; Xie, W.; Zhou, X.; Wang, B. IoTSim: Internet of Things-Oriented Binary Code Similarity Detection with Multiple Block Relations. Sensors 2023, 23, 7789. https://doi.org/10.3390/s23187789
Luo Z, Wang P, Xie W, Zhou X, Wang B. IoTSim: Internet of Things-Oriented Binary Code Similarity Detection with Multiple Block Relations. Sensors. 2023; 23(18):7789. https://doi.org/10.3390/s23187789
Chicago/Turabian StyleLuo, Zhenhao, Pengfei Wang, Wei Xie, Xu Zhou, and Baosheng Wang. 2023. "IoTSim: Internet of Things-Oriented Binary Code Similarity Detection with Multiple Block Relations" Sensors 23, no. 18: 7789. https://doi.org/10.3390/s23187789
APA StyleLuo, Z., Wang, P., Xie, W., Zhou, X., & Wang, B. (2023). IoTSim: Internet of Things-Oriented Binary Code Similarity Detection with Multiple Block Relations. Sensors, 23(18), 7789. https://doi.org/10.3390/s23187789