1. Introduction
In recent years, the widespread adoption of portable smart IoT devices has become an integral part of people’s lives [
1,
2]. These devices have evolved with the rapid advancement of science and technology, now equipped with a diverse array of powerful embedded sensors, including cameras, microphones, GPS, gyroscopes, accelerometers, and compasses. Together, these sensors collaboratively gather extensive information about human activities and the surrounding environment. The convergence of mobile smart terminals, featuring high-performance built-in sensors, and the rapid growth of the Internet have given rise to vehicular crowdsensing (MCS) [
3,
4]. This paradigm offers a novel approach for real-time sensing and environmental data collection. Vehicular crowdsensing effectively utilizes the mobile population to enable low-cost, real-time, large-scale, and fine-grained data collection. It transforms vehicle users from passive data consumers into active data providers, thereby introducing a new service mode for vast multi-source heterogeneous data awareness in the realm of the large-scale Internet of Things [
5,
6,
7]. The great potential of vehicular crowdsensing has led to its widespread application across various fields, including environmental monitoring, smart cities, industrial sensors, city awareness, and social networks [
8,
9,
10]. Its ability to harness the collective power of mobile users to contribute to data collection has made it instrumental in addressing diverse challenges and needs in these domains.
Task assignment stands as a critical research aspect in the realm of vehicular crowdsensing [
11,
12,
13,
14,
15]. The success of vehicular crowdsensing largely hinges on the design of effective task assignment schemes. As the number of vehicle users and perceived tasks in the Cluster Awareness System continues to grow rapidly, an efficient task allocation mechanism becomes crucial to enhance user participation and achieve substantial benefits. Recently, numerous researchers have devoted efforts to developing task allocation mechanisms. Some of these works [
16,
17] focus on maximizing perceived quality or minimizing incentive costs under various constraints, while some other works aim to reduce energy consumption [
18]. Additionally, there has been significant research attention directed toward the assignment of location-dependent and time-sensitive tasks [
19]. These endeavors seek to address the challenges posed by task complexity and dynamic environmental conditions, further advancing the capabilities of vehicular crowdsensing systems.
Most of the existing research [
20,
21,
22] takes into account the effective time of perceived tasks, which can be categorized as either time-sensitive tasks or delay-tolerant tasks. Time-sensitive tasks [
23] require immediate completion and demand high time-effectiveness, typically due to emergency situations. On the other hand, delay-tolerant tasks [
24] target relatively stable perceptual activities and can be completed over an extended period. Some delay-tolerant task assignment schemes focus on recommending appropriate routes for vehicle users or scheduling tasks based on user interests and habits. However, the aforementioned studies primarily focus on task deadlines while disregarding the time required to perform each task. This oversight is particularly critical when the available time of each vehicle user is limited, as it significantly impacts the global optimization of task assignment. Thus, there is an urgent need to design an effective task assignment scheme that considers the sensing duration of vehicle users in a spatio-temporal cluster-aware system.
Privacy protection concerns in task assignment also hold significant importance [
25,
26,
27]. Vehicular crowdsensing faces potential security threats due to the large volume of data streams and the absence of robust security mechanisms. The interactions between vehicle users, platforms, and third parties create a scenario wherein privacy breaches become a serious issue. In vehicular crowdsensing, users are required to upload their perceived data to the platform, which can contain sensitive information such as user identities, locations, and other private attributes. If the platform experiences a security breach or loses trustworthiness (e.g., by selling data to third parties for profit), users’ privacy will be exposed to unauthorized entities.
Recently, researchers have proposed several methods to address user privacy protection in vehicular crowdsensing. To et al. [
28] introduced a mechanism based on differential privacy and geo-broadcasting to safeguard users’ location privacy. The approach confuses the number of users in a particular area using a trusted third-party platform, thus preventing attackers from inferring users’ precise locations. Similarly, Wang et al. [
29] explored the issue of publishing statistical information for location-based datasets. They employed differential privacy technology to ensure that users’ personal location information remains uncompromised. However, the privacy protection schemes currently available are not applicable to vehicular crowdsensing scenarios that prioritize perception duration. Currently, there is no research focusing on privacy protection concerning perception duration in task assignment. Consequently, there is an urgent need to develop effective solutions that cater to users’ privacy protection requirements while optimizing task assignment in space–time-related vehicular crowdsensing. These solutions aim to prevent users’ sensitive information from being disclosed to unauthorized entities.
To sum up, this paper focuses on the space–time characteristics of vehicular crowdsensing and conducts research on task allocation in this context. Additionally, it designs a privacy protection mechanism to safeguard vehicle users’ sensitive data while ensuring efficient task allocation. The research encompasses two main areas: probabilistic task assignment with a probabilistic coverage constraint in vehicular crowdsensing, and privacy protection in the task assignment process. By addressing these aspects, this study successfully resolves the issues of ineffective task assignment caused by neglecting the spatio-temporal characteristics of users and tasks. Moreover, it tackles the problem of user-sensitive data leakage, resulting from the oversight of privacy protection concerning users’ perceptual time in the task assignment process of spatio-temporal-related vehicular crowdsensing.
3. Problem Description
In this paper, we mainly focus on the spatio-temporal-related vehicular crowdsensing, in which the perception task is not only located in a specific spatial region, but also needs a certain amount of sensing time to complete. In this model, vehicular crowdsensing aims to recruit vehicle users who can dedicate a specific duration to perform tasks effectively. For instance, in application scenarios like crowd monitoring, air quality assessment, and noise level detection, the perception tasks necessitate vehicle users to collect data (such as congestion levels, air pollution indicators, and noise levels) within a certain time frame to obtain sufficient and meaningful information.
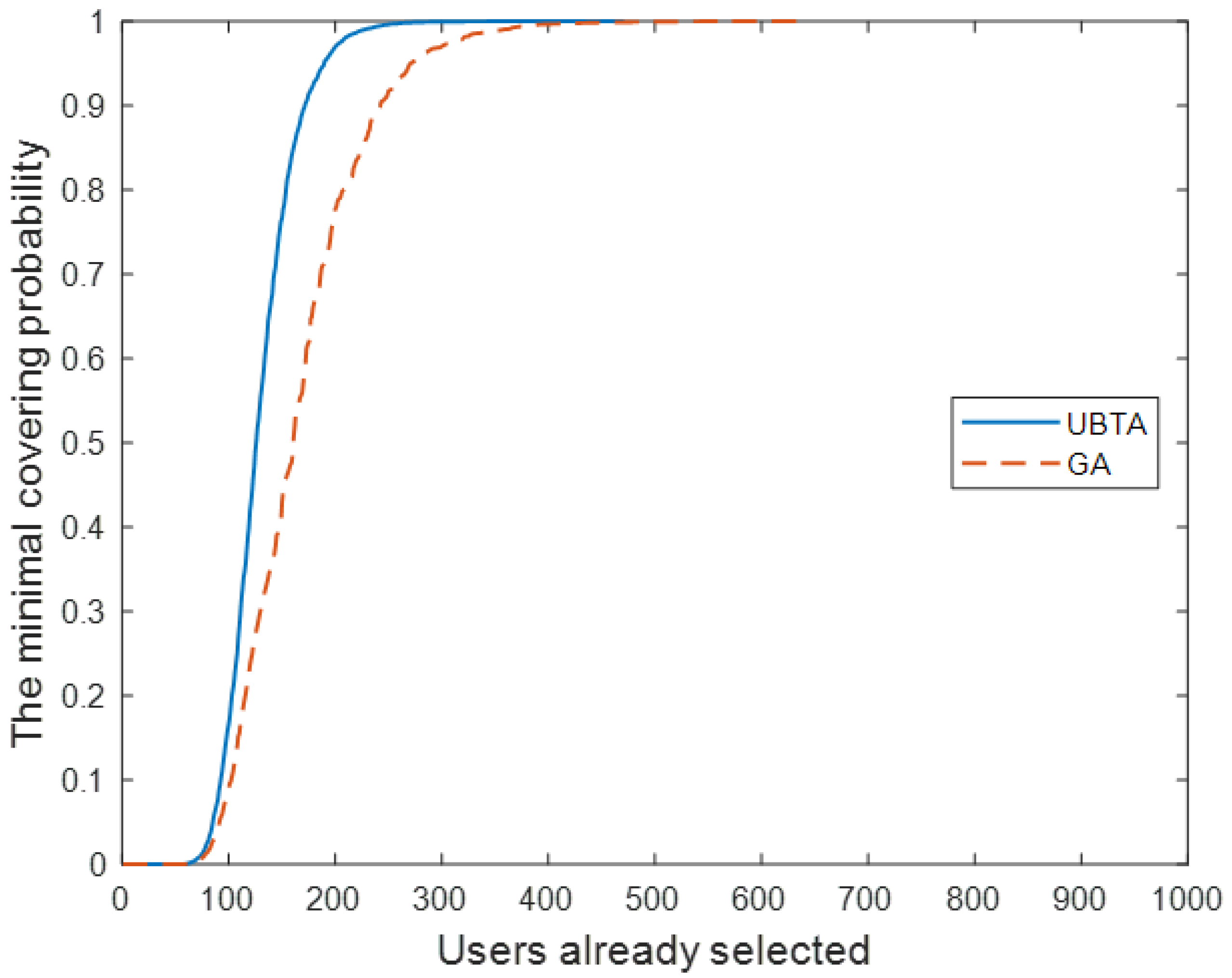
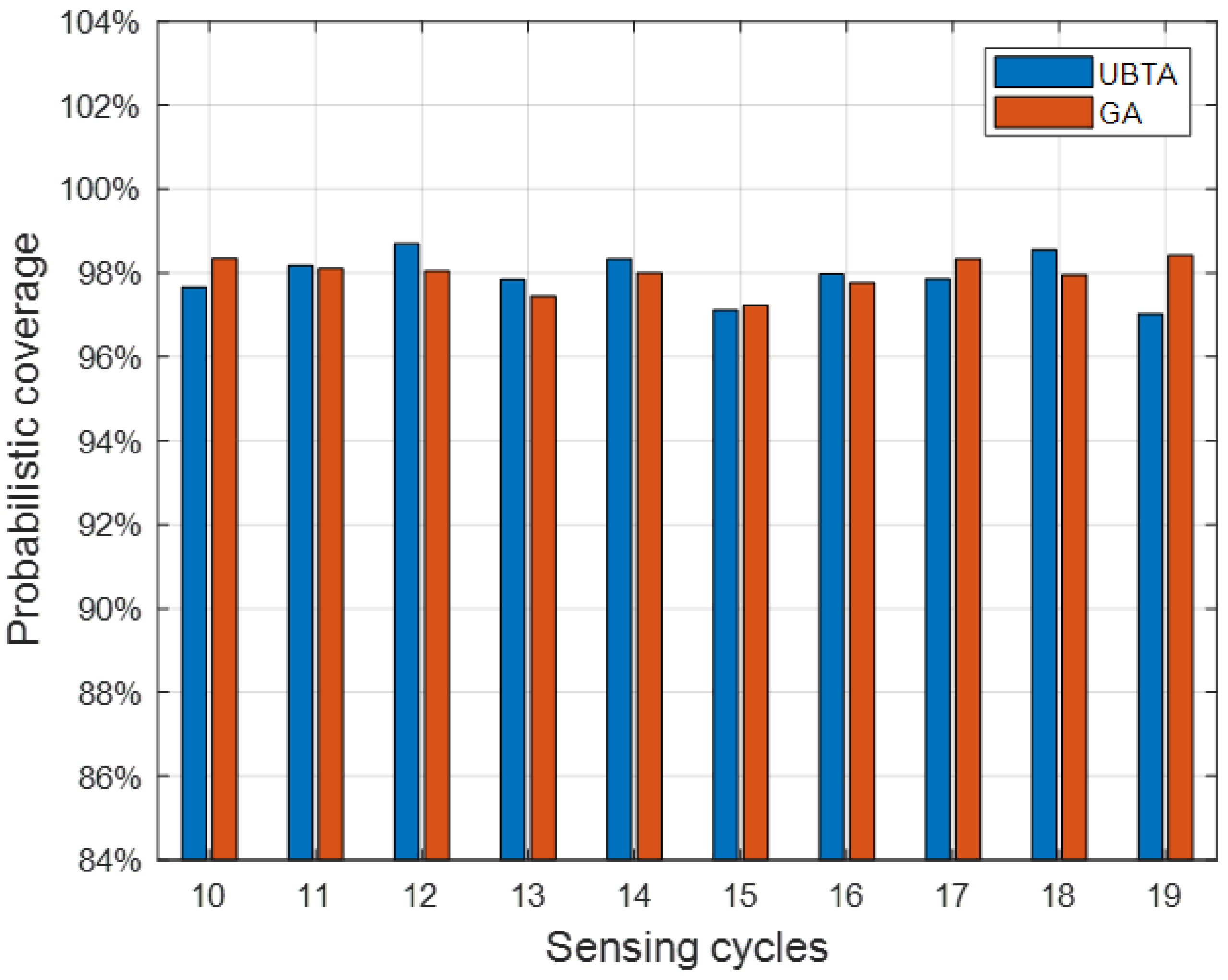
The environmental department of the municipal government has planned an air quality monitoring project to update the air quality index every hour throughout the day. However, due to the high costs associated with deploying, maintaining, and consuming energy for basic monitoring equipment, the municipal government decided to leverage vehicular crowdsensing to accomplish the task. The project aims to recruit vehicle users equipped with smartphones, who will install a specific application to perceive air quality. To execute the project effectively, the sensing area is divided into 45 regions based on signal tower coverage. Each day is further divided into 10 sensing cycles, spanning from 8:00 to 18:00, with each cycle lasting for 1 h. About 1000 smartphone users have agreed to participate in the two-week air quality sensing project. Each selected vehicle user is responsible for sensing air quality in a specific area and transmitting the collected data through the designated signal tower. The project’s objective is to ensure that the tasks performed by the recruited users cover at least 90% of the 45 areas in all sensing cycles. Consequently, in each sensing cycle, no fewer than 41 air quality monitoring tasks should be completed. To minimize the total project cost while ensuring the perceived quality, the municipal government intends to select the minimum number of users from the pool of 1000 candidates. For this purpose, the municipal government obtained the two-week call records of the 1000 candidates (with time stamps of the calls and communication tower IDs, after desensitizing other information) with the assistance of telecom operators, after obtaining the consent of users.
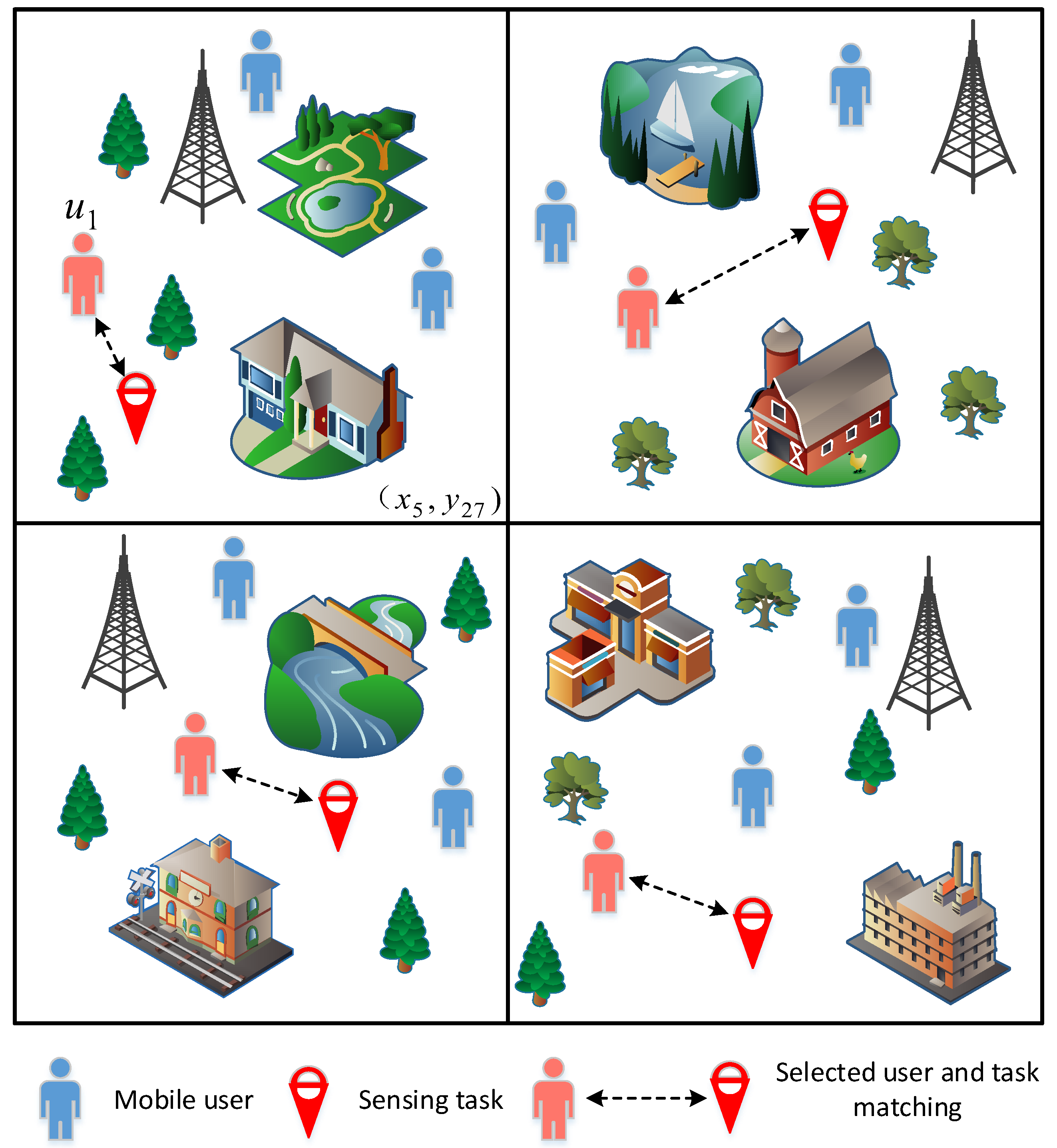
As shown in
Figure 1, for example, vehicle user
is assigned a sensing task associated with the space-time unit
(that is, the sensing task is in the fifth sensing cycle and located in the 27th perception area), user
air quality monitoring needs to be carried out in the space–time unit
. Air quality monitoring is a time-dependent task in vehicular crowdsensing, requiring vehicle users to spend a specific duration for obtaining effective data. To ensure the successful completion of the sensing task, users are required to upload their stay time in the sensing area during the designated sensing cycle. To protect users’ privacy, the stay time data will be subject to privacy protection measures. Upon selecting the smallest vehicle user set based on users’ historical calls and mobile records, each chosen participant will receive a fixed reward and activate the application on their mobile phones. Throughout the entire project, when vehicle users reach a specific sensing area within the sensing cycle, they can utilize the application on their mobile phones to perceive and upload air quality data.
4. System Model
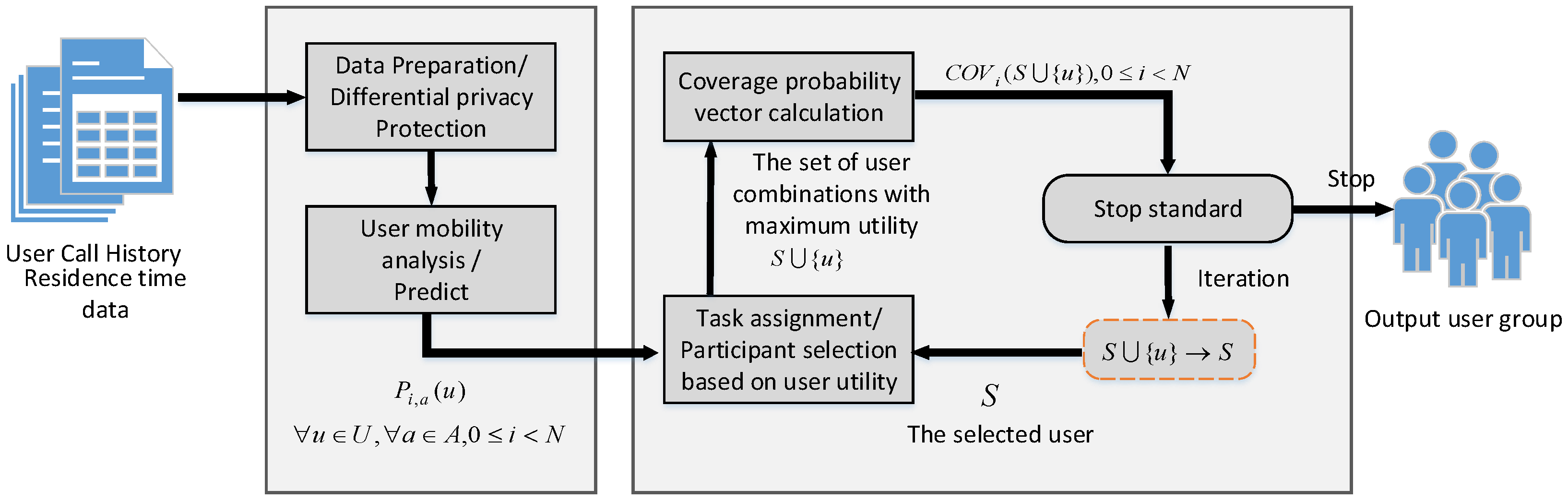
As can be seen from the above examples, the goal of this research work is to select the smallest set of participants for the perception task, and ensure that in each sensing cycle, there is a sensing area that is not lower than the predefined coverage. We propose a vehicular crowdsensing opportunistic task allocation problem. The main goal is to minimize the total incentive cost while satisfying the predefined coverage constraints. In the described model, the project can exist for a period of time (for example, two weeks), including multiple sensing cycles, such as 10 cycles per day, from 8:00 to 18:00, each cycle of 1 h. We set that, if a vehicle user completes the sensing task in the sensing period i and the sensing area a, it is said that the area a is covered in the cycle i. If a vehicle user goes to multiple sensing areas and completes the sensing tasks in these areas in the sensing cycle i, it is said that these sensing areas are covered in the sensing cycle i. Therefore, the goal of this study is to give a group of call records and confused residence time data of vehicle users, select the minimum number of users, and meet the space–time coverage constraint of the specified proportion, that is, in all sensing cycles, the proportion of the covered sensing area should be equal to or greater than the set coverage threshold.
According to the above definitions, we model the problem as follows. Given a group of vehicle users
willing to participate in the sensing project, the divided sensing area set
A, the call records (including call timestamp and communication tower ID), and dwell time data of all vehicle users, we define
as the participants (
) selected from the vehicle user set
,
is the set of sensing areas covered by the participant set
in the I sensing cycle, then the whole problem is to find a subset
of the vehicle user set
, which can be expressed as follows:
where
R is the preset coverage threshold and N is the number of sensing cycles. Due to the fact that we cannot know in advance when vehicle users will appear and in which sensing area to perform sensing tasks (that is, when selecting the set of participants,
is uncertain), the whole task allocation problem can be divided into two sub problems: vehicle user mobility prediction problem and prediction-based participant selection problem. The swarm intelligence sensing project uses a platform-centric task assignment method. The platform collects and stores the historical call records and residence time data of vehicle users. Before the sensing task is executed, participants are selected from all candidate vehicle users. Only the selected participants are required to perform the task and upload the perceived results in each sensing cycle. Considering the two sub problems of task assignment, the mechanism we designed is divided into two stages. In the first stage, we predict the flow of users between perceived areas based on the historical call records and residence time data of vehicle users, and in the second stage, we select participants according to the prediction results. The overall system framework is shown in
Figure 2.
4.1. The First Stage—Data Preparation and User Mobility Analysis
After obtaining the call records and residence time data of all candidate vehicle users, the vehicular crowdsensing platform proceeds to calculate the mobility of each user. This mobility metric represents the probability of each user successfully completing the sensing task in a specific sensing area during a designated sensing cycle. The calculation process involves two steps as follows:
(1) Calculate the probability that each user makes at least one call in a specific sensing cycle and sensing area. First, map the historical call record of each user to n sensing cycles, so that the parameter can be calculated, that is, the average number of calls made by vehicle user in sensing area in sensing cycle . Get , the probability that the vehicle user u makes at least one call in the sensing period i and the sensing area a can be calculated.
(2) Calculate the probability that each user’s residence time in a specific sensing cycle and sensing area is equal to or greater than the sensing duration required by the task. What the vehicle user uploads is the residence time after confusion, and the sensing tasks concerned in this paper are all time-dependent tasks (that is, the task needs a certain perception time to be completed, and the user can obtain valid data). Therefore, it is necessary to calculate the probability that the residence time of the vehicle user u in the sensing cycle i and sensing area a is not less than the sensing duration required by the task. Finally, the probability of each user completing the task in a specific sensing cycle and area is the product of and .
4.2. The Second Stage—Participant Selection
According to the user mobility data obtained in the first stage, we propose a user utility-based task assignment mechanism (UBTA), which iteratively selects participants by calculating the utility of the user portfolio, which is divided into three steps:
(1) Select the most effective user among all candidate vehicle users, and add the user to the recruited user set.
(2) Among the remaining non-recruited vehicle users, select the user who has the greatest utility after combining with the recruited vehicle users, and add this user to the recruited user set.
(3) Continue to select and add new vehicle users until the recruited user set can cover the sensing area of the preset threshold in each sensing cycle.
5. Task Assignment Algorithm Based on User Utility
In this section, users utilize the Laplacian mechanism to add noise to their own residence time, and then upload the confusing residence time instead of the real residence time to the platform to protect their privacy. In this process, only the platform and the users are aware of the privacy protection mechanism, so the attackers cannot infer from the residence time which user completed the task. At the same time, based on the fact that the platform is not interfered with by confusing data, the User6Based Task Allocation (UBTA) algorithm that we propose selects the smallest set of participants to minimize the payoff cost while measuring the probability of performing the tasks perceived by the user combinations. Moreover, the Poisson distribution, commonly used in queuing theory, is employed in this research. In real-life scenarios, numerous situations adhere to the Poisson distribution, such as passengers arriving at an airport or calls received by a customer service desk. Similarly, the Poisson distribution finds relevance in the domain of cellular networks. For this study, we assume that the call sequence adheres to a non-homogeneous Poisson process. Consequently, we model the probability of each vehicle user completing each sensing task based on the Poisson distribution. In the sensing period
, the probability that the vehicle user
u makes
n calls in the sensing area
can be expressed as follows:
where
represents Poisson strength, and its estimated value is the average number of calls made by vehicle user
u in sensing area
a in sensing period
i. For example, in order to estimate
of sensing period
i from 08:00 to 09:00, we will calculate the average number of calls made by vehicle user
u in sensing area
a from 08:00 to 09:00 in historical call records. Therefore, the probability that the vehicle user
u makes at least one call in the sensing area
a during the sensing period
i can be calculated as follows:
In this paper, the sensing time of vehicle users plays a crucial role in determining whether a task can be successfully completed. The sensing task is considered effectively completed only when the vehicle users reach a specific perception area and remain there for a duration equal to or exceeding the required perception time. To facilitate accurate and efficient task assignment, vehicle users can submit their stay time in the sensing period and area to the platform. However, privacy concerns arise due to potential malicious attackers who may infer daily habits, tracks, and other sensitive information from the real stay time, leading to privacy risks. To address this issue, this paper employs the Laplacian mechanism, which locally confuses the residence time. Subsequently, vehicle users upload the fuzzy residence time instead of the actual residence time to the platform, thereby safeguarding their privacy. We use to represent the residence time of the vehicle user u in the perception area a during the sensing period i, and to represent the confusing residence time generated by adding Laplace noise to the real residence time. When is known, it is easy to know whether the vehicle users have the ability to complete the sensing task or not. However, the existing methods cannot predict the user mobility problem because the users only upload the confused staying time, so a new solution is urgently needed.
Considering the noise added to the residence time, we transform the problem into the probability that the fuzzy residence time is greater than the perceived duration. When the sensing duration required to define the perception task is
, the goal of the platform is to obtain the probability that
is not less than
, which is expressed as
. Assume that vehicle user U adds Laplace noise to the real residence time
by using privacy budget parameter
, and obtains the fuzzy residence time
and uploads it to the platform. Therefore, we can obtain:
where
is a variable that obeys Laplace distribution, and the smaller the privacy budget parameter
, the greater the added noise and the higher the level of privacy protection. For
, there is the following equation:
where
platform can be calculated, the above equation can be regarded as the probability problem of continuous random variables; then, we can obtain the following equation:
where
represents the probability density function of variable
:
As a result, the platform can calculate the probability
of vehicle user
u in perception cycle
i and perception region
a not less than the sensing duration required by the task according to the fuzzy residence time
and privacy budget parameter
.
Based on the above calculation process, we can obtain the probability of each user completing the sensing task in specific sensing cycle i and sensing area a, that is, the probability that sensing area a is covered by vehicle user u in sensing cycle i. In addition, is the product of and .
Next, we calculate the utility of users. Given all candidate mobile user set
and selected participant set
, first combine each unselected user
with the selected participant to generate a combinatorial set
. Then, calculate the utility of each combinatorial set
and select the combinatorial set with the maximum utility. Finally, utilize the result as the newly selected participant set for the next iteration. In this paper, the utility of user combinatorial set is defined as the expectation of sensing area covered by
in all sensing cycles, and its calculation formula is as follows:
The task assignment mechanism based on user utility calculates the utility of each combination set, selects the combination set with the maximum utility, and continues the next iteration until the stop criterion is met. After obtaining the set of combinations with maximum utility
, the algorithm computes a covering probability vector, where each element of the vector is the probability of being covered by the combinatorial set
with a preset percentage (R) of the perceived region in the corresponding perceptual cycle. The following formula gives the probability calculation formula in the i-th perception cycle.
where
indicates the number of the minimum sensing areas that should be covered in each sensing cycle, and
is a subset of the sensing area set A, indicating the combination of sensing areas that should be covered.
After obtaining the probability vector calculated based on the aggregation of the maximum utility user group, the algorithm identifies the minimum probability value within the vector. It then compares this minimum probability value with the given stop threshold. If the minimum probability is greater than or equal to the stop threshold, the combination set returned will be considered as the final user set selected by the algorithm. On the other hand, if the minimum probability falls below the stop threshold, the algorithm will use the combination set as the selected participant and initiate the next iteration. To summarize, the algorithm iteratively repeats the process until it finds a combination set with a minimum probability value greater than or equal to the stop threshold. This set will then be used as the final selected user set.
Given the number of users , in the worst case, the proposed algorithm UBTA runs iterations (i.e., all users are selected) to obtain the result, and in the best case, the algorithm runs only iterations (i.e., one user is selected) to obtain the result.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}