1. Introduction
Since 2010, photovoltaics have been steadily increasing their share of cumulative electricity capacity worldwide. In 2023, they occupy third place, with a share of 14.7%, behind coal (24.7%) and hydroelectricity (15.7%) [
1]. In recent years, both companies and private households have installed photovoltaic systems for various reasons. This is firstly for financial reasons, as it reduces the cost of energy consumed once the cost of installation has been absorbed [
2]. But it is also attractive in the short term, given the tax breaks introduced by governments to encourage people to take the plunge. Secondly, people are also doing it for ecological reasons [
2]. In the long term, the use of solar energy has a much smaller carbon footprint than electricity produced with fossil fuels. Given the ecological emergency faced by our planet but also in order to diversify energy sources in the face of the current energy crisis, the number of photovoltaic installations should continue to rise.
There are two types of installation: those with a battery and those without one. Having a battery increases the home’s autonomy, as it enables the energy produced to be stored and used at any time of day. However, the production of a battery has a high carbon footprint, as it uses rare materials that will soon be exhausted, and is often quite expensive. It would, therefore, be preferable to opt for battery-free systems while optimising the instant use of the solar energy produced.
However, optimising the use of the solar energy produced can be complicated for the homeowner. They should schedule tasks according to personal and private schedules, without having access to consumption and production data. Such a task can be handled by an artificial intelligence system, which can plan the execution of energy-intensive household tasks according to a number of parameters: weather and temperature, energy consumed and produced, occupant habits, etc. A recommender system could be appropriate in this context: it would help the end-user to make decisions and optimise the energy produced while leaving him/her free to choose whether or not to apply the recommendation. Indeed, a user would prefer an automated system that gives them recommendations and over which they have control, rather than a totally autonomous system that performs tasks for them [
3]. To maximise the chances of users following recommendations, the latter would need to be adapted to their habits. In fact, a system that takes into account the context (i.e., the user’s habits) should suggest recommendations that are more attractive and better adapted to the user’s mood and tastes. This should have a positive impact on the acceptance and thus the use of such a system [
4]. That is the reason why including a home automation solution in the system architecture would help to better understand the user’s habits and provide recommendations tailored to their needs. If so, this could have a beneficial economic and ecological impact in the long term for many inhabitants equipped with solar panels. Additionally, proposing data visualisation for the end-user might increase their awareness of energy consumption and production [
5].
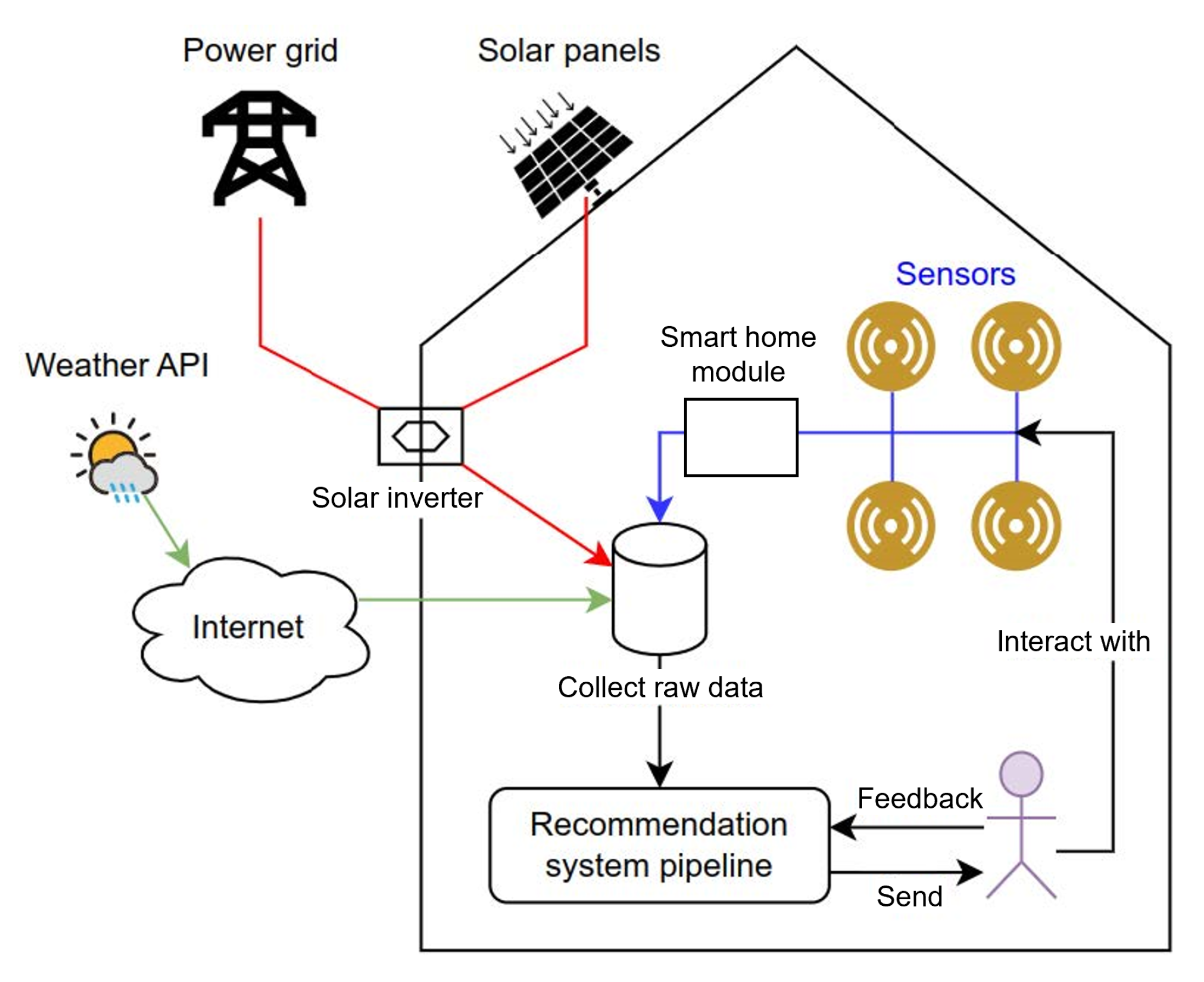
The main innovation of the proposed system is to propose recommendations to the resident using information provided by non-intrusive sensors in a home automation solution, in addition to weather and solar inverter data. This would give us a better understanding of the user’s consumption habits and activities, with the aim of making increasingly relevant recommendations. The other difference is that the system is trained on data from an individual home equipped with solar panels but without a battery to store energy, to further reduce the carbon footprint of the inhabitant.
This manuscript details the design, implementation, and evaluation of such a recommender system. The data used to train and evaluate the system are those of a Swiss resident equipped with solar panels and a home automation solution.
4. Evaluation
4.1. Method
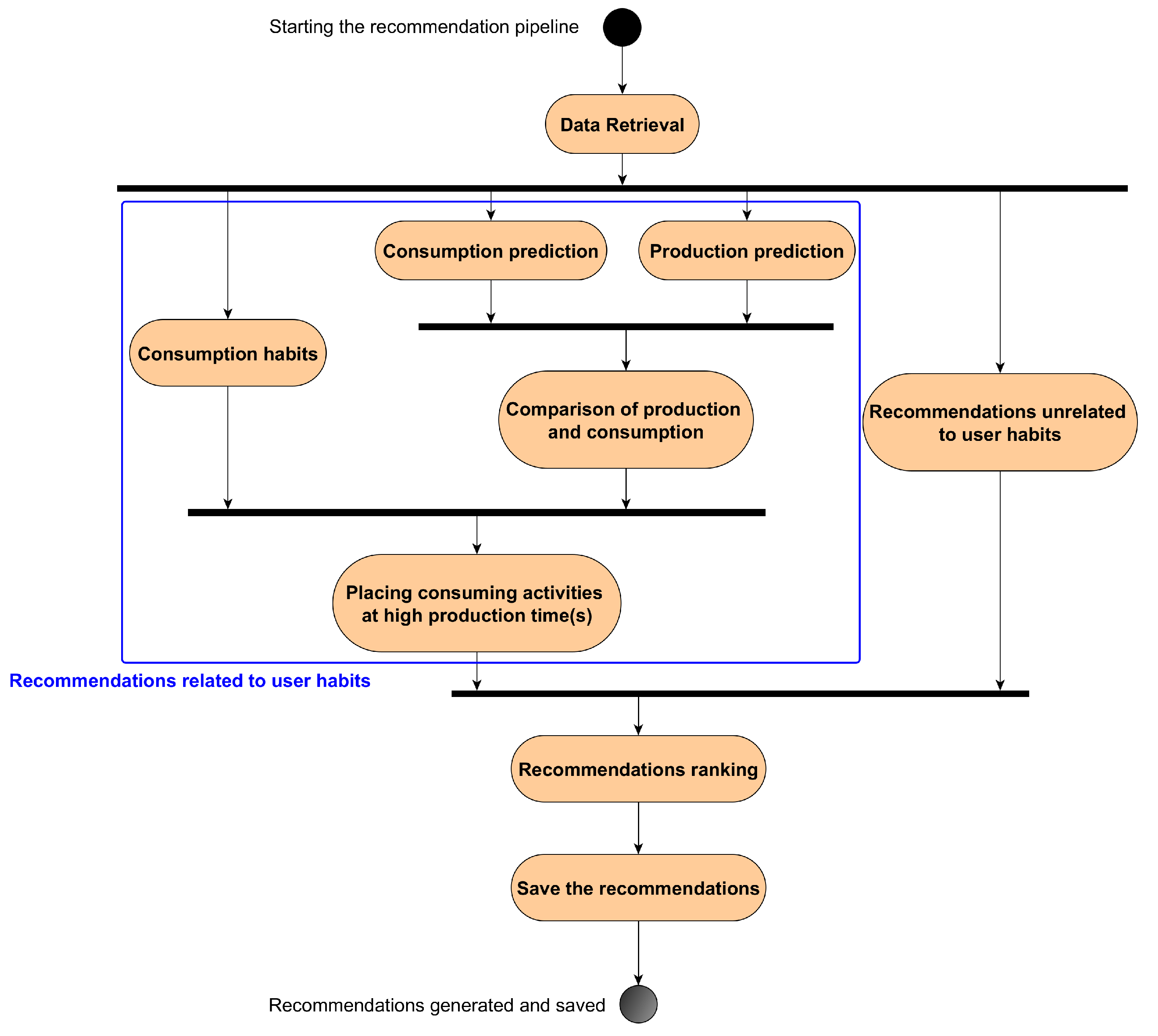
Two variants of the recommender system were implemented and evaluated:
Variant 1, taking into account the predicted energy to be consumed.
Variant 2, without taking the predicted energy to be consumed into account (based solely on energy production predictions).
The second variant was created to investigate whether recommendations based solely on energy production would satisfy the user equally well. For each day of the data collection periods, recommendations were generated, and those selected from 15 to 28 August 2022 (14 days) were used for system evaluation. All the recommendations that could potentially be selected by the system each day appear in
Table 6 (
Textual Recommendation column).
Eleven people who were not residents of the household where data were collected participated in the evaluation process. The results are presented in
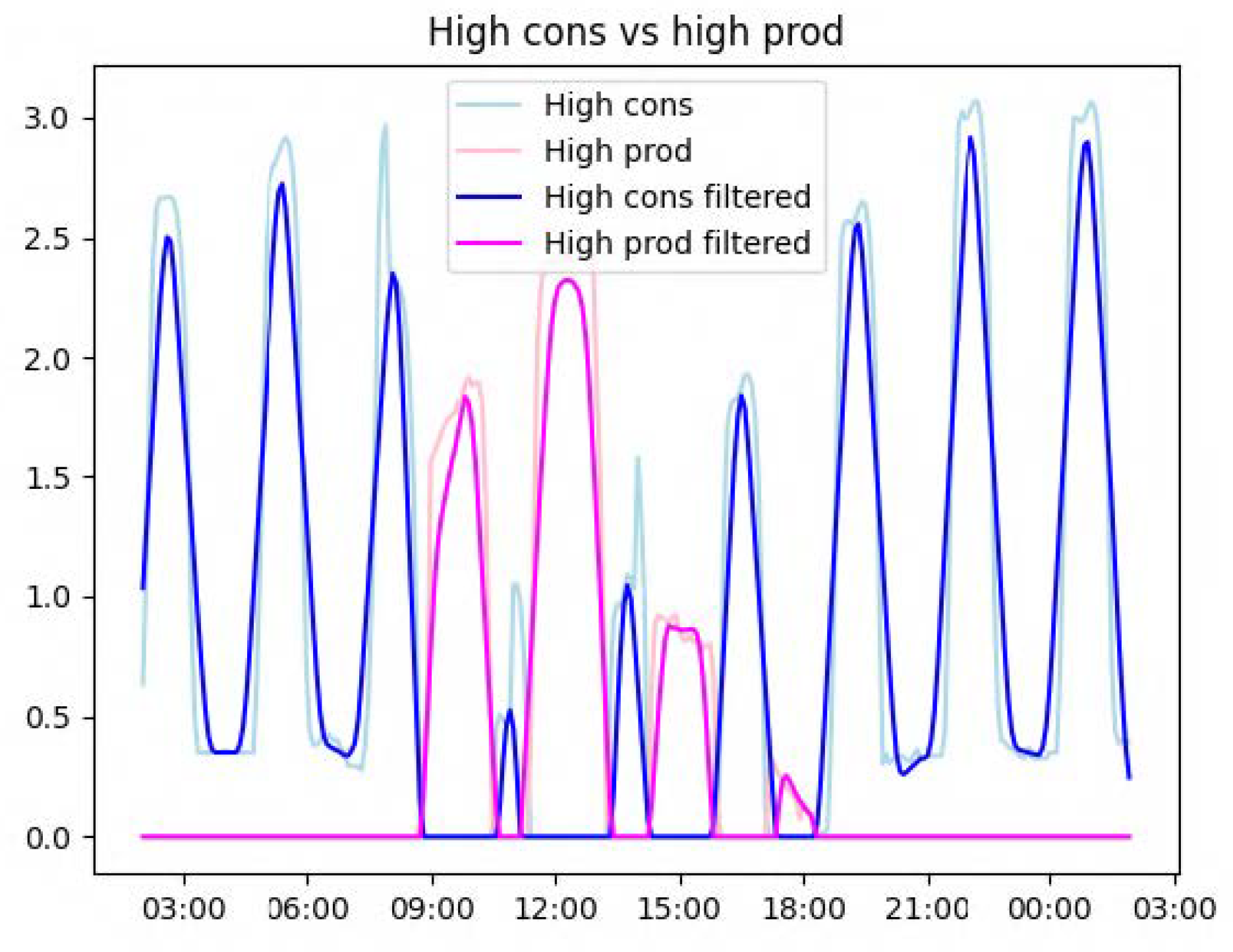
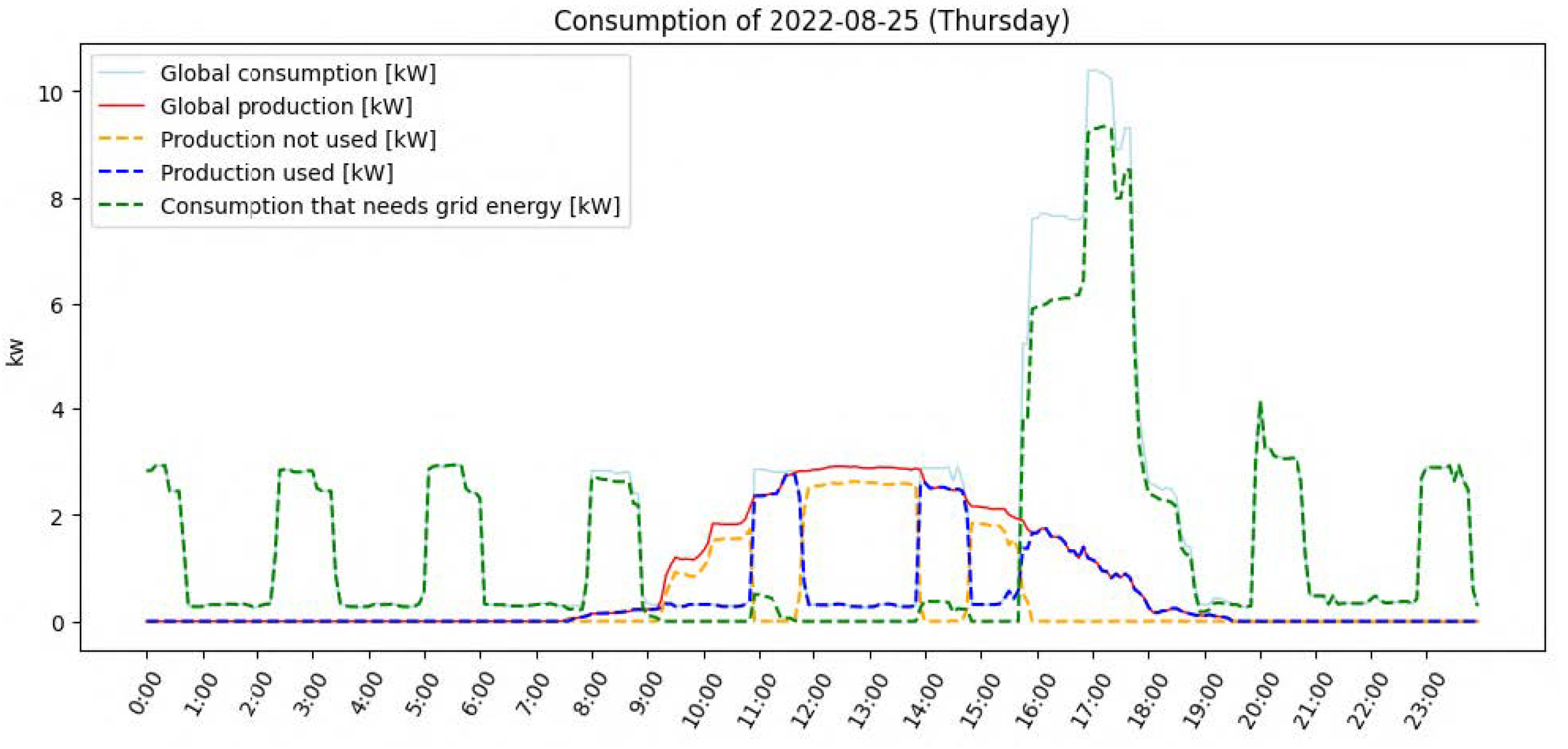
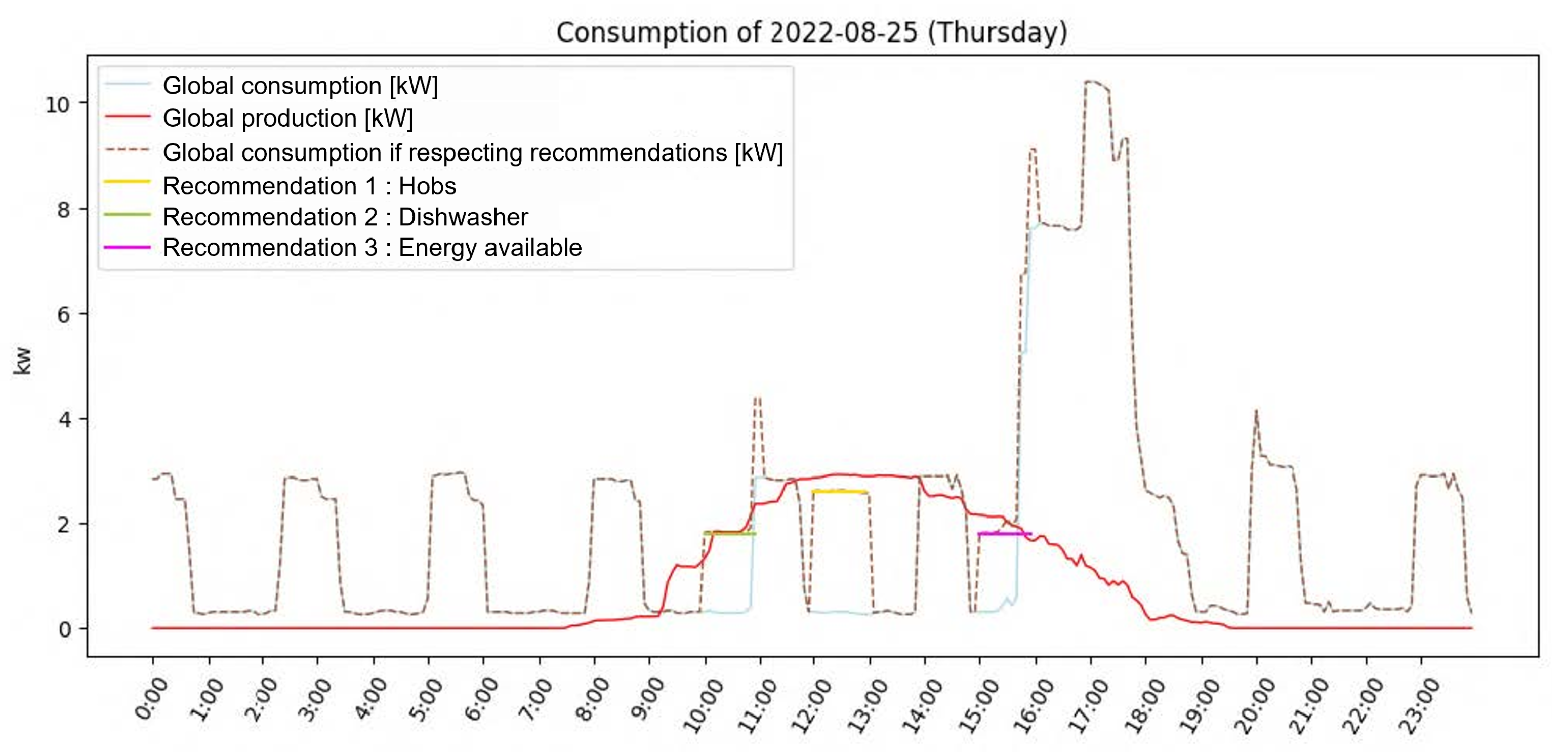
Table 6. They had to fill in a template document to evaluate the relevance of the recommendations (i.e., textual content), the predicted values they contained (time of day and energy in kW), and the ranking. Firstly, the document presented all the recommendations, and respondents were asked to tick the “Relevant” column if they would have liked to have received such a recommendation (based on the raw text). Then, for each day and for both variants, the document presented the recommendations selected by the system, arranged in ascending order based on TOPSIS ranking, along with a graph like the one in
Figure 7. Respondents had to answer in a two-choice column (yes vs. no) whether the values contained in the textual content of the recommendations (time of day and energy in kW) made sense regarding the data prediction presented in the graph. They were also asked to tick the “Logical” column if they thought that the ranking of recommendations made sense to them.
Apart from the evaluation process conducted by the respondents, the diversity of the recommendations selected by the system was also investigated. For each recommendation, the number of times it was selected over the 14 days is shown in
Table 6 (see
Occurrences column).
4.2. Relevance of Recommendations
The results (
Relevance column in
Table 6) are presented as a percentage, with 100% indicating that all participants would have liked to receive this recommendation. It shows that the recommendations were rated relevant in 74% of cases on average. Seven were appreciated by more than 80% of the respondents. However, three recommendations were considered not relevant by more than half of the respondents (less than 50% of relevance), so they could be adapted or removed in the next version of the system.
4.3. Accuracy of Values Contained in Recommendations
Regarding the values contained in the recommendations (
Values column in
Table 6), the respondents reported that they were accurate in 66% and 77% of recommendations selected by variants 1 and 2 of the system, respectively. For variant 1, the time predictions of boiler activation were usually offset, which explains the low accuracy for that recommendation (38%). Respondents surely noticed the discrepancy between the times in the text and those corresponding to consumption peaks in the graph. If we remove this one to calculate the average accuracy of values, the accuracy rises to 73% for variant 1.
4.4. Diversity of Recommendations
Variant 1 of the system selected 56 recommendations over the 14 days (4 recommendations per day on average). Three recommendations were selected (almost) every day by the system, with each representing more than 20% of selected recommendations. Five recommendations were selected five times or less by the system over the 14 days, ranging between 2% and 9% of the selected recommendations. Three recommendations were never selected by the system. Two of them are related to bad and cold weather, which is not likely to occur in August. The last one would be selected if the consumption were high and the production were low, which are also not likely to occur in August. Variant 2 selected only 27 recommendations in total (almost 2 per day on average), which is half of those of variant 1. Two recommendations were selected every 2 days, each representing more than 25% of selected recommendations. Three recommendations were selected three times (11% of selected recommendations), and two were selected less than three times. Three recommendations were never selected by the system (the same as variant 1), and one recommendation could not be selected as it was only related to the consumed energy.
4.5. Ranking of Recommendations
On average, over the 14 days, the recommendations ranking was rated relevant in 91% and 88% of cases for variants 1 and 2, respectively.
5. Discussion
5.1. User’s Habits
As suspected according to data exploration and confirmed with the ML tasks, it was not possible to fully use the potential of the logs from the smart home automation solution to understand the user’s habits and in particular to link it with the energy consumed in the house. To better understand the user’s habits regarding energy-intensive household tasks, a solution could be to install smart meters on household electric appliances and connect them to the home automation solution. Not only it would give more relevant information about the habits of the inhabitants, but the consumption for each household appliance might also be easier to predict than the user’s consumption habits with ML techniques [
6,
7,
9]. However, this would make the system more intrusive into the private lives of residents, which could put a brake on the adoption of such a system. Another alternative could be to apply Non-Intrusive Monitoring (NILM) techniques to detect the use of household appliances from the aggregated consumption signal [
23]. However, some device activation might be more difficult to detect than others [
24].
If the activities related to household appliances can be predicted accurately enough, the user’s habits could be formatted with the same format as simulated in this version of the proposed recommender system (e.g., Listing 1). In this way, the recommender system would be fully automated while fitting the user’s habits.
5.2. Prediction of Energy Consumption and Production
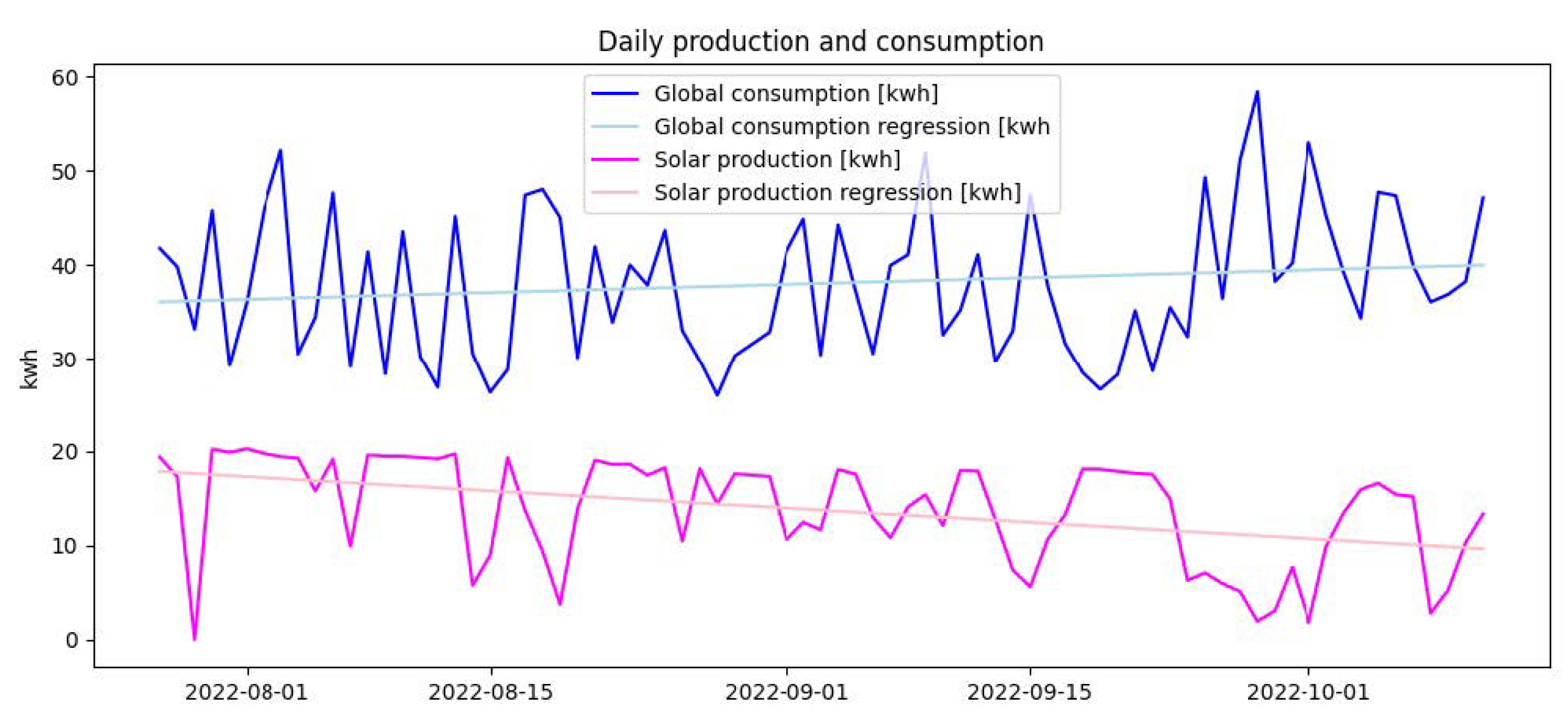
For both consumption and production prediction, the models overfitted the collected weather data (EC2 and EP1) when shuffling the dataset (i.e., training and evaluating the models on data collected the same day). This reminds us that researchers should be careful when interpreting results obtained with ML techniques on time-series data.
Additionally, even with an unshuffled dataset, energy consumption could hardly be explained by the models based on sensor logs, as expected after data exploration. It was also hard to predict it based on weather data. The best performance was obtained with the hourly consumed energy as ground truth (R
score of 13.56%, EC5). Yet, this is not enough for the concrete use of such a system in the wild. Indeed, the RMSE achieved in the different experiments (between 0.57 and 1.75) is higher than in previous work. Saoud et al. [
8] obtained RMSEs of 0.004 to 0.009 depending on the time intervals used (5 to 30 min, respectively), while Bashawyah and Qaisar [
9] achieved MSEs between 1.08% and 2.4%, which also suggests a lower prediction error. The former used a combination of transformers and stationary wavelet transforms for prediction, while the latter had a much more consequent dataset for training the model (data collected in 5566 households over 3 years). These are two avenues on which we need to focus our research to improve the prediction of consumed energy for our use-case scenario.
Energy production could be accurately predicted by the models. The prediction of hourly produced solar energy was less accurate (R
score of 82.27% and RMSE of 0.37; EP3) than the 5 min window prediction (R
score of 84.81% and RMSE of 0.36; EP2). However, the prediction accuracy was lower than in previous works that used similar sources of data (weather data and solar radiation). Jebli et al. [
12] achieved R
scores of 93 to 95% for scenarios that did not overfit, while Al-Jaafreh et al. [
13] achieved an RMSE of 0.035 using 16 features to predict the hourly produced energy. Those slightly better results might be explained by the bigger size of datasets and algorithms used (neural network-based architectures). Additionally, Alomari et al. [
11] achieved an RMSE of 0.07 using irradiance from the previous five days. The methodologies and algorithms used in these previous works, combined with a longer period of data collection, should be considered to improve our predictions of energy produced.
5.3. Relevance and Diversity of the Recommendations
Most of the recommendations were appreciated by the respondents, but three recommendations did not receive great interest. The first one (“We produce enough to power appliances of around 1700 W from 10 a.m. to 11 a.m.”) might have been not specific enough, because no details on which appliance should be used were given. The second one (“We predict that periodic consumption will consume about 3 kW for about an hour at these times: 2 a.m., [..], 0 a.m.”) just gave information about the high periodic consumption (3 kW every three hours) detected by the system. In this case, we suspect that it is the boiler that reactivates every 3 h once the low set temperature (55°) is reached to heat the water for about 1 h and reach the high set temperature (60°). Here, the resident would have to contact a specialist to adjust or resize the water heater. We believe that such a recommendation may be useful to avoid wasting energy and money, but this was not perceived as such by respondents. The third one (“Glass ceramic hobs have a power rating of 2000 W, while induction hobs have a power rating of 2800 W. On the other hand, induction hobs heat up faster, which means they use less energy on average.”) was a generic recommendation comparing ceramic hobs and induction hobs. It was the least preferred by those questioned, probably because it offers no advantage to the end-user in terms of improving their behaviour over the next few days. This type of recommendation will probably have to be removed from the list. The results regarding the relevance of recommendations, whether good or bad, indicate that end-users prefer to receive precise recommendations suggesting which specific device should be used at which time of day. Advice that is too broad and may not have a beneficial impact on their behaviour in the following days should be avoided. This should be taken into account when refining the list of recommendations implemented in the next version of the system while maintaining an appropriate level of diversity.
Speaking of the latter, our system showed that three recommendations were selected more often than the others in each variant of the system. This is not ideal if one of the recommendations is not appreciated by users, as was the case here. However, the system was only evaluated over 14 consecutive days in August, and it seems logical that some recommendations were not selected, as explained above (see
Section 4). Diversity should, therefore, be evaluated on recommendations generated over a whole year to limit the effect of seasonality.
5.4. Limitations and Further Research
This first version of the system obviously has a few limitations. Unfortunately, the device logs did not help much to link the user’s habits with the energy consumed in the house. Also, one major issue we faced was to understand that the high periodic consumption in the house was due to the boiler, which was oversized in relation to the size of the house. Detecting these recurrent boiler ignitions using time-series analysis techniques and isolating them from the rest of the aggregated consumption signal represent another idea to improve the prediction of the energy consumed.
In this work, the likelihood (i.e., the probability that the recommendation will be accepted by the resident) is currently arbitrary. If we manage to detect habits more accurately, we could define and adapt this likelihood according to the user’s behaviour over the first few weeks of using the system.
Of course, the results presented are those of the current system, based on data collected from a single household in Switzerland over a limited period. It would be interesting to study whether similar results can be obtained with data collected from other households, of different sizes, for a longer period and in different seasons, in other regions or countries, with a greater variety of inhabitants (a single person vs. a couple vs. a family) who have different habits. Here, the user had no well-defined routines, which certainly made the prediction of energy consumption more complex.
Many adjustments can be made to improve the proposed recommender system, notably by adding other recommendations to increase diversity or by modifying existing recommendations on the basis of the results obtained. In addition, a module for creating the recommendation text using natural language generation (NLG) techniques could be added. Currently, some recommendations already explain how the system arrived at a decision, but users may find that some are not explicit enough. Explainable AI (xAI) is one of the major challenges for recommender systems, particularly in encouraging the adoption of this type of automated system by the general population [
5]. It would, therefore, be interesting to investigate the effect of the xAI modality (no xAI vs. textual explanation vs. textual explanation + image) or the level of information (little vs. very detailed recommendation) on users’ intention to use, appreciation, and trust.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






