
HOMLC-Hyperparameter Optimization for Multi-Label Classification of Intrusion Detection Data for Internet of Things Network




Abstract
:1. Introduction
Our Contributions
- The use of a hybrid network intrusion dataset, i.e., merging of BoT-IoT and UNSW NB-15 dataset.
- The performance of low-rank optimised SVM by determining the hyperplane efficiently for predicting classifiable labels on reproduced observations.
- The weight optimization method through a low rank matrix factorization process on deep learning classifiers (CNN and CNN-MLP) for improvising multilabel classification.
- The use of Bayesian optimization in conjunction with low-rank factorization SVM, CNN and CNN-MLP models, enables efficient hyperparameter tuning and model optimization.
2. Related Work
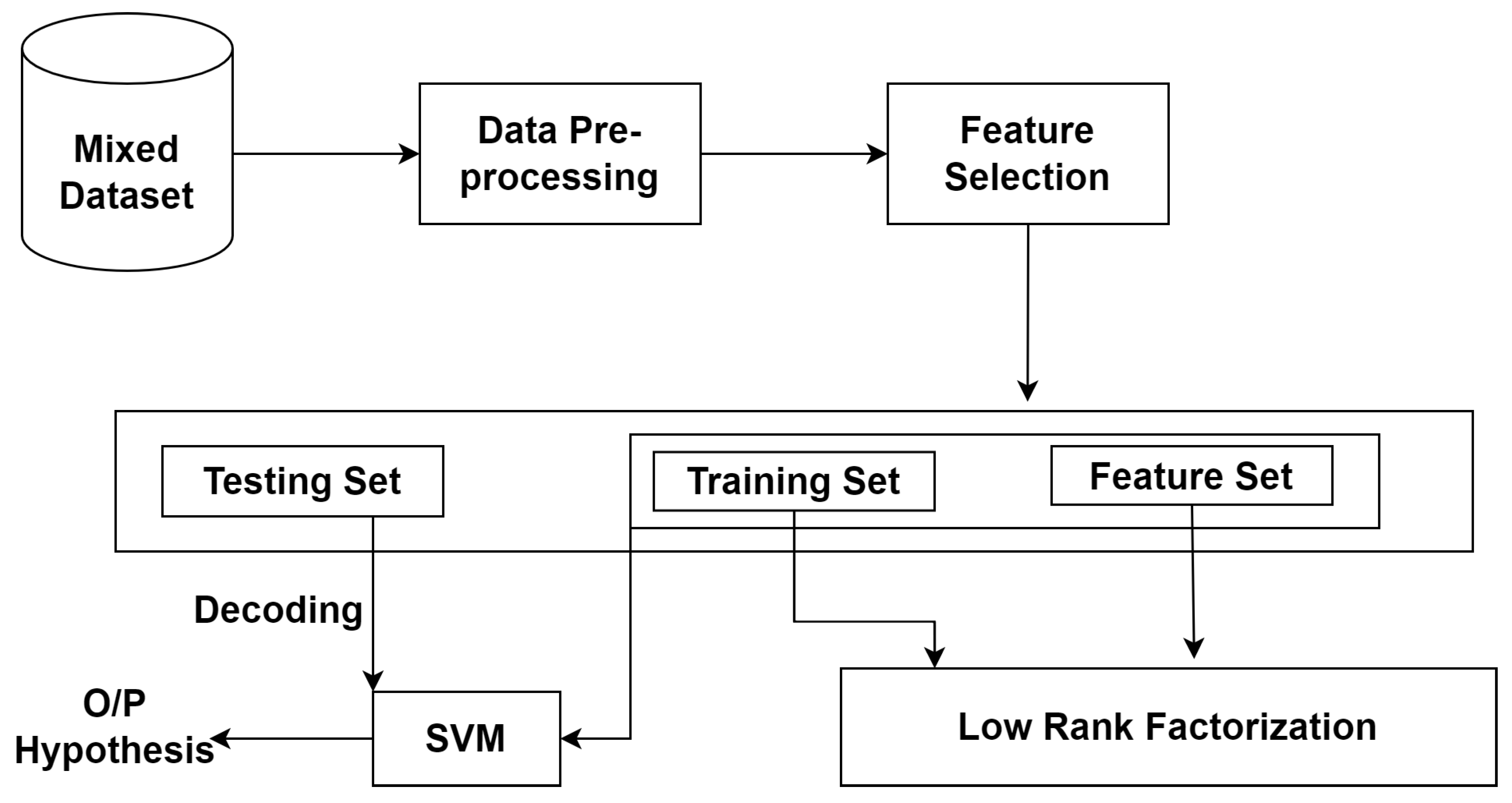
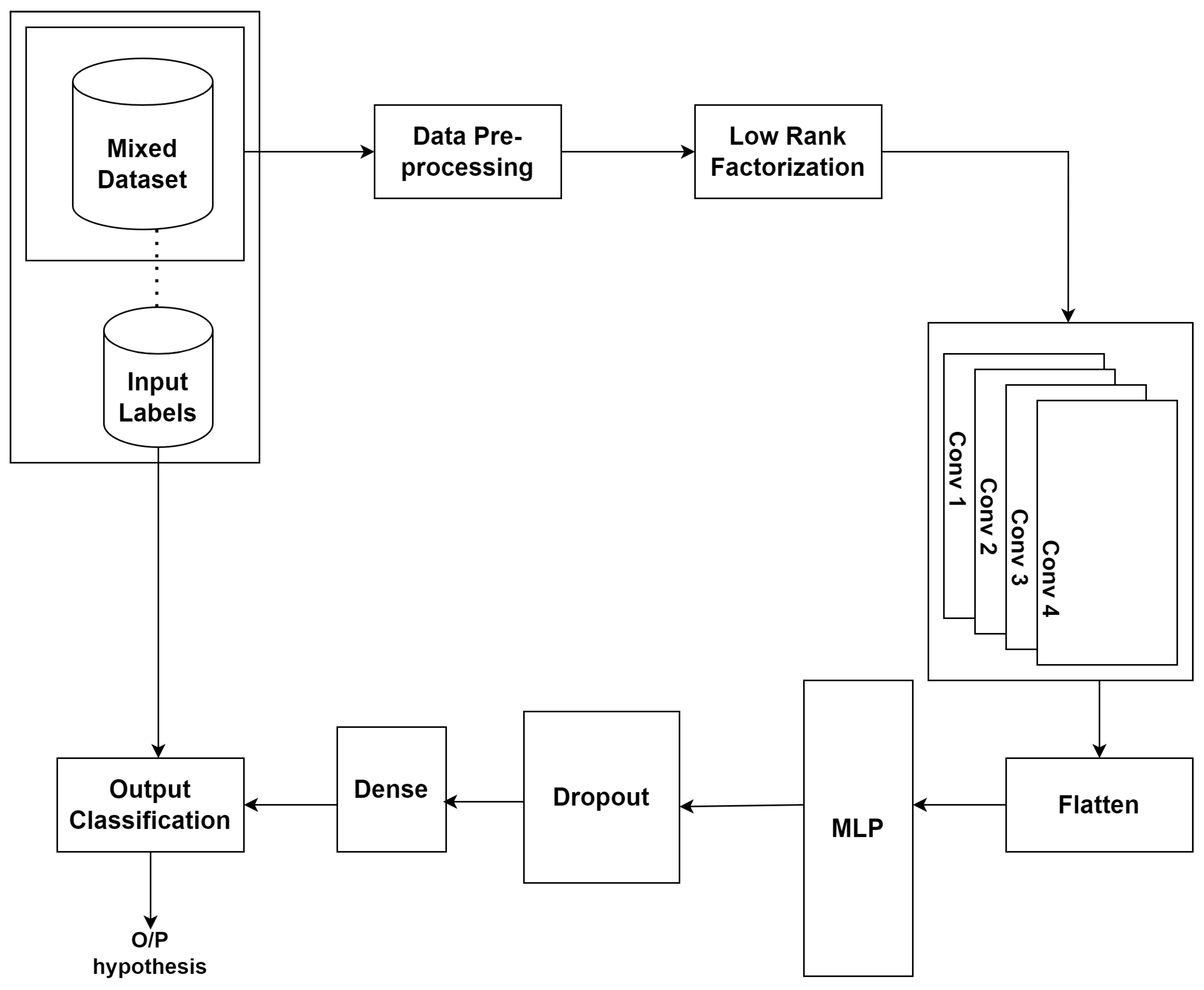
3. Methodology
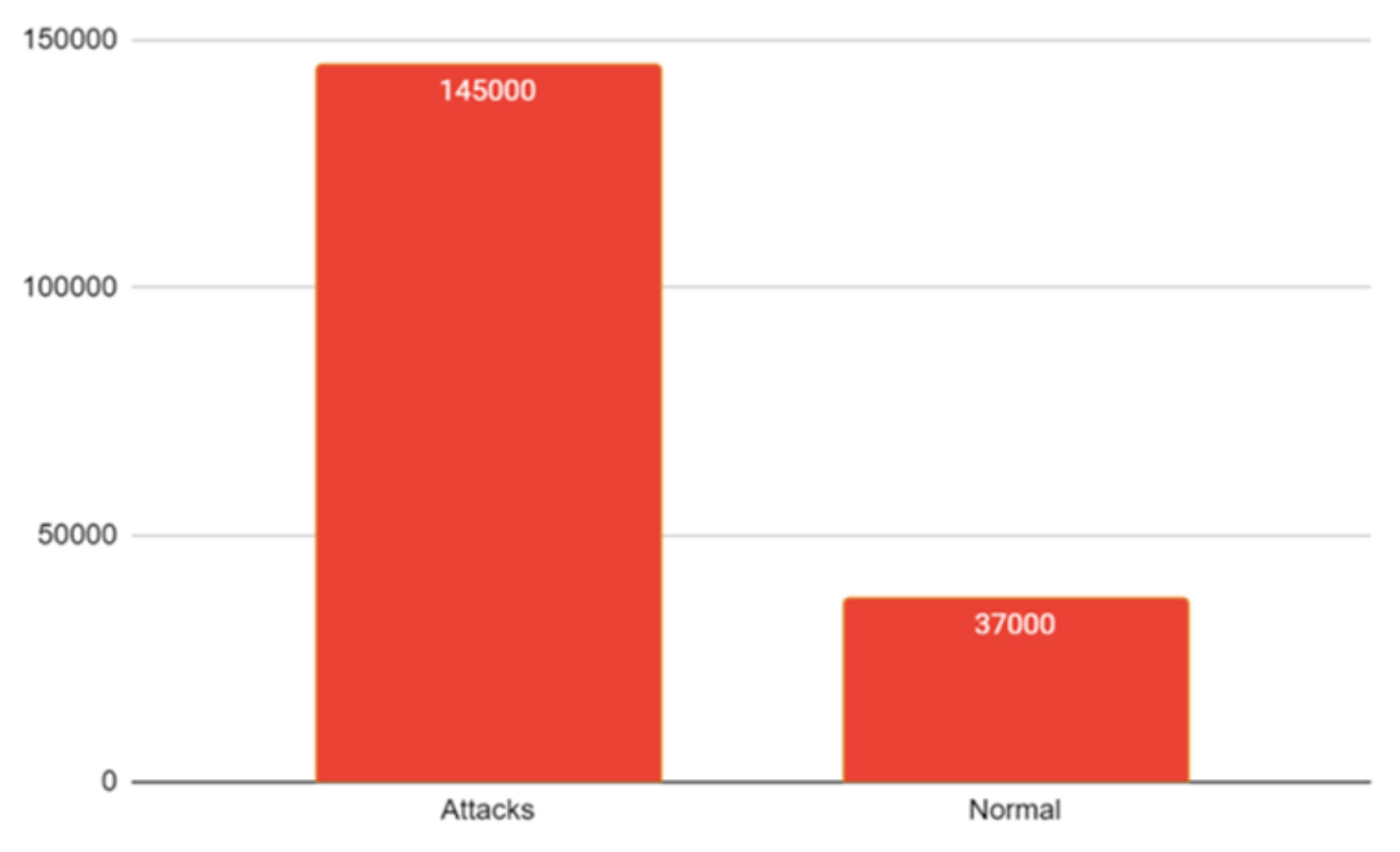
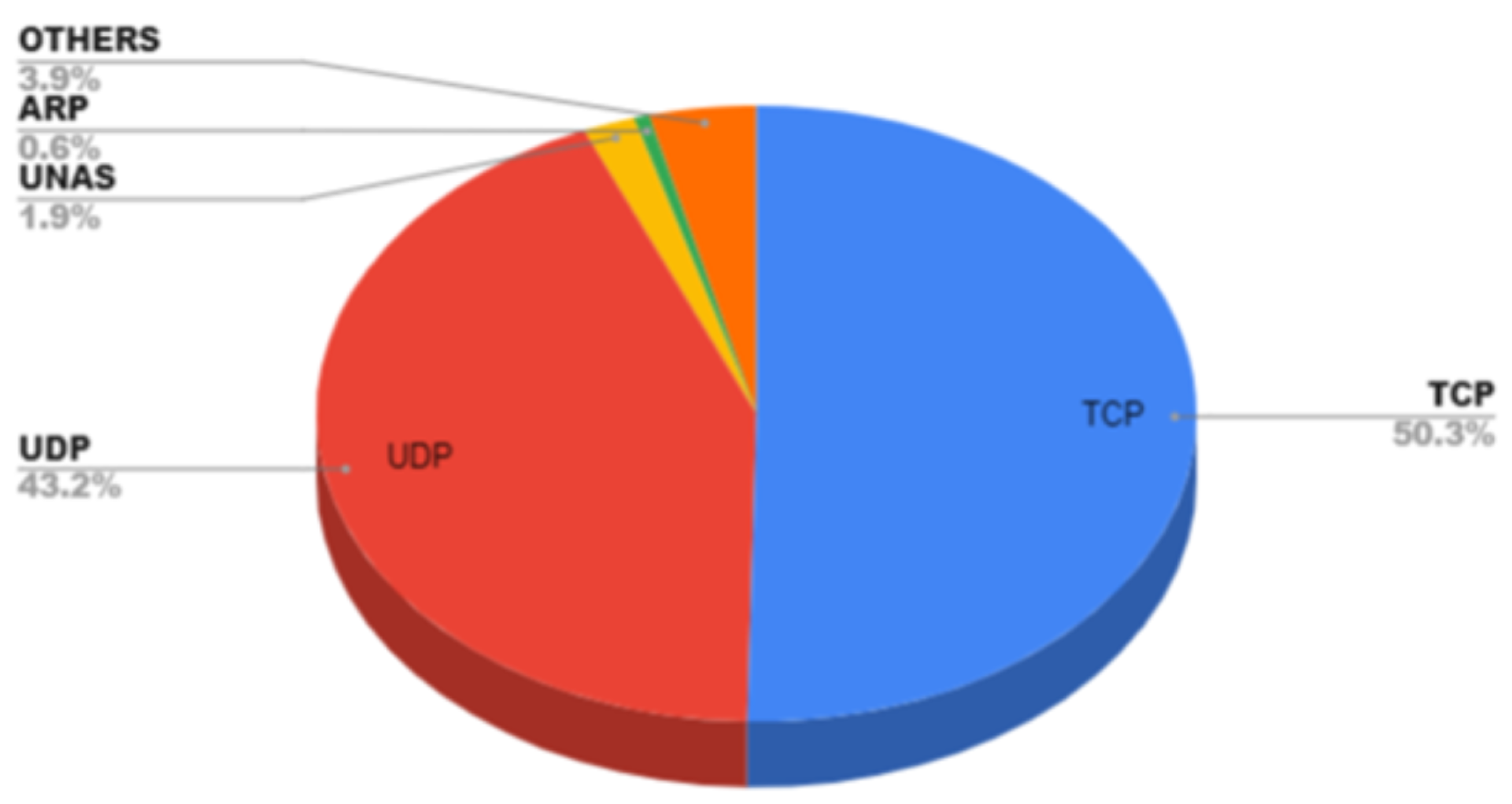
3.1. Dataset Details
3.2. Data Pre-Processing and Mixing
3.3. Discretization
3.4. Normalization
3.5. Low Rank Factorization
3.6. LR-SVM
3.7. LR-CNN-MLP
3.8. Bayesian Optimization
| Algorithm 1. Optimal selection of hyperparameter using Gaussian-based Bayesian parameter optimization for multi-label classification. |
Input: Attack dataset in CSV format (dataset) Output: Probability estimates for each label in the multi-label classification problem Step 1: Load the dataset and split it into training and testing sets . Step 2: Perform data pre-processing on . Step 3: Define the rank r, no. of classes n, no. of labels k, iters, learning rate lr, epochs and optimizer as hyperparameters. Step 4: Initialize CNN-MLP model and train it on and target labels Y (n * k). spm ← model ((conv()))/(conv()) Step 4.1: Apply the parameters to objective function = arg f(k) Step 4.2: Update surrogate probabilistic model for new parameters. spm ← model ((conv()))/(conv()) Step 5: Obtain weights ‘W’ of last fully connected layer. Step 6: Perform low-rank matrix factorization on ‘W’. W = T where = h*r = r*k Step 7: Initialize r with random values. Step 8: Define a function ‘, , lr)’ at last fully connected layer. Step 8.1: Obtain the low-rank matrix until convergence: = * ( * )/( * * ) = * ( * )/( * * ) Step 8.2: Compute the residuals E=W- T Step 8.3: Compute the gradient of ‘’ ‘’ w.r.t grad =−2E − grad = −2E T Step 8.4: Update and using learning rate as = −(lr* grad ) = −(lr* grad ) Step 8.5: Update the weights as last fully connected layers. W = T Step 9: Replace the weights of last fully connected layer in CNN-MLP with updated weights . Step 10: Retrain the CNN-MLP model on and target labels Y using fully connected layer. Step 11: Repeat Steps 5–9 for ’iters’ iterations Step 12: Probability estimates for each label in the multi-label classification problem as the average of the probability estimates obtained from the ensemble of models. |
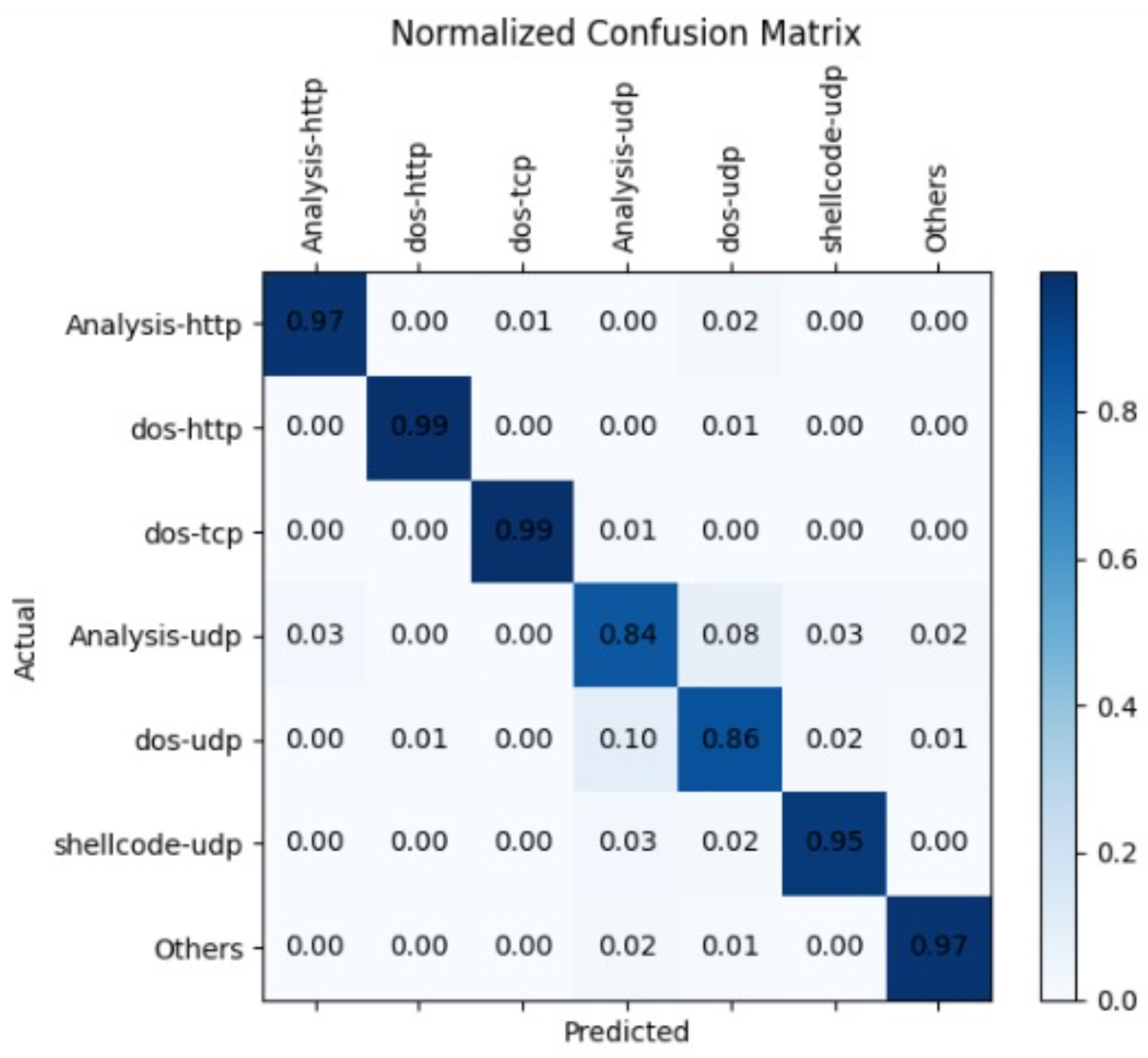
4. Results and Discussion
4.1. Parameter Tuning for Proposed SVM-Based Attack-Type Label Classification
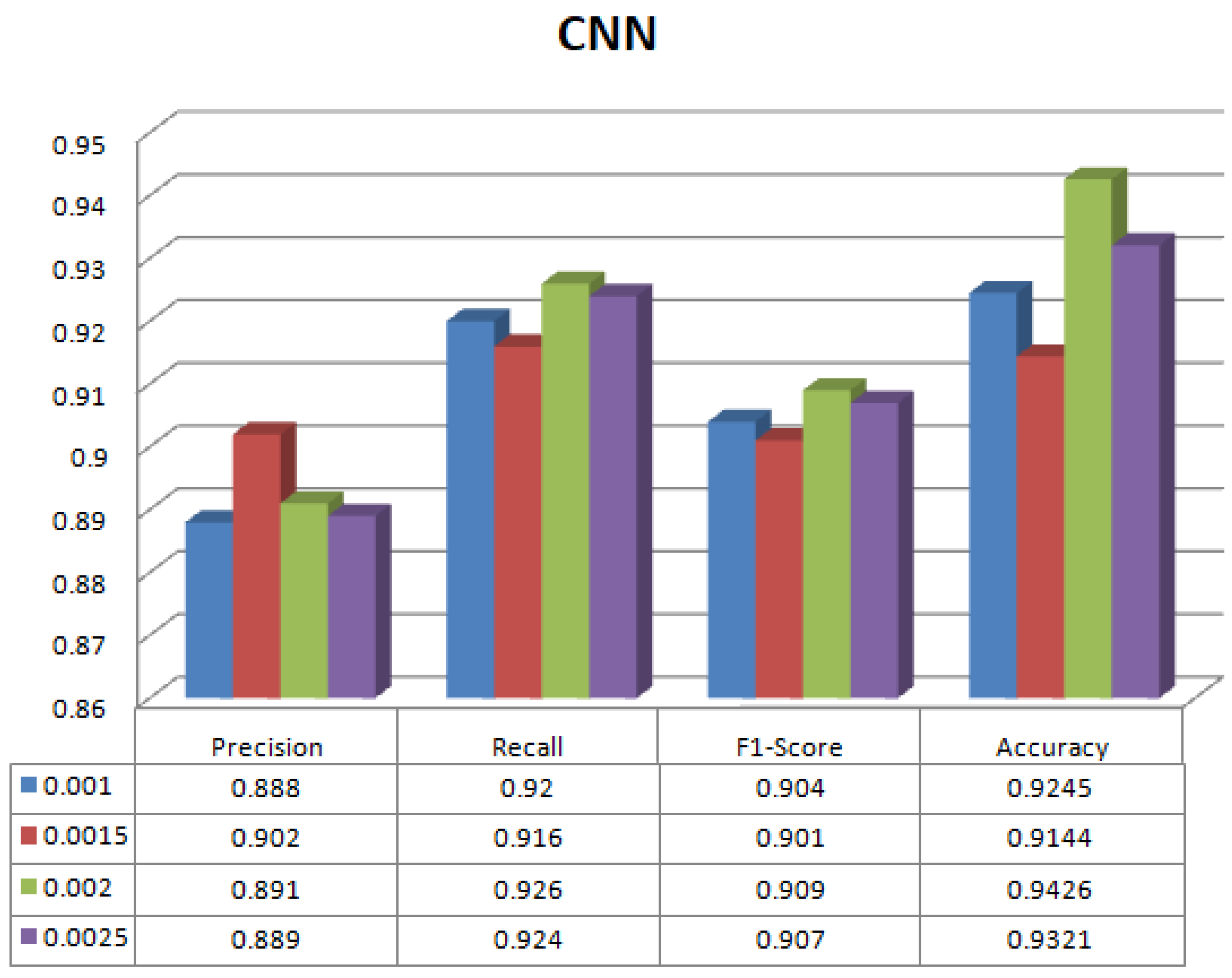
4.2. Parameter Tuning for Proposed CNN and CNN-MLP Based Attack-Type Label Classification
4.3. Parameter Tuning for Guassian Based Bayesian Optimization Algorithm
4.4. Limitation
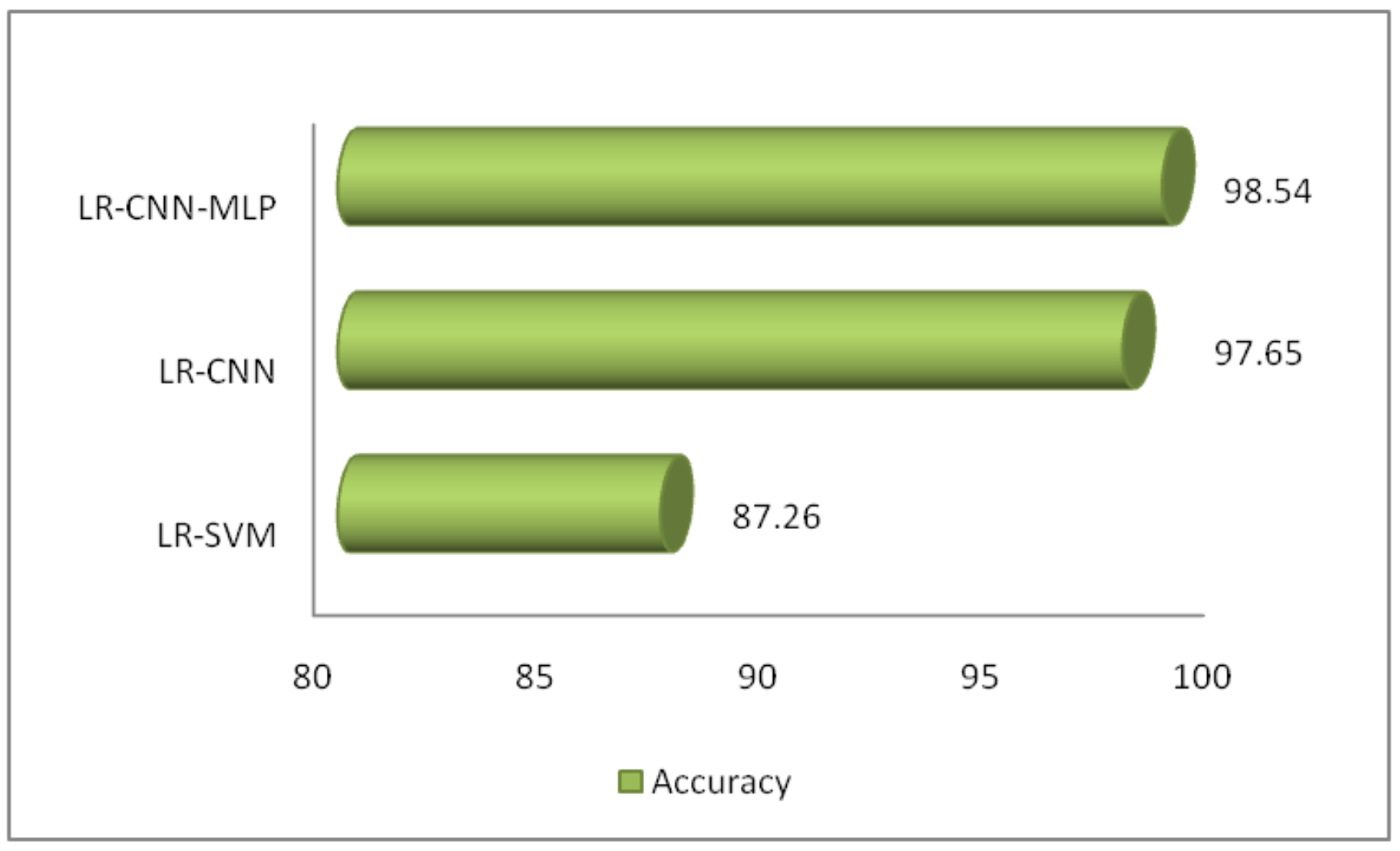
5. Comparative Analysis
6. Conclusions
7. Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Iwendi, C.; Khan, S.; Anajemba, J.; Mittal, M.; Alenezi, M.; Alazab, M. The use of ensemble models for multiple class and binary class classification for improving intrusion detection systems. Sensors 2020, 20, 2559. [Google Scholar] [CrossRef] [PubMed]
- Saba, T.; Sadad, T.; Rehman, A.; Mehmood, Z.; Javaid, Q. Intrusion detection system through advance machine learning for the internet of things networks. IT Prof. 2021, 23, 58–64. [Google Scholar] [CrossRef]
- Churcher, A.; Ullah, R.; Ahmad, J.; Ur Rehman, S.; Masood, F.; Gogate, M.; Alqahtani, F.; Nour, B.; Buchanan, W.J. An experimental analysis of attack classification using machine learning in IoT networks. Sensors 2021, 21, 446. [Google Scholar] [CrossRef] [PubMed]
- Atitallah, S.; Driss, M.; Ghezala, H. FedMicro-IDA: A federated learning and microservices-based framework for IoT data analytics. Internet Things 2023, 23, 100845. [Google Scholar] [CrossRef]
- Alsamiri, J.; Alsubhi, K. Internet of things cyber attacks detection using machine learning. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 627–634. [Google Scholar] [CrossRef]
- Khan, M.; Khan Khattk, M.; Latif, S.; Shah, A.; Ur Rehman, M.; Boulila, W.; Driss, M.; Ahmad, J. Voting classifier-based intrusion detection for iot networks. Adv. Smart Soft Comput. 2022, 1399, 313–328. [Google Scholar]
- Driss, M.; Hasan, D.; Boulila, W.; Ahmad, J. Microservices in IoT security: Current solutions, research challenges, and future directions. Procedia Comput. Sci. 2021, 192, 2385–2395. [Google Scholar] [CrossRef]
- Alshamkhany, W.; Mansour, M.; Khan, M.; Dhou, S.; Aloul, F. Botnet attack detection using machine learning. In Proceedings of the 2020 14th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–18 November 2020; pp. 203–208. [Google Scholar]
- Rashid, M.M.; Kamruzzaman, J.; Hassan, M.M.; Imam, T.; Gordon, S. Cyberattacks detection in iot-based smart city applications using machine learning techniques. Int. J. Environ. Res. Public Health 2020, 17, 9347. [Google Scholar] [CrossRef]
- Badotra, S.; Panda, S.N. SNORT based early DDoS detection system using Opendaylight and open networking operating system in software defined networking. Clust. Comput. 2021, 24, 501–513. [Google Scholar] [CrossRef]
- Sethi, M.; Ahuja, S.; Rani, S.; Bawa, P.; Zaguia, A. Classification of Alzheimer’s Disease Using Gaussian-Based Bayesian Parameter Optimization for Deep Convolutional LSTM Network. Comput. Math. Methods Med. 2021, 2021, 4186666. [Google Scholar] [CrossRef]
- Ge, M.; Fu, X.; Syed, N.; Baig, Z.; Teo, G.; Robles-Kelly, A. Deep learning-based intrusion detection for IoT networks. In Proceedings of the 2019 IEEE 24th Pacific Rim International Symposium on Dependable Computing (PRDC), Kyoto, Japan, 1–3 December 2019; pp. 256–25609. [Google Scholar]
- Xiao, Y.; Xing, C.; Zhang, T.; Zhao, Z. An Intrusion Detection Model Based on Feature Reduction and Convolutional Neural Networks. IEEE Access 2019, 7, 42210–42219. [Google Scholar] [CrossRef]
- Susilo, B.; Sari, R.F. Intrusion detection in IoT networks using deep learning algorithm. Information 2020, 11, 279. [Google Scholar] [CrossRef]
- Ben Atitallah, S.; Driss, M.; Boulila, W.; Ben Ghezala, H. Randomly initialized convolutional neural network for the recognition of COVID-19 using X-ray images. Int. J. Imaging Syst. Technol. 2022, 32, 55–73. [Google Scholar] [CrossRef] [PubMed]
- Zeeshan, M.; Riaz, Q.; Bilal, M.A.; Shahzad, M.K.; Jabeen, H.; Haider, S.A.; Rahim, A. Protocol-based deep intrusion detection for dos and ddos attacks using unsw-nb15 and bot-iot data-sets. IEEE Access 2021, 10, 2269–2283. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J.; Alazab, A. A Novel Ensemble of Hybrid Intrusion Detection System for Detecting Internet of Things Attacks. Electronics 2019, 8, 1210. [Google Scholar] [CrossRef]
- Kotpalliwar, M.V.; Wajgi, R. Classification of attacks using support vector machine (svm) on kddcup’99 ids database. In Proceedings of the 2015 Fifth International Conference on Communication Systems and Network Technologies, Gwalior, India, 4–6 April 2015; pp. 987–990. [Google Scholar]
- Pujari, M.; Pacheco, Y.; Cherukuri, B.; Sun, W. A Comparative Study on the Impact of Adversarial Machine Learning Attacks on Contemporary Intrusion Detection Datasets. SN Comput. Sci. 2022, 3, 412. [Google Scholar] [CrossRef]
- Malik, M.; Singh, Y. A review: DoS and DDoS attacks. Int. J. Comput. Sci. Mob. Comput. 2015, 4, 260–265. [Google Scholar]
- Rajput, H. MachineX: Simplifying Logistic Regression. Knoldus Blogs, 28 March 2018. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Bartkewitz, T.; Lemke-Rust, K. Efficient template attacks based on probabilistic multi-class support vector machines. In Smart Card Research and Advanced Applications, Proceedings of the 11th International Conference, CARDIS 2012, Graz, Austria, 28–30 November 2012, Revised Selected Papers 11; Springer: Berlin/Heidelberg, Germany, 2013; pp. 263–276. [Google Scholar]
- Sumarsono, A.; Du, Q.; Younan, N. Hyperspectral image segmentation with low-rank representation and spectral clustering. In Proceedings of the 2015 7th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Tokyo, Japan, 2–5 June 2015; pp. 1–4. [Google Scholar]
- Sumarsono, A.; Du, Q. Low-rank subspace representation for supervised and unsupervised classification of hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4188–4195. [Google Scholar] [CrossRef]
- Wang, J.; Shi, D.; Cheng, D.; Zhang, Y.; Gao, J. LRSR: Low-rank-sparse representation for subspace clustering. Neurocomputing 2016, 214, 1026–1037. [Google Scholar] [CrossRef]
- Wang, J.; Wang, X.; Tian, F.; Liu, C.H.; Yu, H. Constrained low-rank representation for robust subspace clustering. IEEE Trans. Cybern. 2016, 47, 4534–4546. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Shallow neural network with kernel approximation for prediction problems in highly demanding data networks. Expert Syst. Appl. 2019, 124, 196–208. [Google Scholar] [CrossRef]
- Akinsola, J.E.T.; Awodele, O.; Kuyoro, S.O.; Kasali, F.A. Performance evaluation of supervised machine learning algorithms using multi-criteria decision making techniques. In Proceedings of the International Conference on Information Technology in Education and Development (ITED), Valencia Spain, 11–13 March 2019; pp. 17–34. [Google Scholar]
- Liu, Z.; Wang, J.; Liu, G.; Zhang, L. Discriminative low-rank preserving projection for dimensionality reduction. Appl. Soft Comput. 2019, 85, 105768. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L.; Chang, S. A low-rank and sparse matrix decomposition-based dictionary reconstruction and anomaly extraction framework for hyperspectral anomaly detection. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1248–1252. [Google Scholar] [CrossRef]
- Li, L.; Li, W.; Du, Q.; Tao, R. Low-rank and sparse decomposition with mixture of Gaussian for hyperspectral anomaly detection. IEEE Trans. Cybern. 2020, 51, 4363–4372. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Wang, X.; Zhong, Y.; Zhang, L. Hyperspectral anomaly detection via locally enhanced low-rank prior. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6995–7009. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, X.; Li, Y.; Lei, J.; Li, J.; Du, Q. Weakly supervised low-rank representation for hyperspectral anomaly detection. IEEE Trans. Cybern. 2021, 51, 3889–3900. [Google Scholar] [CrossRef] [PubMed]
- Balyan, A.K.; Ahuja, S.; Lilhore, U.K.; Sharma, S.K.; Manoharan, P.; Algarni, A.D.; Elmannai, H.; Raahemifar, K. A hybrid intrusion detection model using ega-pso and improved random forest method. Sensors 2022, 22, 5986. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.P.; Poornachandrany, P. Applying convolutional neural network for network intrusion detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics, ICACCI 2017, Udupi, India, 13–16 September 2017; Volume 2017, pp. 1222–1228. [Google Scholar] [CrossRef]
- Erza Aminanto, M.; Kim, K. Deep Learning in Intrusion Detection System: An Overview. In Proceedings of the 2016 International Research Conference on Engineering and Technology (2016 IRCET), Bali, Indonesia, 28–30 June 2016. [Google Scholar]
- Ibitoye, O.; Shafiq, O.; Matrawy, A. Analyzing Adversarial Attacks Against Deep Learning for Intrusion Detection in IoT Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Rani, S.; Bashir, A.K.; Krichen, M.; Alshammari, A. A low-rank learning based Multi-Label Security Solution for Industry 5.0 Consumers using Machine Learning Classifiers. IEEE Trans. Consum. Electron. 2023. early access. [Google Scholar]
- Nagisetty, A.; Gupta, G.P. Framework for detection of malicious activities in IoT networks using keras deep learning library. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 633–637. [Google Scholar]
- Abou Khamis, R.; Matrawy, A. Evaluation of adversarial training on different types of neural networks in deep learning-based IDSs. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; pp. 1–6. [Google Scholar]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar]
- Al-Turaiki, I.; Altwaijry, N. A convolutional neural network for improved anomaly-based network intrusion detection. Big Data 2021, 9, 233–252. [Google Scholar] [CrossRef] [PubMed]
- Pokhrel, S.; Abbas, R.; Aryal, B. IoT security: Botnet detection in IoT using machine learning. arXiv 2021, arXiv:2104.02231. [Google Scholar]
- Charaan, R.D.; James, S.A.; Kumar, D.A.; Manigandan, M.D. Enhanced IoT based Approach to provide Secured System. In Proceedings of the 2022 International Conference on Inventive Computation Technologies (ICICT), Lalitpur, Nepal, 20–22 July 2022; pp. 962–966. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. No./Year | Technique | Data-Cleaning | Discretization | Normalization | Advantages | Limitations |
|---|---|---|---|---|---|---|
| [24]/ 2015 | Inexact Augmented Lagrange Multiplier | X | X | X | For complex data LRSR with spatial clustering for better performance. | LRR and LRSR not shown much improvement for simple data. Occupying single subspace. |
| [25]/ 2016 | Inexact Augmented Lagrange Multiplier | ✓ | X | X | Instead of occupying single subspace, occupies multi subspace. Removal of Outliers and Noise with no computational cost. | LRS coefficient matrix is missing. |
| [26]/ 2016 | Linearized alternating direction method (LADM) | X | X | ✓ | LRS coeffient matrix is obtained using LADM. | No systematical way to estimate parameters Lambda 1 and Lambda 2. |
| [27]/ 2017 | Alternating direction method (ADM) | ✓ | X | ✓ | Fixed Lambda = 2, noise free data with independent subspaces. | Aim to obtain an effective data representation matrix is still needed. |
| [28]/ 2019 | Wilcoxon Signed Rank | X | X | X | Fast and Flexible model with non-linear behavior and representation of data matrix. | Low detection performance. |
| [29]/ 2019 | SAW, TOP SIS, MCM | X | X | X | The collected samples’ low rankness in low-dimensional space is used to create an instructive graph that captures local information. | Capturing global information is still an issue. |
| [30]/ 2019 | Low-Rank Representation | X | X | X | Both local and global info of the original samples can be well captured. | Insufficient creation of dictionary |
| [31]/ 2019 | LRaSMD | X | X | ✓ | Proper dictionary is created using LR and SM. | Single distribution can be used to simulate both anomalies and noise, which separates weak anomalies and noise. |
| [32]/ 2020 | Manhattan Distance LSMD-MoG | X | X | ✓ | Single distribution is replaced by MoG. Not only stable but also effective for hyperspectral AD. | Lambda and beta set to 0.1. |
| [33]/ 2020 | LELRP-AD | X | X | X | Low rank property of DM is enhanced. | The rank value r and cardinality c taken to be specific. |
| [34]/ 2021 | Manhattan Distance LSMD-MoG | X | X | ✓ | Finds all anomalies and shapes them clearly. | WSL can not be used without LRR. |
| Epochs | Learning Rate | Accuracy |
|---|---|---|
| Epochs = 150 | lr = 0.010 | 85.35% |
| lr = 0.015 | 81.34% | |
| lr = 0.020 | 82.21% | |
| lr = 0.025 | 82.56% | |
| Epochs = 200 | lr = 0.010 | 85.45% |
| lr = 0.015 | 87.26% | |
| lr = 0.020 | 85.65% | |
| lr = 0.025 | 86.69% | |
| Epochs = 250 | lr = 0.010 | 83.20% |
| lr = 0.015 | 86.24% | |
| lr = 0.020 | 86.54% | |
| lr = 0.025 | 86.44% |
| Learning Rate | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| lr1 = 0.0010 | 0.888 | 0.920 | 0.904 | 92.45 |
| lr2 = 0.0015 | 0.902 | 0.916 | 0.901 | 91.44 |
| lr3 = 0.0020 | 0.891 | 0.926 | 0.909 | 94.26 |
| lr4 = 0.0025 | 0.889 | 0.924 | 0.907 | 93.21 |
| Learning Rate | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| lr1 = 0.0010 | 0.943 | 0.975 | 0.959 | 96.12 |
| lr2 = 0.0015 | 0.956 | 0.97 | 0.963 | 96.84 |
| lr3 = 0.0020 | 0.944 | 0.979 | 0.961 | 98.17 |
| lr4 = 0.0025 | 0.942 | 0.978 | 0.960 | 97.91 |
| Model | Parameter | Accuracy |
|---|---|---|
| LR-SVM | c = 1.0, = 0.1, lr = 0.0020, epochs = 150, and optimizer = SGD | 87.26% |
| LR-CNN | = 1.0, = 0.5, lr = 0.001, epochs = 100, layers = 2, and optimizer = Adam | 96.36% |
| = 1.0, = 0.5, lr = 0.002, epochs = 200, layers = 2, and optimizer = SGD | 97.65% | |
| LR-CNN-MLP | = 1.0, = 0.5, lr = 0.001, epochs = 100, layers = 2, and optimizer = Adam | 98.89% |
| = 1.0, = 0.5, lr = 0.0015, epochs = 125, layers = 2, and optimizer = SGD | 99.20% | |
| = 1.0, = 0.5, lr = 0.0020, epochs = 125, layers = 2, and optimizer = RMSProp | 98.54% |
| Ref. No./Year | Dataset | DL Classifier | Parameters | Findings | Limitations |
|---|---|---|---|---|---|
| [41] 2019 | UNSW-NB15 | CNN, MLP | Accuracy and F1-Score | Good performance in terms of RMSE. | Not easily customizable. |
| [42] 2020 | UNSW-NB15 | CNN | Accuracy | Analysis of min-max formulation with DL. | Specific attack types. |
| [43] 2020 | Bot-IoT | CNN | Accuracy, Detection Rate, FAR | Results is binary and multiclass classification | No results for multilabel classification |
| [44] 2021 | UNSW-NB15 | BCNN MCNN | Accuracy, Precision, Recall, F-measure | Skip connection methodology into CNN | Not performed well on the specific dataset. |
| [45] 2021 | Bot-IoT | MLP | Precision and F1-Score | Help to monitor traffic flow in connected host | Only worked in binary classification |
| [46] 2022 | Bot-IoT | CNN | Accuracy, Precision and Training Time | CNN achieved best results as compared to LR and DT | Computational and memory utilization can be improved by using optimized generalized techniques. |
| Proposed Methodology | Hybrid dataset | LR-SVM | Accuracy | SVM has not been able to achieve results in multilabel classification of attack classes corresponding to one label | Due to high sparsity and high dimensionality of data in the integrated dataset |
| Proposed Methodology | Hybrid dataset | LR-CNN-MLP | Accuracy, Precision, Recall and F1-Score | Hybrid CNN-MLP achieved results in multilabel classification of attack classes corresponding to one label |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, A.; Rani, S.; Sah, D.K.; Khan, Z.; Boulila, W. HOMLC-Hyperparameter Optimization for Multi-Label Classification of Intrusion Detection Data for Internet of Things Network. Sensors 2023, 23, 8333. https://doi.org/10.3390/s23198333
Sharma A, Rani S, Sah DK, Khan Z, Boulila W. HOMLC-Hyperparameter Optimization for Multi-Label Classification of Intrusion Detection Data for Internet of Things Network. Sensors. 2023; 23(19):8333. https://doi.org/10.3390/s23198333
Chicago/Turabian StyleSharma, Ankita, Shalli Rani, Dipak Kumar Sah, Zahid Khan, and Wadii Boulila. 2023. "HOMLC-Hyperparameter Optimization for Multi-Label Classification of Intrusion Detection Data for Internet of Things Network" Sensors 23, no. 19: 8333. https://doi.org/10.3390/s23198333
APA StyleSharma, A., Rani, S., Sah, D. K., Khan, Z., & Boulila, W. (2023). HOMLC-Hyperparameter Optimization for Multi-Label Classification of Intrusion Detection Data for Internet of Things Network. Sensors, 23(19), 8333. https://doi.org/10.3390/s23198333