

A Novel Fractional Accumulative Grey Model with GA-PSO Optimizer and Its Application


Abstract
:1. Introduction
- (1)
- According to the principle of new information priority, we proposed an optimized fractional accumulative GM(1,1) model, which was applied to the prediction of cyber security situations for the first time;
- (2)
- The combination of the genetic algorithm and particle swarm optimization was used to find the optimal order of the FAGM(1,1) model, which improved the accuracy of the model and achieved remarkable results.
2. Materials and Methods
2.1. Grey Model
2.1.1. Classic GM(1,1) Model
2.1.2. Fractional Accumulative GM(1,1)
2.2. Optimization Technology
2.2.1. Genetic Algorithm
2.2.2. Particle Swarm Optimization
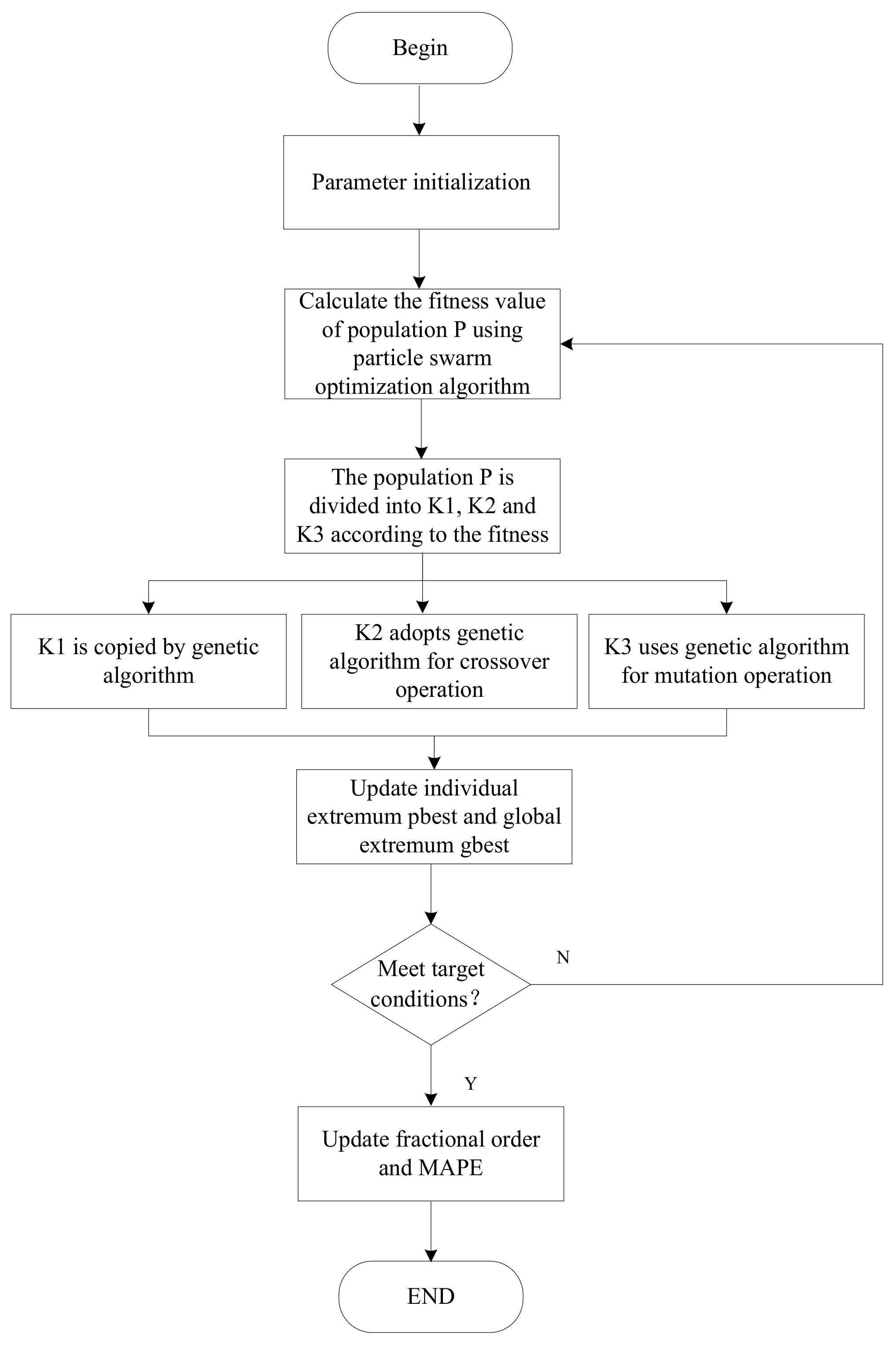
2.3. The Proposed Method
3. Results
3.1. Experimental Data
3.2. Experimental Environment
- Hardware conditions:
- CPU: Inter(R) Core(TM) i5-4590 3.30 GHZ;
- Ram: 8 GB;
- Hard disk: 500 GB.
- Operating system: 64 bits.
3.3. Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, J. Introduction to Grey System Theory. J. Grey Syst. UK 1989, 1, 1–24. [Google Scholar]
- Yuan, C.; Liu, S.; Fang, Z. Comparison of China’s Primary Energy Consumption Forecasting by Using Arima (the Autoregressive Integrated Moving Average) Model and GM (1, 1) Model. Energy 2016, 100, 384–390. [Google Scholar] [CrossRef]
- Xie, N.M.; Liu, S.F. Discrete Grey Forecasting Model and Its Optimization. Appl. Math. Model. 2009, 33, 1173–1186. [Google Scholar] [CrossRef]
- Ye, J.; Dang, Y.; Ding, S.; Yang, Y. A Novel Energy Consumption Forecasting Model Combining an Optimized DGM (1, 1) Model with Interval Grey Numbers. J. Clean Prod. 2019, 229, 256–267. [Google Scholar] [CrossRef]
- Lu, S. Integrating Heuristic Time Series with Modified Grey Forecasting for Renewable Energy in Taiwan. Renew. Energy 2019, 133, 1436–1444. [Google Scholar] [CrossRef]
- Zeng, B.; Tong, M.; Ma, X. A New-Structure Grey Verhulst Model: Development and Performance Comparison. Appl. Math. Model. 2020, 81, 522–537. [Google Scholar] [CrossRef]
- Luo, X.; Duan, H.; He, L. A Novel Riccati Equation Grey Model and its Application in Forecasting Clean Energy. Energy 2020, 205, 118085. [Google Scholar] [CrossRef]
- Xie, N.M.; Liu, S.F. Discrete GM (1, 1) and Mechanism of Grey Forecasting Model. Syst. Eng. Theory Pract. 2005, 25, 93–99. [Google Scholar] [CrossRef]
- Mao, S.; Xiao, X.; Gao, M.; Wang, X.; He, Q. Nonlinear Fractional Order Grey Model of Urban Traffic Flow Short-Term Prediction. J. Grey Syst. UK 2018, 30, 1–17. [Google Scholar]
- Shen, Q.; Shi, Q.; Tang, T.; Yao, L. A Novel Weighted Fractional GM(1,1) Model and its Applications. Complexity 2020, 2020, 6570683. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Guo, Y.; Li, B.; Gao, P.; Liu, J.; Zhang, W.; Jiao, M. Prediction of SO2 Emission from Industrial Sector in Shanghai City Based on Novel Discrete Grey Model. J. Grey Syst. UK 2017, 29, 26–35. [Google Scholar]
- Zeng, L. A Fractional Order Opposite-Direction Accumulative Grey Prediction Model with Time-Power. J. Grey Syst. UK 2019, 31, 90–104. [Google Scholar]
- Shen, Y.; Qin, P. Optimization of Grey Model with the Fractional Order Accumulation. J. Grey Syst. UK 2014, 17, 127–132. [Google Scholar]
- Yang, Y.; Xue, D.U. Continuous Fractional-Order Grey Model and Electricity Prediction Research Based on the Observation Error Feedback. Energy 2016, 115, 722–733. [Google Scholar] [CrossRef]
- Mao, S.; Gao, M.; Xiao, X.; Zhu, M. A Novel Fractional Grey System Model and its Application. Appl. Math. Model. 2016, 40, 5063–5076. [Google Scholar] [CrossRef]
- Zhu, X.; Dang, Y.; Ding, S. Using a Self-Adaptive Grey Fractional Weighted Model to Forecast Jiangsu’s Electricity Consumption in China. Energy 2020, 190, 116417. [Google Scholar] [CrossRef]
- Al-Mdallal, Q.M.; Hajji, M.A. A Convergent Algorithm for Solving Higher-Order Nonlinear Fractional Boundary Value Problems. Fract. Calc. Appl. Anal. 2015, 18, 1423–1440. [Google Scholar] [CrossRef]
- Al-Mdallal, Q.; Abro, K.A.; Khan, I. Analytical Solutions of Fractional Walter’s B Fluid with Applications. Complexity 2018, 2018, 8131329. [Google Scholar] [CrossRef] [Green Version]
- Meng, W.; Yang, D.; Huang, H. Prediction of China’s Sulfur Dioxide Emissions by Discrete Grey Model with Fractional Order Generation Operators. Complexity 2018, 2018, 8610679. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Liu, S.; Yao, L.; Yan, S.; Liu, D. Grey System Model with the Fractional Order Accumulation. Commun. Nonlinear Sci. 2013, 18, 1775–1785. [Google Scholar] [CrossRef]
- Wu, L.; Gao, X.; Xiao, Y.; Yang, Y.; Chen, X. Using a Novel Multi-Variable Grey Model to Forecast the Electricity Consumption of Shandong Province in China. Energy 2018, 157, 327–335. [Google Scholar] [CrossRef]
- Jiang, H.; Kong, P.; Hu, Y.; Jiang, P. Forecasting China’s CO2 Emissions by Considering Interaction of Bilateral FDI Using the Improved Grey Multivariable Verhulst Model. Environ. Dev. Sustain. 2021, 23, 225–240. [Google Scholar] [CrossRef] [Green Version]
- Gao, P.; Zhan, J.; Liu, J. Fractional Order Reverse Accumulative Non-Homogeneous Discrete Grey Forecasting Model and its Application. J. Grey Syst. UK 2019, 31, 98–109. [Google Scholar]
- Wu, W.; Ma, X.; Zeng, B.; Wang, Y.; Cai, W. Application of the Novel Fractional Grey Model FAGMO (1, 1, K) to Predict China’s Nuclear Energy Consumption. Energy 2018, 165, 223–234. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Mei, X.; Wu, W.; Wu, X.; Zeng, B. A Novel Fractional Time Delayed Grey Model with Grey Wolf Optimizer and its Applications in Forecasting the Natural Gas and Coal Consumption in Chongqing China. Energy 2019, 178, 487–507. [Google Scholar] [CrossRef]
- Wu, L.; Zhao, H. Forecasting Air Quality Indicators for 33 Cities in China. Clean Soil Air Water 2020, 48, 1900097. [Google Scholar] [CrossRef]
- Wu, W.; Ma, X.; Zhang, Y.; Li, W.; Wang, Y. A Novel Conformable Fractional Non-Homogeneous Grey Model for Forecasting Carbon Dioxide Emissions of Brics Countries. Sci. Total Environ. 2020, 707, 135447. [Google Scholar] [CrossRef]
- Abdeljawad, T.; Al-Mdallal, Q.M.; Jarad, F. Fractional Logistic Models in the Frame of Fractional Operators Generated by Conformable Derivatives. Chaos Solitons Fractals 2019, 119, 94–101. [Google Scholar] [CrossRef]
- Yang, Y.; Xue, D. Modified Grey Model Predictor Design Using Optimal Fractional-Order Accumulation Calculus. IEEE-CAA J. Autom. 2017, 4, 724–733. [Google Scholar] [CrossRef]
- Liu, Q.; Yu, D. Non-Equidistance and Nonhomogeneous Grey Model NNFGM (1, 1) with the Fractional Order Accumulation and its Application. J. Interdiscip. Math. 2017, 20, 1423–1426. [Google Scholar] [CrossRef]
- Abdel-Magid, Y.L.; Abido, M.A. Optimal Multiobjective Design of Robust Power System Stabilizers Using Genetic Algorithms. IEEE Trans. Power Syst. 2003, 18, 1125–1132. [Google Scholar] [CrossRef] [Green Version]
- Abido, M.A. Optimal Design of Power-System Stabilizers Using Particle Swarm Optimization. IEEE Trans. Energy Conver. 2002, 17, 406–413. [Google Scholar] [CrossRef]
- Tam, J.H.; Ong, Z.C.; Ismail, Z.; Ang, B.C.; Khoo, S.Y. Identification of Material Properties of Composite Materials Using Nondestructive Vibrational Evaluation Approaches: A Review. Mech. Adv. Mater. Struc. 2017, 24, 971–986. [Google Scholar] [CrossRef]
- Guo, H.Y.; Zhang, L.; Zhang, L.L.; Zhou, J.X. Optimal Placement of Sensors for Structural Health Monitoring Using Improved Genetic Algorithms. Smart Mater. Struct. 2004, 13, 528. [Google Scholar] [CrossRef] [Green Version]
- Minaei-Bidgoli, B.; Punch, A.W.F. Using Genetic Algorithms for Data Mining Optimization in an Educational Web-Based System. In Proceedings of the Genetic and Evolutionary Computation Conference, Chicago, IL, USA, 12–16 July 2003. [Google Scholar]
- Pluhacek, M.; Senkerik, R.; Zelinka, I.; Davendra, D. Chaos PSO Algorithm Driven Alternately by Two Different Chaotic Maps-an Initial Study. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013. [Google Scholar]
- Tharwat, A.; Elhoseny, M.; Hassanien, A.E.; Gabel, T.; Kumar, A. Intelligent Bézier Curve-Based Path Planning Model Using Chaotic Particle Swarm Optimization Algorithm. Clust. Comput. 2019, 22, 4745–4766. [Google Scholar] [CrossRef]
- Khairy, M.; Fayek, M.B.; Hemayed, E.E. Pso2: Particle Swarm Optimization with PSO-Based Local Search. In Proceedings of the 2011 IEEE Congress of Evolutionary Computation (CEC), New Orleans, LA, USA, 5–8 June 2011. [Google Scholar]
- Zhang, R.; Chang, P.; Song, S.; Wu, C. Local Search Enhanced Multi-Objective PSO Algorithm for Scheduling Textile Production Processes with Environmental Considerations. Appl. Soft Comput. 2017, 61, 447–467. [Google Scholar] [CrossRef]
- Deng, W.; Zhao, H.; Yang, X.; Xiong, J.; Sun, M.; Li, B. Study on an Improved Adaptive PSO Algorithm for Solving Multi-Objective Gate Assignment. Appl. Soft Comput. 2017, 59, 288–302. [Google Scholar] [CrossRef]
- Deng, W.; Yao, R.; Zhao, H.; Yang, X.; Li, G. A Novel Intelligent Diagnosis Method Using Optimal LS-SVM with Improved PSO Algorithm. Soft Comput. 2019, 23, 2445–2462. [Google Scholar] [CrossRef]
- Khan, R.U.; Almakdi, S.; Alshehri, M.; Kumar, R.; Ali, I.; Hussain, S.M.; Haq, A.U.; Khan, I.; Ullah, A.; Uddin, M.I. Probabilistic Approach to COVID-19 Data Analysis and Forecasting Future Outbreaks Using a Multi-Layer Perceptron Neural Network. Diagnostics 2022, 12, 2539. [Google Scholar] [CrossRef]
- Adeli, H.; Sarma, K.C. Cost Optimization of Structures: Fuzzy Logic, Genetic Algorithms, and Parallel Computing; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Madabhushi, P.B.; Adams II, T.A. Side Stream Control in Semicontinuous Distillation. Comput. Chem. Eng. 2018, 119, 450–464. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
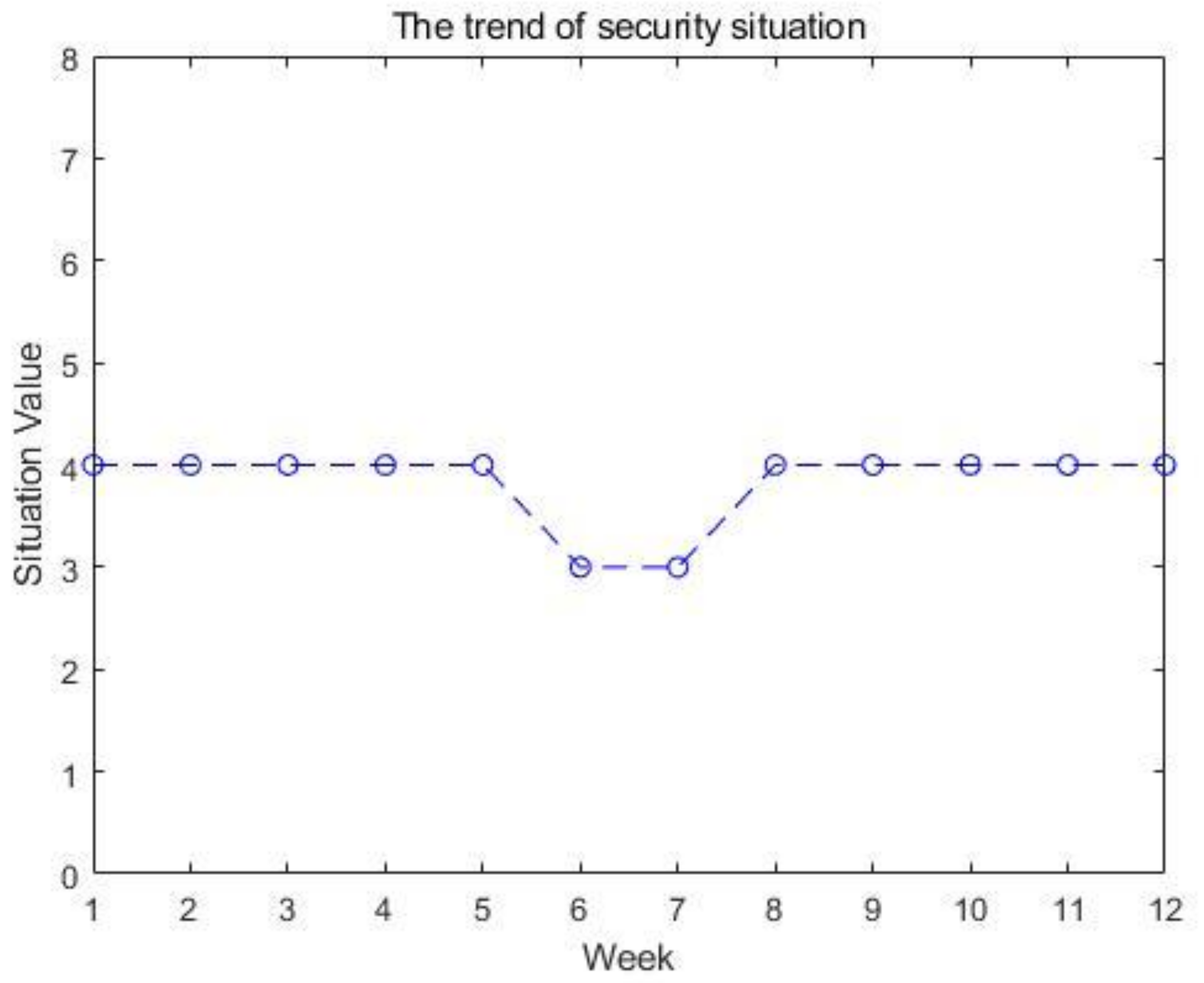
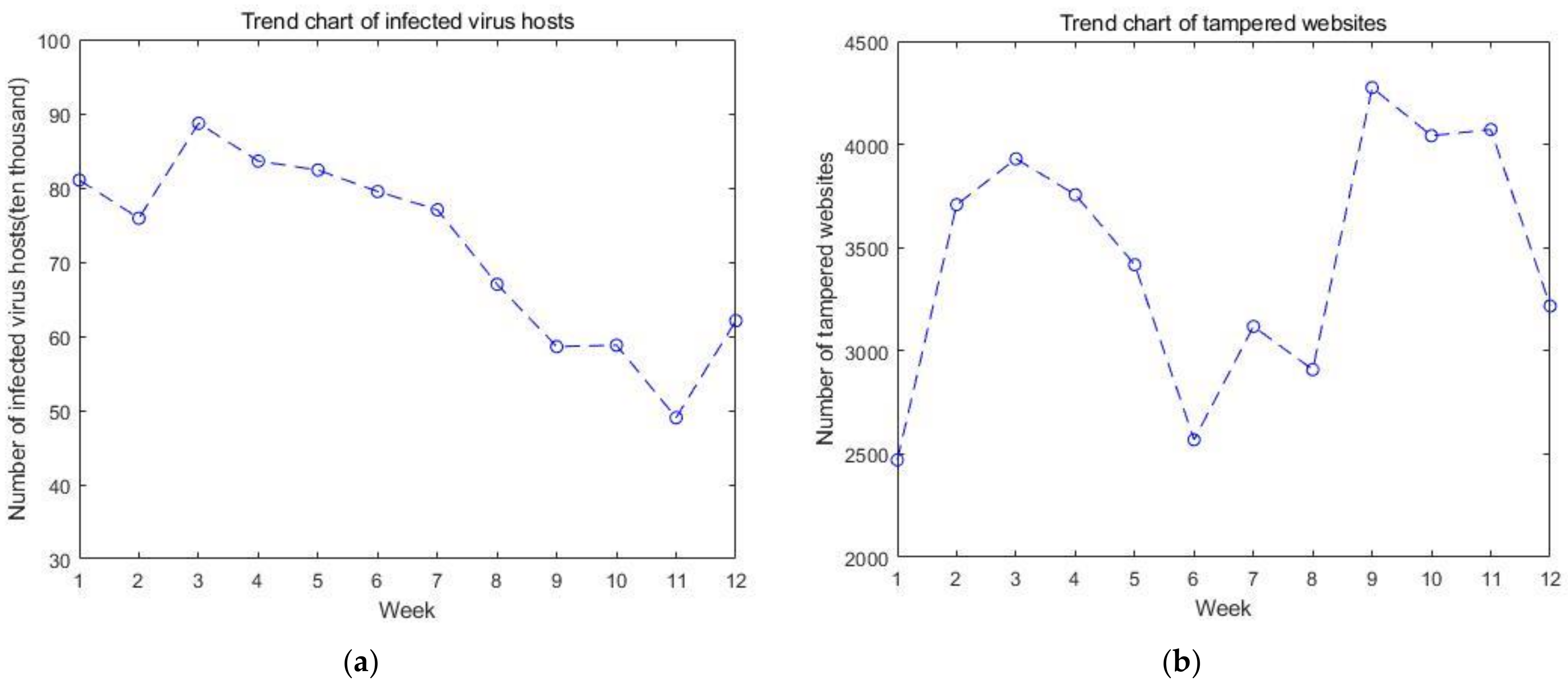
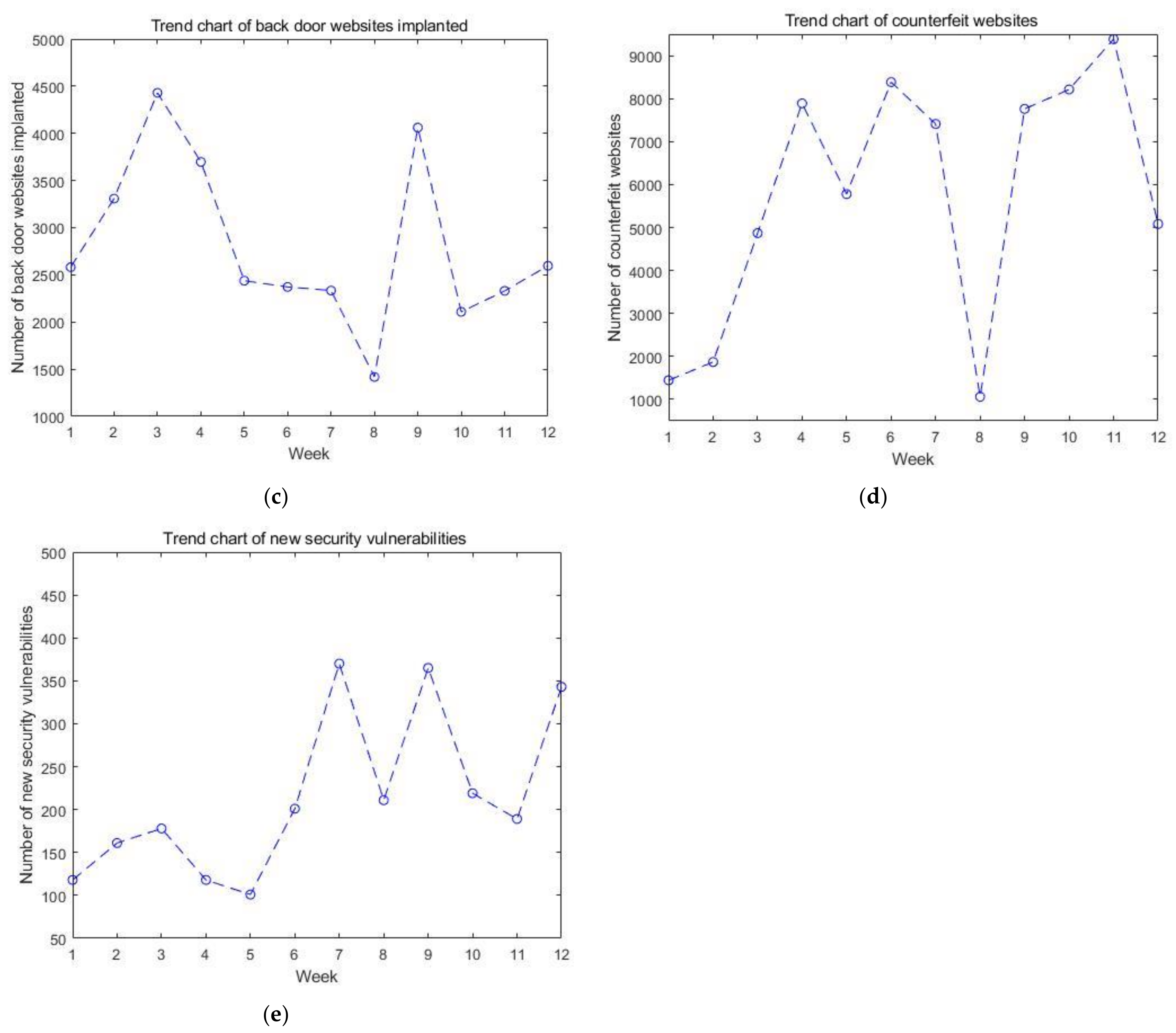
| SN | Cyber Security Situation Level | Number of Infected Virus Hosts | Number of Tampered Websites | Number of Back Door Websites Implanted | Number of Counterfeit Websites | Number of New Security Vulnerabilities |
|---|---|---|---|---|---|---|
| 1. | 4 | 81.05 | 2471 | 2581 | 1444 | 118 |
| 2. | 4 | 75.9 | 3708 | 3309 | 1870 | 161 |
| 3. | 4 | 88.7 | 3930 | 4430 | 4870 | 178 |
| 4. | 4 | 83.6 | 3756 | 3697 | 7889 | 118 |
| 5. | 4 | 82.39 | 3417 | 2438 | 5778 | 101 |
| 6. | 3 | 79.5 | 2569 | 2372 | 8384 | 201 |
| 7. | 3 | 77.04 | 3118 | 2334 | 7410 | 370 |
| 8. | 4 | 67 | 2909 | 1418 | 1061 | 211 |
| 9. | 4 | 58.6 | 4275 | 4061 | 7761 | 365 |
| 10. | 4 | 58.8 | 4042 | 2108 | 8212 | 219 |
| 11. | 4 | 49.03 | 4072 | 2330 | 9384 | 189 |
| 12. | 4 | 62.1 | 3217 | 2596 | 5082 | 343 |
| Excellent | Good | Medium | Poor | Dangerous |
|---|---|---|---|---|
| 5 | 4 | 3 | 2 | 1 |
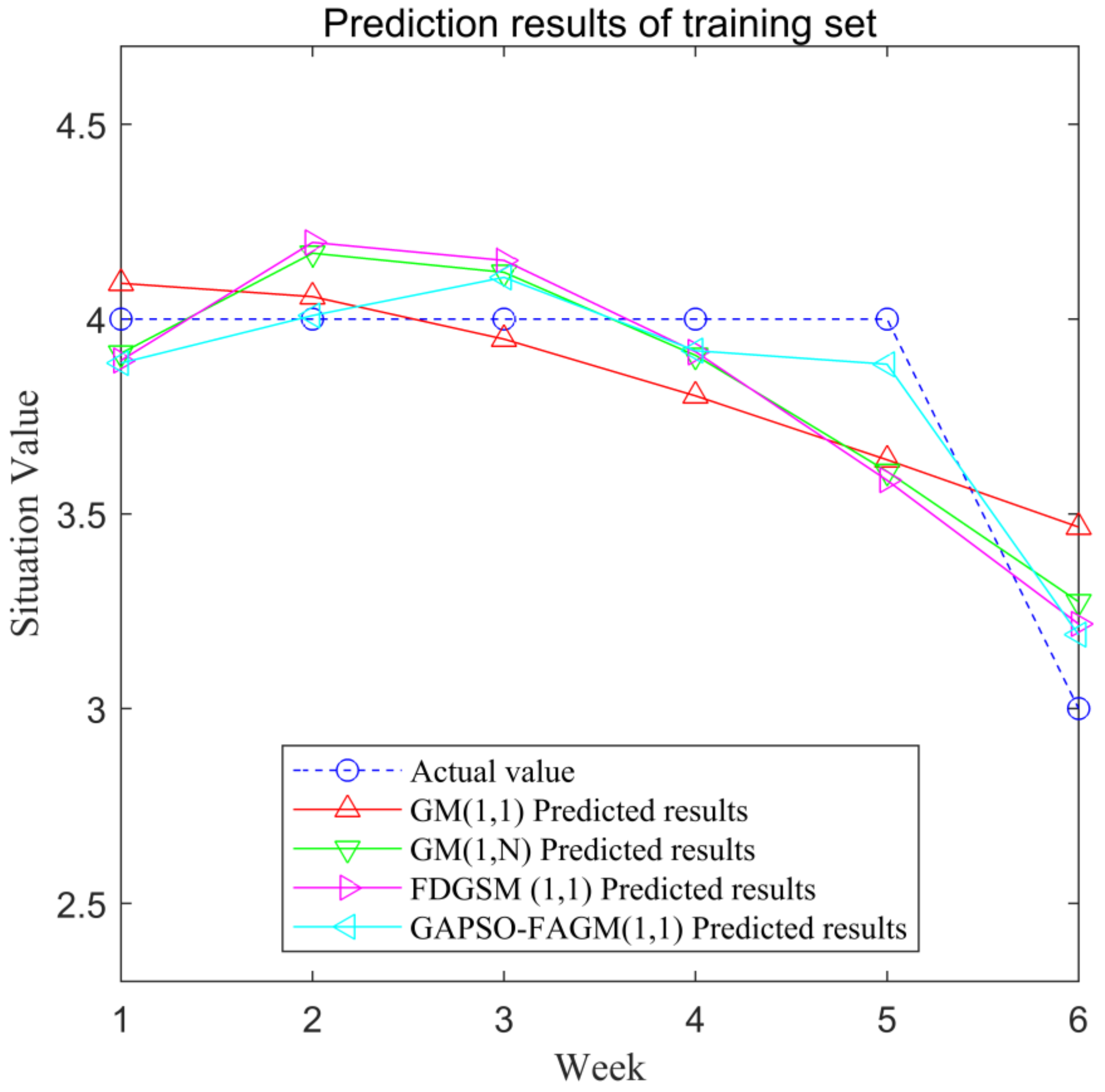
| Sn. | Actual Value | GM(1,1) | GM(1,N) | FDGSM(1,1) | GAPSO-FAGM(1,1) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Values | Relative Error (%) | Values | Relative Error (%) | Values | Relative Error (%) | Values | Relative Error (%) | ||
| 1 | 4 | 4.0917 | 2.2937 | 3.9123 | 2.1922 | 3.8938 | 2.6559 | 3.887 | 2.825 |
| 2 | 4 | 4.0575 | 1.4376 | 4.1690 | 4.2242 | 4.1967 | 4.9170 | 4.0090 | 0.225 |
| 3 | 4 | 3.9484 | 1.2891 | 4.1199 | 2.9973 | 4.1505 | 3.7626 | 4.1070 | 2.675 |
| 4 | 4 | 3.8028 | 4.9293 | 3.9067 | 2.3337 | 3.9159 | 2.1018 | 3.9187 | 2.0325 |
| 5 | 4 | 3.6387 | 9.0314 | 3.6089 | 9.7770 | 3.5861 | 10.3467 | 3.8840 | 2.9 |
| 6 | 3 | 3.4661 | 15.5361 | 3.2743 | 9.1436 | 3.2173 | 7.2422 | 3.1897 | 6.3233 |
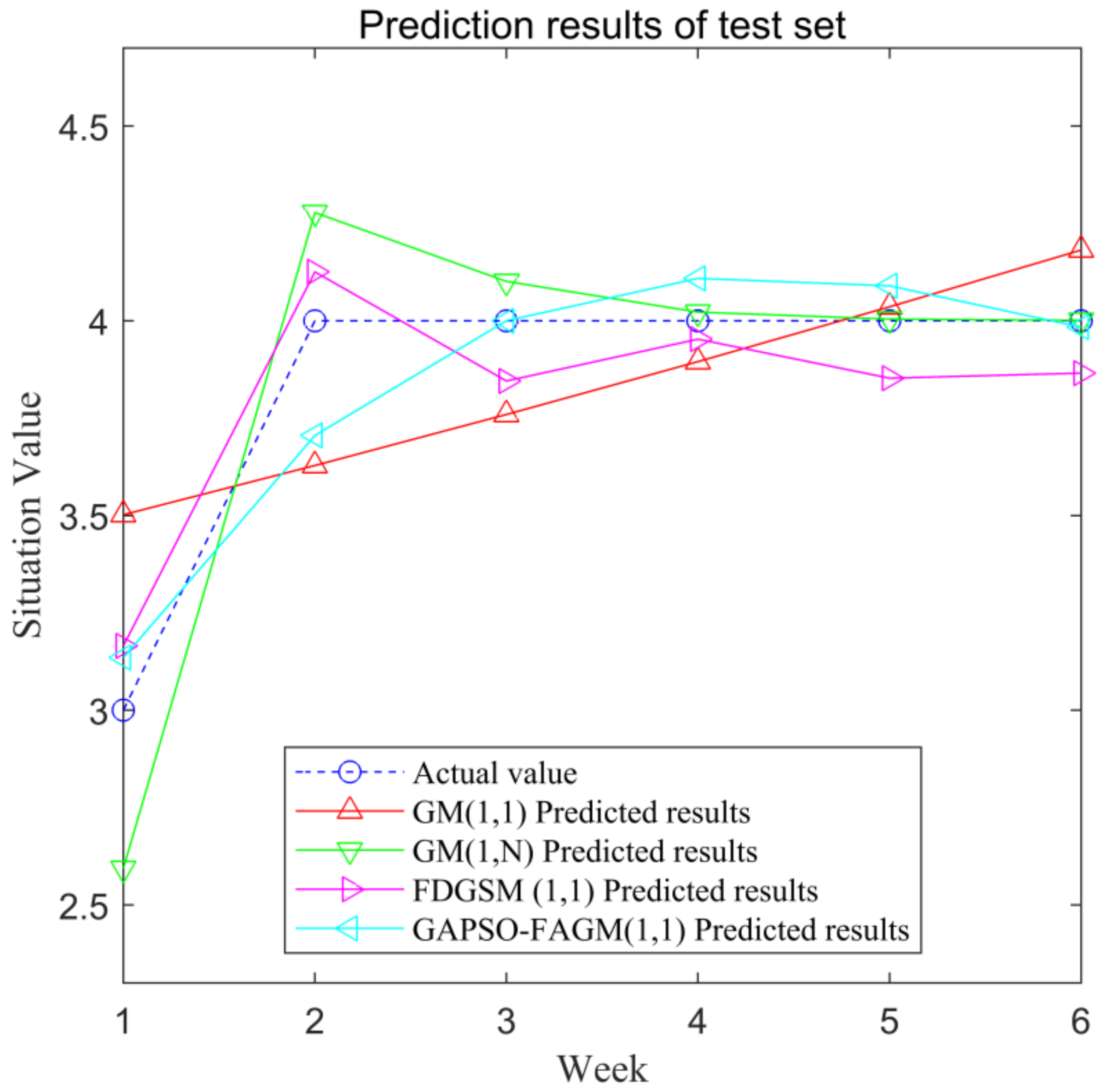
| Sn. | Actual Value | GM(1,1) | GM(1,N) | FDGSM(1,1) | GAPSO-FAGM(1,1) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Values | Relative Error (%) | Values | Relative Error (%) | Values | Relative Error (%) | Values | Relative Error (%) | ||
| 1 | 3 | 3.5020 | 16.73 | 2.5940 | 13.53 | 3.1654 | 5.51 | 3.1350 | 4.50 |
| 2 | 4 | 3.6284 | 9.29 | 4.2778 | 6.94 | 4.1255 | 3.14 | 3.7055 | 7.36 |
| 3 | 4 | 3.7594 | 6.01 | 4.1010 | 2.52 | 3.8454 | 3.87 | 4.0001 | 0.0024 |
| 4 | 4 | 3.8951 | 2.62 | 4.0222 | 0.56 | 3.9527 | 1.19 | 4.1087 | 2.7185 |
| 5 | 4 | 4.0358 | 0.89 | 4.0042 | 0.10 | 3.8526 | 3.69 | 4.0897 | 2.2435 |
| 6 | 4 | 4.1815 | 4.53 | 4.0010 | 0.02 | 3.8656 | 3.36 | 3.9835 | 0.4132 |
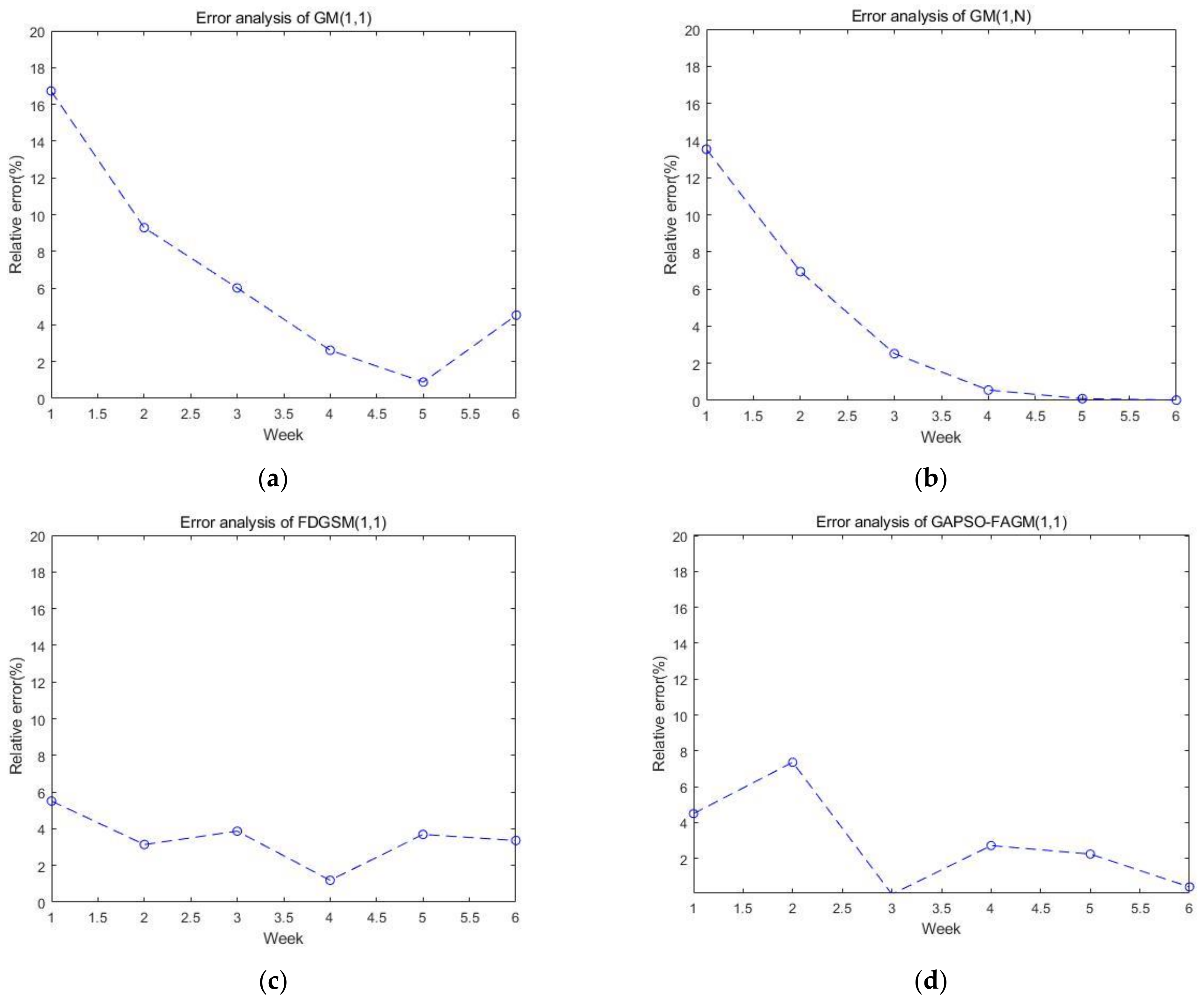
| GM(1,1) | GM(1,n) | FDGSM(1,1) | GAPSO-GM(1,1) |
|---|---|---|---|
| 5.75% | 5.11% | 5.17% | 2.83% |
| GM(1,1) | GM(1,n) | FDGSM(1,1) | GAPSO-GM(1,1) |
|---|---|---|---|
| 6.68% | 3.95% | 3.46% | 2.87% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, R.; Fu, X.; Pu, Y. A Novel Fractional Accumulative Grey Model with GA-PSO Optimizer and Its Application. Sensors 2023, 23, 636. https://doi.org/10.3390/s23020636
Huang R, Fu X, Pu Y. A Novel Fractional Accumulative Grey Model with GA-PSO Optimizer and Its Application. Sensors. 2023; 23(2):636. https://doi.org/10.3390/s23020636
Chicago/Turabian StyleHuang, Ruixiao, Xiaofeng Fu, and Yifei Pu. 2023. "A Novel Fractional Accumulative Grey Model with GA-PSO Optimizer and Its Application" Sensors 23, no. 2: 636. https://doi.org/10.3390/s23020636
APA StyleHuang, R., Fu, X., & Pu, Y. (2023). A Novel Fractional Accumulative Grey Model with GA-PSO Optimizer and Its Application. Sensors, 23(2), 636. https://doi.org/10.3390/s23020636