

Deep Learning-Based Multiclass Brain Tissue Segmentation in Fetal MRIs

Abstract
:1. Introduction
2. Materials and Methods
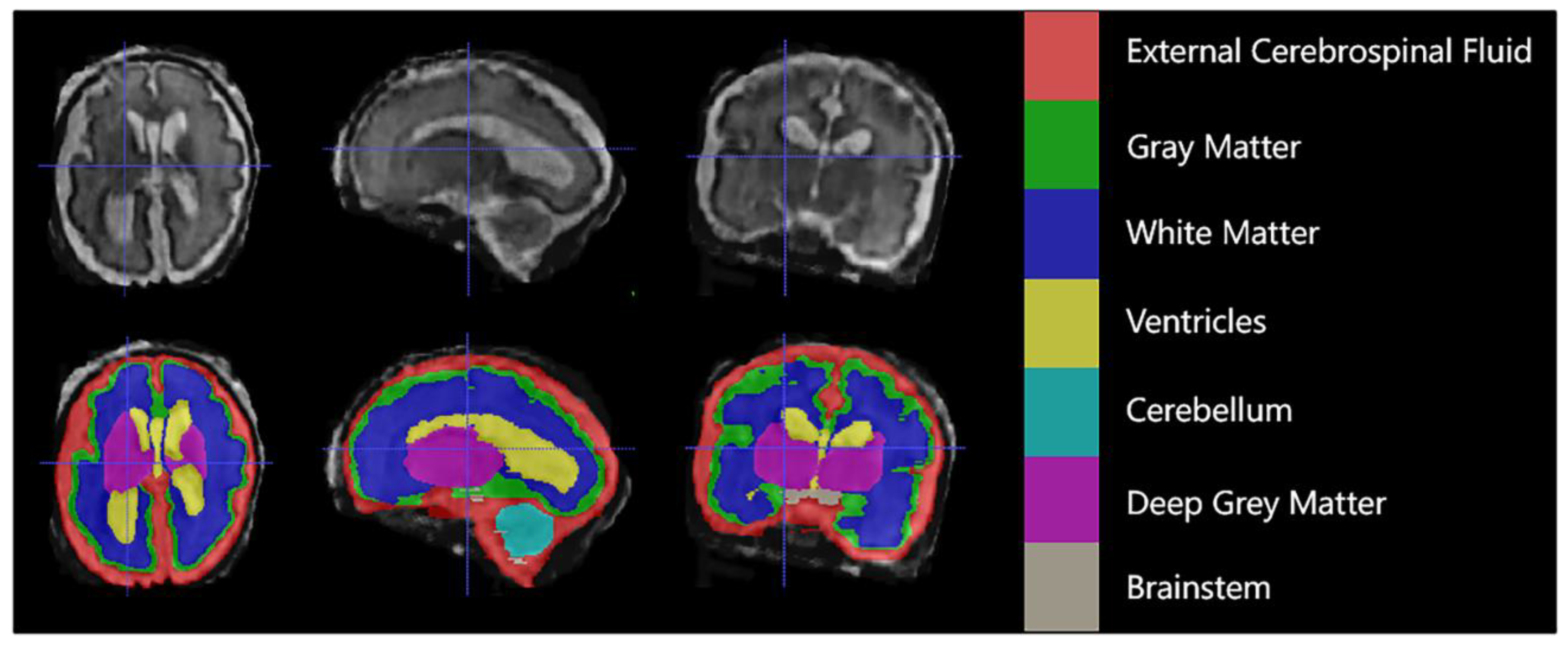
2.1. Fetal MRI Data
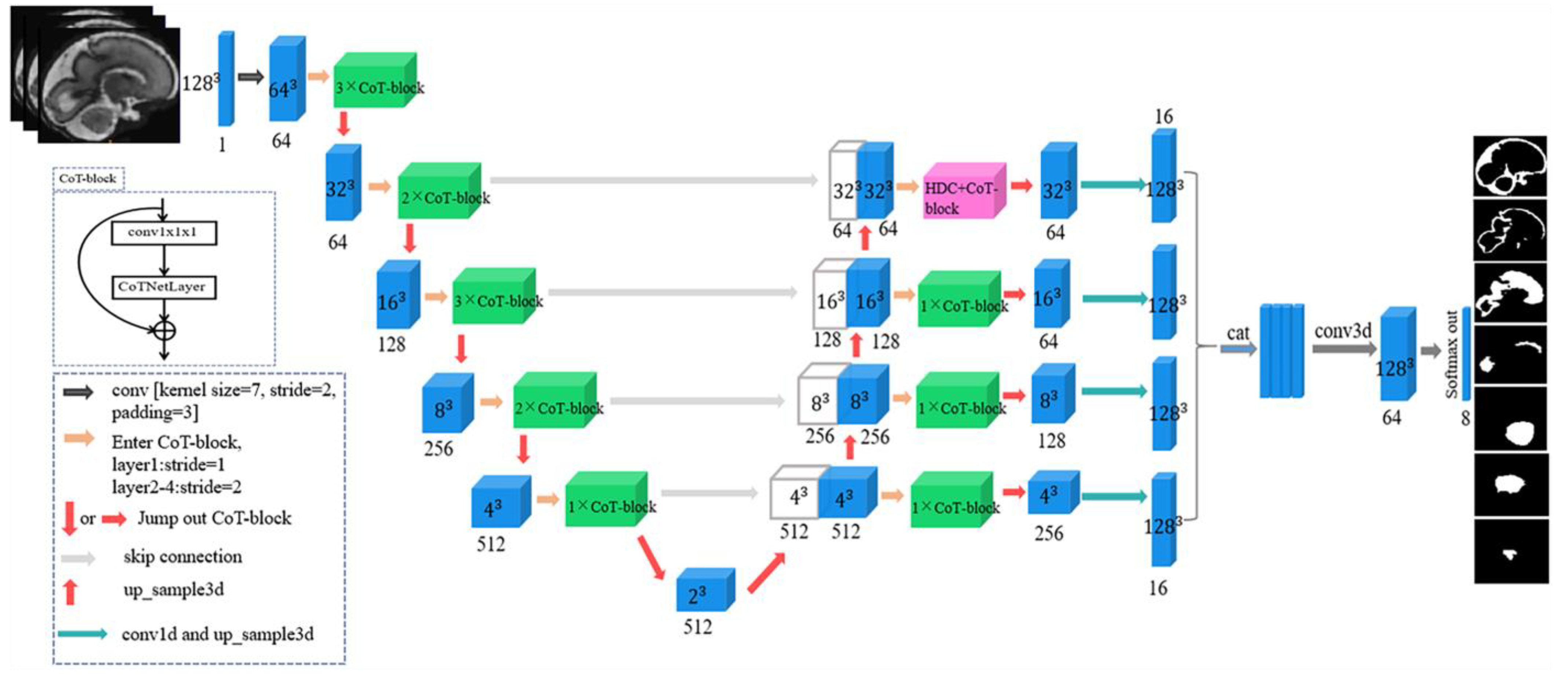
2.2. Model Architecture
2.2.1. Backbone Network
2.2.2. Hybrid Dilated Convolution
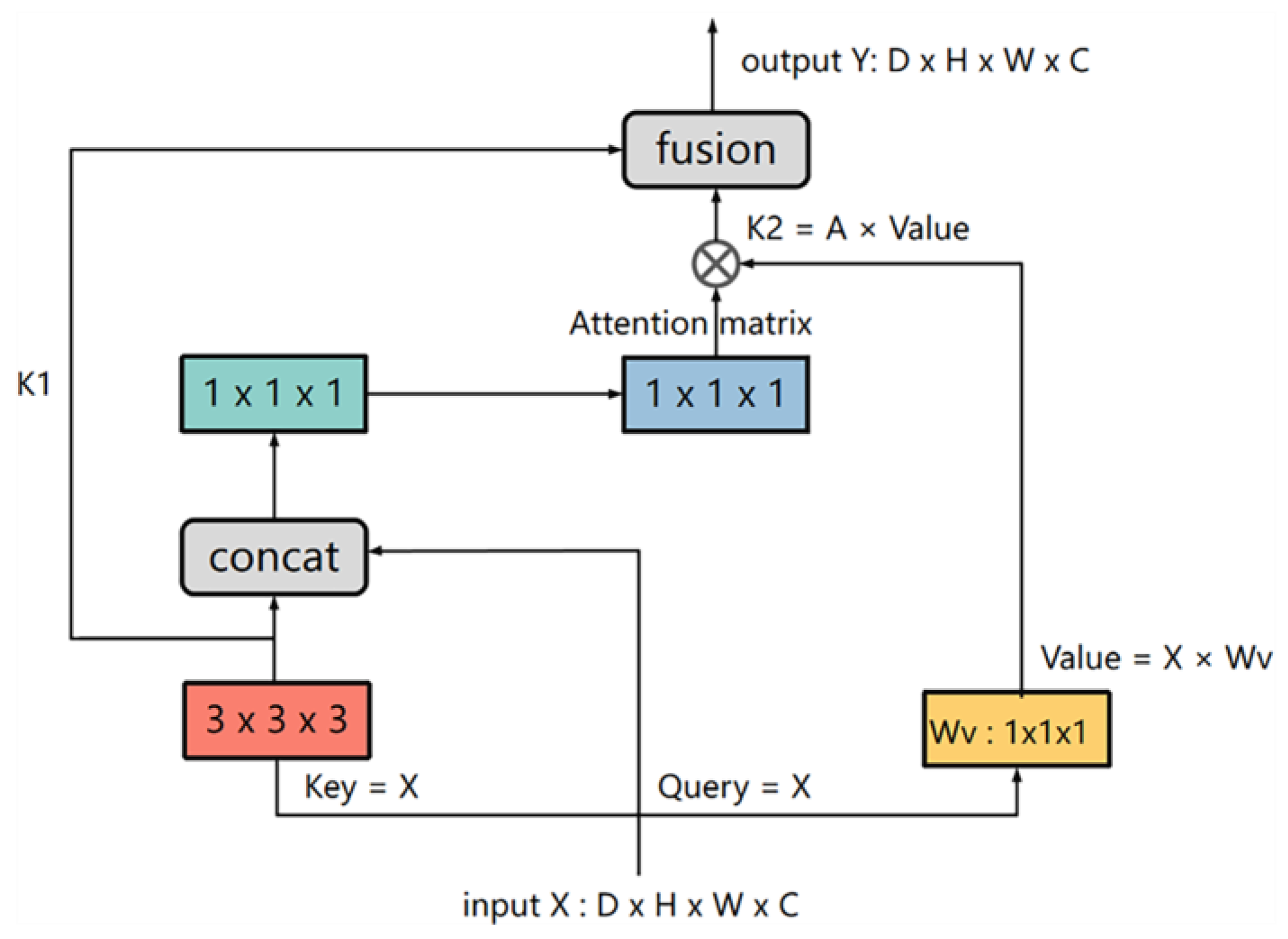
2.2.3. CoT-Block
2.3. Loss Function
2.4. Implementation and Training
2.5. Data Augmentation
3. Experiments and Results
3.1. Alternative Techniques
3.2. Gestational Age Analysis
3.3. Evaluation Metrics
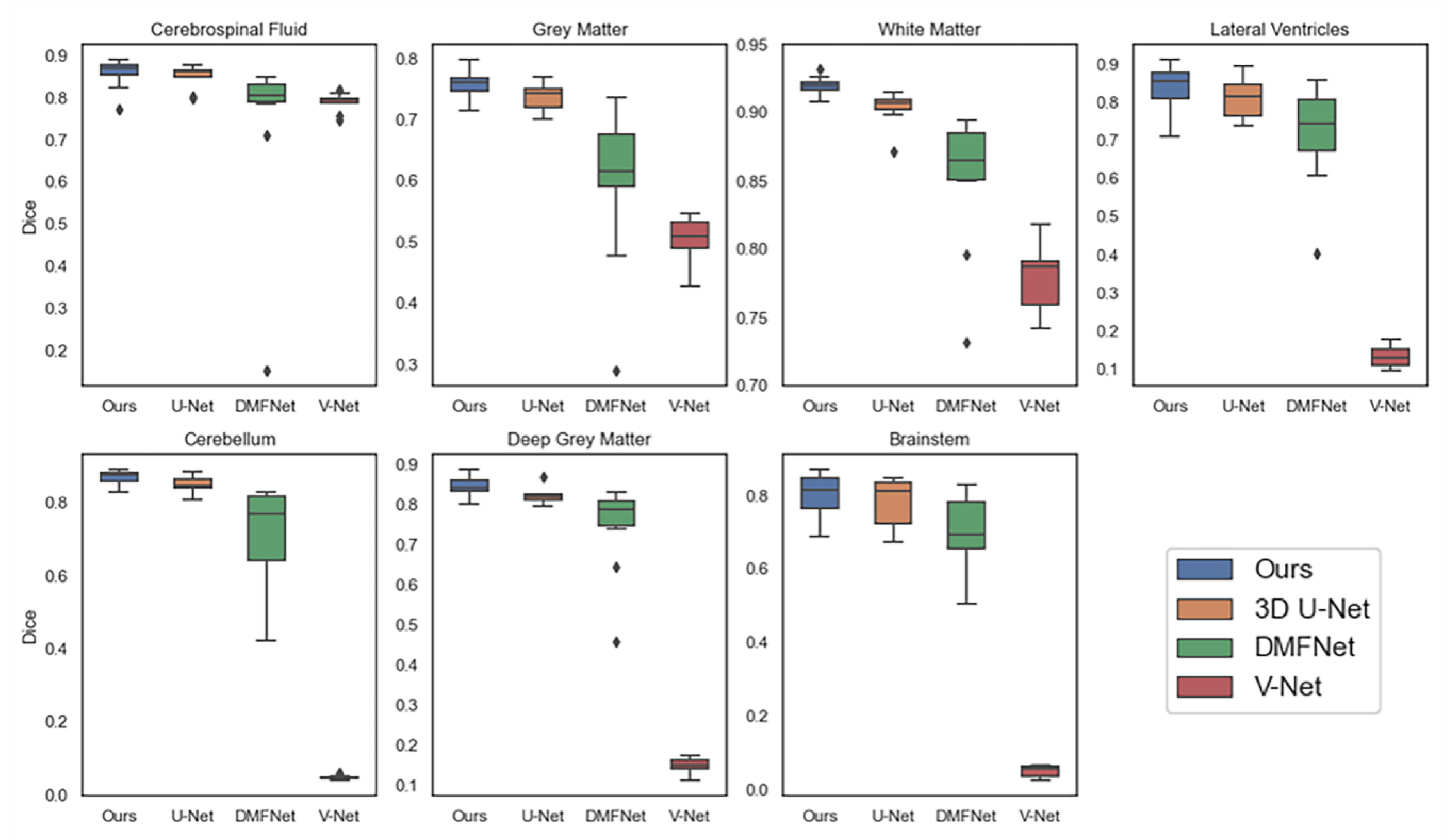
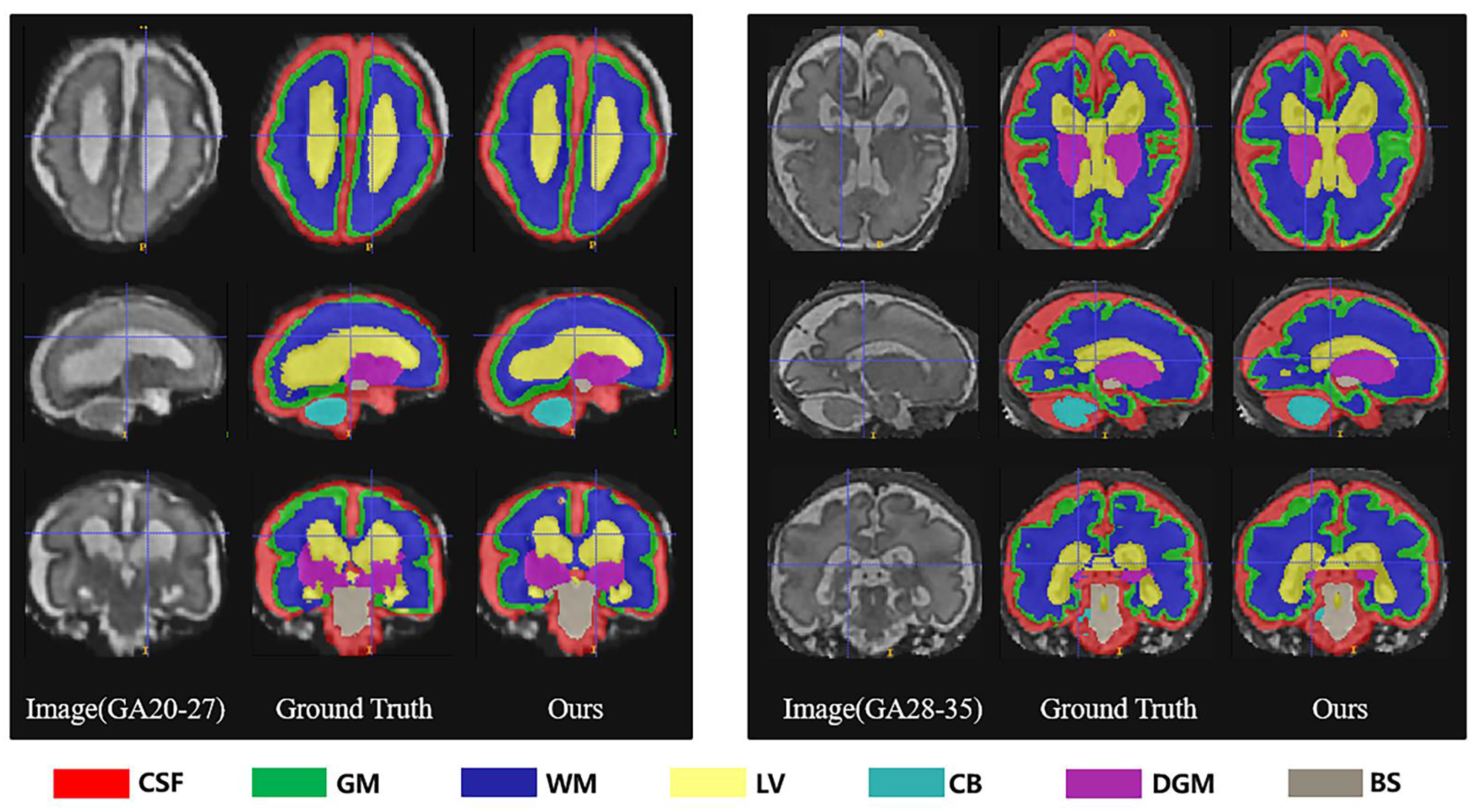
3.4. Evaluation Results
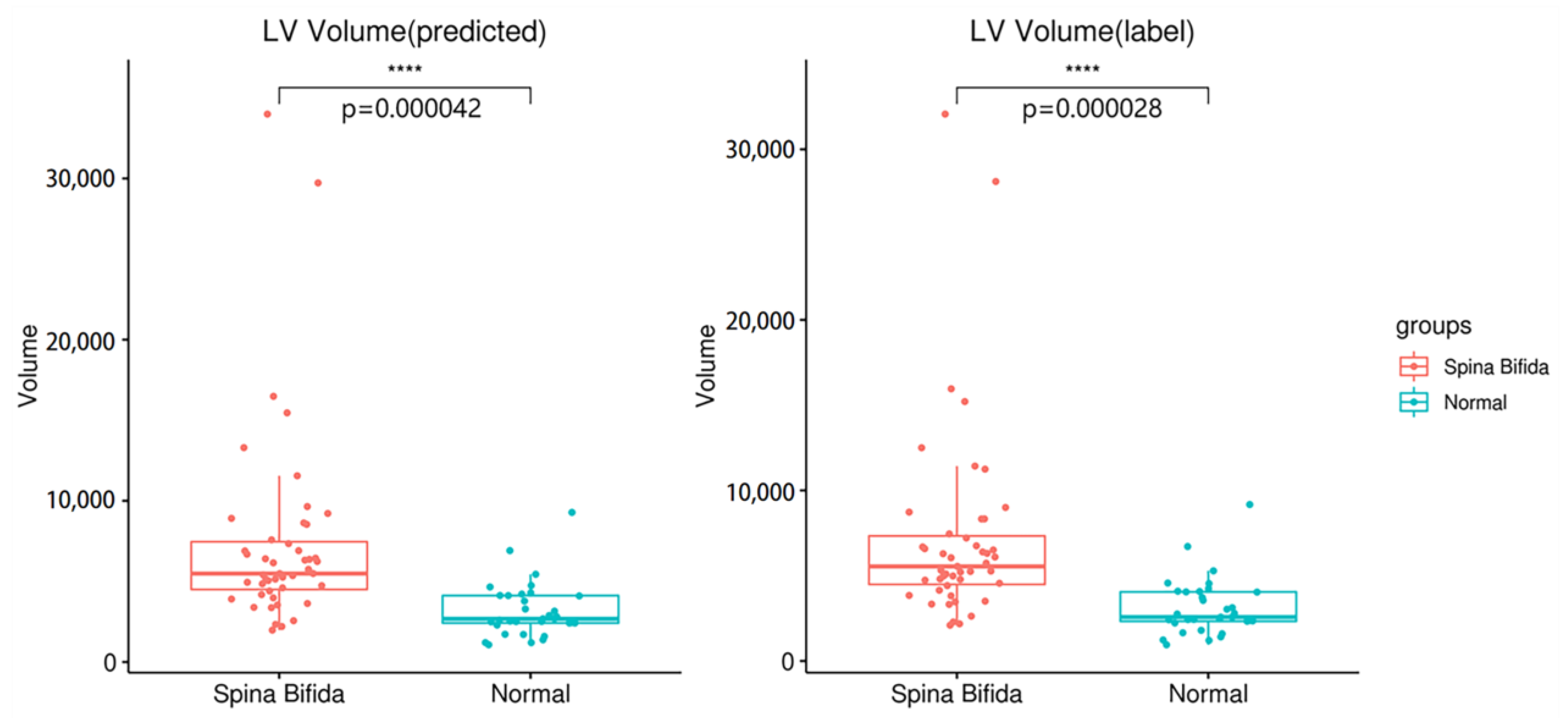
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gholipour, A.; Akhondi-Asl, A.; Estroff, J.A.; Warfield, S.K. Multi-Atlas Multi-Shape Segmentation of Fetal Brain MRI for Volumetric and Morphometric Analysis of Ventriculomegaly. NeuroImage 2012, 60, 1819–1831. [Google Scholar] [CrossRef] [Green Version]
- Payette, K.; Moehrlen, U.; Mazzone, L.; Ochsenbein-Kölble, N.; Tuura, R.; Kottke, R.; Meuli, M.; Jakab, A. Longitudinal Analysis of Fetal MRI in Patients with Prenatal Spina Bifida Repair. In Smart Ultrasound Imaging and Perinatal, Preterm and Paediatric Image Analysis; Springer: Cham, Switzerland, 2019; Volume 11798, pp. 161–170. [Google Scholar] [CrossRef] [Green Version]
- Payette, K.; Kottke, R.; Jakab, A. Efficient Multi-Class Fetal Brain Segmentation in High Resolution MRI Reconstructions with Noisy Labels. In Medical Ultrasound, and Preterm, Perinatal and Paediatric Image Analysis; Springer: Cham, Switzerland, 2020; Volume 12437, pp. 295–304. [Google Scholar] [CrossRef]
- Licht, D.J.; Wang, J.; Silvestre, D.W.; Nicolson, S.C.; Montenegro, L.M.; Wernovsky, G.; Tabbutt, S.; Durning, S.M.; Shera, D.M.; Gaynor, J.W.; et al. Preoperative Cerebral Blood Flow Is Diminished in Neonates with Severe Congenital Heart Defects. J. Thorac. Cardiovasc. Surg. 2004, 128, 841–849. [Google Scholar] [CrossRef] [Green Version]
- Lachmann, R.; Chaoui, R.; Moratalla, J.; Picciarelli, G.; Nicolaides, K.H. Posterior Brain in Fetuses with Open Spina Bifida at 11 to 13 Weeks: OPEN SPINA BIFIDA AT 11 TO 13 WEEKS. Prenat. Diagn. 2011, 31, 103–106. [Google Scholar] [CrossRef]
- Ghi, T.; Pilu, G.; Falco, P.; Segata, M.; Carletti, A.; Cocchi, G.; Santini, D.; Bonasoni, P.; Tani, G.; Rizzo, N. Prenatal Diagnosis of Open and Closed Spina Bifida. Ultrasound Obstet. Gynecol. 2006, 28, 899–903. [Google Scholar] [CrossRef]
- Habas, P.A.; Kim, K.; Rousseau, F.; Glenn, O.A.; Barkovich, A.J.; Studholme, C. Atlas-Based Segmentation of Developing Tissues in the Human Brain with Quantitative Validation in Young Fetuses. Hum. Brain Mapp. 2010, 31, 1348–1358. [Google Scholar] [CrossRef] [Green Version]
- Habas, P.A.; Kim, K.; Corbett-Detig, J.M.; Rousseau, F.; Glenn, O.A.; Barkovich, A.J.; Studholme, C. A Spatiotemporal Atlas of MR Intensity, Tissue Probability and Shape of the Fetal Brain with Application to Segmentation. NeuroImage 2010, 53, 460–470. [Google Scholar] [CrossRef] [Green Version]
- Serag, A.; Kyriakopoulou, V.; Rutherford, M.A.; Edwards, A.D.; Hajnal, J.V.; Aljabar, P.; Counsell, S.J.; Boardman, J.P.; Rueckert, D. A Multi-Channel 4D Probabilistic Atlas of the Developing Brain: Application to Fetuses and Neonates. Ann. BMVA 2012, 2012, 1–14. [Google Scholar]
- Wright, R.; Kyriakopoulou, V.; Ledig, C.; Rutherford, M.A.; Hajnal, J.V.; Rueckert, D.; Aljabar, P. Automatic Quantification of Normal Cortical Folding Patterns from Fetal Brain MRI. NeuroImage 2014, 91, 21–32. [Google Scholar] [CrossRef] [Green Version]
- Ledig, C.; Wright, R.; Serag, A.; Aljabar, P. Neonatal Brain Segmentation Using Second Order Neighborhood Information. In Proceedings of the Workshop on Perinatal and Paediatric Imaging: PaPI, Medical Image Computing and Computer-Assisted Intervention: MICCAI, Nice, France, 1–5 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 33–40. [Google Scholar]
- Li, S.; Sui, X.; Luo, X.; Xu, X.; Liu, Y.; Goh, R. Medical Image Segmentation Using Squeeze-and-Expansion Transformers. arXiv 2021, arXiv:2105.09511. [Google Scholar] [CrossRef]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context Encoder Network for 2D Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [Green Version]
- Dou, H.; Karimi, D.; Rollins, C.K.; Ortinau, C.M.; Vasung, L.; Velasco-Annis, C.; Ouaalam, A.; Yang, X.; Ni, D.; Gholipour, A. A Deep Attentive Convolutional Neural Network for Automatic Cortical Plate Segmentation in Fetal MRI. IEEE Trans. Med. Imaging 2021, 40, 1123–1133. [Google Scholar] [CrossRef]
- Lei, Z.; Qi, L.; Wei, Y.; Zhou, Y. Infant Brain MRI Segmentation with Dilated Convolution Pyramid Downsampling and Self-Attention. arXiv 2019, arXiv:1912.12570. [Google Scholar]
- Khalili, N.; Lessmann, N.; Turk, E.; Claessens, N.; de Heus, R.; Kolk, T.; Viergever, M.A.; Benders, M.J.N.L.; Išgum, I. Automatic Brain Tissue Segmentation in Fetal MRI Using Convolutional Neural Networks. Magn. Reson. Imaging 2019, 64, 77–89. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, A.; Khan, R.; Karayannis, T. Developing Brain Atlas through Deep Learning. Nat. Mach. Intell. 2019, 1, 277–287. [Google Scholar] [CrossRef] [Green Version]
- Payette, K.; de Dumast, P.; Kebiri, H.; Ezhov, I.; Paetzold, J.C.; Shit, S.; Iqbal, A.; Khan, R.; Kottke, R.; Grehten, P.; et al. An Automatic Multi-Tissue Human Fetal Brain Segmentation Benchmark Using the Fetal Tissue Annotation Dataset. Sci. Data 2021, 8, 167. [Google Scholar] [CrossRef]
- Tourbier, S.; Bresson, X.; Hagmann, P.; Thiran, J.-P.; Meuli, R.; Cuadra, M.B. An Efficient Total Variation Algorithm for Super-Resolution in Fetal Brain MRI with Adaptive Regularization. NeuroImage 2015, 118, 584–597. [Google Scholar] [CrossRef]
- Gholipour, A.; Warfield, S.K. Super-Resolution Reconstruction of Fetal Brain MRI. In Proceedings of the MICCAI Workshop on Image Analysis for the Developing Brain (IADB’ 2009), London, UK, 24 September 2009. [Google Scholar]
- Kuklisova-Murgasova, M.; Quaghebeur, G.; Rutherford, M.A.; Hajnal, J.V.; Schnabel, J.A. Reconstruction of Fetal Brain MRI with Intensity Matching and Complete Outlier Removal. Med. Image Anal. 2012, 16, 1550–1564. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–11. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. arXiv 2016, arXiv:1606.06650. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE Press: New York, NY, USA, 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Liu, X.; Ding, M.; Zheng, J.; Li, J. 3D Dilated Multi-Fiber Network for Real-Time Brain Tumor Segmentation in MRI. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; Volume 11766, pp. 184–192. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Hänsch, A.; Schwier, M.; Gass, T.; Morgas, T. Evaluation of Deep Learning Methods for Parotid Gland Segmentation from CT Images. J. Med. Imaging 2018, 6, 011005. [Google Scholar] [CrossRef] [Green Version]
- Huang, Q.; Sun, J.; Ding, H.; Wang, X.; Wang, G. Robust Liver Vessel Extraction Using 3D U-Net with Variant Dice Loss Function. Comput. Biol. Med. 2018, 101, 153–162. [Google Scholar] [CrossRef]
- An, L.; Zhang, P.; Adeli, E.; Wang, Y.; Ma, G.; Shi, F.; Lalush, D.S.; Lin, W.; Shen, D. Multi-Level Canonical Correlation Analysis for Standard-Dose PET Image Estimation. IEEE Trans. Image Process. 2016, 25, 3303–3315. [Google Scholar] [CrossRef]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. Multi-Fiber Networks for Video Recognition. In Proceedings of the 2018 Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 11205, pp. 364–380. [Google Scholar] [CrossRef] [Green Version]
- Prayer, D.; Kasprian, G.; Krampl, E.; Ulm, B.; Witzani, L.; Prayer, L.; Brugger, P.C. MRI of Normal Fetal Brain Development. Eur. J. Radiol. 2006, 57, 199–216. [Google Scholar] [CrossRef]
- Kinoshita, Y.; Okudera, T.; Tsuru, E.; Yokota, A. Volumetric Analysis of the Germinal Matrix and Lateral Ventricles Performed Using MR Images of Postmortem Fetuses. Am. J. Neuroradiol. 2001, 22, 382–388. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Metrics | eCSF | GM | WM | LV | CB | dGM | BS | |
|---|---|---|---|---|---|---|---|---|---|
| V-Net | DSC (%) | 64.32 2.45 | 32.36 4.63 | 80.89 2.30 | 8.87 3.35 | 5.44 1.75 | 9.76 3.12 | 4.57 1.49 | 29.46 2.73 |
| VS (%) | 72.66 2.59 | 21.75 11.83 | 88.32 3.09 | - | - | - | - | - | |
| HD95 (mm) | 22.69 3.17 | 25.86 2.44 | 26.81 2.35 | 37.17 1.53 | 53.482.61 | 43.02 4.53 | 48.263.50 | 36.76 2.88 | |
| PRE (%) | 69.64 2.37 | 88.298.20 | 83.81 4.40 | - | - | - | - | - | |
| SEN (%) | 77.45 1.52 | 13.09 7.85 | 93.49 3.24 | - | - | - | - | - | |
| SPC (%) | 97.73 0.63 | 99.900.09 | 97.74 0.71 | - | - | - | - | - | |
| DMFNet | DSC (%) | 73.59 2.3 | 59.73 7.05 | 85.21 3.47 | 74.28 5.40 | 73.05 4.11 | 76.05 2.55 | 69.79 4.89 | 73.10 4.25 |
| VS (%) | 74.10 2.12 | 60.87 6.94 | 85.68 3.48 | 75.67 4.74 | 74.05 3.85 | 76.79 2.63 | 71.10 4.60 | 74.04 3.77 | |
| HD95 (mm) | 21.33 1.69 | 23.71 1.29 | 25.331.17 | 35.35 1.93 | 54.79 2.92 | 41.03 1.34 | 49.26 3.69 | 35.83 2.00 | |
| PRE (%) | 73.76 3.62 | 62.04 9.47 | 84.41 4.79 | 74.84 7.3 | 82.31 6.99 | 80.47 8.64 | 70.66 8.1 | 75.50 6.99 | |
| SEN (%) | 75.67 2.90 | 60.22 6.18 | 87.19 3.86 | 79.39 5.95 | 70.79 8.08 | 78.13 9.28 | 75.77 5.31 | 75.31 5.94 | |
| SPC (%) | 97.41 0.39 | 98.12 0.44 | 97.96 0.83 | 99.56 0.09 | 99.87 0.05 | 99.73 0.12 | 99.80 0.07 | 98.92 0.28 | |
| 3D U-Net | DSC (%) | 80.19 2.83 | 69.04 4.96 | 89.942.48 | 85.54 4.21 | 82.50 4.47 | 85.043.35 | 78.08 4.89 | 81.48 3.88 |
| VS (%) | 80.43 2.84 | 69.41 4.01 | 90.152.47 | 86.27 6.86 | 83.97 4.54 | 85.783.36 | 80.10 4.46 | 82.30 4.08 | |
| HD95 (mm) | 22.56 3.20 | 24.80 1.44 | 26.48 1.40 | 35.48 2.13 | 56.80 4.28 | 40.122.40 | 51.77 3.80 | 36.06 2.66 | |
| PRE (%) | 82.06 2.90 | 67.87 3.03 | 89.36 4.46 | 83.77 8.41 | 82.02 1.56 | 91.283.75 | 78.09 8.94 | 82.06 4.72 | |
| SEN (%) | 79.18 2.36 | 71.48 6.90 | 91.102.02 | 89.045.13 | 89.2910.6 | 81.40 7.06 | 83.58 6.64 | 83.58 5.82 | |
| SPC (%) | 98.570.78 | 98.54 0.43 | 98.80 0.64 | 99.71 0.09 | 99.87 0.14 | 99.870.07 | 99.900.03 | 99.32 0.31 | |
| Ours | DSC (%) | 85.493.16 | 71.204.87 | 89.73 1.73 | 86.384.78 | 85.754.42 | 84.64 2.91 | 83.311.62 | 83.793.36 |
| VS (%) | 85.883.13 | 72.014.84 | 90.06 1.70 | 87.224.52 | 87.654.17 | 85.53 2.97 | 85.561.26 | 84.843.23 | |
| HD95 (mm) | 20.791.77 | 23.671.52 | 25.38 1.41 | 34.001.84 | 54.91 2.92 | 41.51 1.34 | 49.34 3.69 | 35.662.07 | |
| PRE (%) | 85.584.03 | 72.34 3.39 | 90.412.95 | 88.764.25 | 91.830.98 | 84.65 4.88 | 86.525.75 | 85.733.75 | |
| SEN (%) | 86.232.70 | 71.846.74 | 89.84 2.63 | 85.90 6.23 | 84.20 7.53 | 87.046.34 | 85.194.34 | 84.325.22 | |
| SPC (%) | 98.26 0.36 | 98.64 0.16 | 98.950.28 | 99.750.14 | 99.950.02 | 99.82 0.05 | 99.93 0.02 | 99.330.15 |
| Method | Param (M) | FLOPs (G) |
|---|---|---|
| V-Net | 45.63 | 809.78 |
| DMFNet | 3.87 | 26.92 |
| 3D U-Net | 90.3 | 2128.3 |
| Ours | 66.09 | 299.24 |
| GA | Metrics | eCSF | GM | WM | LV | CB | dGM | BS | |
|---|---|---|---|---|---|---|---|---|---|
| 20–27 | DSC (%) | 87.49 8.31 | 83.61 1.29 | 95.66 0.43 | 90.59 3.29 | 92.13 0.29 | 94.37 0.50 | 85.30 2.79 | 89.88 2.41 |
| VS (%) | 89.05 6.94 | 85.46 1.24 | 96.18 0.40 | 91.82 2.72 | 94.08 0.31 | 95.44 0.49 | 89.00 1.78 | 91.58 1.98 | |
| HD95 (mm) | 22.64 3.08 | 22.91 1.38 | 24.39 1.52 | 33.52 2.03 | 55.97 2.55 | 40.82 1.58 | 52.54 3.18 | 36.11 2.19 | |
| PRE (%) | 91.48 3.32 | 85.78 0.81 | 96.26 0.30 | 90.72 2.62 | 94.58 0.71 | 96.23 0.92 | 89.36 0.74 | 92.06 1.35 | |
| SEN (%) | 87.01 0.10 | 85.14 1.82 | 96.11 0.51 | 92.94 2.88 | 93.59 0.84 | 94.68 0.27 | 88.67 2.79 | 91.16 1.32 | |
| SPC (%) | 99.44 0.35 | 99.43 0.05 | 99.45 0.19 | 99.77 0.14 | 99.96 0.01 | 99.94 0.01 | 99.96 0.01 | 99.71 0.11 | |
| 28–35 | DSC (%) | 92.04 0.88 | 76.41 3.86 | 94.68 0.70 | 77.98 3.93 | 93.09 0.68 | 94.27 0.61 | 87.17 1.68 | 87.95 1.76 |
| VS (%) | 92.78 0.87 | 78.38 3.56 | 95.23 0.65 | 81.35 3.55 | 94.70 0.70 | 95.38 0.59 | 90.59 1.56 | 89.77 1.64 | |
| HD95 (mm) | 20.50 1.83 | 23.47 1.36 | 24.69 1.35 | 37.26 2.43 | 53.71 1.96 | 39.77 1.65 | 50.94 2.82 | 35.76 1.91 | |
| PRE (%) | 92.73 0.01 | 79.43 3.15 | 95.00 0.84 | 80.97 5.37 | 95.14 0.53 | 95.64 0.39 | 90.51 1.77 | 89.92 1.72 | |
| SEN (%) | 92.83 0.76 | 77.37 3.99 | 95.45 0.52 | 81.85 1.79 | 94.27 1.30 | 95.14 1.31 | 90.68 1.87 | 89.66 1.65 | |
| SPC (%) | 99.05 0.08 | 99.12 0.16 | 99.30 0.11 | 99.91 0.02 | 99.95 0.01 | 99.92 0.01 | 99.96 0.01 | 99.60 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Liu, Y.; Li, Y.; Qi, K.; Gao, A.; Zheng, B.; Liang, D.; Long, X. Deep Learning-Based Multiclass Brain Tissue Segmentation in Fetal MRIs. Sensors 2023, 23, 655. https://doi.org/10.3390/s23020655
Huang X, Liu Y, Li Y, Qi K, Gao A, Zheng B, Liang D, Long X. Deep Learning-Based Multiclass Brain Tissue Segmentation in Fetal MRIs. Sensors. 2023; 23(2):655. https://doi.org/10.3390/s23020655
Chicago/Turabian StyleHuang, Xiaona, Yang Liu, Yuhan Li, Keying Qi, Ang Gao, Bowen Zheng, Dong Liang, and Xiaojing Long. 2023. "Deep Learning-Based Multiclass Brain Tissue Segmentation in Fetal MRIs" Sensors 23, no. 2: 655. https://doi.org/10.3390/s23020655
APA StyleHuang, X., Liu, Y., Li, Y., Qi, K., Gao, A., Zheng, B., Liang, D., & Long, X. (2023). Deep Learning-Based Multiclass Brain Tissue Segmentation in Fetal MRIs. Sensors, 23(2), 655. https://doi.org/10.3390/s23020655