
KD-Net: Continuous-Keystroke-Dynamics-Based Human Identification from RGB-D Image Sequences




Abstract
:1. Introduction
- We explored a novel visual modality of keystroke dynamics for human identification from RGB-D image sequences captured by a single RGB-D sensor.
- We created a novel dataset dubbed KD-MultiModal (RGB/depth images of keystroke dynamics) that contains 243.2 K frames of RGB images and depth images, obtained by recording a video of hand typing via an Azure Kinect. We will make the dataset public when the paper is published to facilitate related studies.
- We trained a deep neural network to verify the proposed modality of keystroke biometrics.
2. Related Work
2.1. Keystroke Dynamics
2.2. Hand Gesture Recognitions
3. Methodology
3.1. Proposed Dataset
3.1.1. Hardware Setup and Data Acquisition
3.1.2. Data Preprocessing
RGB Image Preprocessing
Depth Image Preprocessing
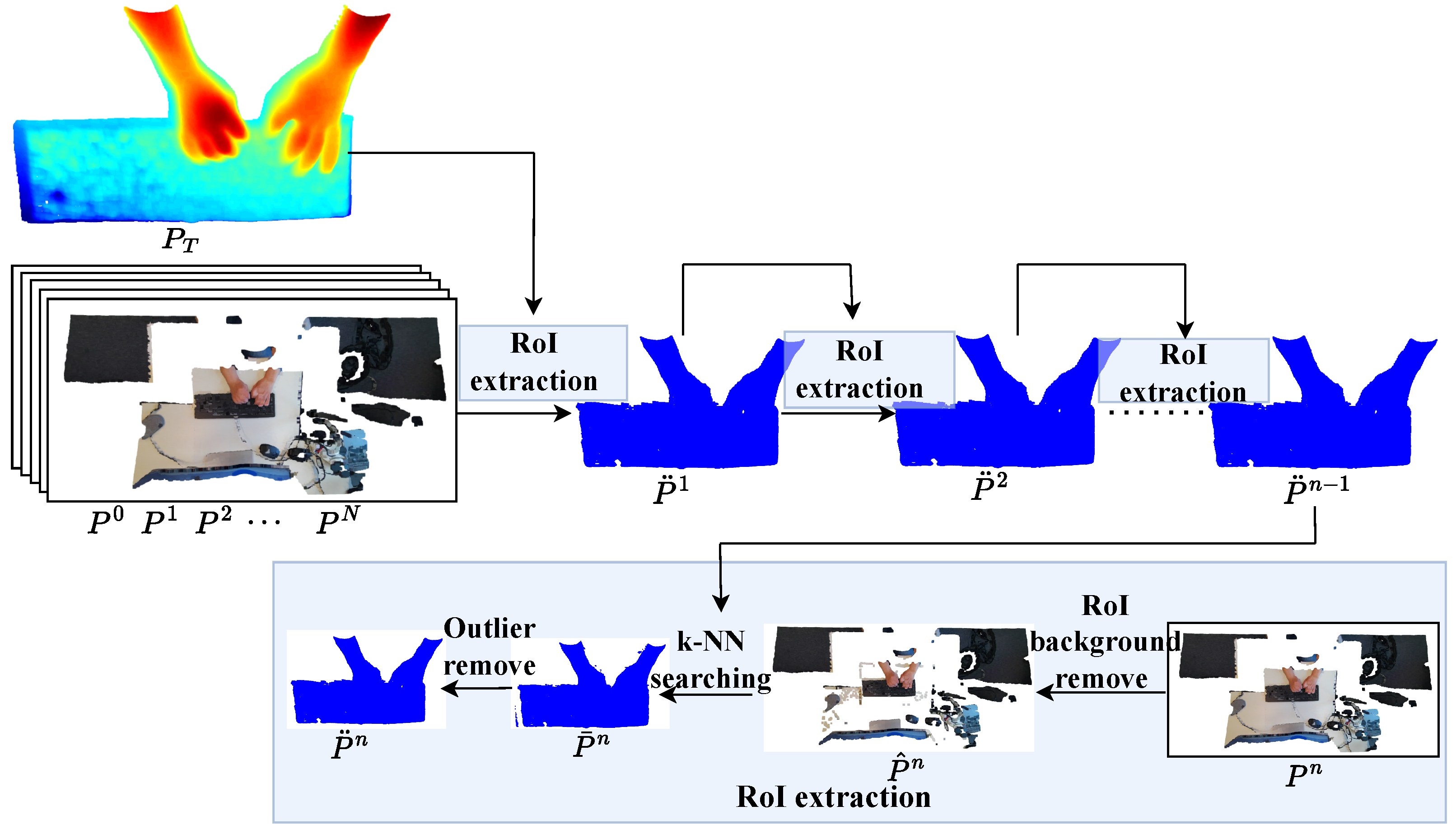
Point Cloud Preprocessing
3.2. Human Identification from Visual Keystroke Dynamics
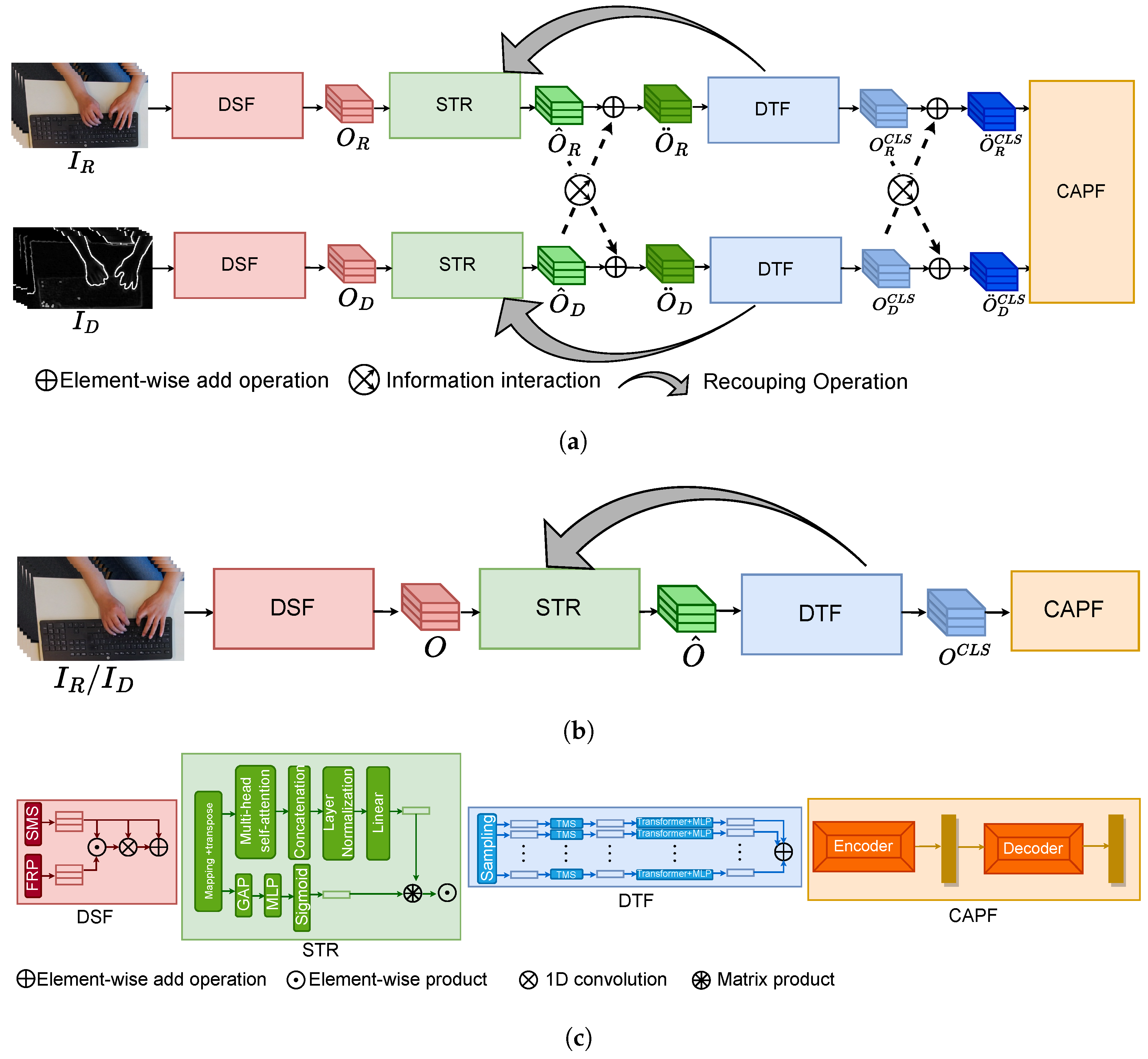
3.2.1. Decoupling Spatiotemporal Feature Module
3.2.2. Spatiotemporal Recoupling Module
3.2.3. Cross-Modal Interactive Learning
3.2.4. Experimental Strategy
3.2.5. Loss Functions
4. Results
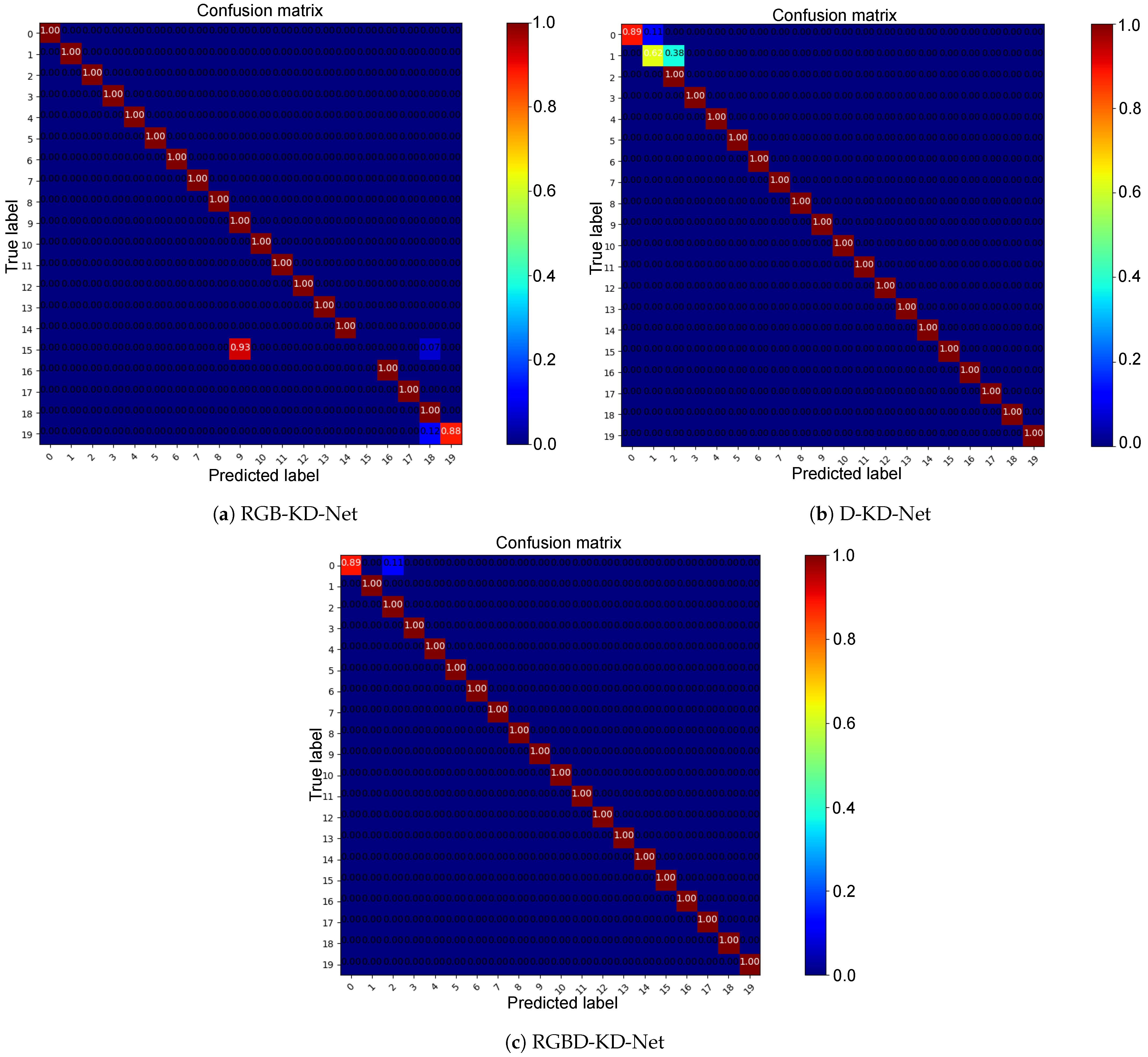
4.1. Self-Comparison
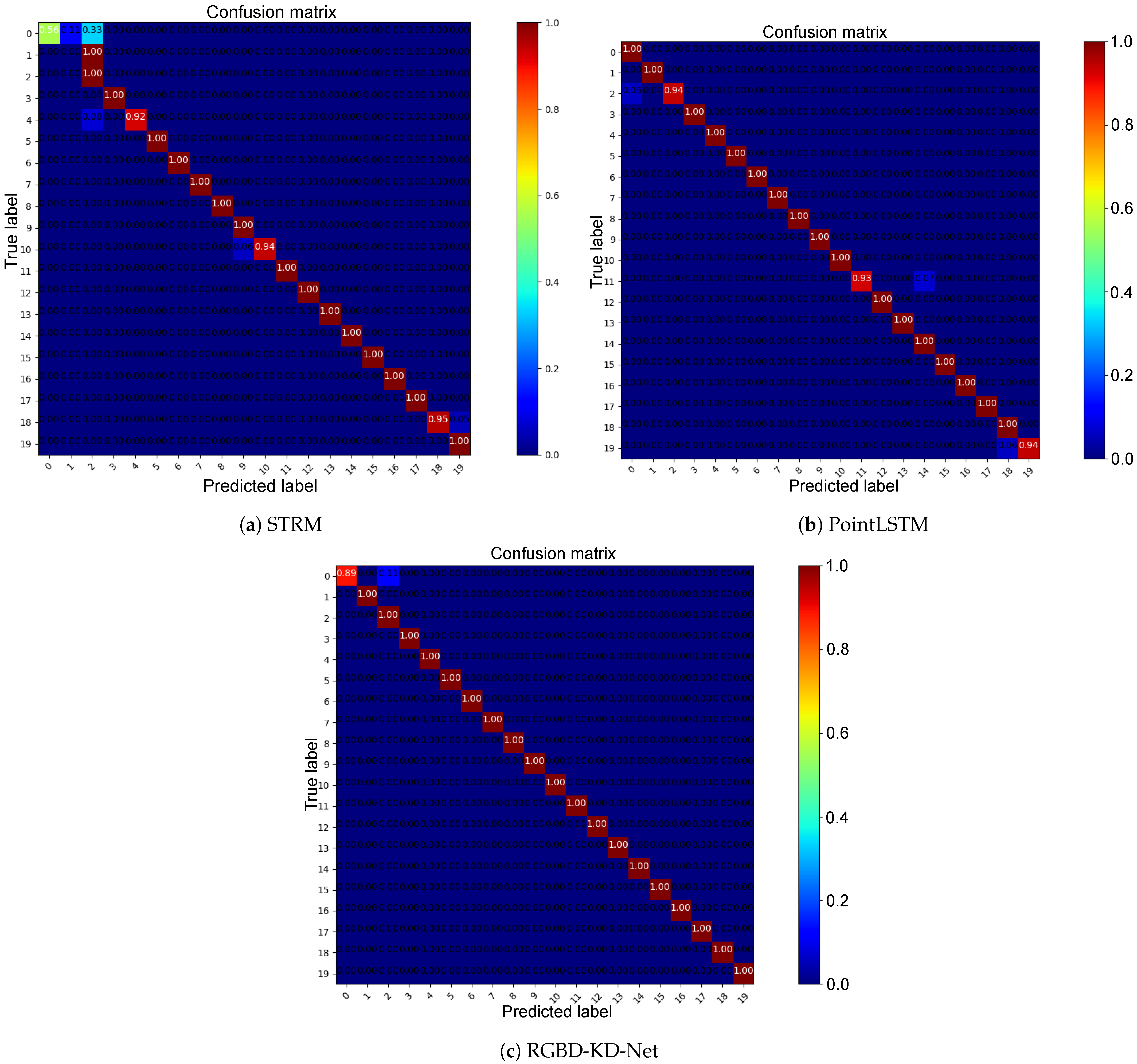
4.2. State-of-the-Art Comparison
4.3. Evaluation of the Number of Frames
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, A.; Gao, S.; Chen, J.; Xu, L.; Nathan, A. High security user authentication enabled by piezoelectric keystroke dynamics and machine learning. IEEE Sens. J. 2020, 20, 13037–13046. [Google Scholar] [CrossRef]
- Kiyani, A.T.; Lasebae, A.; Ali, K.; Rehman, M.U.; Haq, B. Continuous user authentication featuring keystroke dynamics based on robust recurrent confidence model and ensemble learning approach. IEEE Access 2020, 8, 156177–156189. [Google Scholar] [CrossRef]
- Kim, J.; Kang, P. Freely typed keystroke dynamics-based user authentication for mobile devices based on heterogeneous features. Pattern Recognit. 2020, 108, 107556. [Google Scholar] [CrossRef]
- Tsai, C.J.; Huang, P.H. Keyword-based approach for recognizing fraudulent messages by keystroke dynamics. Pattern Recognit. 2020, 98, 107067. [Google Scholar] [CrossRef]
- Kasprowski, P.; Borowska, Z.; Harezlak, K. Biometric identification based on keystroke dynamics. Sensors 2022, 22, 3158. [Google Scholar] [CrossRef]
- Bilan, S.; Bilan, M.; Bilan, A. Interactive biometric identification system based on the keystroke dynamic. In Biometric Identification Technologies Based on Modern Data Mining Methods; Springer: Berlin/Heidelberg, Germany, 2021; pp. 39–58. [Google Scholar]
- Gupta, S.; Maple, C.; Crispo, B.; Raja, K.; Yautsiukhin, A.; Martinelli, F. A Survey of Human-Computer Interaction (HCI) & Natural Habits-based Behavioural Biometric Modalities for User Recognition Schemes. Pattern Recog. 2023, 139, 109453. [Google Scholar]
- Morales, A.; Fierrez, J.; Tolosana, R.; Ortega-Garcia, J.; Galbally, J.; Gomez-Barrero, M.; Anjos, A.; Marcel, S. Keystroke biometrics ongoing competition. IEEE Access 2016, 4, 7736–7746. [Google Scholar] [CrossRef]
- Acien, A.; Morales, A.; Monaco, J.V.; Vera-Rodriguez, R.; Fierrez, J. TypeNet: Deep learning keystroke biometrics. IEEE Trans. Biom. Behav. Identity Sci. 2021, 4, 57–70. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Traore, I. Biometric recognition based on free text keystroke dynamics. IEEE Trans. Cybern. 2013, 44, 458–472. [Google Scholar] [CrossRef] [PubMed]
- Acien, A.; Morales, A.; Vera-Rodriguez, R.; Fierrez, J. Keystroke mobile authentication: Performance of long-term approaches and fusion with behavioral profiling. In Proceedings of the Pattern Recognition and Image Analysis: 9th Iberian Conference, IbPRIA 2019, Madrid, Spain, 1–4 July 2019; pp. 12–24. [Google Scholar]
- Hassan, B.; Izquierdo, E.; Piatrik, T. Soft biometrics: A survey: Benchmark analysis, open challenges and recommendations. Multimed. Tools Appl. 2021, 1–44. [Google Scholar] [CrossRef]
- Karouni, A.; Daya, B.; Bahlak, S. Offline signature recognition using neural networks approach. Procedia Comput. Sci. 2011, 3, 155–161. [Google Scholar] [CrossRef]
- Rasnayaka, S.; Sim, T. Action Invariant IMU-Gait for Continuous Authentication. In Proceedings of the 2022 IEEE International Joint Conference on Biometrics (IJCB), Abu Dhabi, United Arab Emirates, 10–13 October 2022; pp. 1–10. [Google Scholar]
- Mondal, S.; Bours, P. Person identification by keystroke dynamics using pairwise user coupling. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1319–1329. [Google Scholar] [CrossRef]
- Zhu, C.; Liu, H.; Yu, Z.; Sun, X. Towards omni-supervised face alignment for large scale unlabeled videos. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13090–13097. [Google Scholar]
- Jiang, B.; Wang, M.; Gan, W.; Wu, W.; Yan, J. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 2000–2009. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Chang, H.C.; Li, J.; Wu, C.S.; Stamp, M. Machine Learning and Deep Learning for Fixed-Text Keystroke Dynamics. In Artificial Intelligence for Cybersecurity; Springer: Berlin/Heidelberg, Germany, 2022; pp. 309–329. [Google Scholar]
- Ali, M.L.; Thakur, K.; Tappert, C.C.; Qiu, M. Keystroke biometric user verification using Hidden Markov Model. In Proceedings of the 2016 IEEE 3rd International Conference on Cyber Security and Cloud Computing (CSCloud), Beijing, China, 25–27 June 2016; pp. 204–209. [Google Scholar]
- Murphy, C.; Huang, J.; Hou, D.; Schuckers, S. Shared dataset on natural human-computer interaction to support continuous authentication research. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 525–530. [Google Scholar]
- Monaco, J.V.; Tappert, C.C. The partially observable hidden Markov model and its application to keystroke dynamics. Pattern Recognit. 2018, 76, 449–462. [Google Scholar] [CrossRef]
- Abavisani, M.; Joze, H.R.V.; Patel, V.M. Improving the performance of unimodal dynamic hand-gesture recognition with multimodal training. In Proceedings of the EEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1165–1174. [Google Scholar]
- D’Eusanio, A.; Simoni, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. A transformer-based network for dynamic hand gesture recognition. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 623–632. [Google Scholar]
- Yu, Z.; Zhou, B.; Wan, J.; Wang, P.; Chen, H.; Liu, X.; Li, S.Z.; Zhao, G. Searching multi-rate and multi-modal temporal enhanced networks for gesture recognition. IEEE Trans. Image Process. 2021, 30, 5626–5640. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Wang, P.; Wan, J.; Liang, Y.; Wang, F.; Zhang, D.; Lei, Z.; Li, H.; Jin, R. Decoupling and recoupling spatiotemporal representation for RGB-D-based motion recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20154–20163. [Google Scholar]
- Min, Y.; Zhang, Y.; Chai, X.; Chen, X. An efficient pointlstm for point clouds based gesture recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5761–5770. [Google Scholar]
- Min, Y.; Chai, X.; Zhao, L.; Chen, X. FlickerNet: Adaptive 3D Gesture Recognition from Sparse Point Clouds. In Proceedings of the BMVC, Cardiff, UK, 9–12 September 2019; Volume 2, p. 5. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 1 January 2004).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 ×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Thatipelli, A.; Narayan, S.; Khan, S.; Anwer, R.M.; Khan, F.S.; Ghanem, B. Spatio-temporal relation modeling for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19958–19967. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy (%) |
|---|---|
| RGB-KD-Net | 94.41 |
| D-KD-Net | 97.57 |
| RGBD-KD-Net | 99.44 |
| Method | Accuracy (%) |
|---|---|
| STRM [32] | 91.85 |
| PointLSTM [27] | 98.00 |
| RGBD-KD-Net | 99.44 |
| Number of Frames | Accuracy (%) | Training Time (h) | Inferencetime (s) |
|---|---|---|---|
| 4 | 93.04 | 15.5 | 1.8 |
| 8 | 97.32 | 25.5 | 1.9 |
| 16 | 99.44 | 33.5 | 2.2 |
| 32 | 97.91 | 47.5 | 2.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, X.; Zhao, R.; Hu, P.; Munteanu, A. KD-Net: Continuous-Keystroke-Dynamics-Based Human Identification from RGB-D Image Sequences. Sensors 2023, 23, 8370. https://doi.org/10.3390/s23208370
Dai X, Zhao R, Hu P, Munteanu A. KD-Net: Continuous-Keystroke-Dynamics-Based Human Identification from RGB-D Image Sequences. Sensors. 2023; 23(20):8370. https://doi.org/10.3390/s23208370
Chicago/Turabian StyleDai, Xinxin, Ran Zhao, Pengpeng Hu, and Adrian Munteanu. 2023. "KD-Net: Continuous-Keystroke-Dynamics-Based Human Identification from RGB-D Image Sequences" Sensors 23, no. 20: 8370. https://doi.org/10.3390/s23208370
APA StyleDai, X., Zhao, R., Hu, P., & Munteanu, A. (2023). KD-Net: Continuous-Keystroke-Dynamics-Based Human Identification from RGB-D Image Sequences. Sensors, 23(20), 8370. https://doi.org/10.3390/s23208370