


Comparing Three Methods of Selecting Training Samples in Supervised Classification of Multispectral Remote Sensing Images

Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Image Data
3.2. Classification Models
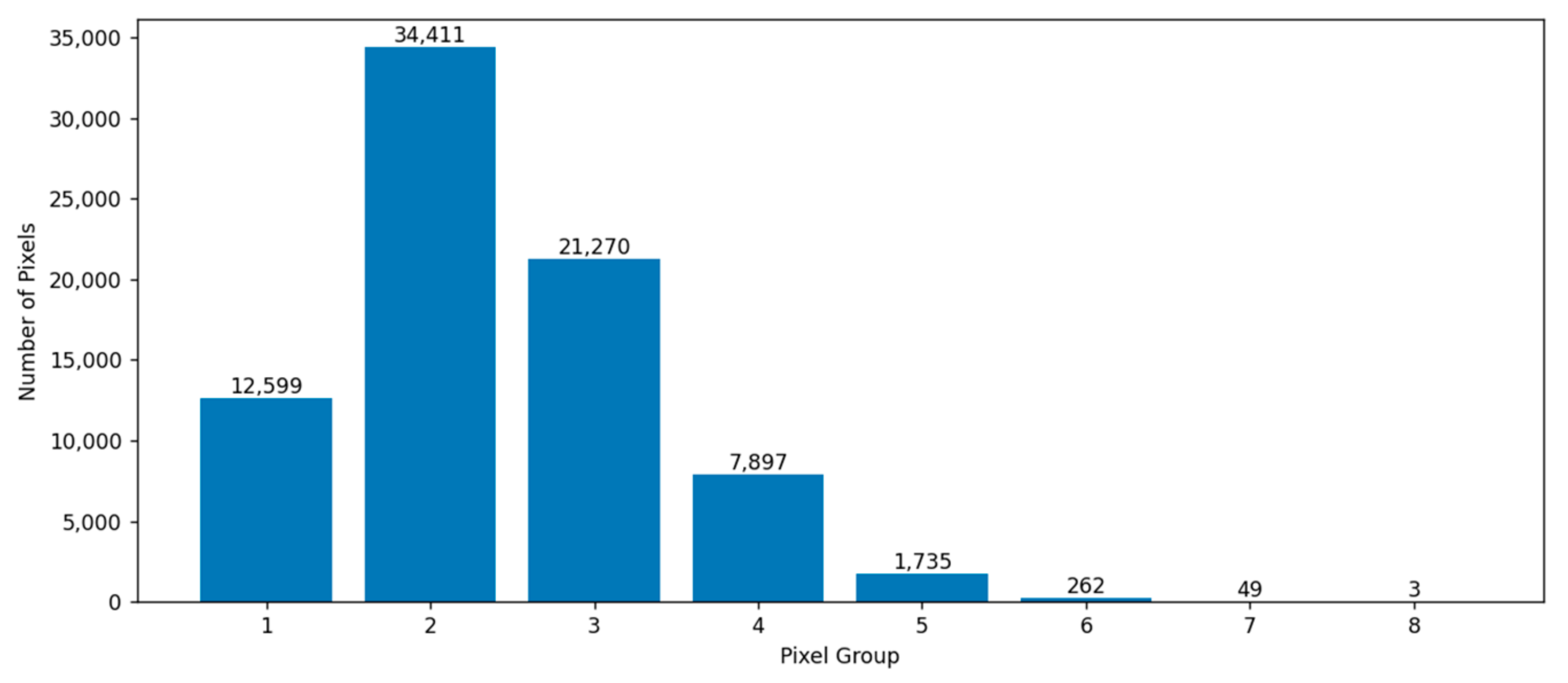
3.3. Sample Selection Method
3.3.1. Group-Based Selection Method
3.3.2. The Selection Method Based on “Entropy”
3.3.3. Direct Sampling Method
4. Experiments
4.1. Experimental Steps
4.1.1. Selecting Training Samples
4.1.2. Selecting Model Parameters
4.2. Analysis of Experimental Results
5. Conclusions and Outlook
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xi, J.; Ersoy Okan, K.; Cong, M.; Zhao, C.; Qu, W.; Wu, T. Dynamic Wide and Deep Neural Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 2575. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Yang, F.; Zhou, G.Q.; Xiao, J.R.; Li, Q.; Jia, B.; Wang, H.Y.; Gao, J. Multispectral remote sensing image classification based on quantum entanglement. Remote Sens. Spat. Inf. Sci. 2020, 42, 667–670. [Google Scholar] [CrossRef]
- Geiß, C.; Pelizari, P.A.; Blickensdörfer, L.; Taubenböck, H. Virtual Support Vector Machines with self-learning strategy for classification of multispectral remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2019, 151, 42–48. [Google Scholar] [CrossRef]
- Li, H.; Zhang, S.; Zhang, C.; Li, P.; Cropp, R. A novel unsupervised Levy flight particle swarm optimization (ULPSO) method for multispectral remote-sensing image classification. Int. J. Remote Sens. 2017, 38, 6970–6992. [Google Scholar] [CrossRef]
- Wieland, W.; Pittore, M. Performance Evaluation of Machine Learning Algorithms for Urban Pattern Recognition from Multi-spectral Satellite Images. Remote Sens. 2014, 6, 2912–2939. [Google Scholar] [CrossRef]
- Shivam, P.; Biplab, B. Self-supervision assisted multimodal remote sensing image classification with coupled self-looping convolution networks. Neural Netw. 2023, 164, 1–20. [Google Scholar]
- Tarabalka, Y.; Fauvel, M.; Chanussot, J.; Benediktsson, J.A. SVM- and MRF-Based Method for Accurate Classification of Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 736–740. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised hyperspectral image classification using soft sparse multinomial logistic regression. IEEE Geosci. Remote Sens. Lett. 2012, 10, 318–322. [Google Scholar]
- Tu, B.; Zhang, X.; Zhang, G.; Wang, J.; Zhou, Y. Hyperspectral image classification via recursive filtering and KNN. Remote Sens. Land Resour. 2019, 31, 22–23. [Google Scholar]
- Millard, K.; Richardson, M. On the Importance of Training Data Sample Selection in Random Forest Image Classification: A Case Study in Peatland Ecosystem Mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar] [CrossRef]
- Zhen, Z.; Quakenbush, L.; Stehman, S.; Zhang, L. Impact of training and validation sample selection on classification accuracy assessment when using reference polygons in object-based classification. Remote Sens. 2013, 34, 6914–6930. [Google Scholar] [CrossRef]
- Corcoran, J.; Knight, J.; Pelletier, K.; Rampi, L.; Wang, Y. The effects of point or polygon based training data on RandomForest classification accuracy of wetlands. Remote Sens. 2015, 7, 4002–4025. [Google Scholar] [CrossRef]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2017, 204, 648–658. [Google Scholar] [CrossRef]
- Shang, M.; Wang, S.; Zhou, Y.; Du, C. Effects of Training Samples and Classifiers on Classification of Landsat-8 Imagery. J. Indian Soc. Remote Sens. 2018, 46, 1333–1340. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with landsat thematic mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Hartig, F.; Latifi, H. Importance of sample size, data type and prediction method for remote sensing-based estimations of aboveground forest biomass. Remote Sens. Environ. 2014, 154, 102–114. [Google Scholar] [CrossRef]
- Foody, G.M. Sample size determination for image classification accuracy assessment and comparison. Int. J. Remote Sens. 2009, 30, 5273–5291. [Google Scholar] [CrossRef]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection of accuracy of an urban classification: A case study in Denver, Colorado. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Zhiyong, L.; Li, G.; Yan, J. Training Samples Enriching Approach for Classification Improvement of VHR Remote Sensing Image. IEEE Geosci. Remote Sens. Lett. 2021, 99, 1–5. [Google Scholar]
- Pal, M. Kernel Methods in Remote Sensing: A Review. ISH J. Hydraul. Eng. 2012, 15, 194–215. [Google Scholar] [CrossRef]
- Ramezan, C.A.; Warner, T.A. Effects of Training Set Size on Supervised Machine-Learning Land-Cover Classification of Large-Area High-Resolution Remotely Sensed Data. Remote Sens. 2021, 13, 368. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Satellite | Key Features |
|---|---|
| Sentinel-2 | High-resolution multispectral imaging satellite equipped with 13 bands. Primarily used for monitoring terrestrial environments and providing information on vegetation, soil, and coastal conditions. |
| Landsat 8 | Equipped with the Operational Land Imager (OLI) and Thermal Infrared Sensor (TIRS). The OLI has 9 bands with a resolution of 30 m. It is widely used in fields such as global change, agriculture, and water quality. |
| GF-1 | Equipped with high-resolution and multispectral cameras. It can cover large areas with high spatial and temporal resolution. |
| Image Name | Object A | Object B | Object C | Object D | Object E | Total Sample Size |
|---|---|---|---|---|---|---|
| Sentinel-2 | 78,225 | 26,844 | 33,643 | 8962 | 6498 | 154,172 |
| Landsat 8 | 118,247 | 93,162 | 93,053 | 24,295 | / | 328,757 |
| GF-1 | 249,954 | 11,202 | / | / | / | 261,156 |
| Image Name | Object A | Object B | Object C | Object D | Object E | Total Sample Size |
|---|---|---|---|---|---|---|
| Sentinel-2 | 116 | 76 | 150 | 44 | 23 | 409 |
| Landsat 8 | 364 | 192 | 193 | 89 | / | 828 |
| GF-1 | 203 | 50 | / | / | / | 253 |
| Classifier | Parameter | Tested Parameter Ranges |
|---|---|---|
| SVM(RBF) | C | 0.25, 0.50, 1, 2, 4, 8, 16, 32, 64, 128 |
| gamma | 0.001, 0.01, 0.1, 1, 10, 100 | |
| RF | num.trees | 10, 50, 100, 200 |
| mtry | 1, 3, 5, 7, 9 | |
| KNN | K | 1, 3, 5, 7, 9 |
| Classification Model | Optimal Parameters Under Different Sample Selection Methods | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Sample selection methods | Direct sampling method | Group-based selection method | The selection method based on “entropy” | |||||||
| Image name | GF-1 | Landsat 8 | Sentinel-2 | GF-1 | Landsat 8 | Sentinel-2 | GF-1 | Landsat 8 | Sentinel-2 | |
| SVM(RBF) | C | 8 | 2 | 16 | 8 | 2 | 128 | 0.25 | 1 | 0.25 |
| gamma | 0.01 | 0.001 | 0.001 | 0.01 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | |
| Kappa coefficient | 0.7 | 0.8 | 0.85 | 0.76 | 0.7 | 0.913 | 0.6 | 0.7 | 0.73 | |
| RF | num.trees | 200 | 50 | 100 | 100 | 200 | 100 | 10 | 10 | 10 |
| mtry | 3 | 1 | 3 | 1 | 3 | 1 | 1 | 1 | 1 | |
| Kappa coefficient | 0.90 | 0.83 | 0.89 | 0.95 | 0.94 | 0.89 | 0.91 | 0.86 | 0.8 | |
| KNN | K | 3 | 3 | 3 | 5 | 9 | 7 | 1 | 1 | 1 |
| Sample Selection Methods | Image Name | Classification Model | Accuracy (%) |
|---|---|---|---|
| Direct sampling method | GF-1 | SVM | 86 |
| RF | 88 | ||
| KNN | 89 | ||
| Landsat 8 | SVM | 31 | |
| RF | 57 | ||
| KNN | 70 | ||
| Sentinel-2 | SVM | 87 | |
| RF | 86 | ||
| KNN | 88 | ||
| Group-based selection method | GF-1 | SVM | 95 |
| RF | 93 | ||
| KNN | 95 | ||
| Landsat 8 | SVM | 81 | |
| RF | 94 | ||
| KNN | 93 | ||
| Sentinel-2 | SVM | 90 | |
| RF | 93 | ||
| KNN | 90 | ||
| The selection method based on “entropy” | GF-1 | SVM | 69 |
| RF | 88 | ||
| KNN | 81 | ||
| Landsat 8 | SVM | 79 | |
| RF | 91 | ||
| KNN | 91 | ||
| Sentinel-2 | SVM | 81 | |
| RF | 67 | ||
| KNN | 78 |
| The Value of p | RF Classification Accuracy (%) | KNN Classification Accuracy (%) | SVM Classification Accuracy (%) |
|---|---|---|---|
| 0.001 | 87.3 | 76 | 82 |
| 0.003 | 92.7 | 89.1 | 88.4 |
| 0.005 | 93 | 91.4 | 90.8 |
| 0.007 | 92.2 | 90.2 | 90.6 |
| 0.01 | 92.3 | 90.4 | 91.2 |
| 0.03 | 93.2 | 92.6 | 92.7 |
| 0.05 | 93.1 | 93.4 | 93 |
| 0.07 | 93.3 | 93.6 | 93.6 |
| 0.1 | 93.4 | 93.9 | 93.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; He, J.; Chen, S.; Zhan, Y.; Bai, Y.; Qin, Y. Comparing Three Methods of Selecting Training Samples in Supervised Classification of Multispectral Remote Sensing Images. Sensors 2023, 23, 8530. https://doi.org/10.3390/s23208530
Zhang H, He J, Chen S, Zhan Y, Bai Y, Qin Y. Comparing Three Methods of Selecting Training Samples in Supervised Classification of Multispectral Remote Sensing Images. Sensors. 2023; 23(20):8530. https://doi.org/10.3390/s23208530
Chicago/Turabian StyleZhang, Hongying, Jinxin He, Shengbo Chen, Ye Zhan, Yanyan Bai, and Yujia Qin. 2023. "Comparing Three Methods of Selecting Training Samples in Supervised Classification of Multispectral Remote Sensing Images" Sensors 23, no. 20: 8530. https://doi.org/10.3390/s23208530
APA StyleZhang, H., He, J., Chen, S., Zhan, Y., Bai, Y., & Qin, Y. (2023). Comparing Three Methods of Selecting Training Samples in Supervised Classification of Multispectral Remote Sensing Images. Sensors, 23(20), 8530. https://doi.org/10.3390/s23208530