


Application of Deep Reinforcement Learning to UAV Swarming for Ground Surveillance

Abstract
:1. Introduction
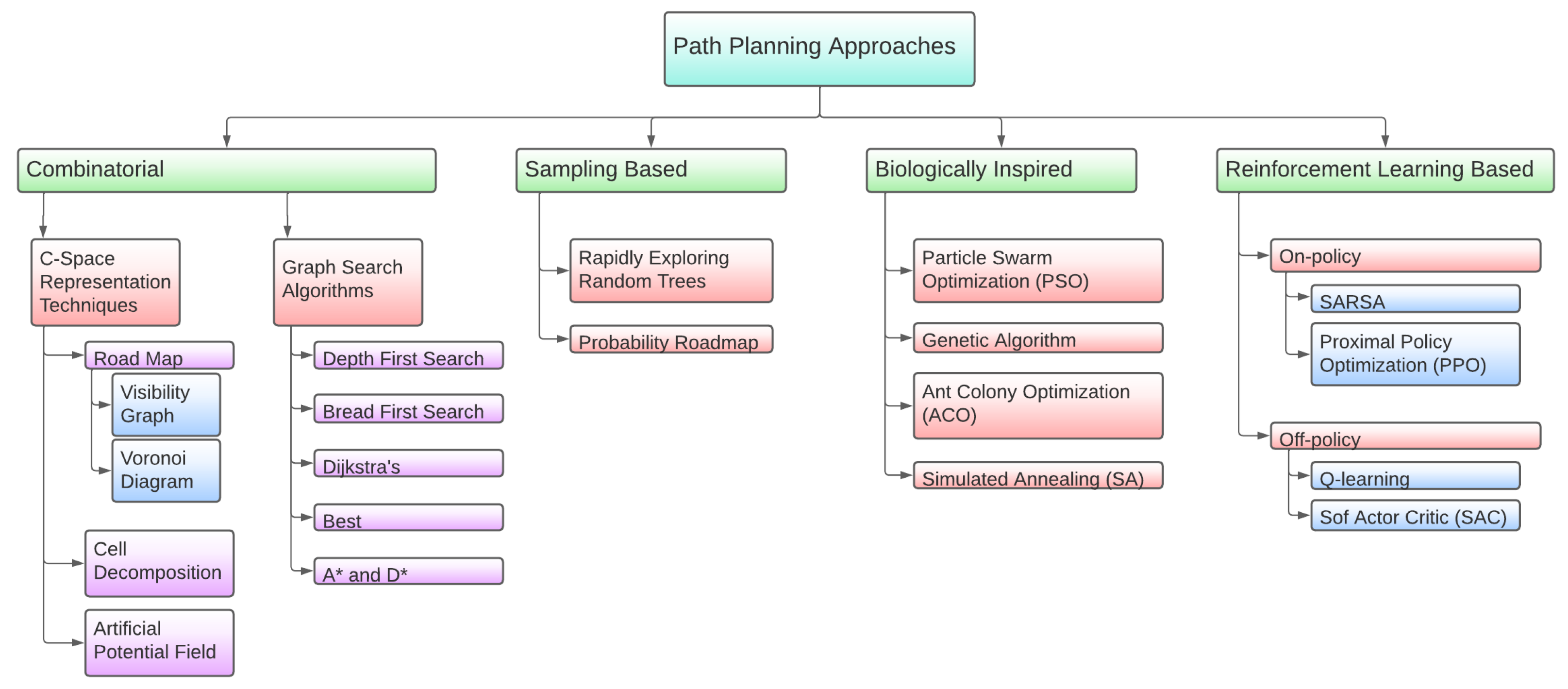
2. State of the Art
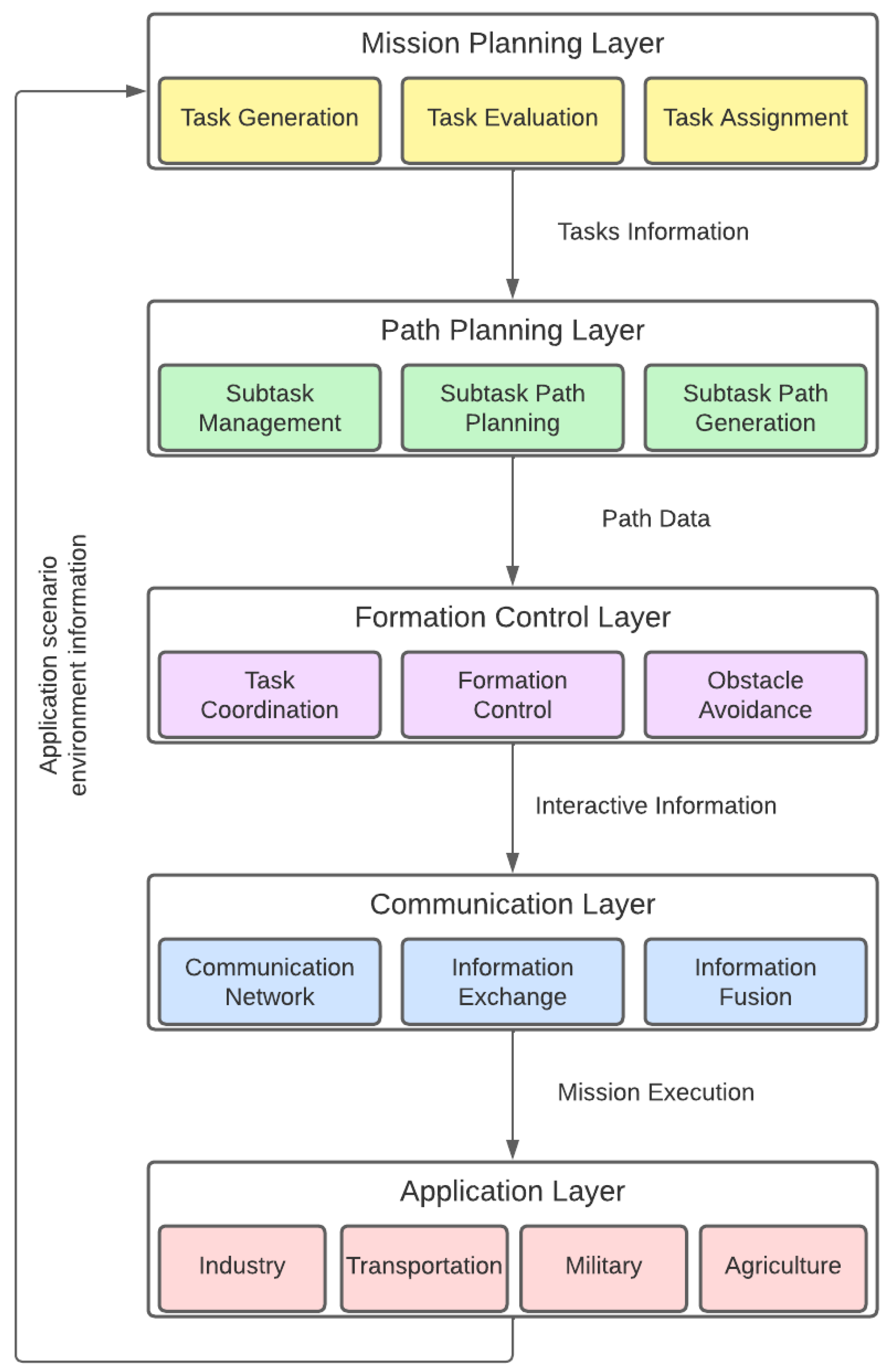
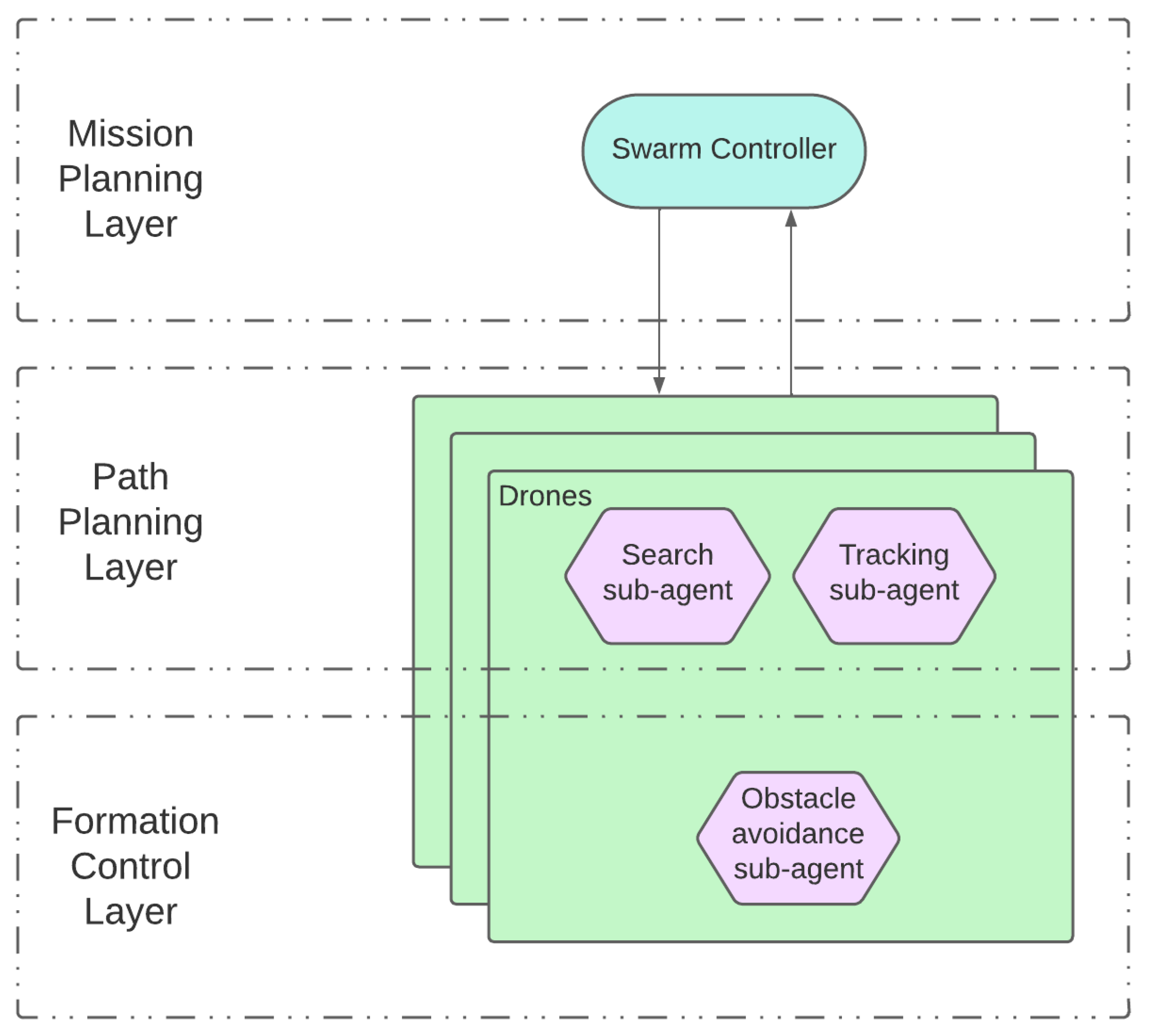
- Mission-planning layer: High-level layer which is responsible for the evaluation, planning, and assignment of tasks to individual UAVs and UAV formations (or clusters), and generates decision data for the path-planning layer.
- Path-planning layer: Mid-level layer that manages the tasks and generates corresponding task planning paths for each UAV or formation based on the decision data.
- Formation-control/collision-avoidance layer: This performs task coordination between several nearby UAVs according to the path information, and implements automatic obstacle avoidance and formation control.
- Communication layer: This conducts network communication according to the interactive information generated by the control layer to implement the necessary information sharing between individuals.
- Application layer: This will feed back the corresponding environment information to the mission-planning layer according to different application scenarios, closing the loop and enabling adaptation to the dynamic scenario.
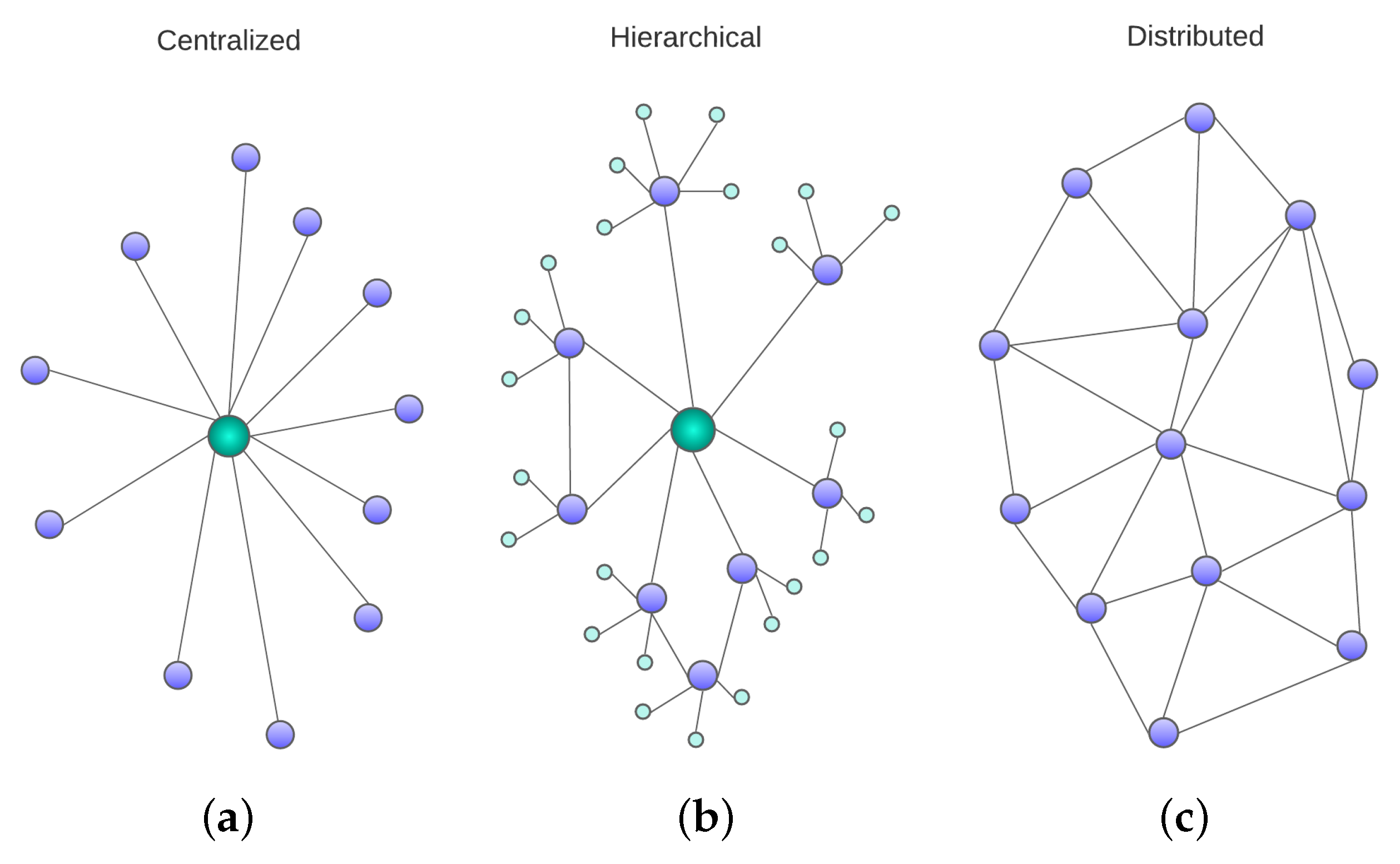
2.1. Swarm Management Organization
2.2. Mission-Planning Layer
- Each of the n UAVs available will be denoted as .
- A swarm is the set of all UAVs available: .
- Each task to be performed by the swarm is denoted .
- Tasks are not independent, and there are a collection of dependencies , meaning that in order to start executing , must have been completed. Here, will be a predecessor task of .
- is the set of all tasks to be performed.
- is the set of all dependencies.
- The mission is defined as the set of all tasks and dependencies.
- Compute the cost the task will involve for each UAV. The SC will use its latest knowledge about the swarm to estimate the cost of finishing it. This cost may be different for different UAVs. For a UAV which does not have scheduled tasks, the cost is the traveling cost from its current position plus the task’s completion cost. Conversely, if the UAV has already scheduled tasks, the task cost is calculated considering the estimated final location after completing the current tasks.
- Assign the task to a UAV. A potential candidate would be the UAV with the smallest cost.
- First come, first served: The new task will be executed after all earlier tasks are completed.
- Insertion-based policy: If there are no scheduled tasks on the UAV, the new task will start execution immediately. Otherwise, the UAV will schedule the new task to optimize its own overall cost. If before the new task is assigned the UAV must perform N sorted tasks , a way to recalculate the plan would be placing the new task in each position from 1 to and computing every cost of performing all the tasks, i.e., the cost of ordered sets . The policy will choose the position of the new task that minimizes the cost.
- Use of classical solutions to the traveling salesman problem (TSP) [10]. If task execution costs are assumed to be independent of the task order, traveling costs drive the difference between the different scheduling processes, and then the application of those solutions are direct.
- Adaptive policy: This policy simply uses other policies to calculate task costs and picks the policy that produces the minimum cost each time the UAV needs to perform a task scheduling.
2.3. Path-Planning Layer
2.4. Formation-Control/Collision-Avoidance Layer
2.5. Swarming Survey Summary and Conclusions
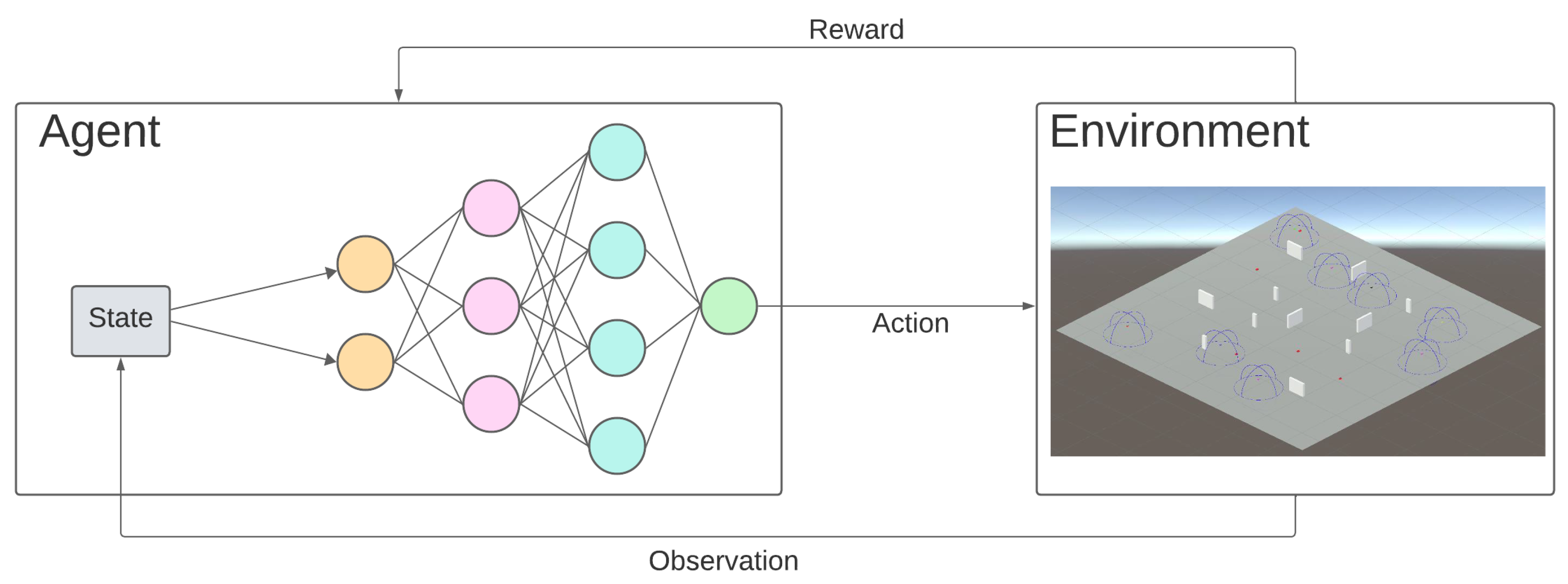
2.6. Reinforcement-Learning-Based Methods
- Finite set of states S.
- Finite set of actions A.
- Transition function , defined as the probability that performing action a in state s leads to state in the next time step.
- Reward , provided as a result from moving from state s to state due to action a.
| Algorithm 1 Q-learning |
|
| Algorithm 2 SARSA |
|
| Algorithm 3 PPO |
|
3. Proposed System
- First, a representative use case of the surveillance problem was compiled, describing the expected concept of operation of the swarm, the types of available drones, the targets of interest, limitations, etc. As a result, a set of requirements for the swarm was derived, as discussed in Section 3.1.
- Considering the problem description, a system-level architecture was designed, as described in Section 3.2. The architecture adapts the conceptual architecture previously depicted in Figure 1 to a centralized swarm organization. Considered tasks, information exchange between the swarm elements, and selected algorithms for each element are also discussed here.
- Then, the behaviors implemented with DRL were trained using a simulation environment. A novel hybrid methodology was followed, consisting in dividing the drone functionality into individually trainable models. Then, for each model, an iterative training approach was adopted consisting of increasingly adjusting the scenario complexity and rewards until the desired behavior is obtained. This process is explained in Section 3.3.
- Finally, the implementation was validated using a set of simulation scenarios. For this, we propose relevant performance indicators for the considered problem. These metrics and results are discussed in Section 4.
3.1. Surveillance Application Description and Requirements
- Deployment of the swarm: the swarm of drones is released from a platform.
- Target search and acquisition, where swarm assets, holding suitable sensors for exploration, search for the targets that are moving in the area of interest.
- Target tracking, after target acquisition, where the SC assigns to some of the UAVs the tasks to follow and track the detected targets while the swarm maintains the ability to acquire new targets.
- During the continuous tracking of targets, both the SC and the UAVs’ control systems shall take into account the possibility of losing the target. Loss of target sight can happen due to occlusion, which would occur in low-altitude ground environments where obstacles are present, to evasive maneuvers by the target, or by errors in the swarm control functionality. Swarm control must reassign tasks to reacquire the target. Tracking UAVs may also be reassigned to either tracking or search as the target leaves the area of interest.
- Once the time is over, there shall be a retreat phase of the UAV swarm to the pick-up point. The swarm’s intelligent control shall manage the path planning for such a retreat sequence if the follow-up mission is interrupted. It then shall adapt to the current swarm status and reassess the UAVs’ trajectories towards a safe point.
- The paths the ground targets may follow are not constrained. The trajectories of the targets are combinations of straight sections joined by curves in which the direction is changed. Speeds and accelerations will be typical for the interest ground targets (vehicles, individuals, etc.).
- The scenario might contain sparse buildings that could occlude the ground targets.
- The meteorological conditions in the scenario are assumed to be benign, without adverse weather conditions such as heavy rain or fog, and the system is oriented to daily surveillance. We can, therefore, assume camera sensors will allow correct target detection if the targets are within range of the sensor.
- UAVs can carry two complementary types of sensors for target detection: short-range millimeter radar and optical cameras. The camera can measure the target’s direction and the radar target’s distance, which enable a 3D location of the target’s position.
- For obstacle avoidance, an additional proximity sensor is implemented in each UAV.
- The altitude at which the UAVs fly is the same for all of them and it is not allowed to be modified.
3.2. System Architecture
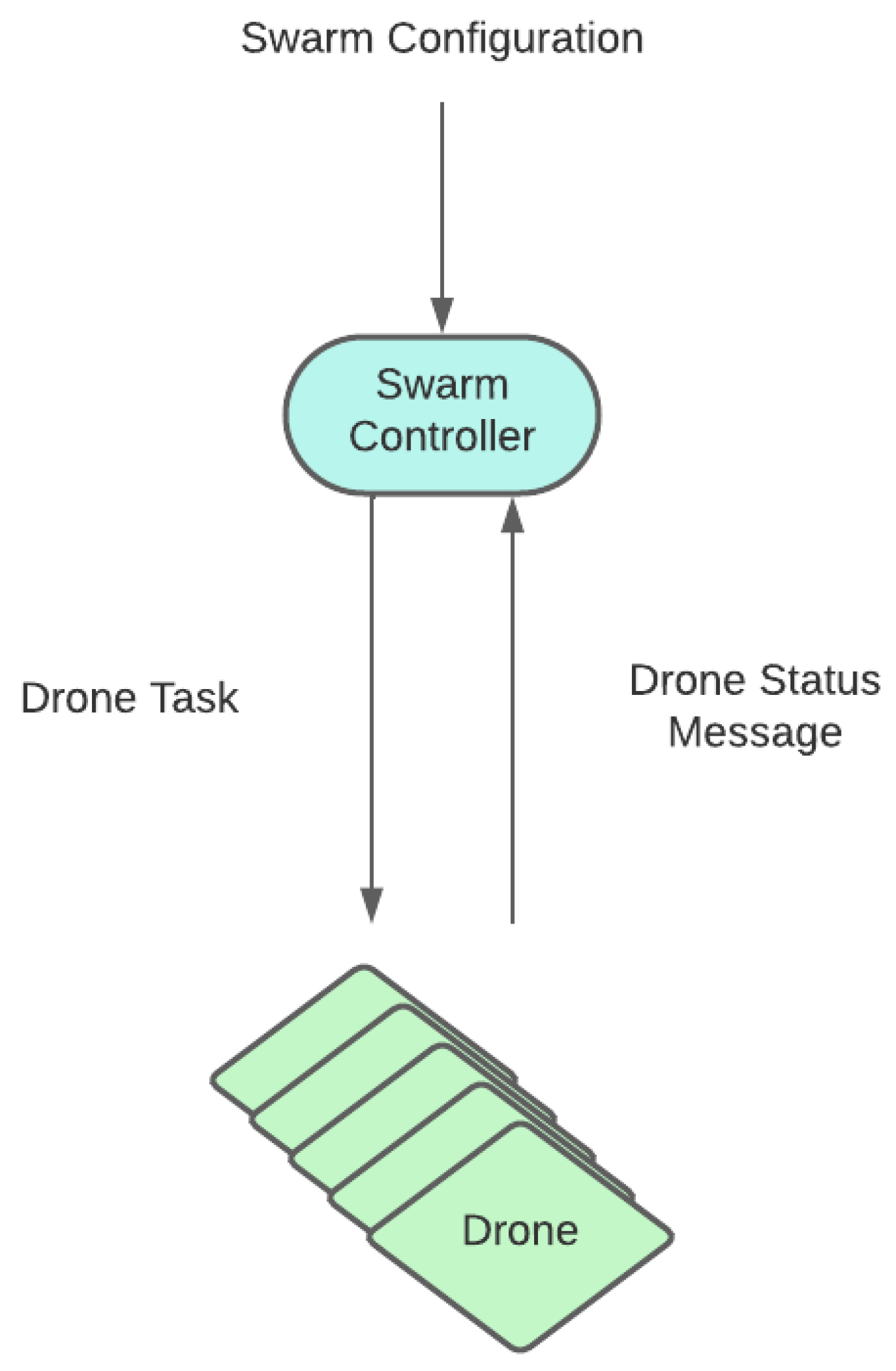
- Swarm controller (upper layer): This is the centralized entity coordinating the UAV swarm. It periodically receives information from each UAV agent regarding its state and its surveillance information. Tasks are generated and allocated to drones as required, so that the surveillance and tracking objectives are fulfilled. Those tasks are communicated to the lower layer so that they are executed by the drones. In our proof of concept, this functionality will be rule-based and deterministic, although in future iterations we would like to extend the use of RL also to this layer.
- UAV agents/entities (lower layer): A set of autonomous and independent drones conforming the UAV swarm. Individual UAV behavior is dependent on the task that has been assigned by the controller. That is, drones dynamically adapt their trajectories to fulfill the task. As the task is executed, a UAV retrieves operational information (e.g., target positions) with simulated onboard sensors and forwards it to the swarm controller. In our proof of concept, this is the functionality to be implemented using RL.
- Search task: The overall swarm search function aims to achieve a complete level of recognition of the search area, covering it as fast as possible. From the UAV perspective, a search task consists of two processes that must be carried out in an orderly way:
- An initial movement to the assigned search area, which is a reduced section of the complete mission search area (if it is out of its assigned search area when it is assigned this task).
- The subsequent reconnaissance and target search phase, within the assigned search area itself, using search patterns.
For this purpose, the assigned UAV shall follow a criterion that guarantees the total exploration of its assigned search area periodically, or that reduces to the minimum time between revisits for each location within the assigned search area.During the search the UAV can detect targets. When a UAV finds a target, it will notify the controller about the position, velocity vector, and identification/classification of the target. On its end, and as a result, the swarm controller will generate new tasks (namely, tracking tasks) to ensure that identified targets are followed. - Tracking task: The main objective of the tracking task is to ensure the tracking of the targets. The tracking itself will consist of keeping the targets within the field of view of the UAV assigned to continuously track them. For each UAV, this task consists of two processes that must be carried out in an orderly way:
- An initial movement to the assigned target’s last known position (if the target is not within the sensor coverage of the UAV).
- The subsequent tracking phase itself.
Within the tracking phase, it may happen that the target is hidden behind an obstacle in such a way that the UAV loses sight of it. This may result in the UAV having to search for the target again while the tracking task is in process. This target re-acquisition search, integrated into the tracking tasks, is not similar to the one performed in the search task, as the latter pursues the goal of inspecting an entire area in the shortest possible time. In this case, the UAV must search around the last point where the target was detected, since it is known that the UAV is close to that point. In the initial movement of the UAV towards the assigned target, a similar local search may also need to be performed around the last available detected position of the target.
- Status of each of the drones of the swarm. UAVs periodically send a UAV status message containing:
- –
- UAV position and velocity.
- –
- Current task being performed by the UAV.
- –
- Current list of detections: targets that are in the field of view of the UAV.
- Current visible targets: A list of the targets detected by the whole swarm. For each target, it contains a fused position estimation from all its detections by the swarm.
- Current search areas: This consists of the set of sub-areas the swarm operational area is divided into for searching task purposes.
- Current task assignations: As tasks are created and assigned, the swarm controller keeps a record of the last assignments provided.
3.3. Implementation and Training Methodology
- The whole operational area must always be covered by a set of search tasks.
- As new targets are discovered, the swarm shall start tracking them while redistributing the search areas (generating new ones if required) between the remaining non-tracking drones.
- It is assumed that each UAV can only fulfill one task at a time. Target tracking has more priority than search tasks. Also, we assume one UAV can track, at most, one target. Therefore, once a UAV is assigned to tracking a specific target, no other tasks will be assigned to that agent (UAV) unless tracking is unsuccessful.
- It is also assumed that the number of drones is greater than the number of targets.
3.3.1. Search Sub-Agent Training
- Observations.
- Agent position.
- Agent velocity vector.
- Directional vector of the complete operation area center with respect to the UAV position.
- Operation area size.
- Directional vector of the task search area center with respect to the UAV position.
- Search area size.
- Actions.
- Heading control: a 2D vector indicating the direction to be followed by the UAV.
- Velocity control: the speed will be controlled indirectly through the thrust of the UAV by applying a force to the UAV, resulting in either acceleration or deceleration. The range of speeds achieved by the UAV in this way is constrained within 35 to 120 m/s.
- Rewards. Table 2 summarizes the rewards given to the search sub-agent during the training stage so that the expected search behavior is reached.
3.3.2. Tracking Sub-Agent Training
- Observations.
- Agent position.
- Agent velocity vector.
- Directional vector of the complete operational area center with respect to the agent position.
- Operational area size.
- Directional vector of the target’s last known position with respect to the agent position.
- Target’s last known velocity vector.
- A Boolean indicating whether or not the target is being detected.
- Actions.
- Heading control: same meaning as in the case of search agent.
- Velocity control: same meaning as in the case of search agent.
- Rewards. Table 3 summarizes the rewards given to the tracking sub-agent during the training stage so that the expected tracking behavior is reached.
3.3.3. Obstacle Avoidance Sub-Agent Training
- Observations.
- Agent position.
- Agent velocity vector.
- Directional vector of the target position with respect to the agent position.
- Proximity sensor detections.
- Actions.
- Heading control: three discrete actions to control the yaw can be taken. The value 0 is used when a forward movement is wanted, so the UAV follows a straight trajectory with the yaw equal to 0. The values 1 and -1 are taken when a rotation in the yaw is wanted.
- Velocity control: same meaning as in the case of the search agent.
- Rewards. Table 4 summarizes the rewards given to the obstacle avoidance sub-agent during the training stage so that the expected behavior is reached.
4. Experiments and Results
4.1. Evaluation Metrics
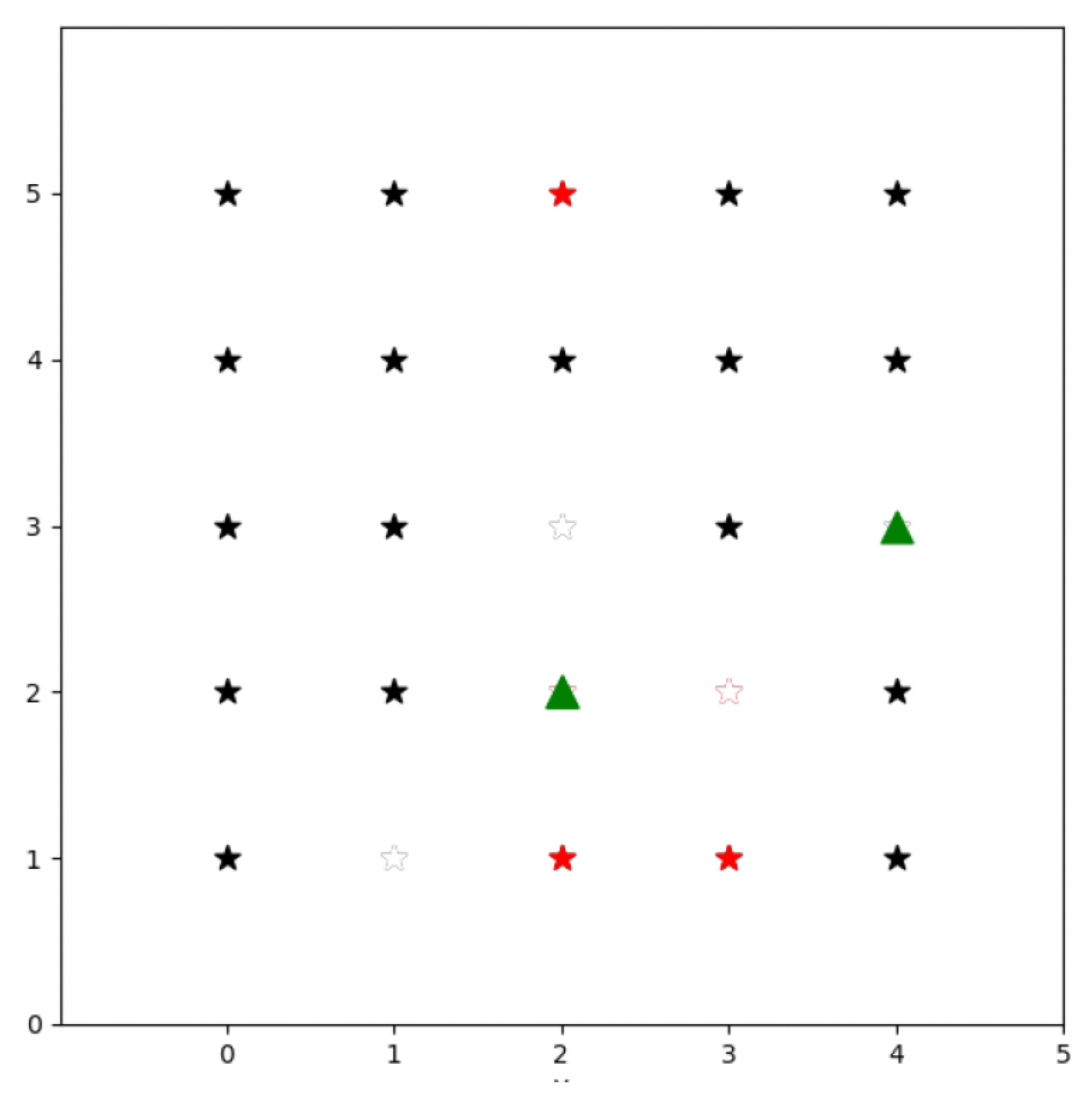
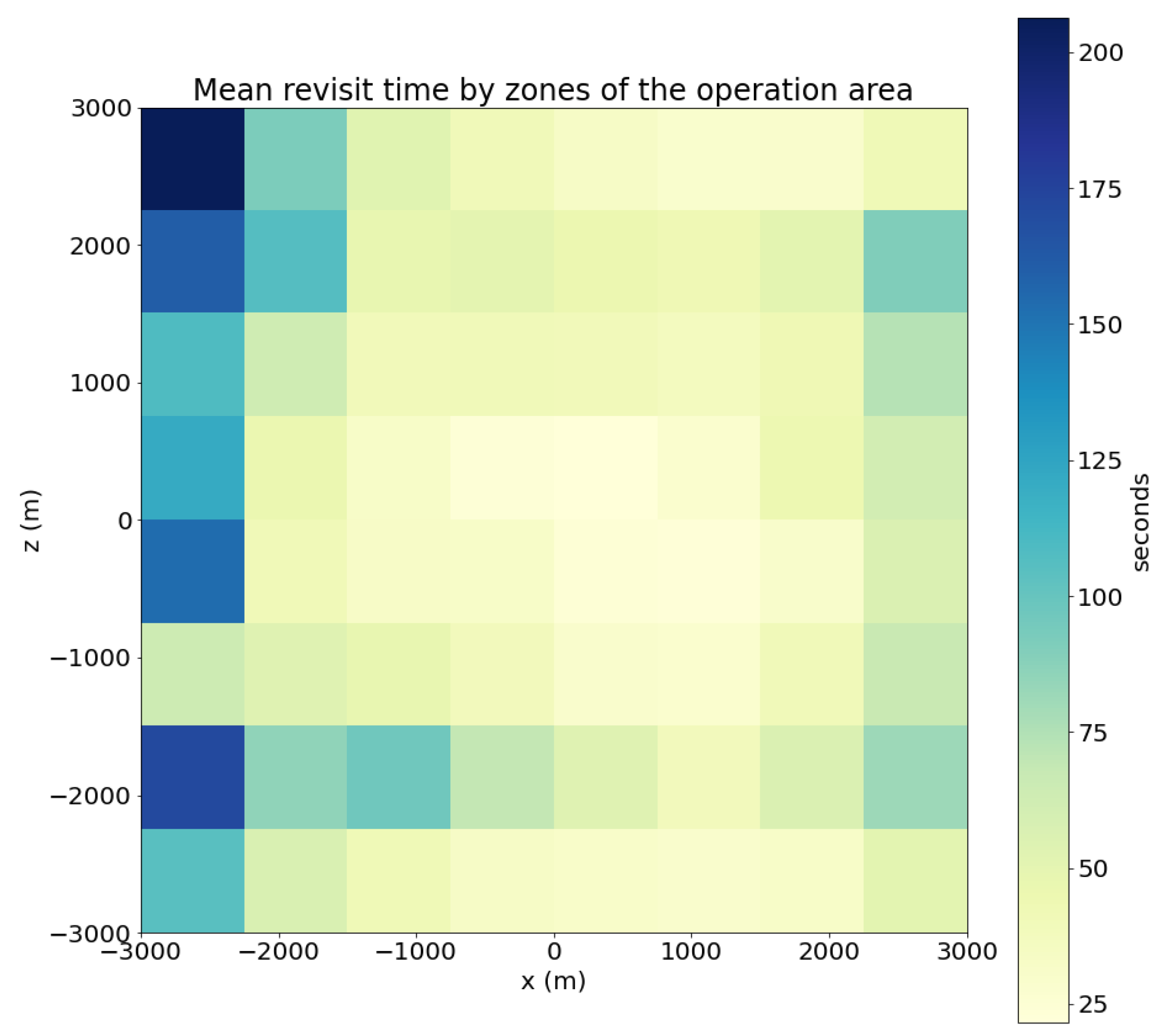
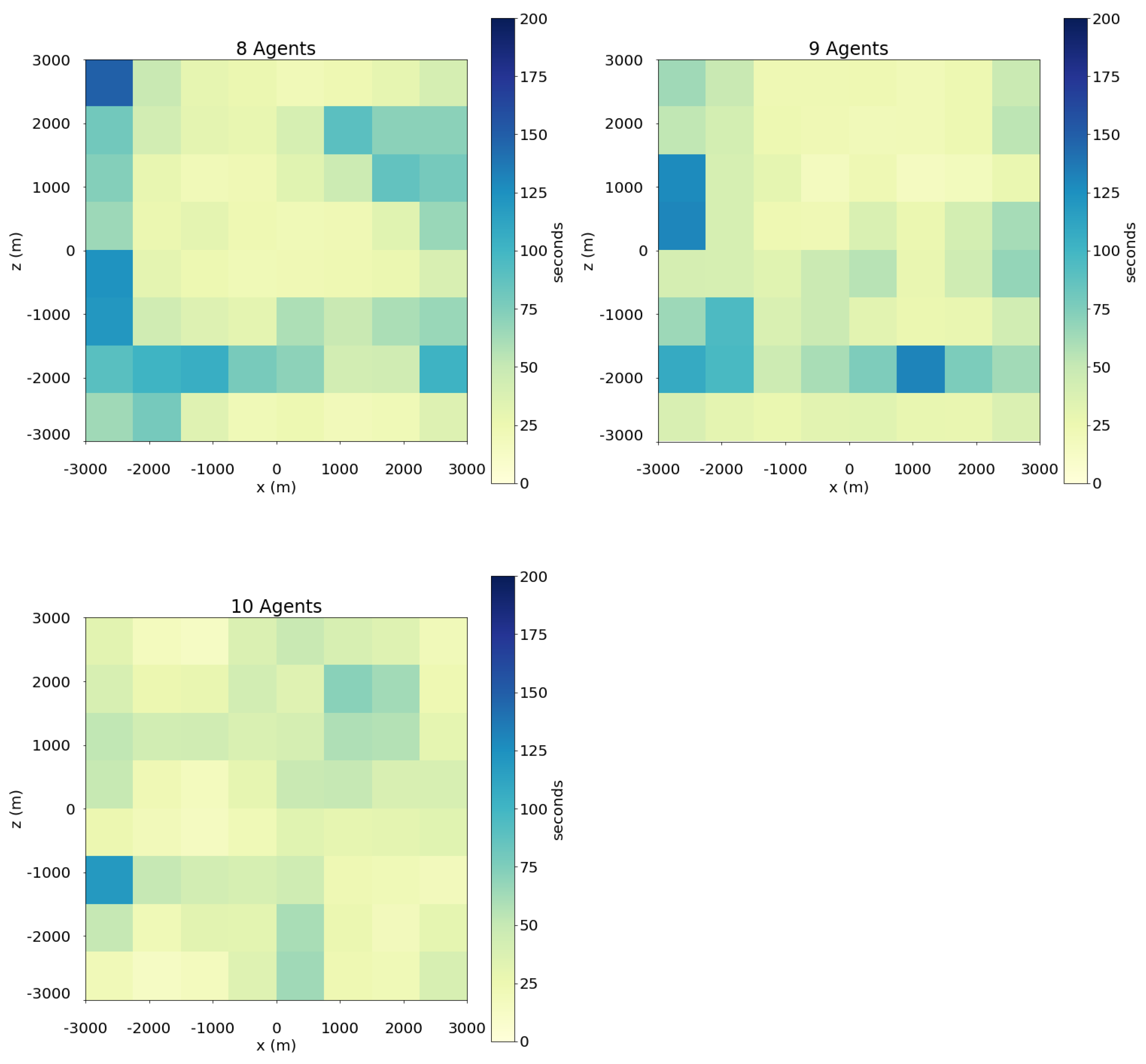
- Revisit period: This metric measures the frequency at which drones return to a specific area to update target information or detect changes in the area. This metric is computed by dividing the swarm’s operation area in smaller cells forming a grid, and calculating for each cell the average duration of the periods when it is not visited by any UAV in the swarm. The goal of a swarm performing a search operation over an area should be to visit every cell as frequently as possible, minimizing this period.
- Search time: This metric refers to the total time it takes for the UAV swarm to find all the targets in the operation area. It is the minimum time for which the swarm controller has visibility of all the targets in the area at the same time.
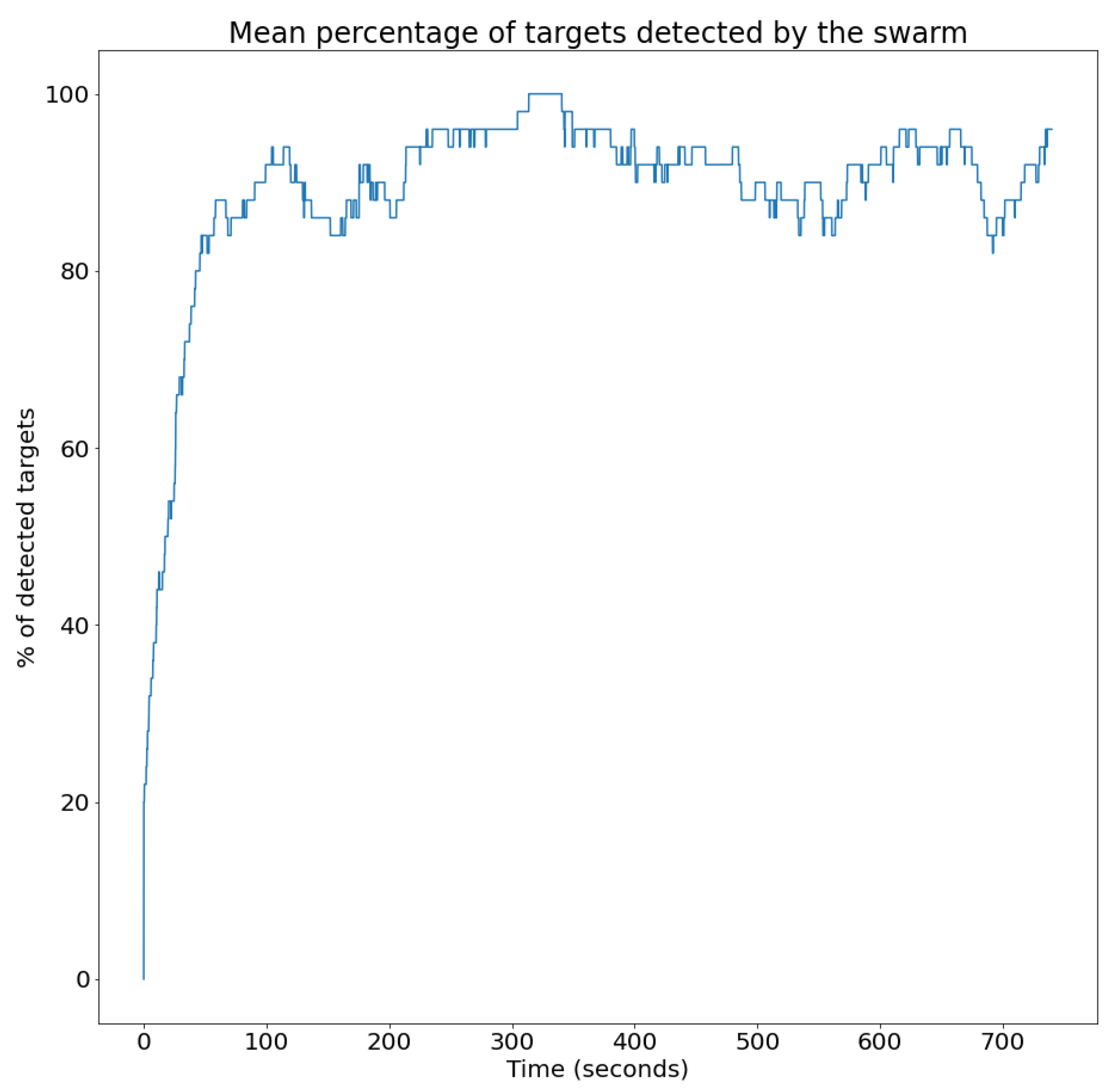
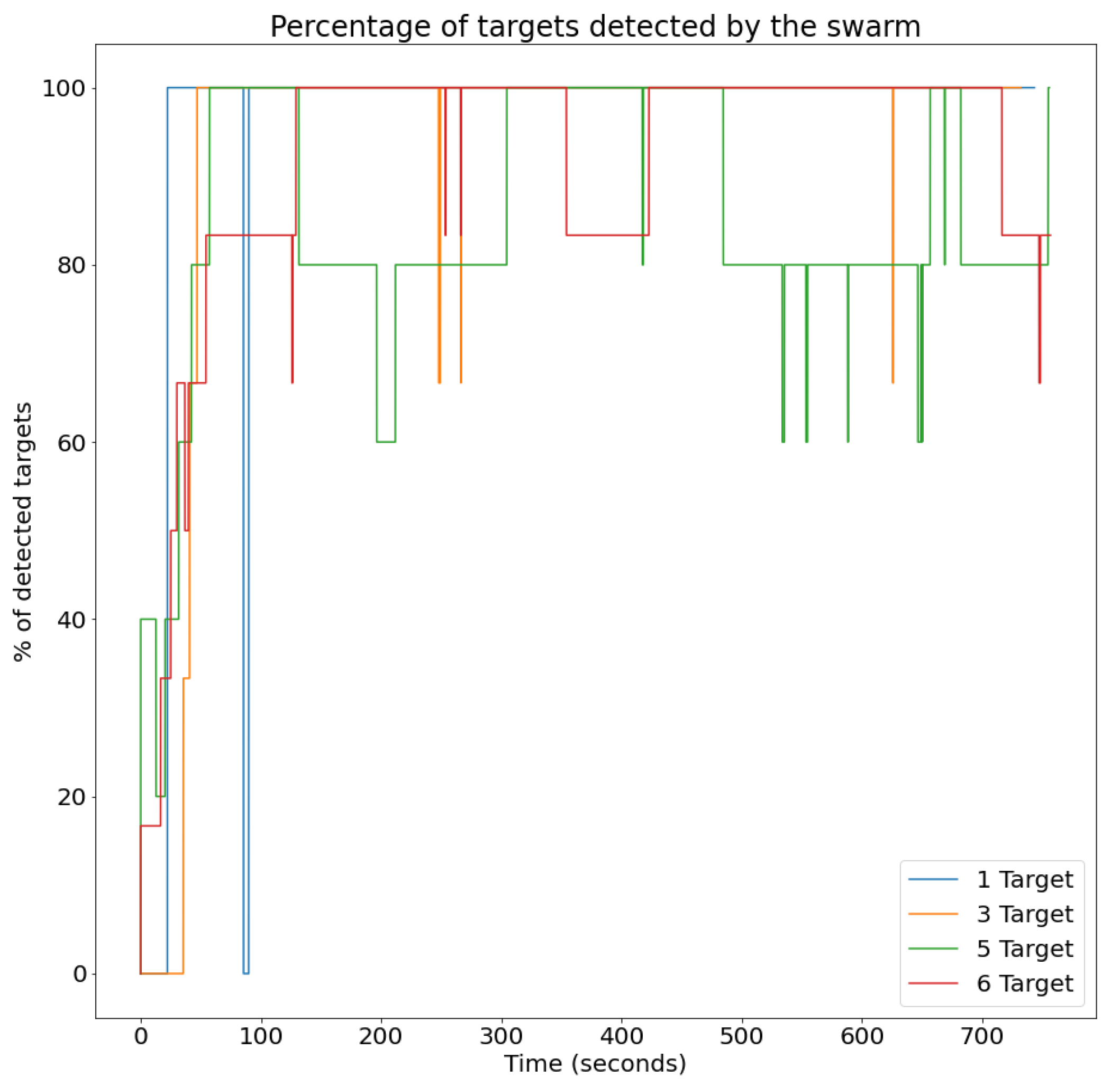
- Percentage of detected targets: This metric assesses the success of the UAV swarm in detecting targets within the area. It is computed for each time instant, as the percentage of targets that are visible to the UAV swarm.
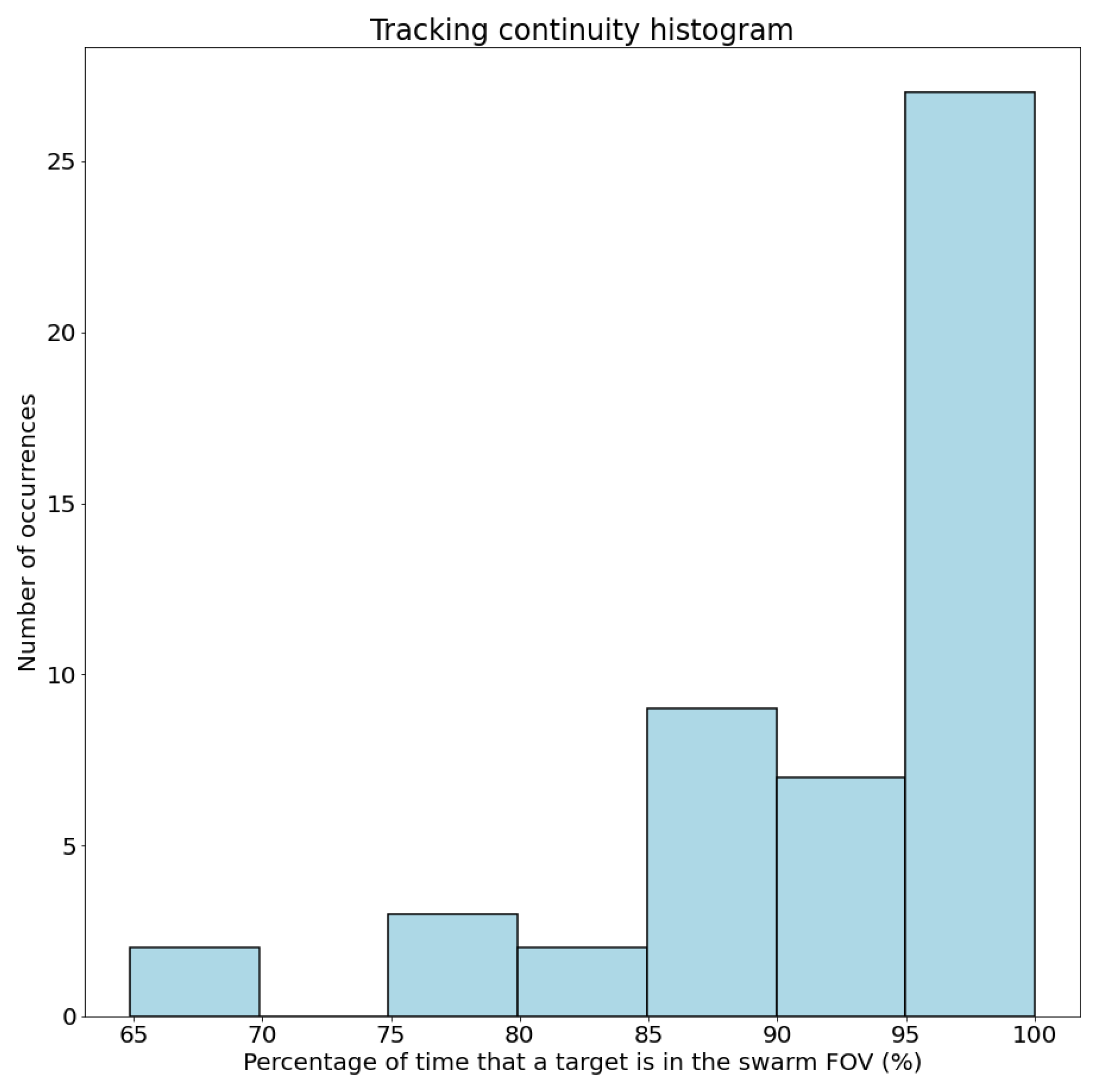
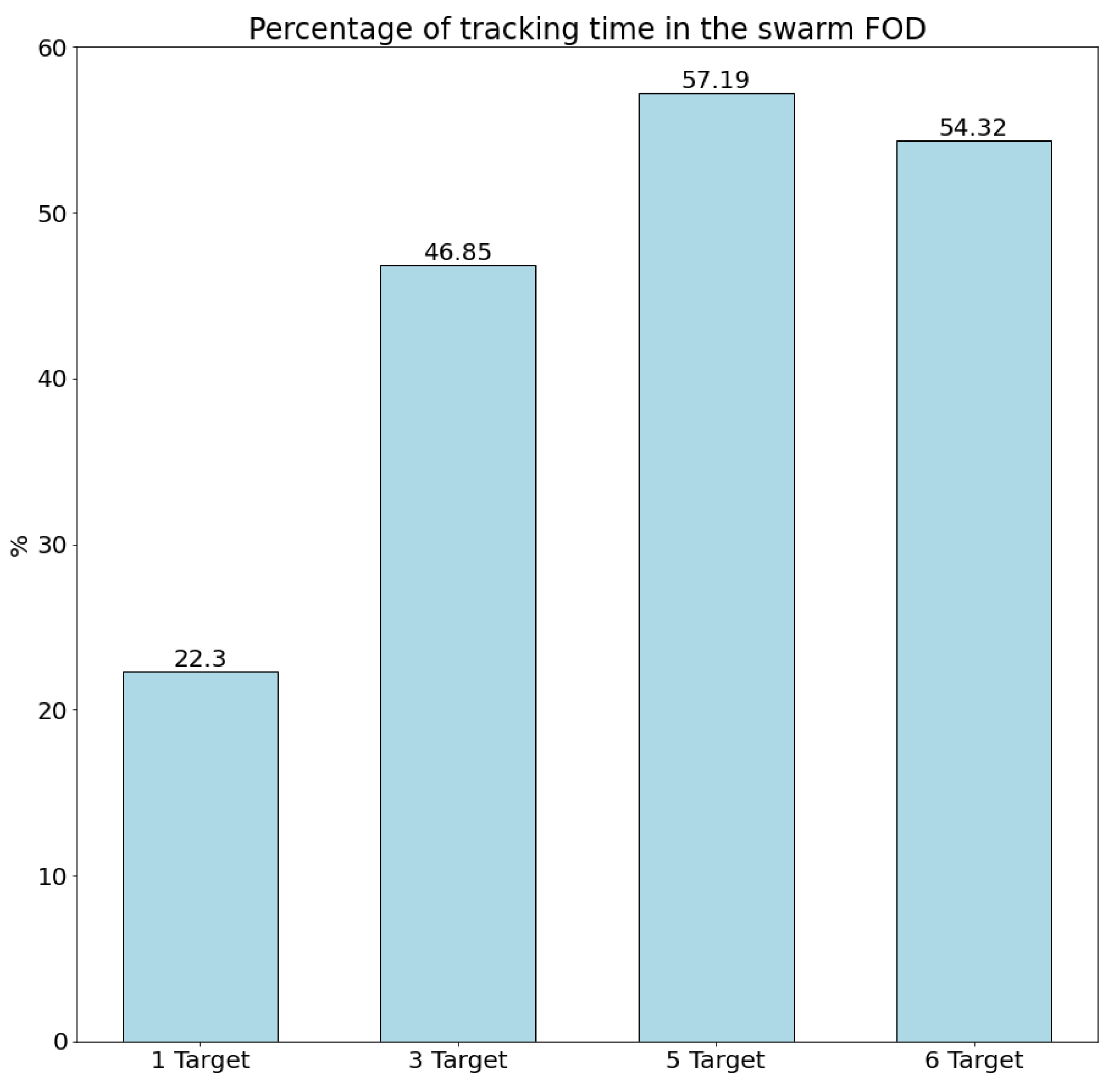
- Tracking continuity: This metric evaluates the ability of the UAV swarm to keep its targets within its field of view and obtain accurate information about their position and movement. It is computed as the ratio of time a target is in the swarm’s field of view, in relation to the total tracking time for that target. The total tracking time for a certain target is the time from the first time it is detected and assigned to a UAV through a tracking task until the end of the operation or until the target exits the operation area, that is, the time where the swarm should keep that target in its field of view.
- Target acquisition time: This metric measures the time it takes for the UAV swarm to identify and start tracking a target after it has entered the surveillance area. If the search tasks are performed in an efficient way, this time should be minimized.
4.2. Simulation Scenarios and Results
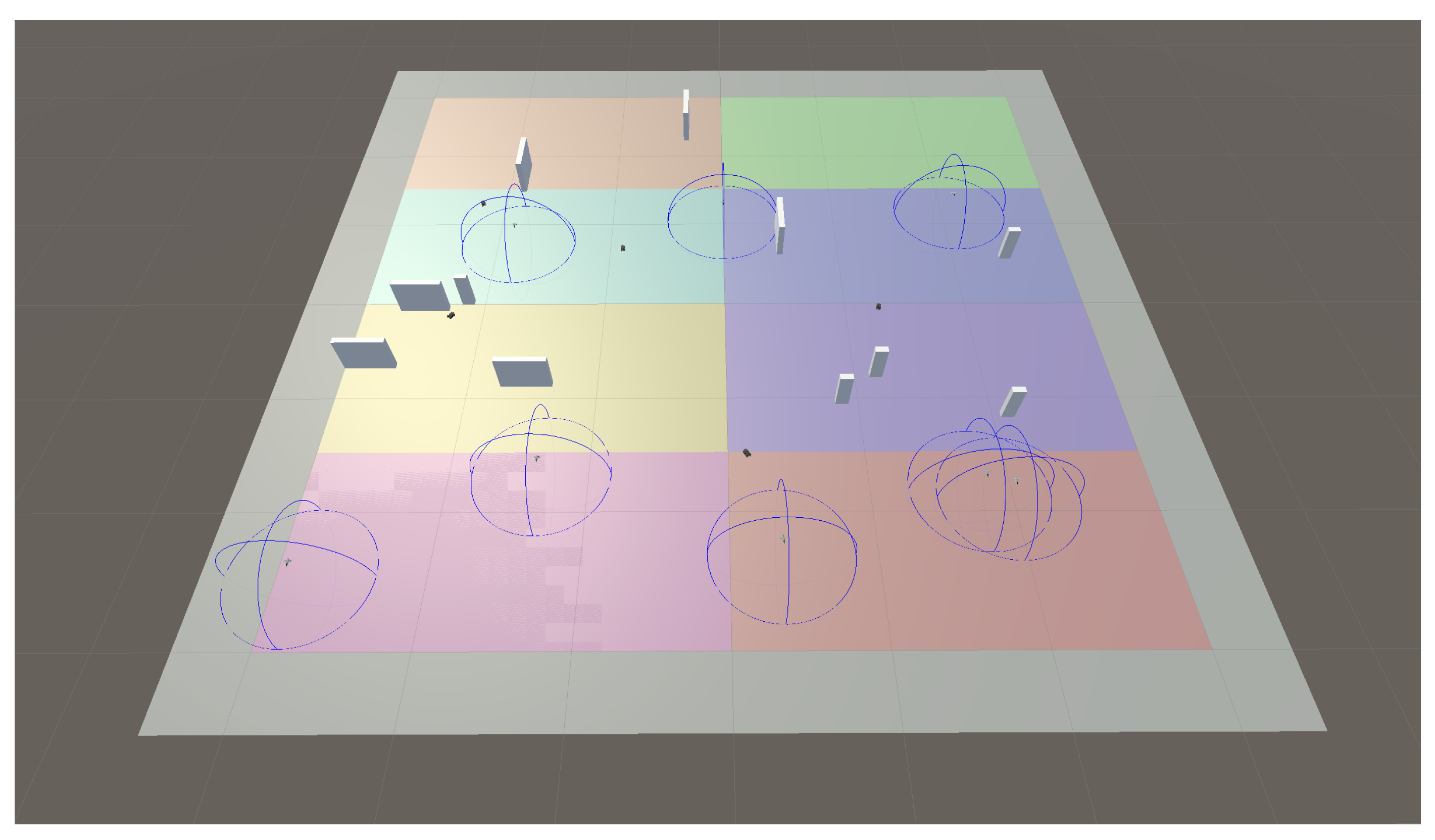
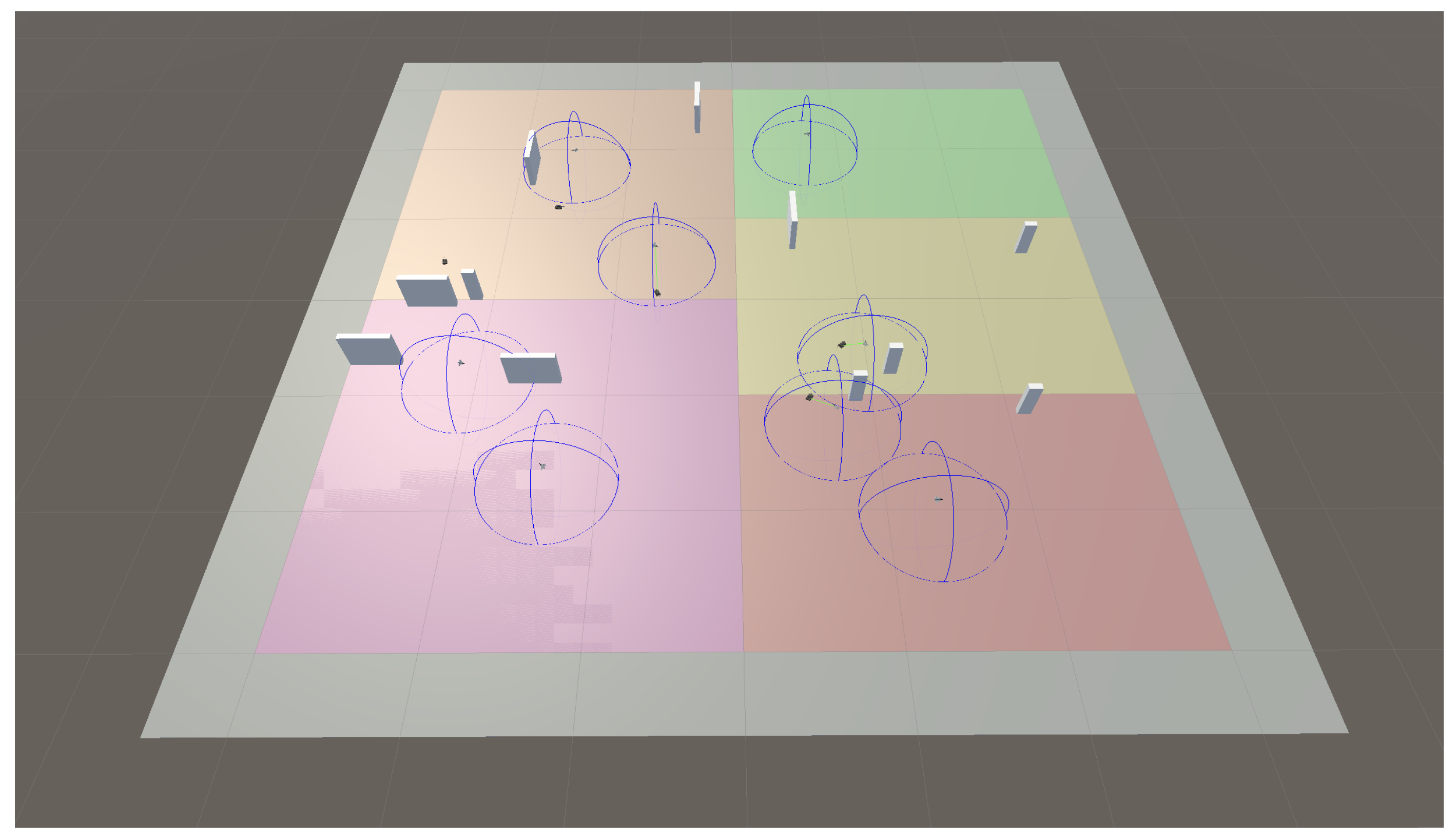
- The targets are depicted as small vehicles on the ground. They are colored red and move with a constant speeds of 20 m/s, as described before.
- The UAVs are depicted as aircraft. UAVs’ sensor coverage is depicted by drawing semi-spheres in blue, centered at the UAV’s position and with a radius equivalent to the sensor coverage.
- Static obstacles are depicted as gray prisms, randomly distributed.
- Different colors on the ground are related to the definition of different search areas, to be assigned as tasks to different UAVs.
- Detection of a given target by a UAV sensor is depicted by joining both with a green line.
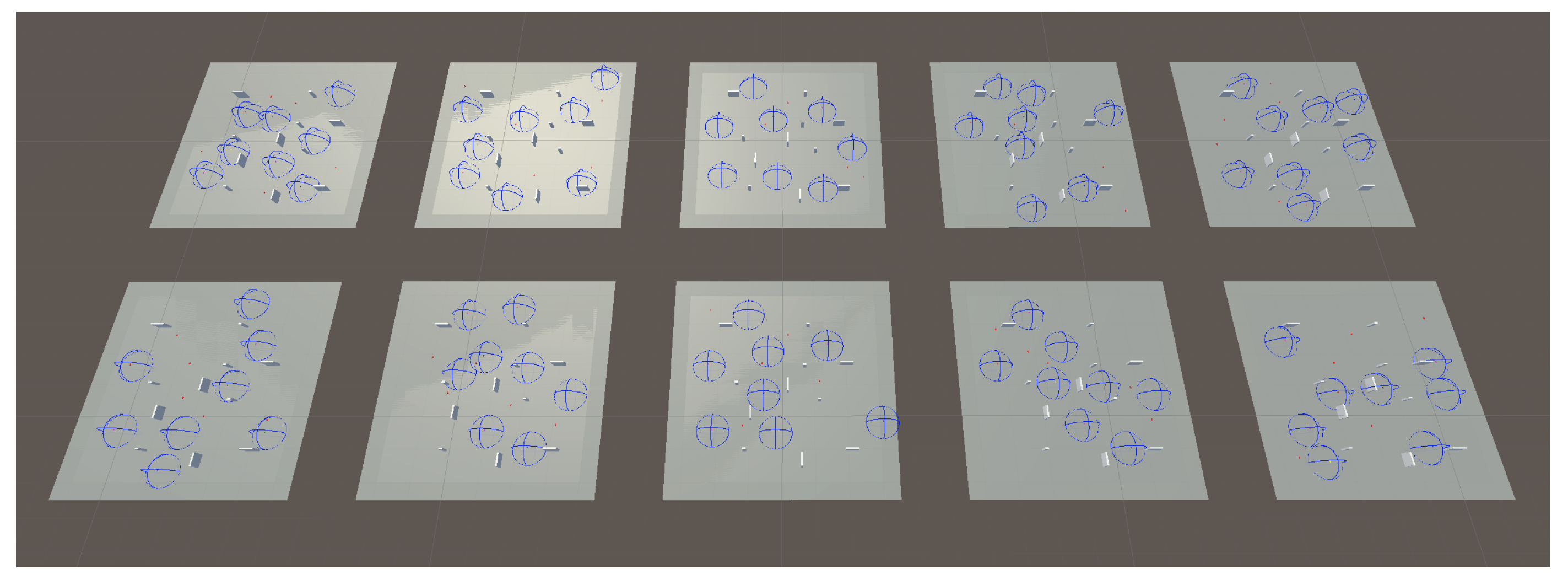
- A statistical analysis using 10 simulations to assess the behaviors of the UAV agents with the models obtained from the training process detailed in the previous section. This analysis, discussed in Section 4.2.1, uses a set number of drones and targets for all simulations.
- An exploration on the swarm system’s ability to adapt to a changing number of targets. For this, simulations with a varying number of targets are tested in Section 4.2.2.
- An examination on how the system behaves with a varying number of drones within the swarm, as discussed in Section 4.2.3.
4.2.1. Statistical Analysis
4.2.2. Scenario with Changing Number of Targets
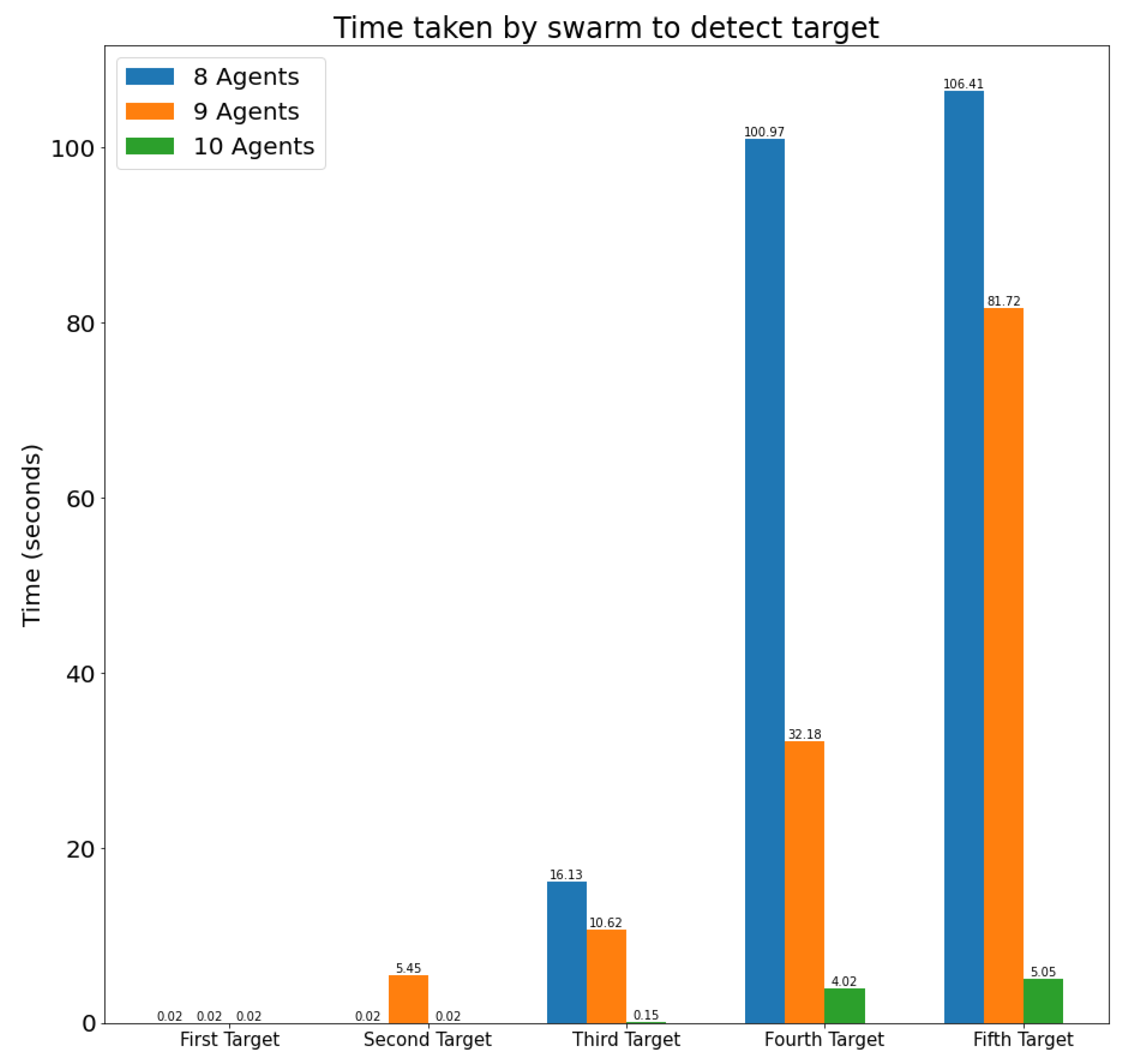
4.2.3. Scenario with Changing Number of Drones
5. Conclusions
- Design of more realistic simulation environments that allow the efficient generation of training data for RL-based control algorithms, even tailored for a specific mission, in an acceptable time interval.
- Development of more efficient training systems for reinforcement learning. Both algorithmic and hardware aspects need to be addressed.
- Related to the previous point, a more systematic approach for the identification of the most relevant input features and their most compact representation, as well as of higher-level UAV control actions, might allow for more effective training processes.
- Further hybridization of classical and DRL approaches could be investigated, at all swarming layers.
- Development of structured design methods to obtain the actions sets and the reward functions for the swarm training phase adapted to a specific military mission.
Author Contributions
Funding

Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stolfi, D.H.; Brust, M.R.; Danoy, G.; Bouvry, P. A Cooperative Coevolutionary Approach to Maximise Surveillance Coverage of UAV Swarms. In Proceedings of the 2020 IEEE 17th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 10–13 January 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ebrahimi, E.; Page, J. UAV Swarm Search Strategy Applied To Chaotic Ship Wakes. In Proceedings of the 15th Australian International Aerospace Congress, Melbourne, Australia, 25–28 February 2013. [Google Scholar]
- Palunko, I.; Fierro, R.; Cruz, P. Trajectory generation for swing-free maneuvers of a quadrotor with suspended payload: A dynamic programming approach. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 2691–2697. [Google Scholar]
- Wang, Y.; Bai, P.; Liang, X.; Wang, W.; Zhang, J.; Fu, Q. Reconnaissance Mission Conducted by UAV Swarms Based on Distributed PSO Path Planning Algorithms. IEEE Access 2019, 7, 105086–105099. [Google Scholar] [CrossRef]
- Shakoor, S.; Kaleem, Z.; Baig, M.I.; Chughtai, O.; Duong, T.Q.; Nguyen, L.D. Role of UAVs in Public Safety Communications: Energy Efficiency Perspective. IEEE Access 2019, 7, 140665–140679. [Google Scholar] [CrossRef]
- Zhou, Y.; Rao, B.; Wang, W. UAV Swarm Intelligence: Recent Advances and Future Trends. IEEE Access 2020, 8, 183856–183878. [Google Scholar] [CrossRef]
- Chriki, A.; Touati, H.; Snoussi, H.; Kamoun, F. UAV-GCS Centralized Data-Oriented Communication Architecture for Crowd Surveillance Applications. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 2064–2069. [Google Scholar] [CrossRef]
- Iocchi, L.; Nardi, D.; Salerno, M. Reactivity and Deliberation: A Survey on Multi-Robot Systems. In Balancing Reactivity and Social Deliberation in Multi-Agent Systems; BRSDMAS 2000; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2103. [Google Scholar]
- Idalene, A.; Boukhdir, K.; Medromi, H. UAV Control Architecture: Review. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2019, 10, 652–657. [Google Scholar] [CrossRef]
- Gupta, D. Solving tsp using various meta-heuristic algorithms. Int. J. Recent Contrib. Eng. Sci. IT (iJES) 2013, 1, 22–26. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November—1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Zhou, S.; Yin, G.; Wu, Q. UAV Cooperative Multiple Task Assignment Based on Discrete Particle Swarm Optimization. In Proceedings of the 2015 7th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2015; pp. 81–86. [Google Scholar] [CrossRef]
- Sujit, P.B.; George, J.M.; Bread, R. Multiple UAV Task Allocation Using Particle Swarm Optimization. In Proceedings of the AIAA Guidance, Navigation and Control Conference and Exhibit, Honolulu, HI, USA, 18–21 August 2008. [Google Scholar] [CrossRef]
- Yan, M.; Yuan, H.; Xu, J.; Yu, Y.; Jin, L. Task allocation and route planning of multiple UAVs in a marine environment based on an improved particle swarm optimization algorithm. EURASIP J. Adv. Signal Process 2021, 94, 1–23. [Google Scholar] [CrossRef]
- Zhu, M.; Du, X.; Zhang, X.; Luo, H.; Wang, G. Multi-UAV Rapid-Assessment Task-Assignment Problem in a Post-Earthquake Scenario. IEEE Access 2019, 7, 74542–74557. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, Y.; Zhu, S.; Sun, Y. Multi-UAV Task Allocation Based on Improved Algorithm of Multi-objective Particle Swarm Optimization. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Zhengzhou, China, 18–20 October 2018; pp. 443–4437. [Google Scholar] [CrossRef]
- Chinchuluun, A.; Pardalos, P.M.; Migdalas, A.; Pitsoulis, L. Pareto Optimality, Game Theory and Equilibria; Springer: New York, NY, USA, 2008. [Google Scholar] [CrossRef]
- Halton, J. Sequential Monte Carlo. Math. Proc. Camb. Philos. Soc. 1962, 58, 57–78. [Google Scholar] [CrossRef]
- Lu, Y.; Ma, Y.; Wang, J.; Han, L. Task Assignment of UAV Swarm Based on Wolf Pack Algorithm. Appl. Sci. 2020, 10, 8335. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Pang, W.; Li, H.; Li, P.; Zhang, H. A CSCM-SA method for Multi-UAV Task Assignment. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Junwei, Z.; Jianjun, Z. Study on Multi-UAV Task Clustering and Task Planning in Cooperative Reconnaissance. In Proceedings of the 2014 Sixth International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2014; pp. 392–395. [Google Scholar] [CrossRef]
- Huang, K.; Dong, Y.; Wang, D.; Wang, S. Application of Improved Simulated Annealing Genetic Algorithm in Task Assignment of Swarm of Drones. In Proceedings of the 2020 International Conference on Information Science, Parallel and Distributed Systems (ISPDS), Xi’an, China, 14–16 August 2020; pp. 266–271. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, B.; Liu, W.; Zhang, L. Hierarchical Task Assignment of Multiple UAVs with Improved Firefly Algorithm Based on Simulated Annealing Mechanism. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 1943–1948. [Google Scholar] [CrossRef]
- Huo, L.; Zhu, J.; Wu, G.; Li, Z. A Novel Simulated Annealing Based Strategy for Balanced UAV Task Assignment and Path Planning. Sensors 2020, 20, 4769. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.J.; Zhang, Y.F.; Geng, L.; Fuh, J.Y.H.; Teo, S.H. Mission planning for heterogeneous tasks with heterogeneous UAVs. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 1484–1489. [Google Scholar]
- Shiri, H.; Park, J.; Bennis, M. Communication-Efficient Massive UAV Online Path Control: Federated Learning Meets Mean-Field Game Theory. IEEE Trans. Commun. 2020, 68, 6840–6857. [Google Scholar] [CrossRef]
- Luan, H.; Xu, Y.; Liu, D.; Du, Z.; Qian, H.; Liu, X.; Tong, X. Energy Efficient Task Cooperation for Multi-UAV Networks: A Coalition Formation Game Approach. IEEE Access 2020, 8, 149372–149384. [Google Scholar] [CrossRef]
- Ganesan, R.G.; Kappagoda, S.; Loianno, G.; Mordecai, D.K.A. Comparative Analysis of Agent-Oriented Task Assignment and Path Planning Algorithms Applied to Drone Swarms. arXiv 2021, arXiv:2101.05161. [Google Scholar]
- Sanjoy, K.D.; Rosli, O.; Nor Badariyah, A.L. Comparison of different configuration space representations for path planning under combinatorial method. Indones. J. Electr. Eng. Comput. Sci. 2019, 14, 1–8. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, G.; Mei, Y.; Yu, J.; Su, X. UAV path planning using artificial potential field method updated by optimal control theory. Int. J. Syst. Sci. 2016, 47, 1407–1420. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, C.; Xia, Y.; Xiong, H.; Shao, X. An Improved Artificial Potential Field Method for Path Planning and Formation Control of the Multi-UAV Systems. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1129–1133. [Google Scholar] [CrossRef]
- Kitamura, Y.; Tanaka, T.; Kishino, F.; Yachida, M. 3-D path planning in a dynamic environment using an octree and an artificial potential field. In Proceedings of the 1995 IEEE/RSJ International Conference on Intelligent Robots and Systems. Human Robot Interaction and Cooperative Robots, Pittsburgh, PA, USA, 5–9 August 1995; Volume 2, pp. 474–481. [Google Scholar] [CrossRef]
- Fan, B.; Zhang, Z.; Zhang, R. Distributed UAV swarm based on spatial grid model. Chin. J. Aeronaut. 2020, 33, 2828–2830. [Google Scholar] [CrossRef]
- Madridano, Á.; Al-Kaff, A.; Martín, D.; de la Escalera, A. 3D Trajectory Planning Method for UAVs Swarm in Building Emergencies. Sensors 2020, 20, 642. [Google Scholar] [CrossRef]
- Madridano, Á.; Al-Kaff, A.; Gómez, D.M.; de la Escalera, A. Multi-Path Planning Method for UAVs Swarm Purposes. In Proceedings of the 2019 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Cairo, Egypt, 4–6 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Xue, Q.; Cheng, P.; Cheng, N. Offline path planning and online replanning of UAVs in complex terrain. In Proceedings of the 2014 IEEE Chinese Guidance, Navigation and Control Conference, Yantai, China, 8–10 August 2014; pp. 2287–2292. [Google Scholar] [CrossRef]
- Qu, Y.; Pan, Q.; Yan, J. Flight path planning of UAV based on heuristically search and genetic algorithms. In Proceedings of the 2005 31st Annual Conference of IEEE Industrial Electronics Society. IECON 2005, Raleigh, NC, USA, 6–10 November 2005; p. 5. [Google Scholar] [CrossRef]
- Tseng, F.H.; Liang, T.T.; Lee, C.H.; Chou, L.D.; Chao, H.C. A Star Search Algorithm for Civil UAV Path Planning with 3G Communication. In Proceedings of the Tenth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Kitakyushu, Japan, 27–29 August 2014; pp. 942–945. [Google Scholar] [CrossRef]
- Duchoň, F.; Babinec, A.; Kajan, M.; Beňo, P.; Florek, M.; Fico, T.; Jurišica, L. Path Planning with Modified a Star Algorithm for a Mobile Robot. Procedia Eng. 2014, 96, 59–69. [Google Scholar] [CrossRef]
- Bauso, D.; Giarre, L.; Pesenti, R. Multiple UAV cooperative path planning via neuro-dynamic programming. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC) (IEEE Cat. No.04CH37601), Nassau, Bahamas, 14–17 December 2004; Volume 1, pp. 1087–1092. [Google Scholar] [CrossRef]
- Mokrane, A.; Braham, A.C.; Cherki, B. UAV Path Planning Based on Dynamic Programming Algorithm On Photogrammetric DEMs. In Proceedings of the 2020 International Conference on Electrical Engineering (ICEE), Istanbul, Turkey, 25–27 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Jennings, A.L.; Ordonez, R.; Ceccarelli, N. Dynamic programming applied to UAV way point path planning in wind. In Proceedings of the 2008 IEEE International Conference on Computer-Aided Control Systems, San Antonio, TX, USA, 3–5 September 2008; pp. 215–220. [Google Scholar] [CrossRef]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning. In The Annual Research Report; Ames, IA, USA. 1998. Available online: https://api.semanticscholar.org/CorpusID:14744621 (accessed on 28 July 2023).
- Amin, J.; Bokovic, J.; Mehra, R. A Fast and Efficient Approach to Path Planning for Unmanned Vehicles. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, Keyston, CO, USA, 21–24 August 2006; Available online: https://arc.aiaa.org/doi/abs/10.2514/6.2006-6103 (accessed on 28 September 2023).
- Yang, K.; Sukkarieh, S. 3D smooth path planning for a UAV in cluttered natural environments. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 794–800. [Google Scholar] [CrossRef]
- Mangal, K.; Ian, P.; Da-Wei, G. A Suboptimal Path Planning Algorithm Using Rapidly-exploring Random Trees. Int. J. Aerosp. Innov. 2010, 2, 93–104. [Google Scholar] [CrossRef]
- Yang, K.; Sukkarieh, S. Real-time continuous curvature path planning of UAVS in cluttered environments. In Proceedings of the 2008 5th International Symposium on Mechatronics and Its Applications, Amman, Jordan, 27–29 May 2008; pp. 1–6. [Google Scholar] [CrossRef]
- Jin, H.; Chi, W.; Fu, H. Improved RRT–Connect Algorithm for Urban low-altitude UAV Route Planning. J. Phys. Conf. Ser. 2021, 1948, 1–5. [Google Scholar] [CrossRef]
- Sun, Q.; Li, M.; Wang, T.; Zhao, C. UAV path planning based on improved rapidly-exploring random tree. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 6420–6424. [Google Scholar] [CrossRef]
- Chatterjee, A.; Reza, H. Path Planning Algorithm to Enable Low Altitude Delivery Drones at the City Scale. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 750–753. [Google Scholar] [CrossRef]
- Levine, D.; Luders, B.; How, J. Information-Rich Path Planning with General Constraints Using Rapidly-Exploring Randon Trees. In Proceedings of the 2010 AIAA Infotech@Aerospace, Atlanta, GA, USA, 20–22 April 2010. [Google Scholar] [CrossRef]
- Kothari, M.; Postlethwaite, I. A Probabilistically Robust Path Planning Algorithm for UAVs Using Rapidly-Exploring Random Trees. J. Intell. Robot. Syst. 2013, 71, 231–253. [Google Scholar] [CrossRef]
- Wu, Y.; Low, K.H.; Pang, B.; Tan, Q. Swarm-Based 4D Path Planning For Drone Operations in Urban Environments. IEEE Trans. Veh. Technol. 2021, 70, 7464–7479. [Google Scholar] [CrossRef]
- Wang, G.; Li, Q.; Guo, L. Multiple UAVs Routes Planning Based on Particle Swarm Optimization Algorithm. In Proceedings of the 2010 2nd International Symposium on Information Engineering and Electronic Commerce, Ternopil, Ukraine, 23–25 July 2010; pp. 1–5. [Google Scholar] [CrossRef]
- Sonmez, A.; Kocyigit, E.; Kugu, E. Optimal path planning for UAVs using Genetic Algorithm. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; pp. 50–55. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Labonte, G. Comparison of Parallel Genetic Algorithm and Particle Swarm Optimization for Real-Time UAV Path Planning. IEEE Trans. Ind. Inform. 2013, 9, 132–141. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Labonté, M. Fast Genetic Algorithm Path Planner for Fixed-Wing Military UAV Using GPU. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 2105–2117. [Google Scholar] [CrossRef]
- Gao, X.G.; Fu, X.W.; Chen, D.Q. A Genetic-Algorithm-Based Approach to UAV Path Planning Problem. In Proceedings of the 5th WSEAS International Conference on Simulation, Modeling, and Optimization, Corfu, Greece, 17–19 August 2005; pp. 503–507. [Google Scholar]
- Pehlivanoglu, Y.V. A new vibrational genetic algorithm enhanced with a Voronoi diagram for path planning of autonomous UAV. Aerosp. Sci. Technol. 2012, 16, 47–55. [Google Scholar] [CrossRef]
- Meng, H.; Xin, Z. UAV route planning based on the genetic simulated annealing algorithm. In Proceedings of the 2010 IEEE International Conference on Mechatronics and Automation, Xi’an, China, 4–7 August 2010; pp. 788–793. [Google Scholar] [CrossRef]
- Yan, C.; Xiang, X. A Path Planning Algorithm for UAV Based on Improved Q-Learning. In Proceedings of the 2018 2nd International Conference on Robotics and Automation Sciences (ICRAS), Wuhan, China, 23–25 June 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Cui, J.-H.; Wei, R.-X.; Liu, Z.-C.; Zhou, K. UAV Motion Strategies in Uncertain Dynamic Environments: A Path Planning Method Based on Q-Learning Strategy. Appl. Sci. 2018, 8, 2169. [Google Scholar] [CrossRef]
- Yan, C.; Xiang, X.; Wang, C. Towards Real-Time Path Planning through Deep Reinforcement Learning for a UAV in Dynamic Environments. J. Intell. Robot. Syst. 2020, 98, 297–309. [Google Scholar] [CrossRef]
- Villanueva, A.; Fajardo, A. Deep Reinforcement Learning with Noise Injection for UAV Path Planning. In Proceedings of the 2019 IEEE 6th International Conference on Engineering Technologies and Applied Sciences (ICETAS), Kuala Lumpur, Malaysia, 20–21 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, W.; Qiu, W.; Zhou, T.; Shao, X.; Wang, X. Sarsa-based Trajectory Planning of Multi-UAVs in Dense Mesh Router Networks. In Proceedings of the 2019 International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Barcelona, Spain, 21–23 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Luo, W.; Tang, Q.; Fu, C.; Eberhard, P. Deep-Sarsa Based Multi-UAV Path Planning and Obstacle Avoidance in a Dynamic Environment. In Advances in Swarm Intelligence, ICSI 2018. Lecture Notes in Computer Science; Tan, Y., Shi, Y., Tang, Q., Eds.; Springer: Cham, Switzerland, 2018; Volume 10942. [Google Scholar]
- Zhou, W.; Liu, Z.; Li, J.; Xu, X.; Shen, L. Multi-target tracking for unmanned aerial vehicle swarms using deep reinforcement learning. Neurocomputing 2021, 466, 285–297. [Google Scholar] [CrossRef]
- Chen, Y.J.; Chang, D.K.; Zhang, C. Autonomous Tracking Using a Swarm of UAVs: A Constrained Multi-Agent Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2020, 69, 13702–13717. [Google Scholar] [CrossRef]
- Yan, P.; Jia, T.; Bai, C. Searching and Tracking an Unknown Number of Targets: A Learning-Based Method Enhanced with Maps Merging. Sensors 2021, 21, 1076. [Google Scholar] [CrossRef] [PubMed]
- Wu, E.; Sun, Y.; Huang, J.; Zhang, C.; Li, Z. Multi UAV Cluster Control Method Based on Virtual Core in Improved Artificial Potential Field. IEEE Access 2020, 8, 131647–131661. [Google Scholar] [CrossRef]
- Raja, G.; Anbalagan, S.; Narayanan, V.S.; Jayaram, S.; Ganapathisubramaniyan, A. Inter-UAV Collision Avoidance using Deep-Q-Learning in Flocking Environment. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 1089–1095. [Google Scholar] [CrossRef]
- Yijing, Z.; Zheng, Z.; Xiaoyi, Z.; Yang, L. Q learning algorithm based UAV path learning and obstacle avoidence approach. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 3397–3402. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Levine, S. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Unity Real-Time Development Platform. Available online: https://unity.com (accessed on 14 September 2023).
- ML Agents Documentation—Training PPO. Available online: https://github.com/miyamotok0105/unity-ml-agents/blob/master/docs/Training-PPO.md (accessed on 28 July 2023).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Mission Planning | Path Planning | Formation Control/Collision Avoidance |
|---|---|---|---|
| Reinforcement Learning (RL) | √ [29] | √ [62,63,64,65,66,67,68,69,70] | √ [67,72,73] |
| Particle Swarm Optimization (PSO) | √ [11,13,14,15,16,17,18] | √ [55,57] | − |
| Ant Colony Optimization (ACO) | √ [54] | √ [54] | − |
| Wolf Pack Algorithm (WPA) | √ [19] | − | − |
| Genetic Algorithm (GA) | √ [14,19,23,54] | √ [38,56,57,58,59,60] | − |
| Simulated Annealing (SA) | √ [15,21,23,24,25] | √ [61] | − |
| Game Theory | √ [27,28] | − | − |
| Dynamic Programming | − | √ [41,42,43] | − |
| Mixed-Integer Linear Programming (MILP) | √ [26] | − | − |
| Artificial Potential Field (APF) | − | √ [31,32,36,38] | √ [71] |
| Dijkstra’s Algorithm | − | √ [45] | − |
| A* Search Algorithm | − | √ [35,36,37,38,39,40] | − |
| Probabilistic Road Map | − | √ [35,36,37] | − |
| Rapidly Exploring Random Trees | − | √ [44,46,47,48,49,50,51,52,53] | − |
| Octrees | − | √ [33,34] | − |
| Trigger | Reward | Explanation |
|---|---|---|
| Pass at least once through each cell in the task search area within the time limit. | Aim: to reach the task search area, stay inside, and explore it. | |
| Entering the task search area. | ||
| Leaving the task search area. | ||
| Reach max step. | Aim: to avoid stand-by or loitering positions. | |
| Entering the operation area. | Aim: to stay inside the operation area. | |
| Leaving the operation area. |
| Trigger | Reward | Explanation |
|---|---|---|
| Reach a certain number of consecutive steps detecting the task target. | Aim: to reach the search area, stay inside, and explore it. | |
| The task target enters the sensors’ coverage. | ||
| The task target leaves the sensors’ coverage. | ||
| Reach max step. | Aim: to avoid stand-by or loitering positions. | |
| Entering the operation area. | Aim: to stay inside the operation area. | |
| Leaving the operation area. |
| Trigger | Reward | Explanation |
|---|---|---|
| Reach the target point. | Means that it has avoided every hazard. | |
| Reach max step. | Aim: to avoid stand-by or loitering positions. | |
| Colliding with another agent. | Aim: to avoid collisions. | |
| Colliding with the edges of the environment. | ||
| Colliding with an obstacle |
| First Target | Second Target | Third Target | Fourth Target | Fifth Target | |
|---|---|---|---|---|---|
| Target acquisition time | s | s | s | s | s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arranz, R.; Carramiñana, D.; Miguel, G.d.; Besada, J.A.; Bernardos, A.M. Application of Deep Reinforcement Learning to UAV Swarming for Ground Surveillance. Sensors 2023, 23, 8766. https://doi.org/10.3390/s23218766
Arranz R, Carramiñana D, Miguel Gd, Besada JA, Bernardos AM. Application of Deep Reinforcement Learning to UAV Swarming for Ground Surveillance. Sensors. 2023; 23(21):8766. https://doi.org/10.3390/s23218766
Chicago/Turabian StyleArranz, Raúl, David Carramiñana, Gonzalo de Miguel, Juan A. Besada, and Ana M. Bernardos. 2023. "Application of Deep Reinforcement Learning to UAV Swarming for Ground Surveillance" Sensors 23, no. 21: 8766. https://doi.org/10.3390/s23218766
APA StyleArranz, R., Carramiñana, D., Miguel, G. d., Besada, J. A., & Bernardos, A. M. (2023). Application of Deep Reinforcement Learning to UAV Swarming for Ground Surveillance. Sensors, 23(21), 8766. https://doi.org/10.3390/s23218766