
A Comparative Study of Time Series Anomaly Detection Models for Industrial Control Systems

 , ,
, , 
Abstract
:1. Introduction
1.1. Objectives and Contributions
- We implement those five models and optimize them with their hyperparameters.
- We analyze the effects of the training set size on anomaly detection models and found that most models can achieve a high - with a small portion of the training set, which is comparable with the - when the entire training set is used.
1.2. Structure of This Paper
2. Anomaly Detection in Industrial Control Systems
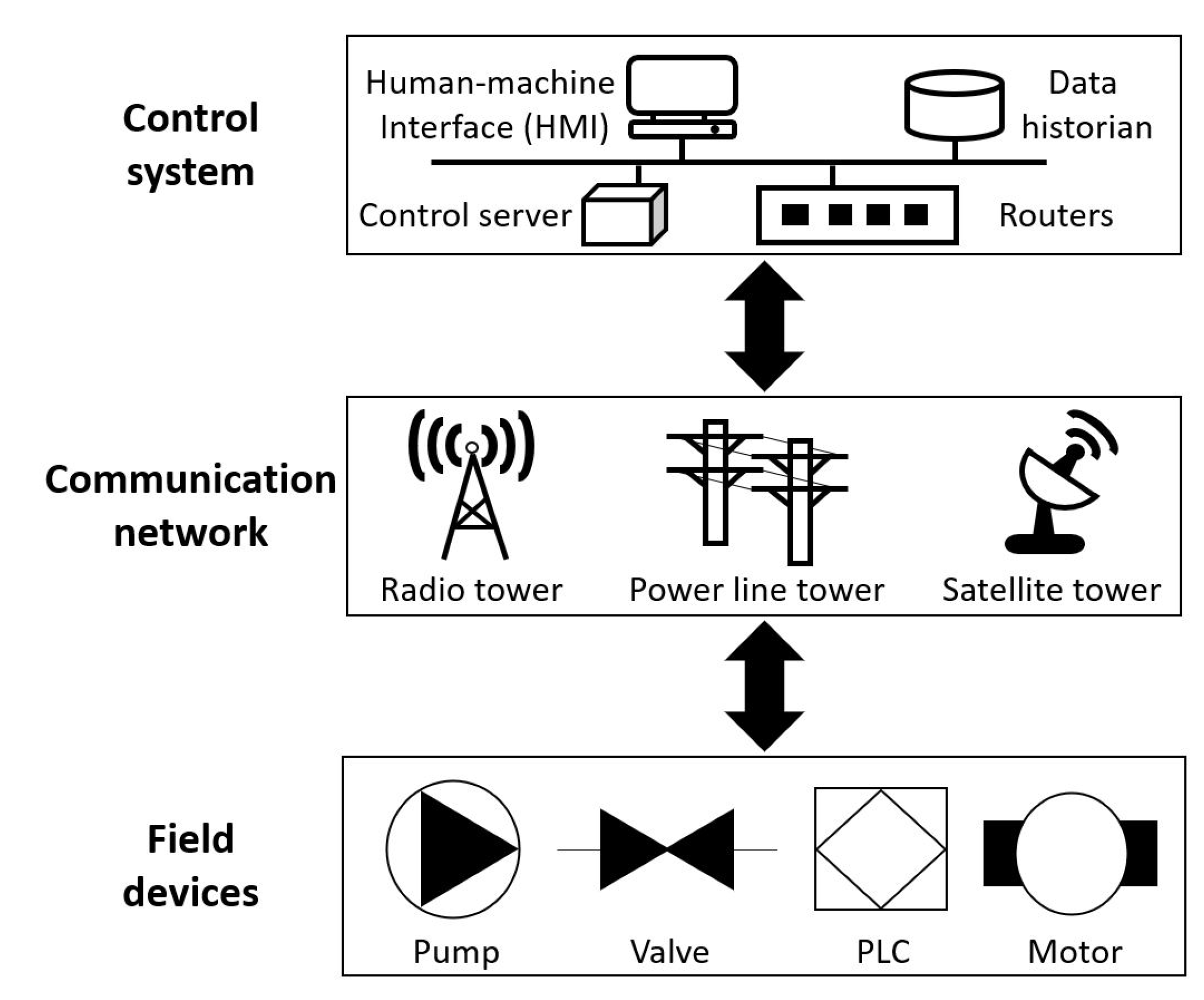
2.1. ICS Architecture
2.2. Anomaly Detection in ICS
3. Related Work
3.1. Cyber-Attacks in ICS
3.2. Defenses against ICS’s Attacks
3.3. Deep Anomaly-Based Detection in ICS
4. Design of the Time Series Anomaly Detection Framework
5. Anomaly Detection Models
- InterFusion [13]: It is an unsupervised-based anomaly detection and interpretation method that simultaneously investigates two main characteristics of MTS. First, a temporal dependency that describes the periodicity attribute of the patterns within each metric. Second, an inter-metric dependency that models the linear and non-linear relations among all metrics of the MTS at each period. Since previous anomaly detection studies often use deterministic approaches (e.g., prediction-based and reconstruction-based) with only one low-dimensional latent embeddings, they are poor in modeling temporal changes or performing inter-metric anomaly detection. Therefore, the InterFusion detection method tackles this problem by providing a new network architecture design. Specifically, they used Hierarchical Variational Auto-Encoder (HVAE) with jointly two low-dimensional latent variables to explicitly and simultaneously learn both temporal and inter-metric representations to capture normal patterns better. In addition, two-view embedding was designed and added to the network to compress MTS characteristics in both time and metric dimensions. To prove the validity of InterFusion for real-world application in the industrial domains, they evaluated its effectiveness over four different MTS datasets (three existing, which are SWaT [18], WADI [50], and SMD [51], while the fourth, ASD, was newly dataset collected during the InterFusion study). InterFusion is one of the current state-of-the-art anomaly detection methods that provide high and reliable performance for monitoring MTS data for industrial applications.
- RANSynCoder [14]: It is an unsupervised real-time anomaly detection framework with large multivariate sets. The system architecture is based on multiple encoder-decoders with a pretraining autoencoder. One of the main characteristics of the framework is that the feature bootstrapping aggregation (bagging) [52] is utilized to randomly select the sets of input features and build multiple autoencoders to reconstruct more extensive time series output with smaller sets of input. For anomaly decision, the framework infers anomalies by determining whether each dimension factor of the input is involved between the upper and lower bound of the reconstructed threshold, and when it is not involved, the factor is labeled as an anomaly. To determine the final anomaly decision, the framework applies majority voting to compute the majority label of the dimension factors and finally generate the overall decision. Other than anomaly inference, the framework also provides anomaly localization to identify a significant feature or attribute related to the anomaly alert by measuring the localization score of each feature or attribute.
- GDN [15]: It is an unsupervised-based anomaly detection method with Graph Attention Network (GAT). GDN makes up for the weak points caused by not explicitly learning with data inter-relationships shown in time series-based features using the graph network method. In addition, each node in the graph structure has sensor embedding, representing each sensor’s unique characteristics. Relationship with the specific sensor is defined to compute the cosine similarity between the target embedding node and other embedding nodes. The similarity score of the embedding vectors utilizes to select the top k neighbor nodes with closed relation to a specific node. The graph updates the state of edges and nodes, considering a node’s information with its neighbors in the training step. Each node computes the anomaly score aggregating a single anomaly score for each tick. If the anomaly score deviates from a fixed threshold, the time tick is an anomaly.
- LSTM-ED [16]: It is an LSTM-based Encoder-Decoder scheme for anomaly detection in multi-sensor MTS datasets. It uses an unsupervised learning method to train its initial network only with unlabeled normal data. Its training involves an encoder learning a fixed-length vector representation of the input MTS dataset, which will help the decoder reconstruct the data accurately. The reconstruction error vector at any future time instance is used to compute the likelihood of anomaly at that point using Maximum Likelihood Estimation (MLE). The intuition behind this is that since the reconstruction error of the trained model is based on normal instances, it produces higher reconstruction errors when anomalous sequences are given. LSTM-ED also provides a threshold mechanism for computed anomaly scores, allowing further tuning of the detection system within a supervised setting to maximize the score.
- USAD [12]: It is an unsupervised-based anomaly detection method based on an autoencoder (AE) architecture whose learning is inspired by GANs. USAD provides a new architecture design using two-phase with adversarial training. Training in USAD is done with two autoencoders, and . The first autoencoder generates the reconstructed data for the original input dataset using a pair of encoders and decoders. The second autoencoder, , intentionally generates anomaly data by adapting adversarial training to the output of the decoder and then giving feedback to the encoder again. In the first phase, the objective is to train each AE to reproduce the input. The second phase aims to train to distinguish the actual data from the data produced from . This two-phase training aims to minimize the reconstruction error of W and the difference between W and the reconstruction output of , respectively. In this process, the model learns anomalies that cannot be seen in the original training dataset, obtaining better results. The anomaly score used by USAD for testing is used by multiplying the results obtained after training two autoencoders.
6. Evaluation
6.1. Datasets
6.2. Evaluation Metrics
6.3. Data Preprocessing
- Data normalization (Normalization): It is one of the preprocessing approaches where the values of each feature are either scaled or transformed to make an equal contribution. Because, in an MTS dataset, many attributes have a different scale, data normalization is required.
- Constant feature exclusion (Feature exclusion): In our work, we exclude constant features, referring to unchanged features, because they would be unnecessary to build a machine learning model. Therefore, a possible strategy is to exclude those features for training. The constant features in each dataset are presented in Table 3.
6.4. Model Optimization
6.5. Performance Results
6.6. Effects of Training Set Size
7. Discussion
- InterFusion and RANSynCoder show superiority in detection accuracy with the SWaT and HAI datasets. InterFusion might be preferred when is more significant than . However, we note that InterFusion requires expensive costs in training and testing times compared with the other models. Hence, we recommend using RANSynCoder when training and testing times are critical to deploying a model in a target ICS environment.
- Overall, values are significantly worse than values in all five models. We surmise that each model can sufficiently learn the characteristics of normal data, but it cannot detect new and unseen attacks effectively because the models are well-trained on only normal data. Similarly, our classification result shows relatively higher and lower when evaluating the performance of each model with both normal and attack samples. We note that identifying attack samples would be more challenging because our model is trained with the normal dataset alone. Therefore, normal samples are relatively well-recognized than attack samples by each model.
- We found that a subset (e.g., 40% or 60%) of the entire training set would produce a performance comparable with the entire training dataset. We surmise that this is because SWaT and HAI datasets have some regular periodic normal behaviors. Therefore, a part of the entire training set could be sufficiently used to build an anomaly detection model that achieves reasonable detection accuracy.
- All the models’ training times proportionally increase with the training set size. Therefore, we can control a model’s training time with the training set’s size when it is important to reduce the training time. Model retraining would be necessary to maintain low error rates over time. To minimize the cost of retraining, we might need to determine the optimal size of the samples for training.
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nawrocki, M.; Schmidt, T.C.; Wählisch, M. Uncovering Vulnerable Industrial Control Systems from the Internet Core. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020. [Google Scholar]
- Barbieri, G.; Conti, M.; Tippenhauer, N.O.; Turrin, F. Sorry, Shodan is not Enough! Assessing ICS Security via IXP Network Traffic Analysis. arXiv 2020, arXiv:2007.01114. [Google Scholar]
- Di Pinto, A.; Dragoni, Y.; Carcano, A. TRITON: The First ICS Cyber Attack on Safety Instrument Systems. In Proceedings of the Black Hat USA, Las Vegas, NV, USA, 4–9 August 2018. [Google Scholar]
- Sha, K.; Wei, W.; Yang, T.A.; Wang, Z.; Shi, W. On Security Challenges and Open Issues in Internet of Things. Future Gener. Comput. Syst. 2018, 83, 326–337. [Google Scholar] [CrossRef]
- Lab, K. Threat Landscape for Industrial Automation Systems in the Second Half of 2016; Technical Report; AO Kaspersky Lab: Moscow, Russia, 1997. [Google Scholar]
- Carcano, A.; Coletta, A.; Guglielmi, M.; Masera, M.; Fovino, I.N.; Trombetta, A. A Multidimensional Critical State Analysis for Detecting Intrusions in SCADA Systems. IEEE Trans. Ind. Inform. 2011, 7, 179–186. [Google Scholar] [CrossRef]
- Zhou, C.; Huang, S.; Xiong, N.; Yang, S.H.; Li, H.; Qin, Y.; Li, X. Design and Analysis of Multimodel-Based Anomaly Intrusion Detection Systems in Industrial Process Automation. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 1345–1360. [Google Scholar] [CrossRef]
- Clarke, E.M.; Zuliani, P. Statistical Model Checking for Cyber-Physical Systems. In Proceedings of the International Symposium on Automated Technology for Verification and Analysis, Taipei, Taiwan, 11–14 October 2011. [Google Scholar]
- Ponomarev, S.; Atkison, T. Industrial Control System Network Intrusion Detection by Telemetry Analysis. IEEE Trans. Dependable Secur. Comput. 2015, 13, 252–260. [Google Scholar] [CrossRef]
- Zhang, F.; Kodituwakku, H.A.D.E.; Hines, J.W.; Coble, J. Multilayer Data-Driven Cyber-Attack Detection System for Industrial Control Systems Based on Network, System, and Process Data. IEEE Trans. Ind. Inform. 2019, 15, 4362–4369. [Google Scholar] [CrossRef]
- MR, G.R.; Somu, N.; Mathur, A.P. A Multilayer Perceptron Model for Anomaly Detection in Water Treatment Plants. Int. J. Crit. Infrastruct. Prot. 2020, 31, 100393. [Google Scholar]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: Unsupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020. [Google Scholar]
- Li, Z.; Zhao, Y.; Han, J.; Su, Y.; Jiao, R.; Wen, X.; Pei, D. Multivariate Time Series Anomaly Detection and Interpretation using Hierarchical Inter-Metric and Temporal Embedding. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021. [Google Scholar]
- Abdulaal, A.; Liu, Z.; Lancewicki, T. Practical Approach to Asynchronous Multivariate Time Series Anomaly Detection and Localization. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021. [Google Scholar]
- Deng, A.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Robles-Durazno, A.; Moradpoor, N.; McWhinnie, J.; Russell, G. A supervised energy monitoring-based machine learning approach for anomaly detection in a clean water supply system. In Proceedings of the 2018 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Glasgow, UK, 11–12 June 2018; pp. 1–8. [Google Scholar]
- Mathur, A.P.; Tippenhauer, N.O. SWaT: A Water Treatment Testbed for Research and Training on ICS Security. In Proceedings of the International Workshop on Cyber-Physical Systems for Smart Water Networks, Vienna, Austria, 11 April 2016. [Google Scholar]
- Shin, H.K.; Lee, W.; Yun, J.H.; Min, B.G. Two ICS Security Datasets and Anomaly Detection Contest on the HIL-based Augmented ICS Testbed. In Proceedings of the Cyber Security Experimentation and Test Workshop, Virtual, 9 August 2021. [Google Scholar]
- Fu, T.C. A Review on Time Series Data Mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A Review on Outlier/Anomaly Detection in Time Series Data. ACM Comput. Surv. 2021, 54, 1–33. [Google Scholar] [CrossRef]
- Borges, H.; Akbarinia, R.; Masseglia, F. Anomaly Detection in Time Series. Trans. Large-Scale-Data Knowl. Centered Syst. 2021, 54, 1–33. [Google Scholar]
- Inoue, J.; Yamagata, Y.; Chen, Y.; Poskitt, C.M.; Sun, J. Anomaly Detection for a Water Treatment System using Unsupervised Machine Learning. In Proceedings of the IEEE International Conference on Data Mining Workshops, New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Firoozjaei, M.D.; Mahmoudyar, N.; Baseri, Y.; Ghorbani, A.A. An evaluation framework for industrial control system cyber incidents. Int. J. Crit. Infrastruct. Prot. 2022, 36, 100487. [Google Scholar] [CrossRef]
- Karnouskos, S. Stuxnet worm impact on industrial cyber-physical system security. In Proceedings of the IECON 2011—37th Annual Conference of the IEEE Industrial Electronics Society, Melbourne, Australia, 7–10 November 2011; pp. 4490–4494. [Google Scholar]
- Lee, R.M.; Assante, M.; Conway, T. Crashoverride: Analysis of the Threat to Electric Grid Operations; Dragos Inc.: Hanover, MD, USA, 2017. [Google Scholar]
- Geiger, M.; Bauer, J.; Masuch, M.; Franke, J. An analysis of black energy 3, Crashoverride, and Trisis, three malware approaches targeting operational technology systems. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 1537–1543. [Google Scholar]
- Robles-Durazno, A.; Moradpoor, N.; McWhinnie, J.; Russell, G. WaterLeakage: A stealthy malware for data exfiltration on industrial control systems using visual channels. In Proceedings of the 2019 IEEE 15th International Conference on Control and Automation (ICCA), Edinburgh, UK, 16–19 July 2019; pp. 724–731. [Google Scholar]
- Chen, Q.; Zhou, M.; Cai, Z.; Su, S. Compliance Checking Based Detection of Insider Threat in Industrial Control System of Power Utilities. In Proceedings of the 2022 7th Asia Conference on Power and Electrical Engineering (ACPEE), Hangzhou, China, 15–17 April 2022; pp. 1142–1147. [Google Scholar]
- Giraldo, J.; Urbina, D.; Cardenas, A.; Valente, J.; Faisal, M.; Ruths, J.; Tippenhauer, N.O.; Sandberg, H.; Candell, R. A survey of physics-based attack detection in cyber-physical systems. ACM Comput. Surv. CSUR 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Komninos, N.; Philippou, E.; Pitsillides, A. Survey in smart grid and smart home security: Issues, challenges and countermeasures. IEEE Commun. Surv. Tutorials 2014, 16, 1933–1954. [Google Scholar] [CrossRef]
- Tan, S.; De, D.; Song, W.Z.; Yang, J.; Das, S.K. Survey of security advances in smart grid: A data driven approach. IEEE Commun. Surv. Tutorials 2016, 19, 397–422. [Google Scholar] [CrossRef]
- Cintuglu, M.H.; Mohammed, O.A.; Akkaya, K.; Uluagac, A.S. A survey on smart grid cyber-physical system testbeds. IEEE Commun. Surv. Tutorials 2016, 19, 446–464. [Google Scholar] [CrossRef]
- He, H.; Yan, J. Cyber-physical attacks and defences in the smart grid: A survey. IET Cyber Phys. Syst. Theory Appl. 2016, 1, 13–27. [Google Scholar] [CrossRef] [Green Version]
- Rushanan, M.; Rubin, A.D.; Kune, D.F.; Swanson, C.M. Sok: Security and privacy in implantable medical devices and body area networks. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 524–539. [Google Scholar]
- AlTawy, R.; Youssef, A.M. Security tradeoffs in cyber physical systems: A case study survey on implantable medical devices. IEEE Access 2016, 4, 959–979. [Google Scholar] [CrossRef]
- Kocabas, O.; Soyata, T.; Aktas, M.K. Emerging security mechanisms for medical cyber physical systems. IEEE/ACM Trans. Comput. Biol. Bioinform. 2016, 13, 401–416. [Google Scholar] [CrossRef]
- Han, S.; Xie, M.; Chen, H.H.; Ling, Y. Intrusion detection in cyber-physical systems: Techniques and challenges. IEEE Syst. J. 2014, 8, 1052–1062. [Google Scholar]
- Mitchell, R.; Chen, I.R. A Survey of Intrusion Detection Techniques for Cyber-Physical Systems. ACM Comput. Surv. 2014, 46, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Wang, Z.; Shen, B.; Alsaadi, F.E.; Hayat, T. Recent advances on filtering and control for cyber-physical systems under security and resource constraints. J. Frankl. Inst. 2016, 353, 2451–2466. [Google Scholar] [CrossRef]
- He, H.; Maple, C.; Watson, T.; Tiwari, A.; Mehnen, J.; Jin, Y.; Gabrys, B. The security challenges in the IoT enabled cyber-physical systems and opportunities for evolutionary computing & other computational intelligence. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 1015–1021. [Google Scholar]
- Kayan, H.; Nunes, M.; Rana, O.; Burnap, P.; Perera, C. Cybersecurity of industrial cyber-physical systems: A review. ACM Comput. Surv. CSUR 2022, 54, 1–35. [Google Scholar] [CrossRef]
- Nedeljkovic, D.; Jakovljevic, Z. CNN based method for the development of cyber-attacks detection algorithms in industrial control systems. Comput. Secur. 2022, 114, 102585. [Google Scholar] [CrossRef]
- Umer, M.A.; Junejo, K.N.; Jilani, M.T.; Mathur, A.P. Machine learning for intrusion detection in industrial control systems: Applications, challenges, and recommendations. Int. J. Crit. Infrastruct. Prot. 2022, 2022, 100516. [Google Scholar] [CrossRef]
- Wang, W.; Wang, C.; Wang, Z.; Yuan, M.; Luo, X.; Kurths, J.; Gao, Y. Abnormal detection technology of industrial control system based on transfer learning. Appl. Math. Comput. 2022, 412, 126539. [Google Scholar] [CrossRef]
- Wang, Y.; Amin, M.M.; Fu, J.; Moussa, H.B. A novel data analytical approach for false data injection cyber-physical attack mitigation in smart grids. IEEE Access 2017, 5, 26022–26033. [Google Scholar] [CrossRef]
- Junejo, K.N.; Yau, D. Data driven physical modelling for intrusion detection in cyber physical systems. In Proceedings of the Singapore Cyber-Security Conference (SG-CRC) 2016, Singapore, 14–15 January 2016; pp. 43–57. [Google Scholar]
- Elgendi, I.; Hossain, M.F.; Jamalipour, A.; Munasinghe, K.S. Protecting cyber physical systems using a learned MAPE-K model. IEEE Access 2019, 7, 90954–90963. [Google Scholar] [CrossRef]
- Ahmed, C.M.; Ochoa, M.; Zhou, J.; Mathur, A.P.; Qadeer, R.; Murguia, C.; Ruths, J. Noiseprint: Attack detection using sensor and process noise fingerprint in cyber physical systems. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4–8 June 2018; pp. 483–497. [Google Scholar]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Prashanth, S.; Shitharth, S.; Praveen Kumar, B.; Subedha, V.; Sangeetha, K. Optimal Feature Selection Based on Evolutionary Algorithm for Intrusion Detection. SN Comput. Sci. 2022, 3, 1–9. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K. Xgboost: Extreme gradient boosting. R Package Version 0.4-2 2015, 1, 1–4. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Ikeda, Y.; Tajiri, K.; Nakano, Y.; Watanabe, K.; Ishibashi, K. Estimation of Dimensions Contributing to Detected Anomalies with Variational Autoencoders. arXiv 2018, arXiv:1811.04576. [Google Scholar]
- Zhai, S.; Cheng, Y.; Lu, W.; Zhang, Z. Deep Structured Energy Based Models for Anomaly Detection. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Shitharth, S. An enhanced optimization based algorithm for intrusion detection in SCADA network. Comput. Secur. 2017, 70, 16–26. [Google Scholar]
- Estabrooks, A.; Japkowicz, N. A Mixture-of-Experts Framework for Learning from Imbalanced Data Sets. In Proceedings of the International Symposium on Intelligent Data Analysis, Cascais, Portugal, 13–15 September 2001. [Google Scholar]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on Deep Learning with Class Imbalance. J. Big Data 2019, 6, 1–54. [Google Scholar] [CrossRef]
- Macas, M.; Chunming, W. Enhanced Cyber-Physical Security through Deep Learning Techniques. In Proceedings of the CPS Summer School PhD Workshop, Alghero, Italy, 23 September 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Features | Training Samples | Testing Samples | Prop. of Anomalies |
|---|---|---|---|---|
| SWaT | 51 | 322,288 | 449,919 | 11.9% |
| HAI | 79 | 921,603 | 402,005 | 2.2% |
| Model | Venue | Precision | Recall | F-score | AUC |
|---|---|---|---|---|---|
| InterFusion [13] | KDD | ✓ | ✓ | ✓ | ✓ |
| MAD-GAN [50] | ICANN | ✓ | ✓ | ✓ | - |
| RANSynCoder [14] | KDD | ✓ | ✓ | ✓ | - |
| GDN [15] | AAAI | ✓ | ✓ | ✓ | - |
| USAD [12] | KDD | ✓ | ✓ | ✓ | - |
| DAGMM [56] | ICLR | ✓ | ✓ | ✓ | - |
| LSTM-NDT [57] | KDD | ✓ | ✓ | ✓ | - |
| VAEpro [58] | AAAI | - | - | ✓ | - |
| DSEBMs [59] | ICML | ✓ | ✓ | ✓ | - |
| MSCRED [60] | AAAI | ✓ | ✓ | ✓ | ✓ |
| OmniAnomaly [51] | KDD | ✓ | ✓ | ✓ | - |
| IWP-CSO with HNA-NN [61] | KDD | ✓ | ✓ | ✓ | - |
| Datasets | Constant Features |
|---|---|
| SWaT | P102, P201, P202, P204, P206, P401, P403, P404, P502, P601, P603 |
| HAI | P1_PCV02D, P2_VTR01, P2_VTR04, P4_HT_PS, P1_PP02D |
| P4_ST_PS, P1_PP02R, P2_MSD, P2_VTR03, P2_TripEx, P1_STSP | |
| P2_VTR02, P1_FCV02D, P3_LL, P2_AutoGo, P1_PP01BD, P3_LH | |
| P1_PP01AD, P1_PP01AR, P2_OnOff, P2_RTR, P2_ManualGo |
| Model | SWaT | HAI | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Epoch | Batch Size | Window Size | Learning Rate | Threshold | Normalization | Feature Exclusion | Epoch | Batch Size | Window Size | Learning Rate | Threshold | Normalization | Feature Exclusion | |
| InterFusion | 15 | 100 | 30 | −28,972 | ✓ | - | 30 | 100 | 100 | ✓ | - | |||
| RANSynCoder | 10 | 180 | 5 | 7.366 | ✓ | ✓ | 10 | 180 | 5 | 5.798 | ✓ | - | ||
| GDN | 10 | 256 | 40 | 10,776 | ✓ | ✓ | 50 | 100 | 60 | 2 | 2095 | ✓ | ✓ | |
| LSTM-ED | 30 | 40 | 20 | 5892 | ✓ | - | 30 | 200 | 4 | 1 | −103.95 | ✓ | - | |
| USAD | 10 | 512 | 6 | ✓ | - | 10 | 6 | 512 | 1 | 8 | ✓ | - | ||
| Model | F1-Score | Precision | Recall | FNR | FPR | TP | FN | FP |
|---|---|---|---|---|---|---|---|---|
| InterFusion | 90.7% (92.8% [13]) | 91.1% | 90.3% | 9.7% | 1.2% | 49,309 | 5312 | 4799 |
| RANSynCoder | 82.7% (84.0% [14]) | 96.6% | 72.3% | 27.7% | 0.4% | 39,511 | 15,110 | 1380 |
| GDN | 80.6% (81.0% [15]) | 97.8% | 68.5% | 31.5% | 0.2% | 37,403 | 17,218 | 836 |
| LSTM-ED | 81.2% (76.0% [64]) | 98.9% | 68.8% | 31.2% | 0.1% | 37,586 | 17,035 | 410 |
| USAD | 75.0% (79.1% [12]) | 91.6% | 63.6% | 36.4% | 0.8% | 34,856 | 19,940 | 3208 |
| Model | F1-Score | Precision | Recall | FNR | FPR | TP | FN | FP |
|---|---|---|---|---|---|---|---|---|
| InterFusion | 78.9% | 74.4% | 83.9% | 16.1% | 0.6% | 7504 | 1443 | 2579 |
| RANSynCoder | 82.9% | 89.1% | 77.6% | 22.4% | 0.2% | 6452 | 1866 | 793 |
| GDN | 59.7% | 78.5% | 48.3% | 54.0% | 0.2% | 4323 | 4624 | 1054 |
| LSTM-ED | 71.7% | 79.1% | 65.5% | 34.5% | 0.4% | 5864 | 3083 | 1547 |
| USAD | 58.8% | 76.0% | 48.0% | 71.3% | 0.2% | 2447 | 6096 | 821 |
| Model | SWaT | HAI | ||
|---|---|---|---|---|
| Training Time (s) | Testing Time (s) | Training Time (s) | Testing Time (s) | |
| InterFusion | 6032 | 3563 | 107,550 | 8961 |
| RANSynCoder | 3945 | 13 | 12,100 | 20 |
| GDN | 471 | 361 | 2832 | 482 |
| LSTM-ED | 6787 | 215 | 1354 | 79 |
| USAD | 2578 | 8 | 2653 | 15 |
| Model | Training Set Size | F1-Score | Precision | Recall | FNR | FPR | TP | FN | FP |
|---|---|---|---|---|---|---|---|---|---|
| 20% | 88.6% | 94.1% | 83.6% | 1.6% | 0.7% | 45,690 | 8931 | 2861 | |
| 40% | 89.2% | 96.9% | 82.7% | 17.3% | 0.4% | 45,168 | 9453 | 1458 | |
| InterFusion | 60% | 89.8% | 94.3% | 85.8% | 14.2% | 0.7% | 46,845 | 7776 | 5585 |
| 80% | 83.2% | 88.5% | 78.5% | 21.5% | 1.4% | 42,895 | 11,726 | 5585 | |
| 100% | 90.7% | 91.1% | 90.3% | 9.7% | 1.2% | 49,309 | 5312 | 4799 | |
| 20% | 83.2% | 92.1% | 75.8% | 24.2% | 0.9% | 41,418 | 13,203 | 3546 | |
| 40% | 81.7% | 94.3% | 72.2% | 27.9% | 0.6% | 39,411 | 15,210 | 2398 | |
| RANSynCoder | 60% | 80.5% | 97.8% | 68.3% | 31.7% | 0.2% | 37,322 | 17,299 | 829 |
| 80% | 82.2% | 96.3% | 71.7% | 28.3% | 0.4% | 39,181 | 15,440 | 1489 | |
| 100% | 82.7% | 96.6% | 72.3% | 27.7% | 0.4% | 39,511 | 15,110 | 1380 | |
| 20% | 76.9% | 96.8% | 63.8% | 36.2% | 0.2% | 34,828 | 19,793 | 1162 | |
| 40% | 77.8% | 97.8% | 64.5% | 35.5% | 0.1% | 35,212 | 19,409 | 778 | |
| GDN | 60% | 78.3% | 96.7% | 65.7% | 34.2% | 0.3% | 35,909 | 18,712 | 1206 |
| 80% | 78.1% | 96.6% | 65.6% | 34.4% | 0.3% | 35,843 | 18,778 | 1272 | |
| 100% | 80.6% | 97.8% | 68.5% | 31.5% | 0.2% | 37,403 | 17,218 | 836 | |
| 20% | 62.8% | 82.9% | 50.6% | 49.4% | 1.4% | 27,626 | 26,995 | 5695 | |
| 40% | 68.9% | 81.3% | 59.8% | 40.2% | 1.8% | 32,645 | 21,978 | 7492 | |
| LSTM-ED | 60% | 76.2% | 98.9% | 62.0% | 38.0% | 0.1% | 33,860 | 20,761 | 369 |
| 80% | 77.4% | 99.0% | 63.6% | 36.4% | 0.1% | 34,729 | 19,892 | 348 | |
| 100% | 81.2% | 98.9% | 68.8% | 31.2% | 0.1% | 37,586 | 17,035 | 410 | |
| 20% | 30.6% | 19.1% | 77.1% | 23.0% | 45.2% | 42,216 | 12,580 | 178,658 | |
| 40% | 74.6% | 92.1% | 62.7% | 37.3% | 0.7% | 34,343 | 20,453 | 2954 | |
| USAD | 60% | 74.3% | 92.1% | 62.3% | 37.7% | 0.7% | 34,119 | 20,677 | 2909 |
| 80% | 74.7% | 92.5% | 62.6% | 37.4% | 0.7% | 34,297 | 20,499 | 2792 | |
| 100% | 75.1% | 91.6% | 63.7% | 36.4% | 0.8% | 34,856 | 19,940 | 3208 |
| Model | Training Set Size | F1-Score | Precision | Recall | FNR | FPR | TP | FN | FP |
|---|---|---|---|---|---|---|---|---|---|
| 20% | 75.9% | 67.6% | 86.5% | 13.5% | 0.9% | 7738 | 1209 | 3712 | |
| 40% | 77.1% | 66.4% | 91.9% | 8.1% | 1.1% | 8226 | 721 | 4158 | |
| InterFusion | 60% | 75.8% | 69.4% | 83.6% | 16.4% | 0.8% | 7476 | 1471 | 3301 |
| 80% | 80.2% | 74.8% | 86.4% | 13.5% | 0.7% | 7734 | 1213 | 2610 | |
| 100% | 78.9% | 74.4% | 83.9% | 16.1% | 0.6% | 7504 | 1443 | 2579 | |
| 20% | 69.1% | 86.7% | 57.4% | 42.6% | 0.2% | 4775 | 3543 | 731 | |
| 40% | 88.5% | 89.2% | 87.8% | 12.9% | 0.3% | 7305 | 1013 | 882 | |
| RANSynCoder | 60% | 71.3% | 89.7% | 59.1% | 40.9% | 0.2% | 4918 | 3400 | 563 |
| 80% | 70.8% | 77.5% | 65.1% | 34.9% | 0.5% | 5417 | 2901 | 1572 | |
| 100% | 82.9% | 89.1% | 77.6% | 22.4% | 0.2% | 6452 | 1866 | 793 | |
| 20% | 31.2% | 85.0% | 19.1% | 80.9% | 0.1% | 1708 | 7239 | 301 | |
| 40% | 45.5% | 63.3% | 35.5% | 64.5% | 0.5% | 3178 | 5769 | 1846 | |
| GDN | 60% | 53.1% | 65.4% | 44.4% | 55.6% | 0.5% | 3975 | 4972 | 2054 |
| 80% | 55.9% | 73.3% | 45.3% | 54.7% | 0.4% | 4055 | 4893 | 1472 | |
| 100% | 59.7% | 78.5% | 48.3% | 54.0% | 0.2% | 4323 | 4624 | 1054 | |
| 20% | 15.9% | 9.0% | 71.3% | 28.6% | 16.4% | 6383 | 2564 | 64,573 | |
| 40% | 72.2% | 79.0% | 66.4% | 33.6% | 0.4% | 5944 | 3003 | 1581 | |
| LSTM-ED | 60% | 71.8% | 80.3% | 64.9% | 35.1% | 0.4% | 5807 | 3140 | 1421 |
| 80% | 72.3% | 80.0% | 65.9% | 34.1% | 0.4% | 5895 | 3052 | 1476 | |
| 100% | 71.7% | 79.1% | 65.5% | 34.5% | 0.4% | 5864 | 3083 | 1547 | |
| 20% | 60.5% | 92.5% | 44.9% | 73.0% | 0.1% | 2229 | 6244 | 383 | |
| 40% | 58.6% | 94.8% | 42.4% | 73.8% | 0.1% | 2231 | 6312 | 354 | |
| USAD | 60% | 59.7% | 81.5% | 47.1% | 70.9% | 0.1% | 2485 | 6058 | 608 |
| 80% | 61.1% | 88.4% | 46.7% | 71.8% | 0.1% | 2407 | 6136 | 467 | |
| 100% | 58.8% | 76.0% | 48.0% | 71.3% | 0.2% | 2447 | 6096 | 821 |
| Model | Type | F1-Score for SWaT | F1-Score for HAI |
|---|---|---|---|
| InterFusion | VAE | 90.7% | 78.9% |
| RANSynCoder | AE | 82.7% | 82.9% |
| GDN | GNN | 80.6% | 59.7% |
| LSTM-ED | LSTM | 81.2% | 71.7% |
| USAD | AE | 75.0% | 58.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Alawami, M.A.; Kim, E.; Oh, S.; Park, J.; Kim, H. A Comparative Study of Time Series Anomaly Detection Models for Industrial Control Systems. Sensors 2023, 23, 1310. https://doi.org/10.3390/s23031310
Kim B, Alawami MA, Kim E, Oh S, Park J, Kim H. A Comparative Study of Time Series Anomaly Detection Models for Industrial Control Systems. Sensors. 2023; 23(3):1310. https://doi.org/10.3390/s23031310
Chicago/Turabian StyleKim, Bedeuro, Mohsen Ali Alawami, Eunsoo Kim, Sanghak Oh, Jeongyong Park, and Hyoungshick Kim. 2023. "A Comparative Study of Time Series Anomaly Detection Models for Industrial Control Systems" Sensors 23, no. 3: 1310. https://doi.org/10.3390/s23031310
APA StyleKim, B., Alawami, M. A., Kim, E., Oh, S., Park, J., & Kim, H. (2023). A Comparative Study of Time Series Anomaly Detection Models for Industrial Control Systems. Sensors, 23(3), 1310. https://doi.org/10.3390/s23031310