
Distributed Data Integrity Verification Scheme in Multi-Cloud Environment


Abstract
:1. Introduction
- This paper designs and proposes a blockchain-based distributed data integrity verification in the multi-cloud environment that increases the verification sampling rate without increasing the computation and communication costs by enabling data verification with multi-verifiers rather than single verifiers. By doing so, the burden is distributed to several verifiers.
- This scheme supports batch verification to increase the efficiency of proof validation and lower the cost for the cloud organizer (CO).
- This paper presents security and performance analyses of distributed data integrity verification protocols under the multi-verifier case. The security analysis consists of a proof of correctness of the equations and unforgeability by malicious CSPs, verifiers, and COs. The performance analysis consists of evaluating computation and communication costs, experiment results, gas usage estimation, and a comparative analysis of existing works.
2. Related Works
3. Preliminaries
3.1. Bilinear Pairings
- Bilinearity: , and , for all ,
- Computability: There is an efficient algorithm to compute , for all .
- Non-degeneracy: There exists such that .
- Discrete Logarithm Problem (DLP): Given two group elements P and Q, find an integer , such that whenever such an integer exists.
- Computational Diffie–Hellman Problem (CDHP): For , given , compute .
- Inverse Computational Diffie–Hellman Problem (Inv-CDHP): For , given , compute .
- Square Computational Diffie–Hellman Problem (Squ-CDHP): For , given , compute .
3.2. ZSS Signature
- ParamGen. Let be a cyclic additive group and be multiplicative cyclic groups with a prime order q, P is the generator of the group . The mapping is a bilinear map. H is a general hash function. So, the system parameters are .
- KeyGen. Randomly selects and computes . The public key is .
- Sign. Given a secret key x and a message m, computes signature .
- Ver. Given a public key , a message m, and a signature S, verify if . The verification works because of the following Equation (1).
4. Properties Requirements
- Public verifiability: the size of the stored data may vary and there is a possibility that users’ data are large. Furthermore, users may have limitations on their resources that can cause an expensive verification process cost. Therefore, the verification mechanism should not only allow users that can verify the data but also allow other parties.
- Blockless verification: stored data size varies and the verifier may not have enough resources to process a large amount of data. The verification scheme must ensure the verifier does not need to download all the data for the verification process. Furthermore, it will decrease the communication overhead at the server and increase the efficiency of the verification scheme.
- Privacy-preserving: prevent data leaks to the verifier during the verification process.
- Batch verification: decreases communication costs for the verifier and the cloud server.
- Reliable verifiers: verifiers play a significant role in data integrity verification schemes. The results will determine the trustability of a CSP as a data host for many users. It is important to ensure that there is no way the verifier could collude with the CSP to deceive users or with users to deceive the CSP. For instance, it can be achieved by performing a decentralized verification process to provide transparency.
- Reliable cloud organizer (CO): in a multi-cloud environment, the cloud organizer manages the interaction between the user and CSPs [6]. It is important to ensure the organizer sends the right data to the intended CSP. Likewise, send the correct proof to the verifier during the verification process.
- Distributed verification: under the case of the multi-cloud environment, stored users’ data may be huge. It is necessary to increase the verification sampling rate without escalating the costs required on the verifier’s side. One way to perform that is by enabling distributed verification to multi-verifiers. Doing so will distribute the burden of verification tasks and not solely rely on one verifier.
5. Proposed Scheme
- Setup phase.
- -
- ParamGen. Let be a Gap Diffie–Hellman (GDH) group and be multiplicative cyclic groups with prime order q; P is the generator of a group . The mapping is a bilinear map with some properties. H is a general hash function such as the SHA family or MD5. The system parameters are .
- -
- KeyGen. Randomly selects as a secret key and computes as a public key.
- -
- User generates ZSS signature for each data block as shown in Equation (2).
- Registration Phase.In the beginning, each user, CO, and verifier need to register to the smart contract once by sending their blockchain address as shown in Figure 2. After that, they will receive an ID so-called and , respectively, that will be used in the storing and verification phases. These IDs are assigned by smart contract internal generation rules. Each ID starts with a different first digit to determine the category. The first digit for is 1, is 2, and is 3, while the rest digit shows the serial number of the ID.

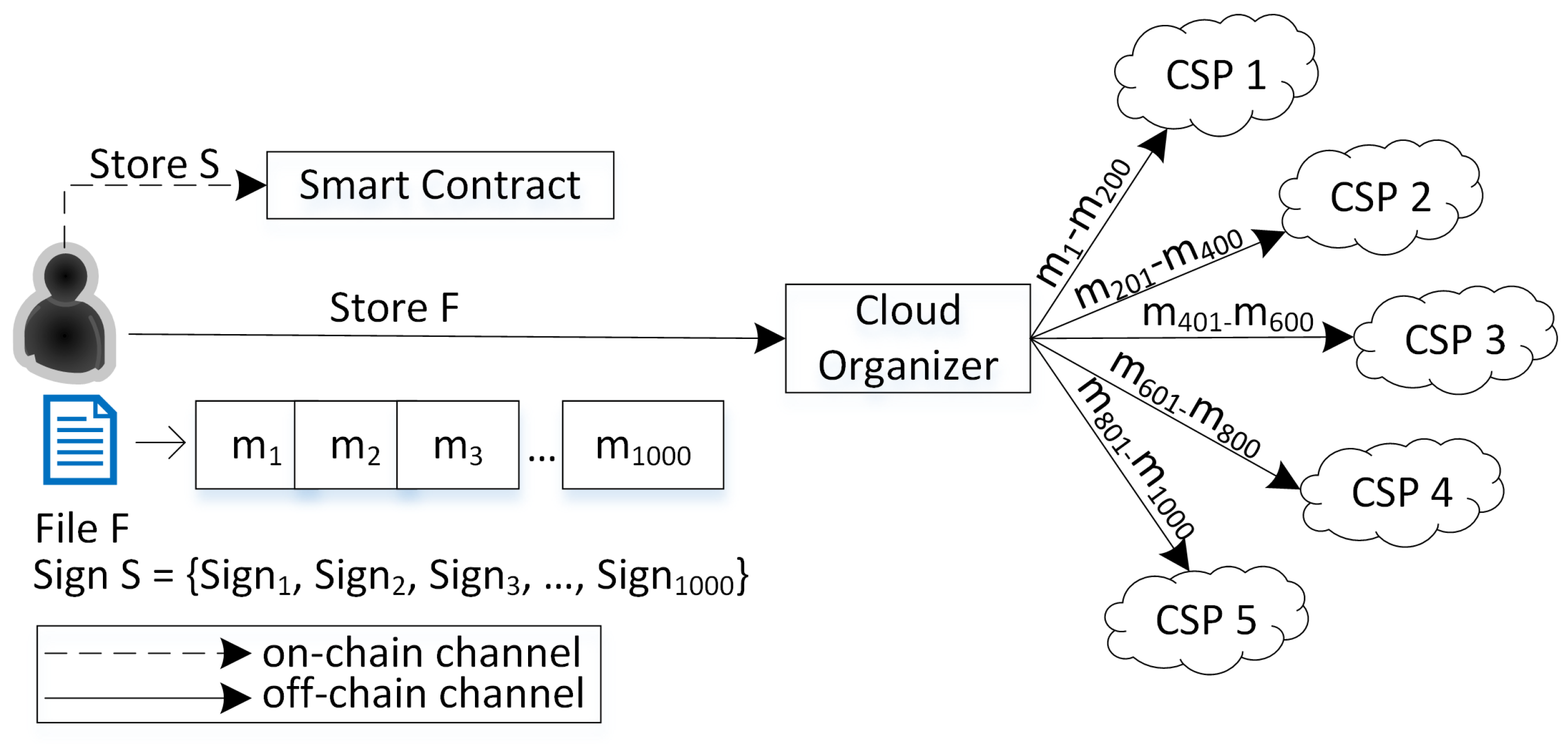
- Storing Phase.The details of the data storing phase are shown in Figure 3 as follows.
- In this phase, the user divides the file F into n blocks of m. For the general case, let each block size be 4 KB. So, the file .
- Then, he will generate a signature for each data block. So, the set of signatures is .
- Subsequently, the user stores the signatures in the smart contract by sending the and S values.
- Then, the smart contract will assign an value, a unique identity number for each file F, to the user. is assigned by the smart contract internal generation rule that begins with 4 as the first digit. The rest of the digits show the serial number of the .
- Next, the user sends file F and also the signature of F that is signed with the private key of the user () to the CO.
- Upon receiving F from the user, CO verifies the signature first using the user’s public key. If valid, CO continues the process; otherwise, it rejects it. The signature verification process is important to prove that the sender is the real user and to prevent the adversary from impersonating the real sender.
- The next process involves CO distributing it to several CSPs with ranges showing the beginning of the data blocks, while shows the last data blocks that will send to the CSP. The CO also sends along the digital signature of the message that is signed with the CO’s private key (). Subsequently, the CO stores the list of data blocks and the corresponding CSPs in the local database.
- The CSP will verify the file from the CO using the CO’s public key. If valid, store the file; otherwise, reject it.

- Verification Phase.The details of the data verification phase are shown in Figure 4 as follows.
- The user sends a data integrity verification (DIV) request by transmitting , , and the signature of the corresponding message that is signed with the user’s private key () as parameters to the CO.
- (a.) Then, CO verifies the signature of the message received from the user using the user’s public key. (b.) If valid, it will obtain the number of blocks of the corresponding ; otherwise, the CO rejects it. The signature verification process is important to prove that the sender is a real user and also prevents the adversary from impersonating the real sender.
- After that, the CO publishes a DIV task in the smart contract by sending , and as parameters.
- The smart contract processes the request and assigns a to be returned to the CO, which is a unique number for each task.
- Since it is a broadcast message, all the nodes that join the blockchain network will receive this notification. Several verifiers will then apply to perform the verification task for the CO by sending the corresponding , and the signature of the message that is signed by the verifier’s private key ().
- (a.) Subsequently, CO verifies the message from the verifier with the verifier’s public key. If valid, continue; otherwise, reject it. (b.) Afterward, CO sets the verifiers that will perform the DIV task by sending and Q as parameters to the smart contract, where a is the number of verifiers and Q is the set of assigned to perform a verification task.
- The CO then sends and the signature of the that is signed with CO’s private key () to each selected verifier, where k is an index of the proof that will be generated by the corresponding CSP, I is the set of challenged data blocks so , and c is the total number of challenged data blocks for each CSP. contains the corresponding CSP information. So, in the given scenario, the CO will send two to verifier-1, first with , I with blocks, and of CSP 1. Second, , I with blocks and of CSP 2.
- (a.) After receiving from the CO, the verifier will verify the signature of the received message using the CO’s public key. If valid, continue; otherwise, reject it. (b.) Then, each verifier will send challenge and the signature of the message that is signed with verifier’s private key () to the corresponding CSPs that have data blocks needed to be verified, where is a random number in and i is an index of randomly selected data blocks to be verified in the set of I.Figure 4. Data verification phase.
![Sensors 23 01623 g004]()
- (a.) Upon receiving from the verifier, the CSP verifies the received message’s signature first using the verifier’s public key. If valid, continue; otherwise, reject it. (b.) Afterward, the CSP will compute the proof as shown in Equation (3). In the above scenario, for verifier-1, CSP 1 generates blocks 1–200 and CSP 2 generates blocks 201–250, respectively.
- Later, the CSP sends proof to the corresponding verifier along with the signature of the message that is signed with the CSP’s private key () to the verifier. So, based on the given scenario, verifier-1 will receive from CSP 1 and from CSP 2.
- (a.) The verifier then verifies the received message’s signature using the CSP’s public key. If valid, continue; otherwise, reject it. (b.) Next, the verifier requests the ZSS signature S value to the smart contract according to the ranges of data blocks to be verified. So, based on the scenario above, verifier-1 will request S for blocks 1–250.
- In response to the verifier, the smart contract sends the corresponding S value.
- After that, the verifier checks the validity of each pair of proofs and as shown in Equation (5). So, from the example above, verifier-1 will perform the bilinear pairing for proofs , and ,, respectively. If the equation holds, the data blocks in the corresponding CSP are safe; otherwise, the verifier will know which CSP failed to prove the integrity of the user’s data.
- Consequently, the verifier reports the results to the smart contract.
- Then, each verifier sends proofs , and the signature of the message signed with the corresponding verifier’s private key to the CO.
- (a.) In this step, the CO will verify the received message’s signature using the verifier’s public key. If valid, continue; otherwise, reject it. (b.) Next, in this step, the CO receives several proofs and from multiple verifiers and will start the batch verification. In the above example, there are four verifiers. The batch verification in this work supports aggregating proofs of file F from multi-verifiers. In the process, the CO will check if Equation (6) holds, where K is a set of proofs = and t is the total number of proofs that the CO received from verifiers. To calculate t, first, let the number of blocks stored in the CSP and number of verifiers. If equals 0, then . Otherwise, check if , then ; otherwise, . In the given scenario, the CO receives eight pairs of proofs and .
- If it holds, update the verification task’s status in the smart contract to success; otherwise, it failed.
- The CO reports the DIV result to the corresponding user and the message’s signature that is signed with CO’s private key ().
- After receiving the result from the CO, the user will verify the signature using the CO’s public key. If valid, the user is assured that the message is indeed from the CO; otherwise, it rejects it.

6. Security Analysis
6.1. Correctness
6.2. Unforgeability
- A malicious CSP may lose the user’s stored data and try to hide it from the users or delete the rarely accessed user’s data to reduce the storage burden. So, when a malicious CSP receives a challenge from the verifier in the verification process, it may try to forge proof to deceive the verifier.
- A malicious verifier may collude with CSP to deceive the user/CO or with the user/CO to deceive the CSP. So, this untrusted verifier may try to forge the proof to manipulate the verification results.
- A malicious CO may collude with the verifier to deceive the user or collude with the user to deceive the verifier. Therefore, the malicious CO may try to forge the validation results of aggregation proofs from verifiers.
- A malicious CSP cannot forge proof because every time the verifiers send a challenge, a random value r will be assigned in the variable. The CSP must generate proof based on r from the verifiers as shown in Equation (3) and the value r is different for each data shard. Even if we further assume that the malicious CSP forges , namely , the verification process performed by the verifiers in Equation (5) shows that the verifiers must validate with another variable, proof generated by verifiers, which also consist of a r value. Therefore, the cannot ensure Equation (5) will hold. Another case is when a malicious CSP tries to deceive the verifier by replacing the challenged data block with another data block when the former data block is broken. Accordingly, the proof becomesSo, Equation (5) can be represented asHence, we have . However, cannot be equal to due to the anti-collision property of the hash function. Therefore, it is infeasible to ensure Equation (10) will hold and the proof from CSP cannot pass the verification process.
- A malicious verifier cannot forge verification results because the verifier must generate proof that requires , which is a signature generated by the user as shown in Equation (4). The values are stored in the smart contract, which is very difficult to be tampered with. Even we further assume that the malicious verifier forges proof to generate variable , the malicious verifier needs the user’s secret key x and original message . The proposed scheme provides privacy-preserving and blockless verification properties, meaning the verifier is capable of verifying the data without receiving the original message from the user or CSP. So, without the possession of those two variables, x and , it is impossible to generate a forged and enable equation to hold. Both the malicious CSP and verifier cannot calculate the user’s private key from the public key under the Inv-CDHP assumption. Furthermore, in the verification process, the verifier must validate with another variable, proof generated by CSP as shown in Equation (5). Therefore, it is infeasible to cause equation to hold where .
- A malicious CO cannot forge validation results because he needs to aggregate several proofs from verifiers and CSPs as shown in Equation (6). As explained above, proof is generated by CSPs and proof is generated by the verifiers. Each proof required a random value r that was generated randomly by each verifier as shown in Equations (3) and (4). In addition, these values did not send to the CO in the protocol. Therefore, the CO will not cause Equation (6) to hold.
7. Performance Evaluation
7.1. Computation Cost
7.2. Communication Cost
7.3. Experiment Results
7.4. Gas Usage Estimation Cost
7.5. Comparative Analysis
- Batch verification. The proposed protocols support batch verification as shown in Equation (6) where the CO will validate proofs from the verifiers. Compared to other work, two out of ten protocols also support batch verification, which is [6,19]. However, eight other protocols only verify the proof from CSPs one by one for each data block.
- Multi-cloud environment and reliable CO. The proposed protocols [6,18] provide data verification in a multi-cloud environment. In addition, in a multi-cloud environment, a CO is assigned to distribute the files from the user to several CSPs. The proposed protocols and the other two supported reliable CO by utilizing blockchain technology. Unfortunately, eight other protocols did not. They mostly focused on verification in a single cloud environment and no CO was needed.
- Reliable verifiers and blockchain-based. The proposed scheme and six out of ten other works support reliable verifiers by employing blockchain technology. This paper can design a decentralized verification process through blockchain to provide transparency between users and CSPs. It removes the intermediary and enables peer-to-peer interactions between nodes, therefore enhancing trust. The other four works [17,20,21,23] did not provide these two points because they rely on the credibility of the third-party auditor (TPA), which is not ideal in real case circumstances.
- Distributed verification. The proposed protocol is the only one that can accomplish it. The other ten protocols were unable to. This paper fulfills it by enabling multi-verifiers to participate in a verification task, whereas the other protocols were interested in data verification by a single verifier. This paper also has performed the verification simulation using 5, 10, 15, and 20 verifiers and demonstrated that the proposed scheme could complete the verification tasks faster with less computation and communication costs than the single verifier.
7.6. Case Study
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| GDH group | |
| Multiplicative cyclic group | |
| P | Generator of group |
| x | ZSS Signature secret key |
| ZSS Signature public key | |
| F | Stored user’s file |
| n | Numbers of data blocks |
| User’s data index of i | |
| Generated ZSS Signature | |
| S | Set of |
| Digital signature using the secret key of the actor | |
| a | Number of verifiers |
| c | Number of challenged data blocks |
| I | Set of challenged data blocks |
| Proof generated by CSP | |
| Proof generated by verifier | |
| k | Index of generated proof or |
| K | Set of k |
| t | Number of proofs |
| v | Number of blocks stored in CSP |
References
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing. Available online: https://bit.ly/2KNOBjs (accessed on 17 June 2022).
- Hong, J.; Dreibholz, T.; Schenkel, J.A.; Hu, J.A. An overview of multi-cloud computing. In Proceedings of the Workshops of the International Conference on Advanced Information Networking and Applications, Matsue, Japan, 27–29 March 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1055–1068. [Google Scholar]
- Garg, N.; Bawa, S. Comparative analysis of cloud data integrity auditing protocols. J. Netw. Comput. Appl. 2016, 66, 17–32. [Google Scholar]
- Sookhak, M.; Gani, A.; Talebian, H.; Akhunzada, A.; Khan, S.U.; Buyya, R.; Zomaya, A.Y. Remote data auditing in cloud computing environments: A survey, taxonomy, and open issues. ACM Comput. Surv. (CSUR) 2015, 47, 1–34. [Google Scholar]
- He, K.; Shi, J.; Huang, C.; Hu, X. Blockchain based data integrity verification for cloud storage with T-merkle tree. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, New York, NY, USA, 2–4 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 65–80. [Google Scholar]
- Zhang, C.; Xu, Y.; Hu, Y.; Wu, J.; Ren, J.; Zhang, Y. A blockchain-based multi-cloud storage data auditing scheme to locate faults. IEEE Trans. Cloud Comput. 2021, 10, 2252–2263. [Google Scholar] [CrossRef]
- Xie, G.; Liu, Y.; Xin, G.; Yang, Q. Blockchain-Based Cloud Data Integrity Verification Scheme with High Efficiency. Secur. Commun. Netw. 2021, 2021, 9921209. [Google Scholar] [CrossRef]
- Darrell Etherington. Amazon AWS S3 Outage Is Breaking Things for a Lot of Websites and Apps. Available online: https://tcrn.ch/3r2xr8c (accessed on 17 June 2022).
- Michael Arrington. Gmail Disaster: Reports of Mass Email Deletions. Available online: https://tcrn.ch/3UzmMPS (accessed on 17 June 2022).
- Zack Whittaker. Amazon Web Services Suffers Partial Outage. Available online: https://zd.net/3C36Eil (accessed on 17 June 2022).
- Rich Miller. Amazon Addresses EC2 Power Outages. Available online: https://bit.ly/3R0HncM (accessed on 17 June 2022).
- Darlene Storm. Epsilon Breach: Hack of the Century? Available online: https://bit.ly/3dF97WP (accessed on 17 June 2022).
- Schwartz, M.J. 6 Worst Data Breaches of 2011. Available online: https://bit.ly/3r2c86u (accessed on 17 June 2022).
- Ateniese, G.; Burns, R.; Curtmola, R.; Herring, J.; Kissner, L.; Peterson, Z.; Song, D. Provable data possession at untrusted stores. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 31 October–2 November 2007; pp. 598–609. [Google Scholar]
- Juels, A.; Kaliski, B.S., Jr. PORs: Proofs of retrievability for large files. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 31 October–2 November 2007; pp. 584–597. [Google Scholar]
- Shin, S.; Kwon, T. A Survey of Public Provable Data Possession Schemes with Batch Verification in Cloud Storage. J. Internet Serv. Inf. Secur. 2015, 5, 37–47. [Google Scholar]
- Ping, Y.; Zhan, Y.; Lu, K.; Wang, B. Public data integrity verification scheme for secure cloud storage. Information 2020, 11, 409. [Google Scholar] [CrossRef]
- Yang, X.; Pei, X.; Wang, M.; Li, T.; Wang, C. Multi-replica and multi-cloud data public audit scheme based on blockchain. IEEE Access 2020, 8, 144809–144822. [Google Scholar] [CrossRef]
- Li, S.; Liu, J.; Yang, G.; Han, J. A blockchain-based public auditing scheme for cloud storage environment without trusted auditors. Wirel. Commun. Mob. Comput. 2020, 2020, 8841711. [Google Scholar] [CrossRef]
- Garg, N.; Bawa, S.; Kumar, N. An efficient data integrity auditing protocol for cloud computing. Future Gener. Comput. Syst. 2020, 109, 306–316. [Google Scholar] [CrossRef]
- Yu, Y.; Li, Y.; Yang, B.; Susilo, W.; Yang, G.; Bai, J. Attribute-based cloud data integrity auditing for secure outsourced storage. IEEE Trans. Emerg. Top. Comput. 2017, 8, 377–390. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, J. Blockchain based data integrity verification for large-scale IoT data. IEEE Access 2019, 7, 164996–165006. [Google Scholar] [CrossRef]
- Zhao, X.P.; Jiang, R. Distributed machine learning oriented data integrity verification scheme in cloud computing environment. IEEE Access 2020, 8, 26372–26384. [Google Scholar] [CrossRef]
- Zhang, F.; Safavi-Naini, R.; Susilo, W. An Efficient Signature Scheme from Bilinear Pairings and Its Applications. In Public Key Cryptography—PKC 2004; Springer: Berlin/Heidelberg, Germany, 2004; Volume 2947, pp. 277–290. [Google Scholar] [CrossRef]
- Ganache Overview. Available online: https://www.trufflesuite.com/docs/ganache/overview (accessed on 20 February 2020).
- The PBC Go Wrapper. Available online: https://pkg.go.dev/github.com/Nik-U/pbc (accessed on 22 September 2022).
- Crypto-ECDSA. Available online: https://pkg.go.dev/crypto/ecdsa (accessed on 22 September 2022).
- Concourse Open Community. ETH Gas Station. Available online: https://bit.ly/3zySXVm (accessed on 31 October 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | User, CO, CSP, Verifier |
|---|---|
| CPU | Intel Core i5-7200U @2.50 GHz |
| Memory | 4 GB |
| OS | Ubuntu 16.04 Xenial |
| Go | v.1.19.3 |
| Library | PBC Go Wrapper, crypto-ecdsa |
| Actor | Computation Cost |
|---|---|
| User | |
| CSP | |
| Verifier | |
| CO |
| Operations | AT (ms) | Library |
|---|---|---|
| 0.001354 | PBC Go Wrapper | |
| 1.464053 | PBC Go Wrapper | |
| 0.000185 | PBC Go Wrapper | |
| 0.000794 | PBC Go Wrapper | |
| P | 1.125117 | PBC Go Wrapper |
| 0.046341 | Crypto-ecdsa | |
| 0.101769 | Crypto-ecdsa |
| User | Communication Cost |
|---|---|
| Send | |
| Send verification request + | |
| CSP | Communication Cost |
| Send proof | |
| Verifier | Communication Cost |
| Send | |
| Send proof | |
| CO | Communication Cost |
| Send | |
| Send |
| Number | Function | Estimation Gas Usage | Estimation Fee (USD) * | Actor |
|---|---|---|---|---|
| 1 | AddNewUser | 50,733 | 1.15 | User |
| 2 | AddNewVerifier | 50,733 | 1.15 | Verifier |
| 3 | AddNewCO | 50,733 | 1.15 | CO |
| 4 | AddNewUserData | 107,399 | 2.42 | CO |
| 5 | AddTask | 171,257 | 3.86 | CO |
| 6 | AssignVerifier | 179,948 | 4.09 | CO |
| 7 | SetTaskState | 32,141 | 0.72 | CO |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Witanto, E.N.; Stanley, B.; Lee, S.-G. Distributed Data Integrity Verification Scheme in Multi-Cloud Environment. Sensors 2023, 23, 1623. https://doi.org/10.3390/s23031623
Witanto EN, Stanley B, Lee S-G. Distributed Data Integrity Verification Scheme in Multi-Cloud Environment. Sensors. 2023; 23(3):1623. https://doi.org/10.3390/s23031623
Chicago/Turabian StyleWitanto, Elizabeth Nathania, Brian Stanley, and Sang-Gon Lee. 2023. "Distributed Data Integrity Verification Scheme in Multi-Cloud Environment" Sensors 23, no. 3: 1623. https://doi.org/10.3390/s23031623
APA StyleWitanto, E. N., Stanley, B., & Lee, S. -G. (2023). Distributed Data Integrity Verification Scheme in Multi-Cloud Environment. Sensors, 23(3), 1623. https://doi.org/10.3390/s23031623