

A Dense Mapping Algorithm Based on Spatiotemporal Consistency

Abstract
:1. Introduction
- We propose a local map extraction and fusion strategy based on spatiotemporal consistency. The local map is extracted through the inter-frame pose observability and temporal continuity. This eliminates the dependence on the common-view relationship of the pose estimation algorithm and is suitable for various pose estimation algorithms.
- A dynamic superpixel extraction. We dynamically adjust the parameters of superpixel extraction based on spatial continuity and temporal stability, achieving continuous and stable time efficiency.
- The normal constraints are added to the surfel weight initialization and fusion so that surfels with better viewing angles are kept during map fusion.
- The experimental results on the ICL-NUIM dataset show that the partial reconstruction accuracy is improved by approximately 27–43%. The experimental results on the KITTI dataset show that the method proposed in this paper is effective. The system achieves a greater than 15Hz real-time performance, which is an improvement of approximately 13%.
2. Related Work
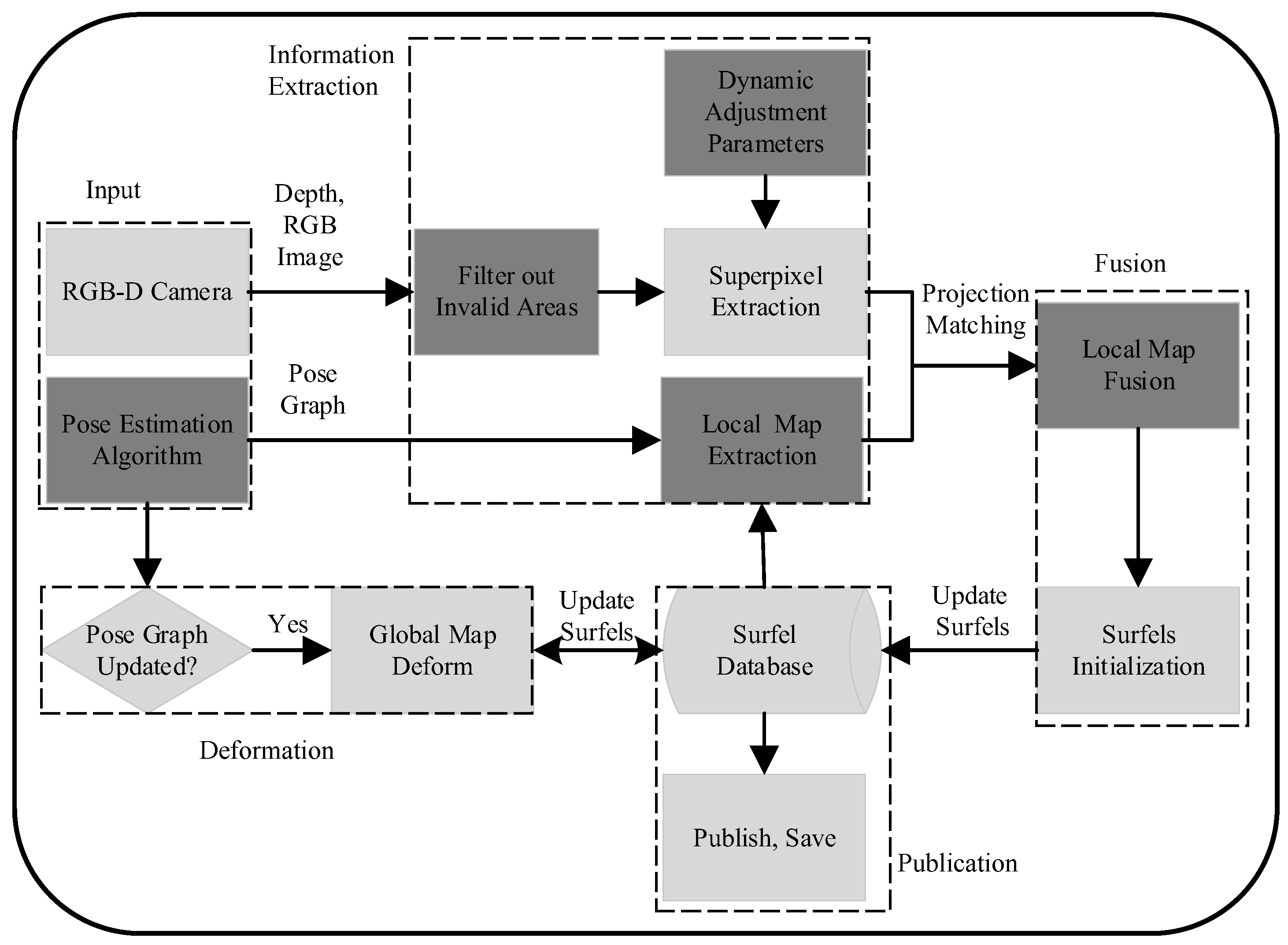
3. System Overview
3.1. System Input
3.2. Global Consistency Deformation
3.3. Superpixel and Local Map Extraction
3.4. Map Fusion
3.5. Map Publication
4. Methods and Principles
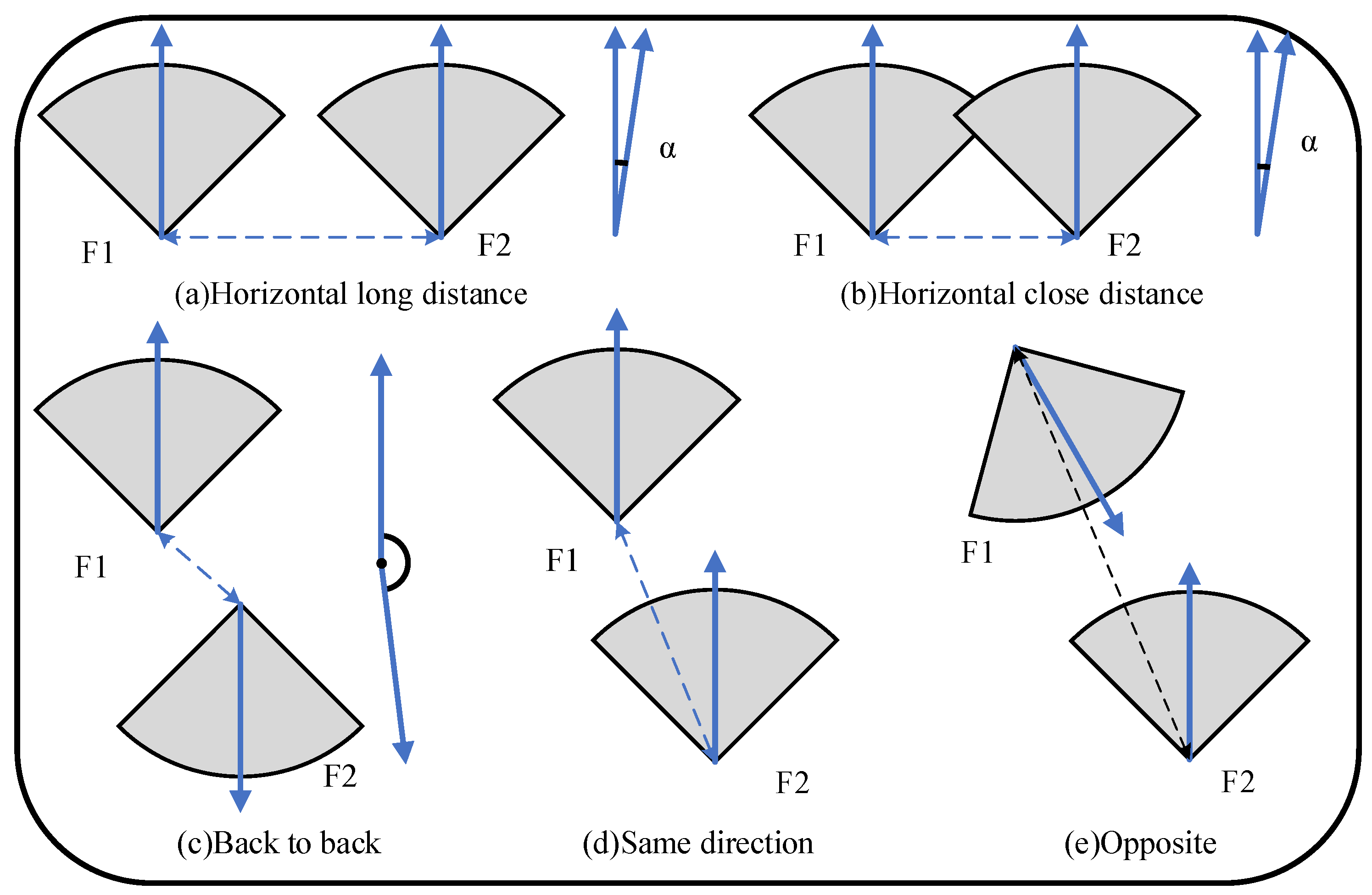
4.1. Spatiotemporally Consistent Local Map Extraction
4.1.1. In the Same Direction Horizontally
4.1.2. In the Same Direction or Opposite
4.1.3. Back to Back
4.1.4. Summary
| Algorithm1. Local Map Extraction. |
|
4.2. Dynamic Superpixel Extraction
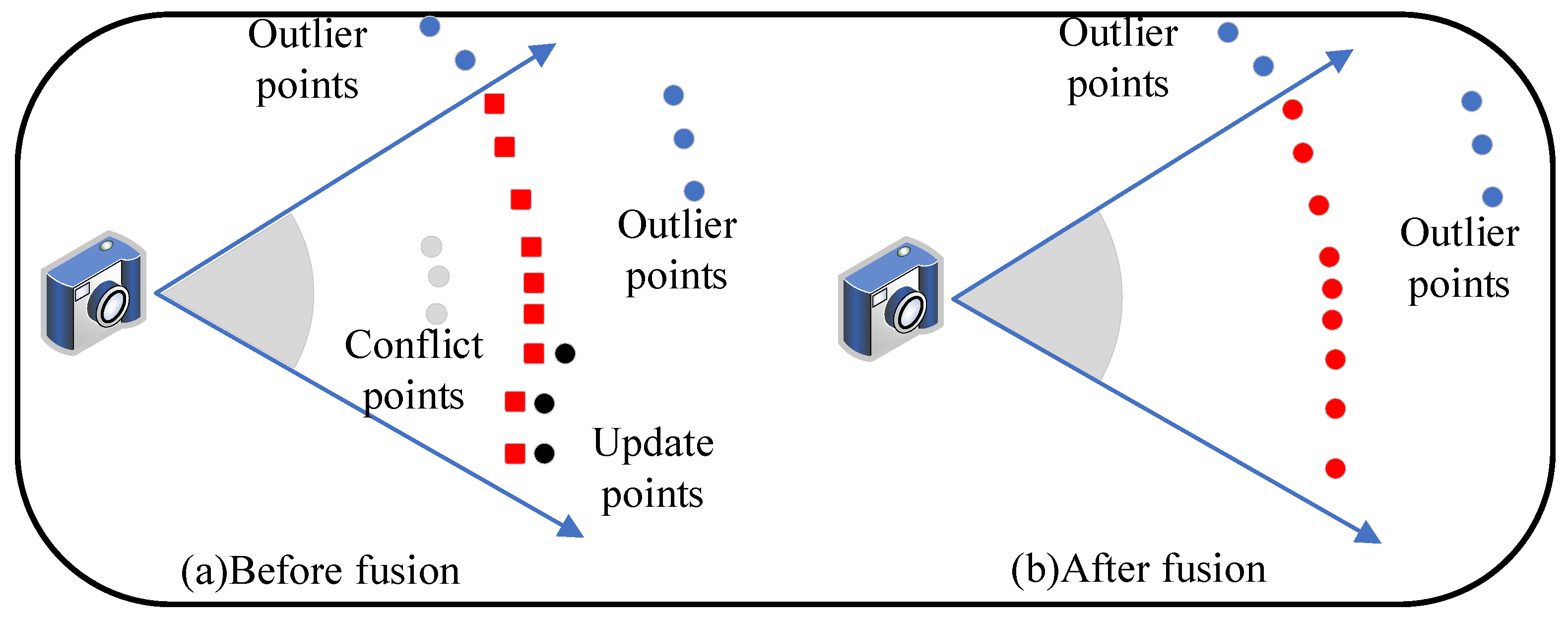
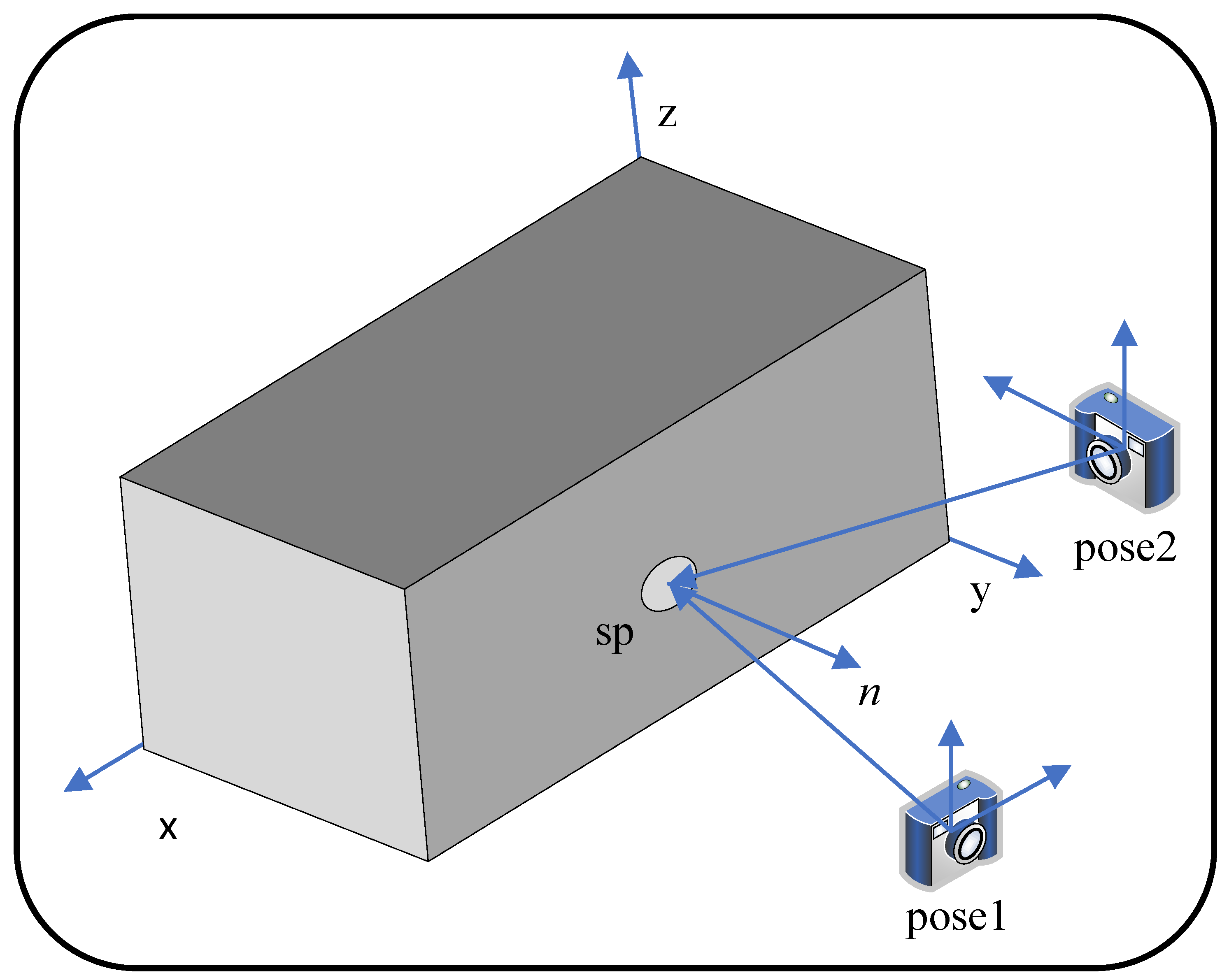
4.3. Projection Matching and Optimal Observation Normal Map Fusion
5. Experiments
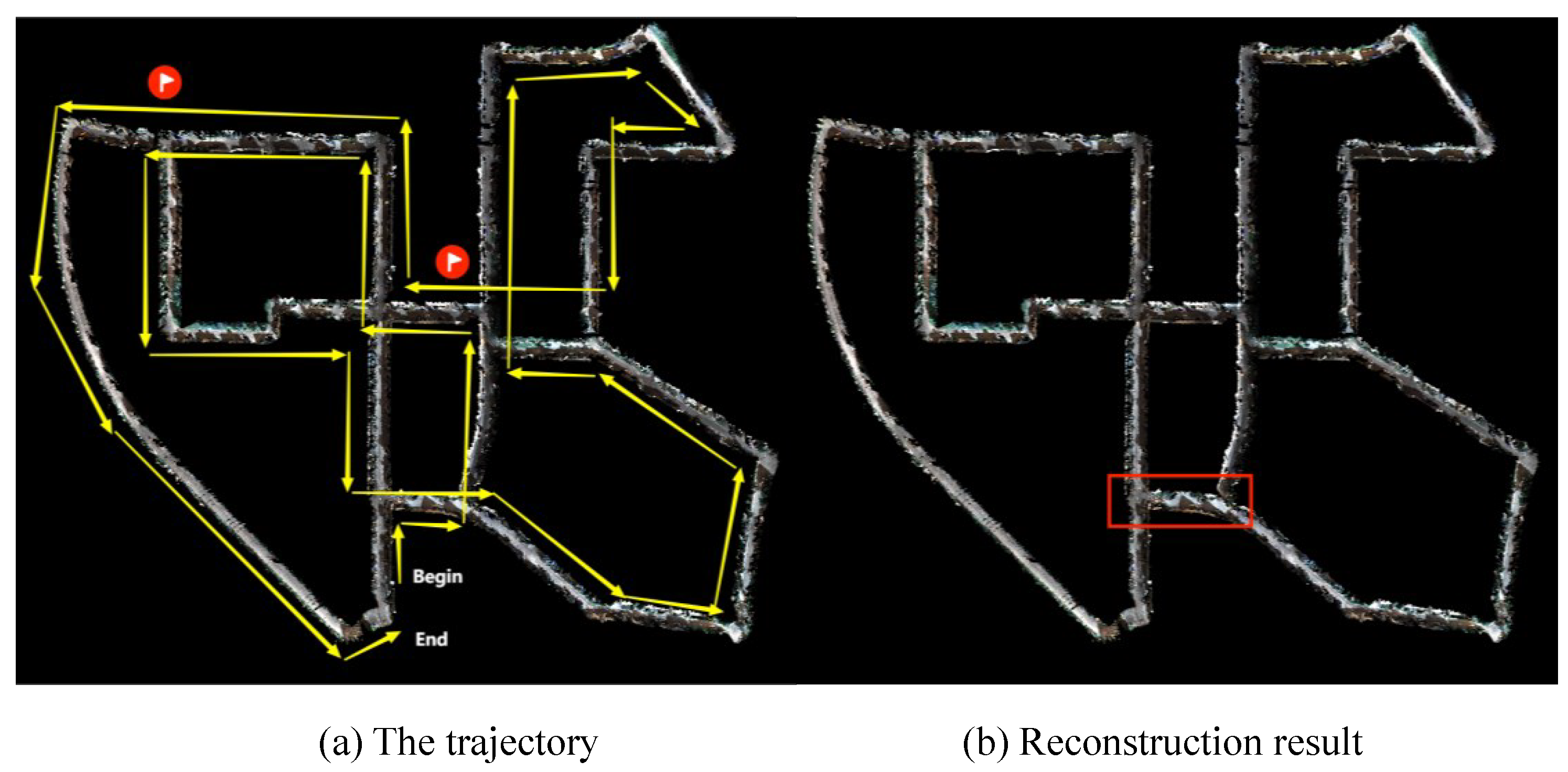
5.1. ICL-NUIM Reconstruction Accuracy
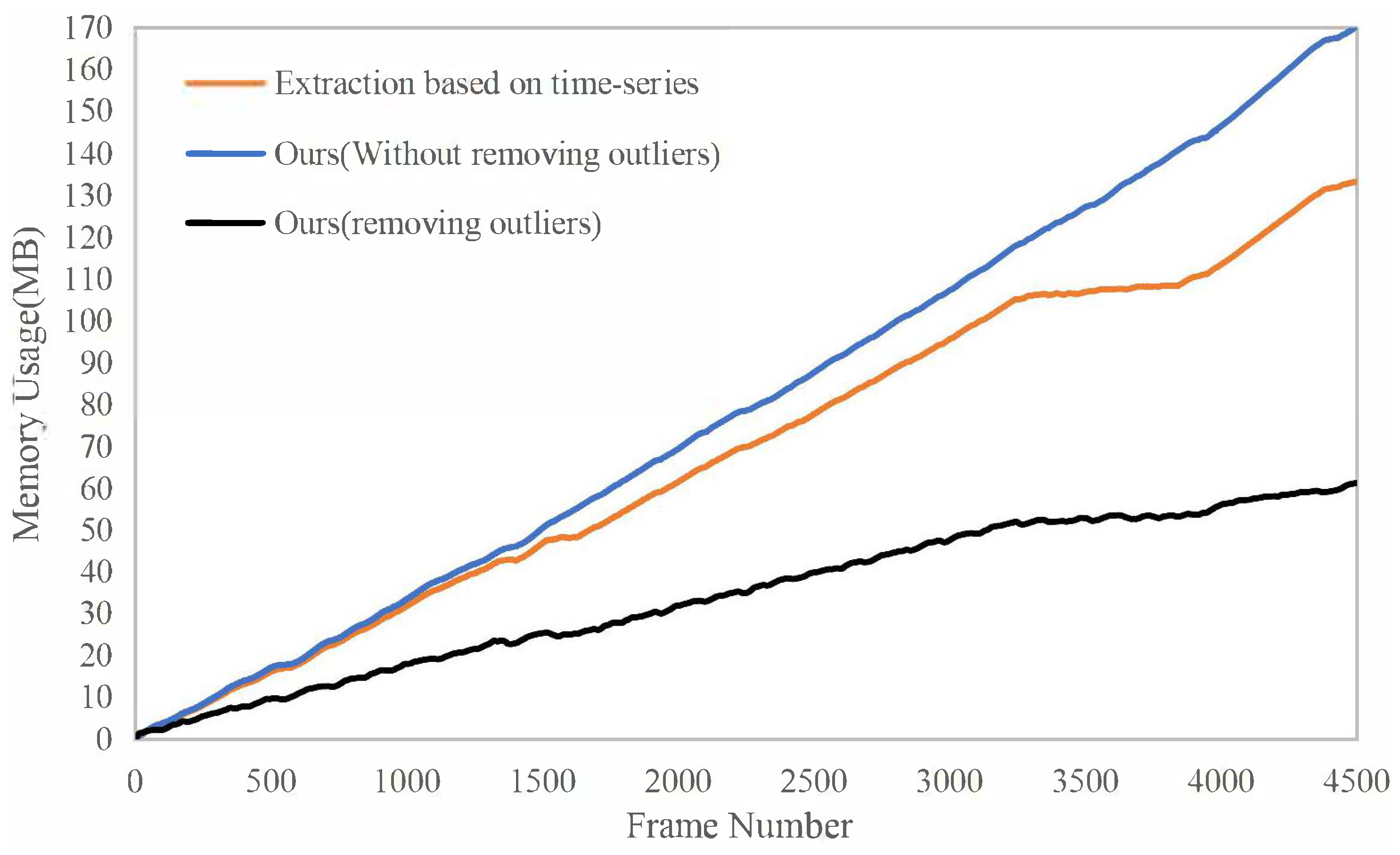
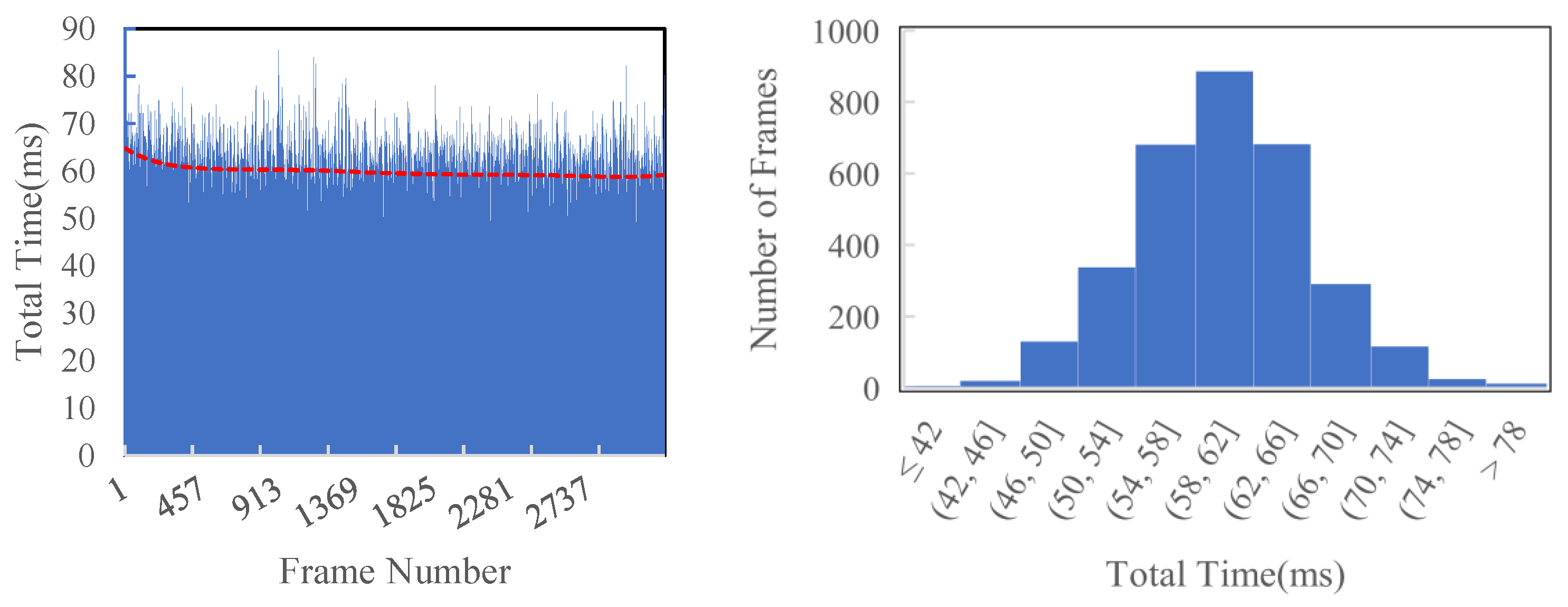
5.2. Kitti Reconstruction Efficiency
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Leonard, J.J.; Durrant-Whyte, H.F. Mobile robot localization by tracking geometric beacons. IEEE Trans. Robot. Autom. 1991, 7, 376–382. [Google Scholar] [CrossRef]
- Gao, J.; Li, B. Research on Automatic Navigation System Construction Based on SLAM Algorithm and Deep Neural Network. In Proceedings of the ICASIT 2020: 2020 International Conference on Aviation Safety and Information Technology, Weihai, China, 14–16 October 2020. [Google Scholar]
- Wang, K.; Gao, F.; Shen, S. Real-time scalable dense surfel mapping. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6919–6925. [Google Scholar]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Whelan, T.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J.; McDonald, J. Kintinuous: Spatially Extended Kinectfusion. In Robotics & Autonomous Systems; MIT Press: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Amanatides, J.; Woo, A. A fast voxel traversal algorithm for ray tracing. In Proceedings of the Eurographics, Amsterdam, The Netherlands, 24–28 August 1987; Volume 87, pp. 3–10. [Google Scholar]
- Oleynikova, H.; Taylor, Z.; Fehr, M.; Nieto, J.; Siegwart, R. Voxblox: Incremental 3D Euclidean Signed Distance Fields for on-board MAV planning. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1366–1373. [Google Scholar] [CrossRef]
- Han, L.; Gao, F.; Zhou, B.; Shen, S. Fiesta: Fast incremental euclidean distance fields for online motion planning of aerial robots. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4423–4430. [Google Scholar]
- Schöps, T.; Sattler, T.; Pollefeys, M. Surfelmeshing: Online surfel-based mesh reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2494–2507. [Google Scholar] [CrossRef] [PubMed]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Curless, B.; Levoy, M. A volumetric method for building complex models from range images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar]
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.; Glocker, B.; Davison, A. ElasticFusion: Dense SLAM without a pose graph. In Robotics: Science and Systems; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Pfister, H.; Zwicker, M.; Van Baar, J.; Surfels, M.G. Surface Elements as Rendering Primitives. In Computer Graphics, SIGGRAPH 2000 Proceeding; ACM Press/Addison-Wesley Publishing Co.: New York, NY, USA, 2000; pp. 343–352. [Google Scholar]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Trans. Graph. ToG 2017, 36, 24. [Google Scholar] [CrossRef]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. Nice-slam: Neural implicit scalable encoding for slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 12786–12796. [Google Scholar]
- Guo, H.; Peng, S.; Lin, H.; Wang, Q.; Zhang, G.; Bao, H.; Zhou, X. Neural 3D Scene Reconstruction with the Manhattan-world Assumption. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5511–5520. [Google Scholar]
- Azinović, D.; Martin-Brualla, R.; Goldman, D.B.; Nießner, M.; Thies, J. Neural RGB-D surface reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 6290–6301. [Google Scholar]
- Sayed, M.; Gibson, J.; Watson, J.; Prisacariu, V.; Firman, M.; Godard, C. SimpleRecon: 3D Reconstruction Without 3D Convolutions. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–19. [Google Scholar]
- Li, K.; Tang, Y.; Prisacariu, V.A.; Torr, P.H. BNV-Fusion: Dense 3D Reconstruction using Bi-level Neural Volume Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 6166–6175. [Google Scholar]
- Nießner, M.; Zollhöfer, M.; Izadi, S.; Stamminger, M. Real-time 3D reconstruction at scale using voxel hashing. ACM Trans. Graph. ToG 2013, 32, 169. [Google Scholar] [CrossRef]
- Fu, X.; Zhu, F.; Wu, Q.; Sun, Y.; Lu, R.; Yang, R. Real-time large-scale dense mapping with surfels. Sensors 2018, 18, 1493. [Google Scholar] [CrossRef] [PubMed]
- Steinbrücker, F.; Sturm, J.; Cremers, D. Volumetric 3D mapping in real-time on a CPU. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2021–2028. [Google Scholar]
- Han, L.; Fang, L. FlashFusion: Real-time Globally Consistent Dense 3D Reconstruction using CPU Computing. In Robotics: Science and Systems; MIT Press: Cambridge, MA, USA, 2018; Volume 1, p. 7. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Qin, T.; Cao, S.; Pan, J.; Shen, S. A general optimization-based framework for global pose estimation with multiple sensors. arXiv 2019, arXiv:1901.03642. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. IJRR 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ||||
|---|---|---|---|---|
| ElasticFusion | 0.7 | 0.7 | 0.8 | 2.8 |
| BundleFusion | 0.5 | 0.6 | 0.7 | 0.8 |
| FlashFusion | 0.8 | 0.8 | 1.0 | 1.3 |
| Dense Surfel Mapping | 0.7 | 0.9 | 1.1 | 0.8 |
| Ours | 0.4 | 1.0 | 0.8 | 0.8 |
| (m) | Generate Superpixels (ms) | Fusion (ms) | Total (ms) | |
|---|---|---|---|---|
| 8 | 10 | 35.6 | 1.3 | 38.8 |
| 8 | 20 | 56.1 | 1.4 | 59.9 |
| 8 | 30 | 60.5 | 1.4 | 64.7 |
| 4 | 10 | 37.1 | 1.4 | 41.2 |
| 4 | 20 | 60.8 | 2.0 | 67.6 |
| 4 | 30 | 63.4 | 2.1 | 70.6 |
| 8 [3] | 30 | ≈70.0 | ≈1.0 | ≈75.0 |
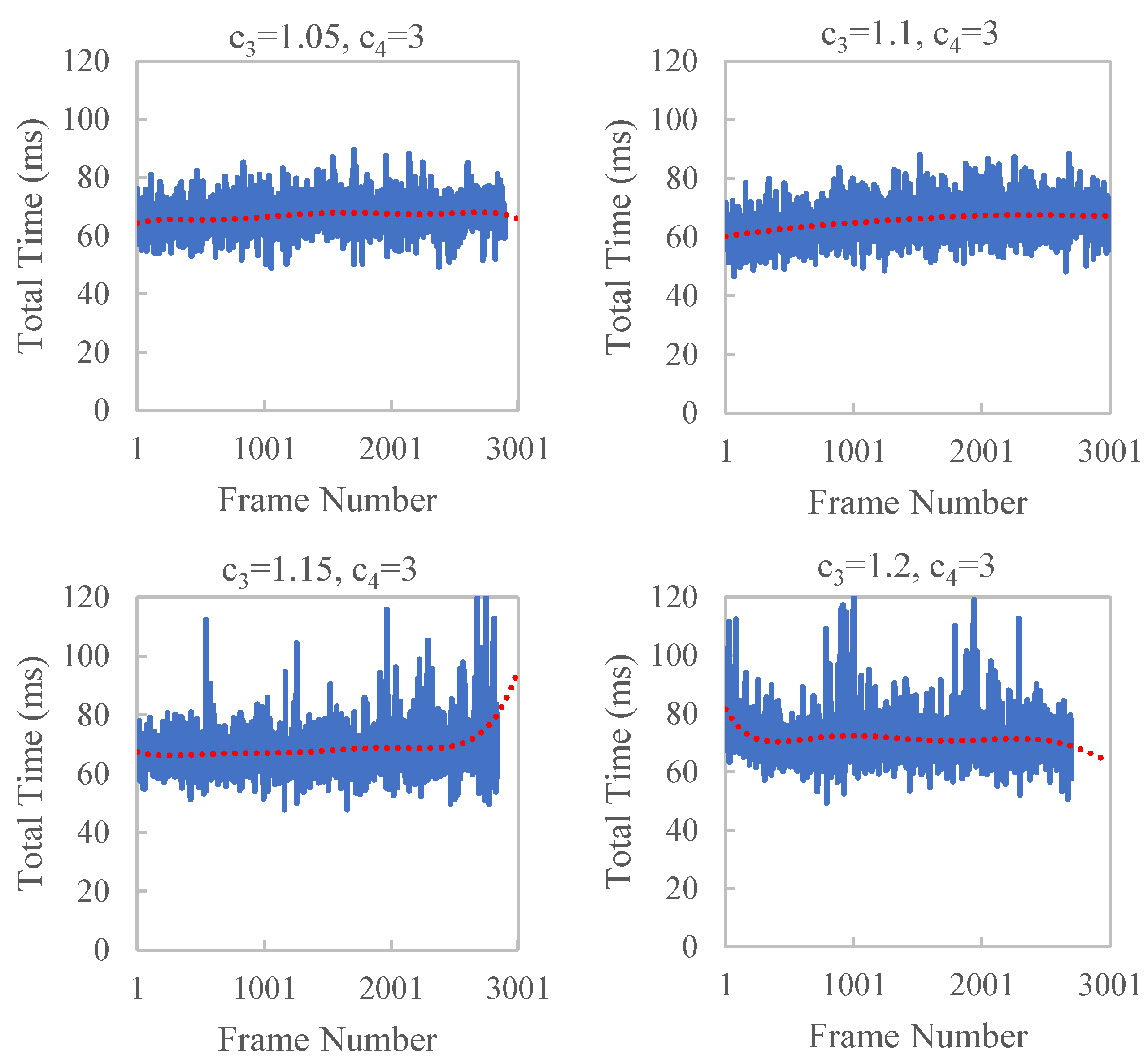
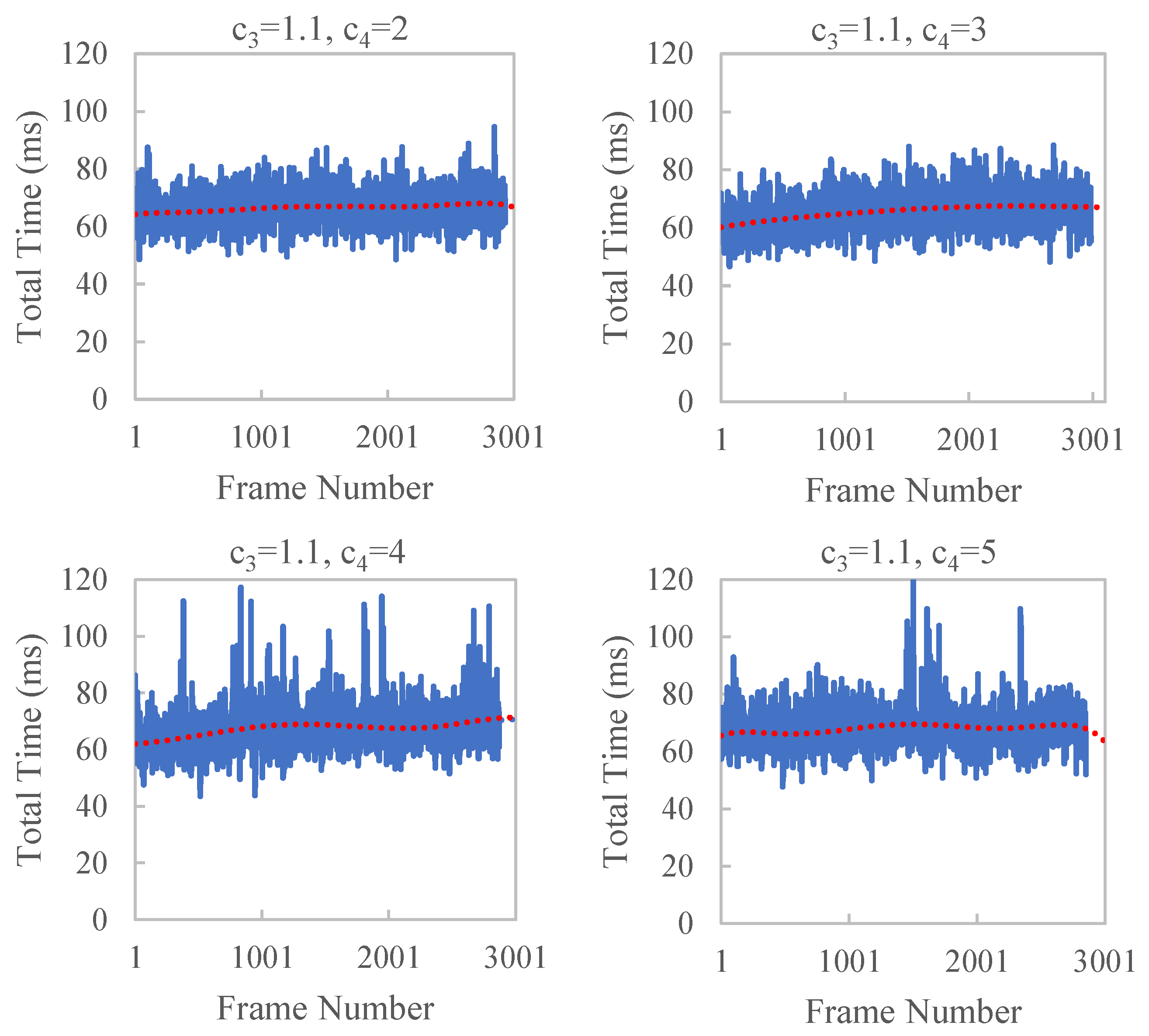
| Average Time (ms) | Standard Deviation | ||
|---|---|---|---|
| 1.1 | 2 | 66.5 | 5.3 |
| 1.1 | 3 | 65.5 | 5.8 |
| 1.1 | 4 | 67.4 | 7.1 |
| 1.1 | 5 | 68.0 | 6.4 |
| 1.05 | 3 | 66.9 | 5.2 |
| 1.15 | 3 | 68.2 | 7.3 |
| 1.2 | 3 | 71.5 | 7.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, N.; Li, C.; Wang, G.; Wu, Z.; Li, D. A Dense Mapping Algorithm Based on Spatiotemporal Consistency. Sensors 2023, 23, 1876. https://doi.org/10.3390/s23041876
Liu N, Li C, Wang G, Wu Z, Li D. A Dense Mapping Algorithm Based on Spatiotemporal Consistency. Sensors. 2023; 23(4):1876. https://doi.org/10.3390/s23041876
Chicago/Turabian StyleLiu, Ning, Chuangding Li, Gao Wang, Zibin Wu, and Deping Li. 2023. "A Dense Mapping Algorithm Based on Spatiotemporal Consistency" Sensors 23, no. 4: 1876. https://doi.org/10.3390/s23041876
APA StyleLiu, N., Li, C., Wang, G., Wu, Z., & Li, D. (2023). A Dense Mapping Algorithm Based on Spatiotemporal Consistency. Sensors, 23(4), 1876. https://doi.org/10.3390/s23041876