1. Introduction
With the explosive growth of data in mobile networks, 5G mobile communication technologies have matured to meet a wide variety of traffic needs. The two most typical types of services in 5G mobile networks are ultra-reliable and low-latency communication (URLLC) and enhanced mobile broadband (eMBB) [
1]. The 5G network provides resources for the two types of users mentioned above in a sliced manner [
2,
3]. When slicing is performed, the allocation of resources is adjusted by the base station (BS) according to the dynamic demands of user services and adapts to different network states [
4]. Slicing of network resources enables data triage management and flexible resource allocation in 5G networks [
5,
6], and it is also necessary to achieve a high data transmission rate, low latency and high capacity [
7,
8].
Due to the intense growth of network traffic and the densification of devices, there are multiple problems and great challenges in the allocation and scheduling of resources between different services [
9]. For example, in the 5G scenario, when there are users of both eMBB and URLLC service types, it is necessary to allocate a lot of bandwidth resources to users of the eMBB service type within a time slot to ensure that their images and voice have high and stable quality, and it is also necessary to successfully transmit the data packets requested by URLLC service type users within the range of very short delay to meet the characteristics of ultra-high reliability and ultra-low delay [
10]. If there is a sudden increase in URLLC traffic in the same area, it will quickly occupy these bandwidth resources to reach its required transmission rate, resulting in an ultra-low latency performance [
11]. When bandwidth resources are insufficient, existing works typically prioritize the performance requirements of URLLC by sacrificing the quality of experience (QoE) of eMBB. The rational allocation and scheduling of slicing resources facilitate efficient resource use in hybrid services systems.
In recent years, reinforcement learning (RL) has become a potential solution to the resource allocation problem. The resource allocation algorithm based on RL has improved resource utilization efficiency [
12]. As deep reinforcement learning (DRL) has evolved, many research works based on DRL approaches have also been achieved [
13,
14]. For example, DRL is applied to solve problems with resource allocation [
15], network optimization, routing, scheduling and radio control. Chen et al. [
16] modeled the problem of auctioning a finite number of channels across scheduling slots to multiple service providers as a stochastic game, then linearly decomposed the Markov decision process for each service provider and derived an online solution based on deep reinforcement learning. In [
17], the stochastic decision process in vehicular networking is modeled as a discrete-time single-intelligent Markov decision process (MDP) to address the partial observability and high dimensionality curse of the local network state space faced by each vehicular user device and to make optimal band allocation and group scheduling decisions in a decentralized manner in each scheduling time slot. In [
18], a deep Q-network (DQN) algorithm based on discrete normalized advantage functions (DNAF) was studied, and the advantage function was decomposed into two function terms to reduce the computational complexity of the algorithm. In addition, the simulation results verify that the deep Q-learning (DQL) based on the K-nearest neighbor algorithm can converge faster in discrete environments. Sciancalepore et al. [
19] proposed the reinforcement learning-based network slice broker (RL-NSB) framework to effectively improve the utilization of the system by considering factors such as traffic flow, mobility, and optimal access control decision. The distributed idea [
20] and the effect of randomness noise for spectrum efficiency (SE) and service level agreement (SLA) satisfaction ratio (SSR) are referred to [
21]. Hua et al. [
21] introduced the generative adversarial network and used it to allocate physical resources among multiple network slices of a single BS, which performs well in terms of demand-aware resource management. Furthermore, Li et al. [
22] considered the user mobility based on [
19] and utilized the actor–critic based on long short-term memory (LSTM-A2C) algorithm to follow the mobility of users, improving the practicality of the resource allocation system. Yuan et al. [
23] provide a DRL-based resource-matching distributed method to maximize energy efficiency (EE) and device-to-device (D2D) capacity through a decentralized approach, match multi-user communication resources to double DQN, and optimize radio channel matching and power allocation. Sun et al. [
24] distinguished resource granularity, utilized virtualized coarse resources to obtain provisioning solutions and used fine resources for dynamic slicing, proposing a dueling DQN-based algorithm customized to the diverse needs of users to improve user satisfaction and resource utilization. Chen et al. [
25] used an algorithm based on dueling deep Q network (Dueling DQN) combined with bidding for bandwidth resource allocation in two layers to improve the QoE of users and verify the advantages of Dueling DQN over Double DQN in resource allocation. Boateng et al. [
26] proposed a new hierarchical framework for autonomous resource slicing in 5G RANs, modeling the seller and buyer pricing and demand problems as a two-stage Stackelberg game to design fair incentives and designing a Dueling DQN scheme to achieve optimal pricing and demand strategies for autonomous resource allocation in negotiated intervals. Zhao et al. [
27] performed joint optimization and obtained a great policy by proposing an algorithm that combines multiple agents with D3QN to maximize network utility and guarantee the quality of service (QoS).
Various schemes have been studied in relation to the problem of resource scheduling between different services. An innovative overlay/perforation framework [
28,
29] is based on the principle of overlaying a part of eMBB services when sporadic uRLLC services occur, although this approach may lead to significant degradation of the QoE of eMBB. Feng et al. [
30] and Han et al. [
31] designed a long and short dual time-scale algorithm for bandwidth allocation and service control, respectively, using Lyapunov optimization to centrally guarantee the latency of URLLC service while improving the quality of the eMBB continuous service. Han et al. [
32] presented a dynamic framework of Q-learning based to improve the latency QoS and energy consumption ratio between URLLC and eMBB traffic in 5G/B5G. Moreover, Wang et al. [
33] proposed a deep deterministic policy gradient (DDPG) algorithm to optimize the hole punch location and bandwidth allocation of URLLC services, and realize the QoS trade-off between URLLC and eMBB in 5G/B5G. Alsenwi et al. [
34] used the DRL-based optimization auxiliary framework to solve the resource slicing problem in the dynamic reuse scenario of eMBB and URLLC services, achieved the ideal data rate of eMBB under the reliability constraints of URLLC and reduced the impact of URLLC traffic that was immediately scheduled on the reliability of eMBB. The time slots occupied with eMBB are split into the small slot and URLLC traffic pre-overlap at the small slot so that the proportional fairness of eMBB users can be maximized while satisfying the URLLC constraint [
35]. Almekhlafi et al. [
36] introduced a new technology that can reuse URLLC and eMBB services to reduce the size of perforated eMBB symbols, and improved the reliability of eMBB, symbol error rate (SER) and SE in the study to meet the delay constraints and reliability of URLLC. In [
37], a new hybrid punching and coverage strategy is used to enhance the compromise between the acceptable number of URLLC users and the throughput of eMBB users.
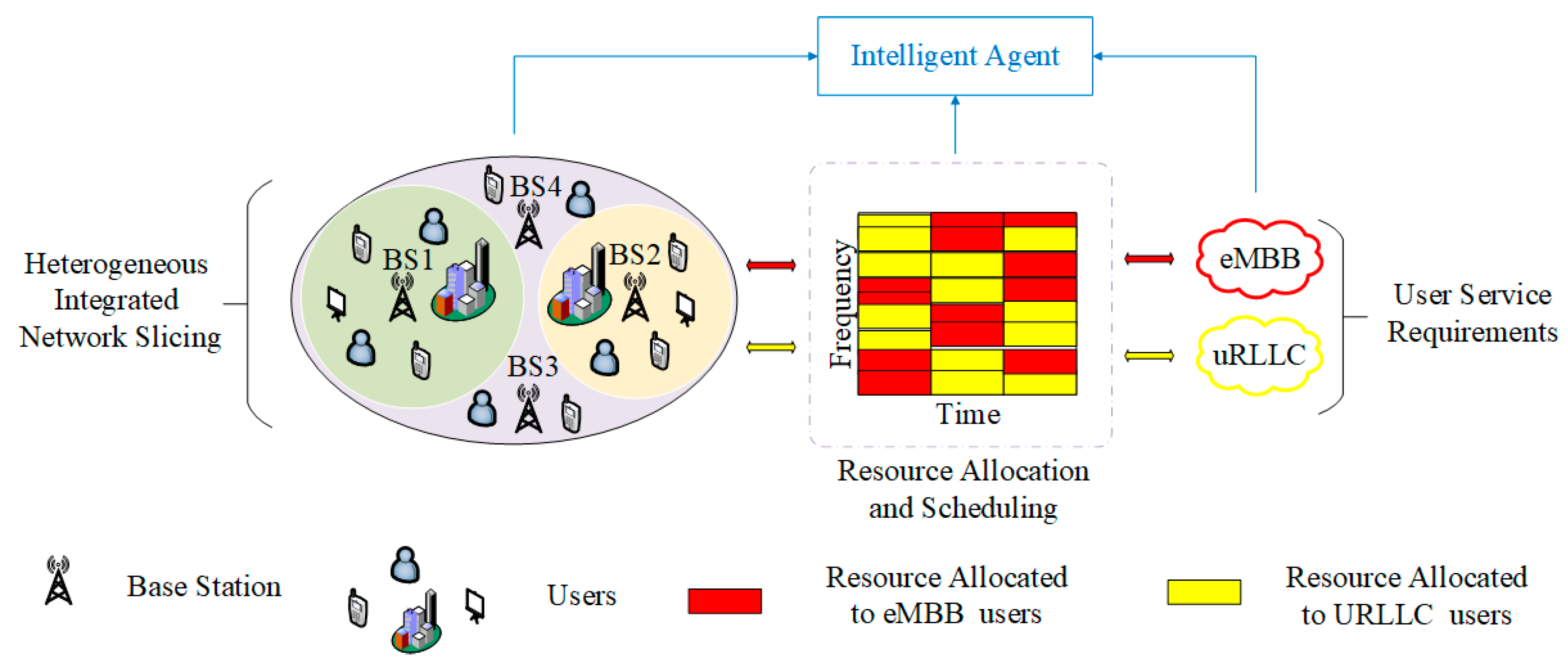
As described in the abovementioned literature, RL is used to solve the dynamic resource allocation problem in various scenarios and has shown good performance. However, the performance requirements of URLLC are not prioritized and the resource scheduling problem among different services is not addressed. In addition, the traditional optimization algorithm and RL algorithm can be used to solve the resource scheduling problem between eMBB and URLLC services, but they still face a series of difficulties and challenges. For example, when scheduling resources among diverse services, the overlay/perforation framework has a huge influence on the QoS of eMBB in order to enhance the performance requirements of URLLC, and the Lyapunov dual time-scale algorithm improves the continuous QoS of eMBB, but its scheduling time slot is long and the optimization speed is slow. In this paper, a new Dueling DQN-based resource allocation and scheduling algorithm that satisfies the slice requirements is proposed. For the different demand characteristics of eMBB and URLLC services, especially for the ultra-low latency constraint of URLLC services, part of the bandwidth resources occupied by users of eMBB services are scheduled to URLLC users. With spectrum efficiency (SE) and quality of experience (QoE) of the two services as the optimization objectives, we have formed an optimization problem restricted by the rate and delay constraints of the two services and innovatively used Dueling DQN to solve the non-convex optimization problem of slicing resource allocation. Meanwhile, we use the resource scheduling mechanism and -greedy strategy to select the optimal resource allocation action, adopt the reward-clipping mechanism to enhance the optimization goal and select a reasonable bandwidth resolution (b) to improve the flexibility of bandwidth resource allocation. The main work can be summarized in three aspects.
(1) First, a scenario in which multiple wireless access network slices exist and BSs share bandwidth resources is considered. In this scenario, the resources are allocated and scheduled by BS for users with two different services. For the different demand characteristics of eMBB and URLLC services, especially for the ultra-low latency constraint of URLLC services, some of the bandwidth resources occupied by users of eMBB services are scheduled to URLLC users.
(2) Second, a novelty Dueling DQN-based algorithm aimed at allocating and scheduling of bandwidth resources is proposed. The problem regarding resource allocation and scheduling for eMBB and URLLC is modeled as an optimization problem and plotted as a Markov process, which is addressed through Dueling DQN training. Dueling DQN divides the action–value function output from the neural network into a state–value function and a dominance function, which reduces the correlation between the current state-action and action selection, and this network architecture is suitable for solving the proposed slicing resource allocation problem in discrete action space. More importantly, we generate the state using the number of packets received by two different service users and define the size of the bandwidth resources allocated to the two slices as actions. Since both the system SE and the QoE of eMBB and URLLC are optimization objectives, it is necessary to consider both the SE and the QoE. Therefore, the reward-clipping mechanism is proposed to encourage the agent to choose the best resource allocation action. Meanwhile, we choose the appropriate bandwidth allocation resolution to ensure the appropriate action space size and increase the flexibility of resource allocation.
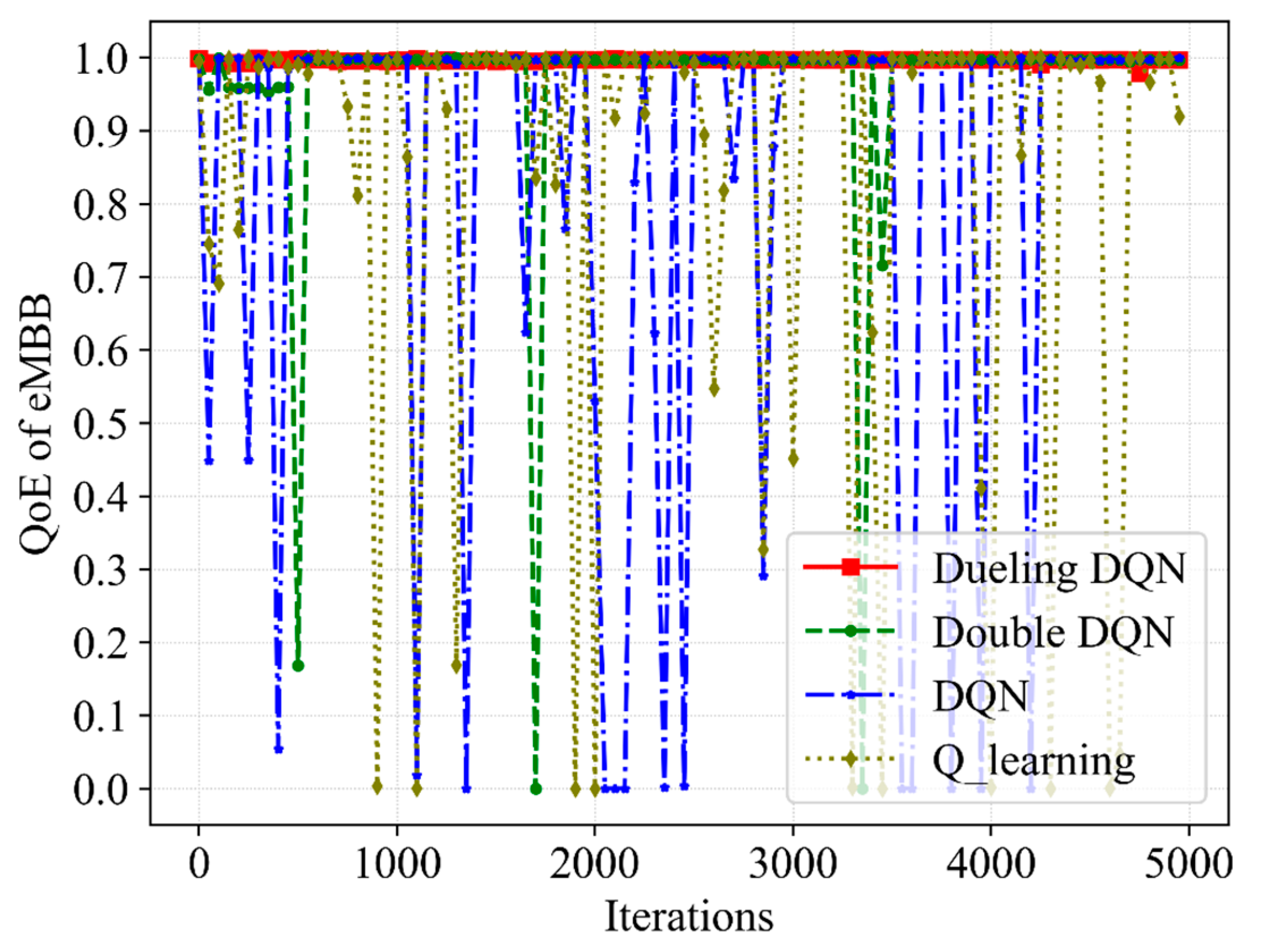
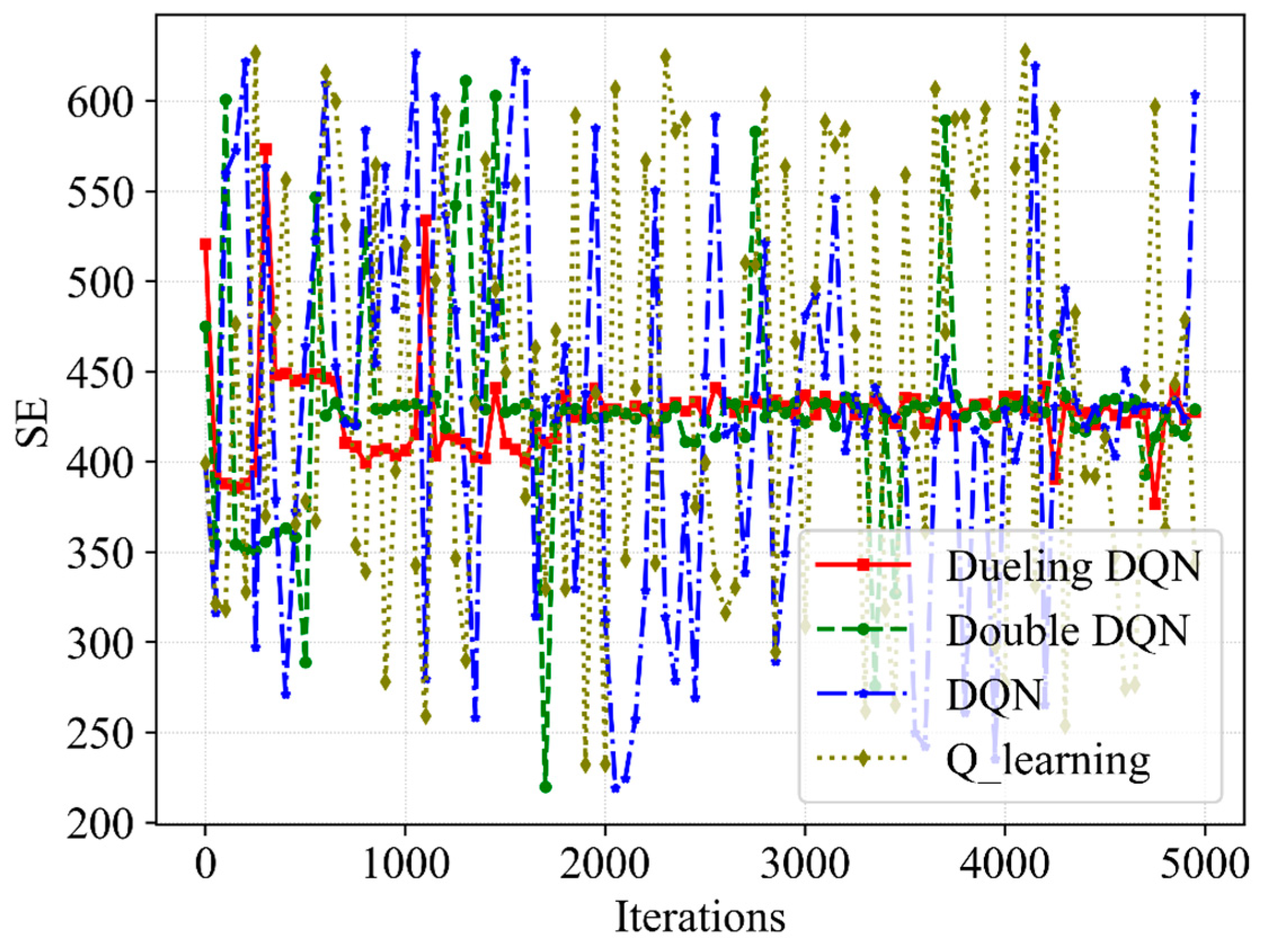
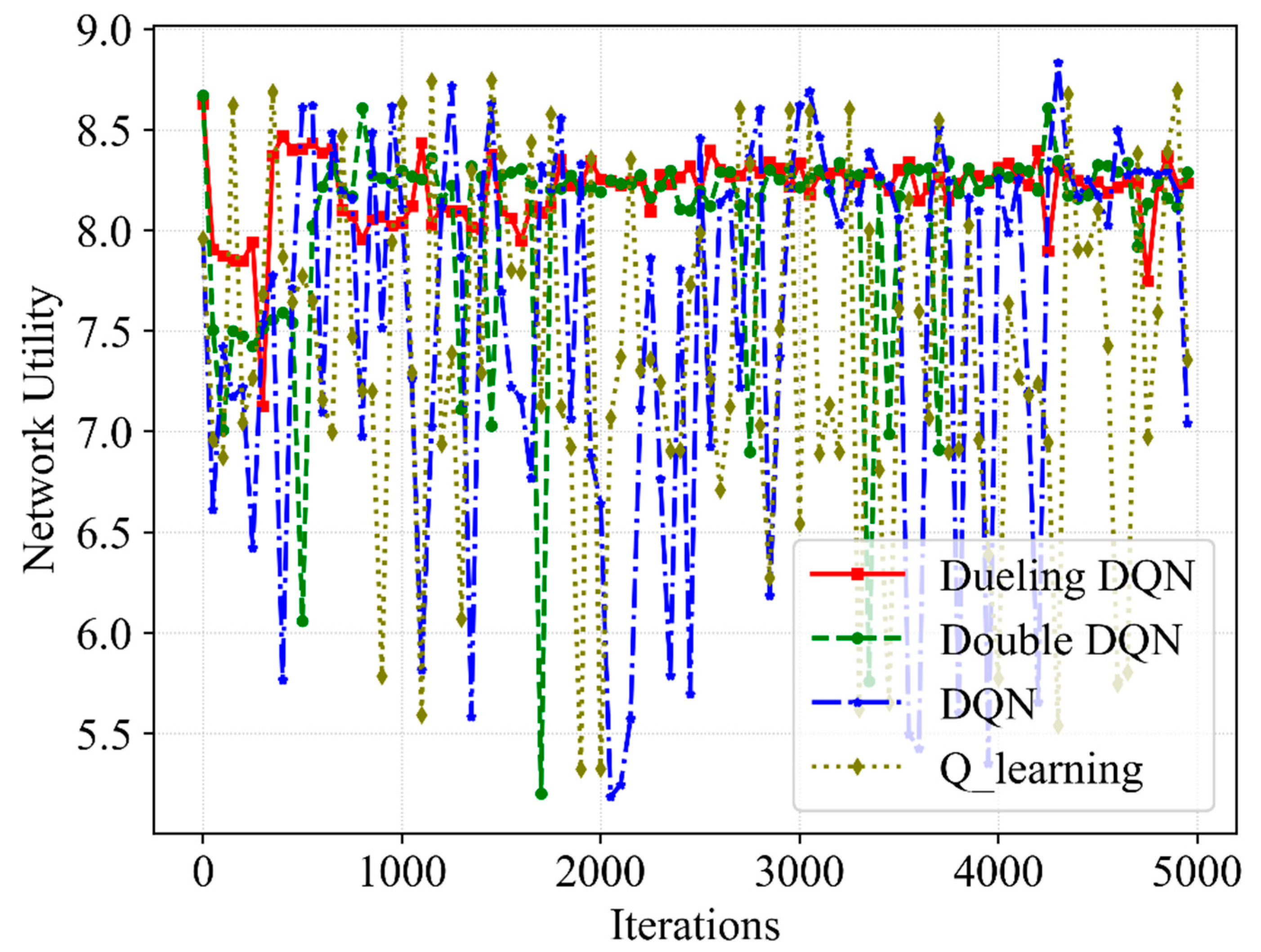
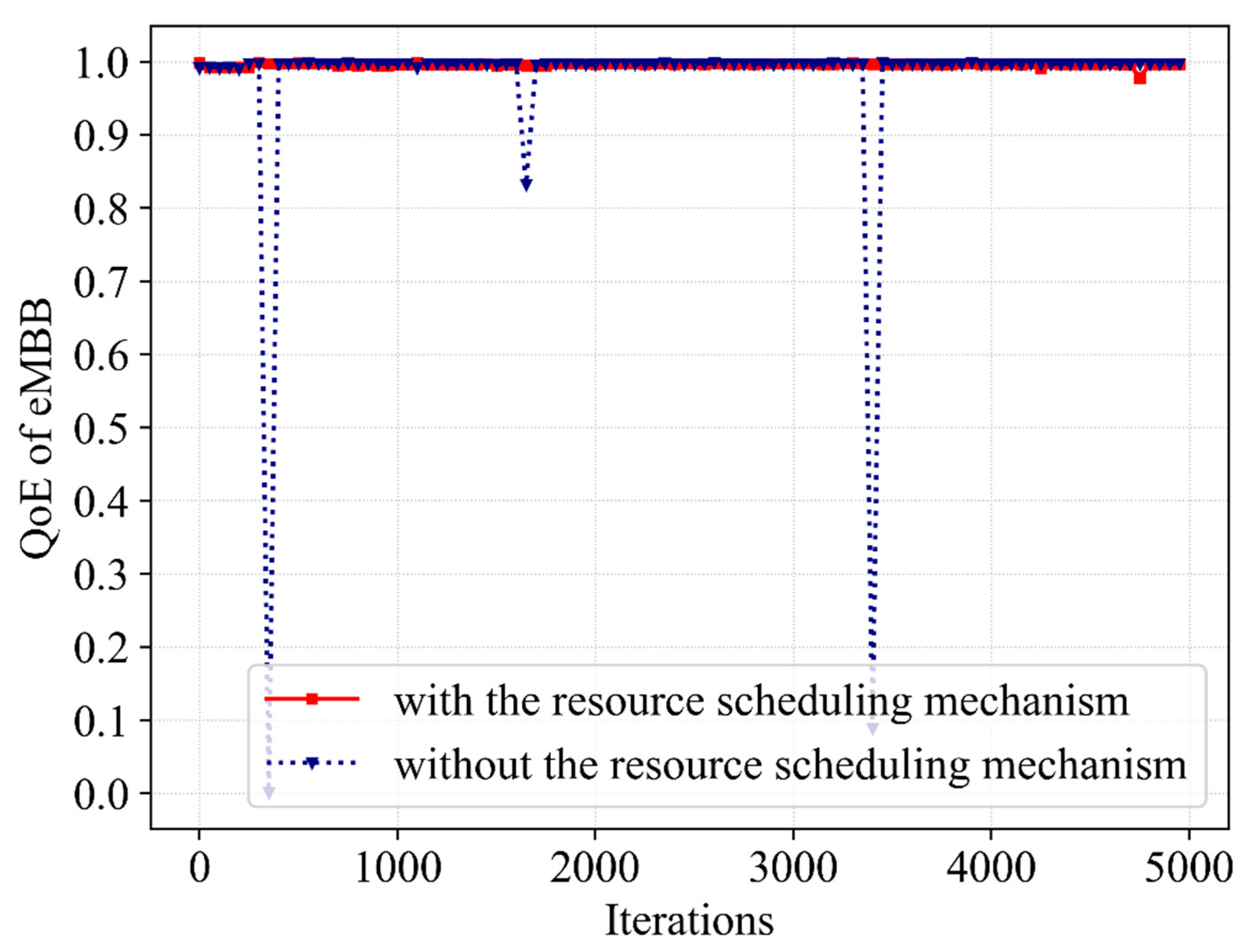
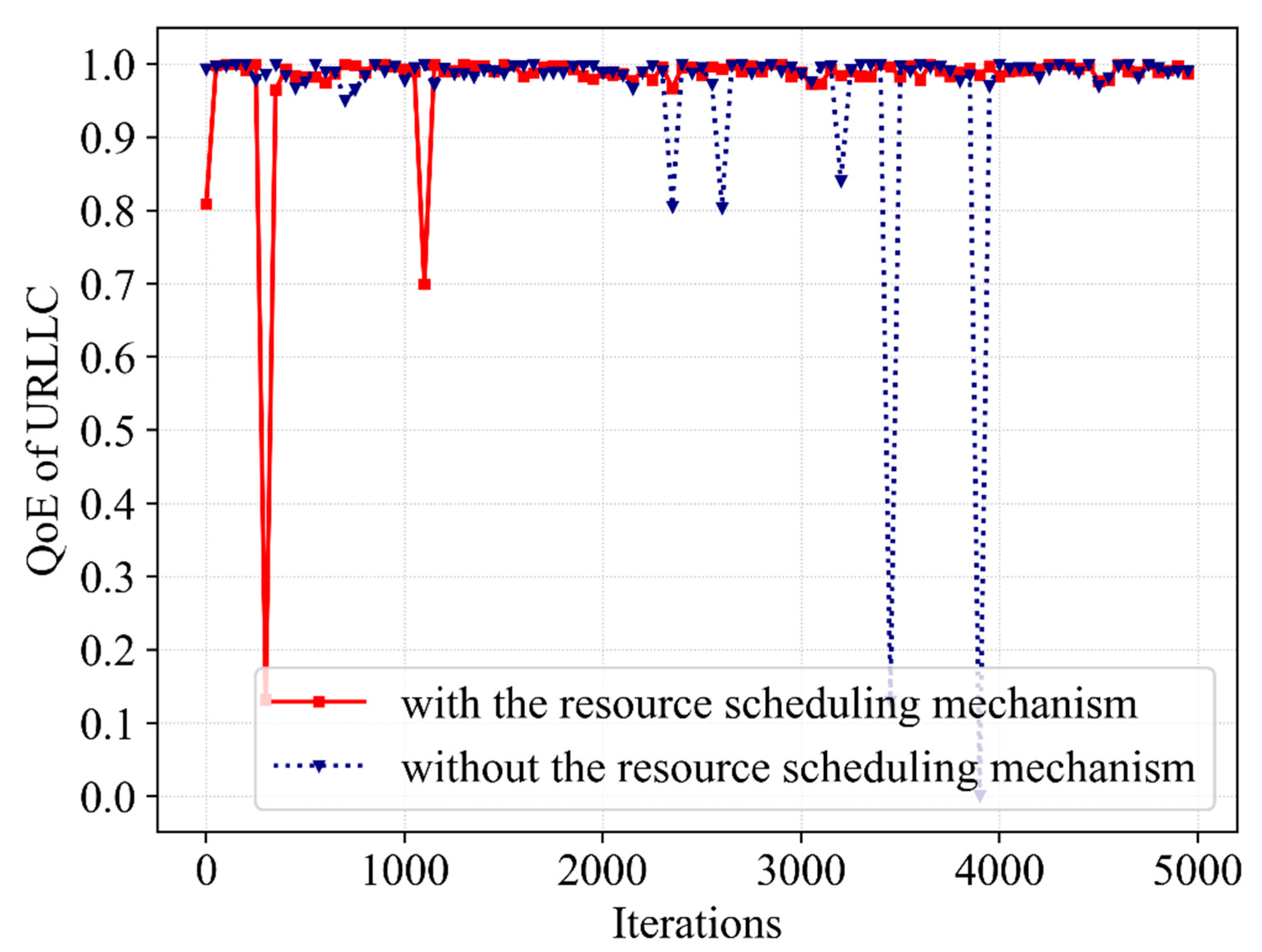
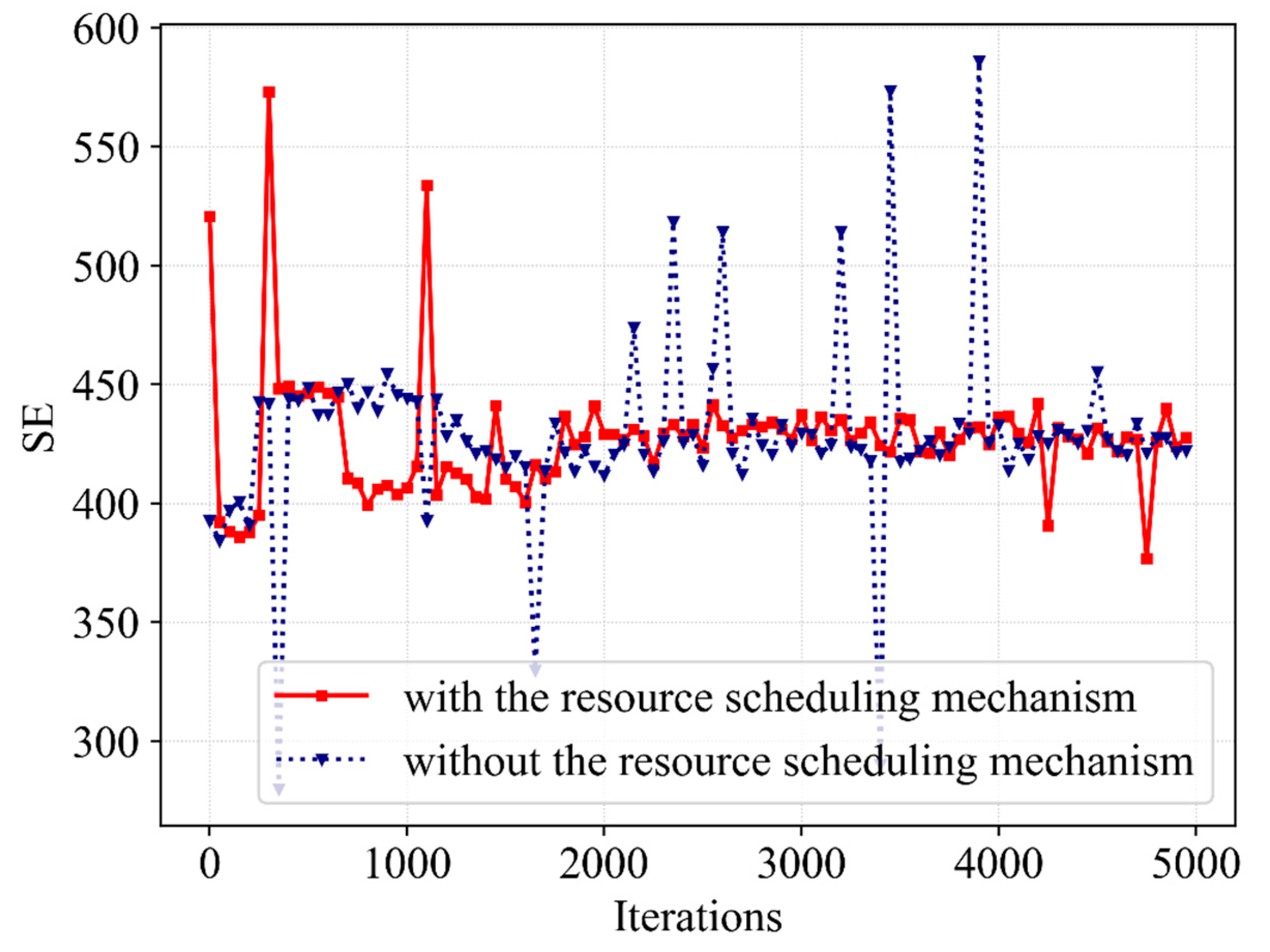
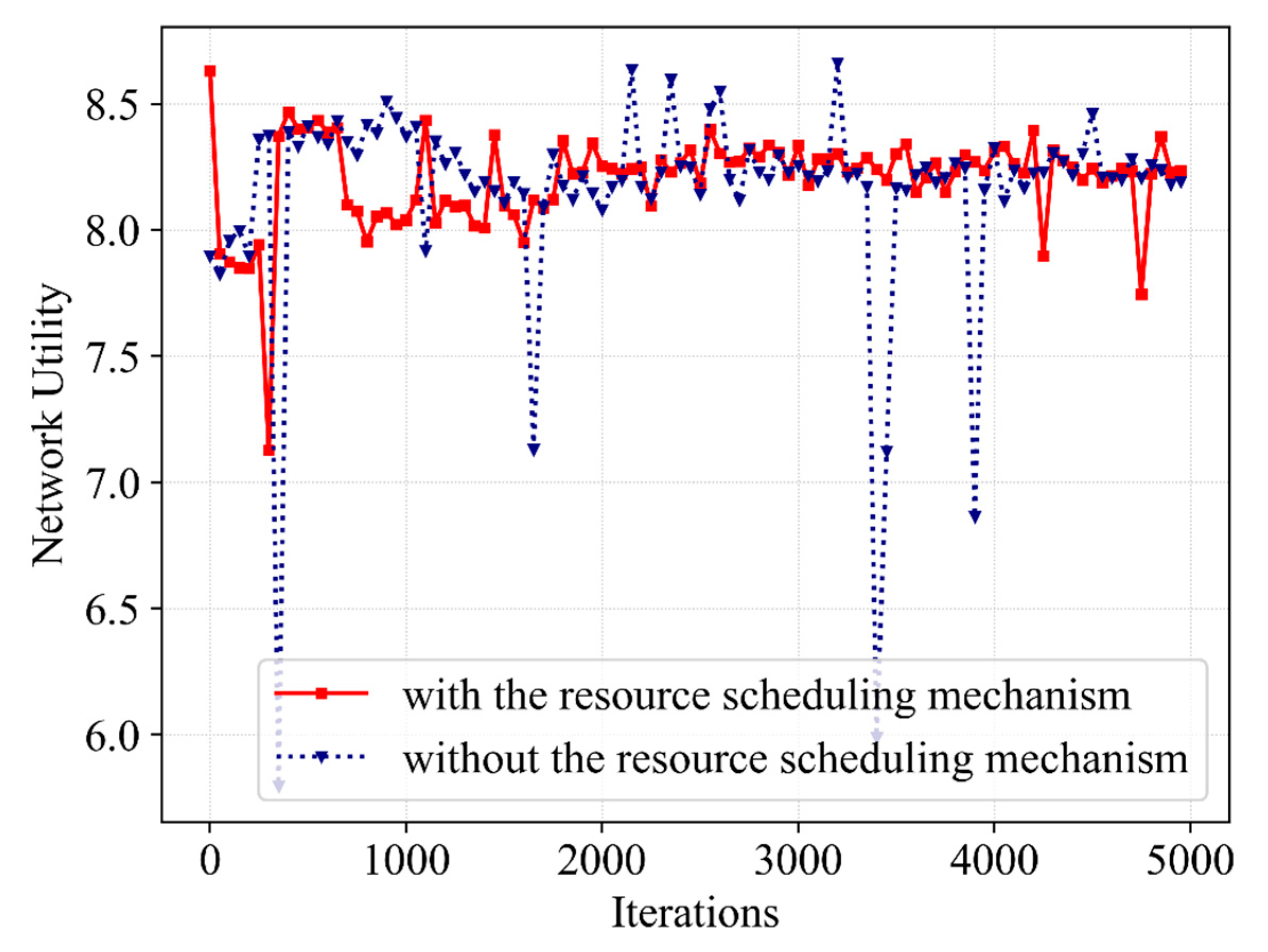
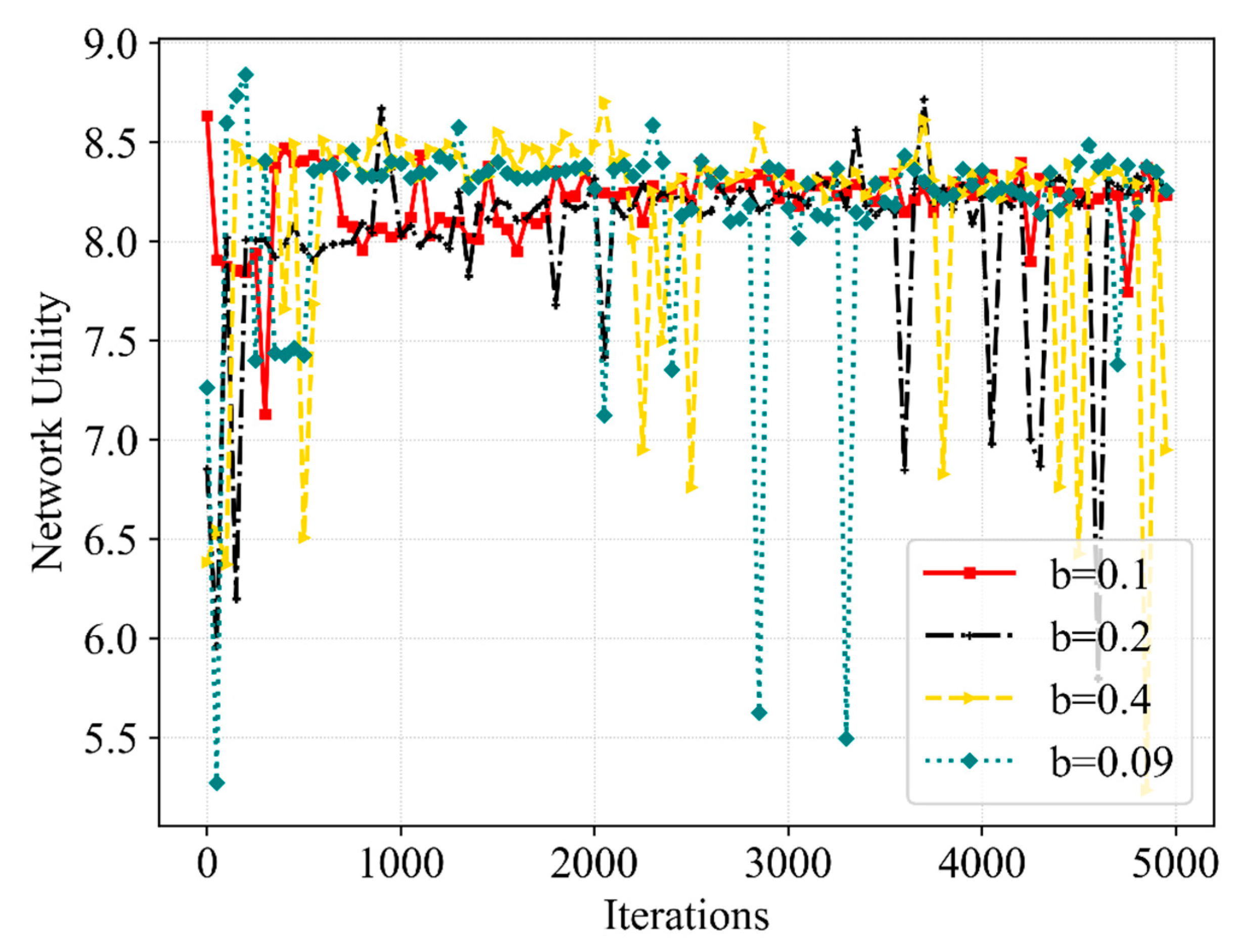
(3) Third, the simulations are performed and reasonable data are obtained. It can be seen from the obtained data that the proposed algorithm ensures that the QoEs of eMBB and URLLC are stable at 1.0 with a high probability, meeting the service requirements in this scenario. Moreover, the QoE, SE and network utility show convergence trends. In contrast with Q-learning, DQN as well as Double DQN, the proposed Dueling DQN algorithm improves the network utility by 11%, 8% and 2%, respectively. Furthermore, the resource scheduling mechanism improves the QoE of URLLC, SE and network utility by 3%, 4.5% and 7%, respectively.
The organization of the following section in this paper is as follows.
Section 2 builds the system model and formulates the optimization problem. In
Section 3, the theoretical basis of Dueling DQN is introduced and the proposed slice resource allocation algorithm based on Dueling DQN is discussed in detail.
Section 4 displays the simulation parameters and results. Finally,
Section 5 concludes this work.
3. Proposed Algorithm
3.1. Foundation of Dueling DQN
It is worth mentioning that DQN, as a branch of DRL, uses two key technologies for improvement and has outstanding advantages in decision making. Firstly, the experience replay mechanism breaks the inherent correlation among samples, making them independent of each other. Secondly, the target value network can enhance the convergence and stability of training by lessening the correlation between the current and target Q value, correspondingly. An intelligent agent obtains information about the environment through trial and error and uses the data obtained during the interaction as observations. Then, the agent traverses the actions in a given state and finds the corresponding action with the largest Q value according to its -greedy policy. However, DQN has a disadvantage in that the Q value output by its neural network denotes the selected action value in the state, which is dependent on the action and state. This means that the DQN fails to reflect the different effects of state and action on the Q value. Furthermore, DQN is vulnerable to the overestimation problem, resulting in poor training stability. Among the improvements of DQN in recent years, Dueling DQN has outstanding advantages, and its network stability and convergence speed have been significantly improved. In particular, Dueling DQN maintains the advantages of the DQN while improving on the DQN in terms of network structure by dividing the action–value function from the output of the neural network into the state–value function and advantage function. This allows Dueling DQN to learn the value function for each state without considering what action to take in that state. Therefore, the Dueling DQN converges better when the current action is less relevant to the successive state and the current state–action function is also less relevant to the current action selection. Based on the improvements and advantages of Dueling DQN over DQN, we prefer to choose Dueling DQN for iterative optimization of proposed nonconvex optimization problems.
The process of interaction between the agent of Dueling DQN and the environment can be cast into a Markov decision process
, where
presents the state space,
is the action space. The current state
and the next state
are stored in the state space, while the current action
and the next action
are stored in the action space.
denotes the reward function, which is the goal that the agent maximizes during action selection and is the key factor that makes the training process more stable.
is the transfer probability, which represents the probability that the current state will be transferred to another state when an action is performed.
is a discount factor greater than 0 and less than 1 that moderates near and far-term effects in reinforcement learning. The action–value function can be formulated as
Here, the policy
denotes the distribution that maps state to action. Then, the two functions
and
are approximated using the neural network. It can be seen that
relates only to states, while
relates to both states and actions. In fact, there are two neural networks with parameters
in the Dueling DQN: the target Q network and the evaluation Q network, respectively. Let
denote the value function with parameters
, which is expressed as
where
is a shared parameter,
denotes a dominant function parameter and
is used to indicate a parameter of the action–value function. However, there exists a serious problem in the above equation, which is that the unique
and
cannot be obtained from
in Equation (19). Thus, a centralization processing of the advantage function is performed to guarantee that zero dominance will occur for a given action. Further,
can be reformulated as
The agent of Dueling DQN makes an observation as it interacts with the environment. The Q-network calculates all Q values for each action when observation is used as state inputs. Then, the agent selects the action that maximizes the Q value relying on a
-greedy strategy and provides the reward value. In Dueling DQN, the target Q value of the target Q-network is updated by copying the current Q value every C iterations. However, the current Q value is reset with real-time updates in each iteration. The target Q value (
) of the target Q-network is denoted by
Then, the loss function
in Dueling DQN is defined by
where
denotes the expected value. Meanwhile, the optimal parameter
is obtained through the minimization of the square of TD error; that is,
Finally, the action–value function
is updated by
The iterative training of Dueling DQN requires that a fixed number of iterations be set. When the iteration is ended, Dueling DQN can utilize the trained neural network for optimal action selection.
3.2. The Dueling DQN Based Slicing Resource Allocation and Scheduling Algorithm
The proposed Dueling DQN-based algorithm is used for resource allocation and scheduling in eMBB and URLLC hybrid traffic. Bandwidth resources are dynamically allocated and scheduled so that the requirements of users are better met and network utility is maximized. In cases in which the bandwidth resources are insufficient, the BS schedules some of the bandwidth resources occupied by eMBB service to the URLLC service, improving the QoE of URLLC and network utility with the premise of ensuring the QoE of the eMBB.
To achieve resource scheduling between eMBB and URLLC users, the following resource scheduling mechanism is set up. When randomly distributed users request resources from the BS, the BS counts the number of users requesting resources and slices the bandwidth by service types. In each iteration, the BS allocates resources to the users of both services while counting the number of users that request resources. When there are insufficient bandwidth resources and URLLC users still request resources, the BS schedules bandwidth resources occupied by the corresponding number of the users of eMBB to URLLC based on the number of URLLC users requesting resources. Furthermore, the bandwidth resources occupied by eMBB users are not all scheduled to avoid service interruption for this user. After several iterations, a resource scheduling scheme can be obtained to provide the best network utility.
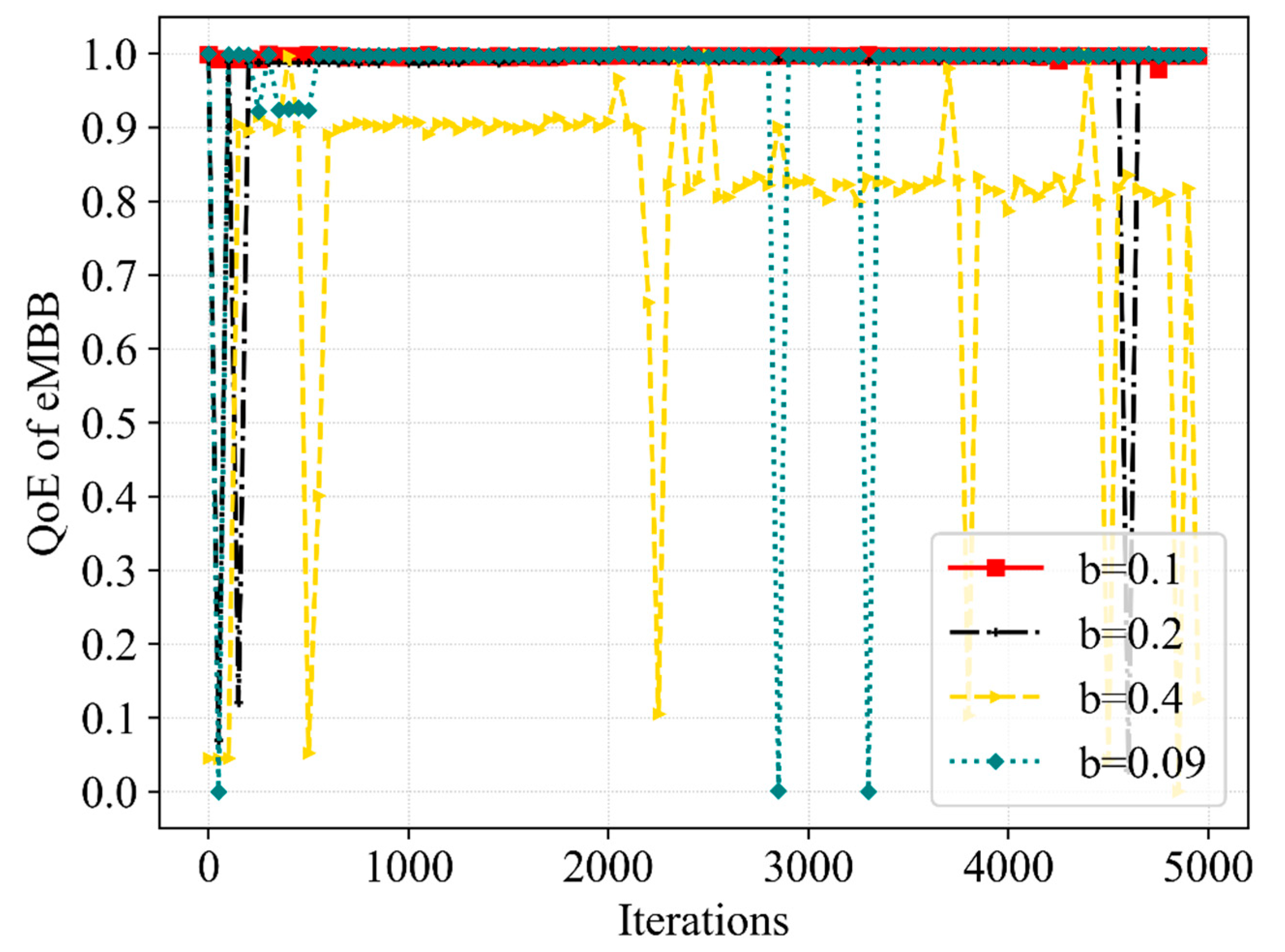
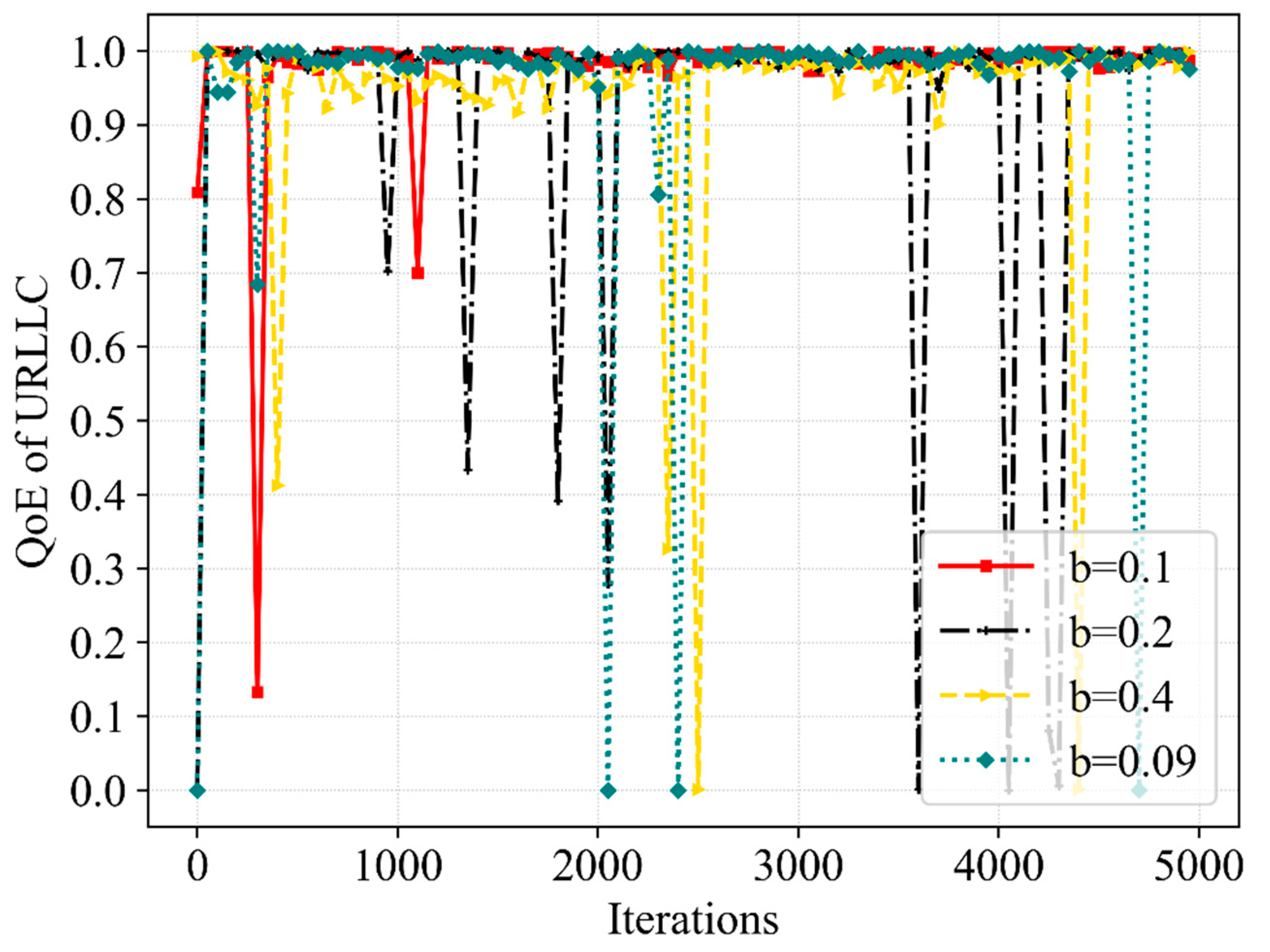
The goal of this paper is to improve the SE of the network system while guaranteeing the QoE of both services, so we use a reward-clipping mechanism that allows the agent to optimize both metrics through the algorithm. Since the QoE and the SE of the system are of different orders of magnitude, we use different coefficients in each segment of the reward parameter to make the reward value reach a value that is easy for the agent to simulate and learn. We expect users of both services to achieve satisfactory QoE. In order to ensure that the QoE of slices meet the 5G standard and reach 1.0 as often as possible, we set the QoE threshold of 0.98 in the reward function. If the
cannot satisfy the requirement we mentioned above, a more unfavorable negative reward value in Equation (25) will be calculated by
When the
satisfies the requirement but the
cannot, we will have a negative reward value as follows
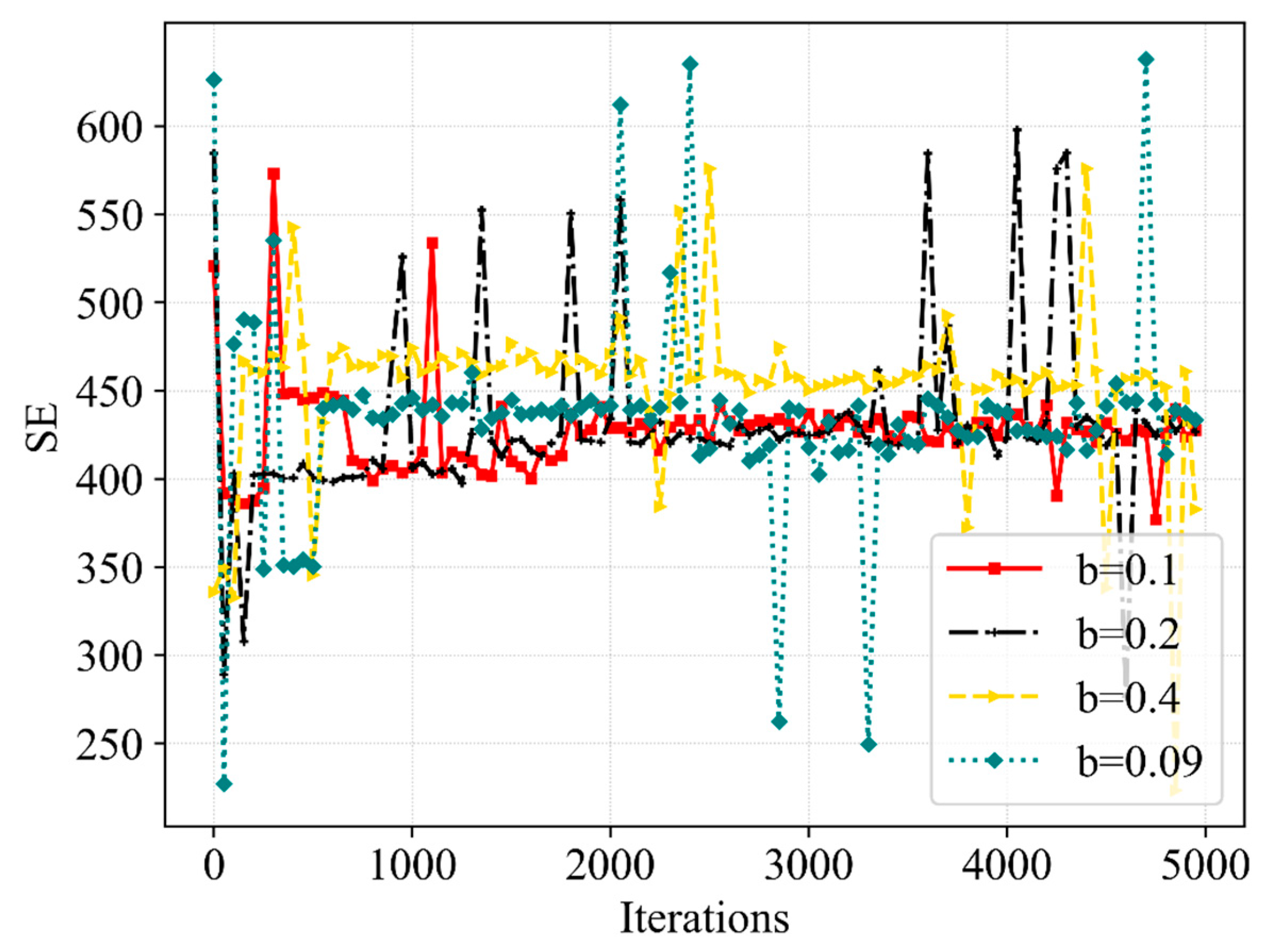
Similarly, we would like to see an improvement in SE. We compared the highest value and lowest value of SE in the algorithm training process, and in order to ensure a higher system SE is achieved as often as possible, so that the agent presents a stable training trend in the training process, we set SE as 380 between the highest value and the lowest value in the reward function. If the QoE of both services can be achieved but the SE does not satisfy this condition, a poorer positive reward value can be given as
Conversely, the QoE of both services can be achieved and the SE satisfies this condition; thus, we will calculate a better positive reward value as follows:
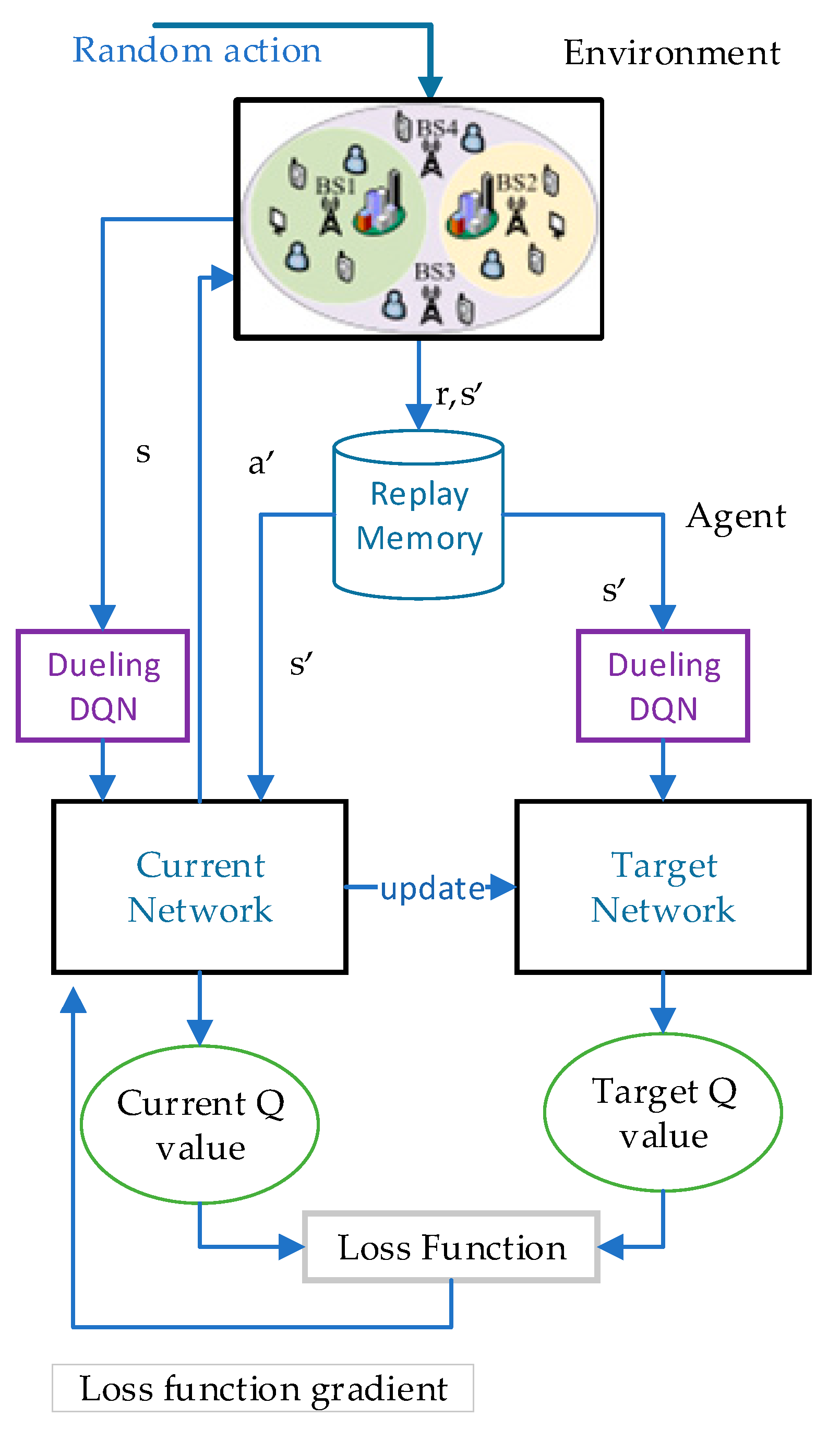
The procedures of resource allocation and scheduling for hybrid eMBB and URLLC services using the proposed Dueling DQN based algorithm with resource allocation and scheduling are as follows. In order to helps readers to understand our process more clearly, the algorithm flowchart is shown in
Figure 2.
Before starting the iterative training, the parameters are initialized and a randomly selected policy is required to produce an original state. Moreover, the BS randomly selects an allocation scheme to first allocate bandwidth resources for eMBB and URLLC users, and then schedule the bandwidth resources according to the resource scheduling mechanism. After the end of scheduling, the intelligent agent of the Dueling DQN obtains information during its interaction with the environment and calculates the of eMBB and URLLC users as an observation. Afterward, the observation is entered into the Q-network to form the initial state.
Each iteration performs the operations as follows. The BS selects a resource allocation action based on the policy in the Dueling DQN, after which scheduling is performed. Then, the user receives the resource allocated by the BS, and and are updated in the Dueling DQN. Each state in the state space is the number of eMBB and URLLC packets successfully transferred. Each action in the action space is the bandwidth resource allocated to users by BS based on the network utility and the state feedback from users. The SE and the packet dropping probabilities are calculated according to Equations (11), (13) and (15). Thereby, the network utility can be calculated as shown in Equation (16). It is worth mentioning that the reward calculation formula is one of Equations (25)–(28). Once again, the is calculated as the next state. Then, the is imported to Dueling DQN for training.
For each iteration, the training process is as follows. Firstly, the agent obtains in the response of the environment, which is saved in the replay memory as a transfer sample. After enough data are deposited in the sample pool, a minibatch-sized transaction is randomly selected in the sample pool for training. Secondly, the evaluation Q-network of the agent adds the advantage function of centralized processing to the state-value function to obtain the current Q value, as illustrated in Equation (20). Meanwhile, Equation (21) is the formula used by the intelligent agent to calculate the target Q value. Moreover, the action that maximizes the current Q value in a given state is selected on the basis of the -greedy strategy. Finally, the current update of Q network parameters is based on the loss function in Equation (22) and the gradient descent method in Equation (23). Consistent with Equation (24), the current Q-network parameters are cloned into the target Q-network by resetting to complete the parameter update of the target Q-network after C iterations.
Using the predetermined number of iterations, the value function network with great performance is trained. The Dueling DQN is capable of obtaining an action under the
-greedy strategy for a given state to reduce the loss function and improve the cumulative expected reward. Therefore, the best scheme of resource allocation and scheduling can be obtained in the eMBB and URLLC hybrid service system, which improves the QoE of URLLC, SE and network utility while ensuring the QoE of eMBB. The pseudocode of the proposed algorithm is presented in Algorithm 1.
| Algorithm 1. The Dueling DQN based slicing resource allocation and scheduling |
| 1: | Initialize the replay memory , the capacity , the current and target action-value function and with random weights , the parameter and ; |
| 2: | Choose random action to allocate bandwidth for eMBB and URLLC users; |
| 3: | Scheduling: |
| 4: | User The bandwidth resources; |
| 5: | The URLLC users continue to request resources; |
| 6: | The eMBB users The URLLC users; |
| 7: | The calculated ; |
| 8: | Repeat |
| 9: | For iteration = 1, to T, do |
| 10: | Policy choosed; |
| 11: | Execution Scheduling; |
| 12: | The SE is calculated as shown in Equation (11); |
| 13: | The and are calculated on the basis of Equations (13) and (15); |
| 14: | Calculate the network utility based on Equation (16); |
| 15: | Calculate the reward based on one of Equations (25)–(28); |
| 16: | The calculated ; |
| 17: | # Train Dueling DQN; |
| 18: | The is stored in of Dueling DQN; |
| 19: | The agent samples from ; |
| 20: | Define according to Equation (20); |
| 21: | Set |
| 22: | The agent updates the network parameters by ; |
| 23: | Executed every C iterations; |
| 24: |
End for |
| 25: | Until The end of the iterations. |
3.3. Time Complexity Analysis of Algorithm
The time complexity of the training phase needs to consider the time complexity of training the Q network and the number of attempts needed to train the Q network. In the process of training the Q network, the connection weights between every two adjacent layers of neurons need to be updated. We set the number of layers of the Q network as
, the number of neurons in the
layer to be
, and the number of iterations in each training to be
, then the time complexity
of training a Q network once can be calculated as.
We denote the total number of iterations in the algorithm as
, and the number of steps in each iteration as
, then the number of times to train the Q network is
, so the time complexity of the proposed algorithm training phase can be calculated as
The time complexity of the online training phase of the deep reinforcement learning algorithm is high, but after the Q network is trained, the Q network does not need to be updated in the running phase, and the time complexity is low, which can meet the requirements of online decision-making time under real-time network conditions. Since the algorithms we compared in the simulation are all deep reinforcement learning algorithms and set the same parameters, they are roughly the same in terms of algorithm complexity.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}