
A 2D-Lidar-Equipped Unmanned Robot-Based Approach for Indoor Human Activity Detection




Abstract
:1. Introduction
- We address the different challenges that come along with such an approach, namely (i) the continuous movement of the Lidar, which makes it hard to keep track of the location of the subject, (ii) the cases when the fall activity might occur when the falling person is hidden by obstacles, and (iii) the fact that the manifestation of an activity from the Lidar’s perspective varies greatly depending on the relative position between the subject and the Lidar.
- We evaluate different tuning parameters for our proposed approach and derive the optimal configuration for better activity detection.
- We introduce a novel simulator that simulates the behavior of cleaning robots equipped with sensors in the presence of a humans in indoor environments.
2. Related Work and Motivations
2.1. Related Work
2.2. Motivations
3. Key Concepts
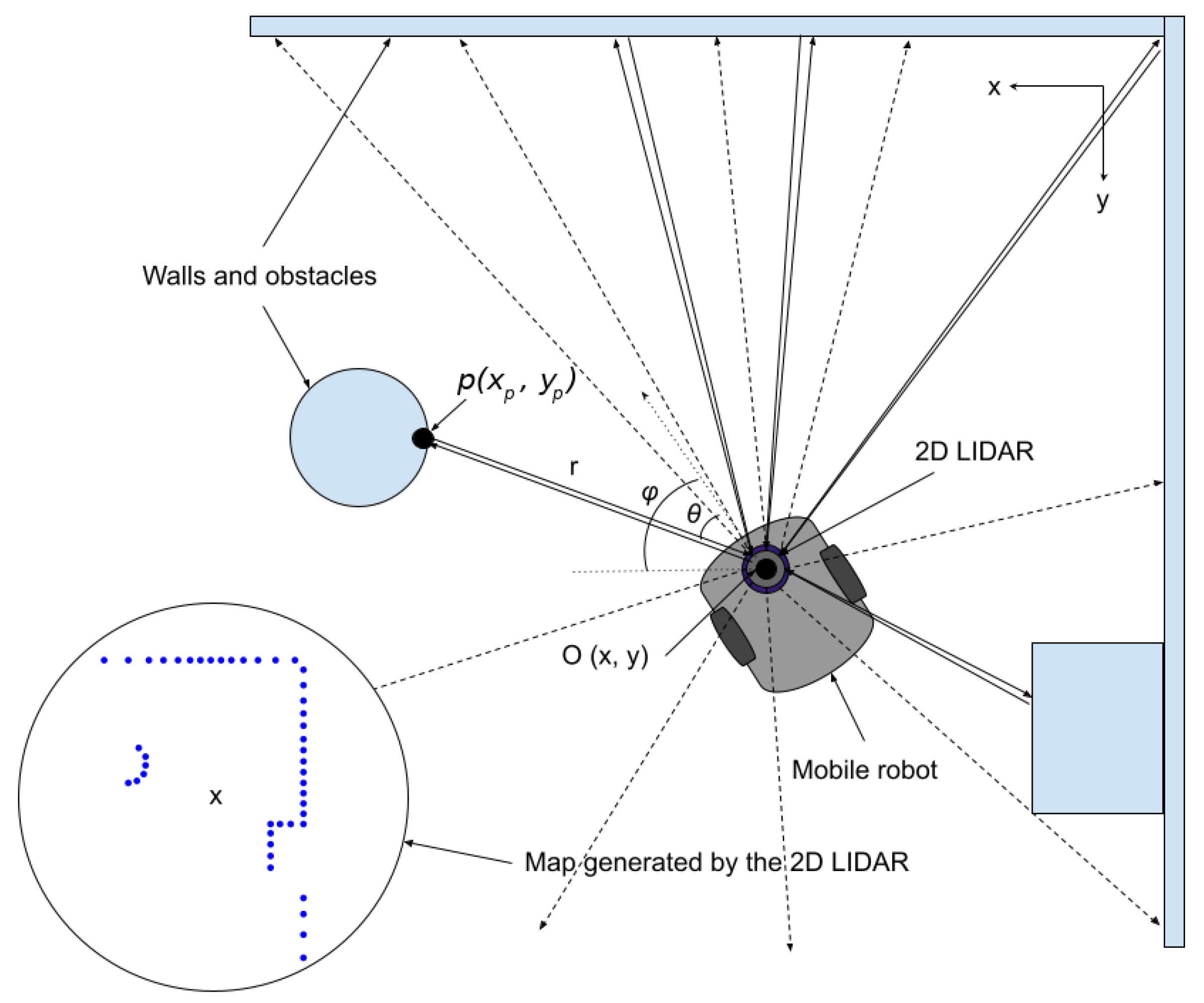
3.1. Lidar Technology
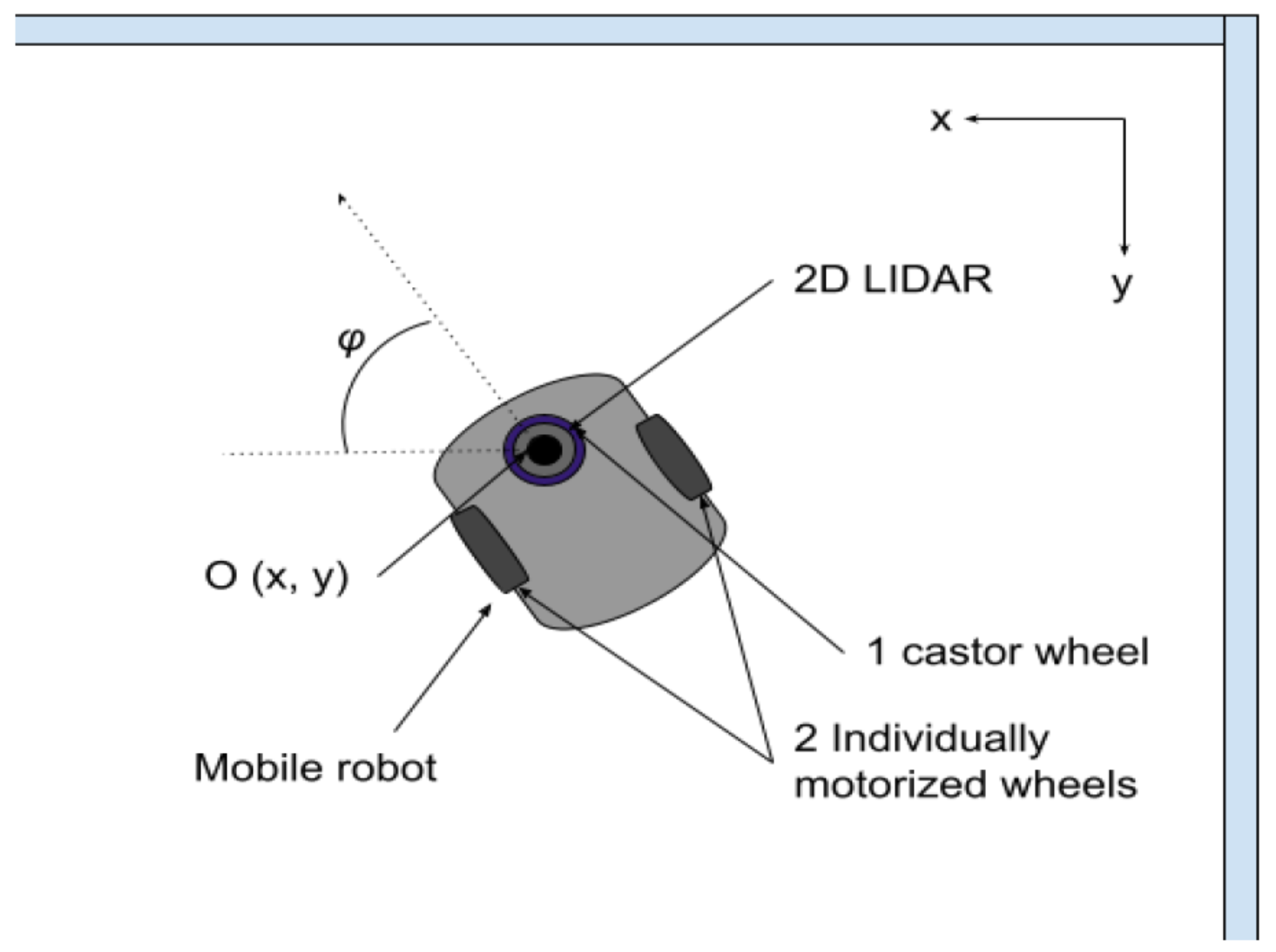
3.2. Mobile Robots
3.3. Robot Operating Systems (ROS) and Unity ROS Simulation
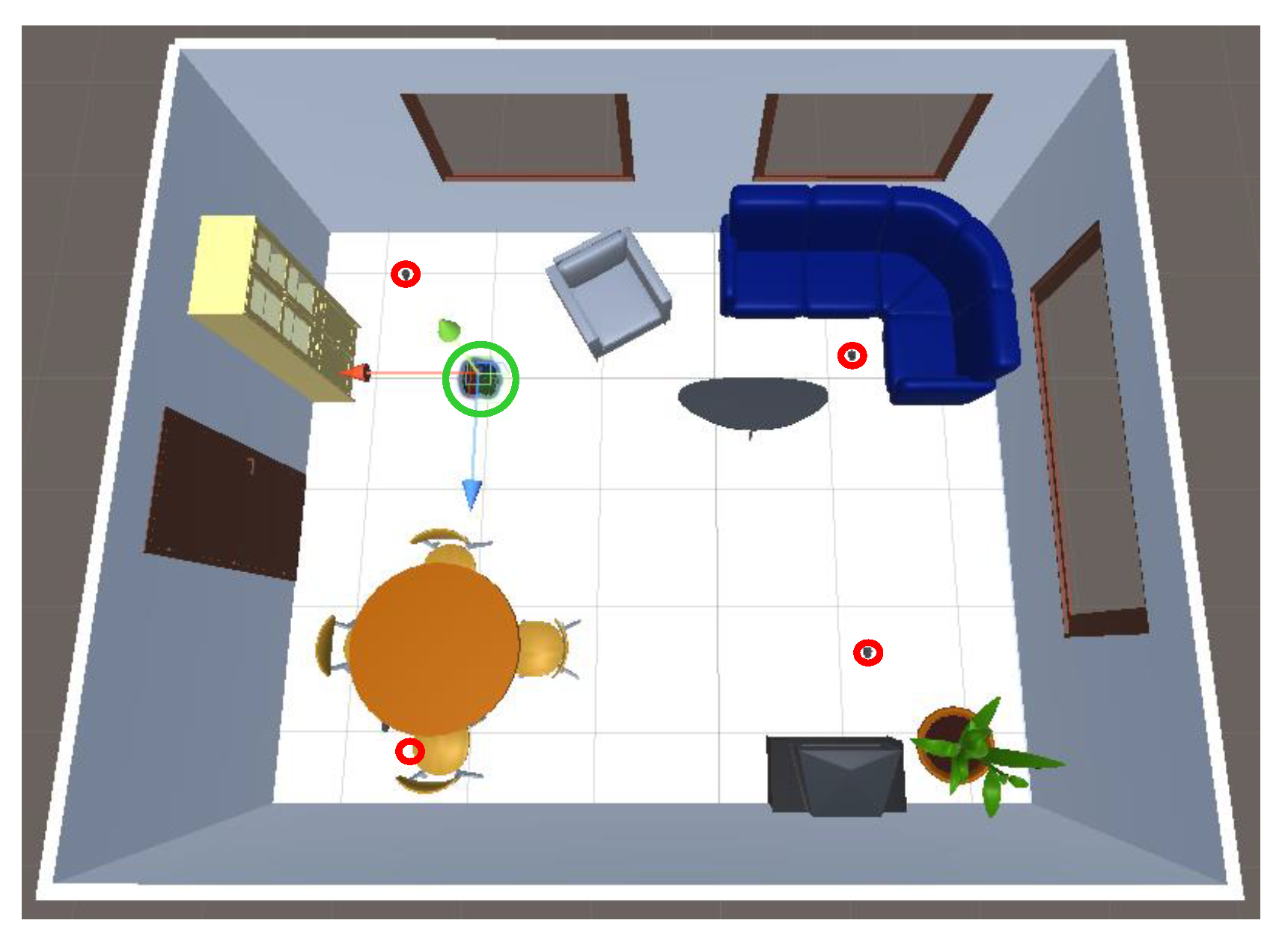
4. Simulator
4.1. Activity-Related Data Collection
4.2. Physics Engine
- The distance measurement error , referring to the inaccuracy in the estimation of the distance and presented in the percentage of the actual distance measured by the simulation Lidar.
- Missing data points , referring to the number of points for which the Lidar emits a light beam but does not receive the reflection, presented in the percentage of data points that are lost due to bad reflection.
- Wrong data points , referring to the number of points where the laser beam was reflected on multiple objects and was received in the wrong angle, leading to a wrongly detected point.
- Angle inaccuracy , referring to how different the measured angle is from the actual one. This is because the Lidar keeps on rotating, and while we assume the exact same angles for each rotation, this is not the case in the real world. It is also presented in an interval of error .
4.3. Robot Simulation
4.4. Additional Features
4.5. Simulator Output
4.5.1. Naming Convention
- Measurement point:A measurement point p is the individual point measured at a time t by the Lidar. It is represented as the tuple , where r is the measured distance and is the angle of measurement. This measurement point is measured from the Lidar’s perspective.
- Scan: A scan is the set of measurement points within a single rotation of the Lidar. Given the high speed of rotation (i.e., over 10 Hz), we could assume that all measurement points taken during one rotation correspond to a single point in time t. A scan can therefore be represented as the tuplewhere is the measurement point and N is the total number of measurement points during the rotation. Theoretically, N is dependent on the rotation, as the number of measurement points collected in one rotation is not always the same; therefore, N should rather be referred to as . However, in our work we do normalize the scans via interpolation to have exactly so that, for each 0.5, a measurement point is recorded (i.e., ).
4.5.2. Output Data
- Lidar-generated data points: They include the scans that the Lidar mounted on the robot generate. This is a set of scans , where is the number of rotations performed by the Lidar during the entire duration of the scenario. .
- Lidar location during the scenario: This is interpolated in a way where a pair of coordinates is generated every time a scan is generated; that is, the location of the Lidar is reported alongside with each individual scan. This is a set . The Lidar location is supposed to be known at any given moment, as the robot is expected to be self-aware of its position within the house/room for cleaning purposes.
- Subject’s location: Similar to the way we generate the coordinates of the Lidar, for every time step t (the time of the scan collected by the robot), the location of the subject is reported. This is also a set of coordinates .
- The activities performed by the subject: During the annotation, each activity happens over a certain duration of time, and all scans that took place during that duration will be given the label associated with that activity. This translates into the set , where is the ground-truth activity performed during the time step t of the scenario.
- Room map: This is a simple matrix-shaped image, with a certain degree of precision indicating whether or not there is an obstacle in a given position. Each pixel contains a value set to 1 or 0, indicating whether or not there is an obstacle in the location of the room corresponding to that pixel. A map of shape pixels for a room of dimensions indicates that each pixel represents a rectangle of the room of the size .
5. Proposed Method for Human Localization and Activity Detection
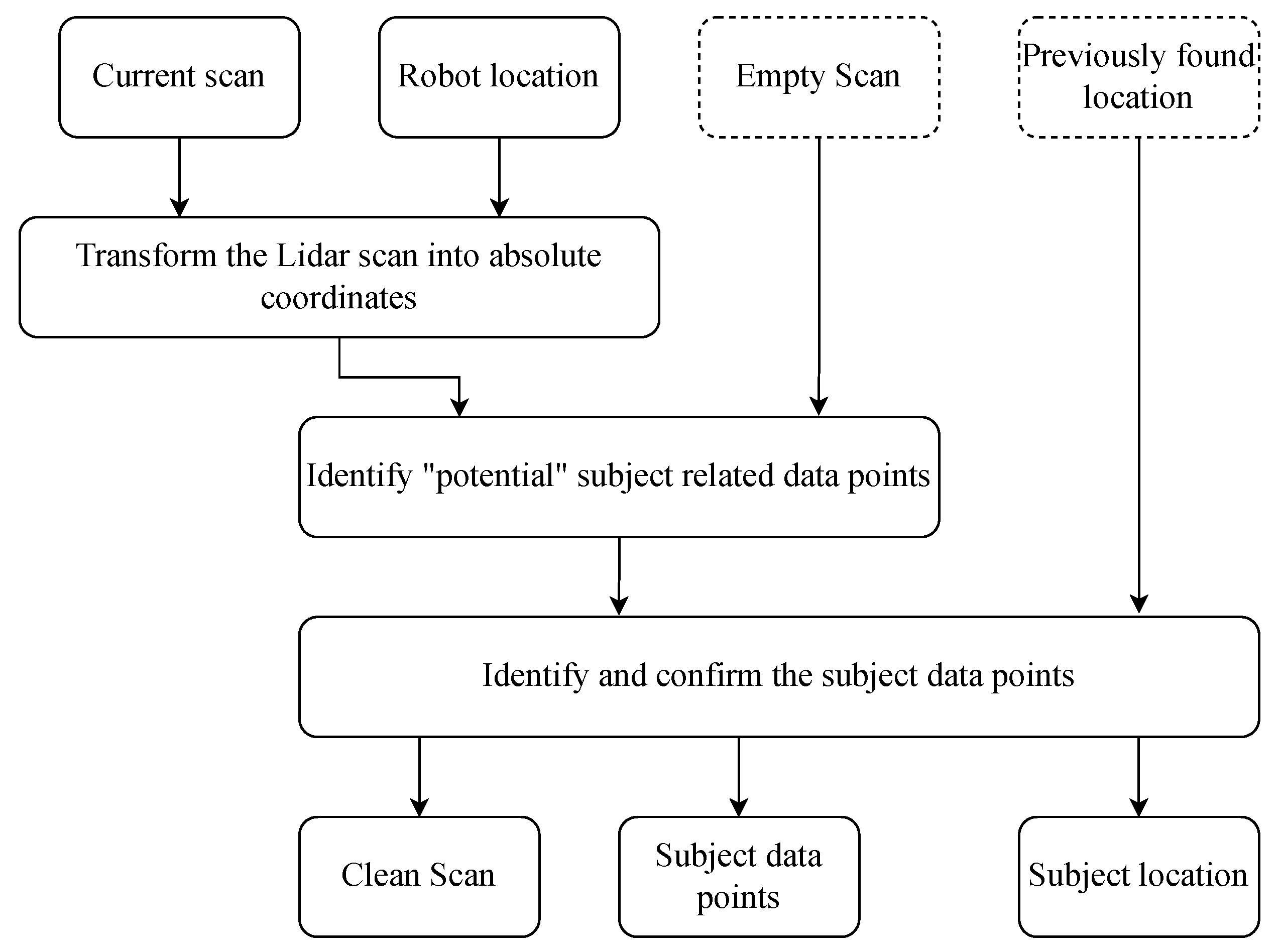
5.1. Localization
| Algorithm 1: Location identification |
 |
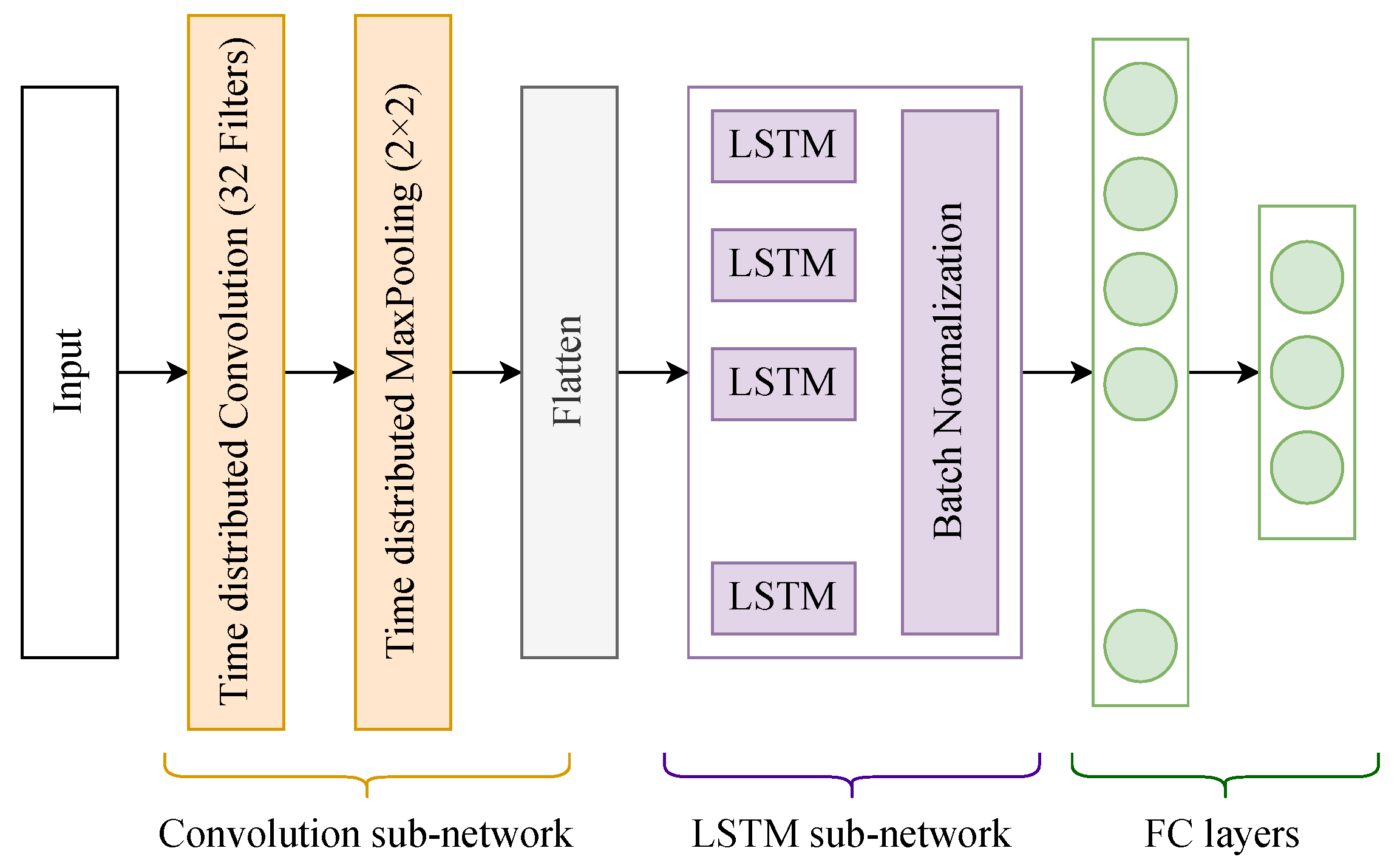
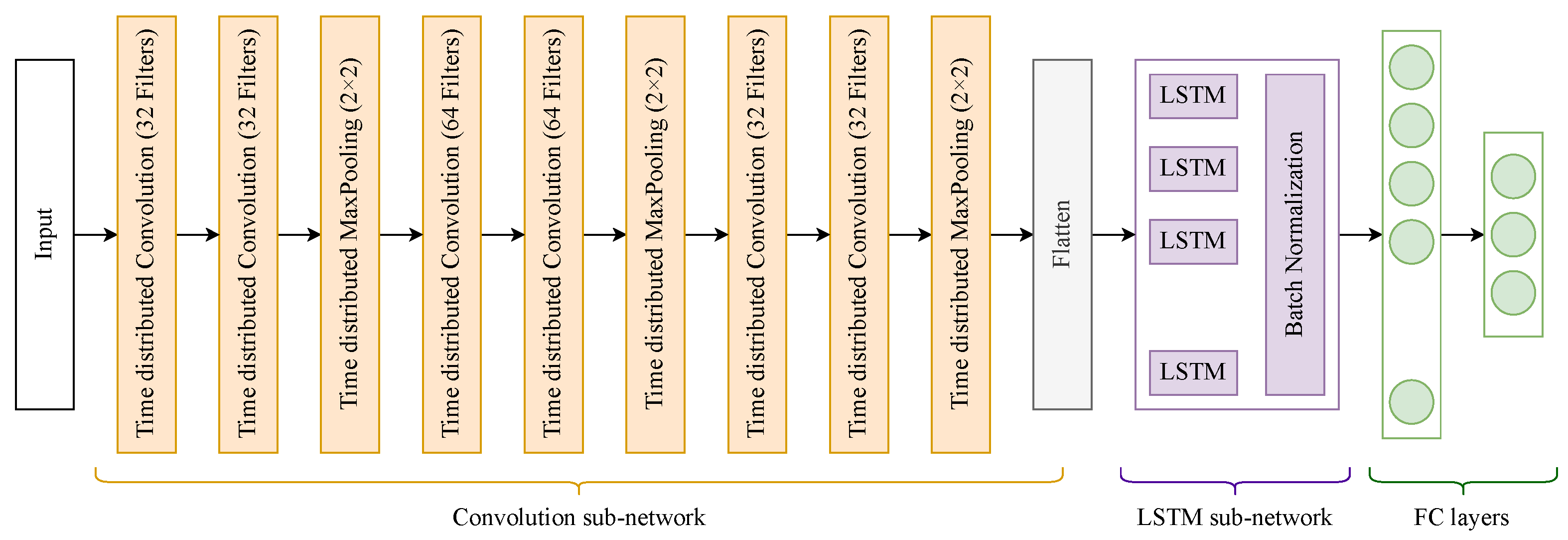
5.2. Activity Recognition
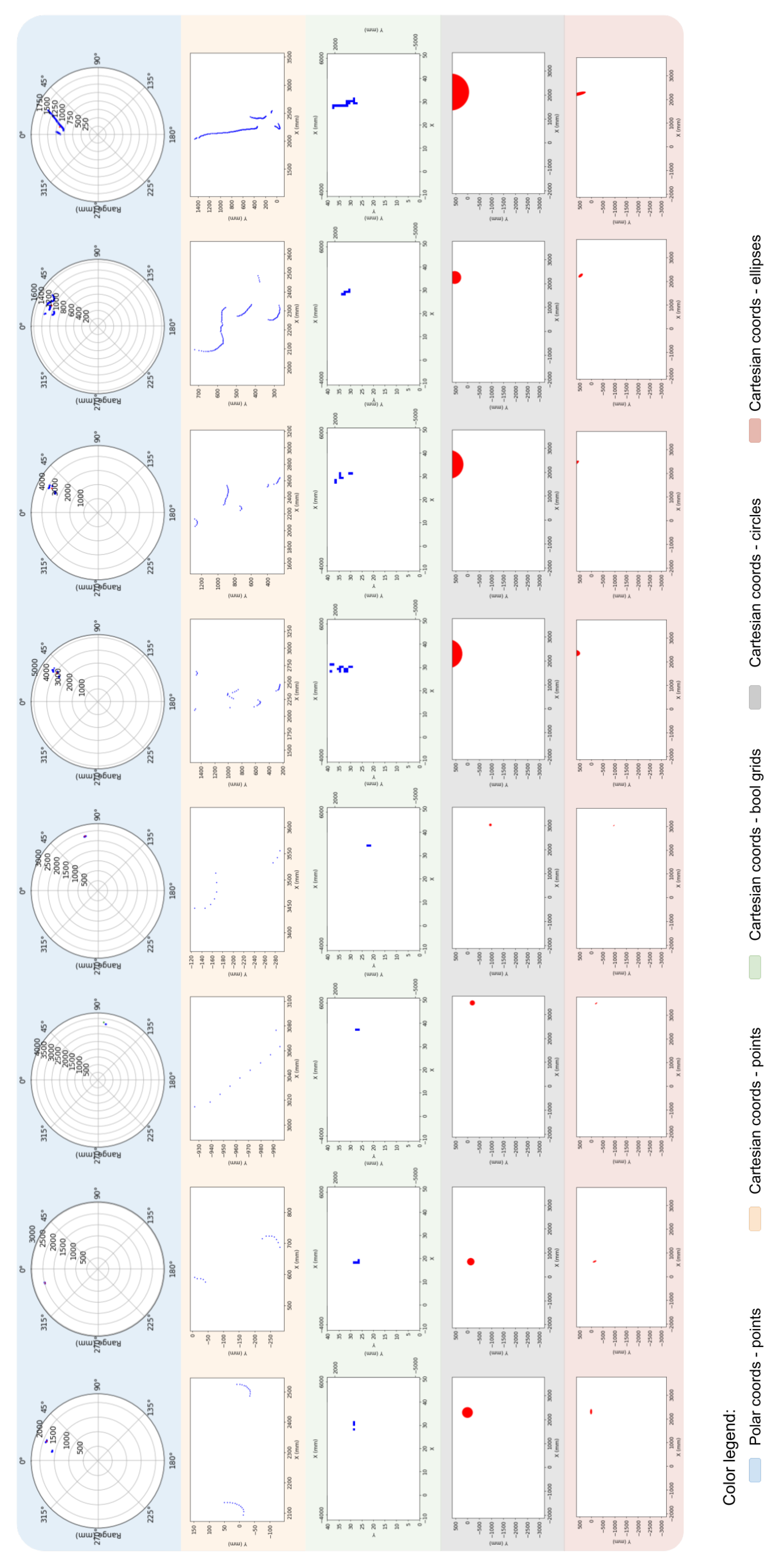
- Boolean grid: in this variation, we create a grid of a fixed size supposedly fitting the largest room possible, similar to how we described a map in Section 4.5.2, given a certain required degree of precision, each pixel indicating whether or not there is a data point in the part of the map that corresponds to that pixel. In other words, each pixel contains a value set to 1 or 0, indicating whether or not there is an obstacle in the location of the room corresponding to that pixel. A map of shape pixels for a room of dimensions indicates that each pixel represents a rectangle of the room of size .
- Image with Circles: in this variation, we assume a white image with a size of pixels. Assuming a larger image size in this variation, plotting small dots indicating the user data points make them almost invisible. We therefore plot each data point with a circle whose center is the coordinates of the data points and with a radius large enough to make it visible in the image.
- Image with ellipses: this variation is similar to the previous one. The only difference is that we use ellipses with radii whose centers are the coordinates of the data points themselves.
6. Evaluation of the Proposed Approach
6.1. Simulation Parameters
6.2. Simulation Results
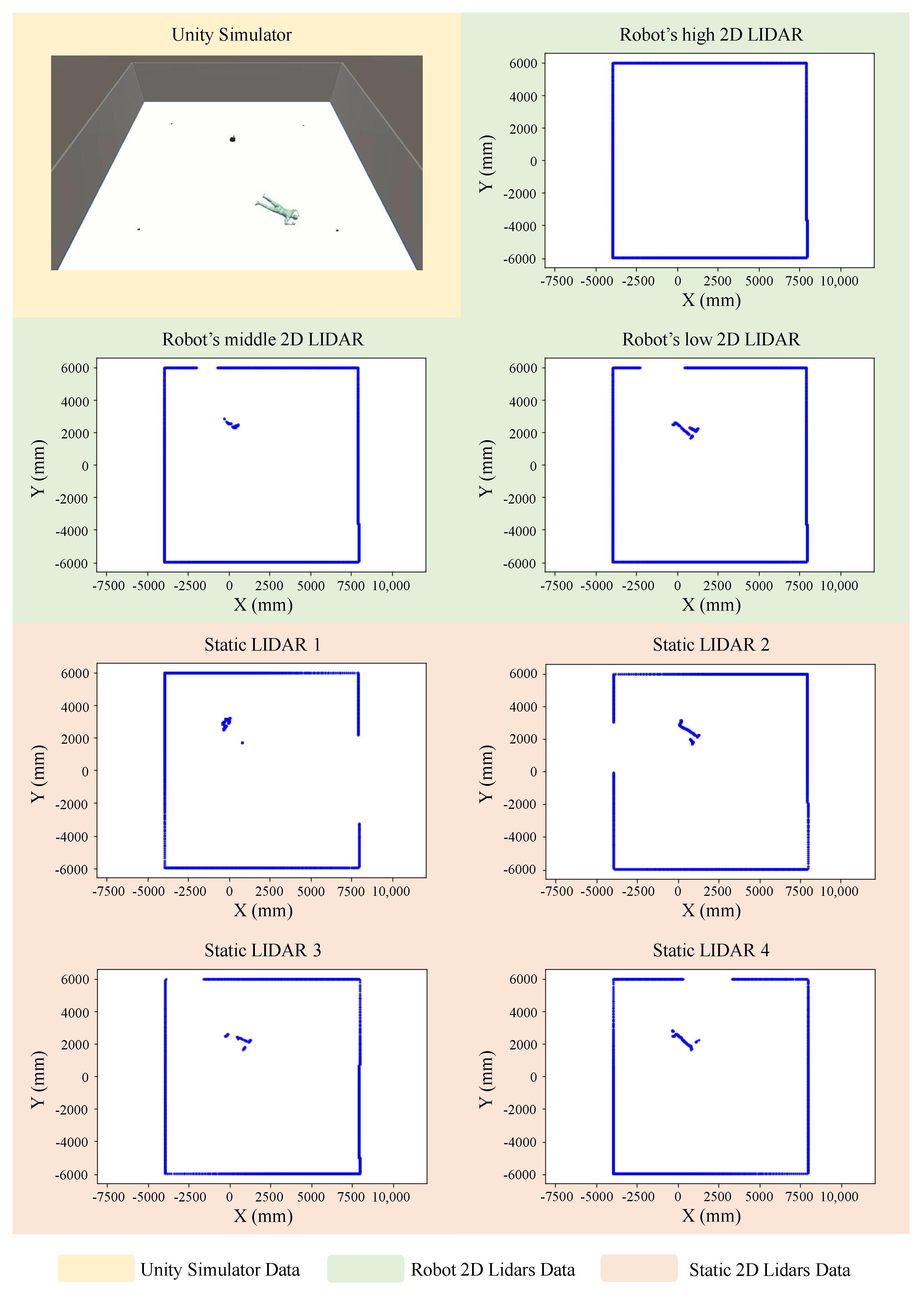
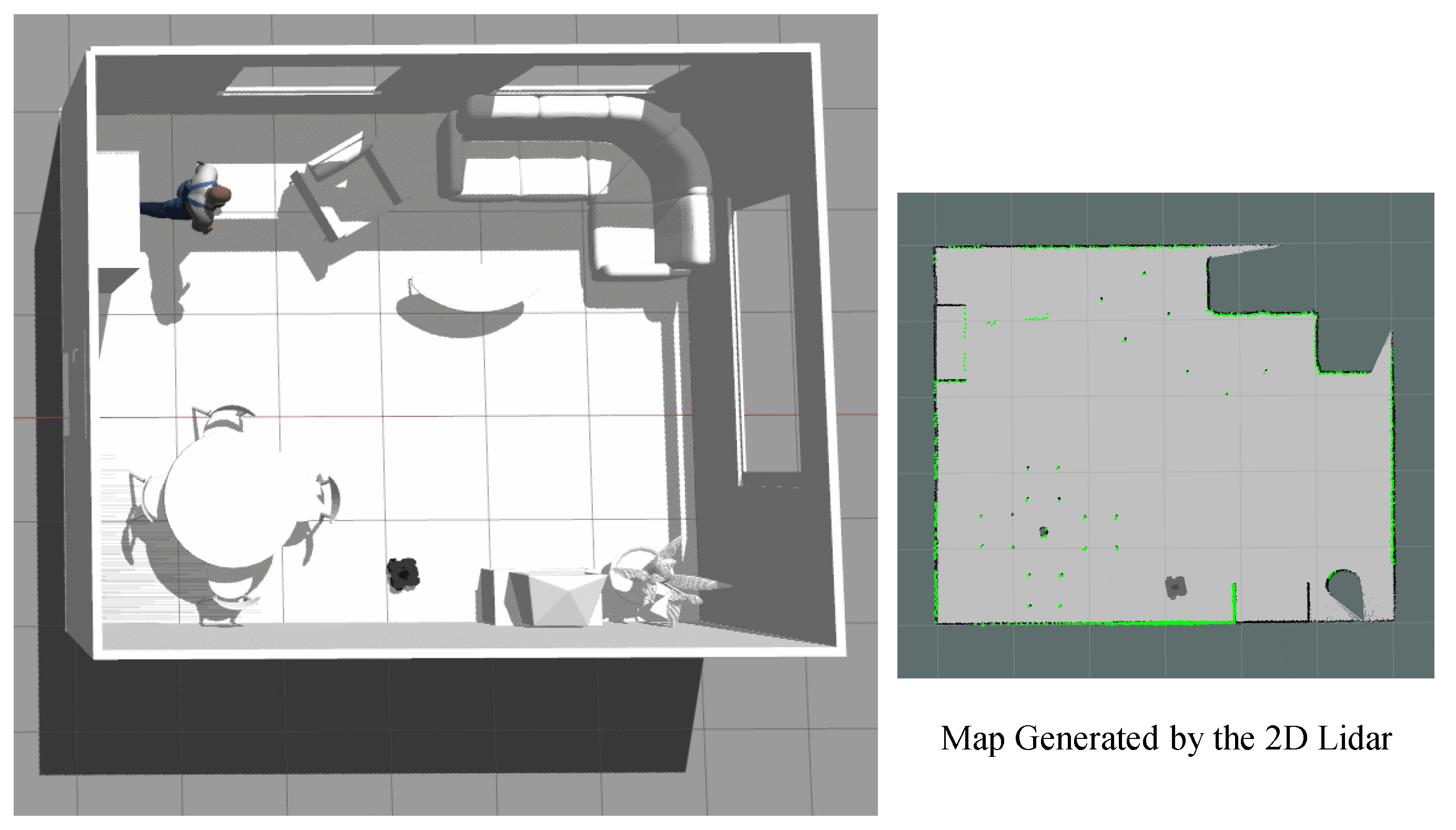
6.2.1. Output Visualization
6.2.2. Data Acquisition
6.2.3. Evaluation Metrics
- True positive = the predicted label of the sample is the same as the label of the activity in question.
- False negative = the sample of the activity in question was wrongly given the label of another activity.
- True negative = a sample from a different activity was indeed given a label that is not that of the activity in question.
- False positive = a sample from a different activity was wrongly given the label of the activity in question.
- Accuracy: The accuracy reflects how good the overall classification is. It shows how many samples are correctly classified compared to the total number of samples. It is expressed as follows:
- Precision: The precision reflects how good the classifier is at identifying a certain class without confusing it with another. For the instances classified as belonging to that class, it computes the ratio of those that indeed belong to it. It is expressed as follows:
- Recall: The recall reflects how good the classifier is at classifying the instance of a given class. In other words, out of all the instances of a given class, it computer the ratio of those that were classified as belonging to it. It is expressed as follows:
- -Score: The -score is a metric that combines both the precision and recall, to address issues related to the misleading values of these two metrics when an unbalanced data set is use. It is defined as follows:
6.2.4. Classification Results
- (a)
- Data representation techniques comparison
- (b)
- Proposed method classification results
- (c)
- Comparison with the conventional method [4]
- (d)
- Comparison with other existing method [8]
6.3. Complexity Analysis
- Step 1: the clustering of measurement points for every scan.
- Step 2: data transformation for every scan.
- Step 3: the classification of the entire sample.
6.3.1. Complexity of Step 1
6.3.2. Complexity of Step 2
6.3.3. Complexity of Step 3
6.3.4. Overall Complexity
6.4. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AMASS | Archive of Motion capture As Surface Shapes |
| ConvLSTM | Convolutional Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| DALY | Disability-Adjusted Life Year |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| DL | Deep Learning |
| EKF | Extended Kalman Filter |
| FN | False Negative |
| FP | False Positive |
| HAR | Human Activity Recognition |
| HOG | Histogram of Oriented Gradients |
| IR | Infrared |
| LIDAR | LIght Detection And Ranging |
| LOS | Line Of Sight |
| LRF | Laser Range Finder |
| LSTM | Long Short-Term Memory |
| RGB | Red Green Blue (color channels) |
| RGB-D | Red Green Blue Depth (color + Depth channels) |
| ROS | Robot Operating System |
| RNN | Recurrent Neural Network |
| SLAM | Simultaneous Localization and Mapping |
| SSD | Single-Shot Multibox Detector |
| SVM | Support Vector Machine |
| TCN | Temporal Convolutional Network |
| TN | True Negative |
| TP | True Positive |
| URDF | Unified Robot Description Format |
Appendix A
Appendix A.1

Appendix A.2

References
- WHO. Falls; World Health Organization: Geneva, Switzerland, 2021. [Google Scholar]
- Nakamura, T.; Bouazizi, M.; Yamamoto, K.; Ohtsuki, T. Wi-Fi-Based Fall Detection Using Spectrogram Image of Channel State Information. IEEE Internet Things J. 2022, 9, 17220–17234. [Google Scholar] [CrossRef]
- Bouazizi, M.; Ye, C.; Ohtsuki, T. Activity Detection using 2D LIDAR for Healthcare and Monitoring. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Bouazizi, M.; Ye, C.; Ohtsuki, T. 2D LIDAR-Based Approach for Activity Identification and Fall Detection. IEEE Internet Things J. 2021, 9, 10872–10890. [Google Scholar] [CrossRef]
- Muthukumar, K.A.; Bouazizi, M.; Ohtsuki, T. A Novel Hybrid Deep Learning Model for Activity Detection Using Wide-Angle Low-Resolution Infrared Array Sensor. IEEE Access 2021, 9, 82563–82576. [Google Scholar] [CrossRef]
- Bouazizi, M.; Ye, C.; Ohtsuki, T. Low-Resolution Infrared Array Sensor for Counting and Localizing People Indoors: When Low End Technology Meets Cutting Edge Deep Learning Techniques. Information 2022, 13, 132. [Google Scholar] [CrossRef]
- Bellotto, N.; Hu, H. Multisensor-Based Human Detection and Tracking for Mobile Service Robots. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2009, 39, 167–181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, F.; Poslad, S.; Bodanese, E. Temporal Convolutional Networks for Multiperson Activity Recognition Using a 2-D LIDAR. IEEE Internet Things J. 2020, 7, 7432–7442. [Google Scholar] [CrossRef]
- Gori, I.; Sinapov, J.; Khante, P.; Stone, P.; Aggarwal, J.K. Robot-Centric Activity Recognition ‘in the Wild’. In Proceedings of the Social Robotics; Tapus, A., André, E., Martin, J.C., Ferland, F., Ammi, M., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 224–234. [Google Scholar]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of posture and motion by accelerometry: A validation study in ambulatory monitoring. Comput. Hum. Behav. 1999, 15, 571–583. [Google Scholar] [CrossRef]
- Joseph, C.; Kokulakumaran, S.; Srijeyanthan, K.; Thusyanthan, A.; Gunasekara, C.; Gamage, C. A framework for whole-body gesture recognition from video feeds. In Proceedings of the 2010 5th international Conference on Industrial and Information Systems, St. Louis, MI, USA, 12–15 December 2010; IEEE: New York, NY, USA, 2010; pp. 430–435. [Google Scholar]
- Yang, J.; Lee, J.; Choi, J. Activity recognition based on RFID object usage for smart mobile devices. J. Comput. Sci. Technol. 2011, 26, 239–246. [Google Scholar] [CrossRef]
- Iosifidis, A.; Tefas, A.; Pitas, I. View-invariant action recognition based on artificial neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 412–424. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 21–23 September 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Chaquet, J.M.; Carmona, E.J.; Fernández-Caballero, A. A survey of video datasets for human action and activity recognition. Comput. Vis. Image Underst. 2013, 117, 633–659. [Google Scholar] [CrossRef] [Green Version]
- Rubio, F.; Valero, F.; Llopis-Albert, C. A review of mobile robots: Concepts, methods, theoretical framework, and applications. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419839596. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Mishra, A.K.; Limosani, R.; Scafuro, M.; Cauli, N.; Santos-Victor, J.; Mazzolai, B.; Cavallo, F. Control strategies for cleaning robots in domestic applications: A comprehensive review. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419857432. [Google Scholar] [CrossRef] [Green Version]
- Zafari, F.; Gkelias, A.; Leung, K.K. A Survey of Indoor Localization Systems and Technologies. IEEE Commun. Surv. Tutor. 2019, 21, 2568–2599. [Google Scholar] [CrossRef] [Green Version]
- Möller, R.; Furnari, A.; Battiato, S.; Härmä, A.; Farinella, G.M. A Survey on Human-aware Robot Navigation. Robot. Auton. Syst. 2021, 145, 103837. [Google Scholar] [CrossRef]
- Fu, B.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Sensing technology for human activity recognition: A comprehensive survey. IEEE Access 2020, 8, 83791–83820. [Google Scholar] [CrossRef]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Haas, J.K. A history of the unity game engine. Diss. Worcest. Polytech. Inst. 2014, 483, 484. [Google Scholar]
- Hautamäki, J. ROS2-Unity-XR interface demonstration. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Wang, Z.; Han, K.; Tiwari, P. Digital twin simulation of connected and automated vehicles with the unity game engine. In Proceedings of the 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), Beijing, China, 15 July–15 August 2021; IEEE: New York, NY, USA, 2021; pp. 1–4. [Google Scholar]
- Linder, T.; Breuers, S.; Leibe, B.; Arras, K.O. On multi-modal people tracking from mobile platforms in very crowded and dynamic environments. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5512–5519. [Google Scholar] [CrossRef]
- Okusako, S.; Sakane, S. Human Tracking with a Mobile Robot using a Laser Range-Finder. J. Robot. Soc. Jpn. 2006, 24, 605–613. [Google Scholar] [CrossRef]
- Arras, K.O.; Grzonka, S.; Luber, M.; Burgard, W. Efficient people tracking in laser range data using a multi-hypothesis leg-tracker with adaptive occlusion probabilities. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 1710–1715. [Google Scholar] [CrossRef] [Green Version]
- Taipalus, T.; Ahtiainen, J. Human detection and tracking with knee-high mobile 2D LIDAR. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics, Phuket, Thailand, 7–11 December 2011; pp. 1672–1677. [Google Scholar] [CrossRef]
- Leigh, A.; Pineau, J.; Olmedo, N.; Zhang, H. Person tracking and following with 2D laser scanners. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 726–733. [Google Scholar] [CrossRef] [Green Version]
- Higueras, Á.M.G.; Álvarez-Aparicio, C.; Olivera, M.C.C.; Lera, F.J.R.; Llamas, C.F.; Martín, F.; Olivera, V.M. Tracking People in a Mobile Robot From 2D LIDAR Scans Using Full Convolutional Neural Networks for Security in Cluttered Environments. Front. Neurorobot. 2019, 12, 85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pantofaru, C.; Lu, D.V. ROSPackagesleg_detector - ROS Wiki; ROS org: San Martin, CA, USA, 2014. [Google Scholar]
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Mataric, M.J. The Robotics Primer; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Miller, D.; Navarro, A.; Gibson, S. Advance Your Robot Autonomy with ROS 2 and Unity; ROS org: San Martin, CA, USA, 2021. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; (IEEE Cat. No. 04CH37566). IEEE: New York, NY, USA, 2004; Volume 3, pp. 2149–2154. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. Mujoco: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; IEEE: New York, NY, USA, 2012; pp. 5026–5033. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; PMLR: London, UK, 2017; pp. 1–16. [Google Scholar]
- Macenski, S.; Foote, T.; Gerkey, B.; Lalancette, C.; Woodall, W. Robot Operating System 2: Design, architecture, and uses in the wild. Sci. Robot. 2022, 7, eabm6074. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M.J. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5442–5451. [Google Scholar]
- Pyo, Y.; Shibata, Y.; Jung, R.; Lim, T.R. Introducing the Turtlebot3. In Proceedings of the ROSCon Seoul 2016, Seoul, Republic of Korea, 8–9 October 2016; Open Robotics: Mountain View, CA, USA, 2016. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. Density-based spatial clustering of applications with noise. In Proceedings of the International Conference of Knowledge Discovery and Data Mining, Portland, OR, USA, 13–17 August 1996; Volume 240. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Signification | Value |
|---|---|---|
| The error in the distance measurement | 2% | |
| The percentage of measurement points lost | 4% | |
| The percentage of non-real points detected | 2% | |
| The error in the estimation of the angle | 0.04° |
| Parameter | Signification | Value |
|---|---|---|
| Scan rate | The frequency of rotation of the Lidar | 20 Hz |
| N | The number of measurements per rotation | 720 |
| The maximum velocity of the robot | 0.2 m/s | |
| The maximum velocity of the human | 1 m/s |
| Parameter | Signification | Value |
|---|---|---|
| The threshold to consider a data point as non-room-related | 0.2 m% | |
| The min distance to a centroid for a point to be considered | 0.8 m |
| Activity | Training | Test |
|---|---|---|
| Crawling forward | 376 | 94 |
| Falling down | 340 | 85 |
| Getting up | 1460 | 365 |
| Lying down | 3608 | 902 |
| Running | 1112 | 278 |
| Sitting on the floor | 1580 | 395 |
| Standing | 3196 | 799 |
| Walking | 2948 | 737 |
| Walking unsteadily | 2760 | 690 |
| Boolean Grid | Circles Image | Ellipses Image | |
|---|---|---|---|
| Accuracy | 91.3% | 78.8% | 78.3% |
| Precision | 91.3% | 77.2% | 76.4% |
| Recall | 91.3% | 78.8% | 78.3% |
| F1-score | 91.3% | 76.5% | 76.9% |
| Activity | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Crawling | 88.3% | 91.2% | 88.3% | 89.7% |
| Falling down | 81.2% | 88.5% | 81.2% | 84.7% |
| Getting up | 93.4% | 90.0% | 93.4% | 91.7% |
| Lying down | 99.0% | 99.3% | 99.0% | 99.2% |
| Running | 73.0% | 77.5% | 73.0% | 75.2% |
| Sitting | 93.9% | 95.1% | 93.9% | 94.5% |
| Standing | 97.4% | 95.3% | 97.4% | 96.3% |
| Walking | 83.4% | 87.0% | 83.4% | 85.2% |
| Unsteady walk | 89.1% | 85.1% | 89.1% | 87.0% |
| Overall | 91.3% | 91.3% | 91.3% | 91.3% |
| Activity | Classified as | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| (A1) | (A2) | (A3) | (A4) | (A5) | (A6) | (A7) | (A8) | (A9) | |
| Crawling (A1) | 83 | 2 | 5 | 2 | 0 | 0 | 0 | 0 | 2 |
| Falling down (A2) | 5 | 69 | 1 | 2 | 0 | 5 | 1 | 2 | 0 |
| Getting up (A3) | 1 | 3 | 341 | 1 | 0 | 5 | 5 | 1 | 8 |
| Lying down (A4) | 1 | 2 | 3 | 893 | 0 | 2 | 0 | 0 | 1 |
| Running (A5) | 0 | 0 | 2 | 0 | 203 | 1 | 1 | 49 | 22 |
| Sitting (A6) | 0 | 1 | 5 | 1 | 1 | 371 | 5 | 4 | 7 |
| Standing (A7) | 1 | 0 | 4 | 0 | 2 | 0 | 778 | 2 | 12 |
| Walking (A8) | 0 | 1 | 5 | 0 | 44 | 1 | 15 | 615 | 56 |
| Unsteady walk (A9) | 0 | 0 | 13 | 0 | 12 | 5 | 11 | 34 | 615 |
| Proposed | Fixed Lidar (Highest) | Fixed Lidar (Lowest) | |
|---|---|---|---|
| Accuracy | 91.3% | 82.9% | 74.0% |
| Precision | 91.3% | 83.8% | 75.5% |
| Recall | 91.3% | 82.9% | 74.0% |
| F1-score | 91.3% | 83.4% | 74.7% |
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| Luo et al. [8]—variation 1 | 77.3% | 78.4% | 77.9% | 77.9% |
| Luo et al. [8]—variation 2 | 82.7% | 82.1% | 82.7% | 82.4% |
| Luo et al. [8]—original | 99.4% | 99.4% | 99.5% | 99.5% |
| Proposed method | 91.3% | 91.3% | 91.3% | 91.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouazizi, M.; Lorite Mora, A.; Ohtsuki, T. A 2D-Lidar-Equipped Unmanned Robot-Based Approach for Indoor Human Activity Detection. Sensors 2023, 23, 2534. https://doi.org/10.3390/s23052534
Bouazizi M, Lorite Mora A, Ohtsuki T. A 2D-Lidar-Equipped Unmanned Robot-Based Approach for Indoor Human Activity Detection. Sensors. 2023; 23(5):2534. https://doi.org/10.3390/s23052534
Chicago/Turabian StyleBouazizi, Mondher, Alejandro Lorite Mora, and Tomoaki Ohtsuki. 2023. "A 2D-Lidar-Equipped Unmanned Robot-Based Approach for Indoor Human Activity Detection" Sensors 23, no. 5: 2534. https://doi.org/10.3390/s23052534
APA StyleBouazizi, M., Lorite Mora, A., & Ohtsuki, T. (2023). A 2D-Lidar-Equipped Unmanned Robot-Based Approach for Indoor Human Activity Detection. Sensors, 23(5), 2534. https://doi.org/10.3390/s23052534