
A Model-Driven Channel Estimation Method for Millimeter-Wave Massive MIMO Systems

Abstract
:1. Introduction
2. System Model and Problem Description
2.1. System Model
2.2. Problem Description
3. Channel Estimation Network Based on Model-Driven Deep Learning
- 1.
- Gradient descent process: can be rewritten as
- 2.
- (Inverse) sparse transformation and residual learning process: The specific method of using sparse transformation is as follows
- 3.
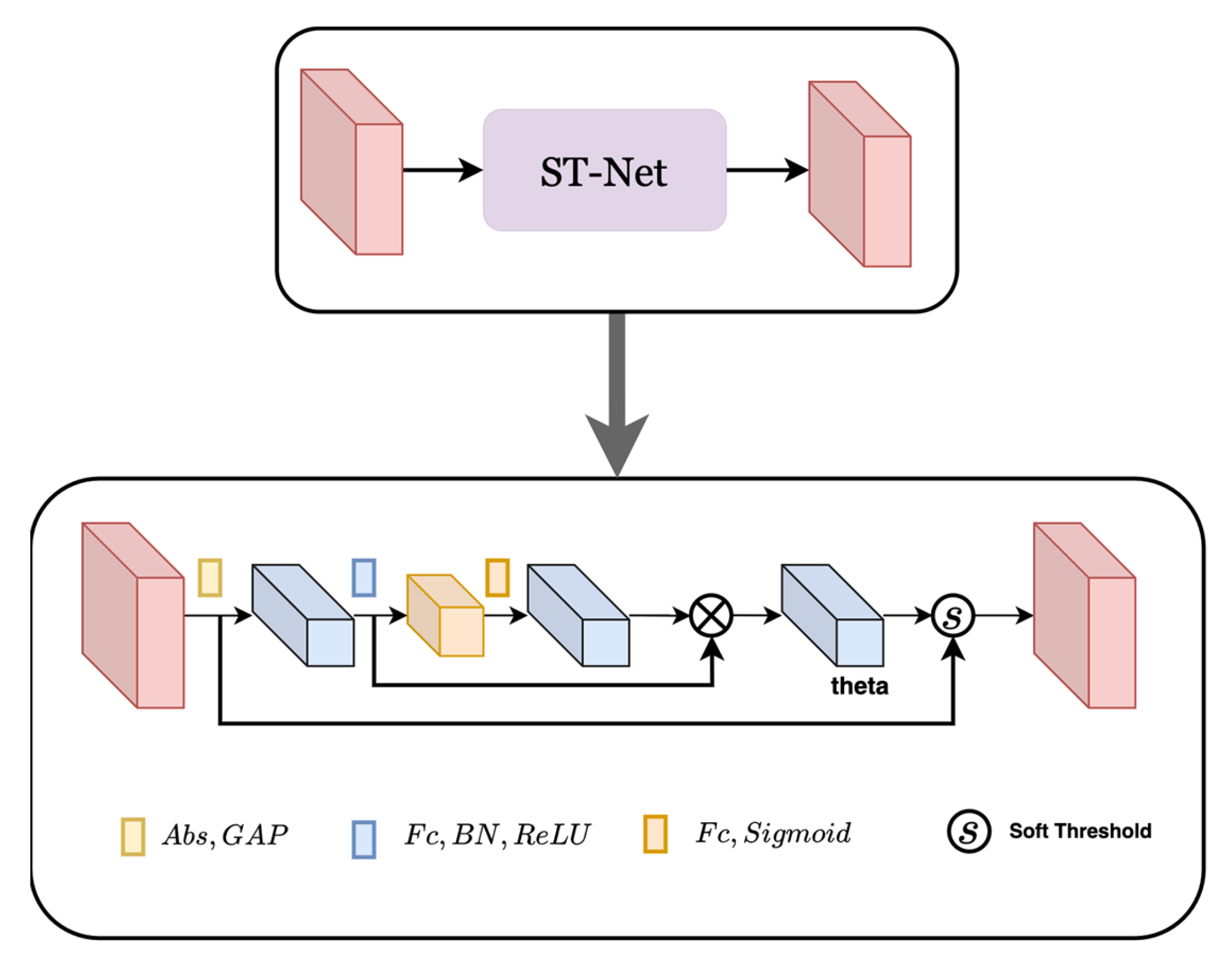
- Shrink Threshold Network (ST-Net) Based on Attention Mechanism: The choice of threshold in Equation (17) has a great influence on the estimation accuracy of the ALISTA-Net model. Since the noise amount of each input is different, ST-Net is introduced in the beam domain denoising stage, inspired by the deep residual shrinkage network DRSN-CW structure in the literature [23]. The basic module is shown in Figure 3. The structure of the proposed shrinkage threshold network based on the attention mechanism is shown in Figure 4. First, the threshold in the soft threshold function is automatically learned and set by the network, which reduces the loss of accuracy caused by the inaccurate manual setting of the threshold. Secondly, the threshold value in the soft threshold function of the network is a positive number within the appropriate value range, to avoid the output situation of all zeros. At the same time, each sample has its own unique set of thresholds, making the model more applicable to situations with different noise contents.
- 4.
- Training parameters: The trainable parameter set in ALISTA-Net is used . According to the above description, can be expressed as follows
- 5.
- Loss function: Since ALISTA-Net contains stages, the loss function of the training process designed in this paper is as follows
4. Simulation Verification and Result Analysis
4.1. Simulation Data and Parameter Settings
4.2. Simulation Result Analysis
- Ablation experiment
- Performance analysis
- Complexity analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bockelmann, C.; Pratas, N. Massive machine-type communications in 5G: Physical and MAC-layer solutions. IEEE Commun. Mag. 2016, 54, 59–65. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.J.; Yu, G.H.; Xu, H.Q. 6G mobile communication networks: Vision, challenge, and key technologies. Sci. China Inf. Sci. 2019, 49, 963–987. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Choi, K.J.; Kim, K.S. Massive MIMO full-duplex for high-efficiency next generation WLAN systems. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 19–21 October 2016; pp. 1152–1154. [Google Scholar]
- Wen, M. A Survey on Spatial Modulation in Emerging Wireless Systems: Research Progresses and Applications. IEEE J. Sel. Areas Commun. 2019, 37, 1949–1972. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Dang, S.; Huang, Y.; Chen, P.; Qi, X.; Wen, M.; Arslan, H. Composite Multiple-Mode Orthogonal Frequency Division Multiplexing with Index Modulation. IEEE Trans. Wirel. Commun. 2022. [Google Scholar] [CrossRef]
- Wu, X.; Claussen, H.; Di Renzo, M.; Haas, H. Channel Estimation for Spatial Modulation. IEEE Trans. Commun. 2014, 62, 4362–4372. [Google Scholar] [CrossRef] [Green Version]
- Pi, Z.; Khan, F. An introduction to millimeter-wave mobile broadband systems. IEEE Commun. Mag. 2011, 49, 101–107. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal Recovery from Random Measurements Via Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Gil, G.-T.; Lee, Y.H. Channel Estimation via Orthogonal Matching Pursuit for Hybrid MIMO Systems in Millimeter Wave Communications. IEEE Trans. Commun. 2016, 64, 2370–2386. [Google Scholar] [CrossRef]
- Manoj, A.; Kannu, A.P. Multi-user millimeter wave channel estimation using generalized block OMP algorithm. In Proceedings of the 2017 IEEE 18th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Sapporo, Japan, 4–6 July 2017; pp. 1–5. [Google Scholar]
- Malla, S.; Abreu, G. Channel estimation in millimeter wave MIMO Systems: Sparsity enhancement via reweighting. In Proceedings of the 2016 International Symposium on Wireless Communication Systems (ISWCS), Poznań, Poland, 20–23 September 2016; pp. 230–234. [Google Scholar]
- Cheng, X.; Li, L.; Du, L. ADMM-based channel estimation for mmWave massive MIMO systems. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 152–157. [Google Scholar]
- Gao, X.; Dai, L.; Han, S. Reliable Beamspace Channel Estimation for Millimeter-Wave Massive MIMO Systems with Lens Antenna Array. IEEE Trans. Wirel. Commun. 2017, 16, 6010–6021. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Wen, C.K.; Jin, S. Beamspace Channel Estimation in mmWave Systems Via Cosparse Image Reconstruction Technique. IEEE Trans. Commun. 2018, 66, 4767–4782. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.; Hu, C.; Dai, L.; Wang, Z. Channel Estimation for Millimeter-Wave Massive MIMO With Hybrid Precoding Over Frequency-Selective Fading Channels. IEEE Commun. Lett. 2016, 20, 1259–1262. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Chen, C.; Yi, N.; Lu, G.; Jin, Y. Channel Estimation Using Low-Resolution PSs for Wideband mmWave Systems. In Proceedings of the 2017 IEEE 85th Vehicular Technology Conference (VTC Spring), Sydney, NSW, Australia, 4–7 June 2017; pp. 1–5. [Google Scholar]
- Wang, Y.; Xu, W.; Zhang, H.; You, X. Wideband mmWave Channel Estimation for Hybrid Massive MIMO With Low-Precision ADCs. IEEE Wirel. Commun. Lett. 2019, 8, 285–288. [Google Scholar] [CrossRef] [Green Version]
- Brady, J.H.; Sayeed, A.M. Wideband communication with high-dimensional arrays: New results and transceiver architectures. In Proceedings of the 2015 IEEE International Conference on Communication Workshop (ICCW), London, UK, 8–12 June 2015; pp. 1042–1047. [Google Scholar]
- Gao, X.; Dai, L.; Zhou, S.; Sayeed, A.M.; Hanzo, L. Wideband Beamspace Channel Estimation for Millimeter-Wave MIMO Systems Relying on Lens Antenna Arrays. IEEE Trans. Signal Process. 2019, 67, 4809–4824. [Google Scholar] [CrossRef] [Green Version]
- Heath, R.W.; González-Prelcic, N.; Rangan, S.; Roh, W.; Sayeed, A.M. An Overview of Signal Processing Techniques for Millimeter Wave MIMO Systems. IEEE J. Sel. Top. Signal Process. 2016, 10, 436–453. [Google Scholar] [CrossRef]
- He, H.; Wang, R.; Jin, S.; Wen, C.-K.; Li, G.Y. Beamspace channel estimation in terahertz communications: A mod-el-driven unsupervised learning approach. arXiv 2020, arXiv:2006.16628. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Society. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep Residual Shrinkage Networks for Fault Diagnosis. IEEE Trans. Ind. Inform. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable Optimization-Inspired Deep Network for Image Compressive Sensing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 1828–1837. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of lens elements | 32 |
| Number of RF chains | 8 |
| Carrier frequency | 28 GHz |
| Bandwidth | 4 GHz |
| Number of subcarriers | 32 |
| Maximum delay | |
| Physical direction of the path | |
| Delay of the path | |
| Number of resolvable paths |
| Parameter | Value |
|---|---|
| Training set | 10,000 |
| Validation set | 1280 |
| Testing set | 2560 |
| Batch Size | 64 |
| Optimizer | Adam |
| Learning rate | 0.0001 |
| SNR | [−10,20] |
| Maximum training iterations | 5000 |
| Algorithm | Time/s |
|---|---|
| LISTA-Net | 9.17 |
| ALISTA-Net | 9.25 |
| Method | Parameters | Computational Complexity |
|---|---|---|
| LISTA-Net | ||
| SSD | ||
| OMP | ||
| LDGEC | ||
| ISTA | ||
| ISTA-Net+ | ||
| ALISTA-Net |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Li, Y.; Sun, J. A Model-Driven Channel Estimation Method for Millimeter-Wave Massive MIMO Systems. Sensors 2023, 23, 2638. https://doi.org/10.3390/s23052638
Liu Q, Li Y, Sun J. A Model-Driven Channel Estimation Method for Millimeter-Wave Massive MIMO Systems. Sensors. 2023; 23(5):2638. https://doi.org/10.3390/s23052638
Chicago/Turabian StyleLiu, Qingli, Yangyang Li, and Jiaxu Sun. 2023. "A Model-Driven Channel Estimation Method for Millimeter-Wave Massive MIMO Systems" Sensors 23, no. 5: 2638. https://doi.org/10.3390/s23052638
APA StyleLiu, Q., Li, Y., & Sun, J. (2023). A Model-Driven Channel Estimation Method for Millimeter-Wave Massive MIMO Systems. Sensors, 23(5), 2638. https://doi.org/10.3390/s23052638