
MTGEA: A Multimodal Two-Stream GNN Framework for Efficient Point Cloud and Skeleton Data Alignment


Abstract
:1. Introduction
- We propose a novel MTGEA. Our major contribution is presenting a new approach for incorporating accurate Kinect skeletal features into the radar recognition model, enabling human activity recognition using sparse point clouds alone without having to use the Kinect stream during reasoning;
- We propose skeleton data with an attention mechanism as a tool for generating reliable features for the multimodal alignment of point clouds. We also utilize three upsampling techniques to address the sparsity of radar point clouds;
- We provide a new point cloud and skeleton dataset for human activity recognition. All data simultaneously collected by mmWave radar and Kinect v4 sensors are open source, along with the entire code and pre-trained classifiers.
2. Related Works
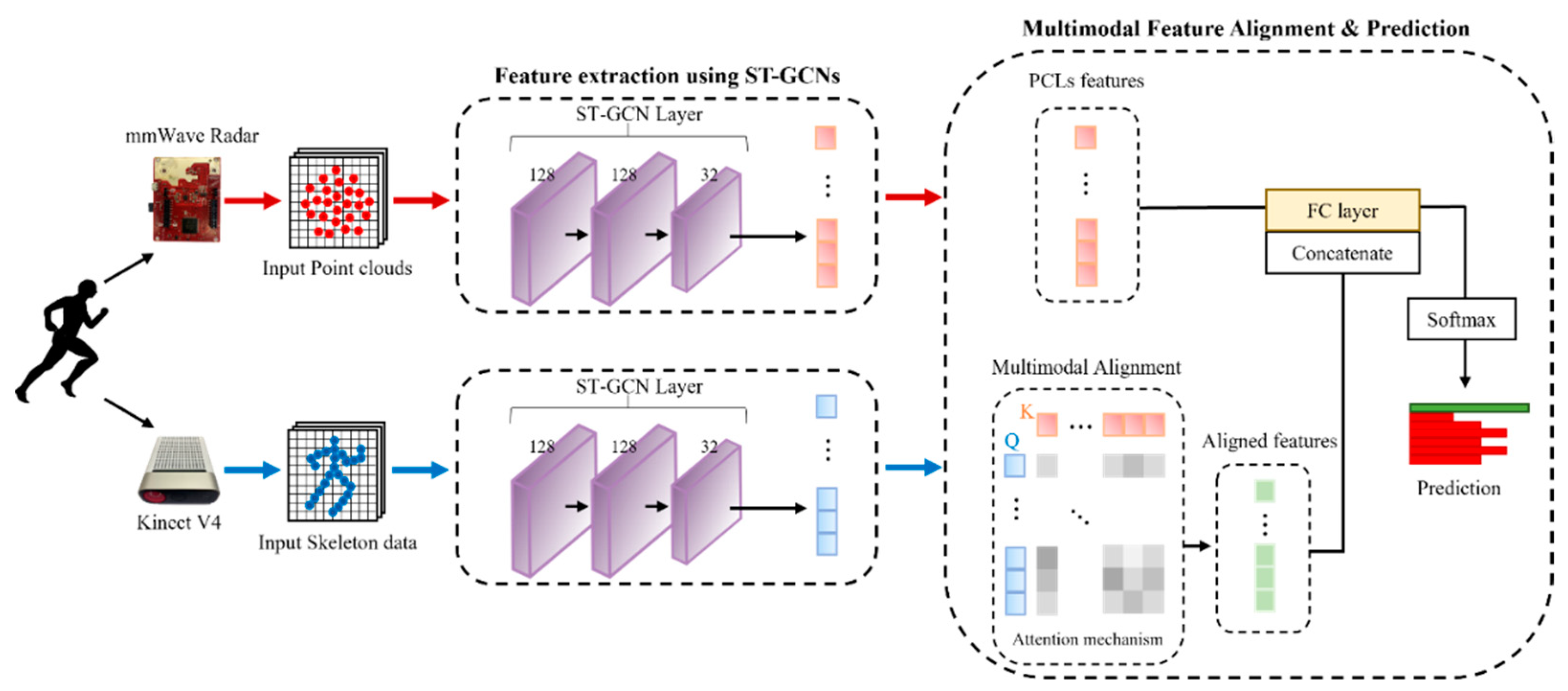
3. Methodology
3.1. Subsection Experimental Environments and Dataset
3.2. Data Augmentation
3.3. Feature Extraction Using ST-GCNs
3.4. Multimodal Feature Alignment by Attention
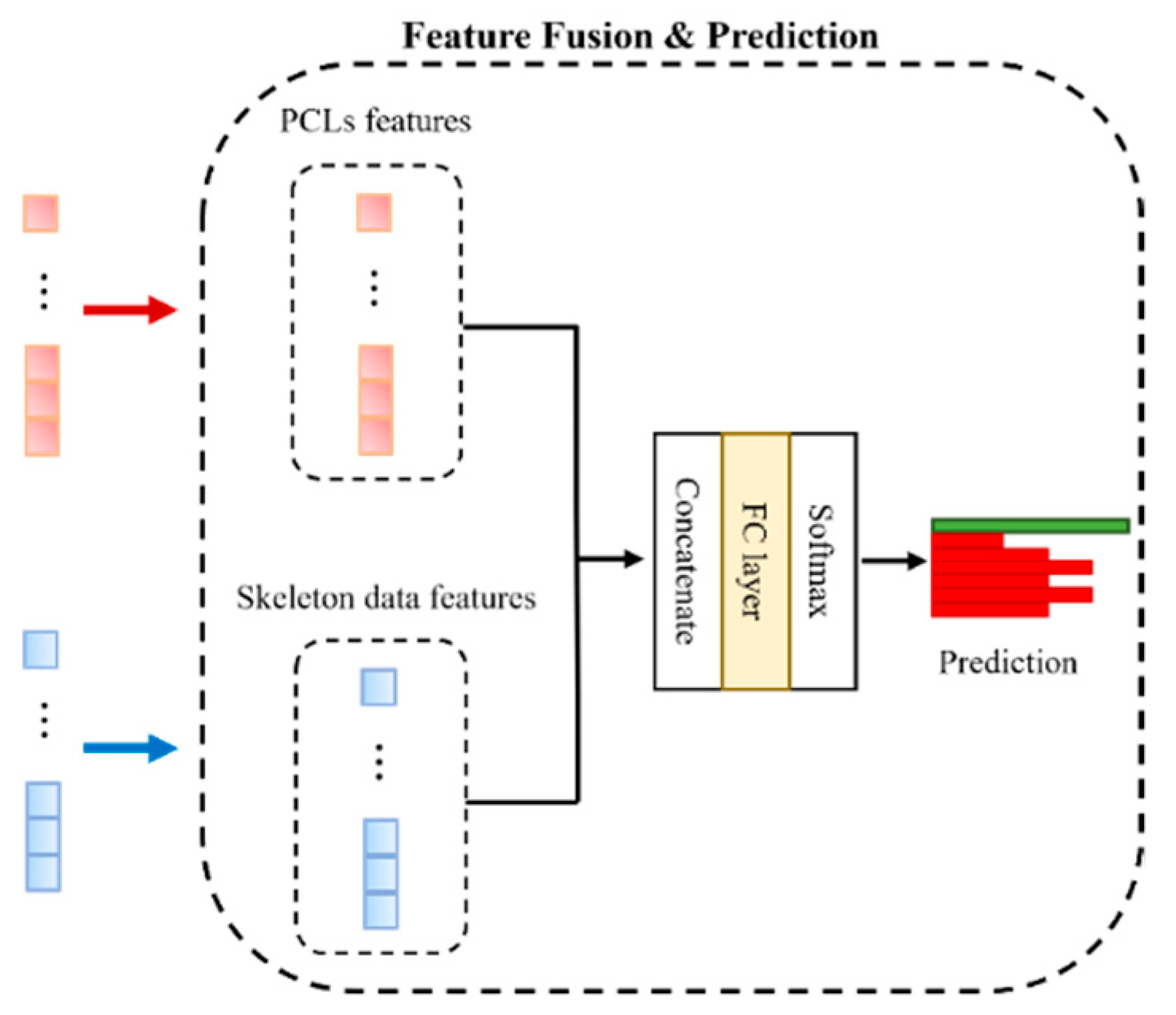
3.5. Feature Concatenation & Prediction
4. Results
5. Ablation Studies
5.1. Ablation Study for the Multimodal Framework
5.2. Ablation Study for the Attention Mechanism
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vaiyapuri, T.; Lydia, E.L.; Sikkandar, M.Y.; Diaz, V.G.; Pustokhina, I.V.; Pustokhin, D.A. Internet of Things and Deep Learning Enabled Elderly Fall Detection Model for Smart Homecare. IEEE Access 2021, 9, 113879–113888. [Google Scholar] [CrossRef]
- Ma, W.; Chen, J.; Du, Q.; Jia, W. PointDrop: Improving object detection from sparse point clouds via adversarial data augmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10004–10009. [Google Scholar]
- Xu, S.; Zhou, X.; Ye, W.; Ye, Q. Classification of 3D Point Clouds by a New Augmentation Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7003405. [Google Scholar]
- Kim, K.; Kim, C.; Jang, C.; Sunwoo, M.; Jo, K. Deep learning-based dynamic object classification using LiDAR point cloud augmented by layer-based accumulation for intelligent vehicles. Expert Syst. Appl. 2021, 167, 113861. [Google Scholar] [CrossRef]
- Kulawiak, M. A Cost-Effective Method for Reconstructing City-Building 3D Models from Sparse Lidar Point Clouds. Remote Sens. 2022, 14, 1278. [Google Scholar] [CrossRef]
- Singh, A.D.; Sandha, S.S.; Garcia, L.; Srivastava, M. Radhar: Human activity recognition from point clouds generated through a millimeter-wave radar. In Proceedings of the 3rd ACM Workshop on Millimeter-Wave Networks and Sensing Systems, Los Cabos, Mexico, 25 October 2019; pp. 51–56. [Google Scholar]
- Palipana, S.; Salami, D.; Leiva, L.A.; Sigg, S. Pantomime: Mid-air gesture recognition with sparse millimeter-wave radar point clouds. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–27. [Google Scholar] [CrossRef]
- Vonstad, E.K.; Su, X.; Vereijken, B.; Bach, K.; Nilsen, J.H. Comparison of a deep learning−based pose estimation system to marker−based and kinect systems in exergaming for balance training. Sensors 2020, 20, 6940. [Google Scholar] [CrossRef] [PubMed]
- Radu, I.; Tu, E.; Schneider, B. Relationships between body postures and collaborative learning states in an Augmented Reality Study. In International Conference on Artificial Intelligence in Education, Ifrane, Morocco, 6–10 July 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 257–262. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas Valley, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 24, 2684–2701. [Google Scholar] [CrossRef] [Green Version]
- Haocong, R.; Shihao, X.; Xiping, H.; Jun, C.; Bin, H. Augmented skeleton based contrastive action learning with momentum LSTM for unsupervised action recognition. Inf. Sci. 2021, 569, 90–109. [Google Scholar]
- Ryselis, K.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R. Computer-aided depth video stream masking framework for human body segmentation in depth sensor images. Sensors 2022, 22, 3531. [Google Scholar] [CrossRef]
- Wozniak, M.; Wieczorek, M.; Silka, J.; Polap, D. Body pose prediction based on motion sensor data and recurrent neural network. IEEE Trans. Ind. Inform. 2021, 17, 2101–2111. [Google Scholar] [CrossRef]
- Weiyao, X.; Muqing, W.; Min, Z.; Ting, X. Fusion of skeleton and RGB features for RGB-D human action recognition. IEEE Sens. J. 2021, 21, 19157–19164. [Google Scholar] [CrossRef]
- Zheng, C.; Feng, J.; Fu, Z.; Cai, Y.; Li, Q.; Wang, T. Multimodal relation extraction with efficient graph alignment. In Proceedings of the MM ’21: ACM Multimedia Conference, Virtual Event, 20–24 October 2021; pp. 5298–5306. [Google Scholar]
- Yang, W.; Zhang, J.; Cai, J.; Xu, Z. Shallow graph convolutional network for skeleton-based action recognition. Sensors 2021, 21, 452. [Google Scholar] [CrossRef] [PubMed]
- Ogundokun, R.O.; Maskeliūnas, R.; Misra, S.; Damasevicius, R. Hybrid inceptionv3-svm-based approach for human posture detection in health monitoring systems. Algorithms 2022, 15, 410. [Google Scholar] [CrossRef]
- Sengupta, A.; Cao, S. mmPose-NLP: A natural language processing approach to precise skeletal pose estimation using mmwave radars. arXiv 2021, arXiv:2107.10327. [Google Scholar] [CrossRef]
- Lee, G.; Kim, J. Improving human activity recognition for sparse radar point clouds: A graph neural network model with pre-trained 3D human-joint coordinates. Appl. Sci. 2022, 12, 2168. [Google Scholar] [CrossRef]
- Pan, L.; Chen, X.; Cai, Z.; Zhang, J.; Liu, Z. Variational Relational Point Completion Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 8520–8529. [Google Scholar]
- Zhang, R.; Cao, S. Real-time human motion behavior detection via CNN using mmWave radar. IEEE Sens. Lett. 2019, 3, 1–4. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7 May 2015. [Google Scholar]
- Rashid, M.; Khan, M.A.; Alhaisoni, M.; Wang, S.-H.; Naqvi, S.R.; Rehman, A.; Saba, T. A Sustainable Deep Learning Framework for Object Recognition Using Multi-Layers Deep Features Fusion and Selection. Sustainability 2020, 12, 5037. [Google Scholar] [CrossRef]
- Yen, C.-T.; Liao, J.-X.; Huang, Y.-K. Feature Fusion of a Deep-Learning Algorithm into Wearable Sensor Devices for Human Activity Recognition. Sensors 2021, 21, 8294. [Google Scholar] [CrossRef]
- Wu, P.; Cui, Z.; Gan, Z.; Liu, F. Three-Dimensional ResNeXt Network Using Feature Fusion and Label Smoothing for Hyperspectral Image Classification. Sensors 2020, 20, 1652. [Google Scholar] [CrossRef] [Green Version]
- Petrovska, B.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Štajduhar, I.; Lerga, J. Deep learning for feature extraction in remote sensing: A case-study of aerial scene classification. Sensors 2020, 20, 3906. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity | Mean | Median | Mode | Min | Max |
|---|---|---|---|---|---|
| Running | 12.79 | 13.0 | 13 | 3 | 24 |
| Jumping | 9.65 | 10.0 | 10 | 3 | 3 |
| Sitting down and standing up | 5.86 | 6.0 | 5 | 2 | 13 |
| Both upper limb extension | 6.18 | 5.0 | 3 | 2 | 17 |
| Falling forward | 3.78 | 4.0 | 3 | 2 | 8 |
| Right limb extension | 6.11 | 6.0 | 5 | 2 | 13 |
| Left limb extension | 5.22 | 5.0 | 5 | 2 | 13 |
| Model | Accuracy (%) | Weighted F1 Score (%) |
|---|---|---|
| MTGEA (ZP + Skeleton) | 85.09 | 79.35 |
| MTGEA (GN + Skeleton) | 95.03 | 95.13 |
| MTGEA (AHC + Skeleton) | 98.14 | 98.14 |
| Model | Accuracy (%) | Weighted F1 Score (%) |
|---|---|---|
| Augmented point clouds using ZP | 81.99 | 81.51 |
| Augmented point clouds using GN | 92.55 | 92.45 |
| Augmented point clouds using AHC | 93.79 | 93.80 |
| Skeleton data | 97.52 | 97.51 |
| Model | Accuracy (%) | Weighted F1 Score (%) |
|---|---|---|
| MTGEA (ZP + Skeleton) without attention | 83.85 | 77.77 |
| MTGEA (GN + Skeleton) without attention | 94.41 | 94.40 |
| MTGEA (AHC + Skeleton) without attention | 96.27 | 96.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.; Kim, J. MTGEA: A Multimodal Two-Stream GNN Framework for Efficient Point Cloud and Skeleton Data Alignment. Sensors 2023, 23, 2787. https://doi.org/10.3390/s23052787
Lee G, Kim J. MTGEA: A Multimodal Two-Stream GNN Framework for Efficient Point Cloud and Skeleton Data Alignment. Sensors. 2023; 23(5):2787. https://doi.org/10.3390/s23052787
Chicago/Turabian StyleLee, Gawon, and Jihie Kim. 2023. "MTGEA: A Multimodal Two-Stream GNN Framework for Efficient Point Cloud and Skeleton Data Alignment" Sensors 23, no. 5: 2787. https://doi.org/10.3390/s23052787
APA StyleLee, G., & Kim, J. (2023). MTGEA: A Multimodal Two-Stream GNN Framework for Efficient Point Cloud and Skeleton Data Alignment. Sensors, 23(5), 2787. https://doi.org/10.3390/s23052787