



Pixel Intensity Resemblance Measurement and Deep Learning Based Computer Vision Model for Crack Detection and Analysis

 and
and
Abstract
:1. Introduction
- A deep learning model for crack detection using image processing for computer vision is proposed;
- In order to detect whether the image has been affected by noise, a unique technique which uses pixel-intensity resemblance is implemented;
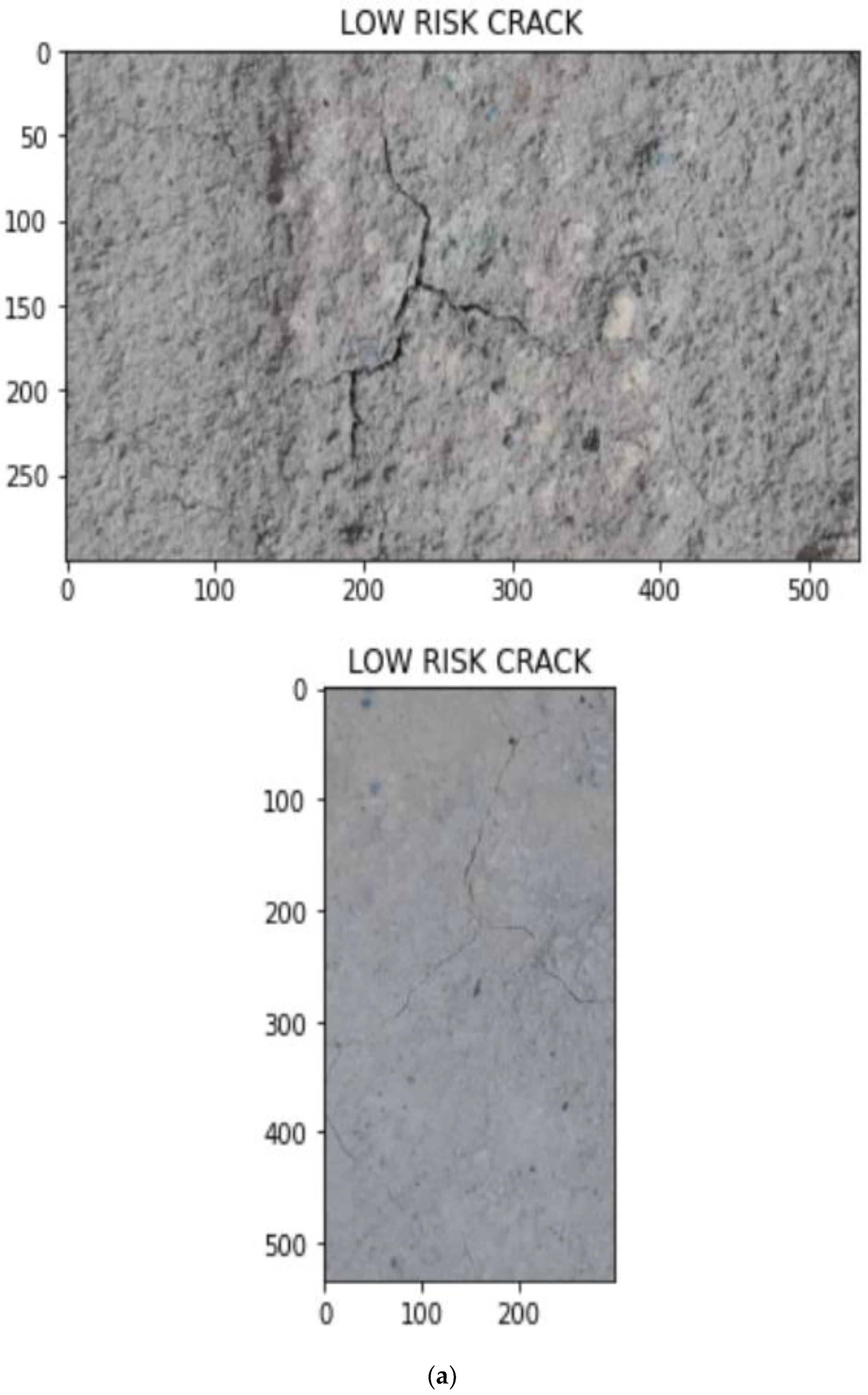
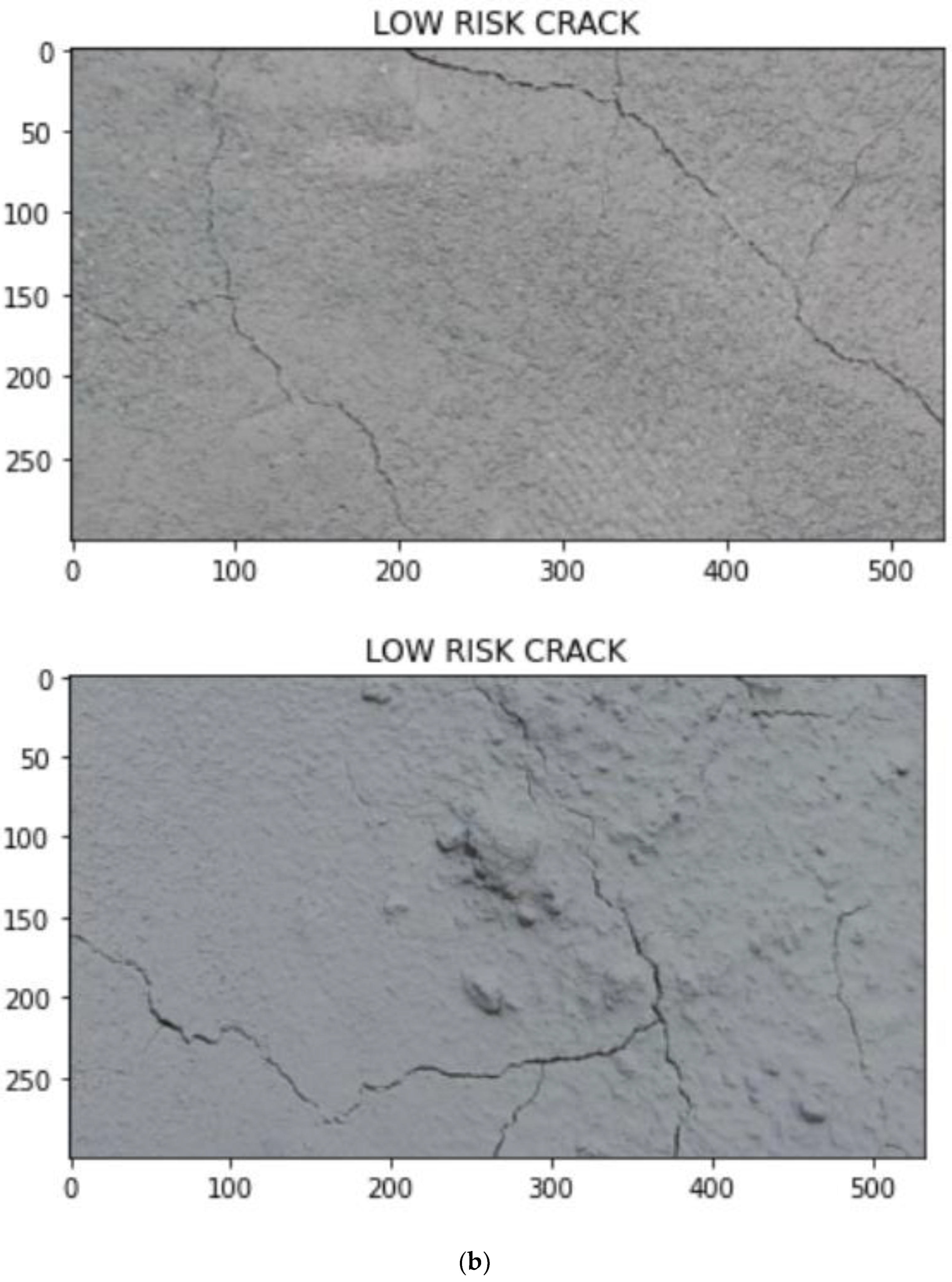
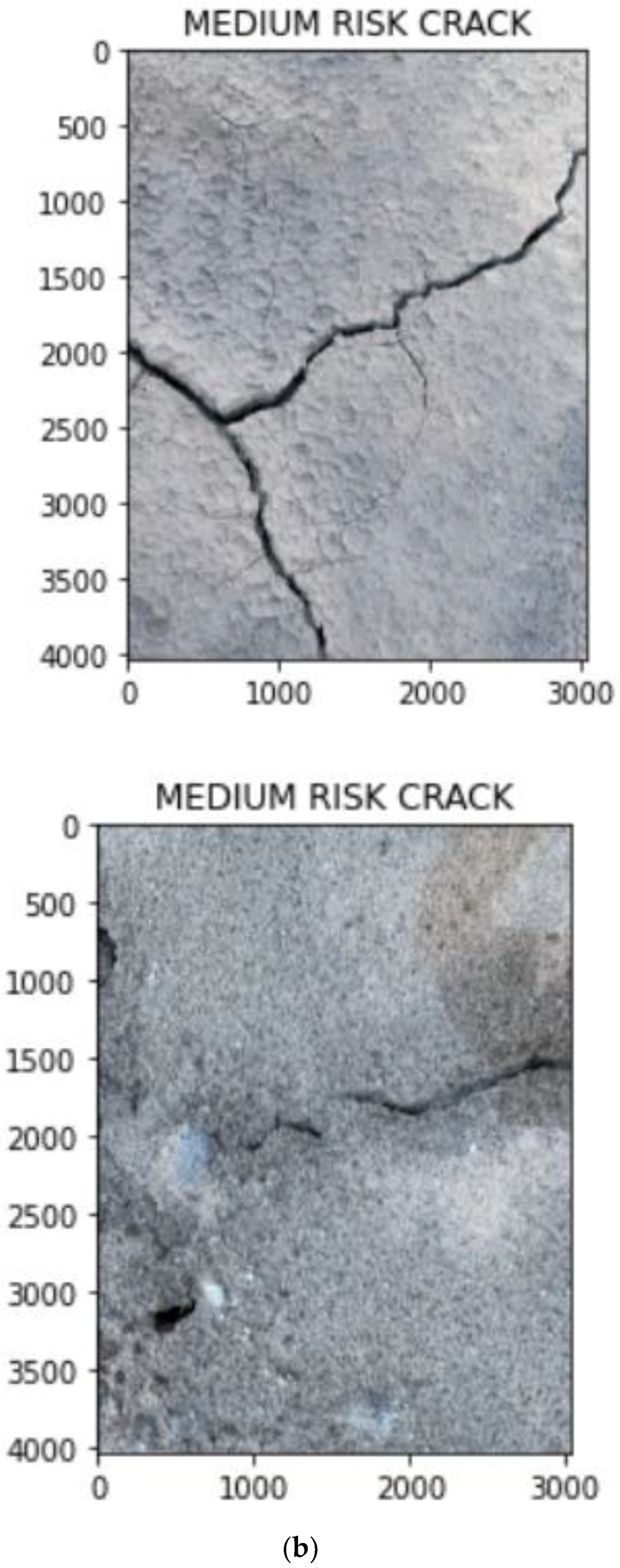
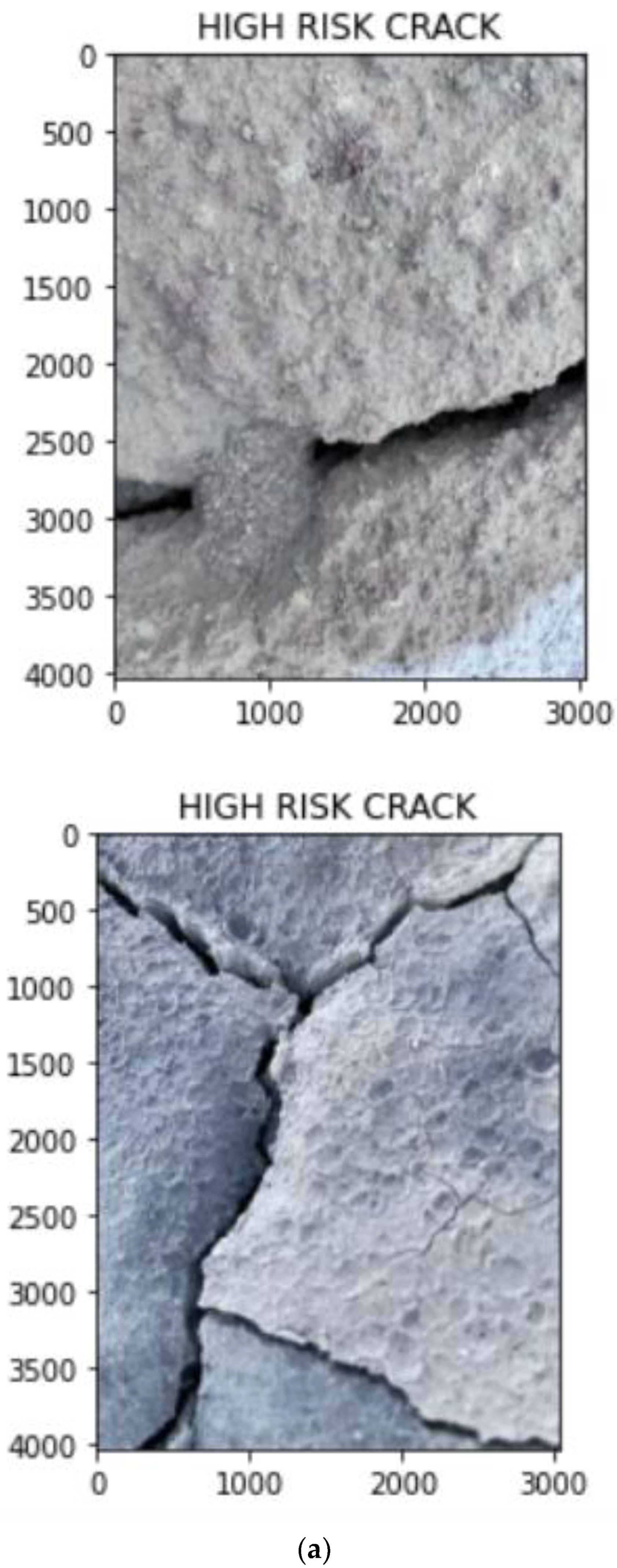
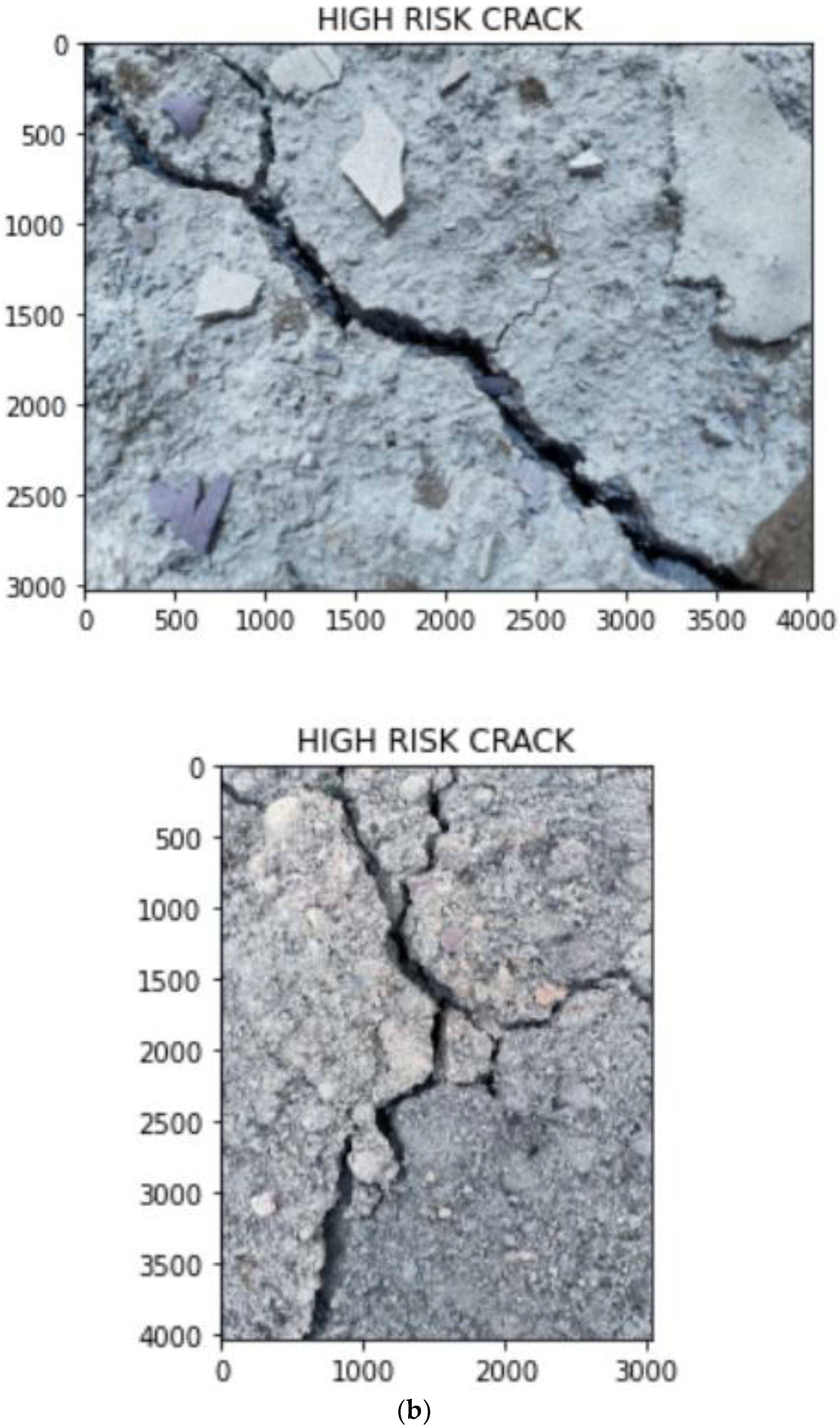
- A binarization-skeletonization-edge detection (BSE) algorithm is proposed for estimating the width of cracks. Based on the width, the images are segregated into high-risk, medium-risk and low-risk cracks using preset thresholds.
2. Background
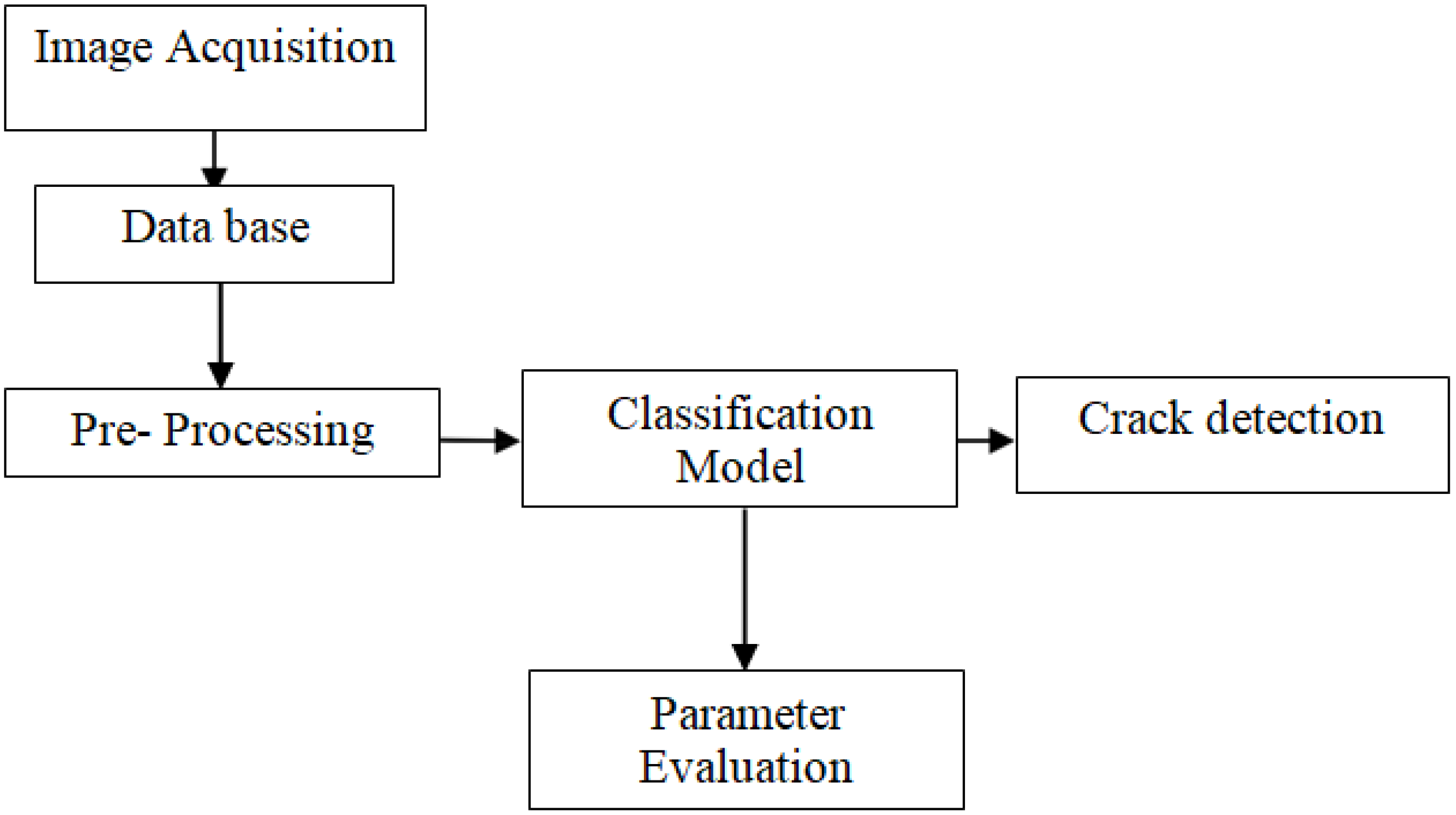
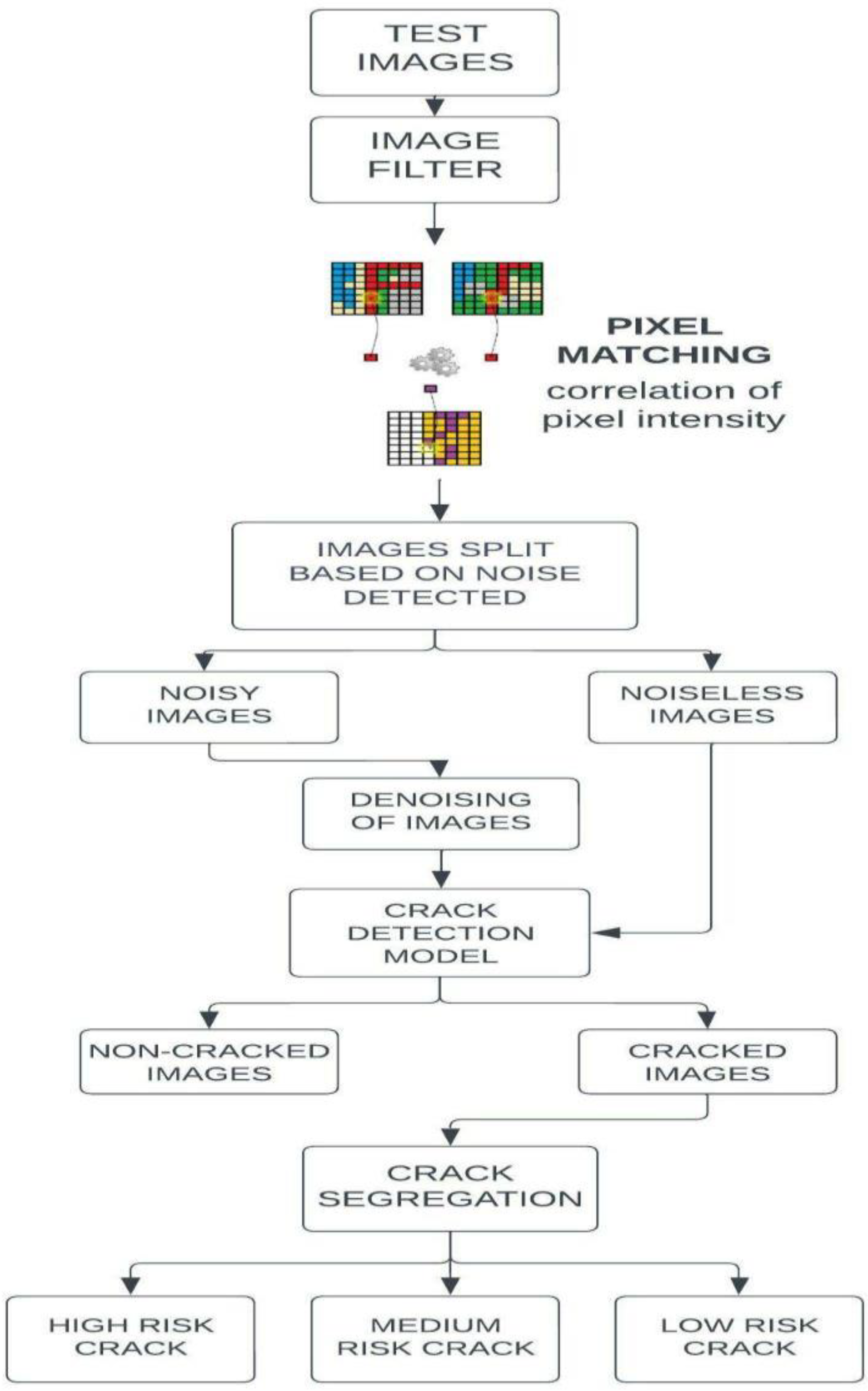
3. Proposed Method
- Cracks should be detected on any surfaces captured from any device under any environment;
- Time complexity is considered;
- Once a crack is identified, it should be categorized and an immediate alert will be given to the authority in order to avoid major accidents.
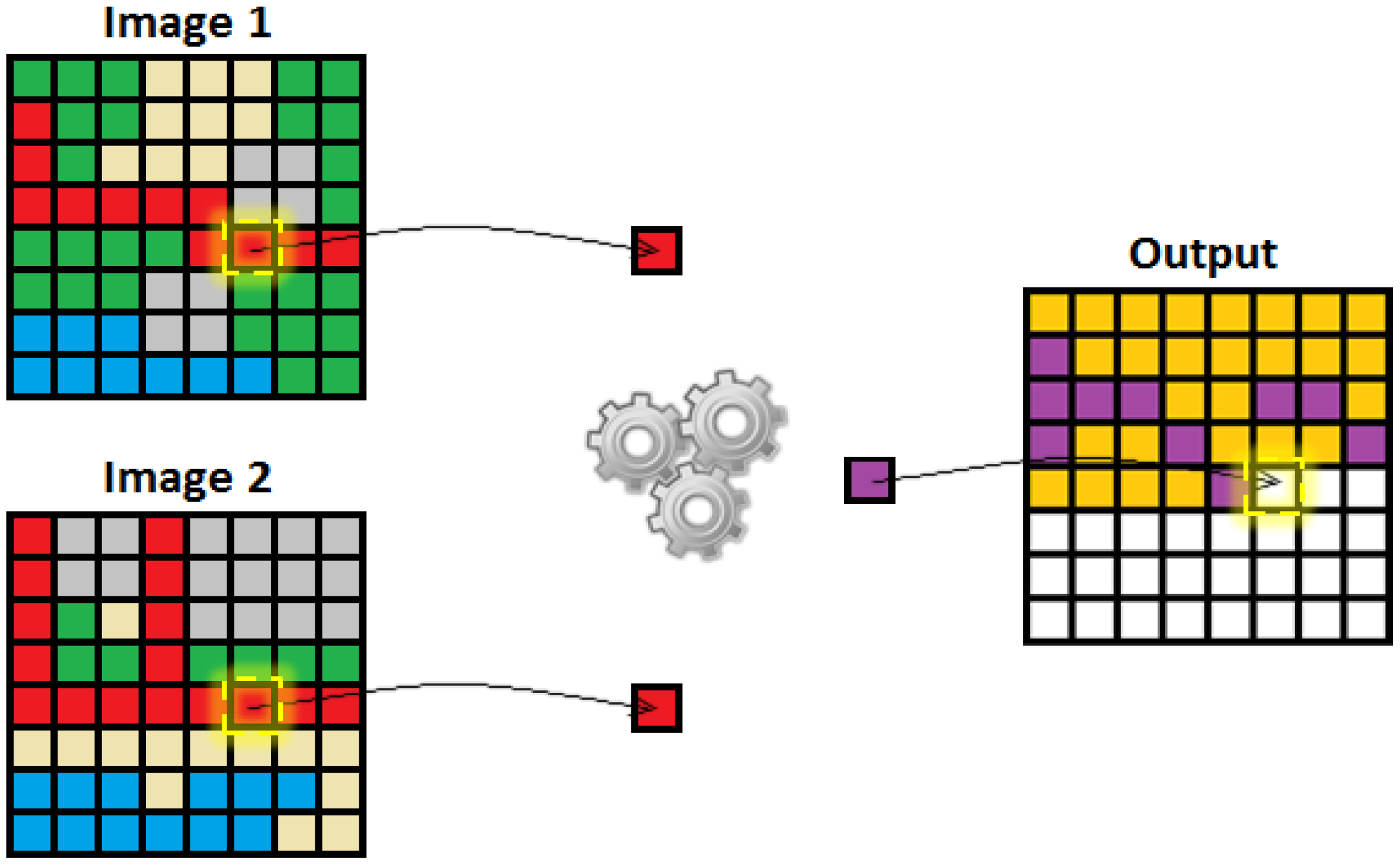
3.1. Filtering and Pixel-Intensity Resemblance Measurement for Noise Classification
3.2. Noise Estimation
3.3. Deep Learning Models Used for Crack Detection
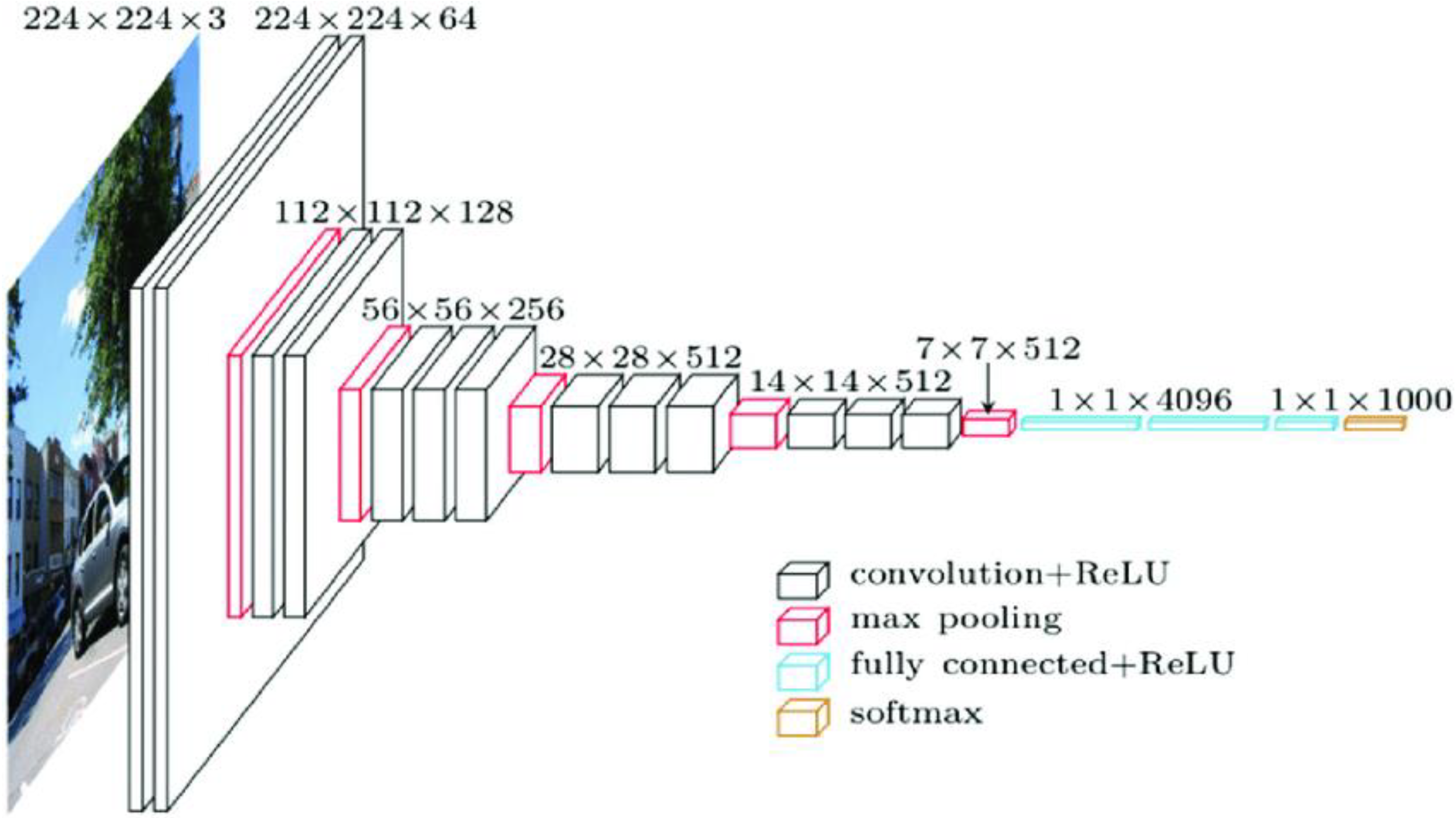
3.3.1. VGG-16 Architecture
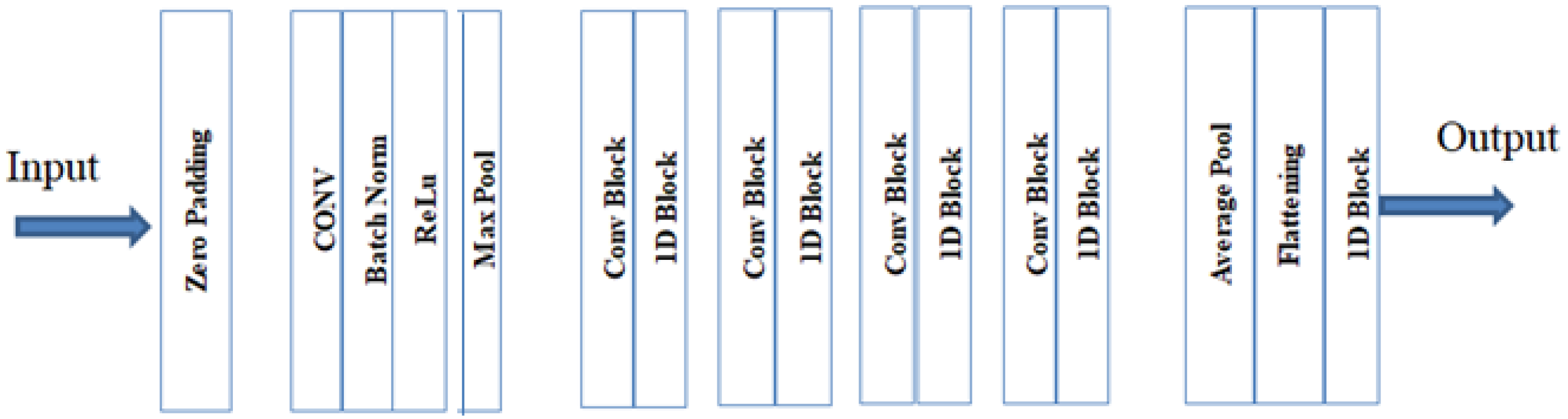
3.3.2. ResNet-50 Architecture
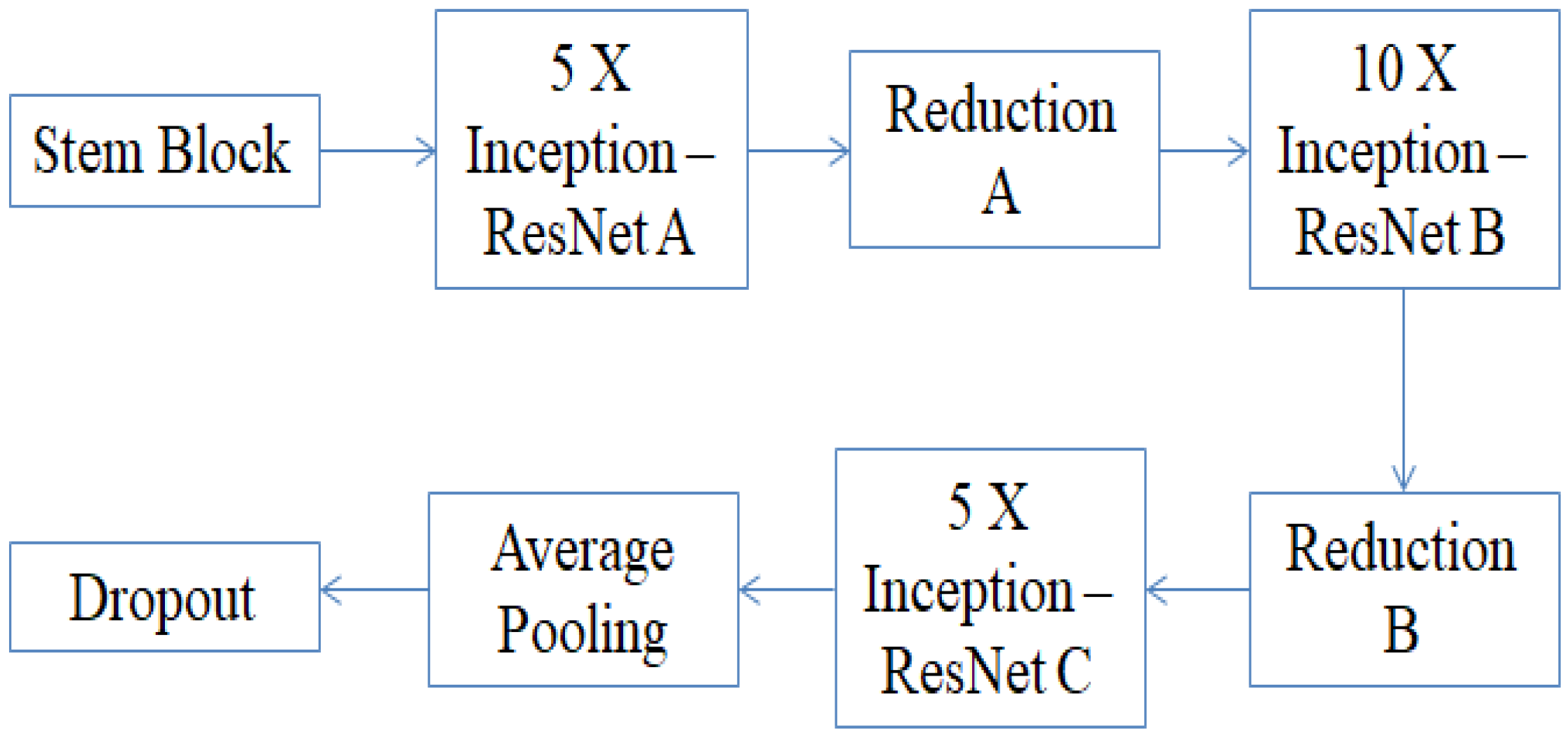
3.3.3. Inception ResNet-V2
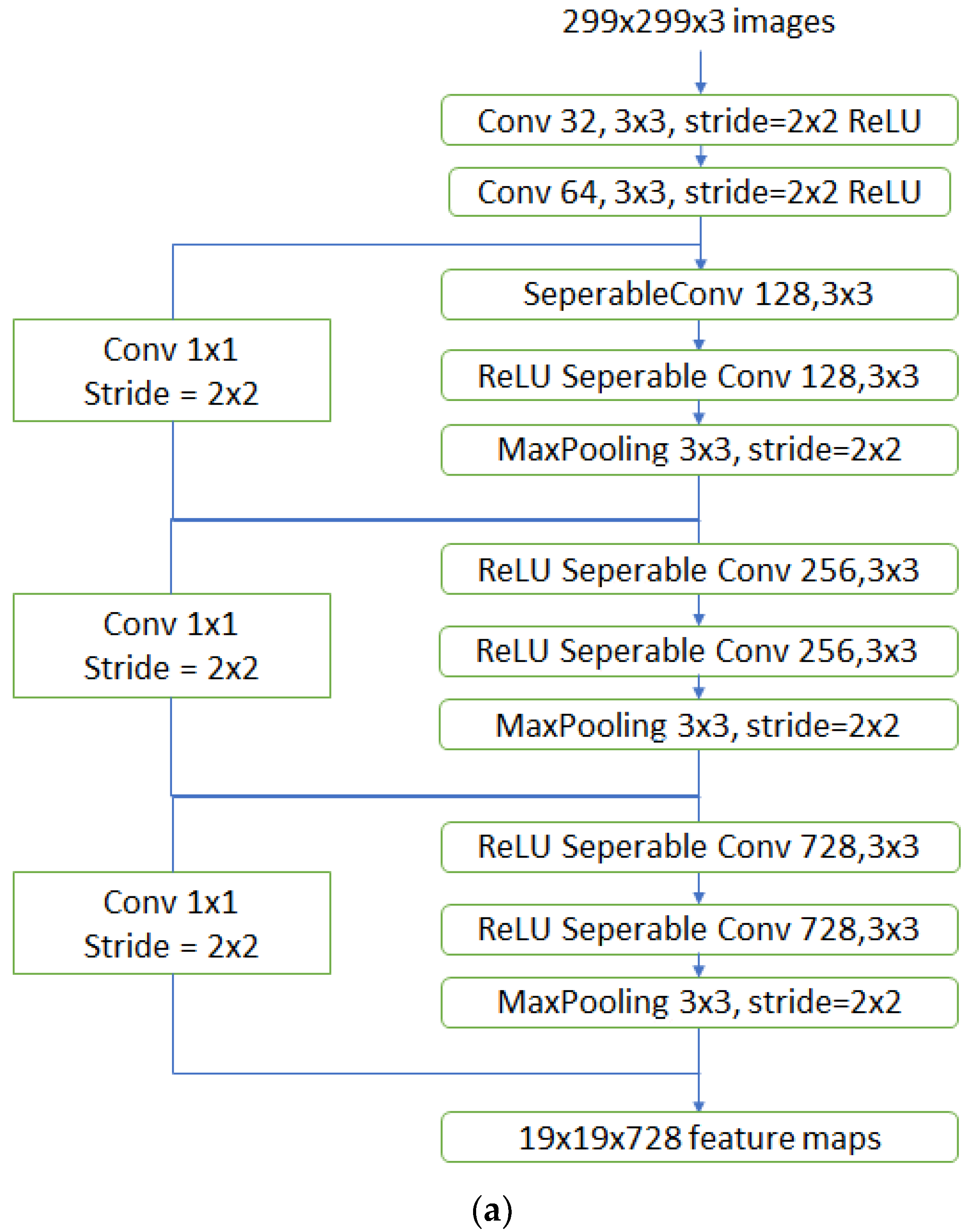
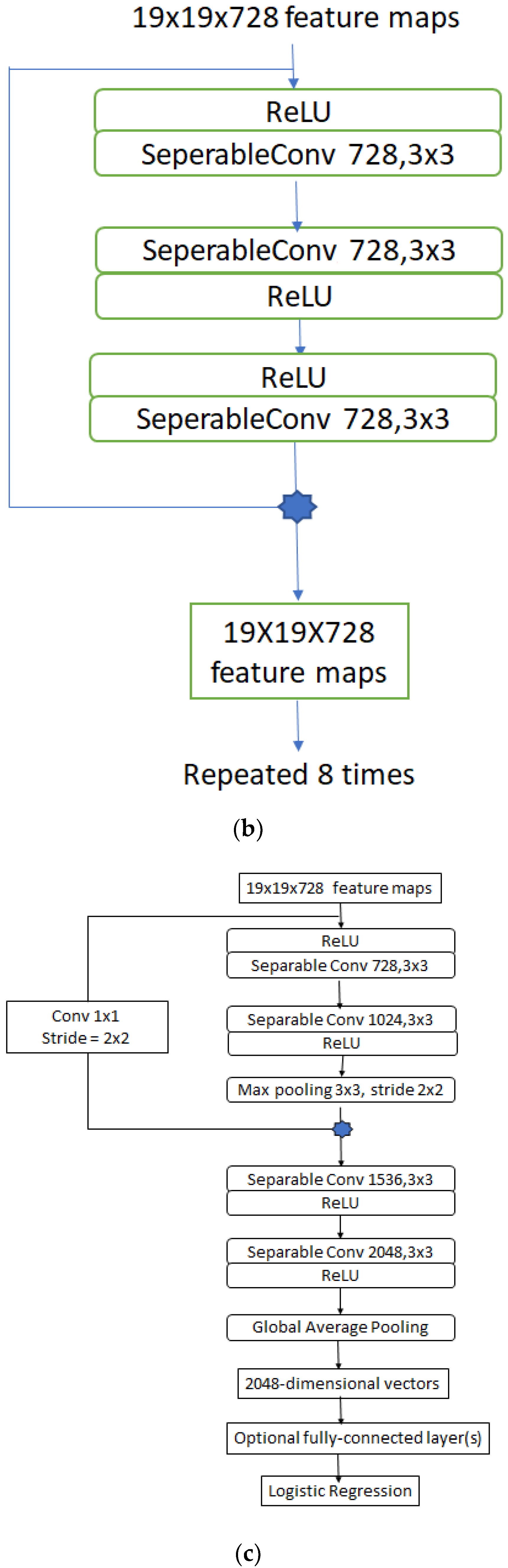
3.3.4. Xception Model
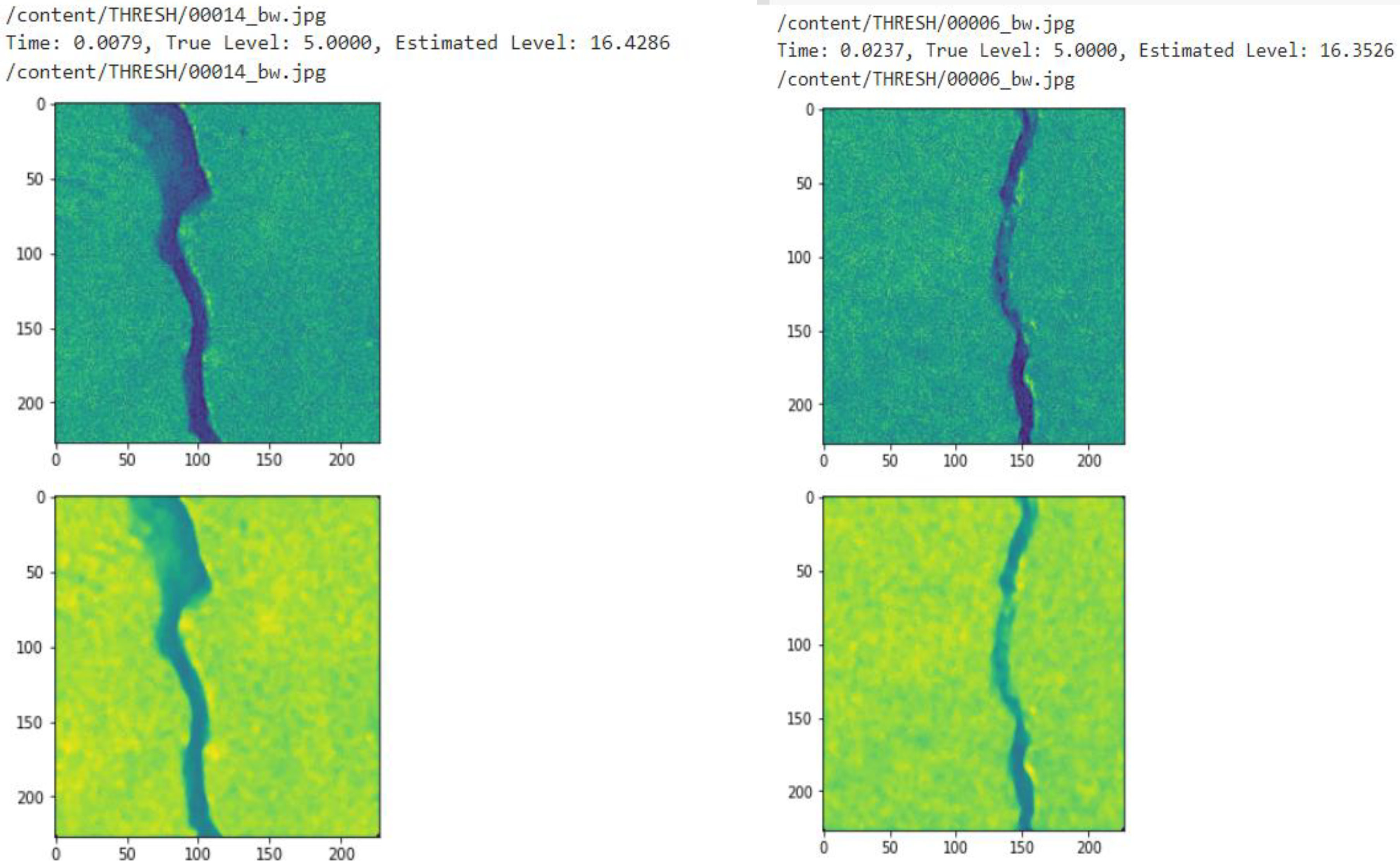
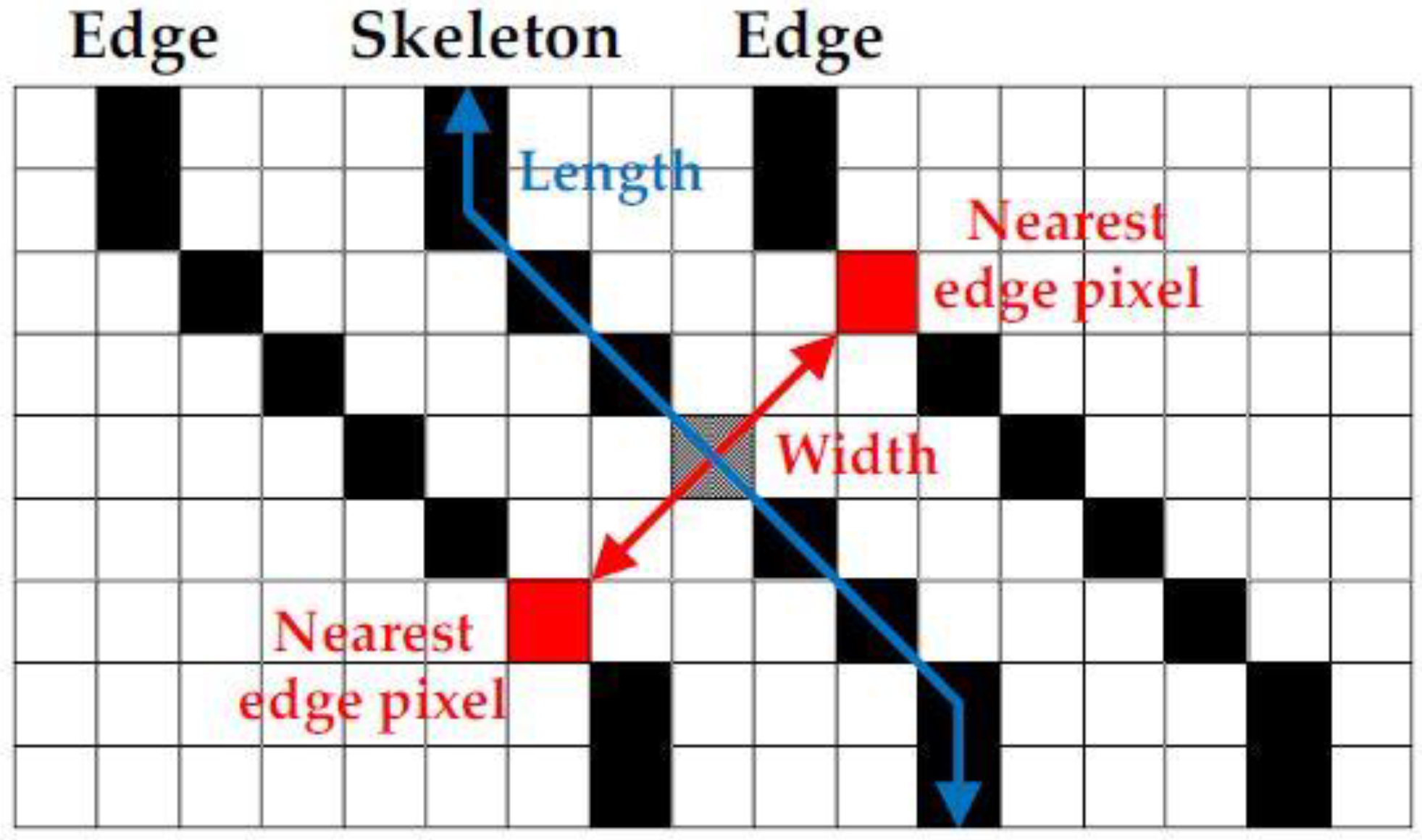
3.4. Crack Segregation Based on BSE Algorithm
- Image binarization: this is the operation of dividing the image into black/white pixels in order to separate the cracks and non-cracks within the image;
- Skeletonization: extracts the central skeleton of the crack which helps to identify the progression of the crack. Hence, it is possible to find the crack width by drawing a line perpendicular to the crack propagation direction at the pixel on the skeleton;
- Edge detection: extracts the outline of the crack. From the skeleton, the line perpendicular to the crack propagation direction and the crack outline are used together to find the crack width.
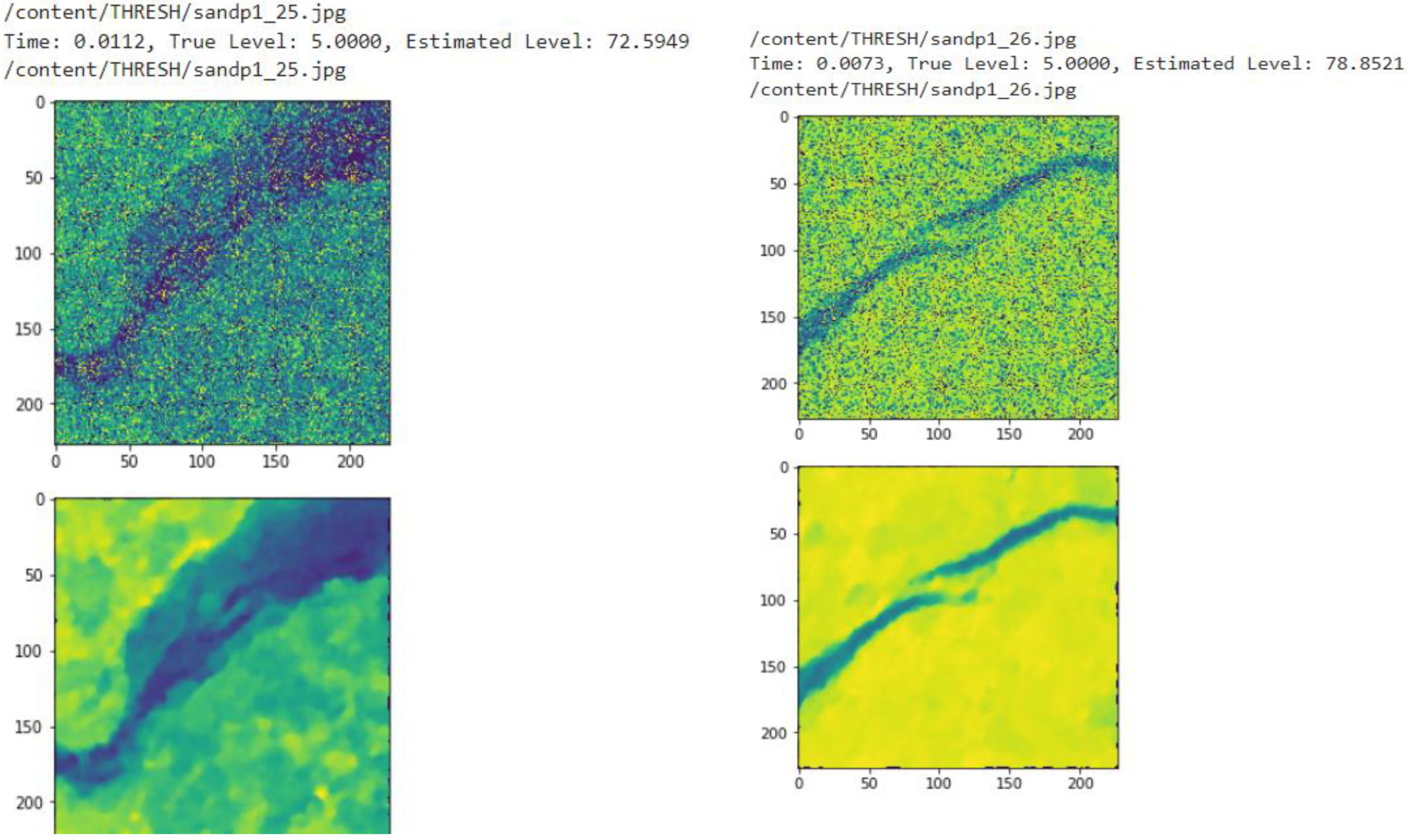
4. Results and Discussion
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, C.N.; Kawamura, K.; Nakamura, H.; Tarighat, A. Research on Automatic Crack Detection for Concrete Infrastructures Using Image Processing and Deep Learning. Curr. Approaches Sci. Technol. Res. 2021, 3, 46–55. [Google Scholar]
- Rao, A.S.; Nguyen, T.; Palaniswami, M.; Ngo, T. Vision-based automated crack detection using convolutional neural networks for condition assessment of infrastructure. Struct. Health Monit. 2020, 20, 2124–2142. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated road crack detection using deep convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5212–5215. [Google Scholar]
- Singh, R.P.; Varma, V.; Chaudhary, P. A Hybrid Technique for Medical Image Denoising using NN, Bilateral filter and LDA. IJFRS 2012, 1, 1–5. [Google Scholar]
- Naragund, M.N.; Jagadale, B.N.; Priya, B.S.; Panchaxri, V.H. An Efficient Image Denoising Method based on Bilateral filter Model and Neighshrink SURE. Int. J. Recent Technol. Eng. 2019, 8, 8470–8475. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Abu Talip, M.S.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2021, 133, 103989. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, J.; Cai, F. On Bridge Surface Crack Detection Based on an Improved YOLO v3 Algorithm. IFAC-PapersOnLine 2020, 53, 8205–8210. [Google Scholar] [CrossRef]
- Li, L.; Zheng, S.; Wang, C.; Zhao, S.; Chai, X.; Peng, L.; Tong, Q.; Wang, J. Crack Detection Method of Sleeper Based on Cascade Convolutional Neural Network. J. Adv. Transp. 2022, 2022, 1–14. [Google Scholar] [CrossRef]
- Chow, J.; Su, Z.; Wu, J.; Tan, P.; Mao, X.; Wang, Y. Anomaly detection of defects on concrete structures with the convolutional autoencoder. Adv. Eng. Inform. 2020, 45, 101105. [Google Scholar] [CrossRef]
- Qu, Z.; Mei, J.; Liu, L.; Zhou, D.-Y. Crack Detection of Concrete Pavement With Cross-Entropy Loss Function and Improved VGG16 Network Model. IEEE Access 2020, 8, 54564–54573. [Google Scholar] [CrossRef]
- Wang, C.; Chen, D.; Hao, L.; Liu, X.; Zeng, Y.; Chen, J.; Zhang, G. Pulmonary image classification based on inception-v3 transfer learning model. IEEE Access 2019, 7, 146533–146541. [Google Scholar] [CrossRef]
- Wang, S.; Guo, T. Transfer Learning-Based Algorithms for the Detection of Fatigue Crack Initiation Sites: A Comparative Study. Front. Mater. 2021, 8, 756798. [Google Scholar] [CrossRef]
- Thendral, R.; Ranjeeth, A. Computer Vision System for Railway Track Crack Detection using Deep Learning Neural Network. In Proceedings of the 2021 3rd International Conference on Signal Processing and Communication (ICPSC), Tamil Nadu, India, 13 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 193–196. [Google Scholar]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2018, 99, 52–58. [Google Scholar] [CrossRef]
- Billah, U.H. Automatic Concrete Defect Identification by Silencing Features of Deep Neural Network. Ph.D. Thesis, University of Nevada, Reno, Nevada, August 2020. [Google Scholar]
- Zhang, Q.; Barri, K.; Babanajad, S.K.; Alavi, A.H. Real-Time Detection of Cracks on Concrete Bridge Decks Using Deep Learning in the Frequency Domain. Engineering 2020, 7, 1786–1796. [Google Scholar] [CrossRef]
- Ahmadi, R.; Farahani, J.K.; Sotudeh, F.; Zhaleh, A.; Garshasbi, S. Survey of image denoising techniques. Life Sci. J. 2013, 10, 753–755. [Google Scholar]
- Li, S.; Qian, P.; Zhang, X.; Chen, A. Research on Image Denoising and Super-Resolution Reconstruction Technology of Multiscale-Fusion Images. Mob. Inf. Syst. 2021, 2021, 1–11. [Google Scholar] [CrossRef]
- Zhong, J.; Sun, H. Edge-Preserving Image Denoising Based on Orthogonal Wavelet Transform and Level Sets. J. Image Graph. 2018, 6, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Sekehravani, E.A.; Babulak, E. Implementing Canny Edge Detection Algorithm for Noisy Image. Bull. Electr. Eng. Inform. 2020, 9, 1404–1410. [Google Scholar] [CrossRef]
- Scholar, P.G. Review and analysis of crack detection and classification techniques based on crack types. Int. J. Appl. Eng. Res. 2018, 13, 6056–6062. [Google Scholar] [CrossRef]
- Sriwong, K.; Kerdprasop, K.; Kerdprasop, N. The Study of Noise Effect on CNN-Based Deep Learning from Medical Images. Int. J. Mach. Learn. Comput. 2021, 11, 202–207. [Google Scholar] [CrossRef]
- Wang, J.; He, X.; Faming, S.; Lu, G.; Cong, H.; Jiang, Q. A Real-Time Bridge Crack Detection Method Based on an Improved Inception-Resnet-v2 Structure. IEEE Access 2021, 9, 93209–93223. [Google Scholar] [CrossRef]
- Avendaño, J.C. Identification and Quantification of Concrete Cracks Using Image Analysis and Machine Learning. Master’s Thesis, KTH, School of Architecture and the Built Environment (ABE), Civil and Architectural Engineering, Structural Engineering and Bridges, June 2020. [Google Scholar]
- Nash, W.; Drummond, T.; Birbilis, N. A review of deep learning in the study of materials degradation. NPJ Mater. Degrad. 2018, 2, 1–2. [Google Scholar] [CrossRef]
- Tang, Z.; Li, M.; Wang, X. Mapping Tea Plantations from VHR Images Using OBIA and Convolutional Neural Networks. Remote Sens. 2020, 12, 2935. [Google Scholar] [CrossRef]
- Boer, M.J.; Vos, R.A. Taxonomic classification of ants (Formicidae) from images using deep learning. bioRxiv 2018, 1, 407452. [Google Scholar]
- Paramanandham, N.; Koppad, D.; Anbalagan, S. Vision Based Crack Detection in Concrete Structures Using Cutting-Edge Deep Learning Techniques. Trait. Signal 2022, 39, 485–492. [Google Scholar] [CrossRef]
- Chen, Q.; Huang, Y.; Sun, H.; Huang, W. Pavement crack detection using hessian structure propagation. Adv. Eng. Inform. 2021, 49, 101303. [Google Scholar] [CrossRef]
- Li, D.; Xie, Q.; Gong, X.; Yu, Z.; Xu, J.; Sun, Y.; Wang, J. Automatic defect detection of metro tunnel surfaces using a vision-based inspection system. Adv. Eng. Inform. 2020, 47, 101206. [Google Scholar] [CrossRef]
- Chen, J.; Liu, D. Bottom-up image detection of water channel slope damages based on superpixel segmentation and support vector machine. Adv. Eng. Inform. 2020, 47, 101205. [Google Scholar] [CrossRef]
- Carrasco, M.; Araya-Letelier, G.; Velázquez, R.; Visconti, P. Image-Based Automated Width Measurement of Surface Cracking. Sensors 2021, 21, 7534. [Google Scholar] [CrossRef]
- An, Q.; Chen, X.; Wang, H.; Yang, H.; Yang, Y.; Huang, W.; Wang, L. Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net. Fractal Fract. 2022, 6, 95. [Google Scholar] [CrossRef]
- Fan, Z.; Lin, H.; Li, C.; Su, J.; Bruno, S.; Loprencipe, G. Use of Parallel ResNet for High-Performance Pavement Crack Detection and Measurement. Sustainability 2022, 14, 1825. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack Detection and Comparison Study Based on Faster R-CNN and Mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- Hamishebahar, Y.; Guan, H.; So, S.; Jo, J. A Comprehensive Review of Deep Learning-Based Crack Detection Approaches. Appl. Sci. 2022, 12, 1374. [Google Scholar] [CrossRef]
- Paramanandham, N.; Rajendiran, K. Swarm intelligence based image fusion for noisy images using consecutive pixel intensity. Multimedia Tools Appl. 2018, 77, 32133–32151. [Google Scholar] [CrossRef]
- Nguyen, L.D.; Lin, D.; Lin, Z.; Cao, J. Deep CNNs for microscopic image classification by exploiting transfer learning and feature concatenation. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Mukherjee, S. The Annotated ResNet-50. Towards Data Science. 2022. Available online: https://towardsdatascience.com/the-annotated-resnet-50-a6c536034758 (accessed on 18 November 2022).
- Tang, Y.; Zhu, M.; Chen, Z.; Wu, C.; Chen, B.; Li, C.; Li, L. Seismic performance evaluation of recycled aggregate concrete-filled steel tubular columns with field strain detected via a novel mark-free vision method. Structures 2022, 37, 426–441. [Google Scholar] [CrossRef]
- Tan, H.; Dong, S. Pixel-Level Concrete Crack Segmentation Using Pyramidal Residual Network with Omni-Dimensional Dynamic Convolution. Processes 2023, 11, 546. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Filters | Classification Accuracy (%) |
|---|---|
| Mean Filter | 87.3 |
| Median Filter | 91.5 |
| Low Pass Filter | 83.3 |
| Gaussian Filter | 88.1 |
| Predicted No | Predicted Yes | |
|---|---|---|
| Actual No | TN | FP |
| Actual Yes | FN | TP |
| NOISE | VGG-16 | RESNET-50 | INCEPTION RESNET-V2 | XCEPTION |
|---|---|---|---|---|
| No noise | 99.9% | 98% | 99.98% | 99.95% |
| Salt and pepper | 50% | 50% | 56.05% | 50% |
| Gaussian | 50% | 89.05% | 56.15% | 50% |
| Poisson | 99.1% | 99.2% | 98.75% | 99.25% |
| Speckle | 96.05% | 91.9% | 99.55% | 99.7% |
| All noises | 73.79% | 82.54% | 85.47% | 74.74% |
| All noises + no noise | 79.41% | 85.63% | 88.36% | 79.79% |
| NOISE | VGG-16 | RESNET-50 | INCEPTION RESNET-V2 | XCEPTION |
|---|---|---|---|---|
| Salt and pepper | 81% | 88.7% | 96.3% | 99.65% |
| Gaussian | 50% | 95.6% | 90.95% | 50% |
| Poisson | 99.1% | 99.2% | 99.65% | 99.25% |
| Speckle | 99.2% | 98.2% | 99.85% | 99.95% |
| All noises | 82.25% | 86.25% | 87.89% | 87.23% |
| All noises + no noise | 85.79% | 88.32% | 90.3% | 88.74% |
| All noises + no noise (with PIRM) | 89.56% | 95.78% | 90.9% | 89.57% |
| Techniques | Accuracy | Specificity | Recall | Precision | F1 Score |
|---|---|---|---|---|---|
| ResNet-50 [26] | 88.36 | 89.06 | 87.16 | 89.46 | 88.11 |
| Auto-CAE [9] | 89.05 | 89.95 | 87.32 | 90.05 | 88.75 |
| Crack Hessian [29] | 91.2 | 91.9 | 90.03 | 91.72 | 90.9 |
| Seg+ SVM [31] | 91.7 | 91.05 | 90.27 | 91.35 | 91.23 |
| Proposed- (PIRM + BSE) | 95.78 | 96.48 | 94.38 | 96.18 | 95.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paramanandham, N.; Rajendiran, K.; Poovathy J, F.G.; Premanand, Y.S.; Mallichetty, S.R.; Kumar, P. Pixel Intensity Resemblance Measurement and Deep Learning Based Computer Vision Model for Crack Detection and Analysis. Sensors 2023, 23, 2954. https://doi.org/10.3390/s23062954
Paramanandham N, Rajendiran K, Poovathy J FG, Premanand YS, Mallichetty SR, Kumar P. Pixel Intensity Resemblance Measurement and Deep Learning Based Computer Vision Model for Crack Detection and Analysis. Sensors. 2023; 23(6):2954. https://doi.org/10.3390/s23062954
Chicago/Turabian StyleParamanandham, Nirmala, Kishore Rajendiran, Florence Gnana Poovathy J, Yeshwant Santhanakrishnan Premanand, Sanjeeve Raveenthiran Mallichetty, and Pramod Kumar. 2023. "Pixel Intensity Resemblance Measurement and Deep Learning Based Computer Vision Model for Crack Detection and Analysis" Sensors 23, no. 6: 2954. https://doi.org/10.3390/s23062954
APA StyleParamanandham, N., Rajendiran, K., Poovathy J, F. G., Premanand, Y. S., Mallichetty, S. R., & Kumar, P. (2023). Pixel Intensity Resemblance Measurement and Deep Learning Based Computer Vision Model for Crack Detection and Analysis. Sensors, 23(6), 2954. https://doi.org/10.3390/s23062954