
Transformer-Based Fire Detection in Videos



Abstract
:1. Introduction
2. Related Work
2.1. Handcraft Features
2.2. Deep Learning Approaches
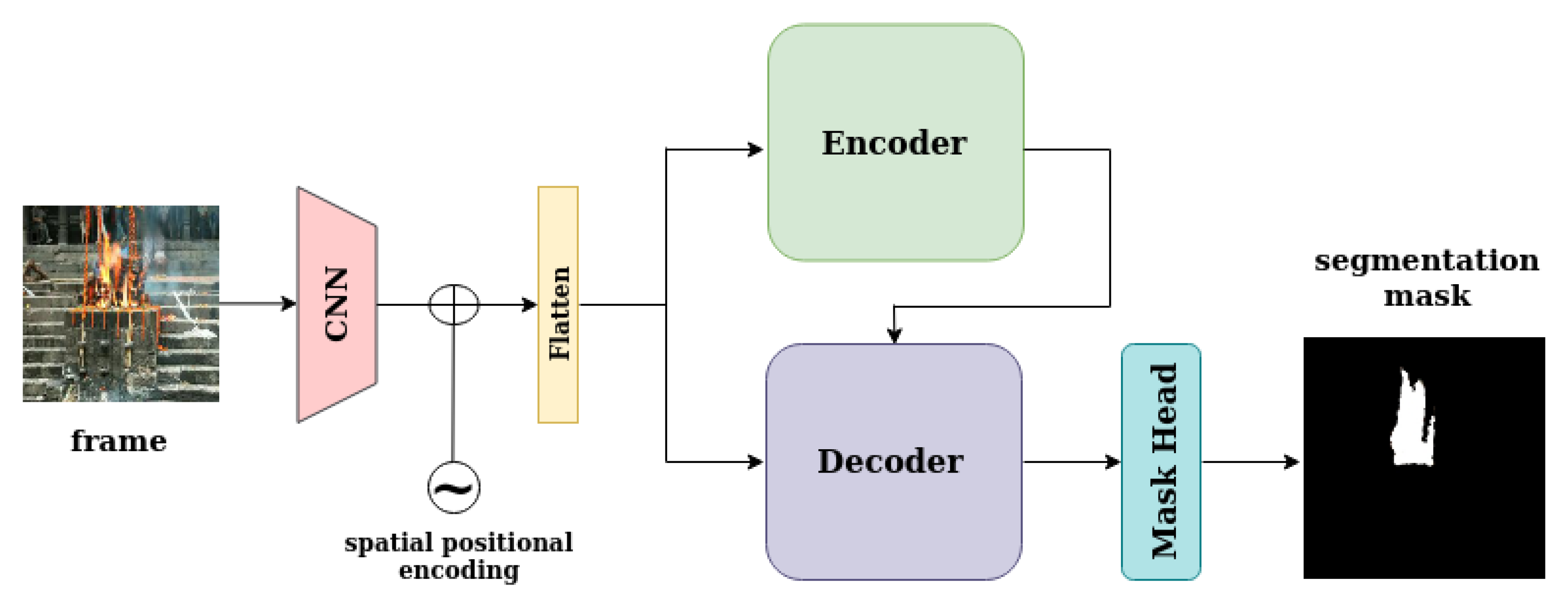
3. Materials and Methods
3.1. Encoder/Decoder Backbone
3.2. Transformer Encoder
3.3. Transformer Decoder
3.4. Fixed Positional Encodings
3.5. Mask Head
3.6. Class Head
3.7. Losses
3.7.1. Fire Localization
3.7.2. Full-Frame Classification
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.2.1. Full-Frame Classification
4.2.2. Fire Localization
4.3. Implementation Details
4.4. Evaluation Results and Discussions
4.4.1. Fire Localization Model
4.4.2. Full-Frame Classification Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Geetha, S.; Abhishek, C.; Akshayanat, C. Machine vision based fire detection techniques: A survey. Fire Technol. 2021, 57, 591–623. [Google Scholar]
- Yuan, F. An integrated fire detection and suppression system based on widely available video surveillance. Mach. Vis. Appl. 2010, 21, 941–948. [Google Scholar]
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video Flame and Smoke Based Fire Detection Algorithms: A Literature Review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient deep CNN-based fire detection and localization in video surveillance applications. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1419–1434. [Google Scholar]
- Aslan, S.; Güdükbay, U.; Töreyin, B.U.; Cetin, A.E. Deep convolutional generative adversarial networks based flame detection in video. arXiv 2019, arXiv:1902.01824. [Google Scholar]
- Yu, N.; Chen, Y. Video flame detection method based on TwoStream convolutional neural network. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 482–486. [Google Scholar]
- Kim, B.; Lee, J. A video-based fire detection using deep learning models. Appl. Sci. 2019, 9, 2862. [Google Scholar]
- Thomson, W.; Bhowmik, N.; Breckon, T.P. Efficient and Compact Convolutional Neural Network Architectures for Non-temporal Real-time Fire Detection. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 136–141. [Google Scholar]
- Samarth, G.; Bhowmik, N.; Breckon, T.P. Experimental exploration of compact convolutional neural network architectures for non-temporal real-time fire detection. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 653–658. [Google Scholar]
- Han, X.F.; Jin, J.S.; Wang, M.J.; Jiang, W.; Gao, L.; Xiao, L.P. Video fire detection based on Gaussian Mixture Model and multi-color features. Signal Image Video Process. 2017, 11, 1419–1425. [Google Scholar]
- Kong, S.G.; Jin, D.; Li, S.; Kim, H. Fast fire flame detection in surveillance video using logistic regression and temporal smoothing. Fire Saf. J. 2016, 79, 37–43. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. Acm Comput. Surv. 2022, 54, 1–41. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision, Proceedings of the European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; Volume 12346, pp. 213–229. [Google Scholar]
- Steffens, C.R.; Rodrigues, R.N.; Silva da Costa Botelho, S. An Unconstrained Dataset for Non-Stationary Video Based Fire Detection. In Proceedings of the 2015 12th Latin American Robotics Symposium and 2015 3rd Brazilian Symposium on Robotics (LARS-SBR), Uberlandia, Brazil, 29–31 October 2015; pp. 25–30. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Çelik, T.; Özkaramanlı, H.; Demirel, H. Fire and smoke detection without sensors: Image processing based approach. In Proceedings of the 2007 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 1794–1798. [Google Scholar]
- Celik, T. Fast and efficient method for fire detection using image processing. ETRI J. 2010, 32, 881–890. [Google Scholar]
- Zhou, X.L.; Yu, F.X.; Wen, Y.C.; Lu, Z.M.; Song, G.H. Early fire detection based on flame contours in video. Inf. Technol. J. 2010, 9, 899–908. [Google Scholar]
- Chenebert, A.; Breckon, T.P.; Gaszczak, A. A non-temporal texture driven approach to real-time fire detection. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1741–1744. [Google Scholar]
- Foggia, P.; Saggese, A.; Vento, M. Real-time fire detection for video-surveillance applications using a combination of experts based on color, shape, and motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar]
- Gong, F.; Li, C.; Gong, W.; Li, X.; Yuan, X.; Ma, Y.; Song, T. A real-time fire detection method from video with multifeature fusion. Comput. Intell. Neurosci. 2019, 2019, 1939171. [Google Scholar]
- Zhang, Q.; Xu, J.; Xu, L.; Guo, H. Deep convolutional neural networks for forest fire detection. In Proceedings of the 2016 International Forum on Management, Education and Information Technology Application, Guangzhou, China, 30–31 January 2016; Atlantis Press: Dordrecht, The Netherlands, 2016; pp. 568–575. [Google Scholar]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar]
- Dunnings, A.J.; Breckon, T.P. Experimentally Defined Convolutional Neural Network Architecture Variants for Non-Temporal Real-Time Fire Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1558–1562. [Google Scholar] [CrossRef] [Green Version]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention Augmented Convolutional Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 4055–4064. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice loss for data-imbalanced NLP tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 32 Advances in Neural Information Processing Systems, Vancouver, BC, USA, 8–14 December 2019; pp. 1–12. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | TPR | FPR | F | P | A | fps |
|---|---|---|---|---|---|---|
| Chenebert, A., et al. [20] | 0.99 | 0.28 | 0.92 | 0.86 | 0.89 | 0.16 |
| InceptionV1-OnFire | 0.92 | 0.17 | 0.90 | 0.88 | 0.89 | 8.4 |
| InceptionV3-OnFire | 0.94 | 0.07 | 0.94 | 0.93 | 0.94 | 13.8 |
| InceptionV4-OnFire | 0.94 | 0.06 | 0.94 | 0.94 | 0.94 | 12 |
| NasNet-A-OnFire | 0.98 | 0.15 | 0.98 | 0.99 | 0.97 | 5 |
| ShuffleNetV2-OnFire | 0.94 | 0.08 | 0.97 | 0.99 | 0.97 | 18 |
| Ours | 0.97 | 0.02 | 0.98 | 0.99 | 0.97 | 20.4 |
| Models | TPR | F | P | S |
|---|---|---|---|---|
| Chenebert, A., et al. [20] | 0.98 | 0.90 | 0.93 | 0.80 |
| InceptionV1-OnFire | 0.92 | 0.88 | 0.84 | 0.78 |
| Ours | 0.75 | 0.80 | 0.95 | 0.95 |
| Ours+dilation(3 × 3, 4iter) | 0.78 | 0.81 | 0.93 | 0.94 |
| Ours+dilation(3 × 3, 5iter) | 0.79 | 0.81 | 0.93 | 0.94 |
| Ours+dilation(3 × 3, 6iter) | 0.80 | 0.82 | 0.93 | 0.94 |
| Ours+dilation(3 × 3, 7iter) | 0.80 | 0.82 | 0.92 | 0.94 |
| Models | TPR | FPR | F | P | A |
|---|---|---|---|---|---|
| InceptionV1-OnFire | 0.96 | 0.10 | 0.94 | 0.93 | 0.93 |
| InceptionV3-OnFire | 0.95 | 0.07 | 0.95 | 0.95 | 0.94 |
| InceptionV4-OnFire | 0.95 | 0.04 | 0.96 | 0.97 | 0.96 |
| NasNet-A-OnFire | 0.92 | 0.03 | 0.94 | 0.96 | 0.95 |
| ShuffleNetV2-OnFire | 0.93 | 0.05 | 0.94 | 0.94 | 0.95 |
| Ours | 0.97 | 0.04 | 0.97 | 0.97 | 0.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mardani, K.; Vretos, N.; Daras, P. Transformer-Based Fire Detection in Videos. Sensors 2023, 23, 3035. https://doi.org/10.3390/s23063035
Mardani K, Vretos N, Daras P. Transformer-Based Fire Detection in Videos. Sensors. 2023; 23(6):3035. https://doi.org/10.3390/s23063035
Chicago/Turabian StyleMardani, Konstantina, Nicholas Vretos, and Petros Daras. 2023. "Transformer-Based Fire Detection in Videos" Sensors 23, no. 6: 3035. https://doi.org/10.3390/s23063035
APA StyleMardani, K., Vretos, N., & Daras, P. (2023). Transformer-Based Fire Detection in Videos. Sensors, 23(6), 3035. https://doi.org/10.3390/s23063035