1. Introduction
Plant factories are an innovative vertical agriculture solution, representing an advanced form of greenhouse agriculture capable of producing sustainable supplies of vegetables, herbs, flowers, and other crops throughout the year, based on relatively controlled environmental conditions [
1]. They also serve as an urban agriculture solution, providing fresh, nutritious, and high-quality plant products to urban areas, allowing city residents to consume freshly harvested vegetables [
2]. Tomatoes are highly valued and widely grown in greenhouses and plant factories. In 2020, the global tomato cultivation area was approximately 5.05 million hectares, with an annual output of 186 million tons [
3]. In tomato target detection, the dense foliage of tomato plants frequently obstructs small-target tomato varieties, resulting in a lower detection accuracy. Additionally, to enhance detection accuracy, detection models commonly depend on complex and large heavyweight models, which necessitate a high computing power and storage capacity and escalate the manufacturing costs of mobile and intelligent devices. These limitations hinder the use of robots for pruning, pollination, harvesting, and other operations in plant factories.
In the automated and intelligent production management process of tomato plant factories, in addition to inspection and picking robots, intelligent control platforms also require the monitoring of tomato growth and yield estimation. This requires the ability to recognize and detect tomatoes and accurately determine the position and quantity of tomato fruits. Traditional detection methods are mainly based on shape and color feature extraction, making logical judgments based on the extracted information. Traditional target detection methods include scale-invariant feature transform (SIFT) [
4], histogram of oriented gradient (HOG) [
5], support vector machine (SVM) [
6], and selective search for object recognition [
7]. Iwasaki et al. [
8] presented a detection approach for mini tomatoes that utilized hue information and candidate area curvature, achieving a detection rate of 78.8%. Linker et al. [
9] employed color and smoothness-based detection to estimate the number of green apples in an orchard environment, achieving a high level of correct detection accuracy, albeit at the cost of poor robustness. Wei et al. [
10] proposed a method that used an improved Otsu threshold algorithm to extract color features in the Ohta color space [
11], followed by segmentation using the Otsu threshold algorithm. The results obtained for detecting the four fruits tested in the experiment were favorable. However, it is worth noting that methods based solely on color features typically have less robustness. Li et al. [
12] proposed a detection method for tomato fruit using the fast normalization cross-correlation function (FNCC) and circular Hough transform (CHT) detection methods. They achieved favorable outcomes on the test dataset. However, the algorithm was susceptible to changes in the environment and was applicable in only limited scenarios. Fu et al. [
13] employed image processing techniques to recognize and detect ripe kiwifruit. The approach relied on performing numerous color-channel- and color-space-based operations, which made it computationally demanding and less robust. In summary, traditional detection methods are highly difficult to design and promote, especially in the case of an insufficient sample size or number of features, and it is difficult to achieve high precision. In addition, the robustness of detection is not high, so it is still challenging to apply these methods in practical situations.
In recent years, with the successful application of deep convolutional neural networks (DCNNs) in agriculture, computer-vision-based DCNN detection algorithms have provided a new research direction for tomato fruit detection and classification. The DCNN target detection methods can be divided into two categories according to the number of detection stages: (1) Two-stage detection methods first enumerate the candidate frames for the image and then classify and predict the candidate frames. Based on convolutional neural networks (CNNs), regional convolutional neural network (RCNN) [
14], Fast RCNN [
15], Faster RCNN [
16], and so on belong to this type of detection method. Two-stage detection models have a high precision and recall performance. However, their application in real-time detection scenarios is challenging due to their large network size and slow operation speed. (2) Single-stage detection methods directly extract features from the input image and then directly locate and classify the target on the extracted features. The single-shot MultiBox detector (SSD) [
17] and You Only Look Once (YOLO) series [
18,
19,
20,
21,
22,
23] belong to this type of detection method. Thanks to their network structure design, single-stage detection models have a fast operation speed that can meet real-time performance requirements, and the accuracy can reach the level of two-stage detection models.
With the further development of computer vision, it has been discovered that deeper networks perform better in machine vision. However, the problem of model degradation arises with the further deepening of the network. He et al. [
24] addressed this issue by using residual networks to further enhance the network to 152 layers and alleviate the problem of feature degradation. The MobileNetV3-Large backbone network used in this study also extensively employs residual structures to alleviate model degradation and further extract features. Mnih et al. [
25] used attention mechanisms in computer vision to reflect the focus of the human gaze in deep learning models. Based on this, spatial attention mechanisms and channel attention mechanisms have also been successful [
26,
27]. Howard et al. [
28] proposed MobileNetV3, a lightweight backbone network, by introducing an SE channel attention mechanism using depthwise separable convolutional and residual structures. Inspired by this, we propose the SM-YOLOv5 model, which replaces the CSPDarknet53 backbone network with MobileNetV3-Large to reduce the model size and maintain high accuracy in the detection of small tomato targets in plant factories.
Zhang et al. [
29] used the improved YOLOV4 model for apple fruit detection, implemented the GhostNet feature extraction network with the coordinate attention module in YOLOv4, and introduced depthwise convolution to reconstruct the neck and YOLO head structure, achieving an mAP of up to 95.72%; however, the network scale was large. Xu et al. [
30] used the improved YOLOv5s model for the real-time detection of Zanthoxylum and achieved good results in terms of both speed and precision. Tian et al. [
31] proposed an improved YOLOV3 model for detecting apples at different growth stages in orchards with light fluctuations, complex backgrounds, overlapping apples, and overlapping branches and leaves. After testing, the proposed YOLOV3-dense model was found to be more effective than the original YOLOV3 model. In summary, DCNNs achieve a higher accuracy and versatility than traditional methods. High-performance computers can support their computation but cannot achieve real-time performance on embedded devices. Su et al. [
32] employed a lightweight YOLOv3 model with a MobileNetV1 backbone network for tomato ripeness classification detection in a greenhouse, achieving an mAP of 97.5%. Despite its lightness, the size of the lightweight model was still 46.7 MB. Wang et al. [
33] utilized an improved YOLOv3 model for the online recognition and yield estimation of tomato fruits in a PF environment, achieving a high mAP of 99.3%. However, the YOLOv3 model they employed was large-scale, rendering it difficult to apply in lightweight scenarios. This study is based on YOLOv5, with the backbone network replaced by MobileNetV3 to further reduce the model’s weight and computational load. As a result, the model is better-suited for deployment in embedded devices and harvesting robots.
In response to the demand for lightweight and high-precision tomato detection in PF environments, this study proposes the SM-YOLOv5 lightweight model for small-target tomato detection. This model addresses the limitations of current research and aims to promote the development of harvesting robots. Our research makes innovative contributions to the study of lightweight target detection algorithms and their practical applications in this field. Our contributions can be summarized as follows:
The CSPDarknet53 backbone network was replaced by the MobileNetV3-Large lightweight network in this study. The lightweight network employed squeeze-and-excitation models and attention mechanisms to efficiently extract features in the channel-wise dimension. This replacement resulted in a reduction in the model size and a decrease in the computational demands.
To enhance the accuracy of the lightweight model in detecting small-sized tomato fruits in images, a small object detection layer was introduced into the network architecture. This additional layer was capable of extracting more features to improve the accuracy of the detection for overlapping or small objects and obscured tomato fruits.
These enhancements are of high importance in plant factories, where the accurate detection of small objects is crucial for effective and precise plant monitoring and management. The lightweight network can also support embedded picking robots when detecting tomato fruits, further highlighting its practical application potential.
The rest of this paper is organized as follows:
Section 2 outlines the experimental environment, dataset acquisition, and processing, as well as the evaluation metrics used in this study.
Section 3 describes the SM-YOLOv5 network model, the lightweight MobileNetV3-Large backbone network, and the added small-target detection layer.
Section 4 provides a thorough comparison and analysis of the experimental results. Additionally, a comparison with mainstream methods and an ablation experiment were conducted. Finally,
Section 5 and
Section 6 provide the discussion and conclusion, respectively, including future research directions and potential improvements.
3. Proposed SM-YOLOv5 Model
YOLOv5 is a state-of-the-art single-stage object detection algorithm that has achieved significant improvements in both accuracy and speed compared to its predecessors in the YOLO series [
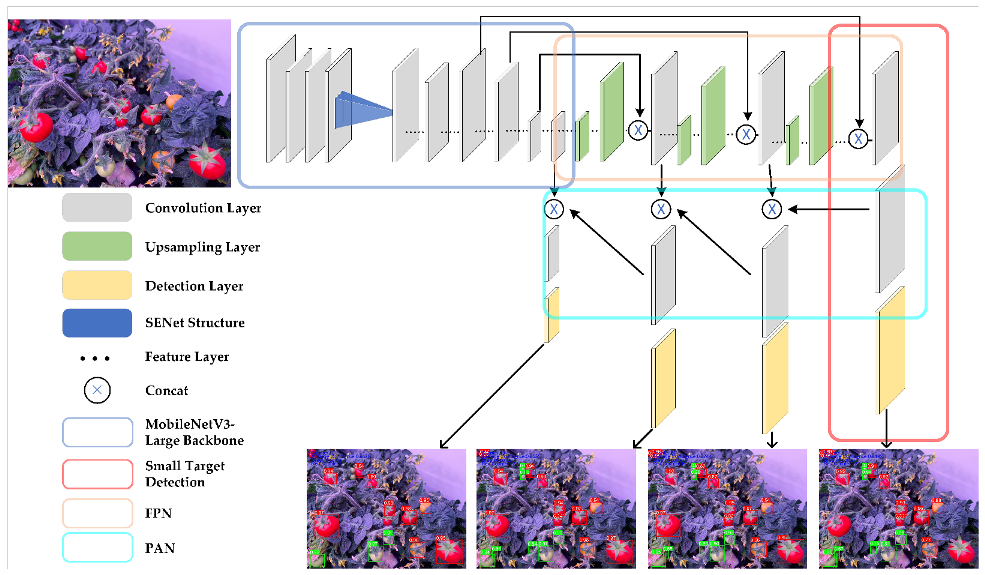
36]. Due to its original architecture, it can be used for the classification of 80 categories. However, in specific applications, only a few categories are typically required. In the case of tomato fruit detection, where the fruit may be small or occluded by leaves, a lightweight YOLOv5 method, namely SM-YOLOv5, is proposed in this paper. The model architecture is illustrated in
Figure 3. The MobileNetV3-Large backbone was used for feature extraction, and the anchor frames, regressed by K-Means machine learning, were used in the prediction layer to train the network. A small-target scale detection layer was added to enhance the model’s ability to detect small targets. Finally, the four-layer detection content was fused for non-maximum suppression (NMS) calculation [
37], and the position and classification of all tomato fruits were outputted. The model used a weight file trained on the COCO dataset [
38], and the transfer learning idea was employed to accelerate the model convergence and avoid network non-convergence due to random weights.
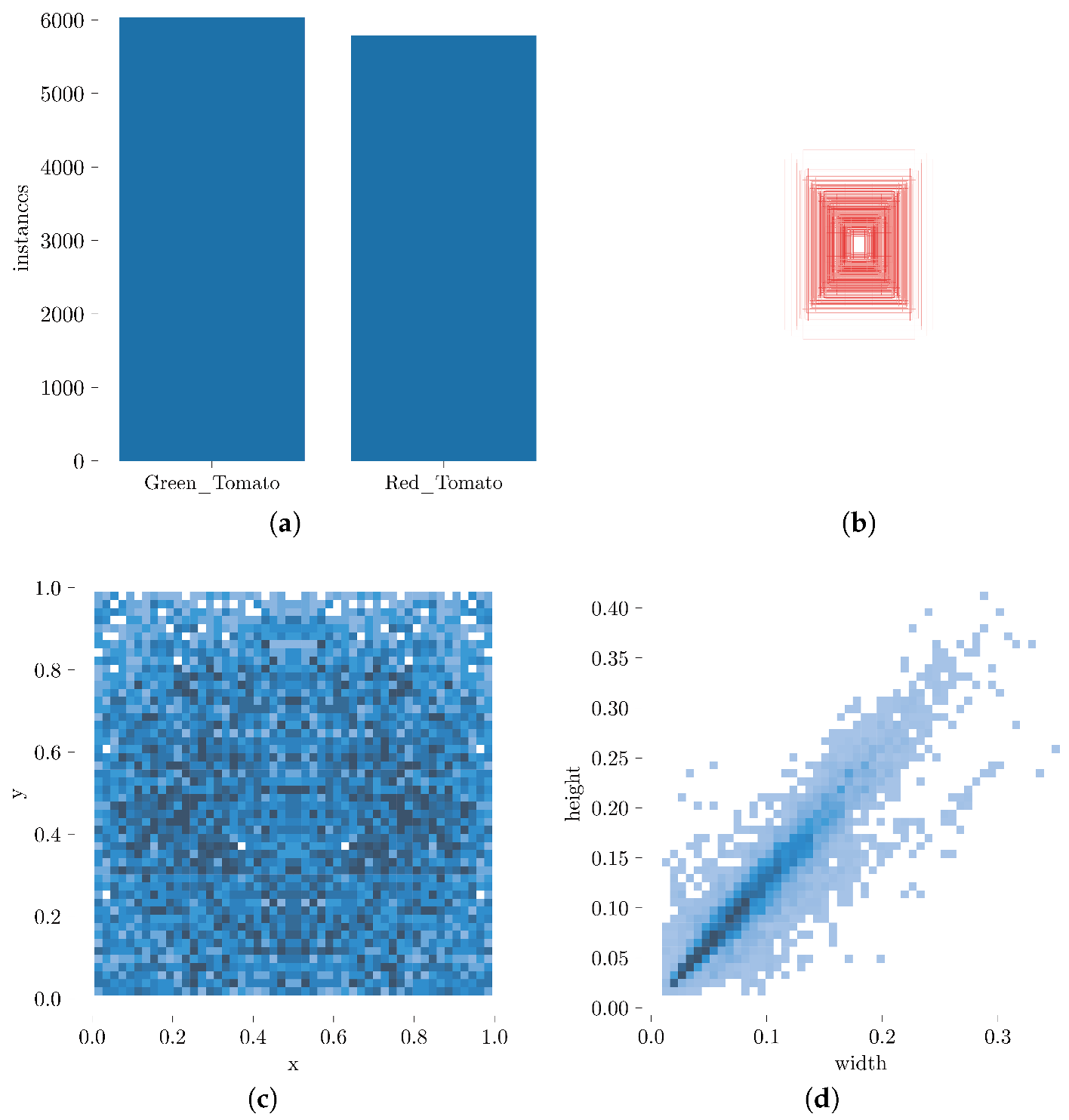
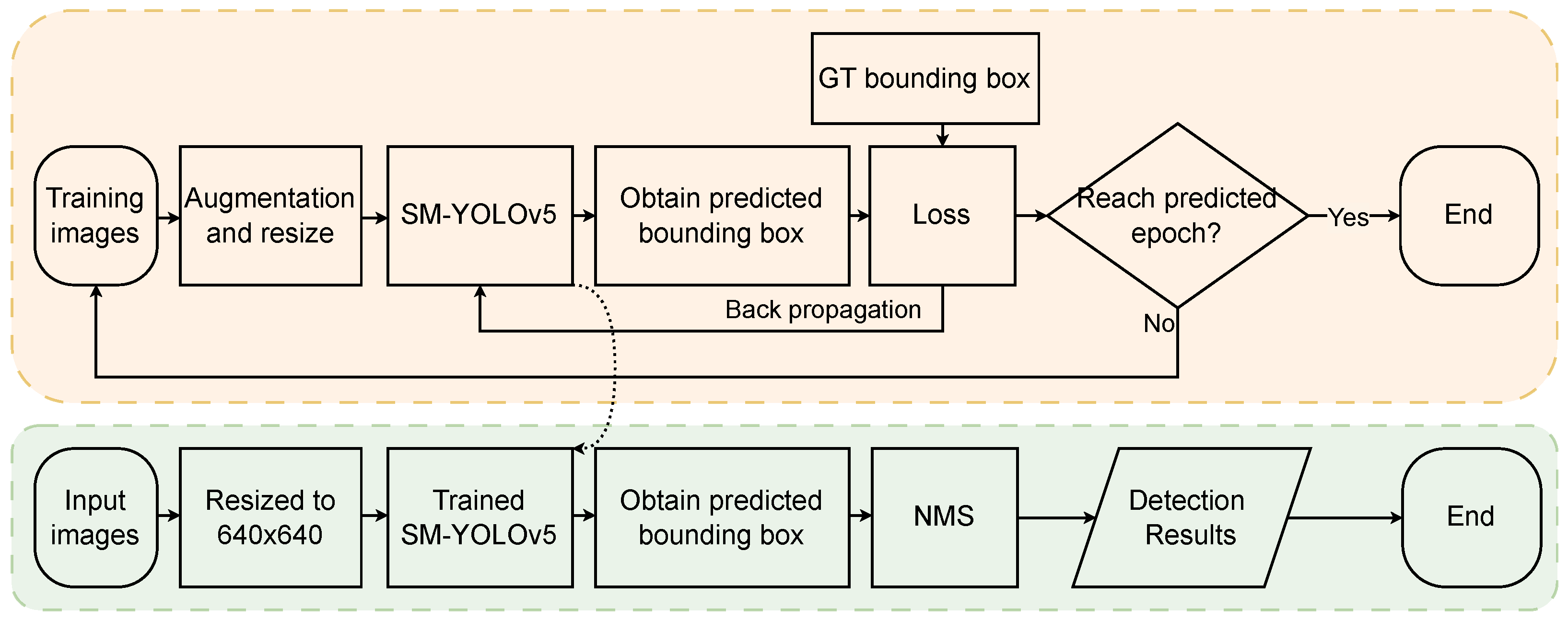
Figure 4 presents a flowchart of the training and detection process of SM-YOLOv5. Model evaluation was performed using unified evaluation standards, including AP, mAP, and FLOPs, for model comparison and evaluation. The PR curve was used to calculate the AP, and the mean value of the AP for the two classifications of green fruit and red fruit was taken as the mAP. The calculation formulas for precision, recall, and F1 score are shown in Formulas (
1)–(
4).
3.1. Lightweight MobileNetV3-Large Backbone Network
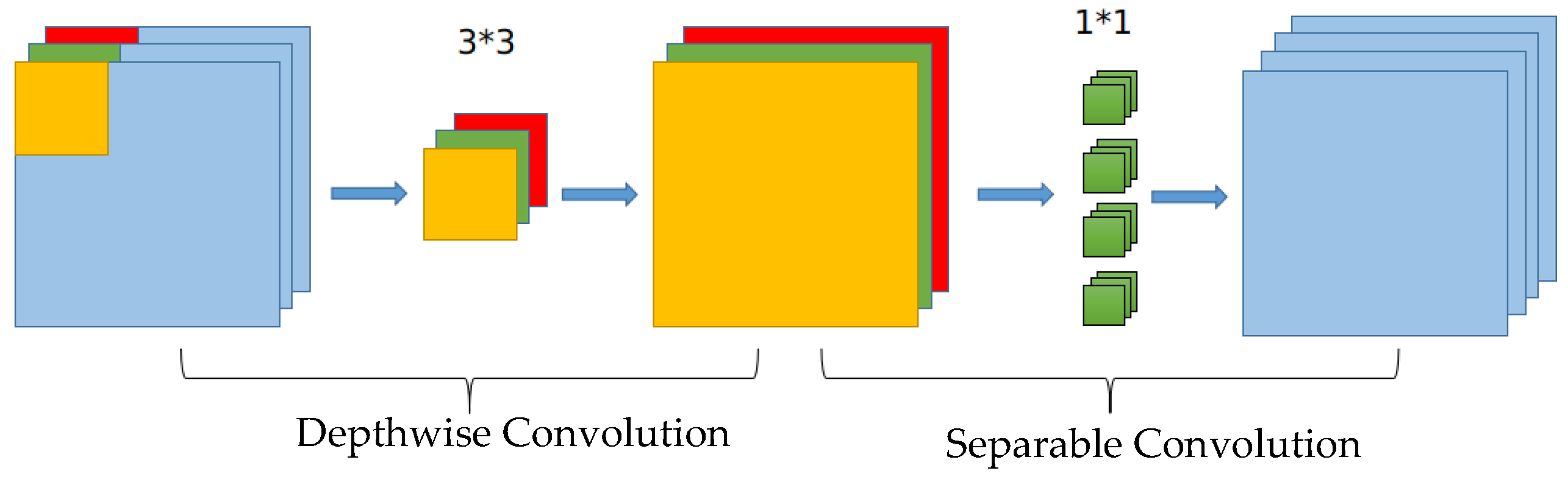
The CSPDarknet53 backbone network, utilized by YOLOv5, can effectively extract image features. However, due to the high computational resources and storage space requirements, its real-time detection applicability in embedded systems is limited. To address this issue, this study proposes the SM-YOLOv5 model, which employs MobileNetV3-Large as the backbone network for a lightweight design. MobileNetV3-Large is made up of numerous bneck units. In each bneck unit, depthwise separable convolution (DWS-Conv) is employed instead of conventional convolution operations to extract features while minimizing the number of parameters and computations. As presented in
Figure 5, the depthwise separable convolution is partitioned into two stages. Initially, each input channel undergoes channel-by-channel depthwise convolution (DW-Conv), and then the output undergoes pointwise convolution (PW-Conv). A depthwise weighted combination is performed, and the final feature map is output [
28]. The SE module (squeeze-and-excitation) channel attention mechanism [
26] is utilized in the channel separable convolution to enable the network to automatically identify the importance of each feature channel, leading to an enhanced effect. Finally, the residual network structure is utilized to alleviate the difficulty in feature transfer as the network depth increases. The detailed parameters of each layer of MobileNetV3-Large as the backbone network and the corresponding output layer are presented in
Table 2 [
39].
The proposed model enhances the detection of small-sized targets in real-time tomato detection by incorporating an additional layer for small-target detection, in addition to the original three layers for detecting targets of varying scales. This model fuses three layers of feature data with one layer of small-target features to achieve better performance. To improve the small-target detection accuracy, MobileNetV3-Large is used as the backbone network, and four different-sized feature layers are extracted for prediction.
Table 2 presents the network architecture parameters of MobileNetV3-Large and the corresponding output layer for each of the four feature layers. The improved model balances accuracy and speed by employing 3, 640, 640 color images as input. The replaced MobileNetV3-Large backbone network extracts features of sizes
,
, and
at layers 6, 13, and 15, respectively. The three-layer features correspond to small, medium, and large fields of view, which detect small, medium, and large tomato targets in the images, respectively. For detailed detection, the
feature images extracted by the third layer of MobileNetV3-Large are used as the input to enable the network to detect tomato targets that are blurred or obscured in the image background, thereby improving the detection ability of panoramic images of tomatoes within the PF environment.
3.2. Small-Target Detection Layer
The small-target detection layer is capable of addressing the challenge of accurately detecting small, partially obscured, or blurred targets within an image. YOLOv5 has successfully implemented multi-scale target detection, thereby compensating for the shortcoming of detecting targets at a single scale [
40]. The comparison of multi-scale detection in
Figure 6a–c demonstrates the output results of each scale layer prediction after NMS in multi-scale detection.
Figure 6a illustrates the output of the large-target detection layer, where many small-target tomato fruits were not accurately detected, but the recognized samples had a high confidence score. This could have been due to the fact that the larger tomato fruits contained more distinctive information, and the network fully extracted these features for detection. On the other hand, as shown in
Figure 6c for the small-target detection layer, only one large tomato fruit was not accurately detected, and the confidence score was high. This could have been because the output of this layer involved more features in the NMS operation. The application of overlapping and merging calculations to more prediction results could enhance the confidence of the detection outcomes, as is evident for the mid-target detection presented in
Figure 6b and the multi-scale fusion detection depicted in
Figure 6d. In the current example, the mid-target detection layer successfully recognized all tomato fruits with a high confidence compared to the multi-scale detection layer. The multi-scale detection layer was shown to be effective in detecting targets of different sizes and improving the confidence of the detection results. The average confidence of multi-scale fusion detection was observed to be higher, and combining the detection results of the small-target layer and the large-target layer through multi-scale fusion achieved better detection results. SM-YOLOv5 was designed to use four-scale feature fusion target detection to enhance the model’s ability to detect small, partially obscured, or blurred tomato targets.
3.3. Trained Anchors and Transfer Learning
The anchor serves as the fundamental basis for the prediction bounding box output of a network. The prediction layer extracts multiple sets of sizes and ratios based on the anchor scale and subsequently computes the predicted classification probability and positional information of all the results. In YOLOv5, an anchor regression is performed using the K-means clustering algorithm based on the labeled sample information, after which it is assigned to the appropriate scale feature map [
41]. By default, the YOLOv5 network uses the regression cluster of the COCO dataset as the highest-priority frame, and the anchors for different scale features are shown in
Table 3. To improve the detection ability of deep networks for tomatoes in plant factories, their shapes were analyzed, and the optimal size of the annotation frame in the dataset was calculated. This process enhanced the accuracy and robustness of the model, and the anchor was recalculated using K-means clustering. The anchor regression clustering process used the following parameters: a cluster count of 9 or 12, twice the aspect ratio threshold, 10,000 iterations, and the determination of optimal anchors through machine learning. By utilizing this method, the accuracy and robustness of the deep network for detecting tomatoes in plant factories were improved, as evidenced by the final anchor box PR recall rate of 0.9997. The optimal parameters for the tomato anchor and tomato small-target anchor in
Table 3 were obtained by performing regression clustering under the conditions of three-layer and four-layer target detection, respectively, and replacing the anchor training model with the COCO dataset. The aspect ratio of the anchor boxes obtained from the regression clustering tended to be rectangular, which aligned with the shape of the round tomato fruits present in the images.
The concept of transfer learning is employed to address issues of underfitting and convergence difficulties during model training. By utilizing network model weights pre-trained on relevant datasets, the applicability of a model to new scenarios can be improved [
42]. Since the COCO dataset contains a large number of image data, the network weights trained on it could be used for the detection task presented in this paper. Thus, the proposed SM-YOLOv5 network was initialized with the COCO-trained weights, followed by the fine-tuning and training of the network. The application of pre-trained weights from a diverse range of datasets to the training of a new network can overcome the challenges associated with the slow or difficult convergence of randomly generated network weights and enhance the network’s representational capacity.
5. Discussion
To address the problem of the difficulty of using general deep learning target detection technology to detect the different growth states of tomato fruits while ensuring a light weight and high precision in the environment of plant factories, this paper proposed a YOLOv5 tomato fruit growth state detection model using the MobileNetV3-Large backbone network.
The method was based on the YOLOv5 network model and used MobileNetV3-Large to replace the CSPDarknet53 backbone network for efficient feature extraction. The search structure used by MobileNetV3-Large can efficiently extract enough features on small-scale networks. For tomato fruits, the image tends to be rectangular in proportion; therefore, the K-Means clustering algorithm was used for regression in the tomato dataset to obtain the best anchors and participate in network training as a hyperparameter. In order to address the insufficiencies arising from the utilization of the MobileNetV3-large backbone network, we proposed the incorporation of a small-target detection layer to improve the three-layer multi-scale detection structure of the original model. This augmentation is particularly well-suited to scenarios in which the target object, in this case tomato fruit, is comparatively small within the context of plant factories; by integrating a smaller backbone network with an additional small-target detection layer, our network was capable of predicting all relevant features with minimal computational overhead, requiring only 7.6 GFLOPs. Furthermore, our approach achieved an mAP score of 98.7% and had a compact model file size of only 6.3 MB.
The approach outlined in this paper achieved the accurate and efficient detection of tomato fruits in testing scenarios, with a performance on par with and improved compared to that of the original YOLOv5 model. The subsequent steps involve implementing the model for detection in embedded systems and robots, refining the network model to enable the real-time detection of tomato fruit growth status in tomato-picking robots, and collaborating with multi-eye 3D cameras to precisely locate the tomato fruits within the robot’s workspace. By achieving accurate coordinate positioning, the aim is to enable high-precision, automated picking by robots.






 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}