
Three-Dimensional Human Pose Estimation from Sparse IMUs through Temporal Encoder and Regression Decoder


Abstract
:1. Introduction
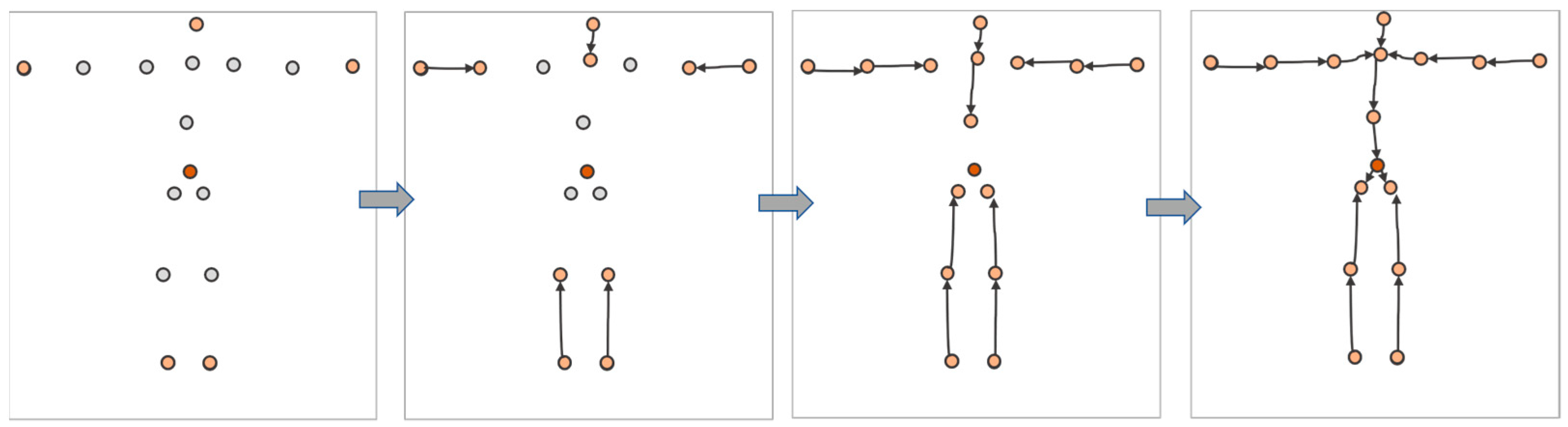
- This paper proposes a method based on an encoder–decoder framework that encodes temporal features and decodes spatial features to generate the three-dimensional human pose, which can alleviate the ambiguity of the conventional methods.
- A spatial-attention and regression network is proposed to enhance the local spatial features of inertial measurements and relies on human topological regression to pay attention to the features of joints.
- The method achieves state-of-the-art performance on two benchmarks for model-based three-dimensional human pose estimation, providing a solution for three-dimensional human motion capture in some unrestricted environments in practice.
2. Related Work
2.1. Image-IMU-Based Methods
2.2. IMU-Based Methods
3. Methods
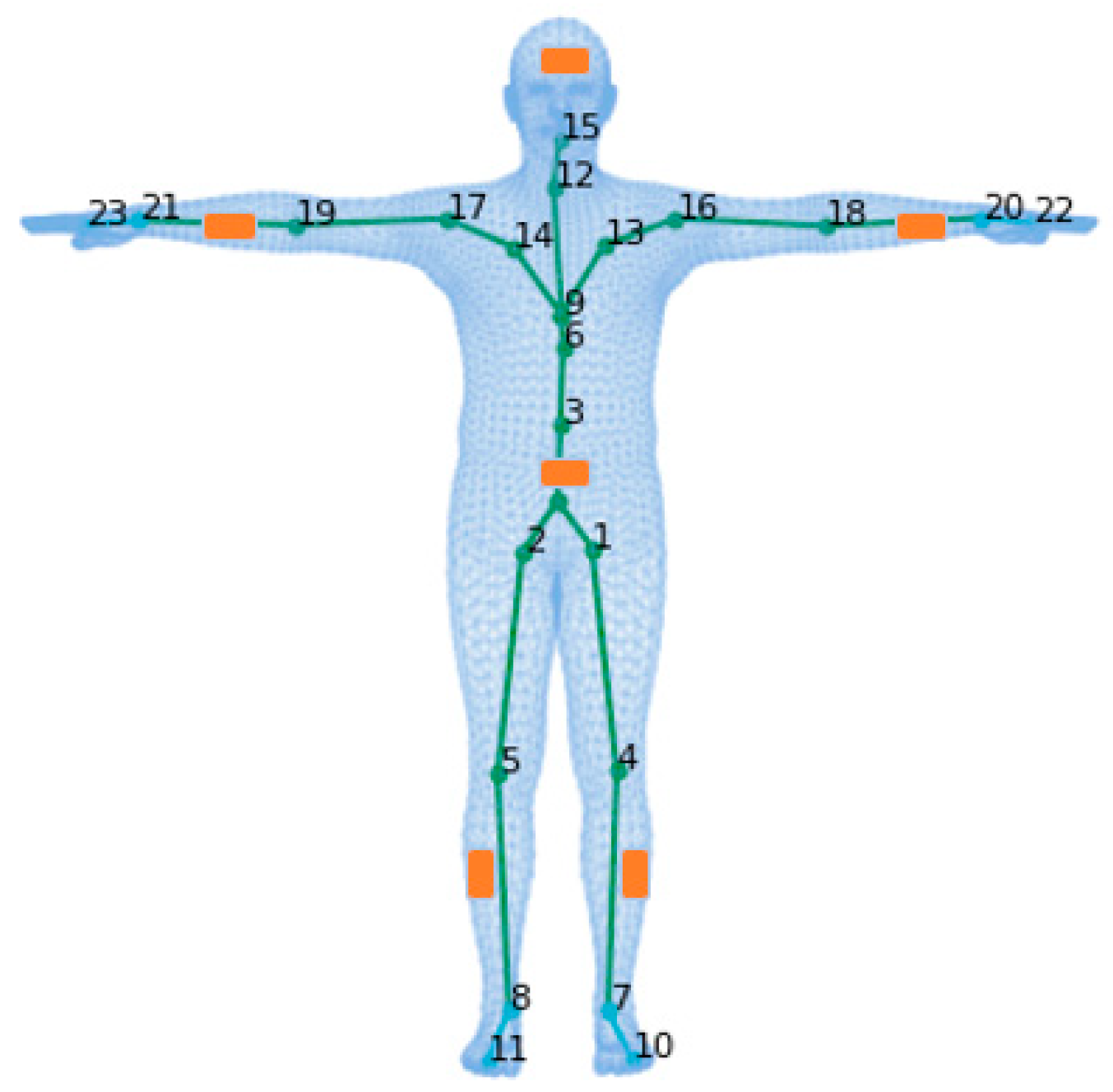
3.1. SMPL
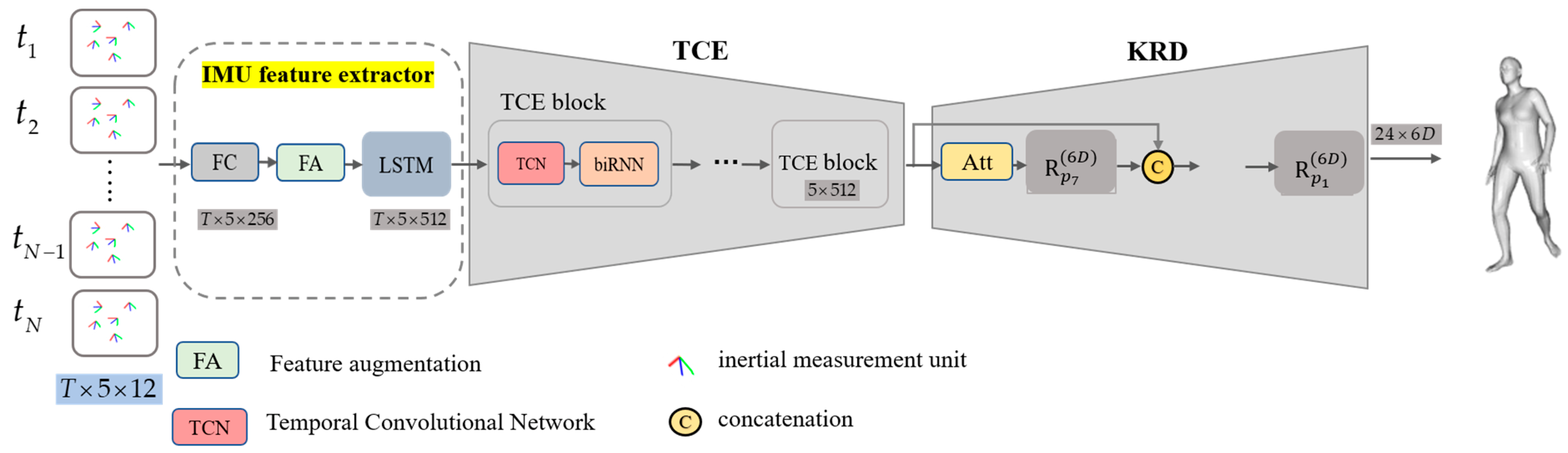
3.2. Framework Overview
3.3. IMU Feature Extractor
3.4. Temporal Convolutional Encoder
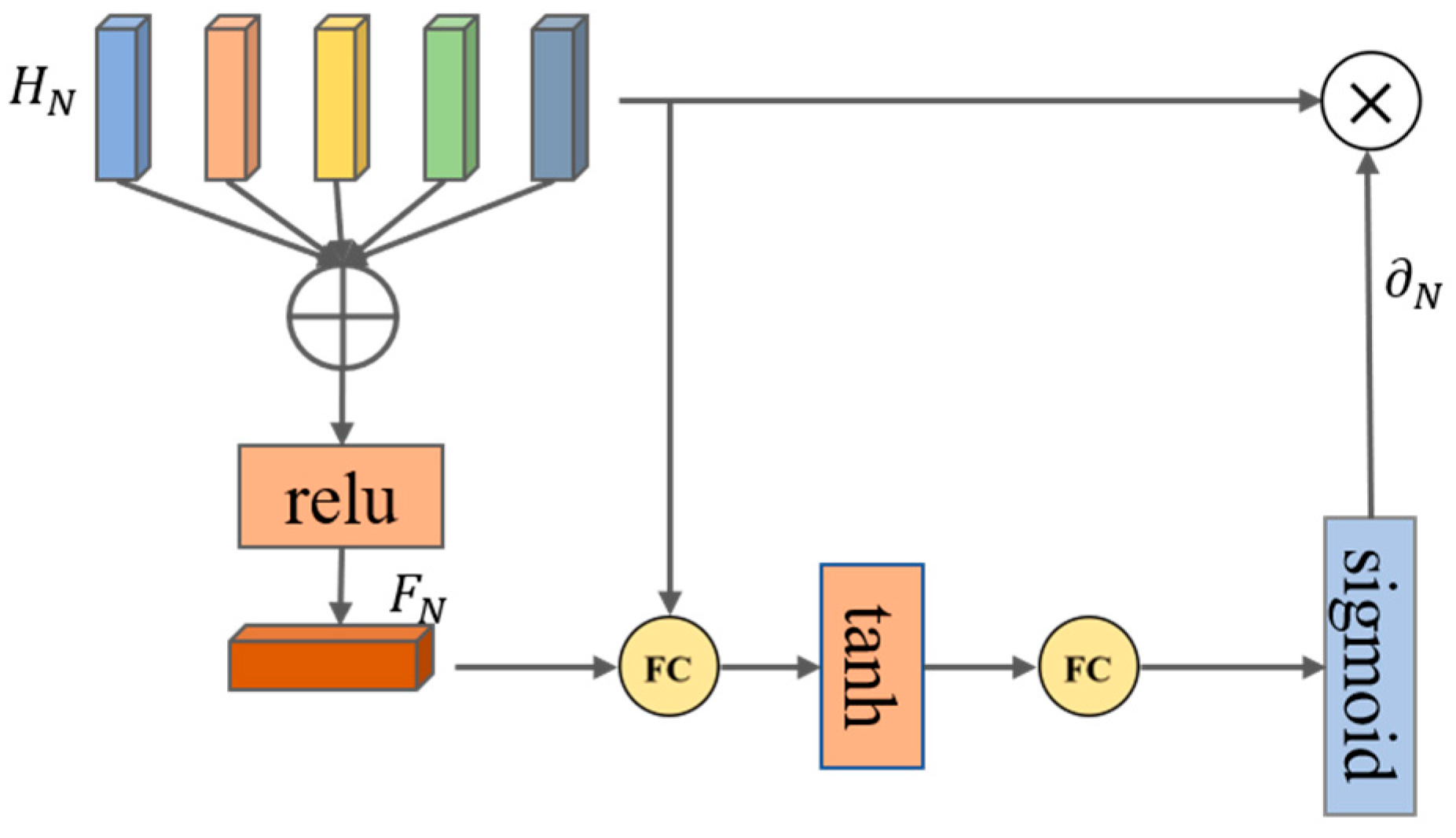
3.5. Kinematic Regression Decoder
3.6. Experimental Details
4. Experiments
4.1. Datasets and Metrics
4.1.1. Data Preparation
4.1.2. Evaluation Metrics
- (1)
- The DIP error is based on the DIP [11], which measures the error of the upper arm and thigh in the global coordinate system in degrees;
- (2)
- The angle error represents the angle error of 15 body joints in the global coordinate system and is measured in degrees;
- (3)
- The position error represents the three-dimensional position error of 15 important body joints and is measured in centimeters;
- (4)
- The jitter error is based on the work of the Tanspose [12], which calculates the position of each joint to obtain the discrete value. This error is expressed as km/s3 and calculated as follows:
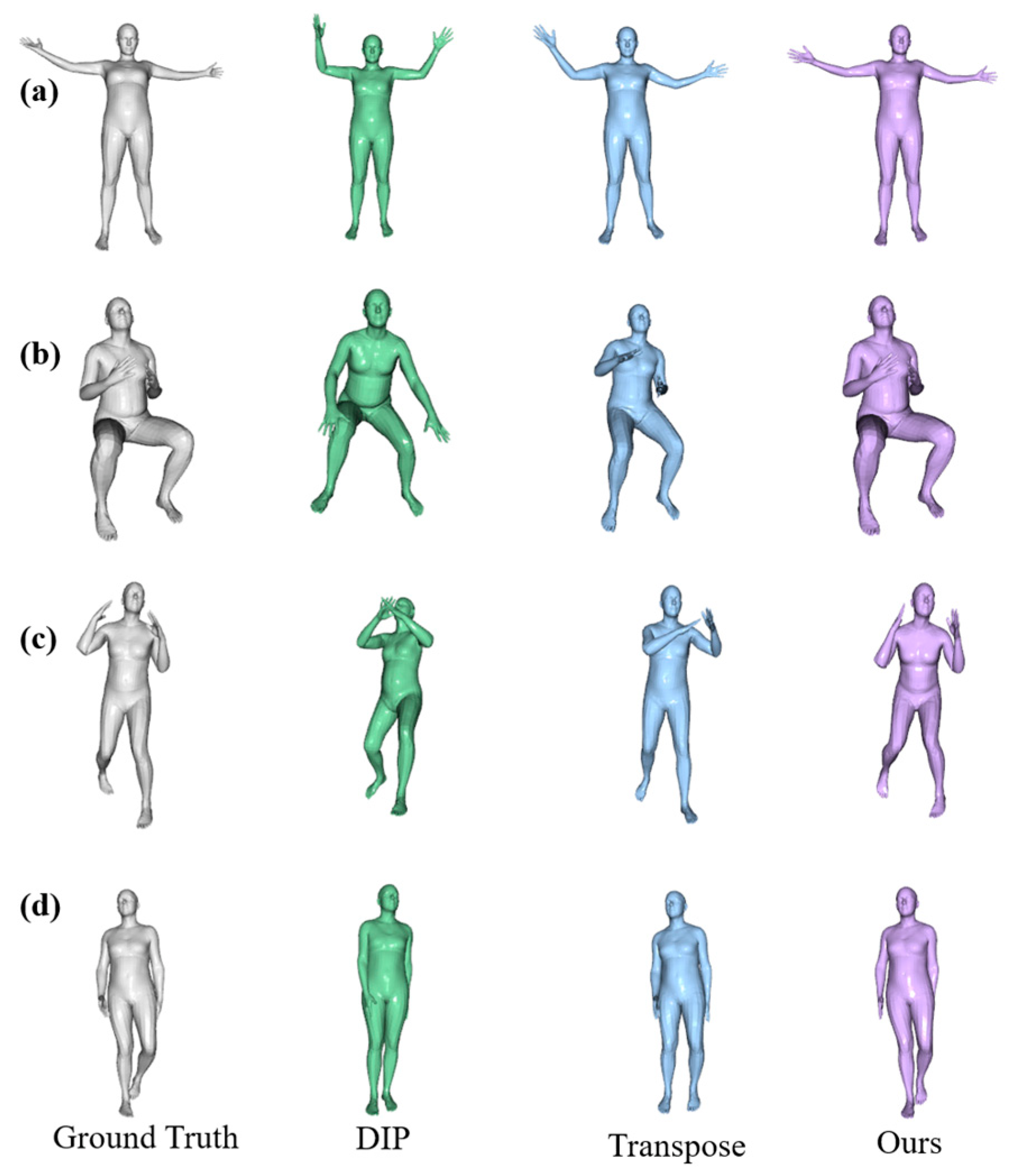
4.2. Contrast Experiment
4.3. Ablation Experiment
5. Summary and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, J.; Jiang, W.; Huang, Q.; Bao, H.; Zhou, X. Fast and robust multi-person 3D pose estimation from multiple views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Qiu, H.; Wang, C.; Wang, J.; Wang, N.; Zeng, W. Cross view fusion for 3D human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, L.; Ai, H.; Chen, R.; Zhuang, Z.; Liu, S. Cross-view tracking for multi-human 3D pose estimation at over 100 fps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yu, T.; Zheng, Z.; Guo, K.; Liu, P.; Dai, Q.; Liu, Y. Function4d: Real-time human volumetric capture from very sparse consumer RGBD sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Yu, T.; Guo, K.; Xu, F.; Dong, Y.; Su, Z.; Zhao, J.; Li, J.; Dai, Q.; Liu, Y. BodyFusion: Real-time capture of human motion and surface geometry using a single depth camera. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kocabas, M.; Athanasiou, N.; Black, M.J. VIBE: Video inference for human body pose and shape estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wei, W.-L.; Lin, J.-C.; Liu, T.-L.; Liao, H.-Y.M. Capturing humans in motion: Temporal-attentive 3D human pose and shape estimation from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end recovery of human shape and pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kocabas, M.; Huang, C.H.P.; Hilliges, O.; Black, M.J. PARE: Part attention regressor for 3D human body estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Von Marcard, T.; Rosenhahn, B.; Black, M.J.; Pons-Moll, G. Sparse inertial poser: Automatic 3D human pose estimation from sparse imus. In Computer Graphics Forum; Wiley: Hoboken, NJ, USA, 2017; Volume 36. [Google Scholar]
- Huang, Y.; Kaufmann, M.; Aksan, E.; Black, M.J.; Hilliges, O.; Pons-Moll, G. Deep inertial poser: Learning to reconstruct human pose from sparse inertial measurements in real time. ACM Trans. Graph. TOG 2018, 37, 185. [Google Scholar] [CrossRef] [Green Version]
- Yi, X.; Zhou, Y.; Xu, F. Transpose: Real-time 3D human translation and pose estimation with six inertial sensors. ACM Trans. Graph. TOG 2021, 40, 86. [Google Scholar] [CrossRef]
- Yi, X.; Zhou, Y.; Habermann, M.; Shimada, S.; Golyanik, V.; Theobalt, C.; Xu, F. Physical inertial poser (pip): Physics-aware real-time human motion tracking from sparse inertial sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Puchert, P.; Ropinski, T. Human pose estimation from sparse inertial measurements through recurrent graph convolution. arXiv 2021, arXiv:2107.11214. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. TOG 2015, 34, 248. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Malleson, C.; Gilbert, A.; Trumble, M.; Collomosse, J.; Hilton, A.; Volino, M. Real-time full-body motion capture from video and IMUs. In Proceedings of the 2017 international conference on 3D vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Trumble, M.; Gilbert, A.; Malleson, C.; Hilton, A.; Collomosse, J. Total capture: 3D human pose estimation fusing video and inertial sensors. In Proceedings of the 28th British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Trumble, M.; Gilbert, A.; Hilton, A.; Collomosse, J. Deep autoencoder for combined human pose estimation and body model upscaling. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Gilbert, A.; Trumble, M.; Malleson, C.; Hilton, A.; Collomosse, J. Fusing visual and inertial sensors with semantics for 3D human pose estimation. Int. J. Comput. Vis. 2018, 127, 381–397. [Google Scholar] [CrossRef] [Green Version]
- Von Marcard, T.; Henschel, R.; Black, M.J.; Rosenhahn, B.; Pons-Moll, G. Recovering accurate 3D human pose in the wild using imus and a moving camera. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Von Marcard, T.; Pons-Moll, G.; Rosenhahn, B. Human pose estimation from video and imus. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1533–1547. [Google Scholar] [CrossRef] [PubMed]
- Guzov, V.; Mir, A.; Sattler, T.; Pons-Moll, G. Human poseitioning system (hps): 3D human pose estimation and self-localization in large scenes from body-mounted sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhang, Z.; Wang, C.; Qin, W.; Zeng, W. Fusing wearable imus with multi-view images for human pose estimation: A geometric approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Schepers, M.; Giuberti, M.; Bellusci, G. Xsens MVN: Consistent tracking of human motion using inertial sensing. Xsens Technol. 2018, 1. [Google Scholar] [CrossRef]
- Slyper, R.; Hodgins, J.K. Action capture with accelerometers. In Proceedings of the 2008 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Dublin, Ireland, 7–9 July 2008. [Google Scholar]
- Tautges, J.; Zinke, A.; Krüger, B.; Baumann, J.; Weber, A.; Helten, T.; Müller, M.; Seidel, H.-P.; Eberhardt, B. Motion reconstruction using sparse accelerometer data. ACM Trans. Graph. TOG 2011, 30, 18. [Google Scholar] [CrossRef]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M.J. AMASS: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Capture | DIP-IMU | |||||||
|---|---|---|---|---|---|---|---|---|
| DIP Err [°] | Ang Err [°] | Pos Err [cm] | Jerk Err | DIP Err [°] | Ang Err [°] | Pos Err [cm] | Jerk Err | |
| Trained on synthetic data | ||||||||
| DIP [11] | 30.00 (19.09) | 24.24 (15.18) | 14.87 (9.33) | 4.92 (6.85) | 33.17 (19.16) | 24.30 (15.17) | 13.74 (8.29) | 3.60 (5.66) |
| Transpose [12] | 18.49 (15.68) | 13.78 (9.40) | 8.22 (6.82) | 0.64 (1.97) | 29.92 (16.78) | 12.46 (7.32) | 8.10 (6.08) | 1.00 (3.50) |
| Puchert et al. [14] | 15.81 (12.38) | 12.53 (8.41) | 7.27 (5.32) | 1.16 (2.61) | 28.12 (14.28) | 11.35 (6.28) | 7.73 (5.61) | 1.12 (3.55) |
| Ours | 17.12 (6.39) | 15.09 (5.46) | 5.80 (2.46) | 1.06 (1.38) | 22.44 (6.08) | 19.73 (5.77) | 6.52 (2.54) | 1.12 (1.41) |
| Fine-tuned on real-world data | ||||||||
| DIP [11] | 17.45 (15.59) | 14.40 (10.94) | 8.26 (7.26) | 2.40 (3.51) | 17.75 (11.77) | 15.68 (11.13) | 7.71 (5.43) | 2.04 (3.92) |
| Transpose [12] | 17.03 (14.74) | 11.72 (8.29) | 7.43 (5.95) | 0.63 (1.96) | 18.52 (13.50) | 9.57 (6.45) | 6.71 (4.95) | 1.00 (3.50) |
| Puchert et al. [14] | 13.12 (10.99) | 10.12 (7.03) | 6.00 (4.64) | 1.08 (2.46) | 15.18 (9.83) | 8.13 (5.23) | 5.65 (3.73) | 1.13 (3.54) |
| Ours | 15.39 (6.28) | 13.37 (5.35) | 5.18 (2.24) | 0.74 (0.93) | 14.54 (5.68) | 13.76 (5.21) | 4.55 (1.90) | 1.02 (1.31) |
| DIP Err [°] | Ang Err [°] | Pos Err [cm] | Jerk Err | |
|---|---|---|---|---|
| Only-regression | 15.14 (5.33) | 13.86 (5.84) | 4.71 (1.82) | 1.06 (1.38) |
| MLP | 36.46 (15.32) | 24.76 (9.23) | 5.98 (2.30) | 1.21 (2.06) |
| Ours | 14.54 (5.68) | 13.76 (5.21) | 4.55 (1.90) | 1.02 (1.31) |
| Joint | Hip | Knee | Ankle | Shoulder | Elbow | Wrist | Back | Neck | Head |
|---|---|---|---|---|---|---|---|---|---|
| Only-regression | 1.72 | 7.97 | 10.08 | 6.01 | 10.67 | 11.84 | 2.33 | 5.26 | 5.96 |
| MLP | 2.33 | 9.45 | 14.14 | 10.40 | 18.14 | 20.84 | 3.28 | 7.83 | 8.30 |
| Ours | 1.69 | 6.79 | 9.42 | 5.67 | 10.08 | 12.30 | 2.35 | 5.08 | 5.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, X.; Dong, J.; Song, K.; Xiao, J. Three-Dimensional Human Pose Estimation from Sparse IMUs through Temporal Encoder and Regression Decoder. Sensors 2023, 23, 3547. https://doi.org/10.3390/s23073547
Liao X, Dong J, Song K, Xiao J. Three-Dimensional Human Pose Estimation from Sparse IMUs through Temporal Encoder and Regression Decoder. Sensors. 2023; 23(7):3547. https://doi.org/10.3390/s23073547
Chicago/Turabian StyleLiao, Xianhua, Jiayan Dong, Kangkang Song, and Jiangjian Xiao. 2023. "Three-Dimensional Human Pose Estimation from Sparse IMUs through Temporal Encoder and Regression Decoder" Sensors 23, no. 7: 3547. https://doi.org/10.3390/s23073547
APA StyleLiao, X., Dong, J., Song, K., & Xiao, J. (2023). Three-Dimensional Human Pose Estimation from Sparse IMUs through Temporal Encoder and Regression Decoder. Sensors, 23(7), 3547. https://doi.org/10.3390/s23073547