


PW-360IQA: Perceptually-Weighted Multichannel CNN for Blind 360-Degree Image Quality Assessment


Abstract
:1. Introduction
- The use of the weight sharing strategy to reduce the complexity of the model and improve the robustness of the multichannel CNN.
- Instead of predicting a single score per 360-degree image, a quality score distribution is predicted by taking advantage of the variability of the visual scan-paths.
- Inspired by the way opinion scores are gathered and processed, we define an agreement-based pooling method to derive the final quality scores.
2. Related Work
2.1. Traditional Models
2.2. Learning-Based Models
2.2.1. Patch-Based Models
2.2.2. Multichannel Models
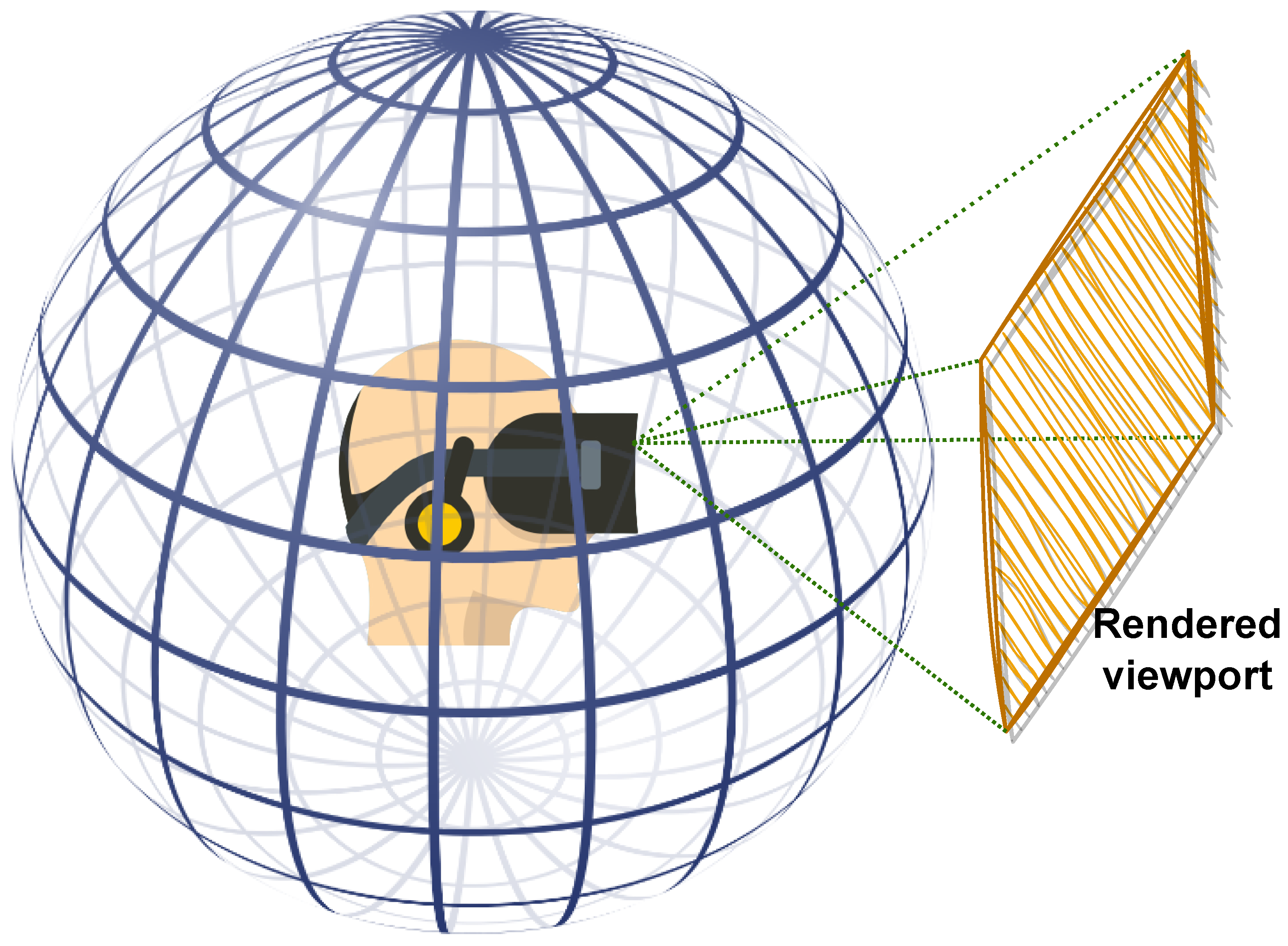
3. Proposed 360-Degree IQA Methodology
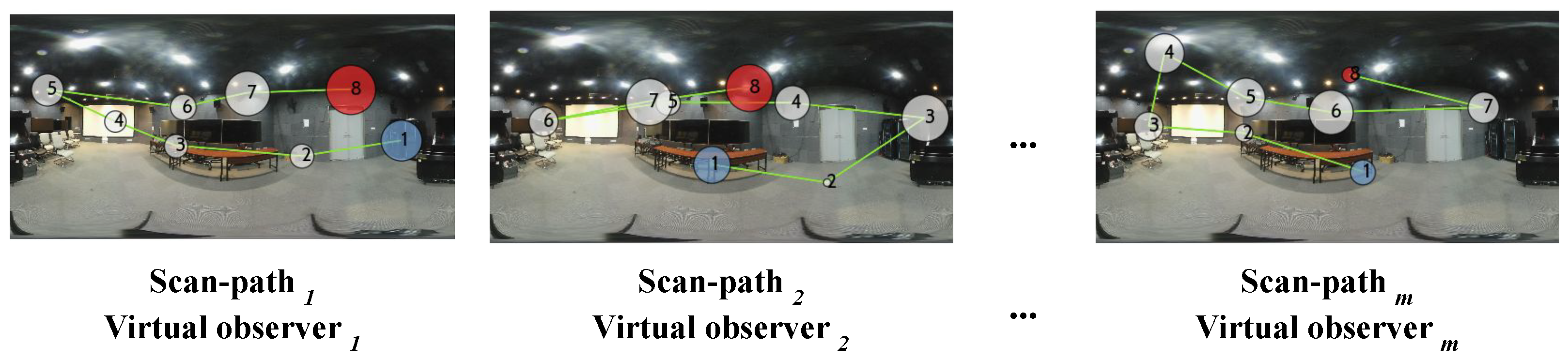
3.1. Data Preparation
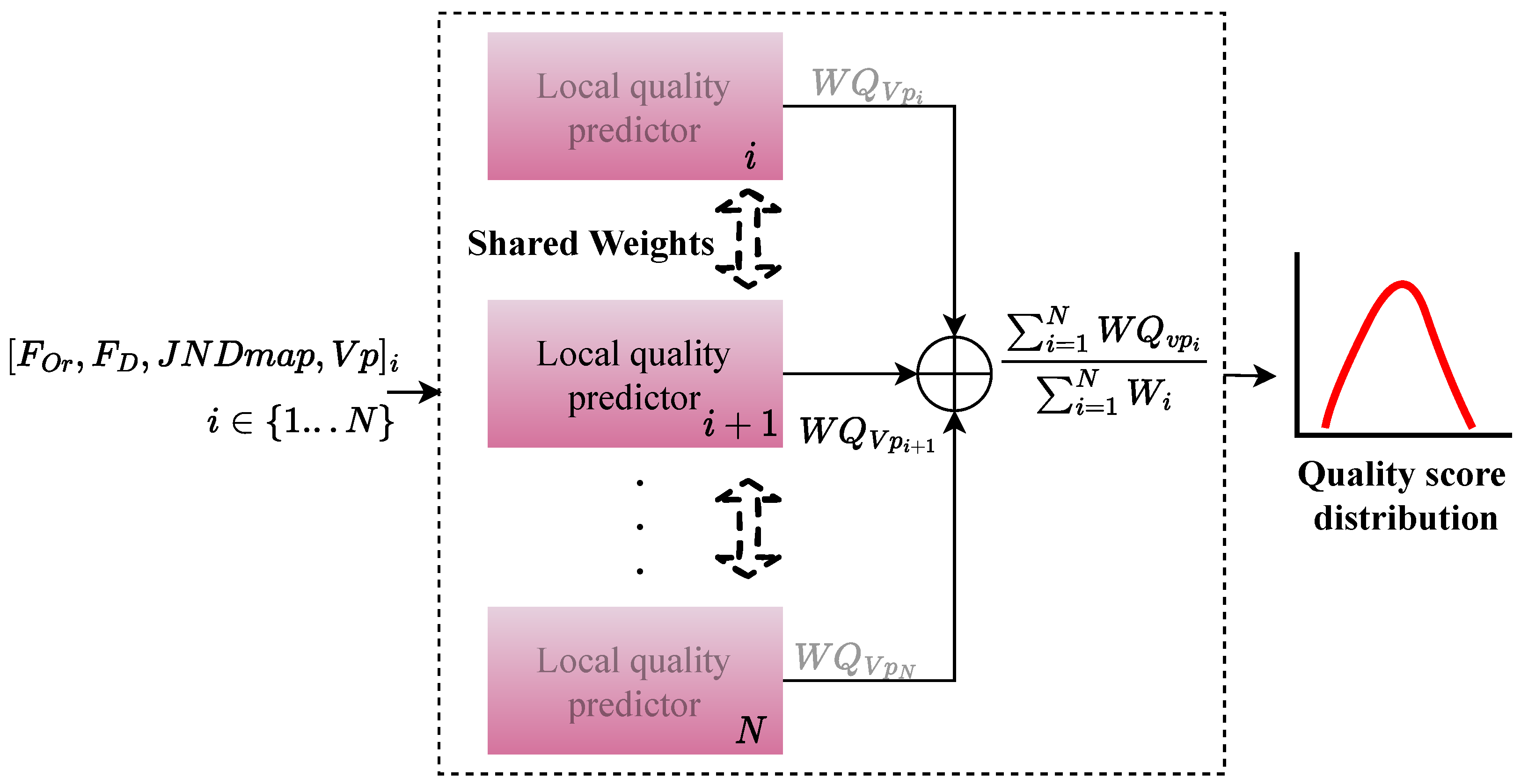
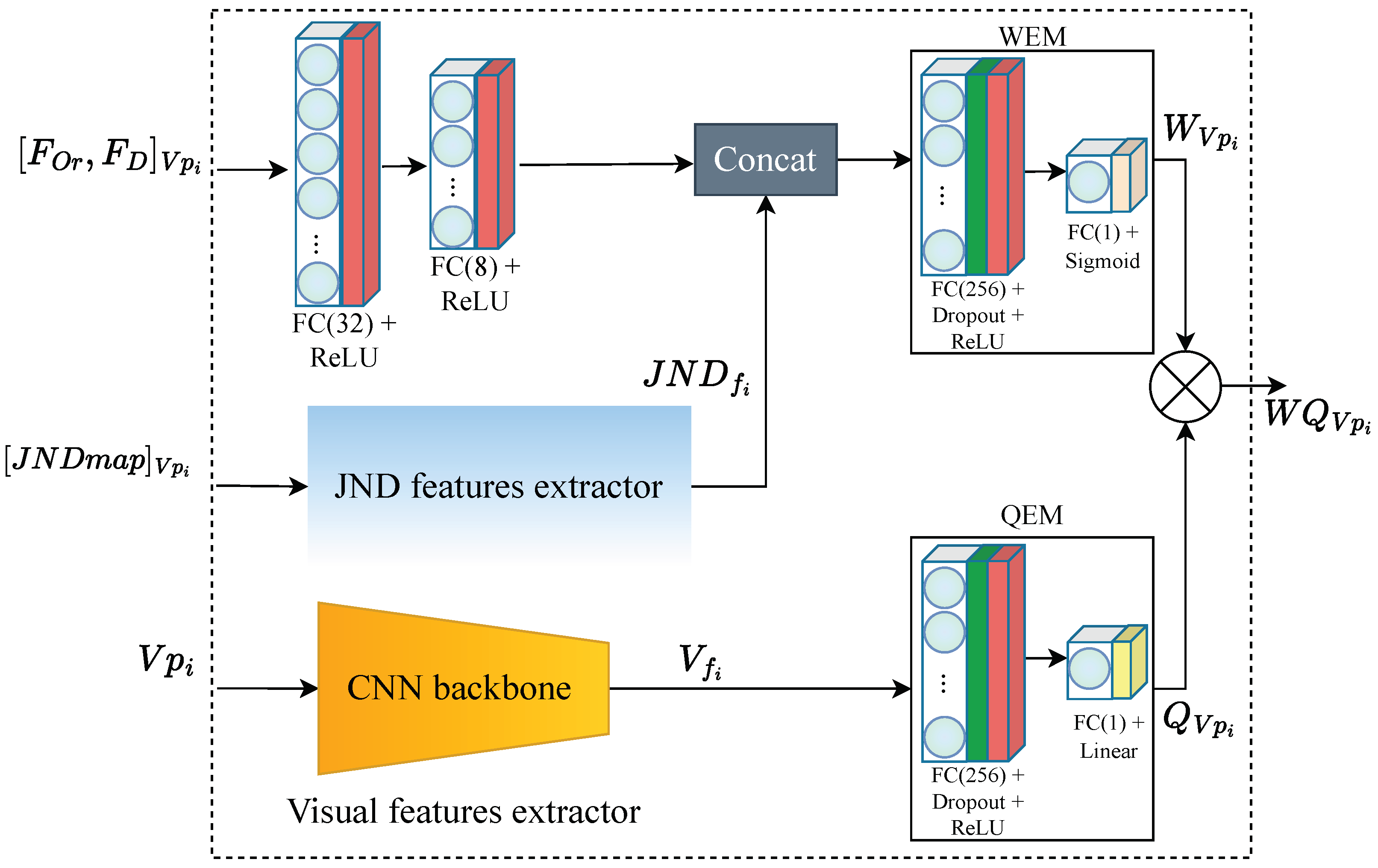
3.2. PW-360IQA Model
3.2.1. Local Quality Predictor
4. Experimental Results
4.1. Experimental Setup
4.1.1. Datasets
- OIQA:
- This includes 320 distorted 360-degree images derived from 16 pristine ones. The used distortions include JPEG compression (JPEG), JPEG 2000 compression (JP2K), Gaussian blur (BLUR), and Gaussian white noise (WN). Each distortion type is applied at five different levels of distortion, resulting in a total of 20 versions for each pristine image.
- CVIQ:
- This includes 16 pristine 360-degree images and their corresponding 528 distorted versions. Only compression-related distortions are used to generate this dataset, namely JPEG with quality factors ranging from 50 to 0, as well as H.264/AVC (AVC) and H.265/HEVC (HEVC) with quantization parameters (QPs) ranging from 30 to 50. Each distortion was applied at eleven levels, resulting in a total of 33 distorted versions for each pristine image.
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
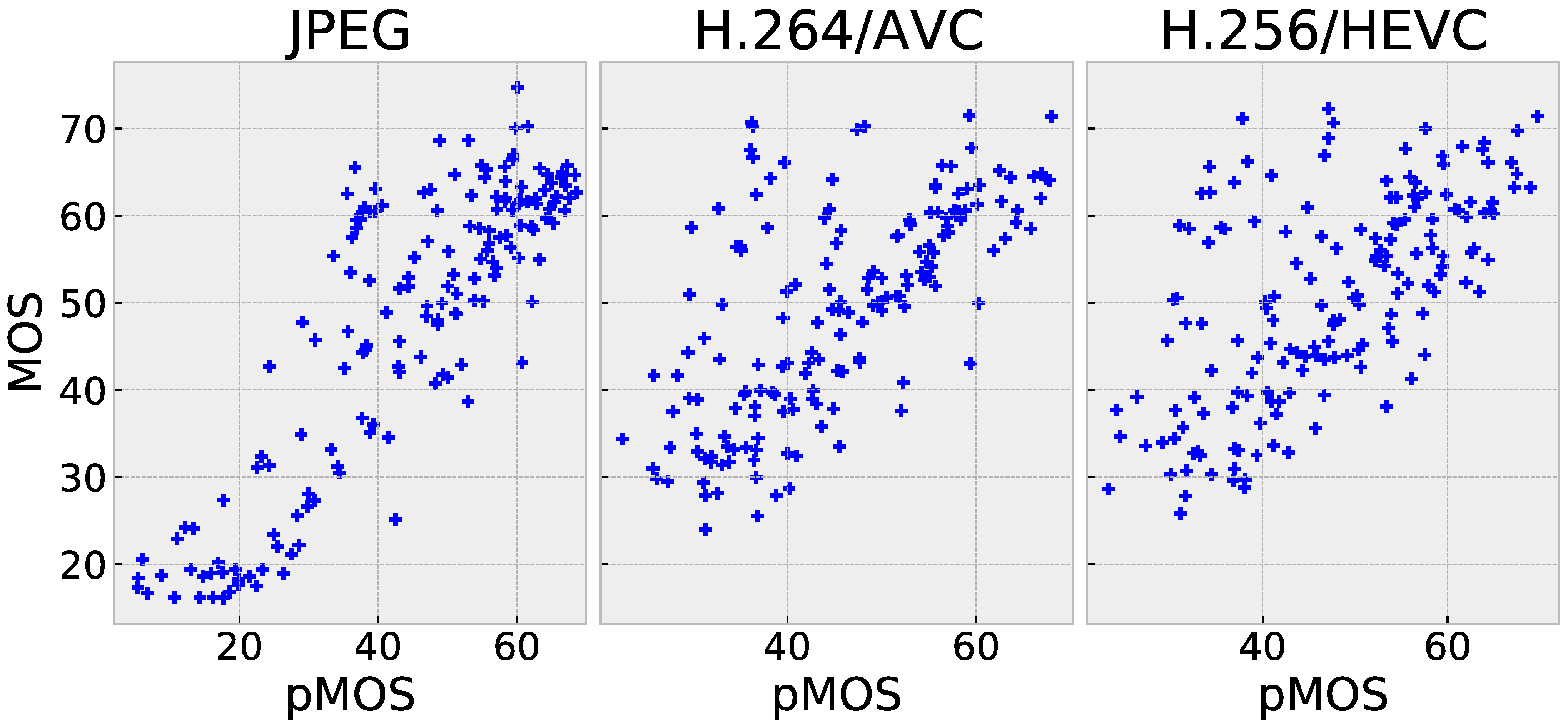
4.2. Performance Comparison
4.3. Ablation Study
4.3.1. Model Architecture
4.3.2. Quality Score Estimation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, W.; Alan, B. Modern image quality assessment. Synth. Lect. Image Video Multimed. Process. 2006, 2, 1–156. [Google Scholar]
- Perkis, A.; Timmerer, C.; Baraković, S.; Husić, J.B.; Bech, S.; Bosse, S.; Botev, J.; Brunnström, K.; Cruz, L.; De Moor, K.; et al. QUALINET white paper on definitions of immersive media experience (IMEx). In Proceedings of the ENQEMSS, 14th QUALINET Meeting, Online, 4 September 2020. [Google Scholar]
- Sendjasni, A.; Larabi, M.; Cheikh, F. Convolutional Neural Networks for Omnidirectional Image Quality Assessment: A Benchmark. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7301–7316. [Google Scholar] [CrossRef]
- Sendjasni, A.; Larabi, M.; Cheikh, F. Perceptually-Weighted CNN For 360-Degree Image Quality Assessment Using Visual Scan-Path And JND. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1439–1443. [Google Scholar]
- Huanga, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yu, M.; Lakshman, H.; Girod, B. A Framework to Evaluate Omnidirectional Video Coding Schemes. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality, Fukuoka, Japan, 19 September–3 October 2015; pp. 31–36. [Google Scholar]
- Sun, Y.; Lu, A.; Yu, L. Weighted-to-Spherically-Uniform Quality Evaluation for Omnidirectional Video. IEEE Signal Process. Lett. 2017, 24, 1408–1412. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Y.; Li, Y.; Chen, Z.; Wang, Z. Spherical Structural Similarity Index for Objective Omnidirectional Video Quality Assessment. In Proceedings of the IEEE International Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zakharchenko, V.; Kwang, P.; Jeong, H. Quality metric for spherical panoramic video. Opt. Photonics Inf. Process. X 2016, 9970, 57–65. [Google Scholar]
- Luz, G.; Ascenso, J.; Brites, C.; Pereira, F. Saliency-driven omnidirectional imaging adaptive coding: Modeling and assessment. In Proceedings of the IEEE 19th International Workshop on Multimedia Signal Processing (MMSP), Luton, UK, 16–18 October 2017; pp. 1–6. [Google Scholar]
- Upenik, E.; Ebrahimi, T. Saliency Driven Perceptual Quality Metric for Omnidirectional Visual Content. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4335–4339. [Google Scholar]
- Ozcinar, C.; Cabrera, J.; Smolic, A. Visual Attention-Aware Omnidirectional Video Streaming Using Optimal Tiles for Virtual Reality. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 217–230. [Google Scholar] [CrossRef]
- Croci, S.; Ozcinar, C.; Zerman, E.; Cabrera, J.; Smolic, A. Voronoi-based Objective Quality Metrics for Omnidirectional Video. In Proceedings of the QoMEX, Berlin, Germany, 5–7 June 2019; pp. 1–6. [Google Scholar]
- Croci, S.; Ozcinar, C.; Zerman, E.; Knorr, S.; Cabrera, J.; Smolic, A. Visual attention-aware quality estimation framework for omnidirectional video using spherical voronoi diagram. Qual. User Exp. 2020, 5, 1–17. [Google Scholar] [CrossRef]
- Sui, X.; Ma, K.; Yao, Y.; Fang, Y. Perceptual Quality Assessment of Omnidirectional Images as Moving Camera Videos. IEEE Trans. Vis. Comput. Graph. 2022, 28, 3022–3034. [Google Scholar] [CrossRef]
- Truong, T.; Tran, T.; Thang, T. Non-reference Quality Assessment Model using Deep learning for Omnidirectional Images. In Proceedings of the IEEE International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019; pp. 1–5. [Google Scholar]
- Miaomiao, Q.; Feng, S. Blind 360-degree image quality assessment via saliency-guided convolution neural network. Optik 2021, 240, 166858. [Google Scholar]
- Kao, K.Z.; Chen, Z. Video Saliency Prediction Based on Spatial-Temporal Two-Stream Network. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3544–3557. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, L.; Xu, M.; Deng, X.; Feng, B. Spatial Attention-Based Non-Reference Perceptual Quality Prediction Network for Omnidirectional Images. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, W.; Ma, K.; Yan, J.; Deng, D.; Wang, Z. Blind Image Quality Assessment Using a Deep Bilinear Convolutional Neural Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 36–47. [Google Scholar] [CrossRef]
- Sun, W.; Luo, W.; Min, X.; Zhai, G.; Yang, X.; Gu, K.; Ma, S. MC360IQA: The Multi-Channel CNN for Blind 360-Degree Image Quality Assessment. IEEE J. Sel. Top. Signal Process. 2019, 14, 64–77. [Google Scholar] [CrossRef]
- Zhou, Y.; Sun, Y.; Li, L.; Gu, K.; Fang, Y. Omnidirectional Image Quality Assessment by Distortion Discrimination Assisted Multi-Stream Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1767–1777. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Kim, H.G.; Lim, H.; Ro, Y.M. Deep Virtual Reality Image Quality Assessment with Human Perception Guider for Omnidirectional Image. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 917–928. [Google Scholar] [CrossRef]
- Xu, J.; Zhou, W.; Chen, Z. Blind Omnidirectional Image Quality Assessment with Viewport Oriented Graph Convolutional Networks. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1724–1737. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Hou, C.; Zhou, W.; Xu, J.; Chen, Z. Adaptive Hypergraph Convolutional Network for No-Reference 360-Degree Image Quality Assessment. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 961–969. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph neural networks. Proc. Aaai Conf. Artif. Intell. 2019, 33, 3558–3565. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Y.; Zhang, Y. Recent advances in omnidirectional video coding for virtual reality: Projection and evaluation. Signal Process. 2018, 146, 66–78. [Google Scholar] [CrossRef]
- Noton, D.; Stark, L. Scanpaths in saccadic eye movements while viewing and recognizing patterns. Vis. Res. 1971, 11, 929–942. [Google Scholar] [CrossRef]
- Sun, W.; Chen, Z.; Wu, F. Visual Scanpath Prediction Using IOR-ROI Recurrent Mixture Density Network. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2101–2118. [Google Scholar] [CrossRef]
- Wu, J.; Shi, G.; Lin, W.; Liu, A.; Qi, F. Just Noticeable Difference Estimation for Images with Free-Energy Principle. IEEE Trans. Multimed. 2013, 15, 1705–1710. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification using a “Siamese” Time Delay Neural Network. Adv. Neural Inf. Process. Syst. 1993, 6, 1–8. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Huber, P. Robust Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 523. [Google Scholar]
- Duan, H.; Zhai, G.; Min, X.; Zhu, Y.; Fang, Y.; Yang, X. Perceptual Quality Assessment of Omnidirectional Images. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- ITU-R. Methodology for the Subjective Assessment of the Quality of Television Pictures BT Series Broadcasting Service; TU Radiocommunication Sector: Geneva, Switzerland, 2012; Volume 13. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Zheng, X.; Jiang, G.; Yu, M.; Jiang, H. Segmented Spherical Projection-Based Blind Omnidirectional Image Quality Assessment. IEEE Access 2020, 8, 31647–31659. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | OIQA [40] | CVIQ [23] |
| Ref images | 16 | 16 |
| Distorted images | 320 | 528 |
| Distortion type (distortion levels) | JPG(5)/WGN(5) JP2K(5)/BLR(5) | JPG(11)/AVC(11) HEVC (11) |
| Number of observers | 20 (M: 15, F: 5) | 20 (M: 14, F: 6) |
| HMD | HTC Vive | HTC Vive |
| ALL | JPEG | H.264/AVC | H.265/HEVC | Complexity | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ref. | Model | PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ | # Params↓ |
| FR | PSNR | 0.7320 | 0.7662 | 9.0397 | 0.7342 | 0.8643 | 8.5866 | 0.7572 | 0.7592 | 8.0448 | 0.7169 | 0.7215 | 8.3279 | |
| FR | SSIM | 0.8857 | 0.8972 | 6.2140 | 0.9334 | 0.9749 | 3.7986 | 0.9451 | 0.9457 | 4.0165 | 0.9220 | 0.9232 | 4.6219 | |
| NR | BRISQUE | 0.7448 | 0.7641 | 9.0751 | 0.8489 | 0.9091 | 7.1137 | 0.7193 | 0.7294 | 8.4558 | 0.7151 | 0.7104 | 8.4646 | |
| FR | S-PSNR | 0.7467 | 0.7741 | 8.9066 | 0.7520 | 0.8772 | 8.1974 | 0.7690 | 0.7748 | 7.8743 | 0.7389 | 0.7428 | 8.0515 | |
| FR | WS-PSNR | 0.7498 | 0.7755 | 8.8816 | 0.7604 | 0.8802 | 8.1019 | 0.7726 | 0.7748 | 7.8143 | 0.7430 | 0.7469 | 7.9974 | |
| NR | SSP-BOIQA | 0.8900 | 0.8561 | 6.9414 | 0.9155 | 0.8533 | 6.8471 | 0.8850 | 0.8611 | 7.0422 | 0.8544 | 0.8410 | 6.3020 | |
| NR | MC360IQA | 0.9506 | 0.9139 | 3.0935 | 0.9746 | 0.9316 | 2.6388 | 0.9461 | 0.9244 | 2.6983 | 0.9126 | 0.8985 | 3.2935 | 22 M |
| NR | Zhou et al. | 0.9020 | 0.9112 | 6.1170 | 0.9572 | 0.9611 | 5.6014 | 0.9533 | 0.9495 | 3.8730 | 0.9291 | 0.9141 | 4.5252 | 29 M |
| NR | PW-360IQA | 0.9518 | 0.9507 | 4.4200 | 0.9716 | 0.9478 | 5.2499 | 0.9337 | 0.9385 | 4.8085 | 0.8818 | 0.8496 | 5.5504 | 7.4 M |
| All | JPEG | JP2K | WGN | BLUR | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ref. | Model | PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ |
| FR | PSNR | 0.6910 | 0.6802 | 10.388 | 0.8658 | 0.8291 | 7.8570 | 0.8492 | 0.8421 | 7.9357 | 0.9317 | 0.9008 | 4.6392 | 0.6357 | 0.6374 | 10.250 |
| FR | SSIM | 0.8892 | 0.8798 | 6.5814 | 0.9409 | 0.9346 | 5.3193 | 0.9336 | 0.9357 | 5.3829 | 0.9026 | 0.8846 | 5.4965 | 0.9188 | 0.9238 | 5.2404 |
| NR | BRISQUE | 0.8424 | 0.8331 | 11.261 | 0.9160 | 0.9392 | 8.9920 | 0.7397 | 0.6750 | 15.082 | 0.9553 | 0.9372 | 3.4270 | 0.8663 | 0.8508 | 9.6970 |
| FR | S-PSNR | 0.7153 | 0.7115 | 10.052 | 0.8703 | 0.8285 | 7.7319 | 0.8555 | 0.8489 | 7.7811 | 0.9190 | 0.8846 | 5.0329 | 0.6929 | 0.6917 | 9.5736 |
| FR | WS-PSNR | 0.6985 | 0.6932 | 10.294 | 0.8607 | 0.8278 | 7.9919 | 0.8435 | 0.8322 | 8.0719 | 0.9221 | 0.8853 | 4.9415 | 0.6609 | 0.6583 | 9.9652 |
| NR | SSP-BOIQA | 0.8600 | 0.8650 | 7.3131 | 0.8772 | 0.8345 | 7.6201 | 0.8532 | 0.8522 | 7.5013 | 0.9054 | 0.8434 | 5.4510 | 0.8544 | 0.8623 | 6.8342 |
| NR | MC360IQA | 0.9247 | 0.9187 | 4.6247 | 0.9279 | 0.9190 | 4.5058 | 0.9324 | 0.9252 | 4.5825 | 0.9344 | 0.9345 | 3.7908 | 0.9220 | 0.9353 | 4.5256 |
| NR | Zhou et al. | 0.8991 | 0.9232 | 6.3963 | 0.9363 | 0.9405 | 5.6911 | 0.9200 | 0.9343 | 5.8862 | 0.9682 | 0.9570 | 3.3304 | 0.9252 | 0.9200 | 4.9721 |
| NR | PW-360IQA | 0.9135 | 0.9155 | 5.7900 | 0.9585 | 0.9107 | 3.9219 | 0.9398 | 0.9107 | 5.4711 | 0.9196 | 0.8929 | 4.9893 | 0.9232 | 0.9386 | 5.3673 |
| Weights Sharing | VFE | MLP | JND | CVIQ | OIQA | Complexity | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| PLCC↑ | SRCC↑ | RMSE↓ | PLCC↑ | SRCC↑ | RMSE↓ | # Params↓ | ||||
| No | ✓ | ✗ | ✗ | 0.9261 | 0.8988 | 4.4364 | 0.8819 | 0.8886 | 6.6685 | 58.3 M |
| ✓ | ✓ | ✗ | 0.9473 | 0.9409 | 4.5000 | 0.8884 | 0.8913 | 6.4900 | 58.4 M | |
| ✓ | ✗ | ✓ | 0.9423 | 0.9214 | 4.7900 | 0.8914 | 0.8920 | 6.4100 | 59.3 M | |
| ✓ | ✓ | ✓ | 0.9372 | 0.9274 | 4.9600 | 0.8989 | 0.8865 | 6.2000 | 59.3 M | |
| Yes | ✓ | ✓ | ✓ | 0.9518 | 0.9507 | 4.4200 | 0.9135 | 0.9155 | 5.7900 | 7.4 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sendjasni, A.; Larabi, M.-C. PW-360IQA: Perceptually-Weighted Multichannel CNN for Blind 360-Degree Image Quality Assessment. Sensors 2023, 23, 4242. https://doi.org/10.3390/s23094242
Sendjasni A, Larabi M-C. PW-360IQA: Perceptually-Weighted Multichannel CNN for Blind 360-Degree Image Quality Assessment. Sensors. 2023; 23(9):4242. https://doi.org/10.3390/s23094242
Chicago/Turabian StyleSendjasni, Abderrezzaq, and Mohamed-Chaker Larabi. 2023. "PW-360IQA: Perceptually-Weighted Multichannel CNN for Blind 360-Degree Image Quality Assessment" Sensors 23, no. 9: 4242. https://doi.org/10.3390/s23094242
APA StyleSendjasni, A., & Larabi, M. -C. (2023). PW-360IQA: Perceptually-Weighted Multichannel CNN for Blind 360-Degree Image Quality Assessment. Sensors, 23(9), 4242. https://doi.org/10.3390/s23094242