A Hybrid Rule-Based and Machine Learning System for Arabic Check Courtesy Amount Recognition


Abstract
:1. Introduction
2. Related Work
3. A System for Arabic Check Courtesy Amount Recognition
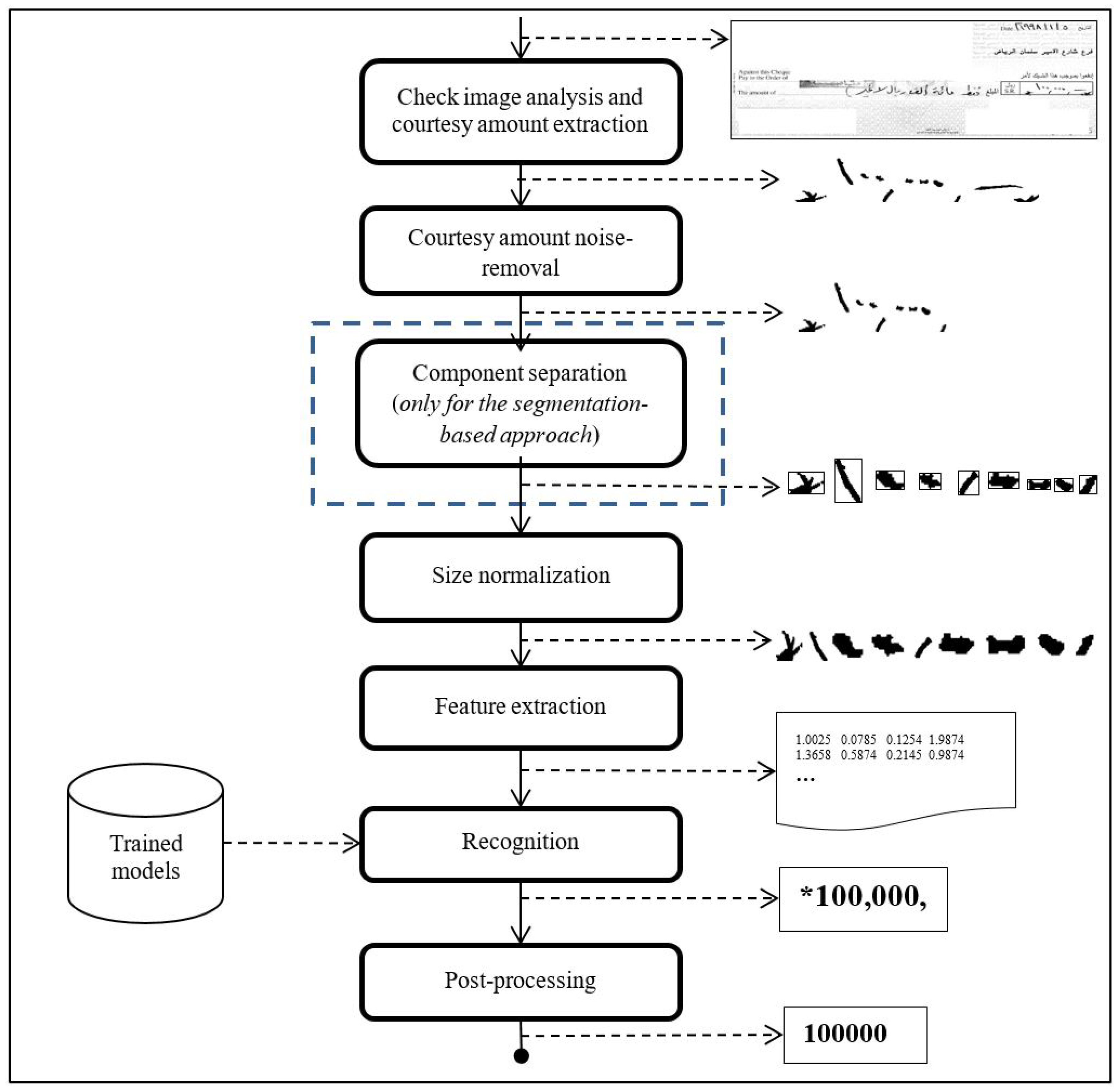
3.1. Check Image Analysis and Courtesy Amount Extraction
| Algorithm 1 Skew Correction and Courtesy Amount Extraction |
Input: scanned check image Output: courtesy amount region
|
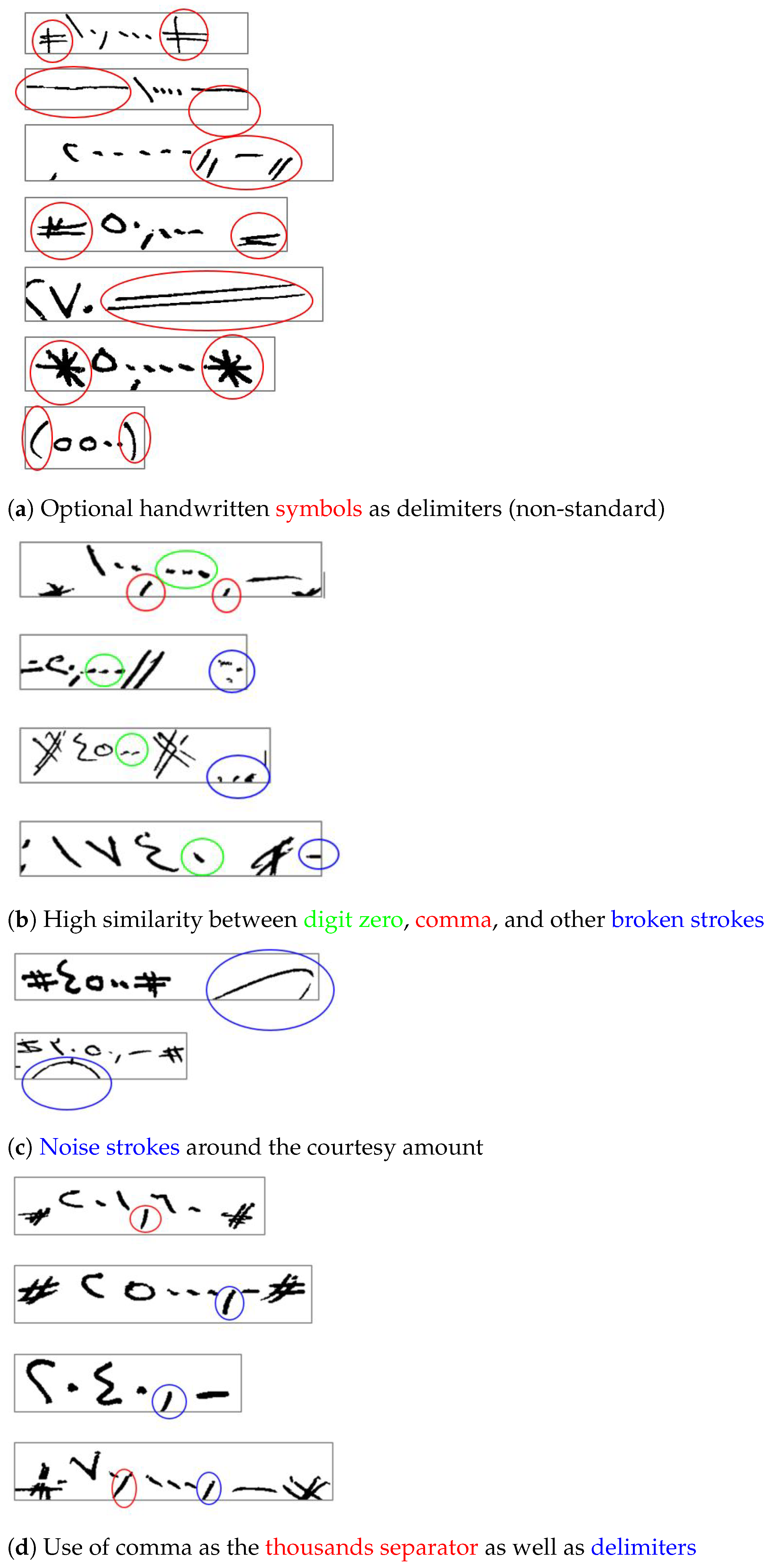
3.2. Preprocessing Courtesy Amount
| Algorithm 2 Preprocessing Courtesy Amount |
Input: courtesy amount image Output: size-normalized image(s)
|
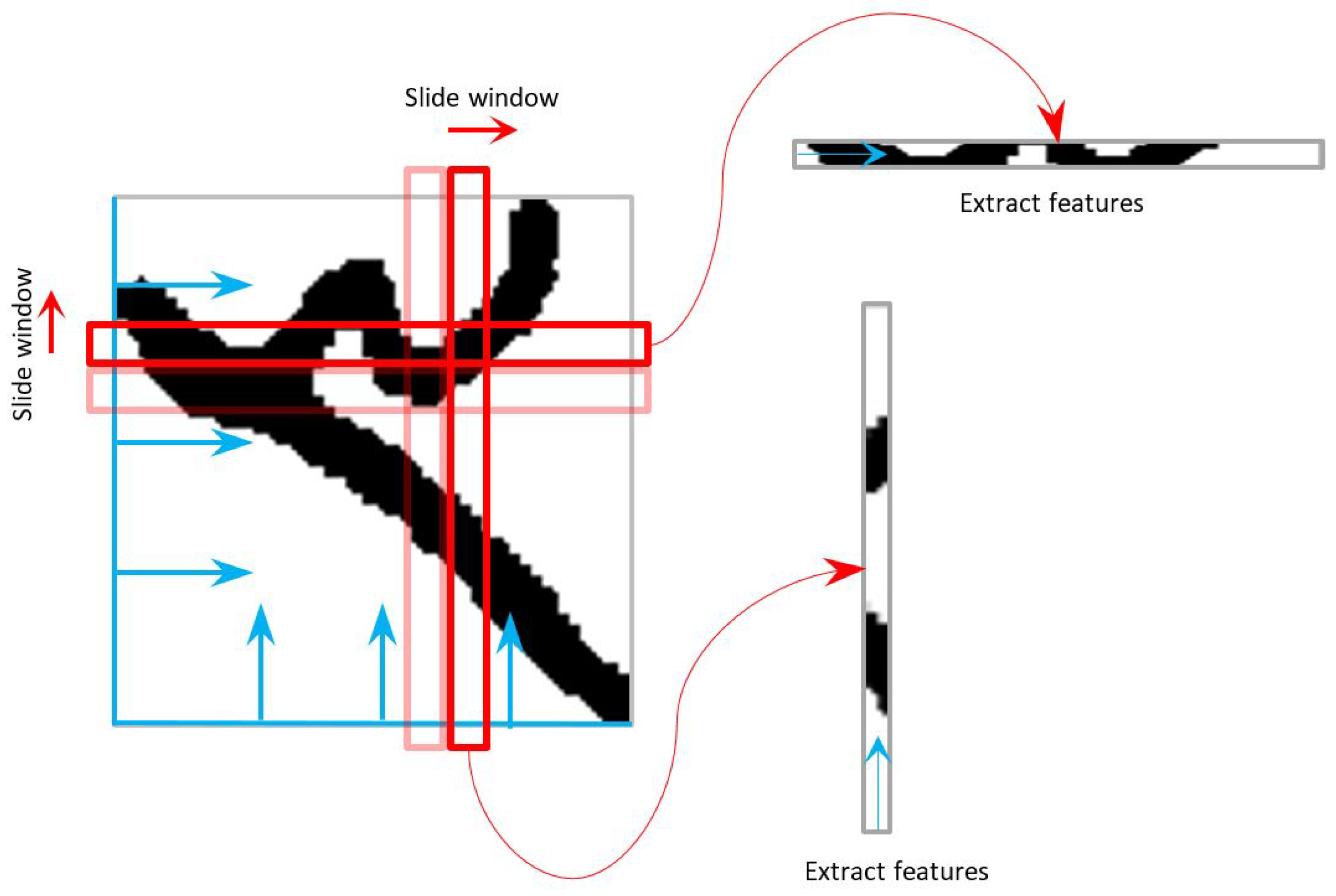
3.3. Feature Extraction
| Algorithm 3 Sliding Window and Feature Extraction |
Input: size-normalized images, width W of the sliding window Output: extracted features from the images
|
3.4. Classifier Training and Courtesy Amount Recognition
3.5. Postprocessing
4. Experiments, Results, and Discussion
4.1. Dataset
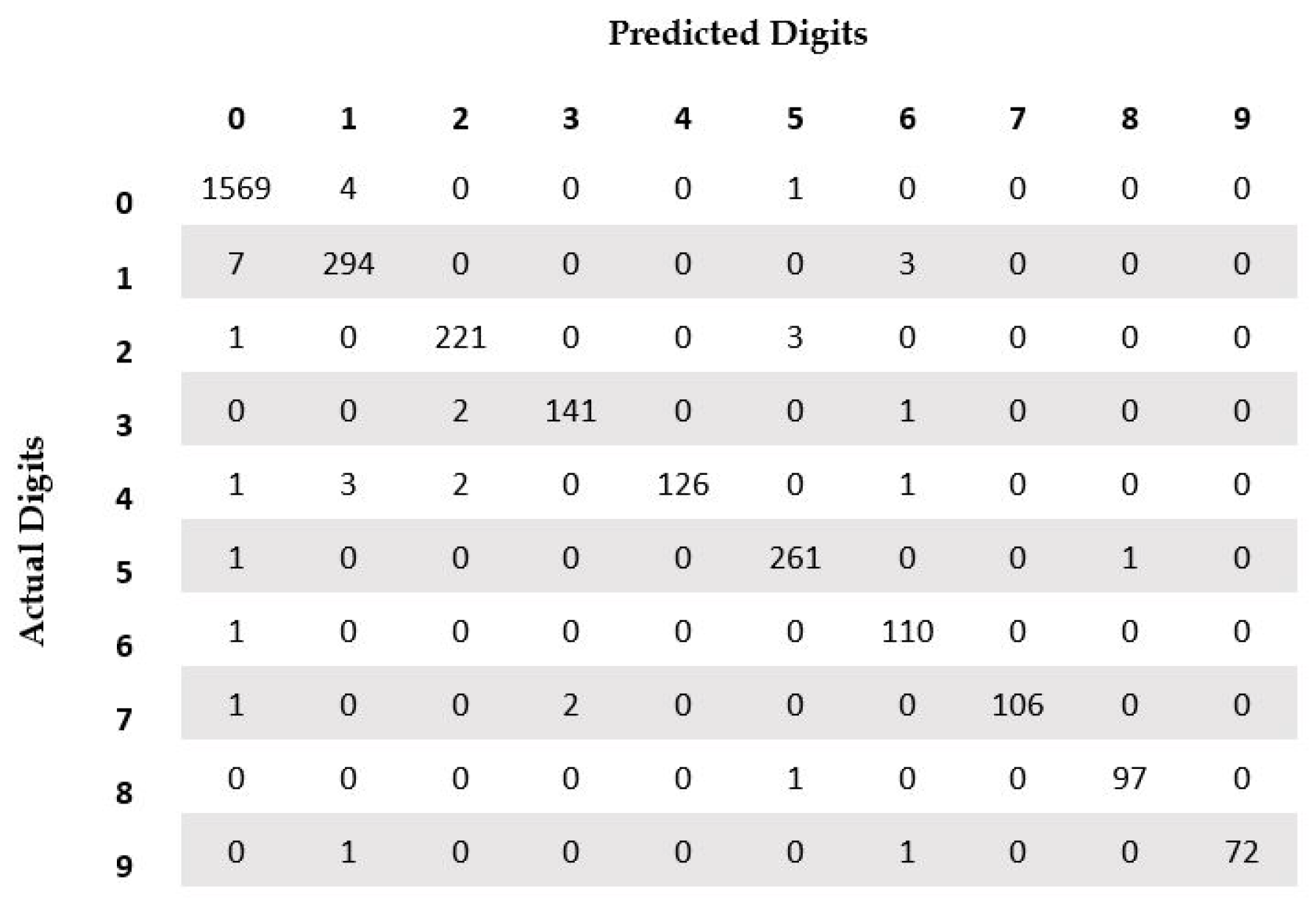
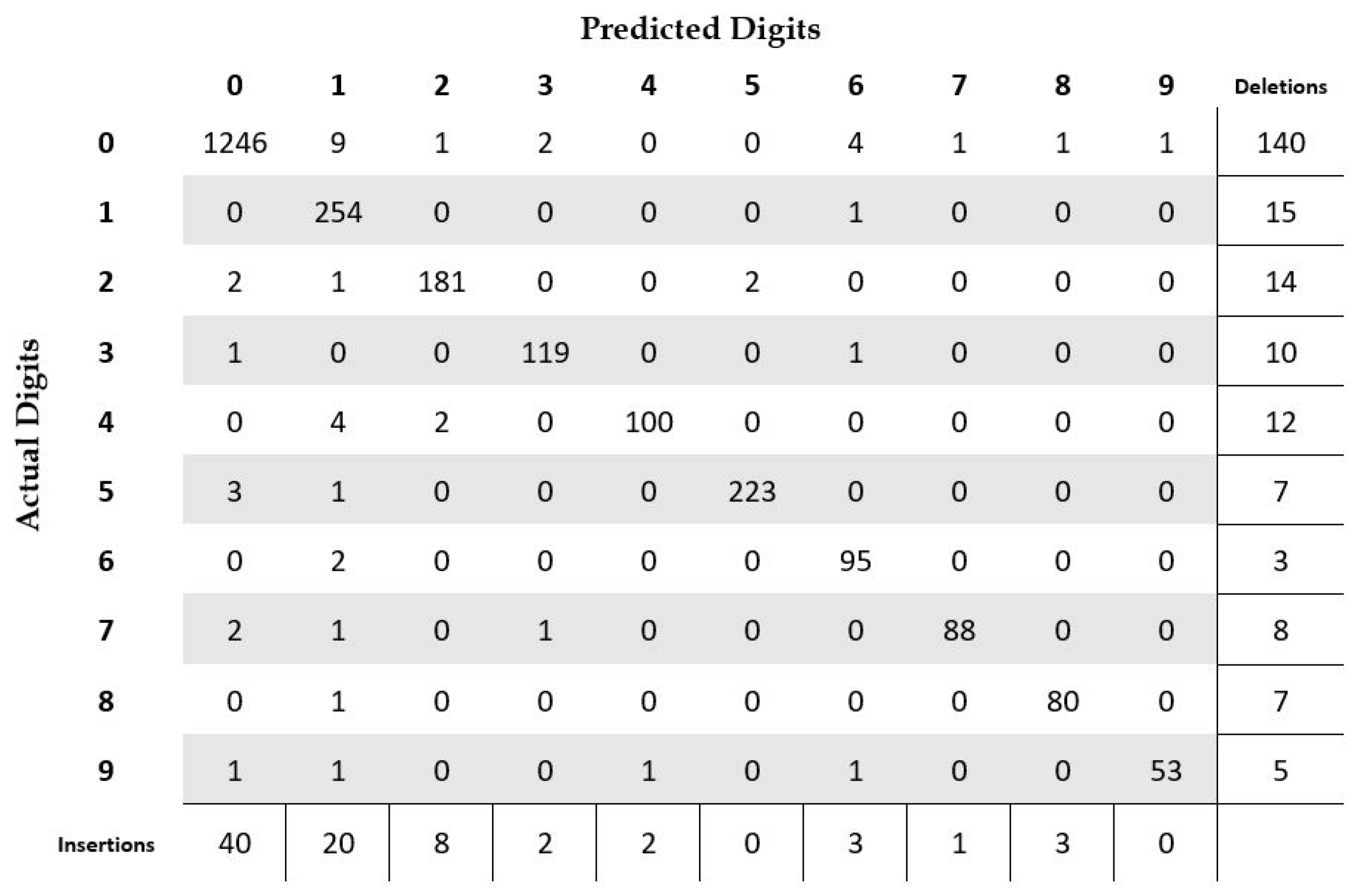
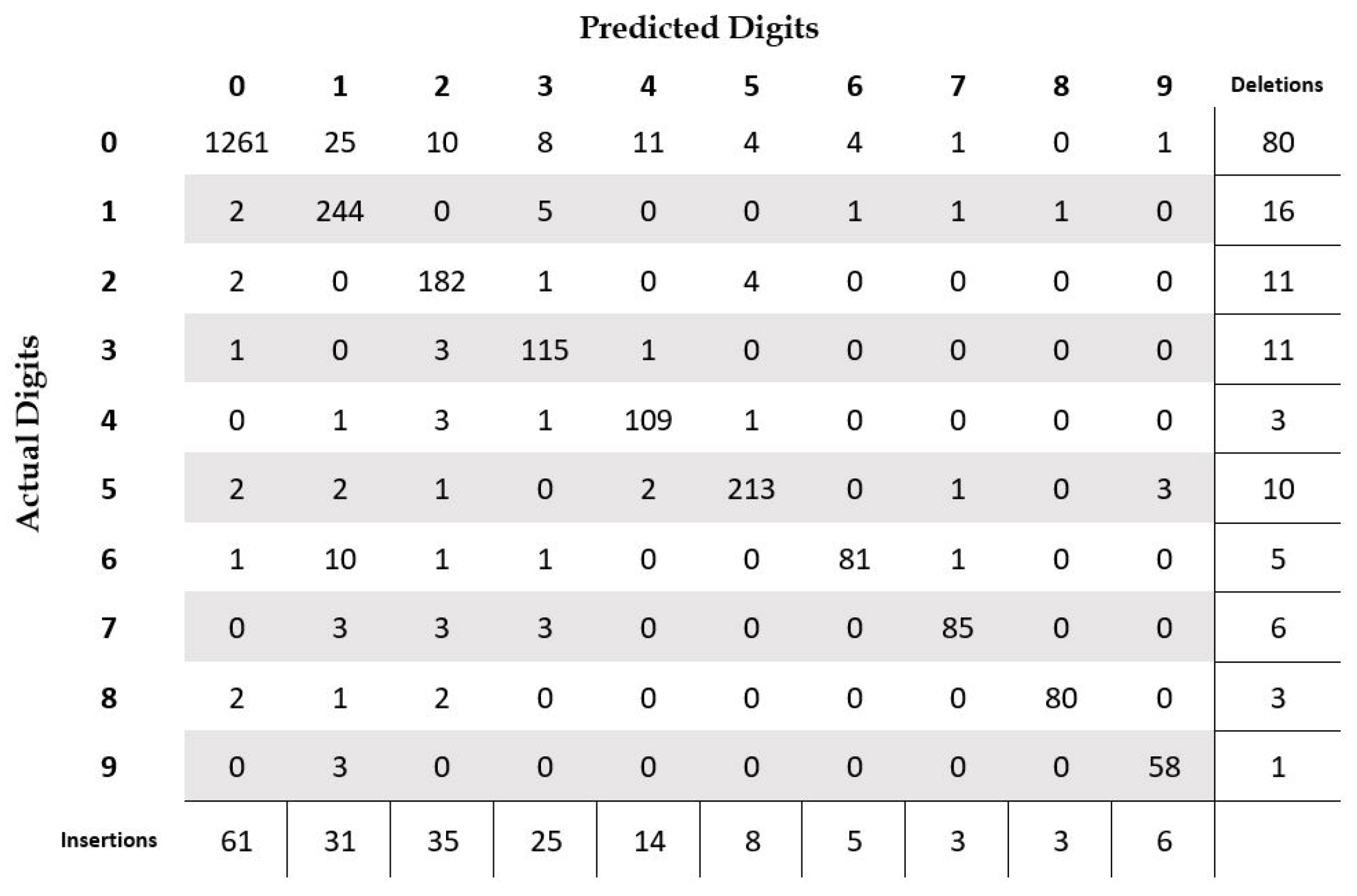
4.2. Isolated Digit Recognition
4.3. Segmentation-Based Courtesy Amount Recognition
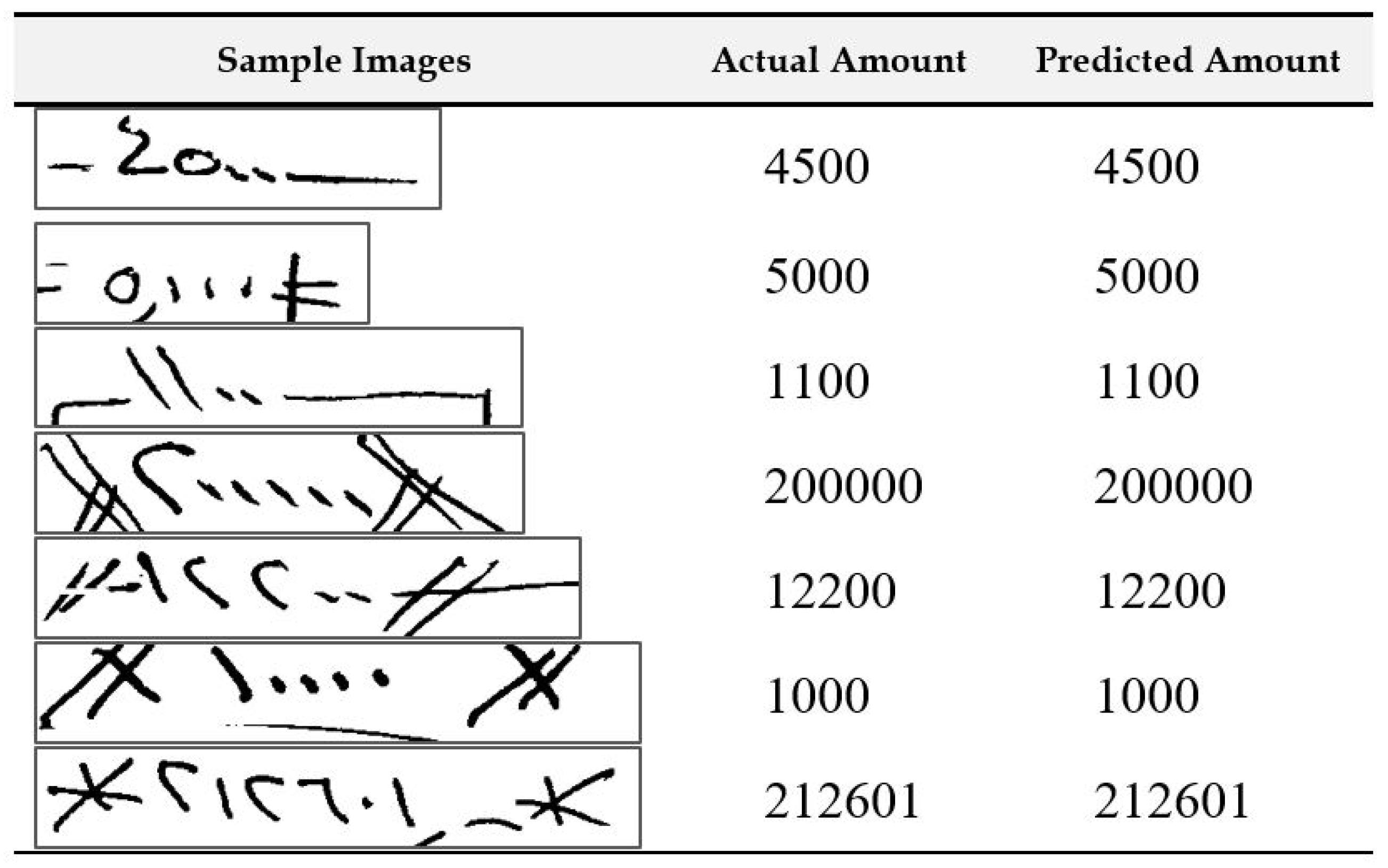
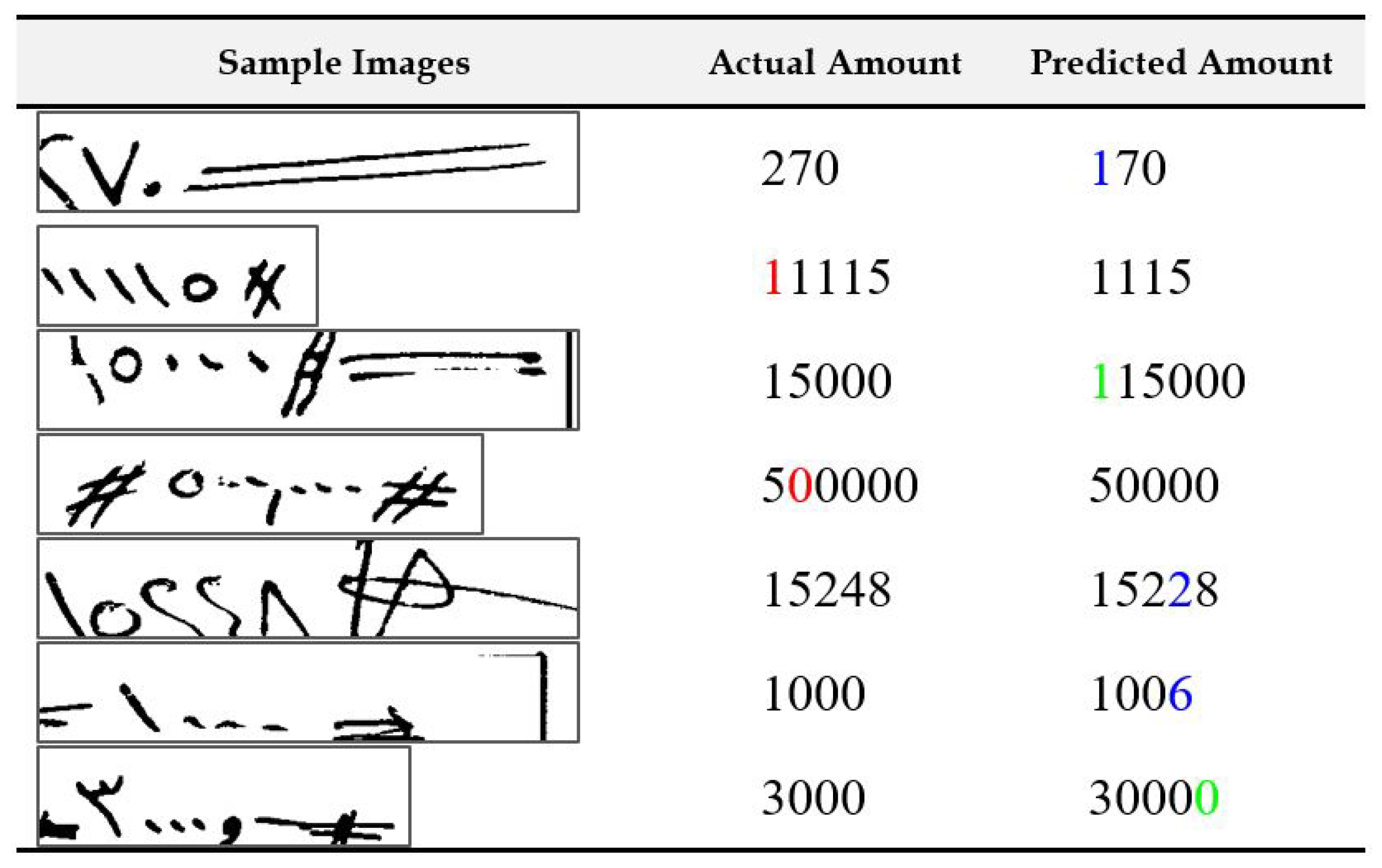
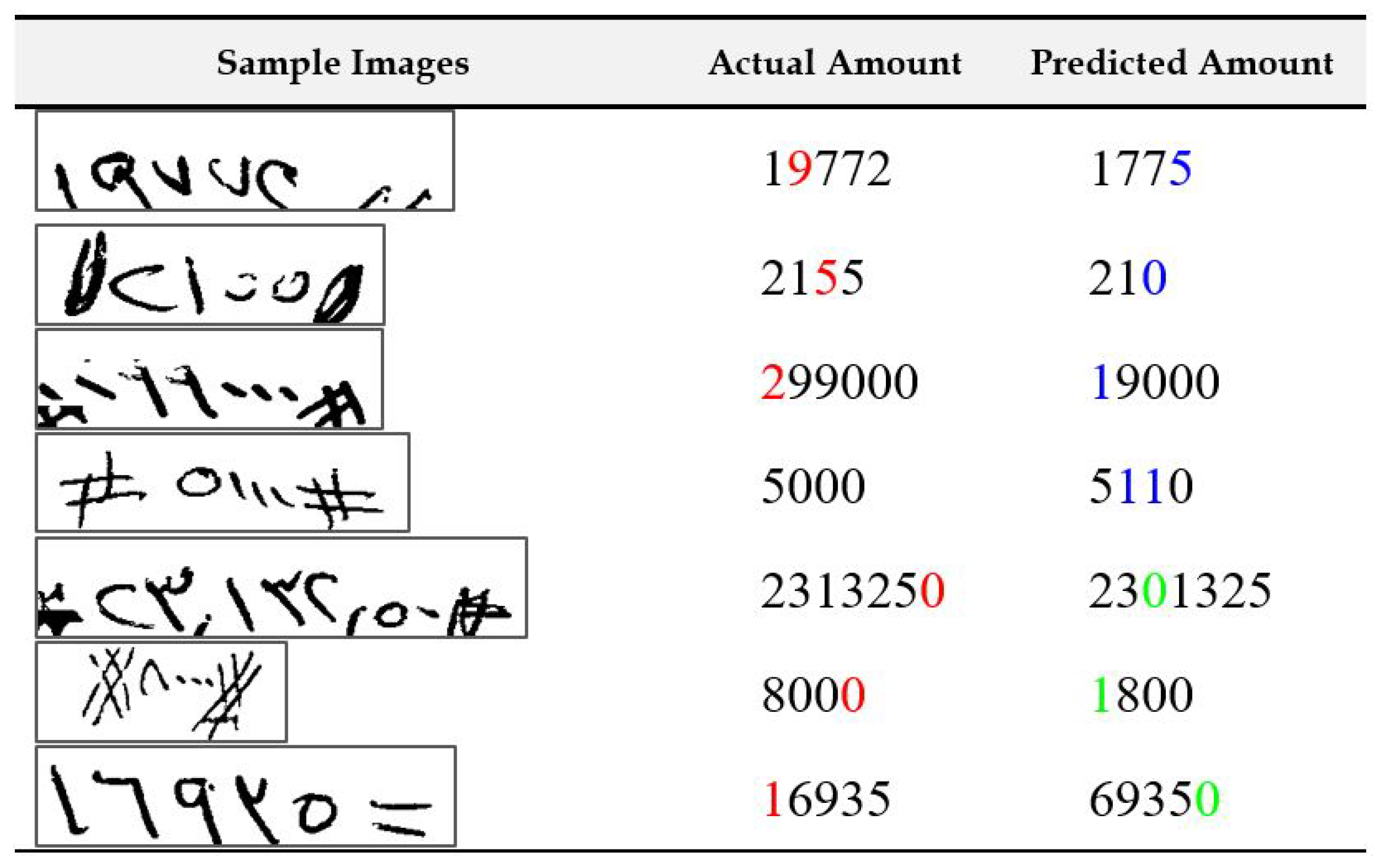
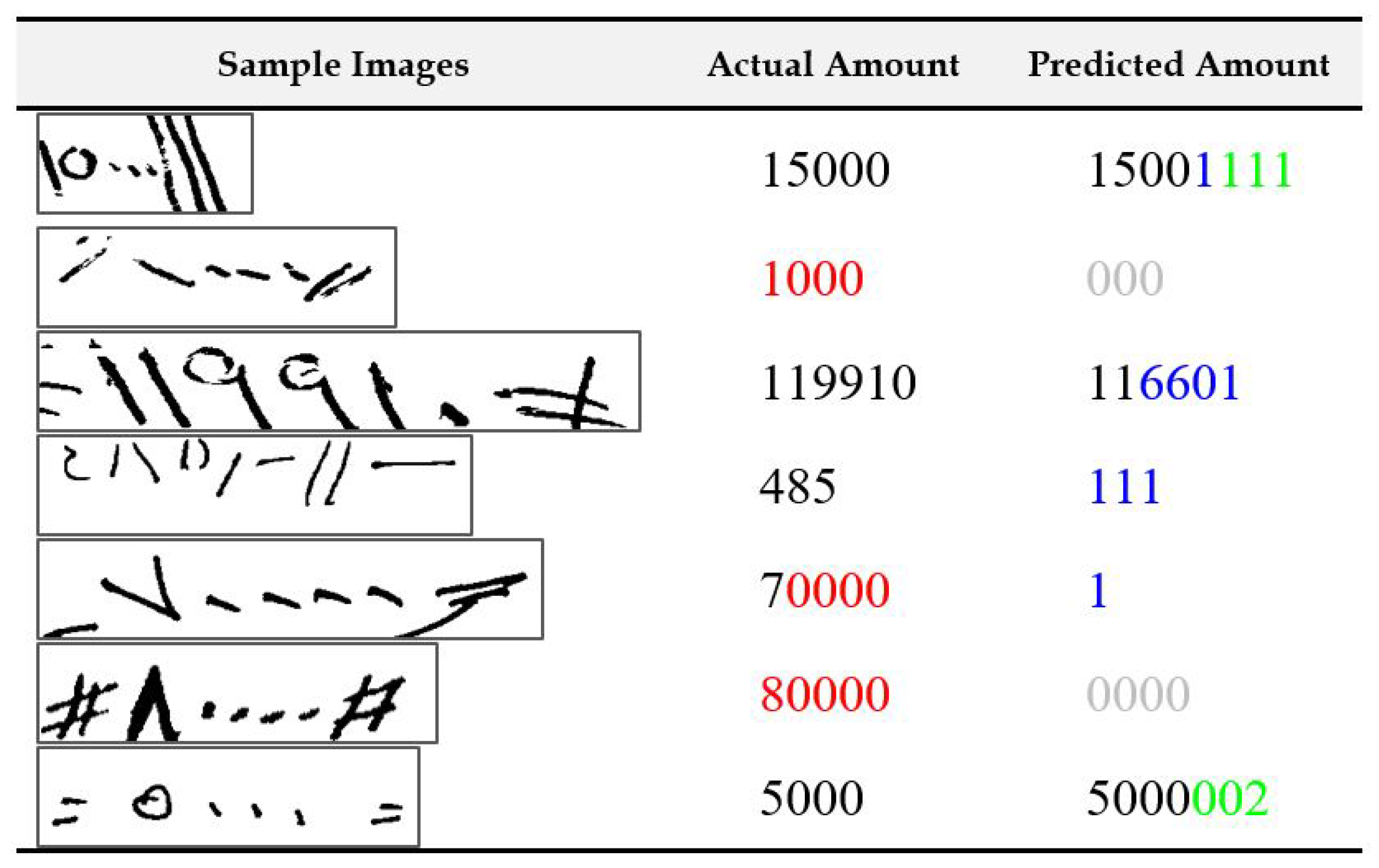
4.4. Result Analysis
4.5. Segmentation-Free Courtesy Amount Recognition
5. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Akana, T. Consumer Payment Preferences and the Impact of Technology and Regulation: Insights from the Visa Payment Panel Study. In The Routledge Handbook of FinTech; Liaw, K.T., Ed.; Routledge: New York, NY, USA, 2021; Chapter 16; pp. 305–321. [Google Scholar]
- Pymnts.com. Making Checks Part of the B2B Payments Modernization Plan. 2021. Available online: https://www.pymnts.com/news/b2b-payments/2021/making-checks-part-of-the-b2b-payments-modernization-plan/ (accessed on 8 February 2022).
- Palacios, R.; Gupta, A. A system for processing handwritten bank checks automatically. Image Vis. Comput. 2008, 26, 1297–1313. [Google Scholar] [CrossRef]
- Leroux, M.; Lethelier, E.; Gilloux, M.; Lemarié, B. Automatic reading of handwritten amounts on French checks. Int. J. Pattern Recognit. Artif. Intell. 1997, 11, 619–638. [Google Scholar] [CrossRef]
- Knerr, S.; Anisimov, V.; Baret, O.; Gorski, N.; Price, D.; Simon, J.C. The A2iA intercheque system: Courtesy amount and legal amount recognition for French checks. Int. J. Pattern Recognit. Artif. Intell. 1997, 11, 505–548. [Google Scholar] [CrossRef]
- Kaufmann, G.; Bunke, H. Automated reading of cheque amounts. Pattern Anal. Appl. 2000, 3, 132–141. [Google Scholar] [CrossRef]
- Yu, M.; Kwok, P.C.; Leung, C.H.; Tse, K. Segmentation and recognition of Chinese bank check amounts. Int. J. Doc. Anal. Recognit. 2001, 3, 207–217. [Google Scholar] [CrossRef]
- Tang, H.; Augustin, E.; Suen, C.Y.; Baret, O.; Cheriet, M. Recognition of unconstrained legal amounts handwritten on Chinese bank checks. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 23–26 August 2004; Volume 2, pp. 610–613. [Google Scholar]
- Tang, H.; Augustin, E.; Suen, C.Y.; Baret, O.; Cheriet, M. Spiral recognition methodology and its application for recognition of Chinese bank checks. In Proceedings of the Ninth International Workshop on Frontiers in Handwriting Recognition, Tokyo, Japan, 26–29 October 2004; pp. 263–268. [Google Scholar]
- de Almendra Freitas, C.O.; El Yacoubi, A.; Bortolozzi, F.; Sabourin, R. Brazilian bank check handwritten legal amount recognition. In Proceedings of the 13th Brazilian Symposium on Computer Graphics and Image Processing (Cat. No. PR00878), Gramado, Brazil, 17–20 October 2000; pp. 97–104. [Google Scholar]
- Palacios, R.; Sinha, A.; Gupta, A. Automatic Processing of Brazilian Bank Checks. 2002. Available online: https://repositorio.comillas.edu/jspui/bitstream/11531/14134/1/IIT-02-065A.pdf (accessed on 8 February 2022).
- Raghavendra, S.; Danti, A. A novel recognition of Indian bank cheques using feed forward neural network. In Computational Intelligence in Data Mining—Volume 2; Springer: New Delhi, India, 2016; pp. 71–79. [Google Scholar]
- Agrawal, P.; Chaudhary, D.; Madaan, V.; Zabrovskiy, A.; Prodan, R.; Kimovski, D.; Timmerer, C. Automated bank cheque verification using image processing and deep learning methods. Multimed. Tools Appl. 2021, 80, 5319–5350. [Google Scholar] [CrossRef]
- Jayadevan, R.; Kolhe, S.R.; Patil, P.M.; Pal, U. Automatic processing of handwritten bank cheque images: A survey. Int. J. Doc. Anal. Recognit. 2012, 15, 267–296. [Google Scholar] [CrossRef]
- Hochuli, A.G.; Britto, A.S., Jr.; Saji, D.A.; Saavedra, J.M.; Sabourin, R.; Oliveira, L.S. A comprehensive comparison of end-to-end approaches for handwritten digit string recognition. Expert Syst. Appl. 2021, 165, 114196. [Google Scholar] [CrossRef]
- Alkhawaldeh, R.S. Arabic (Indian) digit handwritten recognition using recurrent transfer deep architecture. Soft Comput. 2021, 25, 3131–3141. [Google Scholar] [CrossRef]
- Alkhawaldeh, R.S.; Alawida, M.; Alshdaifat, N.F.F.; Alma’aitah, W.; Almasri, A. Ensemble deep transfer learning model for Arabic (Indian) handwritten digit recognition. Neural Comput. Appl. 2022, 34, 705–719. [Google Scholar] [CrossRef]
- Oliveira, L.S.; Sabourin, R.; Bortolozzi, F.; Suen, C.Y. Automatic recognition of handwritten numerical strings: A recognition and verification strategy. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1438–1454. [Google Scholar] [CrossRef]
- Zanchettin, C.; Cavalcanti, G.D.; Dória, R.C.; Silva, E.F.; Rabelo, J.C.; Bezerra, B.L. A neural architecture to identify courtesy amount delimiters. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; pp. 3210–3217. [Google Scholar]
- Holi, G.; Jain, D.K. Convolutional neural network approach for extraction and recognition of digits from bank cheque images. In Emerging Research in Electronics, Computer Science and Technology; Springer: Singapore, 2019; pp. 331–341. [Google Scholar]
- Souici-Meslati, L.; Sellami, M. A Hybrid Approach for Arabic Literal Amounts Recognition. Arab. J. Sci. Eng. (Springer Sci. Bus. Media BV) 2004, 29, 177–194. [Google Scholar]
- Farah, N.; Souici, L.; Sellami, M. Classifiers combination and syntax analysis for Arabic literal amount recognition. Eng. Appl. Artif. Intell. 2006, 19, 29–39. [Google Scholar] [CrossRef]
- Menasria, A.; Bennia, A.; Nemissi, M.; Sedraoui, M. Multiclassifiers system for handwritten Arabic literal amounts recognition based on enhanced feature extraction model. J. Electron. Imaging 2018, 27, 033024. [Google Scholar] [CrossRef]
- Bhat, M.I.; Sharada, B. Automatic Recognition of Legal Amount Words of Bank Cheques in Devanagari Script: An Approach Based on Information Fusion at Feature and Decision Level. In Proceedings of the International Conference on Recent Trends in Image Processing and Pattern Recognition, Solapur, India, 21–22 December 2018; Springer: Singapore, 2018; pp. 96–107. [Google Scholar]
- Ahmad, I.; Awaida, S.; Mahmoud, S.A. Arabic literal amount sub-word recognition using multiple features and classifiers. Int. J. Appl. Pattern Recognit. 2020, 6, 103–123. [Google Scholar] [CrossRef]
- Morita, M.E.; Letelier, E.; El Yacoubi, A.; Bortolozzi, F.; Sabourin, R. Recognition of handwritten dates on bank checks using an HMM approach. In Proceedings of the 13th Brazilian Symposium on Computer Graphics and Image Processing (Cat. No. PR00878), Gramado, Brazil, 17–20 October 2000; pp. 113–120. [Google Scholar]
- Zhang, C.; Li, W. Recognizing handwritten Chinese day and month words by combining a holistic method and a segmentation-based method. Neural Comput. Appl. 2013, 23, 1661–1668. [Google Scholar] [CrossRef]
- Culqui-Culqui, G.; Sanchez-Gordon, S.; Hernández-Álvarez, M. An Algorithm for Classifying Handwritten Signatures Using Convolutional Networks. IEEE Lat. Am. Trans. 2021, 20, 465–473. [Google Scholar] [CrossRef]
- Ahmad, I.; Mahmoud, S.A. Arabic bank check processing: State of the art. J. Comput. Sci. Technol. 2013, 28, 285–299. [Google Scholar] [CrossRef]
- Al-Ohali, Y.; Cheriet, M.; Suen, C. Databases for recognition of handwritten Arabic cheques. Pattern Recognit. 2003, 36, 111–121. [Google Scholar] [CrossRef]
- Sadri, J.; Suen, C.Y.; Bui, T.D. Application of support vector machines for recognition of handwritten Arabic/Persian digits. In Proceedings of the Second Iranian Conference on Machine Vision and Image Processing, Tehran, Iran, 21 January 2003; Volume 1, pp. 300–307. [Google Scholar]
- Akbari, Y.; Jalili, M.J.; Sadri, J.; Nouri, K.; Siddiqi, I.; Djeddi, C. A novel database for automatic processing of Persian handwritten bank checks. Pattern Recognit. 2018, 74, 253–265. [Google Scholar] [CrossRef]
- Juan, A.; Vidal, E. Bernoulli mixture models for binary images. In Proceedings of the 17th International Conference on Pattern Recognition—ICPR 2004, Cambridge, UK, 23–26 August 2004; Volume 3, pp. 367–370. [Google Scholar]
- Cheriet, M.; Al-Ohali, Y.; Ayat, N.; Suen, C.Y. Arabic cheque processing system: Issues and future trends. In Digital Document Processing; Springer: London, UK, 2007; pp. 213–234. [Google Scholar]
- Alamri, H.; He, C.L.; Suen, C.Y. A new approach for segmentation and recognition of Arabic handwritten touching numeral pairs. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Munster, Germany, 2–4 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 165–172. [Google Scholar]
- Mahmoud, S.A.; Al-Khatib, W.G. Recognition of Arabic (Indian) bank check digits using log-gabor filters. Appl. Intell. 2011, 35, 445–456. [Google Scholar] [CrossRef]
- Mahmoud, S.A. Recognition of Arabic (Indian) check digits using spatial gabor filters. In Proceedings of the 2009 5th IEEE GCC Conference & Exhibition, Kuwait City, Kuwait, 17–19 March 2009; pp. 1–5. [Google Scholar]
- Giménez, A.; Andrés-Ferrer, J.; Juan, A.; Serrano, N. Discriminative bernoulli mixture models for handwritten digit recognition. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 558–562. [Google Scholar]
- Awaida, S.M.; Mahmoud, S.A. Automatic check digits recognition for Arabic using multi-scale features, HMM and SVM classifiers. J. Adv. Math. Comput. Sci. 2014, 4, 2521–2535. [Google Scholar] [CrossRef] [PubMed]
- Assayony, M.O.; Mahmoud, S.A. An Enhanced Bag-of-Features Framework for Arabic Handwritten Sub-words and Digits Recognition. J. Pattern Recognit. Intell. Syst. 2016, 4, 27–38. [Google Scholar]
- Ahmad, I. Performance of Classifiers on Noisy-Labeled Training Data: An Empirical Study on Handwritten Digit Classification Task. In Proceedings of the Advances in Computational Intelligence; Rojas, I., Joya, G., Catala, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 414–425. [Google Scholar]
- Villena-Román, J.; Collada-Pérez, S.; Lana-Serrano, S.; González-Cristóbal, J.C. Hybrid approach combining machine learning and a rule-based expert system for text categorization. In Proceedings of the Twenty-Fourth International FLAIRS Conference, Palm Beach, FL, USA, 18–20 May 2011. [Google Scholar]
- Koopman, B.; Zuccon, G.; Nguyen, A.; Bergheim, A.; Grayson, N. Extracting cancer mortality statistics from death certificates: A hybrid machine learning and rule-based approach for common and rare cancers. Artif. Intell. Med. 2018, 89, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Al-Mashhadi, S.; Anbar, M.; Hasbullah, I.; Alamiedy, T.A. Hybrid rule-based botnet detection approach using machine learning for analysing DNS traffic. PeerJ Comput. Sci. 2021, 7, e640. [Google Scholar] [CrossRef]
- Ahmad, I.; Mahmoud, S.A. Arabic Bank Check Analysis and Zone Extraction. In Proceedings of the Image Analysis and Recognition; Campilho, A., Kamel, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 141–148. [Google Scholar]
- Wienecke, M.; Fink, G.A.; Sagerer, G. Toward automatic video-based whiteboard reading. Int. J. Doc. Anal. Recognit. 2005, 7, 188–200. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics New York; Springer: New York, NY, USA, 2001; Volume 2, 758p. [Google Scholar]
- Young, S.; Evermann, G.; Hain, T.; Kershaw, D.; Moore, G.; Odell, J.J.; Ollason, D.; Povey, D.; Valtchev, V.; Woodland, P. The HTK Book (for HTK Version 3.2.1); Cambridge University Engineering Department: Cambridge, UK, 2002. [Google Scholar]
- Ahmad, I.; Fink, G.A. Handwritten Arabic text recognition using multi-stage sub-core-shape HMMs. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 329–349. [Google Scholar] [CrossRef]
- Dietterich, T.G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef]
- Huang, X.; Acero, A.; Hon, H. A guide to Theory, Algorithm, and System Development. In Spoken Language Processing; Prentice-Hall: Hoboken, NJ, USA, 2001. [Google Scholar]
- Jaramillo, J.C.A.; Murillo-Fuentes, J.J.; Olmos, P.M. Boosting handwriting text recognition in small databases with transfer learning. In Proceedings of the 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 429–434. [Google Scholar]
- Eltay, M.; Zidouri, A.; Ahmad, I.; Elarian, Y. Generative adversarial network based adaptive data augmentation for handwritten Arabic text recognition. PeerJ Comput. Sci. 2022, 8, e861. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total number of samples | 626 |
| Average number of digits per sample | 4.3 |
| Median number of digits per sample | 4 |
| Number of digits in the shortest amount | 2 |
| Number of digits in the largest amount | 7 |
| Number of base learners (decision trees) | 200 |
| Number of features randomly selected at node splitting | 14 |
| Maximum depth of each decision tree | 50 |
| Minimum number of samples for splitting a node | 2 |
| Reference | System Description | Accuracy (%) | Statistical Significance |
|---|---|---|---|
| [31] | SVM with distance features | 94.14 | |
| [33] | Multivariate Bernoulli mixtures | ≈98.00 | |
| [34] | SVM with statistical and structural features | 98.18 | |
| [37] | KNN with spatial Gabor filters | 97.99 | |
| [35] | SVM with gradient features | 98.48 | |
| [36] | SVM with log Gabor features | 98.95 | |
| [38] | Log-linear model based on Bernoulli mixtures | 98.00 | |
| [39] | SVM with gradient, structural, and concavity features | 99.04 | |
| [40] | SVM with SIFT bag-of-features | 99.34 | |
| [41] | SVM with features from local geometries of pen strokes | 98.65 | |
| Present work | Random forest with statistical features on local geometry | 98.75 |
| Number of samples with no error (percentage) | 422 (67.4%) |
| Number of samples with only one error (percentage) | 125 (20%) |
| Number of samples with two errors (percentage) | 38 (6.1%) |
| Number of samples with three or more errors (percentage) | 41 (6.5%) |
| Accuracy | 87.15% |
| Total deletion errors (percentage) | 221 (8.2%) |
| Total insertion errors (percentage) | 79 (2.9%) |
| Total substitution errors (percentage) | 48 (1.8%) |
| Sliding window width | 4 pixels |
| Sliding window stride | 2 pixels |
| HMM topology | Bakis |
| Number of states per HMM | 14 |
| Number of mixtures per state | 12 |
| Number of samples with no error (percentage) | 333 (53.2%) |
| Number of samples with only one error (percentage) | 179 (28.6%) |
| Number of samples with two errors (percentage) | 66 (10.5%) |
| Number of samples with three or more errors (percentage) | 48 (7.7%) |
| Accuracy | 82.61% |
| Total deletion errors (percentage) | 146 (5.4%) |
| Total insertion errors (percentage) | 191 (7.1%) |
| Total substitution errors (percentage) | 134 (4.9%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, I. A Hybrid Rule-Based and Machine Learning System for Arabic Check Courtesy Amount Recognition. Sensors 2023, 23, 4260. https://doi.org/10.3390/s23094260
Ahmad I. A Hybrid Rule-Based and Machine Learning System for Arabic Check Courtesy Amount Recognition. Sensors. 2023; 23(9):4260. https://doi.org/10.3390/s23094260
Chicago/Turabian StyleAhmad, Irfan. 2023. "A Hybrid Rule-Based and Machine Learning System for Arabic Check Courtesy Amount Recognition" Sensors 23, no. 9: 4260. https://doi.org/10.3390/s23094260
APA StyleAhmad, I. (2023). A Hybrid Rule-Based and Machine Learning System for Arabic Check Courtesy Amount Recognition. Sensors, 23(9), 4260. https://doi.org/10.3390/s23094260