





Evaluation of Federated Learning in Phishing Email Detection
 , , ,
, , ,  , and
, and
Abstract
:1. Introduction
Our Contributions
- RQ1
- (Balanced data distribution) Could FL be applied to learn from distributed email repositories to achieve comparable performance to centralized learning (CL)?We developed deep-learning phishing email detection models based on FL and CL considering a balanced data distribution. Their performances demonstrated that FL achieved a comparable performance to CL. For example, (i) at epoch 45, THEMIS had 99.3% test accuracy in CL and 97.9% global test accuracy in FL with 5 clients; and (ii) at epoch 15, BERT had 96.2% test accuracy in CL and 96.1% global test accuracy in FL with 5 clients. The details are provided in Section 4.1.
- RQ2
- (Scalability) How would the number of clients affect FL performance and convergence?Our experiments considering a balanced data distribution suggested that, while keeping the same total email dataset, the convergence of the accuracy curve, and its maximum value was model dependent. We observed that THEMIS decreased by around 0.5% on global test accuracy at epoch 45 when increasing the number of clients from 2 to 5 in FL; however, BERT improved by around 0.6% on global test accuracy at epoch 15 when increasing the number of clients from 2 to 5. The details are provided in Section 4.1.
- RQ3
- (Communication overhead) What would the communication overhead be resulting from FL?FL had a communication overhead as a trade-off to privacy, and it was only dependent on the model size. For example, we quantified the overhead per global epoch per client for THEMIS at around 0.192 GB, and for BERT, at around 0.438 GB, for all cases in our settings. We regard such overheads as not of particular concern for organizational-level participants. The details are provided in Section 4.1.
- RQ4
- (Client-level perspectives in FL) Could a client leverage FL to improve its performance?We investigated client-level performances considering both balanced and asymmetrical data distributions in FL, including the cases where clients were available over time in the training process, and the total email dataset increased with the addition of new clients. A fast convergence in the accuracy curve was observed with THEMIS. The details are provided in Section 4.2.
- RQ5
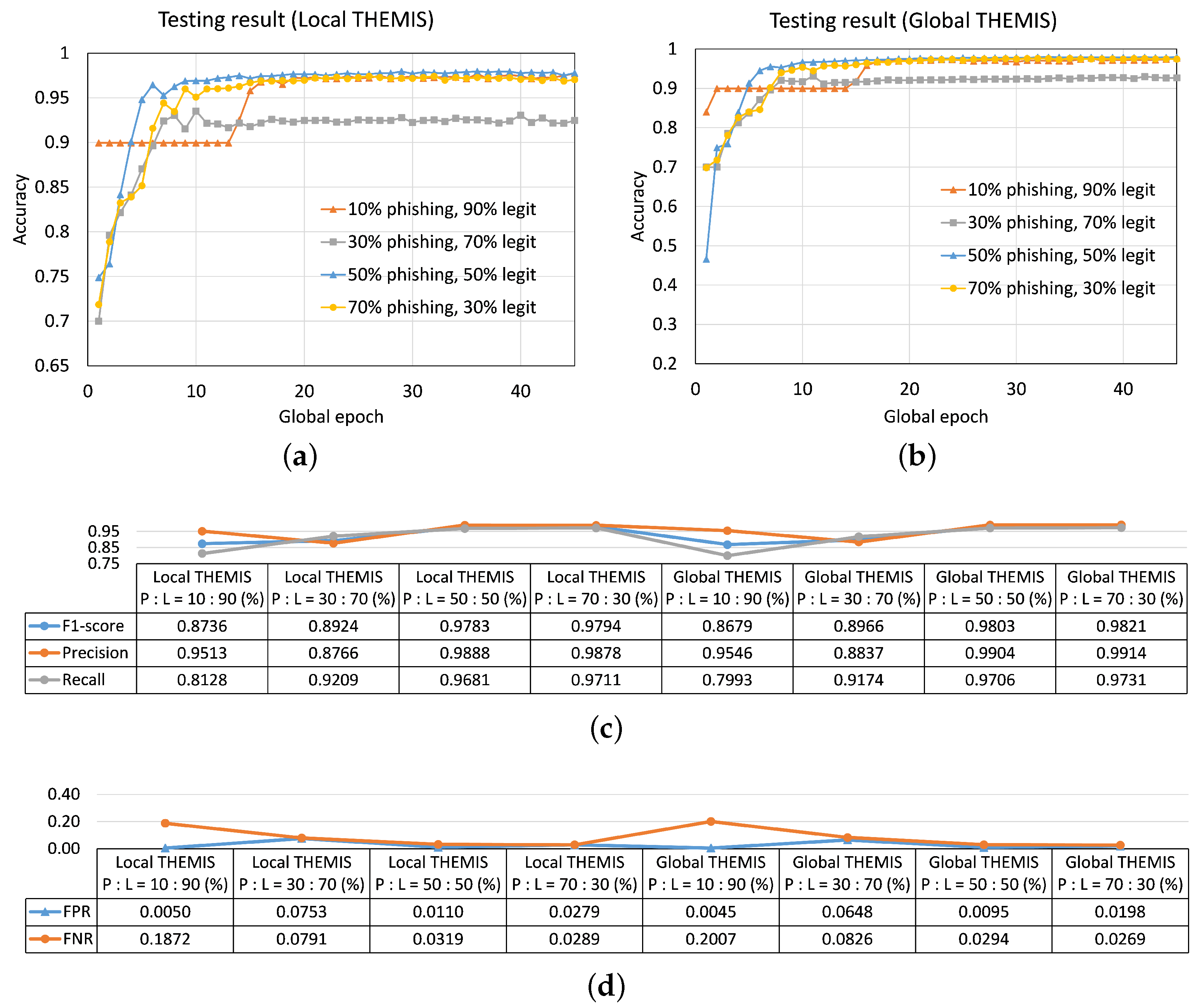
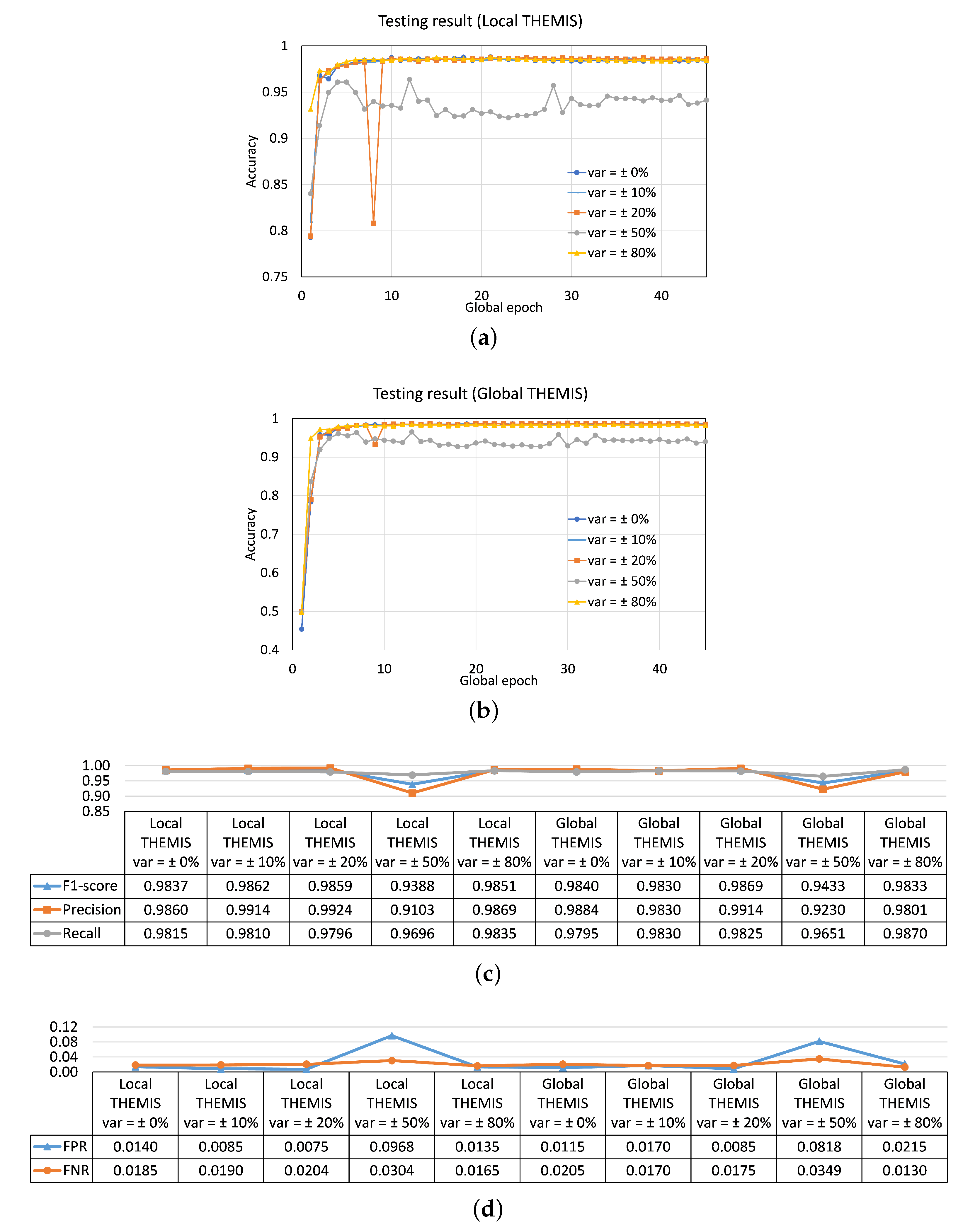
- (Asymmetric data distribution) How would FL perform considering asymmetric data distributions among clients due to the variations in local dataset sizes and local phishing to legitimate sample ratios?Our studies of THEMIS with 2, 5, and 10 clients demonstrated that FL performed well and similarly in asymmetric data distributions due to the differences in local dataset sizes and the local phishing to legitimate sample ratios. Therefore, FL was resilient in these scenarios. The details are provided in Section 4.3.
- RQ6
- (Asymmetric data distribution) How would FL perform under extreme dataset diversity among clients?Data asymmetry, in this case, was due to the class skewness and different dataset sizes (small to large) across the clients. Our studies illustrated that forming a best-performing global model for all clients under FL was not straightforward. In addition, the local and global performances were model dependent. The details are provided in Section 4.4.
2. Background
2.1. Centralized Learning
2.2. Federated Learning
| Algorithm 1: Federated learning |
 |
3. Experimental Setup
3.1. Datasets
- IWSPA-AP phishing emails (a) with header include “account”, “PayPal”, “please”, “eBay”, “link”, “security”, “update”, “bank”, “online”, and “information”; and (b) without header include “text”, “account”, “email”, “please”, “information”, “click”, “team”, “online”, and “security”. IWSPA-AP legitimate emails (a) with header include “email”, “please”, “new”, “sent”, “party”, “people”, “Donald”, “state”, and “president”; and (b) without header include “text”, “link”, “national”, “US”, “Trump”, and “democratic”.
- Nazario includes “important”, “account”, “update”, “please”, “email”, “security”, “PayPal”, “eBay”, “bank”, “access”, “information”, “item”, “click”, “confirm”, and “service”.
- Enron includes “text”, “plain”, “subject”, “please”, “email”, “power”, “image”, “time”, “know”, “this”, “message”, “information”, and “energy”.
- CSIRO includes “shopping”, “parcel”, “invitation”, “payment”, “employee”, “webinar”, “survey”, “newsletter”, “program”, and “workshop”.
- Phishbowl includes “account”, “id”, “password”, “Cornell”, “upgrade”, “notice”, “administrator”, “message”, “job”, “server”, and “verify”.
3.2. Deep Learning Model Selection
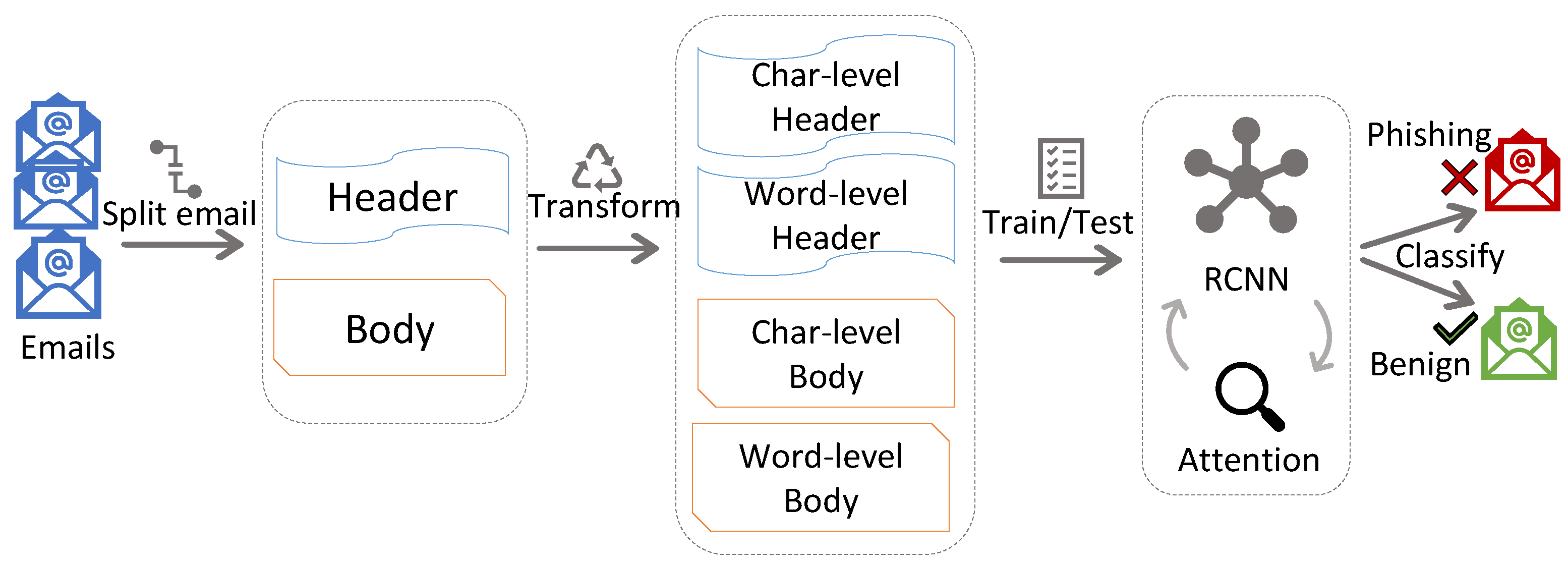
3.2.1. THEMIS
Overview of THEMIS
3.2.2. Bidirectional Encoder Representations from Transformers
Overview of BERT
3.3. Data Preparation
3.3.1. Extraction of Header and Body
3.3.2. Cleaning of the Extracted Header and Body
3.3.3. Tokenization
3.4. Experimental Steps
4. Results
4.1. Distributed Email Learning with Balanced Data Distribution



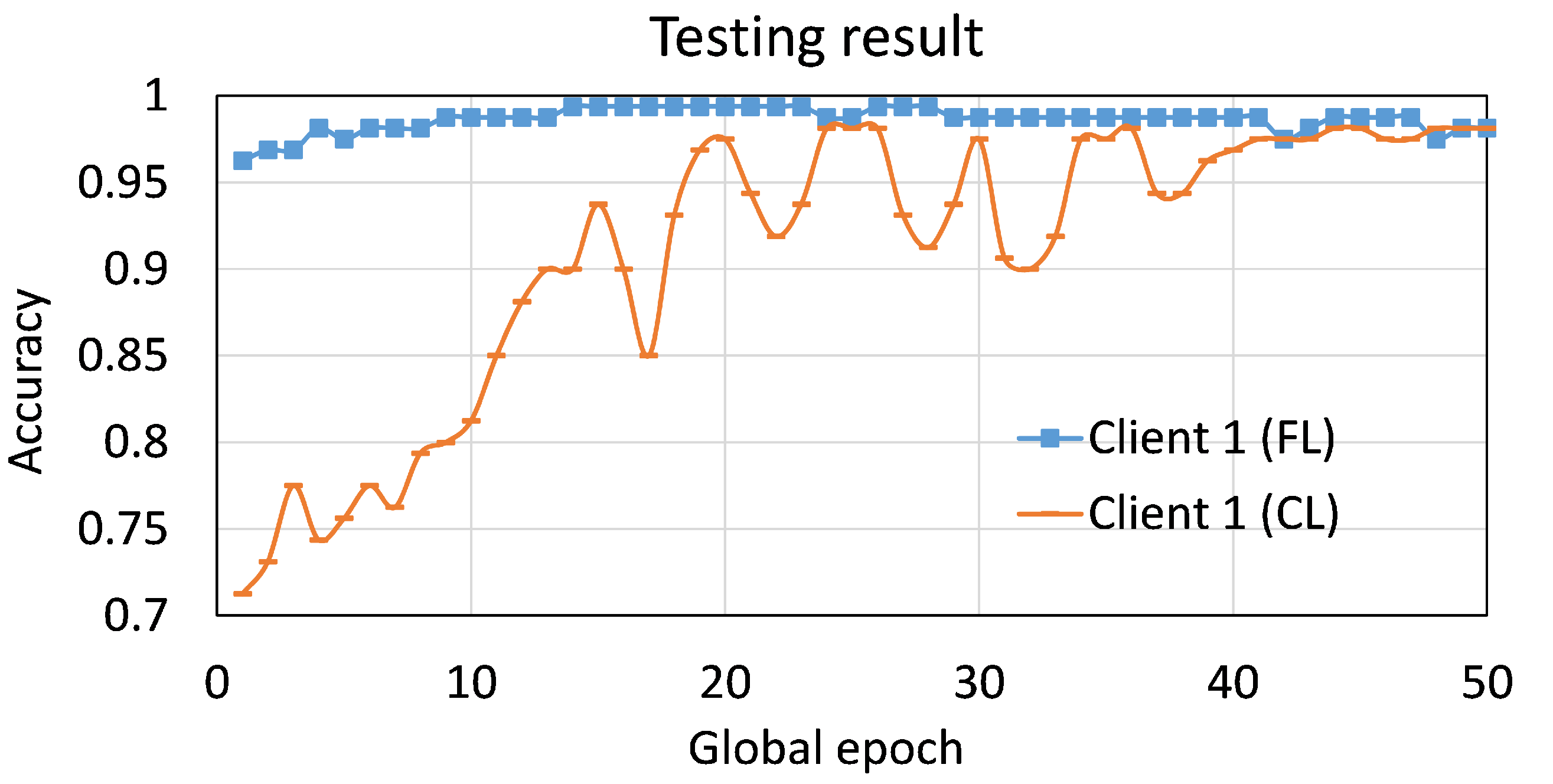
4.2. Client-Level Perspectives in Federated Learning
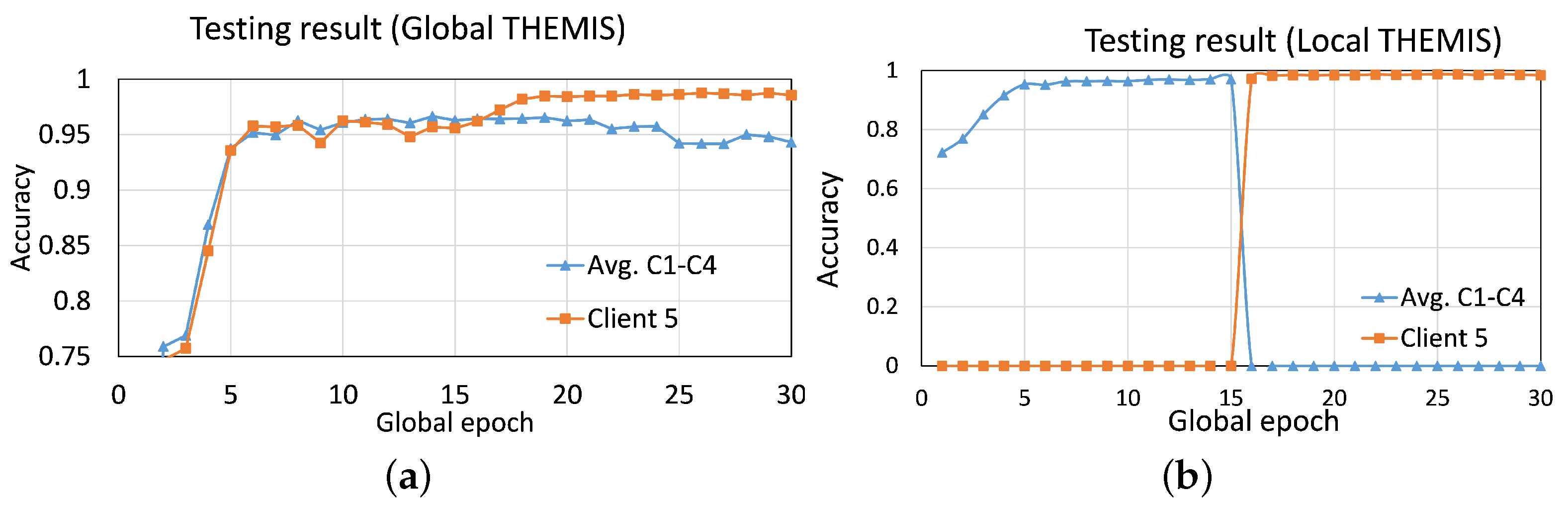
4.2.1. Experiment 1: A Client-Level and Overall Effects of Adding One New Client in FL
4.2.2. Experiment 2: A Client-Level and Overall Effects of Continuously Adding New Clients in FL
4.2.3. Experiment 3: Benefits to the Newly Participated Client in the FL Learning Process

4.3. Distributed Email Learning under Asymmetric Data Distribution
4.3.1. Same P/L Ratio across Clients but Having Different Sizes of the Local Dataset
4.3.2. Different Legit Email to Phishing Email Sample Ratio across Clients but Having the Same Sizes of the Local Dataset

4.4. Distributed Email Learning under an Extreme Asymmetric Data Distribution

5. Related Works
5.1. Centralized Learning in Phishing Detection
5.2. Cryptographic Deep Learning Training
5.3. Federated Learning
6. Discussion and Future Work
6.1. Improving Federated Learning Performance in Phishing Email Detection
6.2. Federated Learning, Privacy, and Security Attacks
6.3. Data and Model Privacy
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DL | Deep learning |
| RCNN | Recurrent convolutional neural network |
| GDPR | General data protection regulation |
| FL | Federated learning |
| NLP | Natural language processing |
| BERT | Bidirectional encoder representations from transformers |
Appendix A. Supplemental Results
Appendix A.1. Performance of THEMISb (Considering Email’s Body Only) in the Centralized and Federated Learning with 2, 5, and 10 Clients

Appendix A.2. Client-Level Performance of the THEMIS



Appendix A.3. THEMIS Performance over Two Clients with Data Size Variations in the Dataset

Appendix A.4. THEMIS Performance over Ten Clients with the Phishing to Legitimate Email Samples Ratio Variations in the Dataset

Appendix A.5. Distributed Email Learning under an Extreme Asymmetric Data Distribution with THEMIS (Considering Both Email’s Header and Body Information)

References
- Retruster Ltd. 2019 Phishing Statistics and Email Fraud Statistics. 2020. Available online: https://retruster.com/blog/2019-phishing-and-email-fraud-statistics.html (accessed on 24 January 2021).
- Mathews, L. Phishing Scams Cost American Businesses Half A Billion Dollars A Year. 2017. Available online: https://www.forbes.com/sites/leemathews/2017/05/05/phishing-scams-cost-american-businesses-half-a-billion-dollars-a-year/#133f645b3fa1 (accessed on 7 February 2021).
- Muncaster, P. COVID19 Drives Phishing Emails Up 667% in Under a Month. 2020. Available online: https://www.infosecurity-magazine.com/news/covid19-drive-phishing-emails-667?utm_source=twitterfeed&utm_medium=twitter (accessed on 8 February 2021).
- Dada, E.G.; Bassi, J.S.; Chiroma, H.; Abdulhamid, S.M.; Adetunmbi, A.O.; Ajibuwa, O.E. Machine learning for email spam filtering: Review, approaches and open research problems. Heliyon 2019, 5, e01802. [Google Scholar] [CrossRef] [PubMed]
- Hiransha, M.; Unnithan, N.A.; Vinayakumar, R.; Soman, K.; Verma, A.D.R. Deep Learning Based Phishing E-mail Detection CEN-Deepspam. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM IWSPA, Tempe, AZ, USA, 21 March 2018. [Google Scholar]
- Fang, Y.; Zhang, C.; Huang, C.; Liu, L.; Yang, Y. Phishing email detection using improved RCNN model with multilevel vectors and attention mechanism. IEEE Access 2019, 7, 56329–56340. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Das, A.; Baki, S.; El Aassal, A.; Verma, R.; Dunbar, A. SoK: A Comprehensive Reexamination of Phishing Research From the Security Perspective. Commun. Surv. Tuts. 2020, 22, 671–708. [Google Scholar] [CrossRef]
- Gao, J.; Ping, Q.; Wang, J. Resisting re-identification mining on social graph data. World Wide Web 2018, 21, 1759–1771. [Google Scholar] [CrossRef]
- Ho, G.; Cidon, A.; Gavish, L.; Schweighauser, M.; Paxson, V.; Savage, S.; Voelker, G.M.; Wagner, D. Detecting and characterizing lateral phishing at scale. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1273–1290. [Google Scholar]
- Shastri, S.; Wasserman, M.; Chidambaram, V. The Seven Sins of Personal-data Processing Systems Under GDPR. In Proceedings of the 11th USENIX Conference on Hot Topics in Cloud Computing, Renton, WA, USA, 8 July 2019; USENIX Association: Berkeley, CA, USA, 2019; p. 1. [Google Scholar]
- EU GDPR. General Data Protection Regulation (GDPR). Available online: https://www.eugdpr.org/ (accessed on 10 November 2019).
- HIPAA Compliance Assistance. Summary of the HIPAA Privacy Rule; Office for Civil Rights: Washington, DC, USA, 2003.
- McMahan, H.B. A survey of Algorithms and Analysis for Adaptive Online Learning. J. Mach. Learn. Res. 2017, 18, 90:1–90:50. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konecný, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards Federated Learning at Scale: System Design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Yang, W.; Zhang, Y.; Ye, K.; Li, L.; Xu, C.Z. FFD: A Federated Learning Based Method for Credit Card Fraud Detection. In Proceedings of the International Conference on Big Data, San Diego, CA, USA, 25–30 June 2019; pp. 18–32. [Google Scholar]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The Future of Digital Health with Federated Learning. NPJ Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef]
- Lin, B.Y.; He, C.; Zeng, Z.; Wang, H.; Huang, Y.; Soltanolkotabi, M.; Ren, X.; Avestimehr, S. FedNLP: A Research Platform for Federated Learning in Natural Language Processing. arXiv 2021, arXiv:2104.08815. [Google Scholar]
- ReDAS Lab@UH. First Security and Privacy Analytics Anti-Phishing Shared Task (IWSPA-AP 2018). Available online: https://dasavisha.github.io/IWSPA-sharedtask/ (accessed on 16 January 2020).
- Nazario, J. Nazario’s Phishing Corpora. Available online: https://monkey.org/~jose/phishing/ (accessed on 16 January 2020).
- CALO Project. Enron Email Dataset. Available online: http://www.cs.cmu.edu/~enron/ (accessed on 16 January 2020).
- Cornell University. Phis Bowl. Available online: https://it.cornell.edu/phish-bowl (accessed on 3 January 2021).
- The Dada Engine. Available online: http://dev.null.org/dadaengine/ (accessed on 16 January 2020).
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- HuggingFace. Bert-Base-Uncased. Available online: https://huggingface.co/bert-base-uncased (accessed on 9 April 2020).
- Lee, Y.; Saxe, J.; Harang, R. CATBERT: Context-Aware Tiny BERT for Detecting Social Engineering Emails. arXiv 2020, arXiv:2010.03484. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2020, arXiv:1910.01108. [Google Scholar]
- Python Software Foundation. email.header: Internationalized Headers. Available online: https://docs.python.org/3/library/email.header.html (accessed on 18 January 2020).
- Secret Labs. re—Regular Expression Operations. Available online: https://docs.python.org/3/library/re.html (accessed on 18 January 2020).
- BeautifulSoup Group. Beautiful Soup. Available online: https://www.crummy.com/software/BeautifulSoup/ (accessed on 19 January 2020).
- Online. html.parser—Simple HTML and XHTML Parser. Available online: https://docs.python.org/3/library/html.parser.html (accessed on 19 January 2020).
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. Available online: https://www.nltk.org/book/ch02.html (accessed on 19 January 2020).
- Online. tf.keras.preprocessing.text.Tokenizer. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer (accessed on 20 January 2020).
- Online. BERT. Available online: https://huggingface.co/transformers/model_doc/bert.html (accessed on 21 January 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; Keeton, K., Roscoe, T., Eds.; USENIX Association: Berkeley, CA, USA, 2016; pp. 265–283. [Google Scholar]
- Keras Team. Keras: The Python Deep Learning Library. Available online: https://keras.io/ (accessed on 18 January 2020).
- Meng, Q.; Chen, W.; Wang, Y.; Ma, Z.M.; Liu, T.Y. Convergence analysis of distributed stochastic gradient descent with shuffling. Neurocomputing 2019, 337, 46–57. [Google Scholar] [CrossRef]
- Abu-Nimeh, S.; Nappa, D.; Wang, X.; Nair, S. A comparison of machine learning techniques for phishing detection. In Proceedings of the Anti-Phishing Working Groups 2nd Annual eCrime Researchers Summit, Pittsburgh, PA, USA, 4–5 October 2007; Volume 269, pp. 60–69. [Google Scholar]
- Bergholz, A.; Beer, J.D.; Glahn, S.; Moens, M.; Paaß, G.; Strobel, S. New filtering approaches for phishing email. J. Comput. Secur. 2010, 18, 7–35. [Google Scholar] [CrossRef]
- Verma, R.M.; Shashidhar, N.; Hossain, N. Detecting Phishing Emails the Natural Language Way. In Proceedings of the ESORICS 2012, Pisa, Italy, 10–12 September 2012; Volume 7459, pp. 824–841. [Google Scholar]
- Vazhayil, A.; Harikrishnan, N.; Vinayakumar, R.; Soman, K.; Verma, A. PED-ML: Phishing email detection using classical machine learning techniques. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM IWSPA, Tempe, AZ, USA, 21 March 2018; pp. 1–8. [Google Scholar]
- Gutierrez, C.N.; Kim, T.; Corte, R.D.; Avery, J.; Goldwasser, D.; Cinque, M.; Bagchi, S. Learning from the Ones that Got Away: Detecting New Forms of Phishing Attacks. IEEE Trans. Dependable Secur. Comput. 2018, 15, 988–1001. [Google Scholar] [CrossRef]
- Unnithan, N.A.; Harikrishnan, N.B.; Vinayakumar, R.; Soman, K.P.; Sundarakrishna, S. Detecting Phishing E-mail using Machine learning techniques CEN-SecureNLP. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM IWSPA, Tempe, AZ, USA, 21 March 2018. [Google Scholar]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of online phishing email using dynamic evolving neural network based on reinforcement learning. Decis. Support Syst. 2018, 107, 88–102. [Google Scholar] [CrossRef]
- Zhang, J.; Li, X. Phishing detection method based on borderline-smote deep belief network. In Proceedings of the International Conference on Security, Privacy and Anonymity in Computation, Communication and Storage, Guangzhou, China, 12–15 December 2017; pp. 45–53. [Google Scholar]
- Nguyen, M.; Nguyen, T.; Nguyen, T.H. A deep learning model with hierarchical lstms and supervised attention for anti-phishing. In Proceedings of the 1st AntiPhishing Shared Pilot at 4th ACM IWSPA, Tempe, AZ, USA, 21 March 2018. [Google Scholar]
- Gascon, H.; Ullrich, S.; Stritter, B.; Rieck, K. Reading Between the Lines: Content-Agnostic Detection of Spear-Phishing Emails. In Proceedings of the RAID 2018, Crete, Greece, 10–12 September 2018; Bailey, M., Holz, T., Stamatogiannakis, M., Ioannidis, S., Eds.; Springer: Cham, Switzerland, 2018; pp. 69–91. [Google Scholar]
- Cidon, A.; Gavish, L.; Bleier, I.; Korshun, N.; Schweighauser, M.; Tsitkin, A. High precision detection of business email compromise. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019; pp. 1291–1307. [Google Scholar]
- Mohassel, P.; Zhang, Y. SecureML: A System for Scalable Privacy-Preserving Machine Learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar]
- Wagh, S.; Gupta, D.; Chandran, N. SecureNN: 3-Party Secure Computation for Neural Network Training. PoPETs 2019, 2019, 26–49. [Google Scholar] [CrossRef]
- Mohassel, P.; Rindal, P. ABY3: A Mixed Protocol Framework for Machine Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 35–52. [Google Scholar]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Leroy, D.; Coucke, A.; Lavril, T.; Gisselbrecht, T.; Dureau, J. Federated learning for keyword spotting. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6341–6345. [Google Scholar]
- Gao, D.; Ju, C.; Wei, X.; Liu, Y.; Chen, T.; Yang, Q. HHHFL: Hierarchical Heterogeneous Horizontal Federated Learning for Electroencephalography. arXiv 2019, arXiv:1909.05784v3. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the AISTATS 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Shoham, N.; Avidor, T.; Keren, A.; Israel, N.; Benditkis, D.; Mor-Yosef, L.; Zeitak, I. Overcoming Forgetting in Federated Learning on Non-IID Data. arXiv 2019, arXiv:1910.07796. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Yu, F.X.; Rawat, A.S.; Menon, A.K.; Kumar, S. Federated Learning with Only Positive Labels. arXiv 2020, arXiv:2004.10342. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. In Proceedings of the ICLR, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–16. [Google Scholar]
- Jiang, Y.; Konečný, J.; Rush, K.; Kannan, S. Improving Federated Learning Personalization via Model Agnostic Meta Learning. arXiv 2019, arXiv:1909.12488. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. arXiv 2018, arXiv:1807.00459. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar]
- Gao, Y.; Xu, C.; Wang, D.; Chen, S.; Ranasinghe, D.C.; Nepal, S. Strip: A defence against trojan attacks on deep neural networks. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; pp. 113–125. [Google Scholar]
- Zhao, L.; Hu, S.; Wang, Q.; Jiang, J.; Chao, S.; Luo, X.; Hu, P. Shielding Collaborative Learning: Mitigating Poisoning Attacks through Client-Side Detection. IEEE Trans. Dependable Secur. Comput. 2020, 18, 2029–2041. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, C.; Wu, T.; Zhu, L.; Liu, X. Achieving Efficient and Privacy-Preserving Neural Network Training and Prediction in Cloud Environments. IEEE Trans. Dependable Secur. Comput. 2022, 1–12. [Google Scholar] [CrossRef]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Zhu, L.; Zhang, W.; Wu, T.; Ni, J. FRUIT: A Blockchain-Based Efficient and Privacy-Preserving Quality-Aware Incentive Scheme. IEEE J. Sel. Areas Commun. 2022, 40, 3343–3357. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Phishing (P) | Legitimate (L) | P + L |
|---|---|---|---|
| IWSPA-AP | 1132 | 9174 | 10,306 |
| Nazario | 8890 | 0 | 8890 |
| Enron | 0 | 4279 | 4279 |
| CSIRO | 309 | 0 | 309 |
| Phisbowl | 132 | 0 | 132 |
| Total | 10,463 | 13,453 | 23,916 |
| Research Questions | Data Distribution among Clients | Data Source | |||||
|---|---|---|---|---|---|---|---|
| Balanced | Asymmetric | IWSPA-AP | Nazario | Enron | CSIRO | Phishbowl | |
| RQ1 | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RQ2 | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RQ3 | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RQ4 | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RQ5 | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| RQ6 | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Round | Involvement of Clients |
|---|---|
| 0 to 9 | Only the first client. |
| 10 to 19 | Only the first and second clients. |
| 20 to 29 | Only the first, second, and third clients. |
| 30 to 39 | First, second, third, and fourth clients. |
| 40 to 50 | All five clients. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thapa, C.; Tang, J.W.; Abuadbba, A.; Gao, Y.; Camtepe, S.; Nepal, S.; Almashor, M.; Zheng, Y. Evaluation of Federated Learning in Phishing Email Detection. Sensors 2023, 23, 4346. https://doi.org/10.3390/s23094346
Thapa C, Tang JW, Abuadbba A, Gao Y, Camtepe S, Nepal S, Almashor M, Zheng Y. Evaluation of Federated Learning in Phishing Email Detection. Sensors. 2023; 23(9):4346. https://doi.org/10.3390/s23094346
Chicago/Turabian StyleThapa, Chandra, Jun Wen Tang, Alsharif Abuadbba, Yansong Gao, Seyit Camtepe, Surya Nepal, Mahathir Almashor, and Yifeng Zheng. 2023. "Evaluation of Federated Learning in Phishing Email Detection" Sensors 23, no. 9: 4346. https://doi.org/10.3390/s23094346
APA StyleThapa, C., Tang, J. W., Abuadbba, A., Gao, Y., Camtepe, S., Nepal, S., Almashor, M., & Zheng, Y. (2023). Evaluation of Federated Learning in Phishing Email Detection. Sensors, 23(9), 4346. https://doi.org/10.3390/s23094346