Prediction of Shooting Events in Soccer Videos Using Complete Bipartite Graphs and Players’ Spatial-Temporal Relations


Abstract
:1. Introduction
- (1)
- Conventional methods solely concentrate on the positional relations among players, without incorporating any visual information from video data.
- (2)
- Conventional methods fail to account for the reliability of event occurrence probabilities derived from deep learning-based methods.
- (1)
- Our novel method for predicting shoot events in soccer videos incorporates player-specific features and spatio-temporal relations using GCRNN.
- (2)
- We propose a method that aims to enhance the robustness of predictions by providing a measure of prediction uncertainty through the use of BNN.
2. Pre-Processing
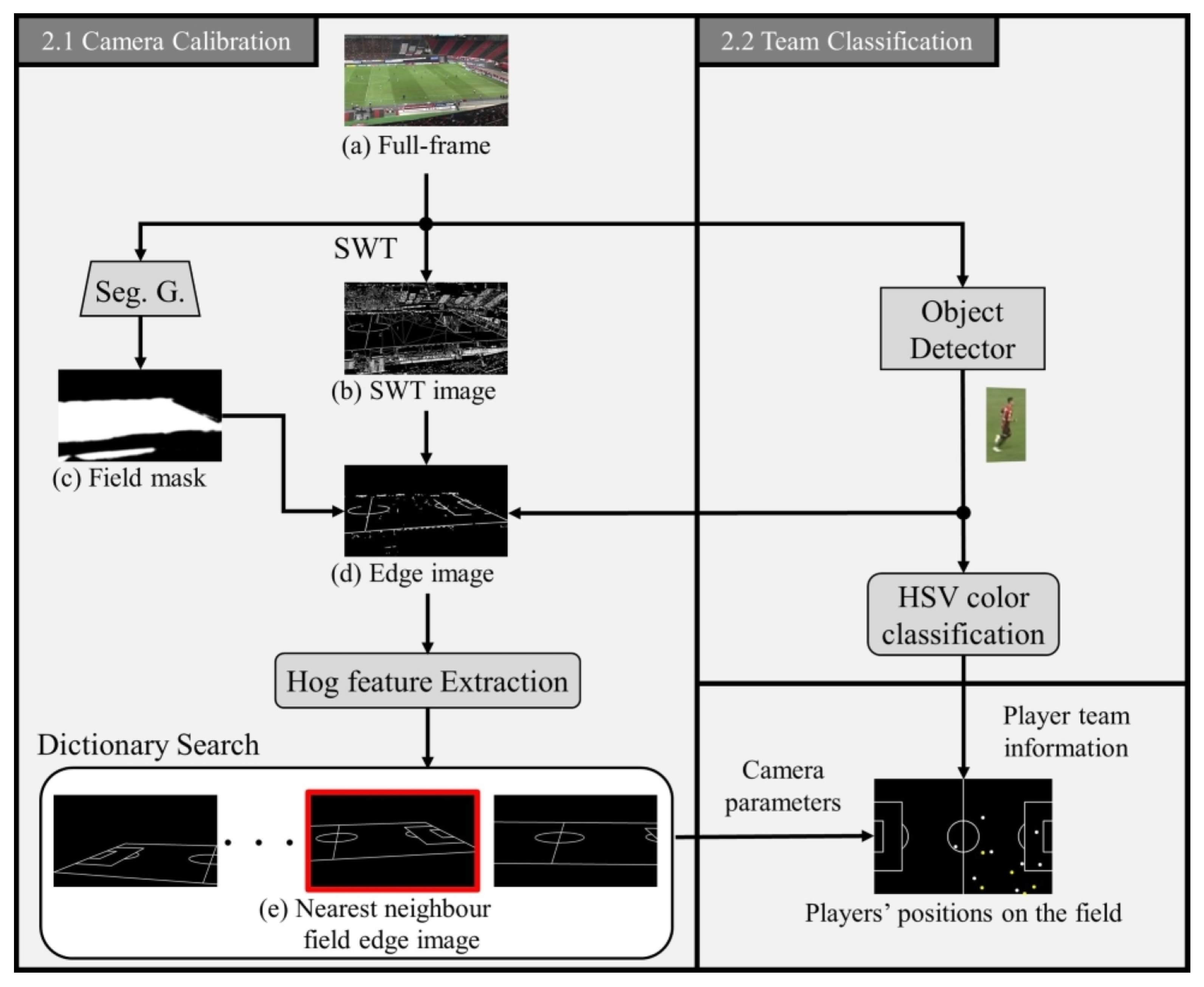
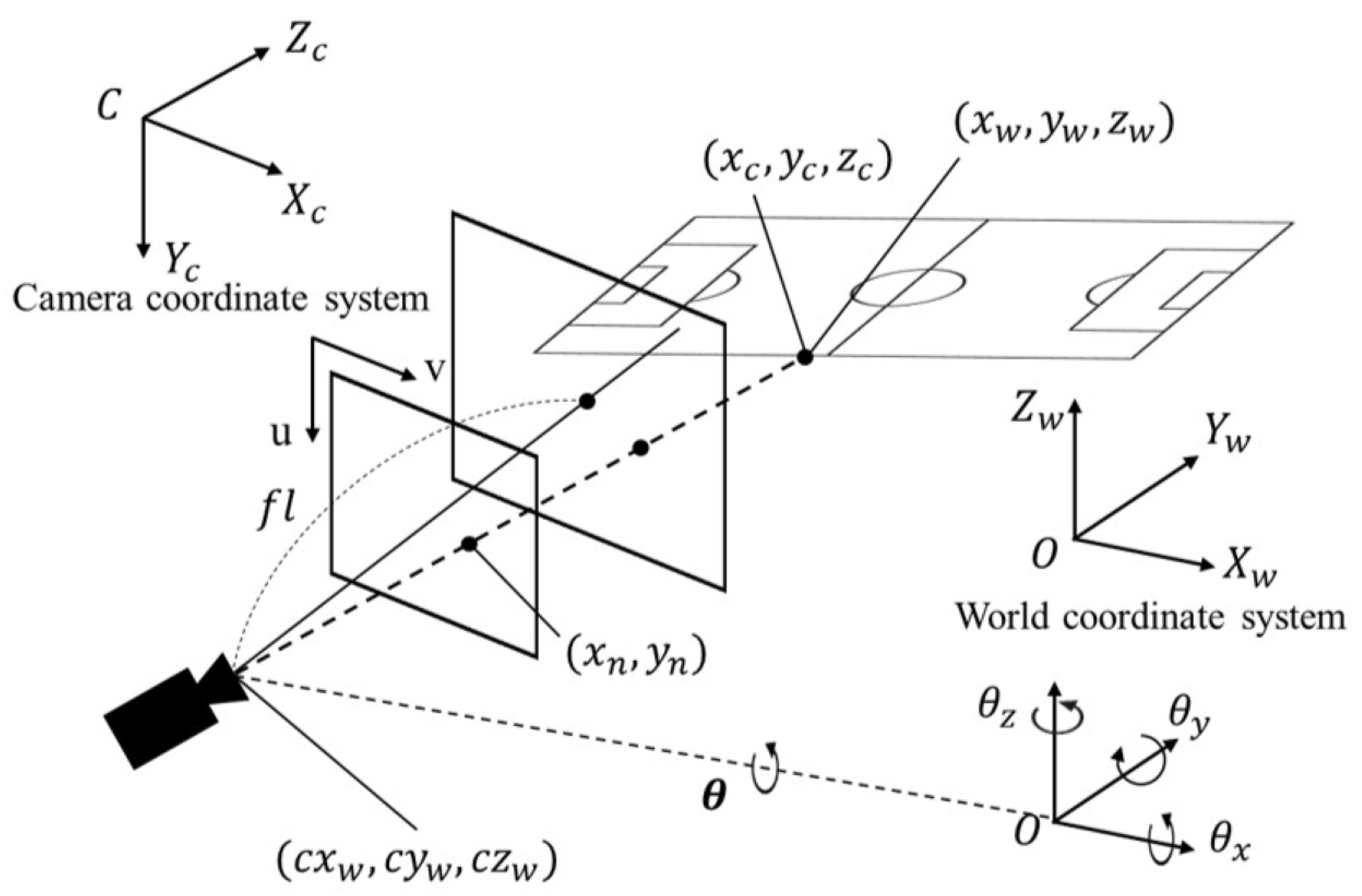
2.1. Camera Calibration
- Since field lines are believed to maintain a small and consistent stroke width, we apply a filter to include only strokes that are longer than 10 pixels.
- To segment strokes based on a the field color, we extract only those strokes within the range in the HSV color space, as the field lines are typically found on the grass.
- We use a field mask (b) to mask off-field areas such as spectator seats and benches.
- To eliminate player regions, we use a Mask R-CNN detector [40].
2.2. Team Classification
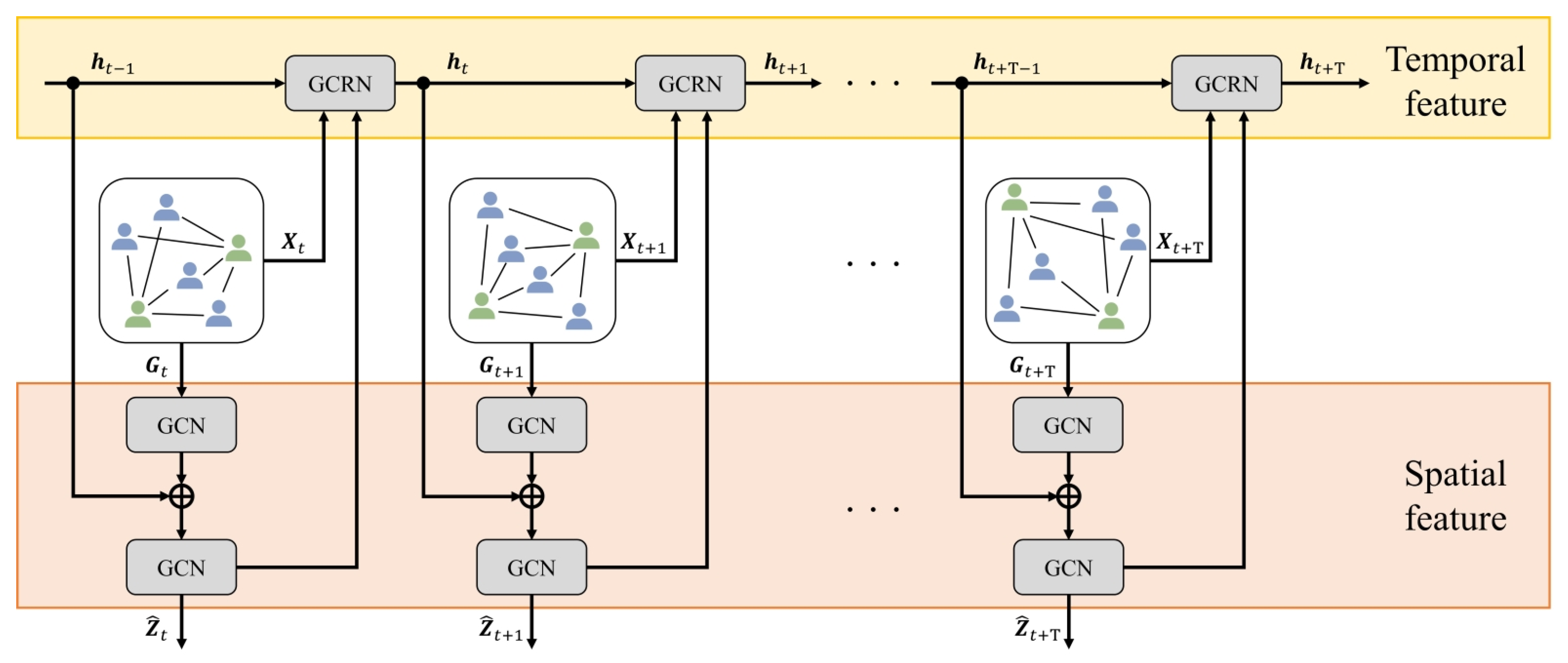
3. Method for Prediction of Shoot Events
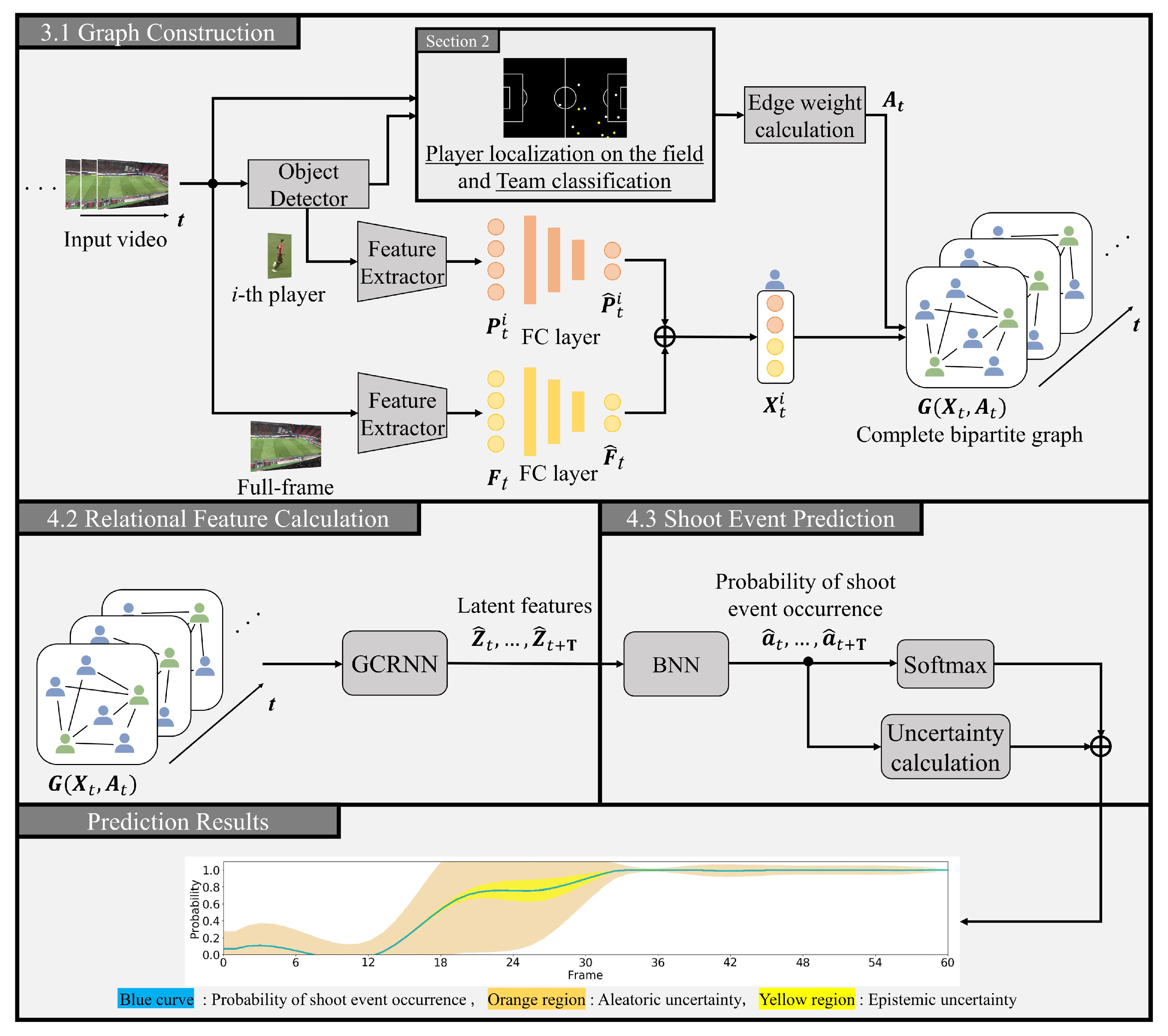
3.1. Construction of Complete Bipartite Graphs
3.2. Calculation of Spatio-Temporal Relational Features
3.3. Event Prediction with Its Uncertainty
4. Experimental Results
4.1. Experimental Settings
- AS1:
- This refers to our previous approach [37], which is similar to the proposed method but uses a complete graph without any team information.
- AS2:
- This method builds upon our previous method but utilizes a complete bipartite graph that does not consider the distances between players.
- AS3:
- This method is similar to our proposed method but employs a complete graph without incorporating edge weights in the graph representation.
- AS4:
- This method uses the full-frame visual features, which applies a field mask obtained in Section 2.1 to the full-frame, as node features in the proposed method.
- CM1:
- This is a method for predictiong traffic accidents in dashcam videos using Dynamic-Spatial-Attention Recurrent Neural Network (DSA-RNN), as presented in the work of [53]. The DSA-RNN facilitates prediction by dynamically allocating soft-attention [54] to candidate objects in each frame, collecting cues, and learning the temporal relationships of all cues.
- CM2:
- This is a state-of-the-art method for video classification that uses the Video Vision Transformer (ViViT) [55]. ViViT tokenizes the video by dividing it into either 2-D spatial or 3-D spatio-temporal grids. The video can be classified by feeding the tokens extracted from it into the transformer encoder.
4.2. Performance Evaluation
4.2.1. Quantitative Results
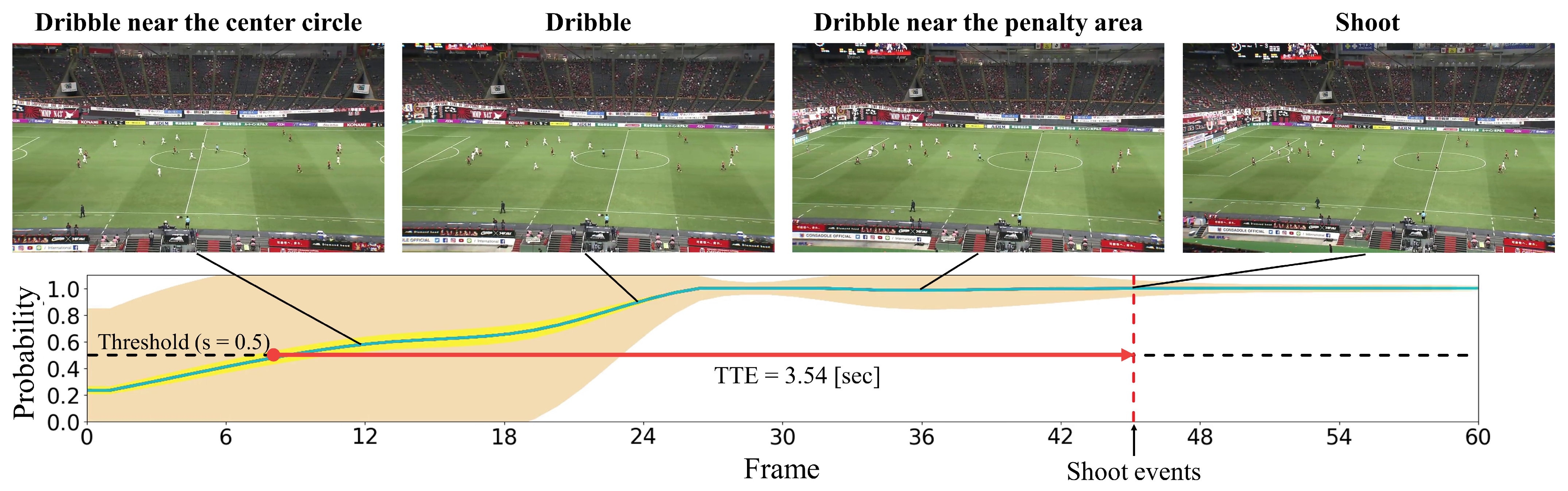
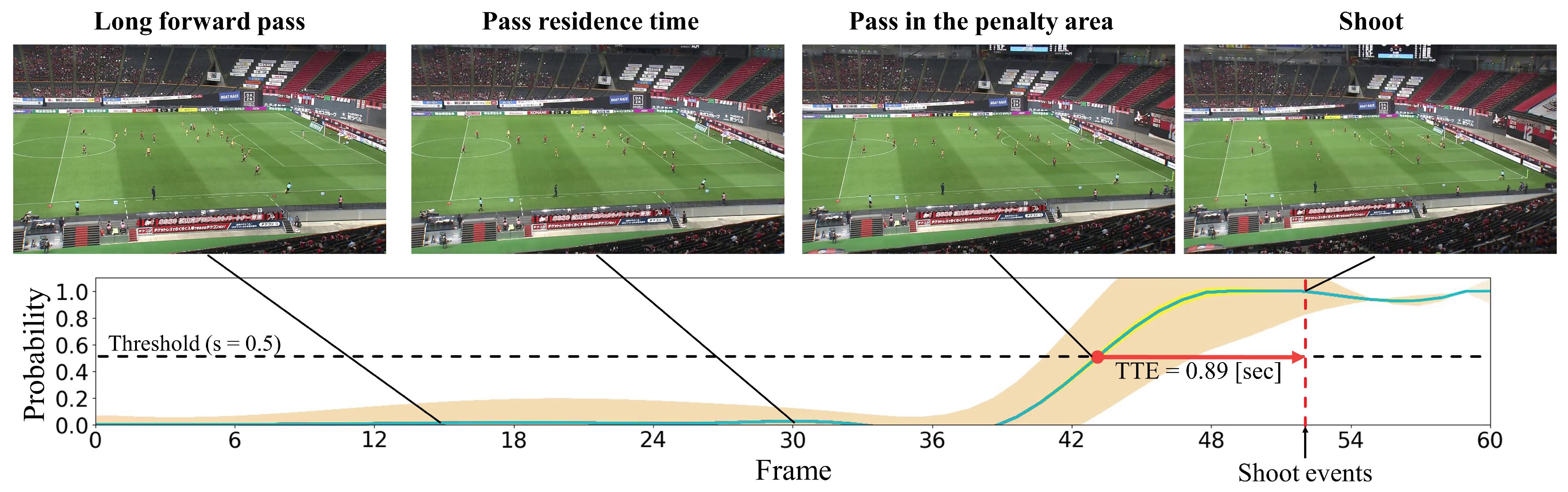
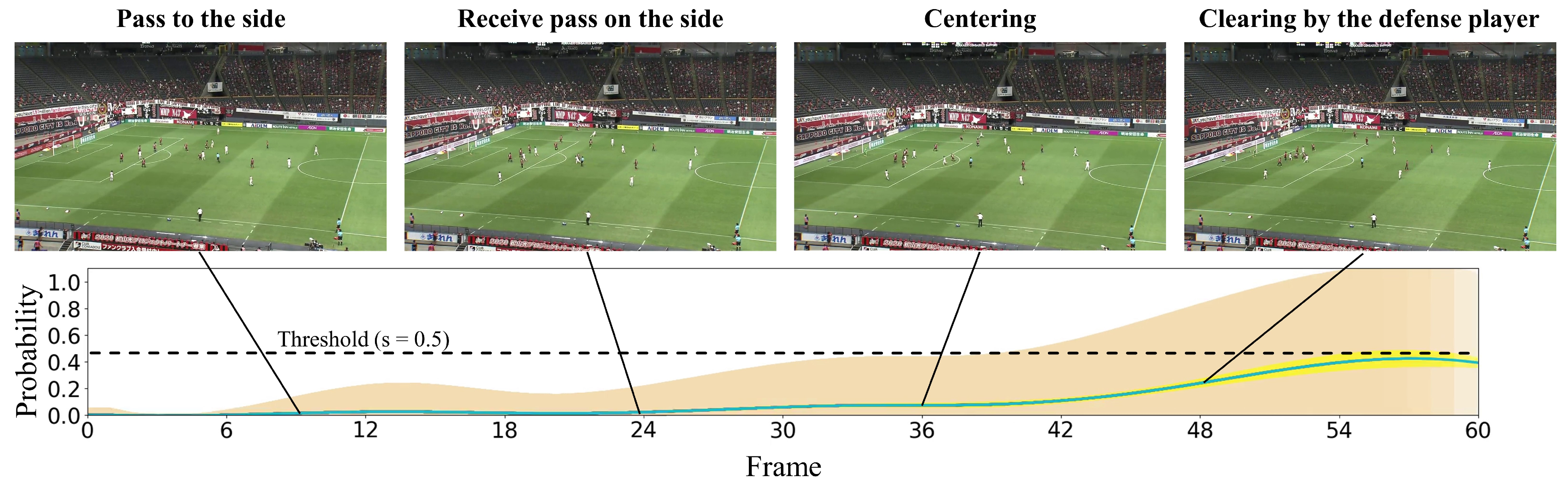
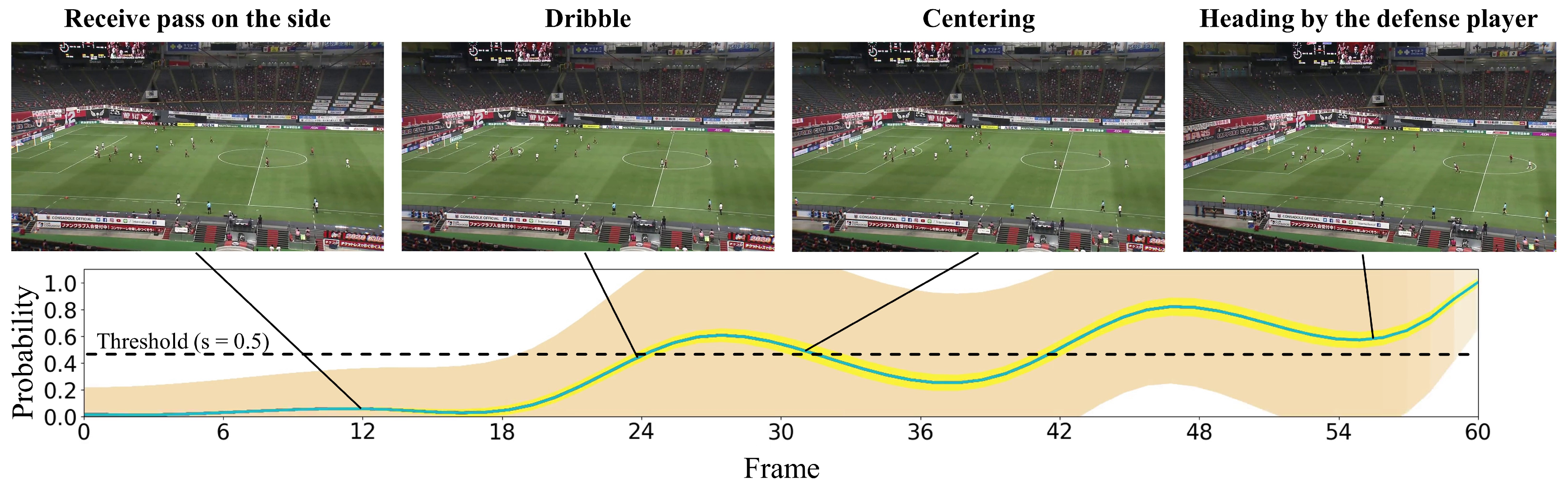
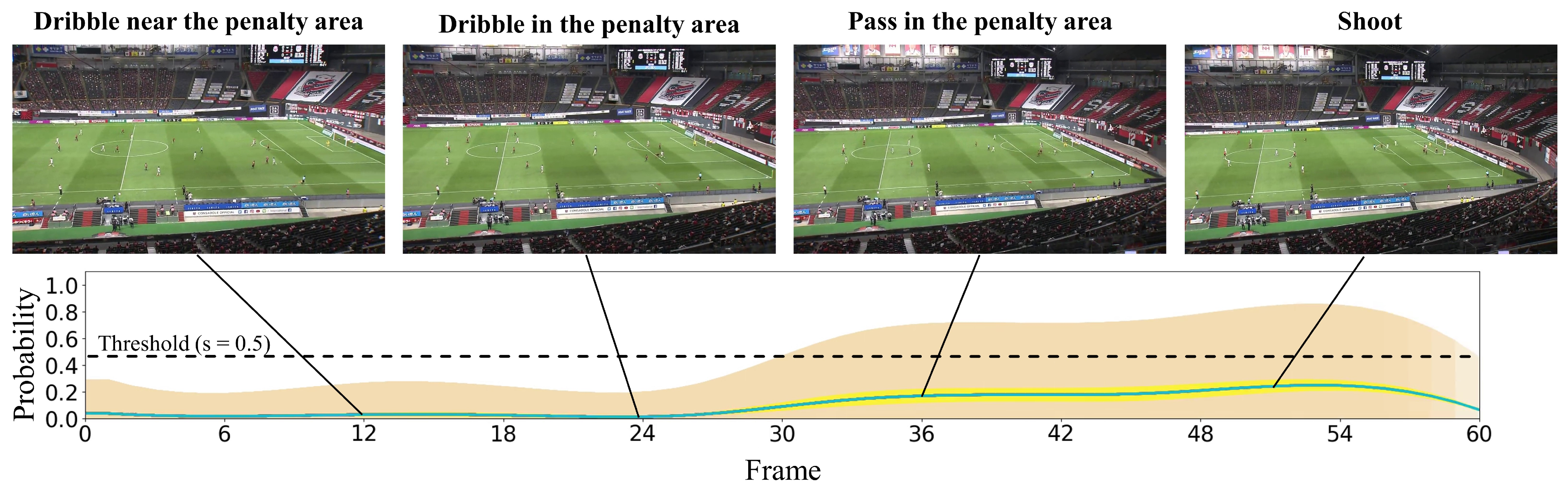
4.2.2. Qualitative Results
5. Conclusions
- (1)
- We developed a new method for predicting shoot events in soccer videos, incorporating player-specific features and spatio-temporal relations with GCRNN.
- (2)
- The proposed method provides a measure of prediction uncertainty by using BNN, which is intended to enhance the robustness of the predictions.
- (1)
- Our model cannot consider the skill levels of each player that could change the development of the game. Annotations for each player are needed for introducing such skill levels, but manual annotation is not a realistic solution since it takes a lot of effort and time.
- (2)
- Reflection of the ball position, which is the direct method for grasping the situations of the game, should be performed in our model. However, when using the scouting soccer videos for recognizing more players, the ball region is too small to be recognized by the object detector. The use of GPS Information is one possible solution, but it is difficult to implement in minor games.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Assunção, R.; Pelechrinis, K. Sports analytics in the era of big data: Moving toward the next frontier. Big Data 2018, 6, 237–238. [Google Scholar] [CrossRef]
- Mercier, M.A.; Tremblay, M.; Daneau, C.; Descarreaux, M. Individual factors associated with baseball pitching performance: Scoping review. BMJ Open Sport Exerc. Med. 2020, 6, e000704. [Google Scholar] [CrossRef]
- Mizels, J.; Erickson, B.; Chalmers, P. Current state of data and analytics research in baseball. Curr. Rev. Musculoskelet. Med. 2022, 15, 283–290. [Google Scholar] [CrossRef] [PubMed]
- Sarlis, V.; Tjortjis, C. Sports analytics—Evaluation of basketball players and team performance. Inf. Syst. 2020, 93, 101562. [Google Scholar] [CrossRef]
- Cervone, D.; D’Amour, A.; Bornn, L.; Goldsberry, K. A multiresolution stochastic process model for predicting basketball possession outcomes. J. Am. Stat. Assoc. 2016, 111, 585–599. [Google Scholar] [CrossRef]
- Kubayi, A.; Larkin, P. Analysis of teams’ corner kicks defensive strategies at the FIFA World Cup 2018. Int. J. Perform. Anal. Sport 2019, 19, 809–819. [Google Scholar] [CrossRef]
- Beavan, A.; Fransen, J. The influence of coaching instructions on decision-making in soccer. J. Sport Exerc. Sci. 2021, 5, 3–12. [Google Scholar]
- Siddharth, S.; Saurav, S.; Kan, J.; Bimlesh, W.; Song, D.J. Model Driven Inputs to aid Athlete’s Decision Making. In Proceedings of the Asia-Pacific Software Engineering Conference, Singapore, 1–4 December 2020; pp. 485–489. [Google Scholar]
- Van Roy, M.; Robberechts, P.; Yang, W.C.; De Raedt, L.; Davis, J. Leaving goals on the pitch: Evaluating decision making in soccer. In Proceedings of the MIT Sloan Sports Analytics Conference, Virtual, 8–9 April 2021; pp. 1–25. [Google Scholar]
- Baca, A.; Dabnichki, P.; Hu, C.W.; Kornfeind, P.; Exel, J. Ubiquitous Computing in Sports and Physical Activity—Recent Trends and Developments. Sensors 2022, 22, 8370. [Google Scholar] [CrossRef]
- Laws of the Game 2018/2019. Available online: https://digitalhub.fifa.com/m/50518593a0941079/original/khhloe2xoigyna8juxw3-pdf (accessed on 11 October 2022).
- Anzer, G.; Bauer, P. A goal scoring probability model for shots based on synchronized positional and event data in football (soccer). Front. Sports Act. Living 2021, 3, 624475. [Google Scholar] [CrossRef] [PubMed]
- Link, D.; Lang, S.; Seidenschwarz, P. Real time quantification of dangerousity in football using spatiotemporal tracking data. PLoS ONE 2016, 11, e0168768. [Google Scholar] [CrossRef]
- Decroos, T.; Van Haaren, J.; Dzyuba, V.; Davis, J. STARSS: A spatio-temporal action rating system for soccer. In Proceedings of the ECML/PKDD Workshop on Machine Learning and Data Mining for Sports Analytics, Skopje, North Macedonia, 18 September 2017; Volume 1971, pp. 11–20. [Google Scholar]
- Spearman, W.; Basye, A.; Dick, G.; Hotovy, R.; Pop, P. Physics-based modeling of pass probabilities in soccer. In Proceedings of the MIT Sloan Sports Analytics Conference, Boston, MA, USA, 3–4 March 2017; pp. 1–14. [Google Scholar]
- Spearman, W. Beyond expected goals. In Proceedings of the MIT Sloan Sports Analytics Conference, Boston, MA, USA, 23–24 February 2018; pp. 1–17. [Google Scholar]
- Goldner, K. A Markov model of football: Using stochastic processes to model a football drive. J. Quant. Anal. Sports 2012, 8, 1–18. [Google Scholar] [CrossRef]
- Lucey, P.; Bialkowski, A.; Monfort, M.; Carr, P.; Matthews, I. Quality vs quantity: Improved shot prediction in soccer using strategic features from spatiotemporal data. In Proceedings of the Annual MIT Sloan Sports Analytics Conference, Boston, MA, USA, 28 February–1 March 2014; pp. 1–9. [Google Scholar]
- Dick, U.; Brefeld, U. Learning to rate player positioning in soccer. Big Data 2019, 7, 71–82. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Luo, Y.; Schulte, O.; Kharrat, T. Deep soccer analytics: Learning an action-value function for evaluating soccer players. Data Min. Knowl. Discov. 2020, 34, 1531–1559. [Google Scholar] [CrossRef]
- Szczepański, Ł.; McHale, I. Beyond completion rate: Evaluating the passing ability of footballers. J. R. Stat. Soc. Ser. Stat. Soc. 2016, 179, 513–533. [Google Scholar] [CrossRef]
- Power, P.; Ruiz, H.; Wei, X.; Lucey, P. Not all passes are created equal: Objectively measuring the risk and reward of passes in soccer from tracking data. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1605–1613. [Google Scholar]
- Decroos, T.; Davis, J. Interpretable prediction of goals in soccer. In Proceedings of the AAAI Workshop on Artificial Intelligence in Team Sports, Honolulu, HI, USA, 27–28 January 2019. [Google Scholar]
- Fernández, J.; Bornn, L.; Cervone, D. Decomposing the immeasurable sport: A deep learning expected possession value framework for soccer. In Proceedings of the MIT Sloan Sports Analytics Conference, Boston, MA, USA, 1–2 March 2019. [Google Scholar]
- Fernández, J.; Bornn, L. PassNet: Learning Pass Probability Surfaces from Single-Location Labels. An Architecture for Visually-Interpretable Soccer Analytics. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; Available online: https://openreview.net/forum?id=r1xxKJBKvr (accessed on 2 April 2023).
- Fernández, J.; Bornn, L. Soccermap: A deep learning architecture for visually-interpretable analysis in soccer. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Ghent, Belgium, 14–18 September 2020; pp. 491–506. [Google Scholar]
- Simpson, I.; Beal, R.J.; Locke, D.; Norman, T.J. Seq2Event: Learning the Language of Soccer using Transformer-based Match Event Prediction. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 3898–3908. [Google Scholar]
- Felsen, P.; Agrawal, P.; Malik, J. What will happen next? Forecasting player moves in sports videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3342–3351. [Google Scholar]
- Ruiz, L.; Gama, F.; Ribeiro, A. Gated graph convolutional recurrent neural networks. In Proceedings of the European Signal Processing Conference, A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Bao, W.; Yu, Q.; Kong, Y. Uncertainty-based traffic accident anticipation with spatio-temporal relational learning. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2682–2690. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Seo, Y.; Defferrard, M.; Vandergheynst, P.; Bresson, X. Structured sequence modeling with graph convolutional recurrent networks. In Proceedings of the International Conference on Neural Information Processing, Siem Reap, Cambodia, 13–16 December 2018; pp. 362–373. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: Cham, Switzerland, 2012. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight uncertainty in neural network. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1613–1622. [Google Scholar]
- Goka, R.; Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. Shoot event prediction from soccer videos by considering players’ spatio-temporal relations. In Proceedings of the IEEE Global Conference on Consumer Electronics, Osaka, Japan, 18–21 October 2022; pp. 193–194. [Google Scholar]
- Epshtein, B.; Ofek, E.; Wexler, Y. Detecting text in natural scenes with stroke width transform. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2963–2970. [Google Scholar]
- Sharma, R.A.; Bhat, B.; Gandhi, V.; Jawahar, C. Automated top view registration of broadcast football videos. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 305–313. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, J.; Little, J.J. Sports camera calibration via synthetic data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 2497–2504. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.B.; Cui, R.y. Player classification algorithm based on digraph in soccer video. In Proceedings of the IEEE Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 20–21 December 2014; pp. 459–463. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- González-Víllora, S.; García-López, L.M.; Gutiérrez-Díaz, D.; Pastor-Vicedo, J.C. Tactical awareness, decision making and skill in youth soccer players (under-14 years). J. Hum. Sport Exerc. 2013, 8, 412–426. [Google Scholar] [CrossRef]
- Owen, A.B. Monte Carlo theory, methods and examples. In Handbooks in Operations Research and Management Science; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? Adv. Neural Inf. Process. Syst. 2017, 30, 5574–5584. [Google Scholar]
- Diederik, P.K.; Ba, J.L. Adam: A method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Chan, F.H.; Chen, Y.T.; Xiang, Y.; Sun, M. Anticipating accidents in dashcam videos. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 136–153. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Haruyama, T.; Takahashi, S.; Ogawa, T.; Haseyama, M. User-selectable event summarization in unedited raw soccer video via multimodal bidirectional LSTM. ITE Trans. Media Technol. Appl. 2021, 9, 42–53. [Google Scholar] [CrossRef]
- Wang, T.; Chen, K.; Chen, G.; Li, B.; Li, Z.; Liu, Z.; Jiang, C. GSC: A Graph and Spatio-temporal Continuity Based Framework for Accident Anticipation. IEEE Trans. Intell. Veh. 2023; online early access. [Google Scholar] [CrossRef]
- Izquierdo, J.M.; Redondo, J.C. Offensive difference styles and technical situational variables between european and south american elite football leagues. MHSalud 2022, 19, 25–37. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| t = 10 | t = 20 | t = 30 | t = 40 | t = 50 | t = 60 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | F1-Score | AP | F1-Score | AP | F1-Score | AP | F1-Score | AP | F1-Score | AP | F1-Score | |
| Ours | 0.960 | 0.880 | 0.966 | 0.909 | 0.964 | 0.923 | 0.964 | 0.923 | 0.970 | 0.921 | 0.963 | 0.914 |
| AS1 [37] | 0.955 | 0.889 | 0.961 | 0.897 | 0.962 | 0.897 | 0.959 | 0.909 | 0.958 | 0.900 | 0.954 | 0.880 |
| AS2 | 0.954 | 0.892 | 0.961 | 0.881 | 0.932 | 0.886 | 0.929 | 0.892 | 0.924 | 0.892 | 0.919 | 0.892 |
| AS3 | 0.956 | 0.865 | 0.960 | 0.889 | 0.934 | 0.883 | 0.914 | 0.895 | 0.909 | 0.895 | 0.904 | 0.895 |
| AS4 | 0.951 | 0.881 | 0.964 | 0.889 | 0.961 | 0.914 | 0.962 | 0.904 | 0.963 | 0.897 | 0.956 | 0.897 |
| CM1 [53] | 0.931 | 0.878 | 0.958 | 0.902 | 0.966 | 0.902 | 0.959 | 0.900 | 0.961 | 0.892 | 0.958 | 0.881 |
| CM2 [55] | 0.752 | 0.714 | 0.776 | 0.729 | 0.778 | 0.725 | 0.782 | 0.747 | 0.784 | 0.759 | 0.790 | 0.722 |
| AP | F1-Score | mTTE(s) | |
|---|---|---|---|
| Ours | 0.967 | 0.914 | 3.88 |
| AS1 [37] | 0.941 | 0.880 | 3.60 |
| AS2 | 0.917 | 0.892 | 4.32 |
| AS3 | 0.903 | 0.895 | 4.66 |
| AS4 | 0.950 | 0.886 | 3.67 |
| CM1 [53] | 0.931 | 0.853 | 3.62 |
| CM2 [55] | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goka, R.; Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. Prediction of Shooting Events in Soccer Videos Using Complete Bipartite Graphs and Players’ Spatial-Temporal Relations. Sensors 2023, 23, 4506. https://doi.org/10.3390/s23094506
Goka R, Moroto Y, Maeda K, Ogawa T, Haseyama M. Prediction of Shooting Events in Soccer Videos Using Complete Bipartite Graphs and Players’ Spatial-Temporal Relations. Sensors. 2023; 23(9):4506. https://doi.org/10.3390/s23094506
Chicago/Turabian StyleGoka, Ryota, Yuya Moroto, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2023. "Prediction of Shooting Events in Soccer Videos Using Complete Bipartite Graphs and Players’ Spatial-Temporal Relations" Sensors 23, no. 9: 4506. https://doi.org/10.3390/s23094506
APA StyleGoka, R., Moroto, Y., Maeda, K., Ogawa, T., & Haseyama, M. (2023). Prediction of Shooting Events in Soccer Videos Using Complete Bipartite Graphs and Players’ Spatial-Temporal Relations. Sensors, 23(9), 4506. https://doi.org/10.3390/s23094506