


A Selection of Starting Points for Iterative Position Estimation Algorithms Using Feedforward Neural Networks

Abstract
:1. Introduction
2. Related Works
3. System Model
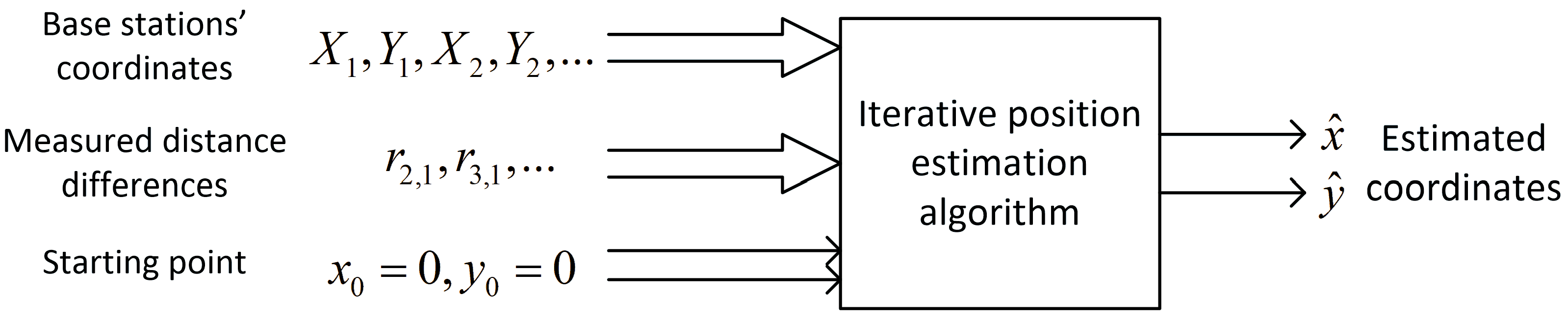
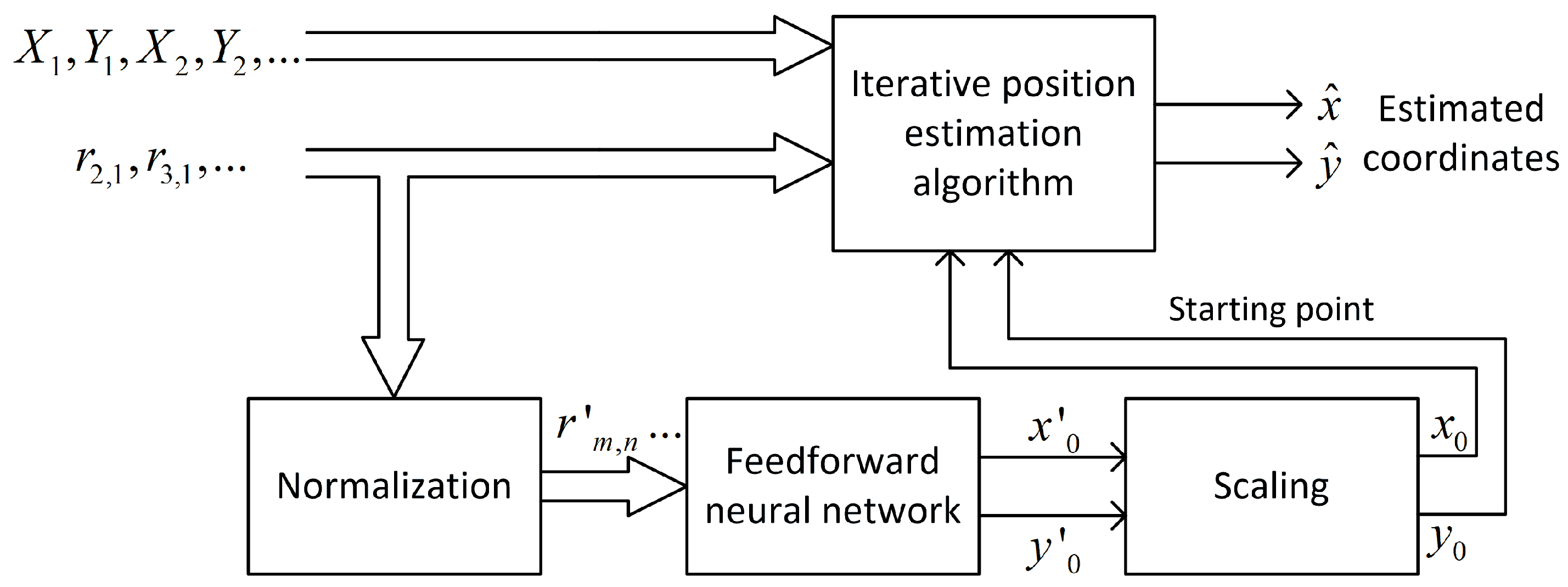
3.1. Position Estimation Method
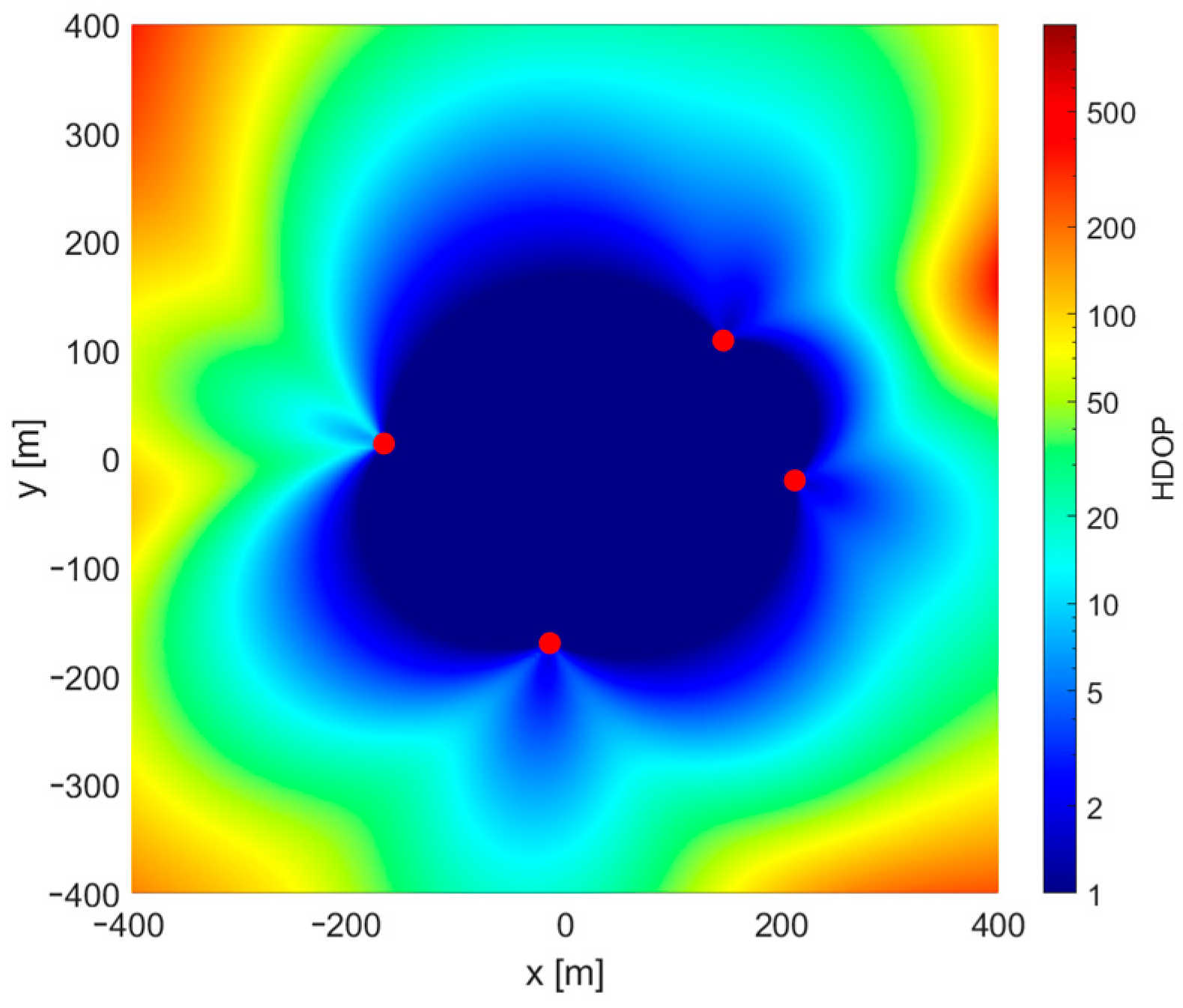
3.2. Base Stations Geometry
3.3. Iterative Position Calculation Algorithms
3.3.1. Gauss-Newton
3.3.2. Levenberg–Marquardt
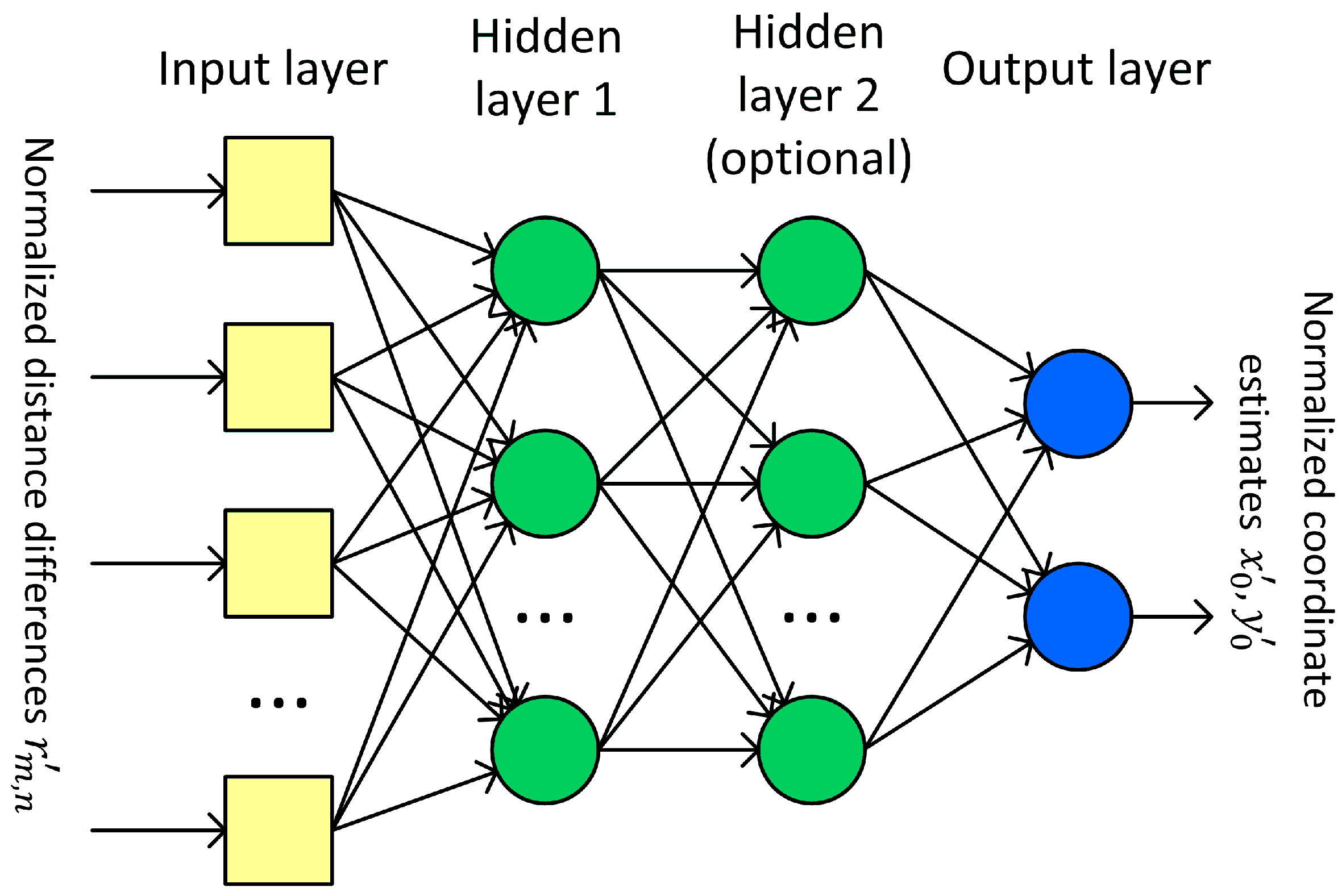
3.4. Neural Network Structure
3.5. Network Efficiency Evaluation
4. Simulations
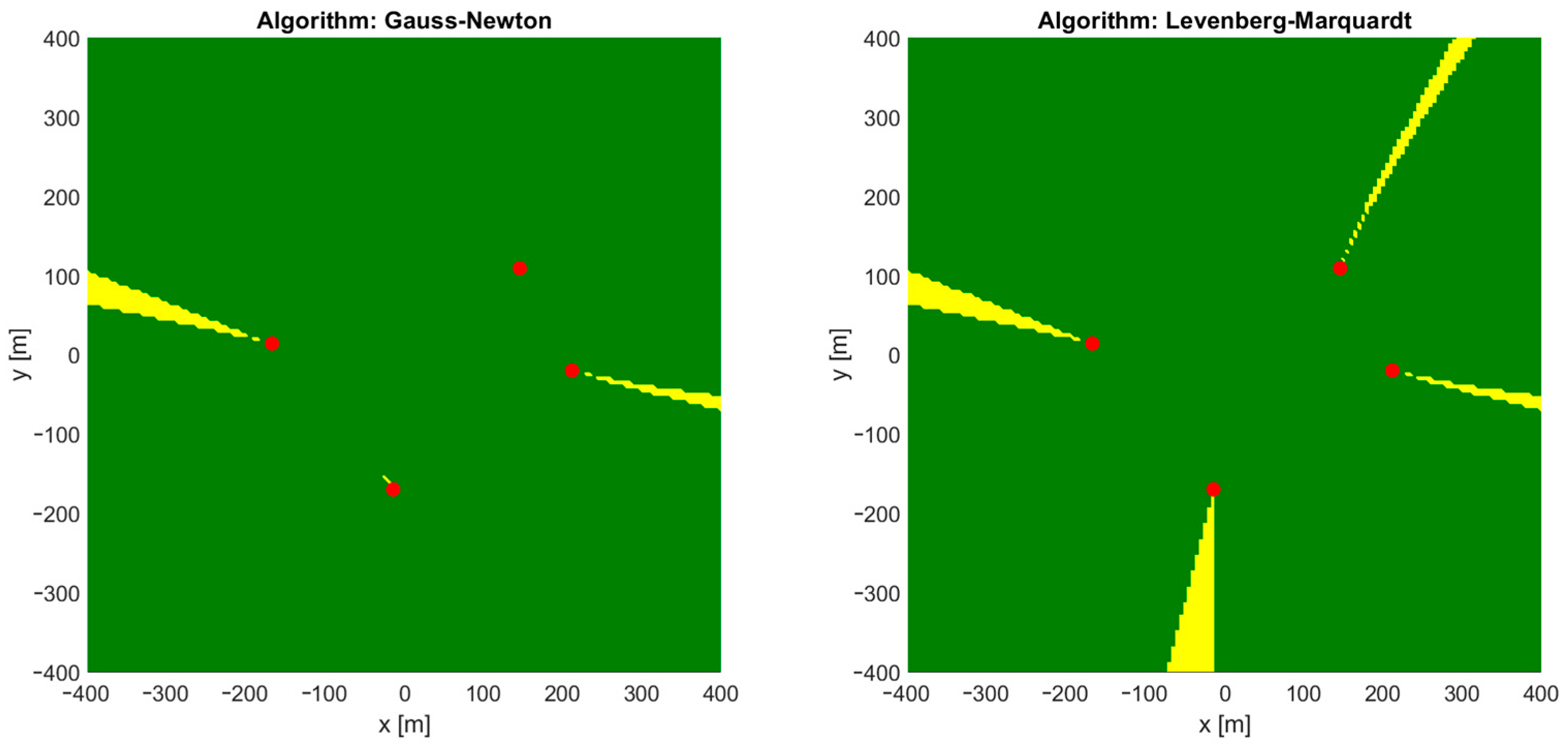
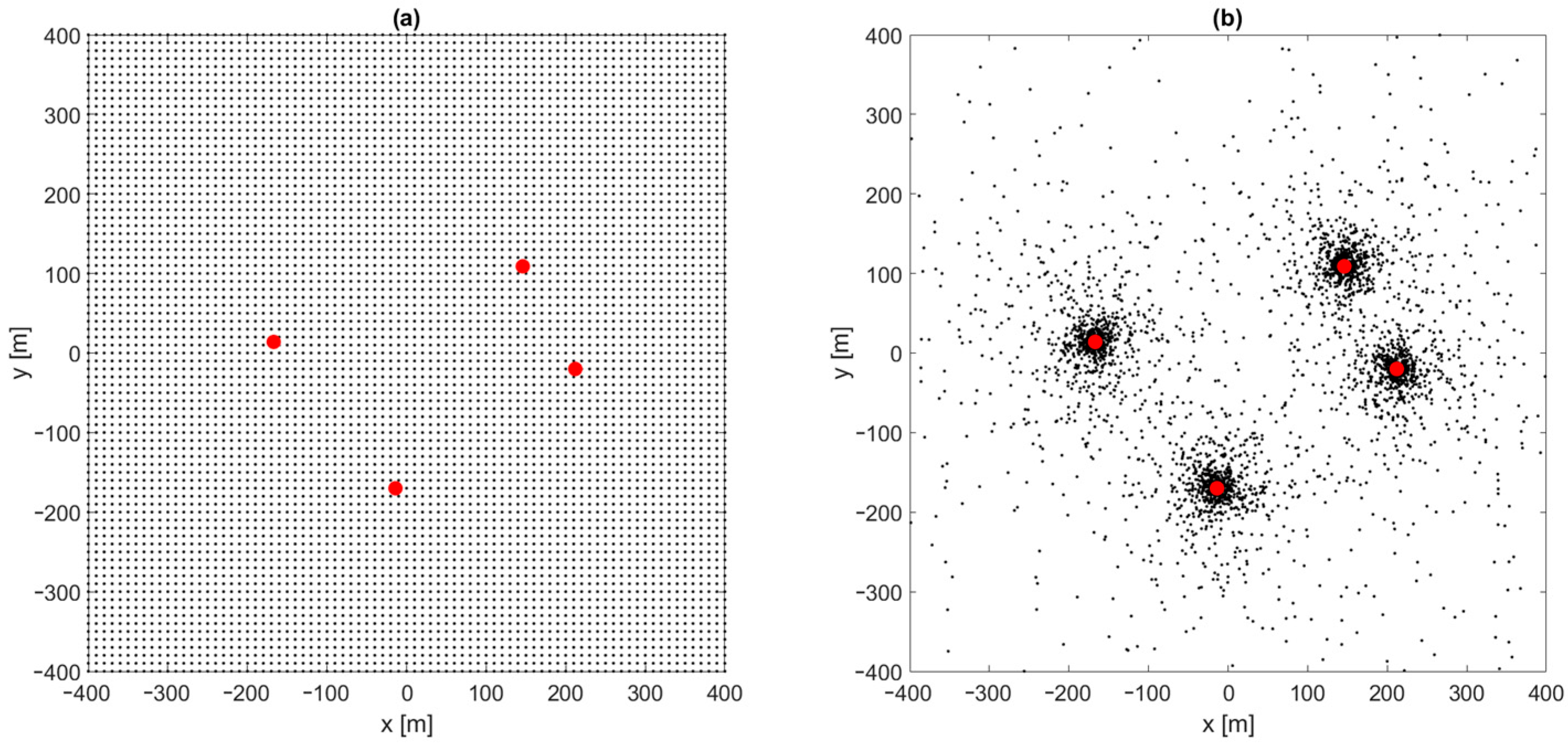
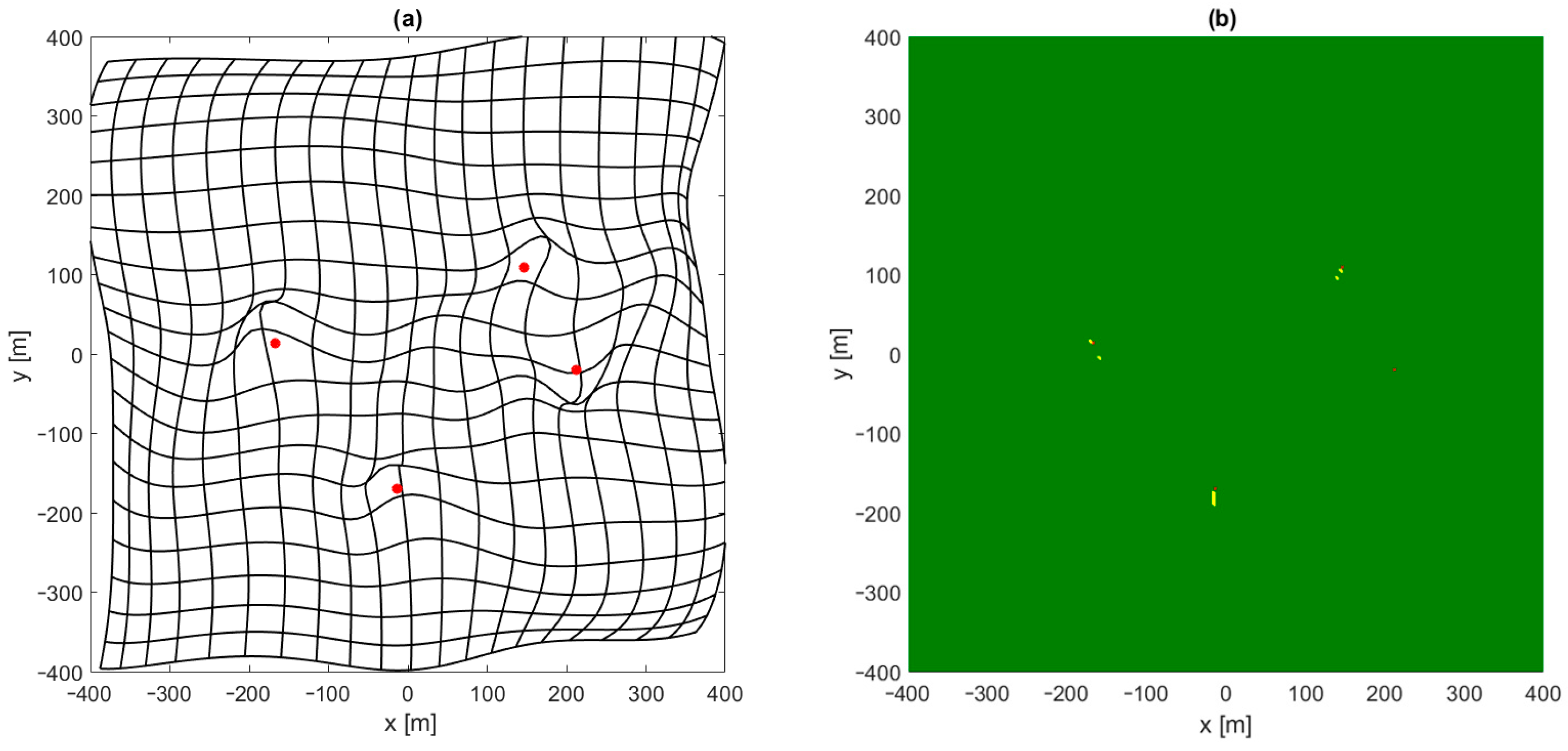
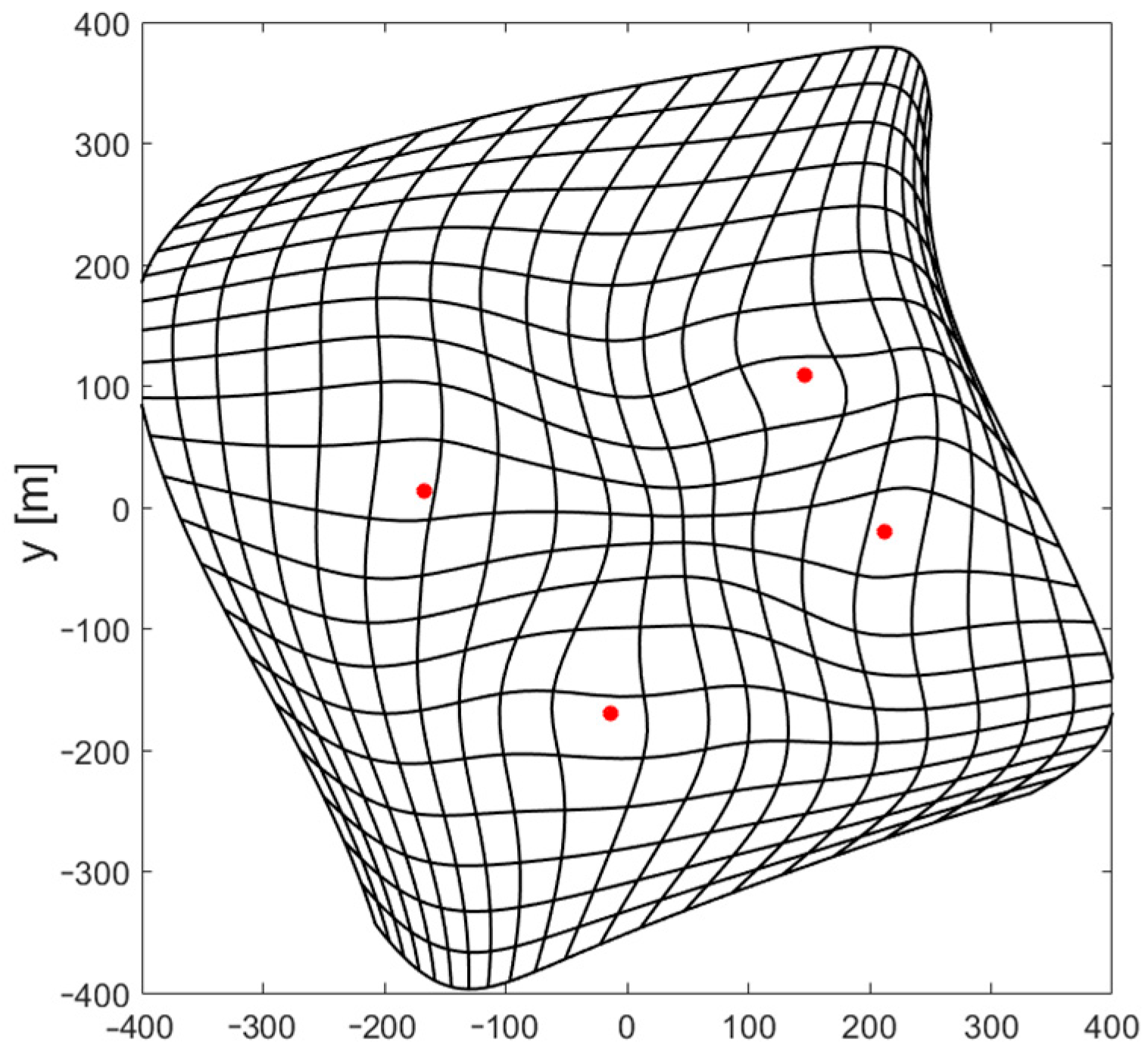
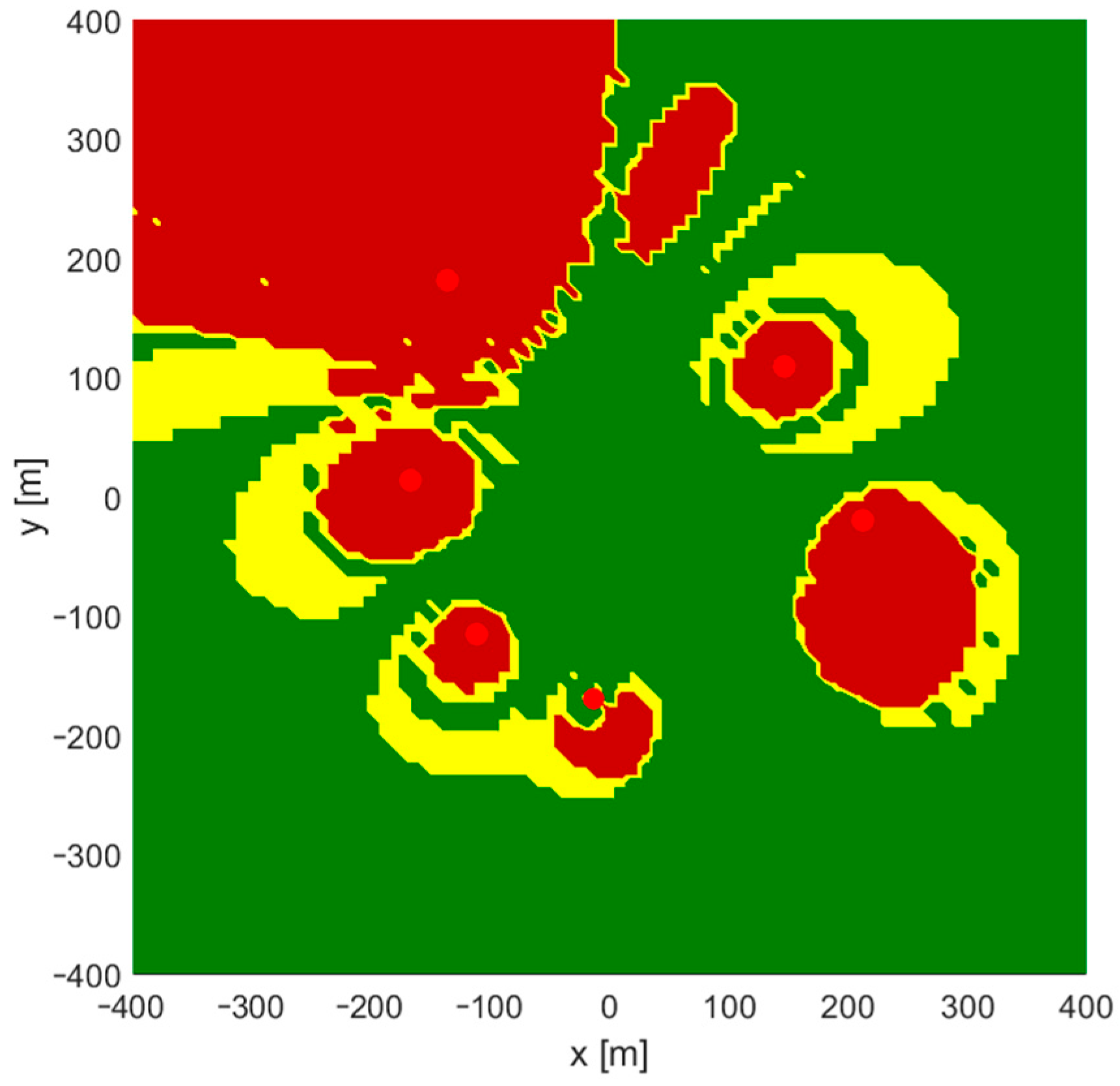
4.1. 2D Case
- Generate test points uniformly distributed in the whole system area with an and step equal to 5 m (25,921 point in total), and calculate TDoA data for all test points;
- Run the iterative position estimation algorithm (Gauss–Newton or Levenberg–Marquardt) with TDoA data corresponding to all test points, with the starting point in origin (, ), and check convergence to correct coordinates;
- Generate reference points for the neural network training: uniformly with an and step equal to 10 m (6561 points in total), or non-uniformly using the rules described later in the article; calculate TDoA data for all reference points;
- Normalize TDoA data and reference points’ coordinates and train the feedforward neural network to predict normalized coordinates using normalized TDoA input data;
- Verify the convergence of the iterative position estimation algorithm (G–N or L–M) using a larger set of test points from step 1 with initial coordinates calculated using the output of a neural network trained using a smaller set of training points from step 3.
4.2. 3D Case
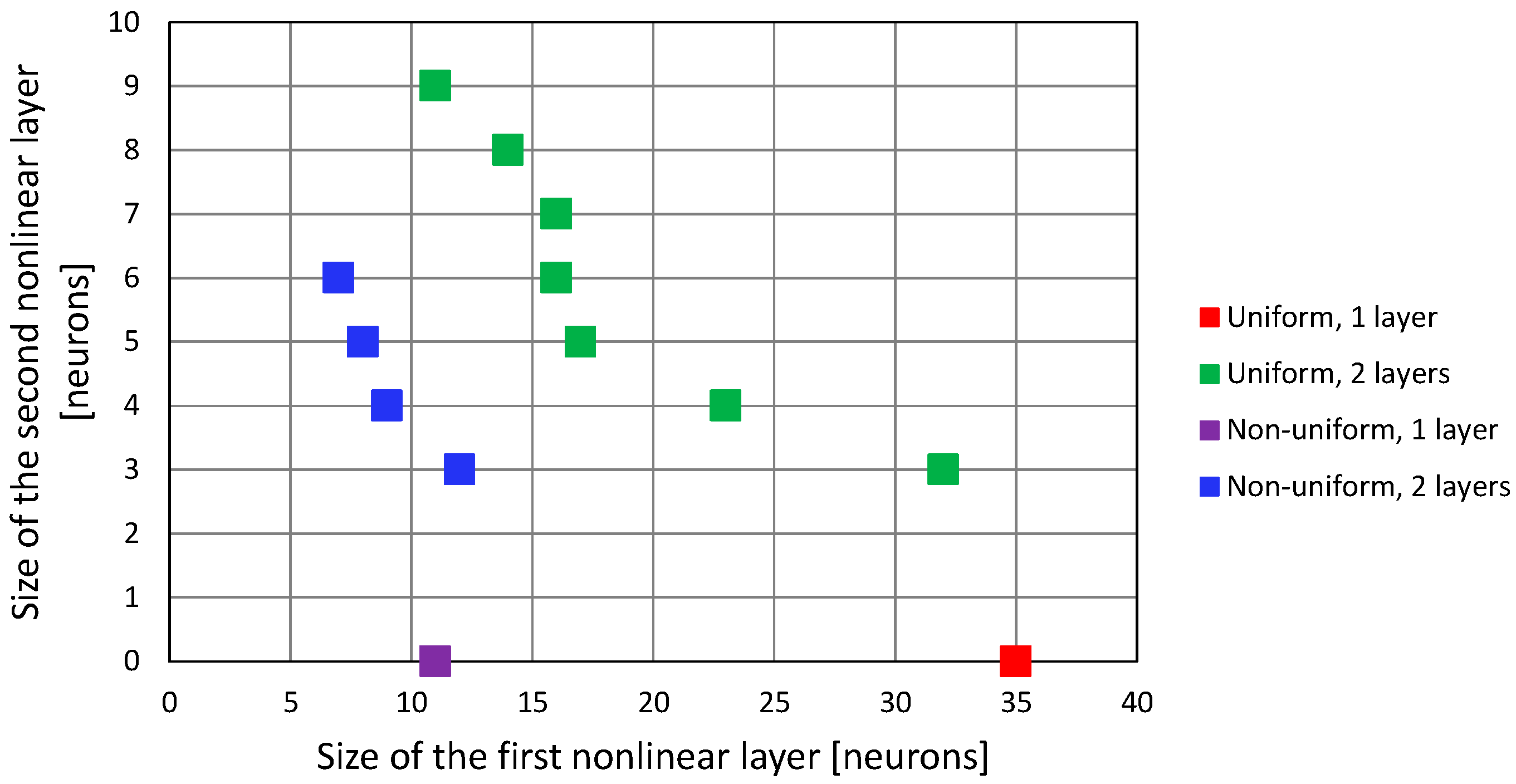
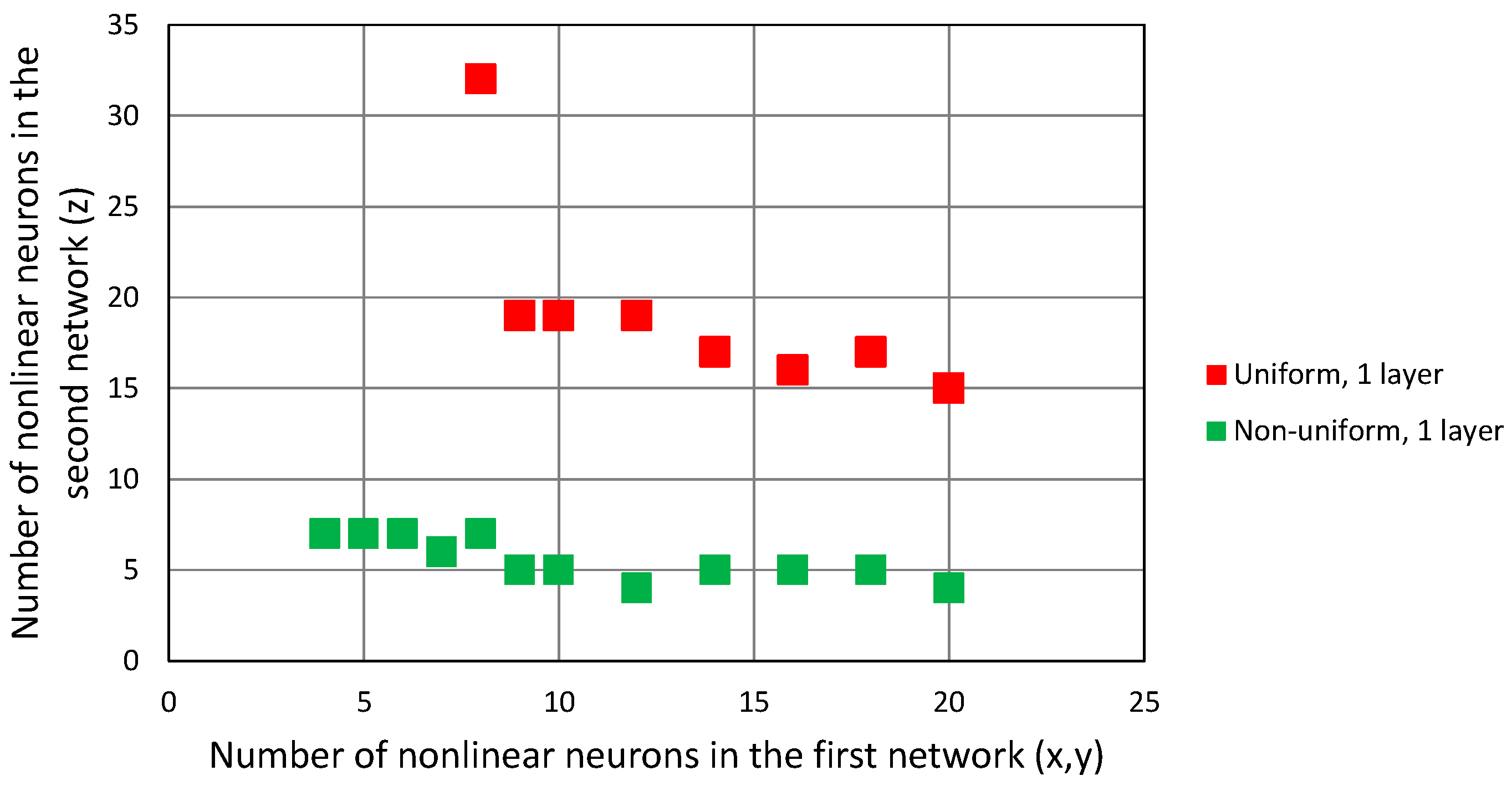
4.2.1. One Network
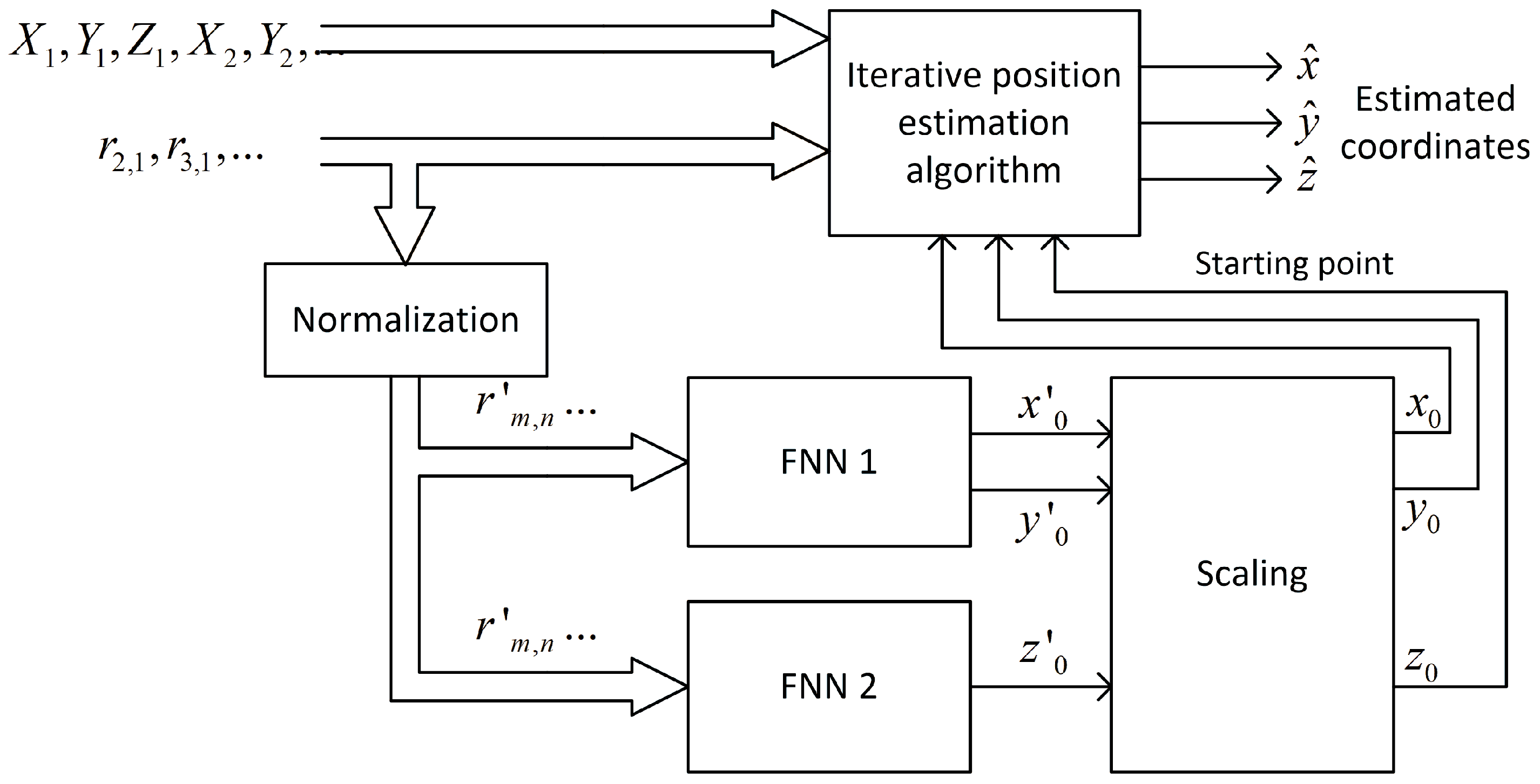
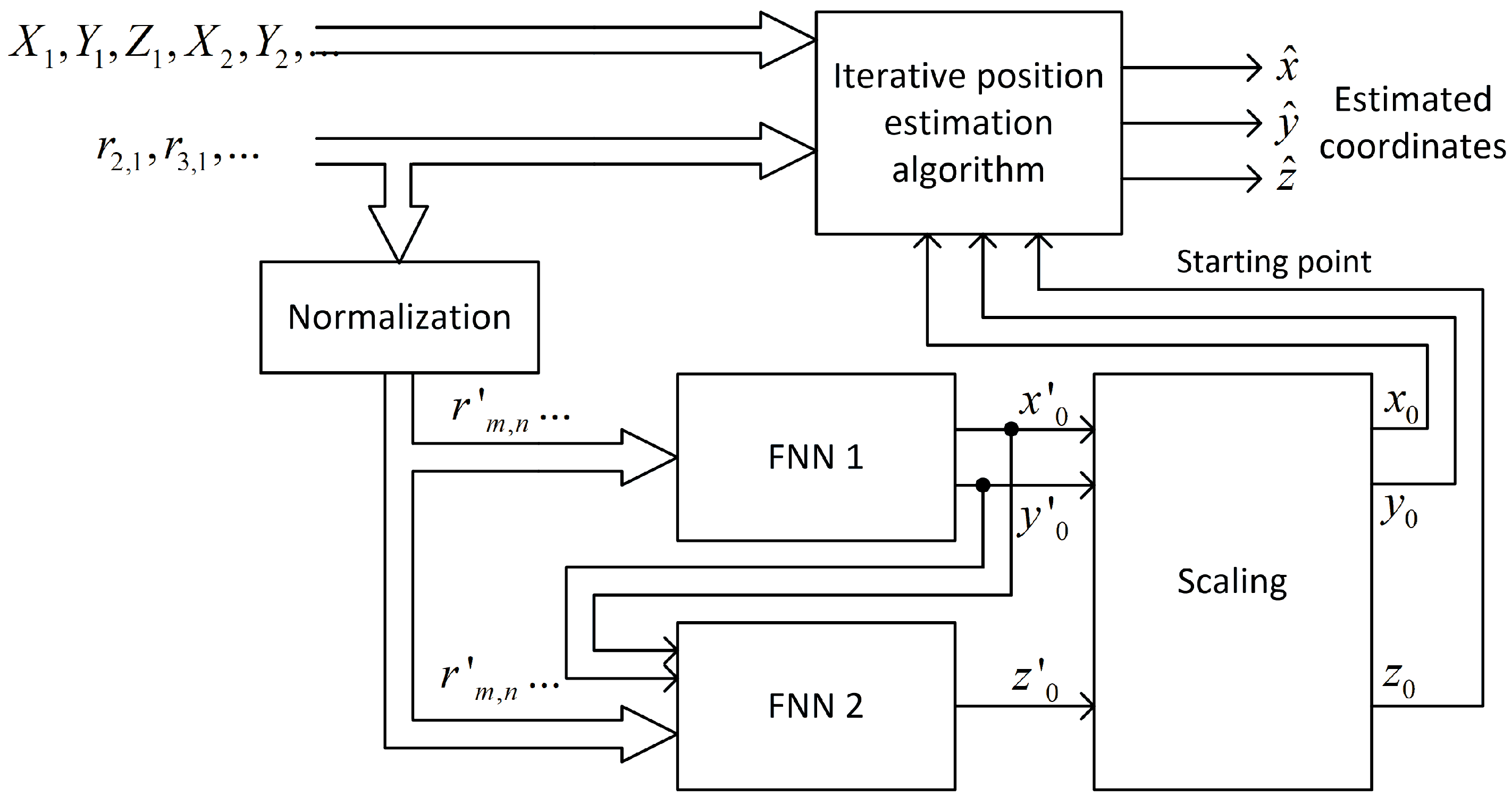
4.2.2. Two Separate Networks
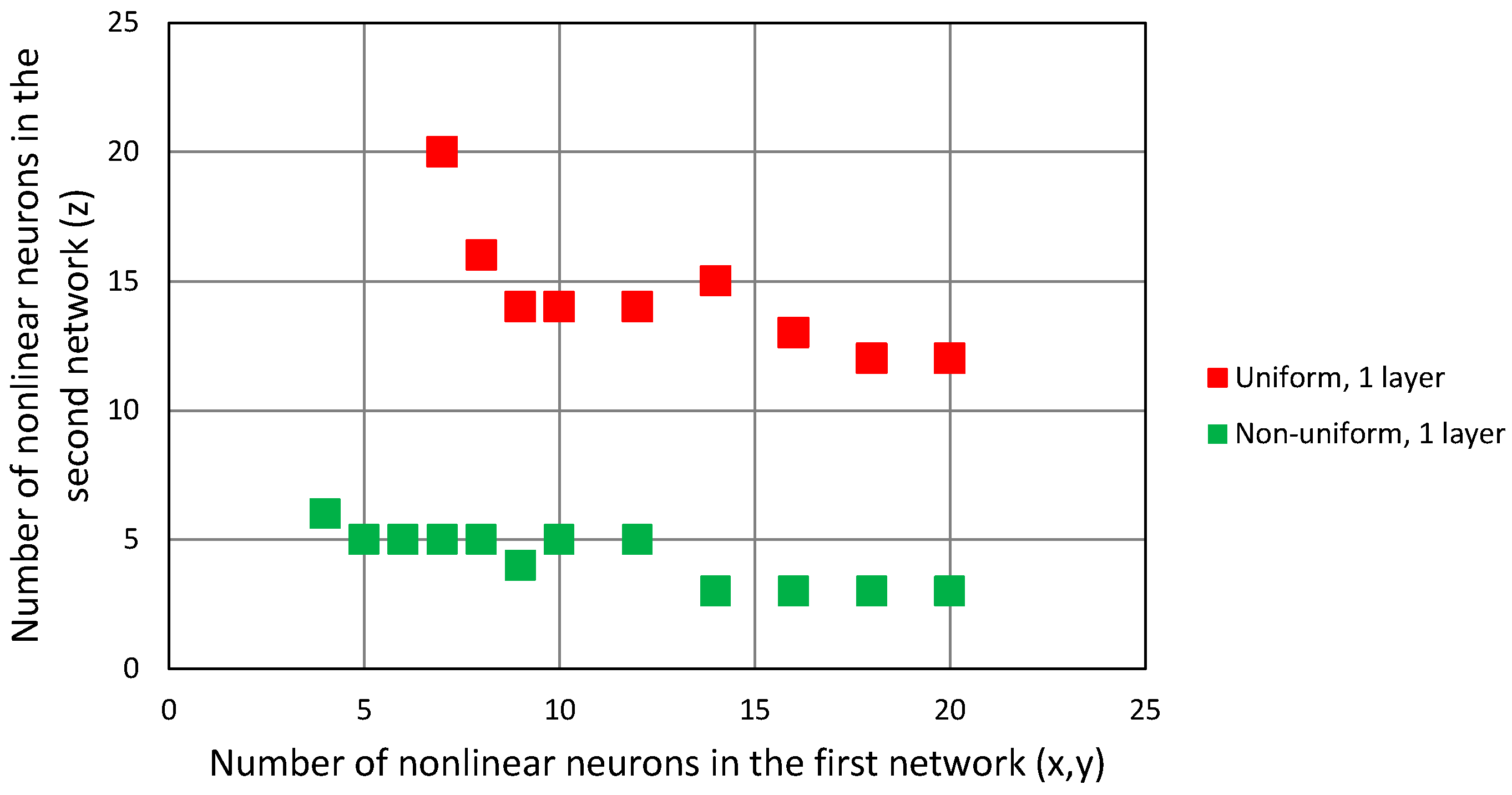
4.2.3. Two Networks Cascaded
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Naseem, A.; Rehman, M.A.; Abdeljawad, T. Numerical Algorithms for Finding Zeros of Nonlinear Equations and Their Dynamical Aspects. J. Math. 2020, 2020, 2816843. [Google Scholar] [CrossRef]
- Marquardt, D.W. An Algorithm for Least-Squares Estimation of Nonlinear Parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Chan, Y.T.; Ho, K.C. A Simple and Efficient Estimator for Hyperbolic Location. IEEE Trans. Signal Process. 1994, 42, 1905–1915. [Google Scholar] [CrossRef]
- Fang, B.T. Simple Solutions for Hyperbolic and Related Position Fixes. IEEE Trans. Aerosp. Electron. Syst. 1990, 26, 748–753. [Google Scholar] [CrossRef]
- Bucher, R.; Misra, D. A Synthesizable VHDL Model of the Exact Solution for Three-dimensional Hyperbolic Positioning System. VLSI Des. 2002, 15, 507–520. [Google Scholar] [CrossRef]
- Sirola, N. Closed-form algorithms in mobile positioning: Myths and misconceptions. In Proceedings of the 2010 7th Workshop on Positioning, Navigation and Communication, Dresden, Germany, 11–12 March 2010; pp. 38–44. [Google Scholar] [CrossRef]
- Czapiewska, A.; Sadowski, J. Analysis of Accuracy of Modified Gradient Method in Indoor Radiolocalisation System. In Proceedings of the 2014 IEEE 79th Vehicular Technology Conference (VTC Spring), Seoul, Republic of Korea, 18–21 May 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Ghorpade, S.; Zennaro, M.; Chaudhari, B. Survey of Localization for Internet of Things Nodes: Approaches, Challenges and Open Issues. Future Internet 2021, 13, 210. [Google Scholar] [CrossRef]
- Laoudias, C.; Moreira, A.; Kim, S.; Lee, S.; Wirola, L.; Fischione, C. A Survey of Enabling Technologies for Network Localization, Tracking, and Navigation. IEEE Commun. Surv. Tutor. 2018, 20, 3607–3644. [Google Scholar] [CrossRef]
- Khan, H.; Hayat, M.N.; Ur Rehman, Z. Wireless sensor networks free-range base localization schemes: A comprehensive survey. In Proceedings of the 2017 International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 8–9 March 2017; pp. 144–147. [Google Scholar] [CrossRef]
- Dwivedi, A.; Vamsi, P.R. Performance analysis of range free localization methods for wireless sensor networks. In Proceedings of the 2017 4th International Conference on Signal Processing, Computing and Control (ISPCC), Solan, India, 21–23 September 2017; pp. 521–526. [Google Scholar] [CrossRef]
- Mok, E.; Cheung, B.K.S. An Improved Neural Network Training Algorithm for Wi-Fi Fingerprinting Positioning. ISPRS Int. J. Geo-Inf. 2013, 2, 854–868. [Google Scholar] [CrossRef]
- Narita, Y.; Lu, S.; Kamabe, H. Accuracy Evaluation of Indoor Positioning by Received Signal Strength using Deep Learning. In Proceedings of the 2022 24th International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Republic of Korea, 13–16 February 2022; pp. 132–136. [Google Scholar] [CrossRef]
- Paudel, K.; Kadel, R.; Guruge, D.B. Machine-Learning-Based Indoor Mobile Positioning Using Wireless Access Points with Dual SSIDs—An Experimental Study. J. Sens. Actuator Netw. 2022, 11, 42. [Google Scholar] [CrossRef]
- Urwan, S.; Wysocka, D.R.; Pietrzak, A.; Cwalina, K.K. Position Estimation in Mixed Indoor-Outdoor Environment Using Signals of Opportunity and Deep Learning Approach. Int. J. Electron. Telecommun. 2022, 68, 594–607. [Google Scholar] [CrossRef]
- Bhatti, G. Machine Learning Based Localization in Large-Scale Wireless Sensor Networks. Sensors 2018, 18, 4179. [Google Scholar] [CrossRef] [PubMed]
- Alhmiedat, T. Fingerprint-Based Localization Approach for WSN Using Machine Learning Models. Appl. Sci. 2023, 13, 3037. [Google Scholar] [CrossRef]
- Gadhgadhi, A.; HachaΪchi, Y.; Zairi, H. A Machine Learning based Indoor Localization. In Proceedings of the 2020 4th International Conference on Advanced Systems and Emergent Technologies (IC_ASET), Hammamet, Tunisia, 15–18 December 2020; pp. 33–38. [Google Scholar] [CrossRef]
- Al-Tahmeesschi, A.; Talvitie, J.; López–Benítez, M.; Ruotsalainen, L. Deep Learning-based Fingerprinting for Outdoor UE Positioning Utilising Spatially Correlated RSSs of 5G Networks. In Proceedings of the 2022 International Conference on Localization and GNSS (ICL-GNSS), Tampere, Finland, 7–9 June 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Avellaneda, D.; Mendez, D.; Fortino, G. A TinyML Deep Learning Approach for Indoor Tracking of Assets. Sensors 2023, 23, 1542. [Google Scholar] [CrossRef] [PubMed]
- Zheng, B.; Masuda, T.; Shibata, T. An Indoor Positioning with a Neural Network Model of TensorFlow for Machine Learning. In Proceedings of the 2021 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hualien City, Taiwan, 16–19 November 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Bellavista-Parent, V.; Torres-Sospedra, J.; Pérez-Navarro, A. Comprehensive Analysis of Applied Machine Learning in Indoor Positioning Based on Wi-Fi: An Extended Systematic Review. Sensors 2022, 22, 4622. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Nguyen, K.A.; Luo, Z. A survey of deep learning approaches for WiFi-based indoor positioning. J. Inf. Telecommun. 2022, 6, 163–216. [Google Scholar] [CrossRef]
- Li, Z.; Xu, K.; Wang, H.; Zhao, Y.; Wang, X.; Shen, M. Machine-Learning-Based Positioning: A Survey and Future Directions. IEEE Netw. 2019, 33, 96–101. [Google Scholar] [CrossRef]
- Alhomayani, F.; Mahoor, M.H. Deep learning methods for fingerprint-based indoor positioning: A review. J. Locat. Based Serv. 2020, 14, 129–200. [Google Scholar] [CrossRef]
- Dvorecki, N.; Bar-Shalom, O.; Banin, L.; Amizur, Y. A Machine Learning Approach for Wi-Fi RTT Ranging. In Proceedings of the International Technical Meeting of The Insitute of Navigation ION ITM 2019, Reston, VA, USA, 28–31 January 2019; pp. 435–444. [Google Scholar] [CrossRef]
- Guidara, A.; Fersi, G.; Jemaa, M.B.; Derbel, F. A new deep learning-based distance and position estimation model for range-based indoor localization systems. Ad Hoc Netw. 2021, 114, 102445. [Google Scholar] [CrossRef]
- Malmström, M.; Skog, I.; Razavi, S.M.; Zhao, Y.; Gunnarsson, F. 5G Positioning—A Machine Learning Approach. In Proceedings of the 2019 16th Workshop on Positioning, Navigation and Communications (WPNC), Bremen, Germany, 23–24 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Gong, X.; Yu, X.; Liu, X.; Gao, X. Machine Learning-Based Fingerprint Positioning for Massive MIMO Systems. IEEE Access 2022, 10, 89320–89330. [Google Scholar] [CrossRef]
- Kotrotsios, K.; Orphanoudakis, T. Accurate Gridless Indoor Localization Based on Multiple Bluetooth Beacons and Machine Learning. In Proceedings of the 2021 7th International Conference on Automation, Robotics and Applications (ICARA), Prague, Czech Republic, 4–6 February 2021; pp. 190–194. [Google Scholar] [CrossRef]
- Cho, J.; Hwang, D.; Kim, K.-H. Improving TDoA Based Positioning Accuracy Using Machine Learning in a LoRaWan Environment. In Proceedings of the 2019 International Conference on Information Networking (ICOIN), Kuala Lumpur, Malaysia, 9–11 January 2019; pp. 469–472. [Google Scholar] [CrossRef]
- Wu, C.; Hou, H.; Wang, W.; Huang, Q.; Gao, X. TDOA Based Indoor Positioning with NLOS Identification by Machine Learning. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Nessa, A.; Adhikari, B.; Hussain, F.; Fernando, X.N. A Survey of Machine Learning for Indoor Positioning. IEEE Access 2020, 8, 214945–214965. [Google Scholar] [CrossRef]
- Isaia, C.; Michaelides, M.P. A Review of Wireless Positioning Techniques and Technologies: From Smart Sensors to 6G. Signals 2023, 4, 90–136. [Google Scholar] [CrossRef]
- Kabiri, M.; Cimarelli, C.; Bavle, H.; Sanchez-Lopez, J.L.; Voos, H. A Review of Radio Frequency Based Localisation for Aerial and Ground Robots with 5G Future Perspectives. Sensors 2023, 23, 188. [Google Scholar] [CrossRef] [PubMed]
- Shen, G.; Zetik, R.; Thoma, R.S. Performance comparison of TOA and TDOA based location estimation algorithms in LOS environment. In Proceedings of the 2008 5th Workshop on Positioning, Navigation and Communication, Hannover, Germany, 27 March 2008; pp. 71–78. [Google Scholar] [CrossRef]
- Yan, J.; Tiberius, C.; Bellusci, G.; Janssen, G. Feasibility of Gauss-Newton method for indoor positioning. In Proceedings of the 2008 IEEE/ION Position, Location and Navigation Symposium, Monterey, CA, USA, 5–8 May 2008; pp. 660–670. [Google Scholar] [CrossRef]
- Bancroft, S. An Algebraic Solution of the GPS Equations. IEEE Trans. Aerosp. Electron. Syst. 1985, AES-21, 56–59. [Google Scholar] [CrossRef]
- Mensing, C.; Plass, S. Positioning Algorithms for Cellular Networks Using TDOA. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, France, 14–19 May 2006; p. IV. [Google Scholar] [CrossRef]
- Foy, W.H. Position-Location Solutions by Taylor-Series Estimation. IEEE Trans. Aerosp. Electron. Syst. 1976, AES-12, 187–194. [Google Scholar] [CrossRef]
- Levenberg, K. A method for the solution of certain non-linear problems in least squares. Q. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef]
- Umar, A.O.; Sulaiman, I.M.; Mamat, M.; Waziri, M.Y.; Zamri, N. On damping parameters of Levenberg-Marquardt algorithm for nonlinear least square problems. J. Phys. Conf. Ser. 2020, 1734, 012018. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 31 October 2023).
- Sobehy, A. Machine Learning Based Localization in 5G. Ph.D. Thesis, Institut Polytechnique de Paris, Palaiseau, France, 2020. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Year | Environment | Radio Interface | Meas. Param. | Network Type and Size | Netw. Use | Performance | Comments |
|---|---|---|---|---|---|---|---|---|
| Mok et al. [12] | 2013 | University building | Wi-Fi | RSS (M) | FNN/MLP, 1 L/5 N | PE | MSE 2.6 to 23 m | |
| Narita et al. [13] | 2021 | 7 × 4 m room | Wi-Fi | RSS (M) | FNN/MLP, 5 L/500 N | PE/FP | Avg. 0.93 m, max. 6.7 m | |
| Paudel et al. [14] | 2022 | 2 rooms in univ. building | Wi-Fi dual band | RSS (M) | SVR, LR, KNN, other | PE/FP | Avg. 2.2 m | |
| Urwan et al. [15] | 2022 | Indoor (university building) and outdoor | Wi-Fi and LTE | RSS (M) | FNN/MLP 2–5 L/169–311 N | PE/FP | 0.9 to 25 m indoor, 12.7 to 55.4 m outdoor | Separate models for indoor and outdoor |
| Bhatti [16] | 2018 | 100 × 100 m | Simulation | RSS (S) | LR/SVM | PE | Approx. 0.6 m | |
| Alhmiedat [17] | 2023 | University lab, 21 × 7.6 m | ZigBee | RSS (M) | LR/KNN/DT/RF | PE | ME 1.4–4.6 m | |
| Gadhgadhi et al. [18] | 2020 | 10 × 10 m | No data | RSS (S) | FNN/MLP 1 L/3–4 N | PE | 1.1 m | |
| Al-Tahmeesschi et al. [19] | 2022 | Outdoor, Madrid simulator | 5G mmWave | RSS (S) | KNN/MLP/LSTM 3 L/1024/512/64 N | PE | ME: 0.5–5.4 | |
| Avellaneda et al. [20] | 2023 | Two-bedroom apartment | BLE | RSS (M) | FNN/MLP 2 L/10 + 20 N | PE/Class | 88% to 97% class. prob. | |
| Zheng et al. [21] | 2021 | Laboratory 10 × 20.6 m | EnOcean | RSS (M) | FNN/SVM 1–5 L/4 N | Class | 96% class. prob. | |
| Dvorecki et al. [26] | 2019 | Office 45 × 25 m | Wi-Fi | RTT (M) | FNN 6L/228/50/251 N | FE | Mean range error 0.7–2 m | |
| Guidara et al. [27] | 2021 | Laboratory 9 × 9 m | 868 MHz | RSS, LQI, T, RH (M) | FNN/LP 1–5 L/4–8 N | FE | Mean range error 0.92 m | |
| Malmström et al. [28] | 2019 | Outdoor, urban area | 5G 15 GHz | RSRP (M) | FNN/RF 2 L/12–16 N | PE | ME 2–39 m | Antenna array 8 × 8 |
| Gong et al. [29] | 2022 | Outdoor 50 × 50 m | MIMO OFDM | CSI (S) | FNN/MLP 2 L/128 + 128 N | PE/FP | ME 0.4–0.9 m | Linear antenna array |
| Kotrotsios et al. [30] | 2021 | One apartment | BLE | RSS (M) | FNN/MLP 2 L/64 N | FE | ME 0.7 m | |
| Cho et al. [31] | 2019 | Outdoor 6 × 6 km | LoRa | TDoA (S) | FNN | FE | ME 61 m | TDoA data conditioning |
| Wu et al. [32] | 2018 | 10 × 10 m | No data | TDoA (S) | SVM | FE | Up to 99% LOS/NLOS det. prob. | LOS/NLOS identification |
| Station Number | X [m] | Y [m] | Z [m] | 2D | 3D |
|---|---|---|---|---|---|
| 1 | 146 | 109 | 20 | ✓ | ✓ |
| 2 | −14 | −170 | 27 | ✓ | ✓ |
| 3 | −167 | 14 | 26 | ✓ | ✓ |
| 4 | 212 | −20 | 23 | ✓ | ✓ |
| 5 | −136 | 181 | 15 | ✓ | |
| 6 | −112 | −116 | 20 | ✓ |
| Position Estimation Algorithm | Test Point Step (x/y) | Total Number of Test Points | Points with Correct Convergence | Probability of Correct Convergence | Average Number of Iterations | Maximum Number of Iterations |
|---|---|---|---|---|---|---|
| Gauss-Newton | 5 m | 25,921 | 25,648 | 98.946% | 8.007 | 92 |
| Levenberg–Marquardt | 5 m | 25,921 | 25,189 | 97.176% | 12.89 | 94 |
| FNN | Iterative Position Estimation Convergence | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Input Layer | Hidden Layer 1 | Hidden Layer 2 | Output Layer | Position Estimation RMS Error [m] | Position Estimation Maximum Error [m] | Tested Points | Correct Convergence | Probability of Convergence | Average Number of Iterations | Maximum Number of Iterations |
| 12: lin | 50: tanh | - | 2: lin | 1.27 | 12.59 | 25,921 | 25,921 | 100 | 3.95 | 12 |
| 12: lin | 30: tanh | - | 2: lin | 1.61 | 9.87 | 25,921 | 25,921 | 100 | 3.98 | 11 |
| 12: lin | 15: tanh | - | 2: lin | 10.91 | 62.64 | 25,921 | 25,921 | 100 | 4.47 | 12 |
| 12: lin | 10: tanh | - | 2: lin | 14.43 | 63.38 | 25,921 | 25,921 | 100 | 4.67 | 15 |
| 12: lin | 8: tanh | - | 2: lin | 18.31 | 66.6 | 25,921 | 25,921 | 100 | 4.81 | 16 |
| 12: lin | 7: tanh | - | 2: lin | 18.93 | 73.47 | 25,921 | 25,920 | 99.996 | 4.84 | 15 |
| 12: lin | 20: tanh | - | 2: tanh | 6.63 | 41.88 | 25,921 | 25,921 | 100 | 4.24 | 16 |
| 12: lin | 15: tanh | - | 2: tanh | 15.64 | 71.4 | 25,921 | 25,920 | 99.996 | 4.69 | 10 |
| 12: lin | 10: log | - | 2: lin | 10.73 | 55.74 | 25,921 | 25,921 | 100 | 4.5 | 56 |
| 12: lin | 7: log | - | 2: lin | 24.25 | 93.25 | 25,921 | 25,921 | 100 | 4.94 | 8 |
| 12: lin | 6: log | - | 2: lin | 26.25 | 109.9 | 25,921 | 25,920 | 99.996 | 4.94 | 8 |
| 12: lin | 15: ell | - | 2: lin | 5.66 | 31.15 | 25,921 | 25,921 | 100 | 4.22 | 15 |
| 12: lin | 12: ell | - | 2: lin | 9 | 57 | 25,921 | 25,920 | 99.996 | 4.41 | 16 |
| 12: lin | 20: rad | - | 2: lin | 6.36 | 38.13 | 25,921 | 25,921 | 100 | 4.22 | 8 |
| 12: lin | 15: rad | - | 2: lin | 10.49 | 45.8 | 25,921 | 25,920 | 99.996 | 4.43 | 21 |
| 12: lin | 10: tanh | 4: tanh | 2: lin | 6.05 | 26.26 | 25,921 | 25,921 | 100 | 4.24 | 15 |
| 12: lin | 4: tanh | 4: tanh | 2: lin | 16.13 | 76.97 | 25,921 | 25,921 | 100 | 4.73 | 19 |
| 12: lin | 6: tanh | 3: tanh | 2: lin | 11.61 | 55.87 | 25,921 | 25,921 | 100 | 4.5 | 10 |
| 12: lin | 5: tanh | 3: tanh | 2: lin | 19.98 | 77.67 | 25,921 | 25,920 | 99.996 | 4.83 | 10 |
| 12: lin | 12: tanh | 2: tanh | 2: lin | 9.15 | 41.42 | 25,921 | 25,921 | 100 | 4.42 | 11 |
| 12: lin | 10: tanh | 2: tanh | 2: lin | 13.1 | 62.1 | 25,921 | 25,919 | 99.992 | 4.59 | 12 |
| FNN | Iterative Position Estimation Convergence | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Input Layer | Hidden Layer 1 | Hidden Layer 2 | Output Layer | Position Estimation RMS Error [m] | Position Estimation Maximum Error [m] | Tested Points | Correct Convergence | Probability of Convergence | Average Number of Iterations | Maximum Number of Iterations |
| 12: lin | 50: tanh | - | 2: lin | 0.93 | 7.46 | 25,921 | 25,921 | 100 | 10.17 | 13 |
| 12: lin | 30: tanh | - | 2: lin | 1.63 | 9.51 | 25,921 | 25,921 | 100 | 10.33 | 14 |
| 12: lin | 15: tanh | - | 2: lin | 6.94 | 33.03 | 25,921 | 25,921 | 100 | 10.67 | 14 |
| 12: lin | 10: tanh | - | 2: lin | 21.97 | 95.25 | 25,921 | 25,921 | 100 | 10.92 | 19 |
| 12: lin | 8: tanh | - | 2: lin | 18.73 | 77.25 | 25,921 | 25,920 | 99.996 | 10.86 | 16 |
| 12: lin | 8: tanh | 4: tanh | 2: lin | 10.14 | 47.67 | 25,921 | 25,921 | 100 | 10.75 | 19 |
| 12: lin | 4: tanh | 4: tanh | 2: lin | 22.88 | 85.7 | 25,921 | 25,921 | 100 | 10.94 | 16 |
| 12: lin | 4: tanh | 3: tanh | 2: lin | 25.06 | 88.4 | 25,921 | 25,921 | 100 | 10.96 | 14 |
| 12: lin | 5: tanh | 2: tanh | 2: lin | 34.6 | 137.5 | 25,921 | 25,921 | 100 | 10.99 | 19 |
| 12: lin | 4: tanh | 2: tanh | 2: lin | 34.95 | 119.3 | 25,921 | 25,917 | 99.98 | 10.96 | 18 |
| Position Estimation Algorithm | Iterative Position Estimation Convergence | ||||
|---|---|---|---|---|---|
| Tested Points | Correct Convergence | Probability of Convergence | Average Number of Iterations | Maximum Number of Iterations | |
| Gauss–Newton | 25,921 | 25,921 | 100 | 5.19 | 7 |
| Levenberg–Marquardt | 25,921 | 25,921 | 100 | 11.11 | 15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadowski, J.; Stefanski, J. A Selection of Starting Points for Iterative Position Estimation Algorithms Using Feedforward Neural Networks. Sensors 2024, 24, 332. https://doi.org/10.3390/s24020332
Sadowski J, Stefanski J. A Selection of Starting Points for Iterative Position Estimation Algorithms Using Feedforward Neural Networks. Sensors. 2024; 24(2):332. https://doi.org/10.3390/s24020332
Chicago/Turabian StyleSadowski, Jaroslaw, and Jacek Stefanski. 2024. "A Selection of Starting Points for Iterative Position Estimation Algorithms Using Feedforward Neural Networks" Sensors 24, no. 2: 332. https://doi.org/10.3390/s24020332
APA StyleSadowski, J., & Stefanski, J. (2024). A Selection of Starting Points for Iterative Position Estimation Algorithms Using Feedforward Neural Networks. Sensors, 24(2), 332. https://doi.org/10.3390/s24020332