1. Introduction
In the modern world, the importance of protecting digital data is very high. Information security is an important part of cyberspace security, ensuring that secret data are not illegally stolen, altered, or damaged by malicious individuals during the transmission phase. It is not only a national matter, but also a matter related to the interests of the people, and is related to a harmonious society. One of the methods to ensure the security of digital data is to use steganography. This is particularly applicable to various multimedia data, such as images, audio, videos, etc. The use of steganography to hide information is an increasingly mature and developing scientific field.
In order to clarify the technical background more clearly, we strictly distinguish the concepts of steganography and watermarking here. Steganography schemes mainly focus on capacity, invisibility, and security, and their protected object is confidential information; watermarking schemes mainly focus on robustness and invisibility, and their protected object is the carrier. Current steganography communication mostly adopts steganography technology, seldom considering the use of robust watermarking technology in noisy channels under big data backgrounds. This article mainly focuses on image carriers. Therefore, we first introduce the current state of image steganography, and then put forward the idea of introducing robust image watermarking schemes for secure communication in noisy channels, grounded in a big data context. Thus, we analyze the current situation of existing robust image watermarking schemes, and then address their shortcomings, and finally introduce our robust image watermarking method and the fragmented covert communication scheme based on this method.
The technical idea of image steganography is to invisibly modulate secret information into the carrier image and transmit it through open channels. This not only hides the transmitted information but also conceals the existence of secret communication, making it a safe and reliable information transmission method in network environments. In particular, if the image steganography scheme can adapt to open network channels, it can more effectively achieve convenient and secure covert communication of secret information. Traditional image steganography techniques are usually based on the assumption of lossless channels [
1]. In the past ten years, many traditional image steganography schemes have been proposed. They can be mainly divided into seven categories [
2]: (1) LSB (least significant bit)-based scheme [
3]. The method [
3] has very good invisibility but insufficient capacity. It avoids the overflow and underflow problem, but steganalysis is missing; therefore, it is hard to predict the dependability of the work. (2) LSB matching-based scheme [
4]. The method [
4] has outstanding invisibility but unsatisfactory capacity. It has good resistance against regular and singular (RS) analysis and pixel difference histogram (PDH) analysis. (3) PVD (pixel value differencing)-based scheme [
5]. The method [
5] has very good invisibility but unsatisfactory capacity. It considers robust techniques as multi-directions, but it is unacceptable for approaches needing supplementary capacity. (4) PVD+LSB-based scheme [
6]. The method [
6] has outstanding invisibility and high capacity. However, steganalysis is missing; therefore, it is hard to predict the dependability of the work. (5) MF (modulus function)+PVD-based scheme [
7]. The method [
7] has very good invisibility and satisfactory capacity, and it avoids the falling-out boundary issue. However, PDH analysis is missing; therefore, it is hard to predict the dependability of the work. (6) RDH (reversible data hiding) + MF-based scheme [
8]. The method [
8] has satisfactory invisibility and satisfactory capacity, and it withstands histogram analysis. However, its capacity and invisibility can be further improved, therefore, it is hard to predict the dependability of the work. (7) RDH+PVO (pixel value ordering)-based scheme [
9]. The method [
9] has outstanding invisibility but unsatisfactory capacity. It has better results compared to existing RDH+PVD techniques. However, steganalysis is missing; therefore, it is hard to predict the dependability of the work.
The main problem with traditional image steganography schemes is that they lean toward capacity but give insufficient attention to robustness. However, in actual open network channels, it is not only necessary for the stego image, produced after steganography, to be indistinguishable from the original carrier image to the naked eye, but also essential to ensure that the embedded secret information can be correctly extracted after being subjected to various image-processing methods or attacks that may exist in the channel. As shown in
Figure 1, after the sender embeds secret information in the carrier image, the stego image output is often transmitted over open network channels, e.g., social platforms such as QQ, Facebook, Twitter, and WeChat. Due to bandwidth limitations and limited processing power, uploaded stego images must undergo lossy operations such as compression and scaling, resulting in a certain degree of image degradation [
10]. After receiving the stego image, which may have been subjected to attack processing, in order to extract the secret information completely and reliably, it is necessary to use strong robust embedding and extraction algorithms in algorithm design.
In response to the aforementioned practical needs, many scholars have achieved fruitful research results in robust image steganography after years of research and exploration efforts. Robust steganography technology focuses on solving the invisibility and extraction accuracy of the embedded secret information in the stego image after various processing attacks. The basic idea is to comprehensively consider the anti-attack ability and imperceptibility during embedding, and combine the embedding cost minimization coding method to achieve high reliability and large embedding capacity for secure communication. For the demand of covert communication in lossy network channels, the commonly used methods for robust image steganography schemes include: (1) constructing or finding specific carriers with strong resistance to attacks, usually robust transform domain coefficients [
11], invariant features, and robust relative relationships; (2) estimating embedding losses and costs [
12], and comprehensively examining attack resistance and imperceptibility; (3) finding the optimal embedding region, which generally requires the region to be embedded to have complex textures and be difficult to model statistically [
13]; (4) integrating source/channel encoding technology with the idea of minimizing embedding distortion encoding [
14]; (5) combining stable, reliable, and covert security strategies [
15]. The purpose of these five technical measures is to design information embedding and extraction methods that are sufficiently robust to common processing operations such as compression and scaling. These methods can make up for the shortcomings of previous traditional image steganography algorithms in terms of both attack resistance and invisibility, thereby becoming a new focus of attention in the field of image information hiding.
The architecture of robust image steganography technology [
11,
12,
13,
14,
15] includes six parts, namely: how to filter carrier images, how to find or construct robust carriers, what embedding cost measures to use, how to filter embedding regions, how to combine source/channel encoding, and how to design security policies. The first step is to screen suitable carrier images. Not all images are suitable as covert communication carriers, and it is usually necessary to select images with complex textures that make it difficult to see the embedded information after hiding it as the carrier. The second step is to find or construct a robust vector. The purpose is to design transform domain coefficients or features or relative relationships that are stable and robust to various image-processing attacks while balancing invisibility and robustness. The third step is to choose a reasonable embedding cost measure. The core purpose is to measure the embedding cost of carrier elements, fully consider robustness and invisibility, and provide quantitative indicators. The fourth step is to filter the embedded region or channel. The core purpose is to fully consider the characteristics of lossy channels to select image regions with complex textures and robust features to hide information, leaving enough modification space to optimize performance. The fifth step is to combine source/channel encoding. Its core purpose is to design effective error control coding methods and provide a theoretical basis for secure and reliable transmission. The sixth step is to design a security strategy. Its purpose is to design communication protocols and strategies, as well as provide application guidance. From the above six aspects, it can be seen that robust image steganography technology needs to have strong security, like adaptive image steganography technology, and strong robustness, like robust image watermarking technology. It also needs to consider both the detection resistance of disguised images and the robustness of embedded information.
In this paper, we consider the situation where we have big image databases in hand and we need to transmit a secret file over social platforms with attacks. An immediate idea involves fragmenting the secret file and hiding the fragments within a number of images using robust image steganography schemes. In fact, any robust watermarking method can be also adopted in this fragmented information-hiding situation based on big image databases, since in this situation, the requirements of steganalysis security and capacity for a single image are largely weakened. That is, under the big data situation, capacity and security are not so important for a single image, while the robustness against attacks during the transmission is very important. Then, it is proposed that robust image watermarking technology can be fully utilized to solve the problem in noisy channels under big data environments. Robust watermarking technology aims to solve the problem of accurately detecting watermark information even when watermarked images are subjected to various attacks and processing. The basic idea is to construct an embedding domain that is sufficiently robust to various common attacks [
16]. It also requires the fusion of redundant embedding and error correction coding schemes to achieve efficient and robust information embedding and extraction. Robust image watermarking algorithms include spatial domain-based methods, transform domain-based methods, and other methods. Currently, the main research field regarding image watermarking focuses on transform domain-based methods.
The spatial domain-based image watermarking algorithm embeds watermarks by modifying the pixel values of the host image. Old algorithms, including LSB replacement algorithms, will not be mentioned here. The latest algorithms are as follows: Ghadi et al. [
17] proposed a spatial domain image watermarking method, which utilizes association rule mining and texture analysis of digital images to embed watermarks in strong texture regions. This not only achieves good imperceptibility but also enhances the ability to resist attacks. Kumar and Singh [
18] proposed a spatial domain image watermarking method that combines the Hill cipher and LSB (least significant bit) substitution. The two-dimensional code is embedded into the grayscale host image, which has good invisibility but general robustness. Liu et al. [
19] proposed a watermarking scheme based on the logistic mapping scrambling algorithm and RSA asymmetric encryption algorithm to provide security for data with large embedding capacity. In addition, reference [
20] proposed a moment-based watermarking method.
Frequency domain watermarking first involves transforming the host image, commonly including matrix decomposition, three major transformations (namely discrete wavelet transform (DWT) [
21,
22,
23,
24,
25], discrete cosine transform (DCT) [
26,
27,
28,
29,
30], and discrete Fourier transform (DFT) [
31,
32,
33,
34]), and other transformations [
20,
35,
36,
37,
38,
39], followed by modifying the transform coefficients to embed the watermark.
Guo et al. [
21] proposed a new method for DWT (discrete wavelet transform), i.e., QRD (QR decomposition) subspace image watermarking based on the FA (firefly algorithm). Reference [
22] proposed an image watermarking scheme in the wavelet domain with optimized compensation of a singular value decomposition via the artificial bee colony. In [
23], a hybrid watermarking scheme based on DWT and SVD in addition to a deep belief neural (DBN) network was proposed. However, this method does not perform well for image-processing attacks with severe parameters. Amini et al. [
24] proposed a wavelet-based watermark decoder based on vector HMM (the hidden Markov model) because they can capture the distribution of subband edges and fully incorporate the cross-scale and cross-directional dependencies of wavelet coefficients. In [
25], an image watermarking scheme by using advantages of both frequency domain and wavelet domain was proposed, which is very robust to Gaussian noise, but the robustness against geometrics is not high and the complexity is not low.
The algorithm based on two-dimensional discrete cosine transform (2D-DCT) proposed by Yuan et al. [
26] can effectively resist multiple attacks. Earnawan and Kabir [
27] proposed a watermarking technique based on the optimal DCT psychological visual threshold, which embeds scrambled watermark bits into certain frequency regions of the DCT to minimize the impact of image distortion. Zhou et al. [
28] proposed a GCC-based watermarking method to improve robustness against geometric transformation attacks. Zong et al. [
29] proposed a level-based watermarking method, which uses 2D-DCT on each host image and embeds the watermark into the DCT coefficients of the host image block using rank-based embedding rules. The watermark is extracted by comparing the levels of the detection matrix generated from the received image using a key, achieving a very high embedding capacity. The scheme proposed by Hatoum et al. [
30] adopts spread transform dithering modulation (STDM), which applies DCT to the host image when embedding the watermark, and then embeds the watermark bit through NSTDM (normalized STDM). After applying IDCT in the extraction stage, the NSTDM decoder is implemented to detect the watermark bit.
Jamal et al. [
31] proposed a watermarking algorithm based on replacement boxes and DFT; it is highly robust and secure against different types of attacks, but also has high complexity. Liao and Yin [
32] proposed a watermarking algorithm using DFT and coefficient classification, which has good imperceptibility and robustness, but takes a long time. Reference [
33] proposed a perceptual DFT watermarking scheme with improved detection and robustness to geometrical distortions. In 2021, Begum and Uddin [
34] implemented a secure and robust DFT-based image watermarking scheme through hybridization with the decomposition algorithm.
Reference [
35] achieved watermark embedding and extraction by discovering and utilizing the correlation between the two coefficients in the U matrix of SVD. Liu et al. [
36] presented a fusion-domain color image watermarking scheme based on Haar transform and image correction. Wang et al. [
37] proposed a blind watermarking algorithm for dual-color images using discrete Hartley transform (DHT). It mainly used the image’s geometric features, such as sides and angles, to correct the attacked image and embedded a color watermark into a color image with a large embedding capacity and strong practicability. However, this algorithm is not robust to rotation of 90°. The color image watermarking using new fractional-order exponent moments in [
20] is very robust to different kinds of geometric distortions and attacks, but the complexity is very high and the efficiency is not high enough for industrial use. In [
38], a blind watermarking algorithm based on contourlet transform with singular value decomposition was proposed, but this method is not robust enough to rotation and collage attacks and the complexity is high. In [
39], synchronization correction is used in robust image watermarking.
There are also some reversible watermarking schemes. Meng et al. [
40] proposed a reversible watermark based on integer wavelet transform (IWT) that embeds binary watermarks into the diagonal components of the grayscale main image. Its invisibility is very good, but the embedding ability and robustness need to be improved. Wang et al. [
41] proposed a scheme for implementing reversible watermarks using prediction error extension (PEE), which fully combines the advantages of PEE and histogram shift, which can improve prediction accuracy and achieve good results. In [
42], a robust and reversible color image watermarking algorithm in the spatial domain fusing discrete Fourier transform (DFT) was proposed, but the scheme is not robust to rotation and collage, and the complexity is not low. In addition to digital image hiding, there are also some other security schemes for images, such as visual cryptography (VC) schemes [
43,
44]. In VC, from one individual visual key, no information about the secret image can be extracted. After the multiple visual keys are overlapped, the secret image can be displayed but each individual key cannot be directly observed from the overlapped result. This is another solution to hiding secret information.
Although the above robust image watermarking schemes can be applied to the fragmented information-hiding situation, many recent robust watermarking schemes are not fast enough and are not so robust to combined attacks, especially combined RST attacks. In fact, although image watermarking techniques can be used in many scenarios, they have not been large-scale used yet in the industry. There are two reasons, one is that the watermarking efficiency is often ignored; the other is that the scheme cannot resist various attacks. From above, we can see that many existing state-of-the-art methods based on different domains cannot achieve both high robustness and fast speed and, thus, they are not so suitable to industrial circles. In order to apply digital watermarking techniques to covert communication with robust performance, we provide a multi-domain image watermarking scheme, including DFT-based watermarking and DCT-based watermarking layers. The first watermarking layer is based on DFT for image synchronization, and the second watermarking layer is based on DCT for embedding information.
The rest of this paper is organized as follows. In
Section 2, a detailed scheme, including the hiding and extracting processes, is described.
Section 3 is the experimental part with analysis. Finally, the conclusions will be shown in
Section 4.
2. Proposed Scheme
2.1. Basic Idea
Although traditional steganography schemes offer good security, they cannot be directly applied to real social network platforms. Due to limited memory and bandwidth, stego images uploaded to social networking platforms inevitably undergo various lossy operations, such as reapplying jpeg compression to reduce size. However, traditional steganography schemes mainly considered an ideal laboratory environment, resulting in most of these schemes being unsuitable for real communication network platforms. Nowadays, almost everyone possesses a smartphone and is accustomed to using social network platforms to share music, images, and videos, which has created a covert communication ecosystem. Therefore, there is significant potential to develop robust covert communication schemes based on robust steganography/watermarking methods for social network platforms.
In this paper, we propose a novel fragmented secure communication system for covert communication in lossy channels, fully considering various attacks that images may experience in these channels. The main purpose of this system is to achieve fragmented steganographic communication across multiple shards and social platforms. The sender fragments the secret data to be transmitted and redundantly hides it in a large number of multimodal carriers of messenger accounts on multiple social platforms. The receiver, after receiving enough covert carriers, extracts each fragment and concatenates the transmitted secret data. This article, taking image carriers as an example, fragments the text files to be transmitted and embeds them into a large number of images. One fragment needs to be redundantly embedded into multiple images. Thus, at the receiver, only enough stego images need to be received to extract the information in each image, and then concatenate the final secret file.
In the following subsections of this section, we first introduce the novelty of the proposed scheme. We then introduce the core watermarking scheme used in the covert communication framework. Finally, we detail our secret hiding process and secret extraction process using the core watermarking scheme based on a large image database.
2.2. The Novelty of the Proposed Scheme
In this subsection, we would like to emphasize the novelty of our scheme. We describe our novelty in terms of two aspects. One is related to the whole framework. The other is related to our core watermarking method.
2.2.1. The Novelty of the Whole Framework
The novelty of the proposed covert communication framework lies in three aspects:
First, we propose the novel idea of splitting the secret file into fragments, and then embedding each fragment in an image. Here, one fragment is redundantly embedded into several images. Thus the whole secret file can be redundantly hidden in a big image database.
Second, we embed both the fragment number and the fragment content into an image. Thus, the receiver can extract the fragment number and its related content from each stego image. Thus, the receiver can restore the secret file as long as it gathers enough stego images.
Third, we adopt our own robust watermarking method in the proposed covert communication framework. Our watermarking method is very robust against nearly all kinds of common attacks, which cover the operations that most of the social platforms will perform during transmission.
2.2.2. The Novelty of Our Watermarking Method
In our covert communication framework, based on social platforms with big data, a novel watermarking method is designed. It seems that our method is just a multi-domain-based method. In fact, there are some special points, unlike other existing methods, that make our watermarking method very robust to nearly all kinds of attacks.
First, a DFT-based watermarking layer is proposed for synchronization with high embedding and detection efficiency; this method also has good imperceptibility. To save the computation time, we convert the DFT-based transform domain method into a spatial domain-based method with better imperceptibility and robustness. The new principles for constructing the 0,1-sequence are given. The template is prepared in advance to greatly reduce the required embedding time. The required detection time is reduced by cropping the image and using the polar transformation and filter. We also design a new method for determining the rotation angle and scale factor during extraction. Thus our method is therefore faster than many existing DFT-based watermarking schemes.
Second, a DCT-based watermarking layer is proposed for resisting translation attacks, JPEG attacks, and other common attacks. On the one hand, we use fast algorithms to calculate DCT. On the other hand, we use the information header to resist the translation attack and shear attack. Thus, our embedding scheme is both efficient and robust.
Third, the watermarking scheme integrates many techniques because it is designed for industrial use with high efficiency, good robustness, and good imperceptibility. We combine several techniques, such as synchronization correction, information header, and error-correcting code—during both the embedding and extraction processes—to make our scheme fast enough as well as robust to most attacks that might in real applications. Thus, our method is superior to existing methods since they use fewer techniques in their scheme and do not think of the real industrial application.
2.3. Proposed Robust Watermarking Algorithm
To implement our fragmented secure communication system for covert communication scenarios in lossy channels, we need to adopt a strongly robust image watermarking algorithm as the core watermarking algorithm of this system. Thus, we designed a specific robust watermarking scheme for our system. The detailed embedding and extraction methods are described as follows:
2.3.1. Proposed Two-Stage Embedding Algorithm
Our core embedding algorithm includes two stages. The first embedding stage is based on DFT for image synchronization. The second embedding stage is based on DCT for embedding information.
(1) DFT-based watermark embedding stage.
DFT is a suitable transform that can be used for synchronization correction. If the image is rotated or scaled, the 2D DFT spectrum of the image will rotate or scale as well. Therefore, by using these features, we can obtain the scaling rate and the rotation angle of the image with a high accuracy during extraction.
The implementation process of this method can be concisely described as follows: First, the image should be a square. If the image is not a square, then it should be padded to be a square. Second, DFT is performed on the image to obtain the 2D spectrum. Third, a pseudo-random {0,1}-sequence is generated and the spectral amplitude is changed according to the sequence. The amplitudes to be changed are located on a circle. If the bit in the sequence is 0, the amplitude is unchanged; if the bit in the sequence is 1, the amplitude is enhanced. An example can be shown in
Figure 2. Finally, IDFT is performed on the spectrum to obtain the watermarked image. Thus, in the extraction process, by computing the cross-covariance value between the embedded pseudo-random sequence and the circle spectral amplitude sequence of the input image, the rotation angle and scaling factor can be obtained.
The above method can obtain good results, but the embedding process takes much time, the embedding strength is not flexible, and the imperceptibility is not good. In addition, the extraction process requires exhaustive search, which has low efficiency. In order to deal with these problems, we designed a new DFT-based method for synchronization.
The proposed method is similar to the above method in principle, but the implementation is different. In our method, before the embedding, a spatial domain template should be constructed. The spatial domain template is a residual result, and the construction process can be summarized as follows:
In Equation (
1),
indicates the weight parameter,
G denotes a grayscale image with a large square size. Here, all pixel values in image
G are the same. To avoid numerical overflow, we usually choose 128 as the same pixel value. In Equation (
1), the “EMBED” function enhances the corresponding amplitudes of
to be
based on the traditional method, but the 0,1-sequence rather than the pseudo-random sequence is embedded. The principles of constructing the 0,1-sequence are as follows: (1) the sequence should not be periodic; (2) the sequence should be asymmetric; (3) the total number of 0 s and 1 s in the sequence should be balanced. A template construction example is shown in
Figure 3.
The template-embedding process can be described as the following equation:
where
I denotes the carrier image,
denotes the embedded image, and
denotes the cropped template from the center of the template in Equation (
1). Note that
and the carrier image have the same size. And
denotes the adaptive gain designed for controlling the local weight of the template. Generally, smooth areas are weighted lower, and rough areas are weighted higher.
The proposed DFT-based watermarking method is robust, but it is not easy to embed enough information. Therefore, the DCT-based watermarking method is proposed to embed the customized information.
(2) DCT-based watermark embedding stage
For the DCT-based watermarking stage, the embedding process is simple. The image after DFT embedding is input and divided into blocks, and then DCT is performed on each block. The information is embedded by modifying DCT coefficients. Before modification, the independent sub-area should be settled in the image, as shown in
Figure 4. In each independent sub-area, the encoded information will be embedded once. Additionally, the information header should be embedded in each sub-area to resist the translation attack, where the header information is embedded into the blocks in the first row. Then, a pair of DCT coefficients of the block is chosen, the difference between the two coefficients is computed, and then the QIM (quantization index modulation) is used to modify the difference for embedding the information.
In the practical applications, some techniques or tips can be used to improve the performance: first, to compile the program faster, with the same algorithm, C++ is more efficient than Python; second, float numbers can be replaced by integer numbers for higher efficiency; third, the information to be embedded needs to be encoded before the embedding; finally, encryption or scrambling can enhance the security, and error-correcting code can be used for error correction.
(3) The whole two-stage watermark embedding process.
Figure 5 shows the whole watermark embedding process, and the detailed embedding algorithmic steps are as follows:
Step 0: Generate a spatial template as follows:
Step 0.1. Construct a large-size (e.g., 10,000 × 10,000) square gray-level image G with each pixel having the same luminance value 128.
Step 0.2. Apply the DFT to G to obtain the DFT spectrum .
Step 0.3. Design a specific {0,1}-sequence C according to the three principles mentioned above, and denote it as a circle.
Step 0.4. Add this circle C to the DFT spectrum and obtain the modified DFT spectrum .
Step 0.5. IDFT is applied to the modified DFT spectrum to generate the final spatial template T to be embedded.
Step 1: Input the cover image I to be embedded. If the image size is not square, then it should be padded to be square. Thus, we have the padded image to be embedded.
Step 2: Crop the template from the center outward to match the size of the padded image . Then, the cropped template is multiplied by an adaptive coefficient and added to the padded image to finish the template-embedding process, obtaining the image .
Step 3: The image is divided into blocks, and DCT is performed on each block.
Step 4: The independent sub-area is settled in the image and the encoded watermark information is embedded once. Furthermore, the information header should be embedded in each sub-area to resist the translation attack. A pair of DCT coefficients of each block is chosen, and then QIM is used to modify the difference between the two coefficients to finish embedding the watermark information.
Step 5: Apply the IDCT to all modified DCT blocks to obtain the final watermarked image , where the padded part should be removed.
2.3.2. Proposed Extraction Algorithm
Our core extraction algorithm also includes two stages. DFT-based extraction is performed first to correct the image, and then DCT-based extraction is performed to extract the information.
(1) DFT-based watermark extraction stage
As we know, the rotation angle and scaling factor can be found by computing the cross-covariance value, but this process takes too much time. To save the computation time, we design a new method for determining the rotation angle and scale factor. Before detection, the image to be detected can be cropped for faster detection if the image has a large size. Then, DFT is performed on the cropped square image to obtain the spectrum. To reduce possible noises in the DFT spectrum, the spectrum needs to be filtered by the Wiener filter, and then the filtered spectrum needs to be thresholded. If a point value exceeds a certain predefined limit, the point value is divided by the local mean. If the point value does not exceed the limit, the point value is replaced with zero. According to the 0,1-sequence, a filter kernel should be constructed as shown in
Figure 6. And the polar transformation needs to be performed on the clean spectrum. Then, the polar transformed spectrum is filtered by the constructed filter kernel, and the maximum value should be found in the filtered map. If the maximum value is larger than the settled threshold, we can say that this image contains the DFT-based watermark; otherwise, there is no DFT-based watermark in the image. And the coordinates of the maximum value are the rotation angle and the circle radius. According to the detected radius, the scaling factor can be computed by:
where
denotes the circle radius in the embedding process,
denotes the detected circle radius, and
l denotes the width of the square image.
(2) DCT-based watermark extraction stage
The DCT-based information extraction process is just the inverse process of the DCT-based information embedding process. DCT is performed on each block, and compute the difference between the two selected coefficients, and then QIM is used to extract the watermark bit according to the difference. The information header is searched in the extracted bits, and the position of the sub-area can be determined if an information header is found. If there is no information header in the extracted bits, the position of the datum mark needs to be moved and the blocks need to be divided again, until an information header can be found in the extracted bits. An example is shown in
Figure 7. In this method, we use sub-areas and the search of information headers to resist translation and shear attacks, and the differential quantization embedding method has good robustness and imperceptibility.
(3) The whole two-stage watermark extraction process.
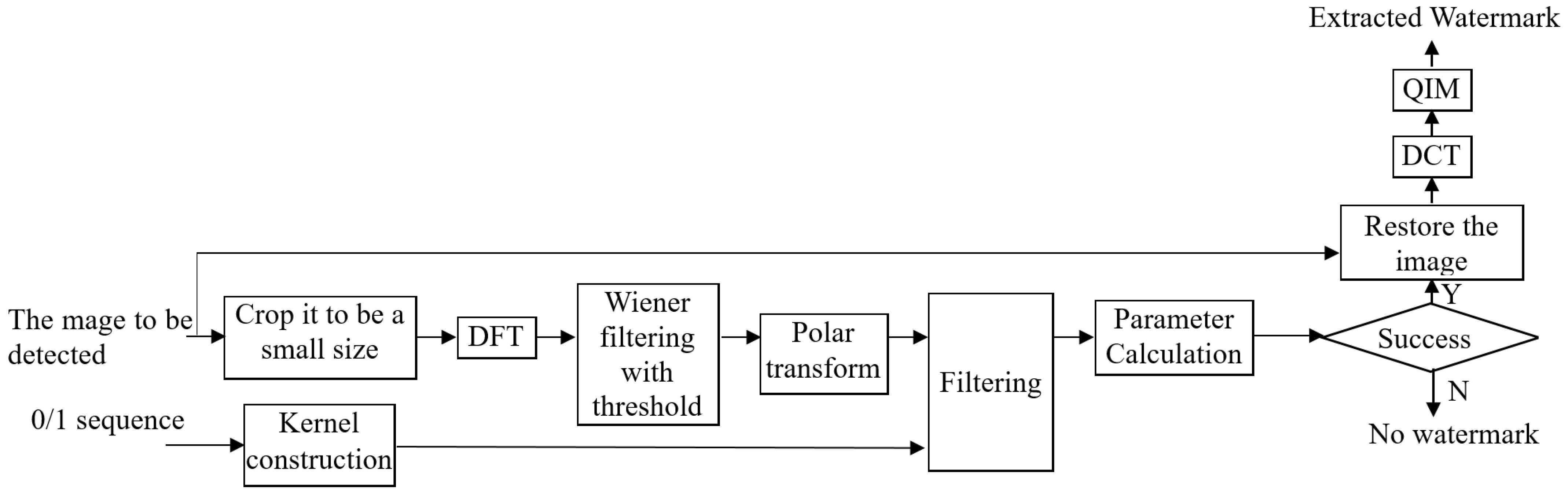
Figure 8 shows the whole watermark extraction process, and the detailed algorithmic steps are as follows:
Step 1: Input the image to be detected ; it can be cropped as of size for faster detection if the image has a large size.
Step 2: DFT is applied to the cropped square image to obtain its spectrum , which is filtered by the Wiener filter, and then the filtered spectrum is thresholded, obtaining .
Step 3: Polar transform is performed on the clean spectrum to obtain . Based on the 0,1-sequence, a filter kernel is constructed. Then, the polar transformed spectrum is filtered by the constructed filter kernel.
Step 4: Parameter calculation. If the maximum value in the filtered map is less than the threshold, the image contains no DFT-based watermark, and the extraction is terminated. Otherwise, the coordinates of the maximum value are the rotation angle and the circle radius . According to the detected radius, , the scaling factor, s, can be computed as the circle radius in the embedding process, , divided by the detected circle radius, , and then multiplied by half of the width of the square image, . Then, the input image is restored based on the calculated parameters.
Step 5: The restored image is divided into blocks.
Step 6: Perform DCT on each block, and compute the difference between the two selected coefficients, and then QIM is used to extract the watermark bit according to the difference.
Step 7: The information header is searched in the extracted bits as discussed above. Thus, the final extracted watermark bits can be obtained by removing the header bits.
2.4. Proposed Secret Hiding Process
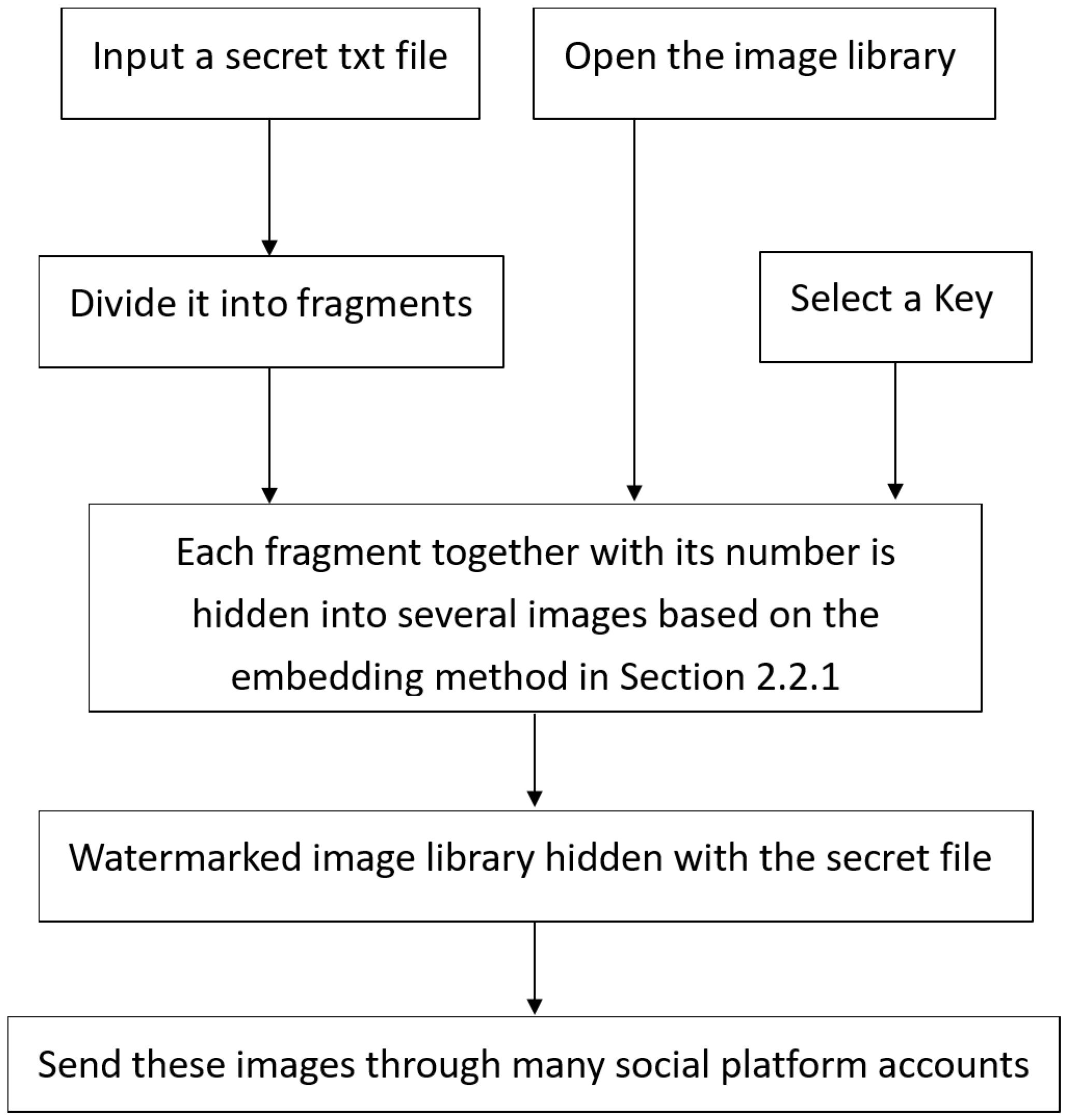
After determining the core watermarking algorithm, we can design the covert communication system by hiding the secret txt file into a large number of images. The secret hiding process is shown in
Figure 9. The basic idea is as follows: given an image library, assume there are
N images in it. Given a text file, assume it contains
M bytes. Assuming that our robust image watermark embedding algorithm in
Section 2.2.1 can embed
K-bit watermark information in each image, we call it a fragment. Here,
K is a multiple of 8, and 20 bits of information, including a 10-bit all-zero header and fragment number, must be added to the actual embedding. This means that
bits of information must be embedded in each image. In this way, if a fragment is
bytes,
N images can hide
bytes. If
, there is significant redundancy in the embedding space, which means that the maximum redundancy is
. If every
image is embedded with the same fragment separately, the receiver may recover the complete text file information just once when only
images are received. If the redundancy is set to
r, it is obvious that
. Obviously, if
, it is not possible to fully embed all fragments once. The hiding process of the sender in this system can be described as follows:
(1) Step 1: Open the text file to be transmitted confidentially, read the number of bytes M, and read all contents in bytes into array B. If is an integer, let . Otherwise, let , where [] represents a rounding-down operation.
(2) Step 2: Open the image library and read the number of valid carrier images N. Compare the sizes of N and based on the input redundancy r. If , output a warning stating that the redundancy setting is too large or the number of images is not enough to embed all text fragments redundantly before exiting. If , continue.
(3) Step 3: Divide array B into S fragments. If the last fragment is less than bytes, add any characters to make up for bytes. That is , where , , and represents the i-th byte of the j-th fragment.
(4) Step 4: Randomly select images from N valid images as carrier image set I, and then divide these carrier images into S groups with r images in each group. That is, , where , , represents the i-th image of the j-th group.
(5) Step 5: Set the fragment number and the intra-group number .
(6) Step 6: Obtain the nth fragment from B, represent the bytes of as K-bit information , and represent the i-th bit of the n-th fragment. The watermark information to be embedded into the n-th set of images is “”, which means that the 10-bit binary numbers of the fragment number are concatenated first by the 10-bit all zero information header, and then the K-bit information is concatenated.
(7) Step 7: Use our robust image watermarking algorithm in
Section 2.2.1 to embed
-bit information
in the image, and obtain the image
containing the watermark.
(8) Step 8: . If , proceed to Step 7; otherwise, proceed to Step 9.
(9) Step 9: . If , proceed to Step 6; otherwise, proceed to Step 10.
(10) Step 10: Collect all watermarked images . Send these watermarked images through various social media platforms.
2.5. Proposed Secret Extraction Process
The secret extract process is shown in
Figure 10. Assuming that the recipient has obtained
L images
from various social platforms, usually at least
; that is to say, the number of collected images is always greater than the number of fragments
S of the text file, in order to fully recover the text file. Moreover, some of the collected images may be embedded with the same fragment, or some of the collected images may not be embedded at all. The extraction process of the receiver in this system can be described as follows:
(1) Step 1: Set .
(2) Step 2: Input
, use the strong stick image watermark algorithm in
Section 2.2.2 to extract the watermark. If the number of ‘0’s in the first 10 extracted bits is not equal to 10, the extraction fails. Continue to Step 3. Otherwise, continue to extract the hidden fragment numbers and their corresponding
K-bit fragment information.
(3) Step 3: . If , proceed to Step 2; otherwise, proceed to Step 4.
(4) Step 4: According to the fragment number–fragment information combination, the final text file is formed: if multiple fragment data are extracted under a certain fragment number, each bit of fragment information is voted on by a minority following a majority to obtain the final fragment information for that fragment number. If some fragment numbers are missing, all corresponding byte information will be marked with ‘?’.


 and
and 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}