
CenterNet-Saccade: Enhancing Sonar Object Detection with Lightweight Global Feature Extraction

Abstract
:1. Introduction
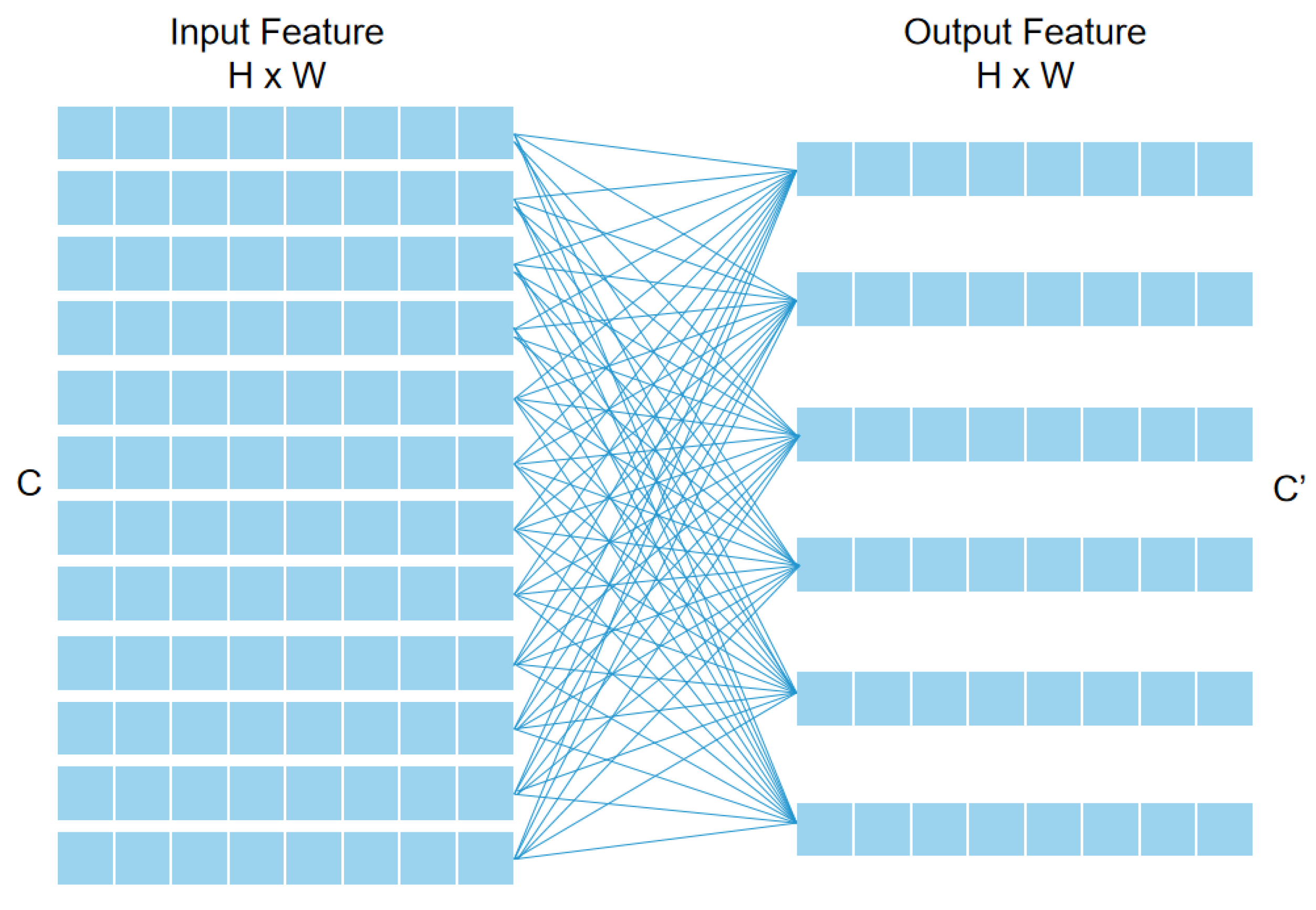
- To capture and utilize the global environment information containing shadows in sonar images, a self-attention mechanism called E-MHSA is designed in ConvNet. E-MHSA can capture the global features in the environment and only consumes a little memory, namely GPU memory and computer RAM.
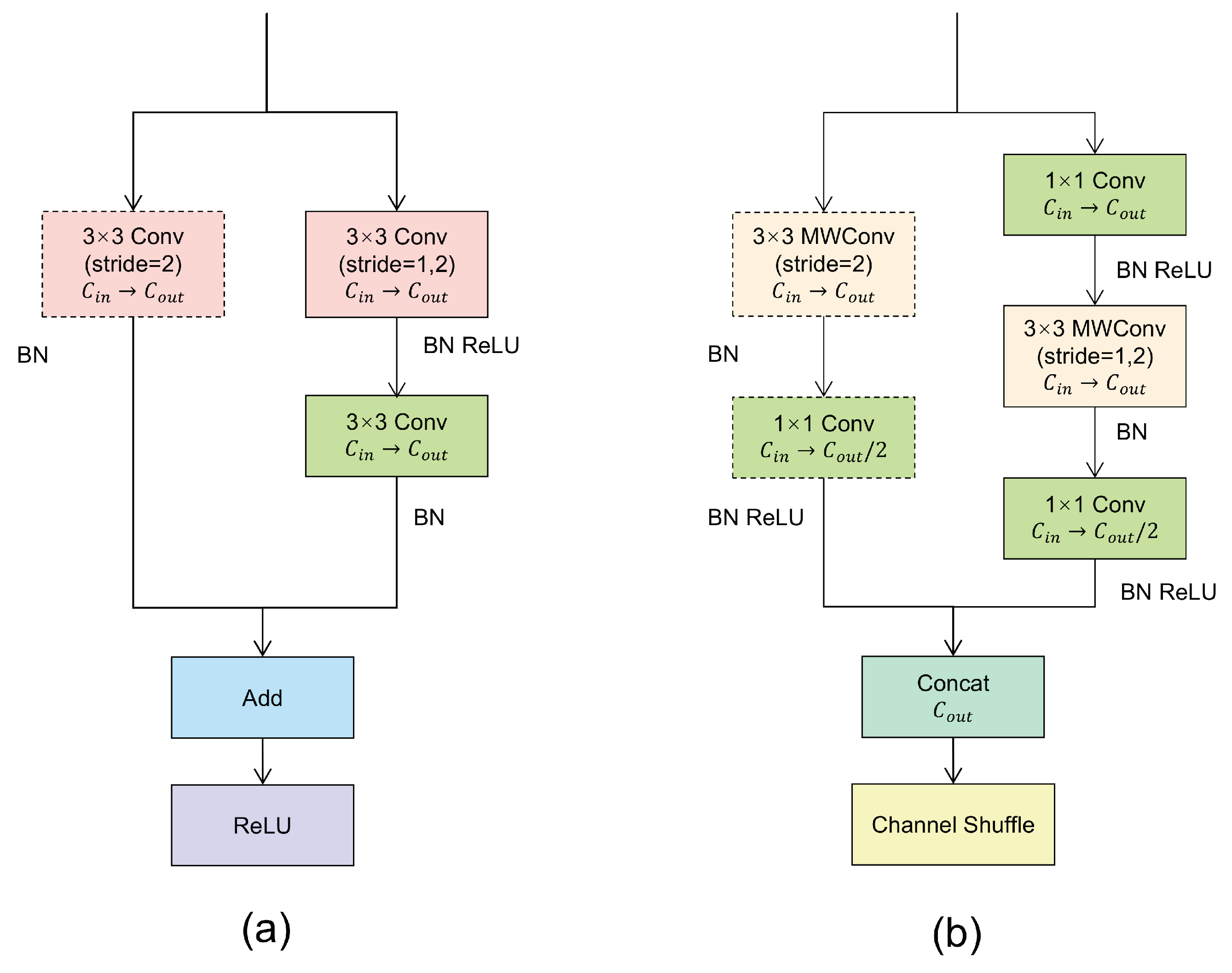
- ShuffleBlock is designed as a block in the backbone Hourglass network, and greatly reduces consumption of computational resources. In addition, a hyperparameter is set for the selection of positive and negative samples to improve the detection accuracy of CenterNet.
- Experiments show that our proposed model can effectively use parameters and calculations, and has faster reasoning speed and higher detection accuracy than the existing popular ConvNet algorithm.
2. Related Work
2.1. Anchor-Free
2.2. Lightweight Architecture
2.3. Self-Attention Modules
3. Method
3.1. Enrichment Multi-Head Self-Attention
3.2. Lightweight Hourglass
3.3. Adjusting Positive and Negative Samples
4. Experiments and Analysis
4.1. Sonar Image Dataset and Experimental Details
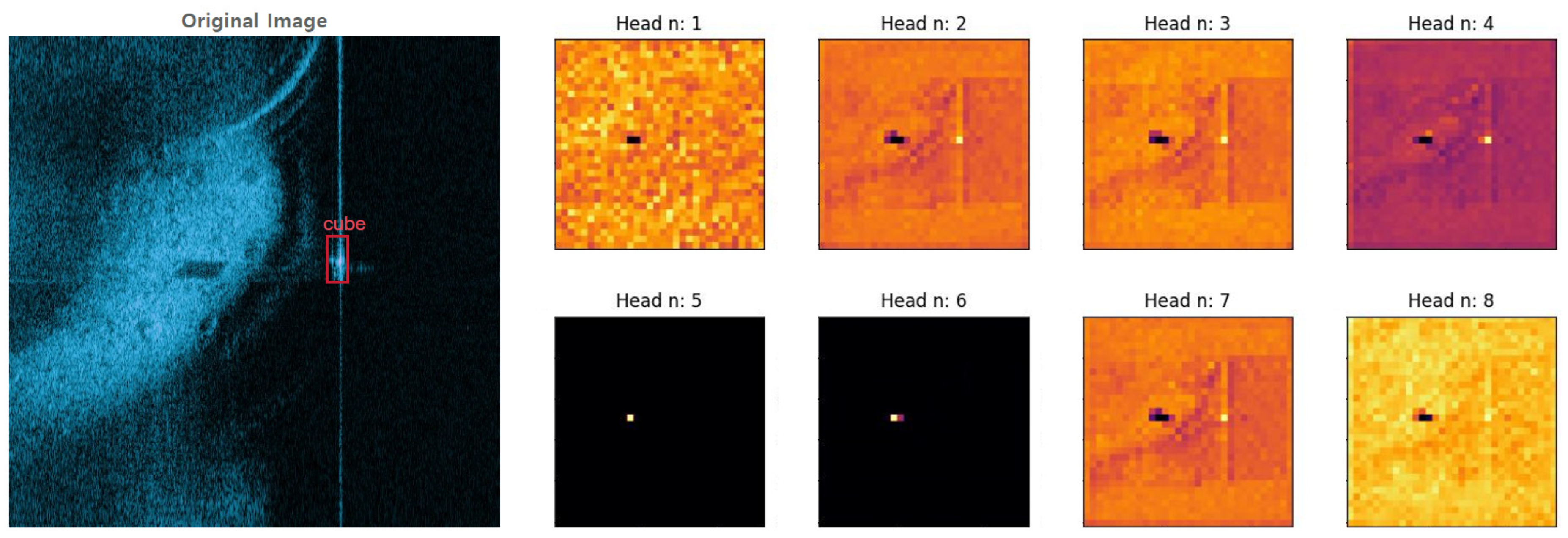
4.2. Visualized E-MHSA
4.3. MHSA Experimentation
4.4. Ablation Study
4.5. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zeng, L.; Chen, Q.; Huang, M. RSFD: A rough set-based feature discretization method for meteorological data. Front. Environ. Sci. 2022, 10, 1013811. [Google Scholar] [CrossRef]
- Chen, Q.; Huang, M.; Wang, H. A feature discretization method for classification of high-resolution remote sensing images in coastal areas. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8584–8598. [Google Scholar] [CrossRef]
- Chen, Q.; Xie, L.; Zeng, L.; Jiang, S.; Ding, W.; Huang, X.; Wang, H. Neighborhood rough residual network-based outlier detection method in IoT-enabled maritime transportation systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11800–11811. [Google Scholar] [CrossRef]
- Chen, Q.; Ding, W.; Huang, X.; Wang, H. Generalized interval type II fuzzy rough model based feature discretization for mixed pixels. IEEE Trans. Fuzzy Syst. 2023, 31, 845–859. [Google Scholar] [CrossRef]
- Lin, C.; Qiu, C.; Jiang, H.; Zou, L. A Deep Neural Network Based on Prior-Driven and Structural Preserving for SAR Image Despeckling. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6372–6392. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of orented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Abu, A.; Diamant, R. A Statistically-Based Method for the Detection of Underwater Objects in Sonar Imagery. IEEE Sens. J. 2019, 19, 6858–6871. [Google Scholar] [CrossRef]
- Azimi-Sadjadi, M.R.; Klausner, N.; Kopacz, J. Detection of Underwater Targets Using a Subspace-Based Method With Learning. IEEE J. Ocean. Eng. 2017, 42, 869–879. [Google Scholar] [CrossRef]
- Dong, R.; Xu, D.; Zhao, J.; Jiao, L.; An, J. Sig-NMS-Based Faster R-CNN Combining Transfer Learning for Small Target Detection in VHR Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8534–8545. [Google Scholar] [CrossRef]
- Shan, Y.; Zhou, X.; Liu, S.; Zhang, Y.; Huang, K. SiamFPN: A Deep Learning Method for Accurate and Real-Time Maritime Ship Tracking. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 315–325. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Jin, L.; Liang, H.; Yang, C. Accurate Underwater ATR in Forward-Looking Sonar Imagery Using Deep Convolutional Neural Networks. IEEE Access 2019, 7, 125522–125531. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, S.; Gross, L.; Zhang, C.; Wang, B. Fused Adaptive Receptive Field Mechanism and Dynamic Multiscale Dilated Convolution for Side-Scan Sonar Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5116817. [Google Scholar] [CrossRef]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-Time Underwater Maritime Object Detection in Side-Scan Sonar Images Based on Transformer-YOLOv5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–16 July 2017; pp. 1251–1258. [Google Scholar]
- Fakiris, E.; Papatheodorou, G.; Geraga, M.; Ferentinos, G. An automatic target detection algorithm for swath sonar backscatter imagery, using image texture and independent component analysis. Remote Sens. 2016, 8, 373. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| H × W | Formular | Params | MAC | Time (s/103) |
|---|---|---|---|---|
| QKV Initialization | 196,608 | 269,549,824 | 21.01 | |
| Dot (Q, KT) | 0 | 136,314,880 | 252.48 | |
| Softmax | 0 | 402,685,952 | 462.64 | |
| Dot (Attn, VT) | 0 | 136,314,880 | 295.53 | |
| QKV Initialization | 1,769,472 | 2,416,771,328 | 28.01 | |
| Dot (Q, KT) | 0 | 8,912,896 | 13.00 | |
| Softmax | 0 | 25,174,016 | 24.01 | |
| Dot (Attn, VT) | 0 | 8,912,896 | 73.01 |
| Method | (%) | Number of Params | Time (s/103) |
|---|---|---|---|
|
Base () | 75.77 | 4,431,360 | 109.30 |
|
Grouping of FNN () | 75.53 | 14,592 | 109.04 |
|
Conv () | 75.70 | 4,431,360 | 90.33 |
|
Conv () | 75.95 | 1,769,984 | 34.44 |
| (%) | (%) | (%) | (%) | |
|---|---|---|---|---|
| 1.00 | 98.45 | 92.83 | 74.25 | 24.55 |
| 0.90 | 98.11 | 94.71 | 78.86 | 26.96 |
| 0.95 | 98.31 | 93.47 | 76.84 | 23.27 |
| 0.80 | 98.06 | 94.53 | 74.93 | 25.11 |
| 0.70 | 97.83 | 93.45 | 73.81 | 25.50 |
| Methods | (%) | (%) | (%) | (%) | Time (s) | Mem (GB) |
|---|---|---|---|---|---|---|
| YOLOv3 | 86.5 | 79.0 | 56.5 | 20.7 | 0.311 | 2.7 |
| SSD [30] | 88.4 | 82.9 | 68.8 | 23.4 | 0.361 | 9.3 |
| RetinaNet [31] | 90.8 | 86.5 | 69.8 | 25.1 | 0.387 | 3.7 |
| FCOS | 92.2 | 86.9 | 69.3 | 24.5 | 0.494 | 3.5 |
| Faster R-CNN | 89.1 | 86.0 | 71.1 | 26.2 | 0.445 | 3.9 |
| CenterNet | 98.5 | 92.8 | 72.1 | 24.6 | 0.376 | 3.3 |
| CenterNet (E-MHSA) | 95.6 | 94.8 | 77.3 | 28.8 | 0.600 | 3.5 |
| CenterNet (L-Hourglass) | 98.3 | 90.2 | 71.4 | 23.9 | 0.102 | 1.4 |
| CenterNet-Saccade | 97.7 | 94.2 | 76.5 | 26.7 | 0.156 | 1.7 |
| Methods | (%) | Ball (%) | Cylindb Aller (%) | Square Cage (%) | Cube (%) | Circle Cage (%) | Human Body (%) | Metal Bucket (%) | Tyre (%) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 56.5 | 72.9 | 50.7 | 53.0 | 63.7 | 56.6 | 51.0 | 51.5 | 52.9 |
| SSD | 68.8 | 75.2 | 65.4 | 59.4 | 72.9 | 74.2 | 60.0 | 74.7 | 69.0 |
| RetinaNet | 69.8 | 72.7 | 66.2 | 59.0 | 77.7 | 74.6 | 67.5 | 73.2 | 68.8 |
| FCOS | 69.3 | 74.5 | 65.4 | 62.2 | 76.4 | 73.9 | 68.1 | 73.5 | 68.4 |
| Faster R-CNN | 71.1 | 75.8 | 61.8 | 67.0 | 76.1 | 77.4 | 71.6 | 76.5 | 62.7 |
| CenterNet | 74.3 | 78.0 | 71.6 | 57.1 | 83.6 | 72.0 | 73.3 | 78.3 | 63.3 |
| CenterNet-Saccade | 76.5 | 79.6 | 75.9 | 66.3 | 85.0 | 74.1 | 81.1 | 74.0 | 75.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Zhang, Q.; Qi, Z.; Huang, M. CenterNet-Saccade: Enhancing Sonar Object Detection with Lightweight Global Feature Extraction. Sensors 2024, 24, 665. https://doi.org/10.3390/s24020665
Wang W, Zhang Q, Qi Z, Huang M. CenterNet-Saccade: Enhancing Sonar Object Detection with Lightweight Global Feature Extraction. Sensors. 2024; 24(2):665. https://doi.org/10.3390/s24020665
Chicago/Turabian StyleWang, Wenling, Qiaoxin Zhang, Zhisheng Qi, and Mengxing Huang. 2024. "CenterNet-Saccade: Enhancing Sonar Object Detection with Lightweight Global Feature Extraction" Sensors 24, no. 2: 665. https://doi.org/10.3390/s24020665
APA StyleWang, W., Zhang, Q., Qi, Z., & Huang, M. (2024). CenterNet-Saccade: Enhancing Sonar Object Detection with Lightweight Global Feature Extraction. Sensors, 24(2), 665. https://doi.org/10.3390/s24020665