
Bayesian Averaging Evaluation Method of Accelerated Degradation Testing Considering Model Uncertainty Based on Relative Entropy


Abstract
:1. Introduction
2. Modeling of ADT Bayesian Evaluation
2.1. Bayesian Inference
2.2. Models of ADT
2.2.1. Degradation Model
2.2.2. Accelerated Model
2.3. Evaluation Framework of ADT Bayesian Model
3. Averaging Method Based on Relative Entropy
3.1. Relative Entropy
3.2. Weight of Model
3.3. Averaging Evaluation Process
- (1)
- Constructing the set {Mv} of the ADT models
- (2)
- Bayesian modeling for each individual evaluation model
- (3)
- Setting of prior distribution π(θv|Mv) for each Bayesian models
- (4)
- Inference of posterior distribution π(θv|y,Mv)
- (5)
- Calculation of relative entropy I(θ| Mv) and model weights ωv
- (6)
- Analysis of outcome
4. An Illustrative Simulation Case
4.1. Simulation Data Declaration
4.2. Model Comparison
4.3. Set of ADT Models
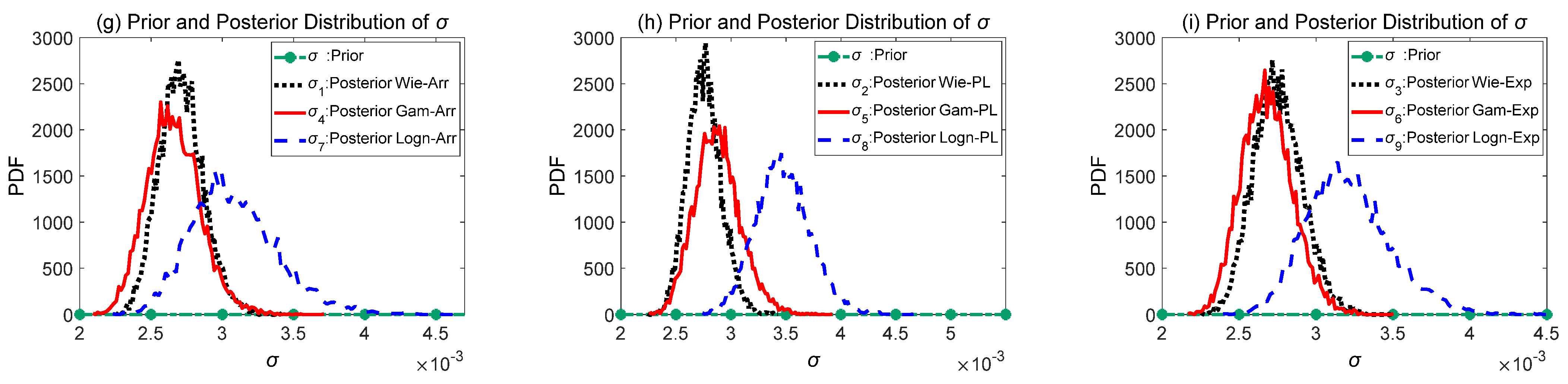
4.4. Comparison of Prior and Posterior Distribution
4.5. Calculation of Relative Entropy
- (1)
- The relative entropy value of M7 is the highest of all models, while the degenerate model and accelerated model of M7 are consistent with the original simulation assumption. From a Shannon information perspective, it represents the maximum IG obtained through M7 from the sample data.
- (2)
- In this simulation case, the choice of the accelerated model is crucial. Therefore, under the correct Arrhenius relation of the accelerated model, a generally higher value of relative entropy is achieved, while the power law and exponential relation yield relatively lower relative entropy values, which is consistent with the result analysis of Figure 5.
- (3)
- The selection of the degradation model is equally important. The correct lognormal process also provides a higher relative entropy value than other processes for the simulation case, but its advantage is not particularly pronounced. This may be because in situations with limited sample data, the features that align with the lognormal process in the original hypothesis exhibited by simulated data are not very prominent. Therefore, employing other stochastic processes for degradation modeling and analysis can also yield good results.
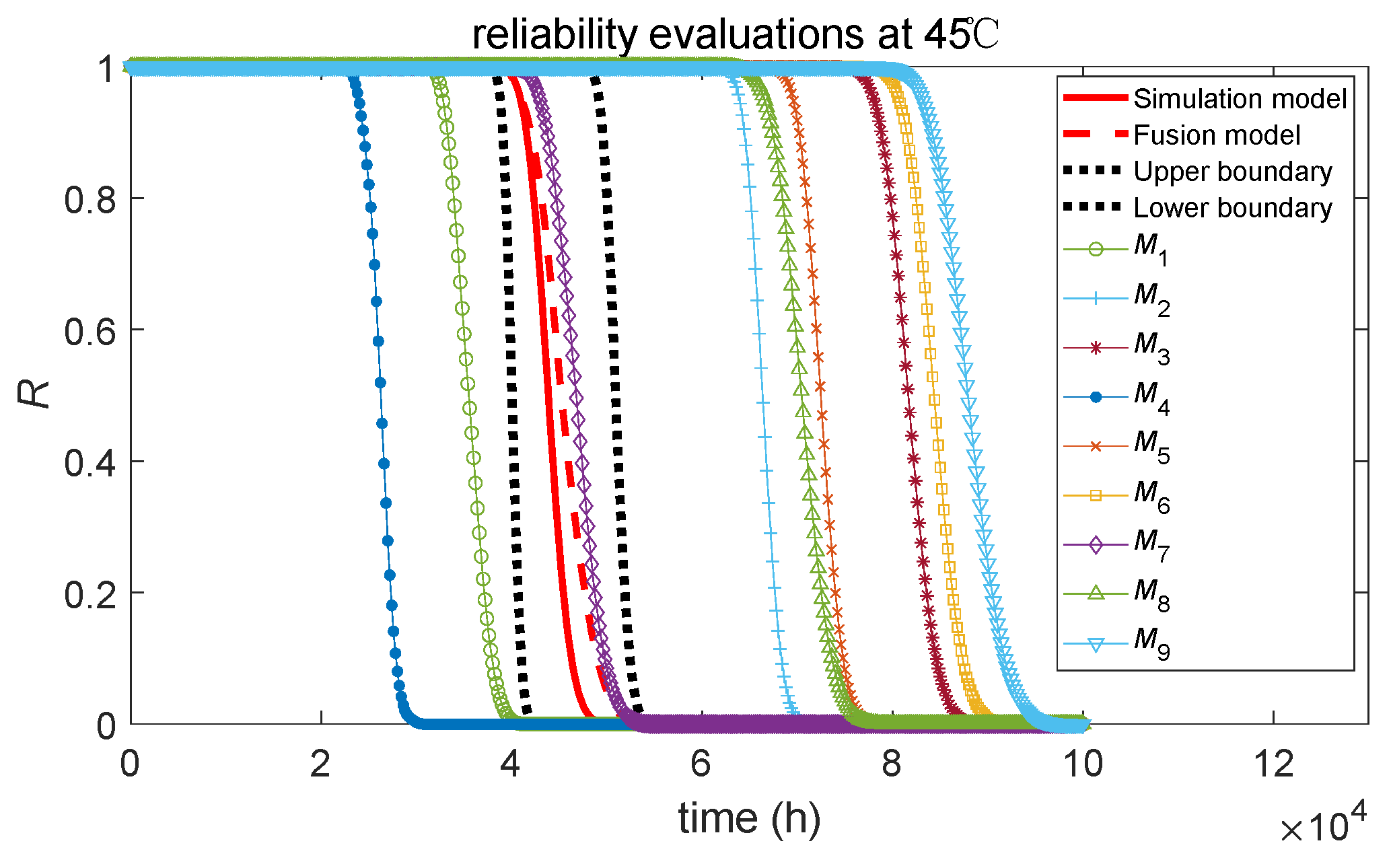
4.6. Result of Model Averaging
- (1)
- Among all the reliability evaluation curves for individual evaluation models, the reliability evaluation curve of the M7 model, which combines the degradation model of the lognormal process with the accelerated model of the Arrhenius relation, closely matches the true reliability assessment curve (red solid line). Therefore, it can be considered that in the case of correct modeling, the Bayesian assessment of ADT through individual models can provide a good estimate of the true product reliability level.
- (2)
- Among the nine individual Bayesian evaluation models, the choice of the accelerated model is crucial. Curves with the same accelerated model exhibit a certain degree of convergence, with the curves for M1, M4, and M7 being similar and M2, M5, and M8 being similar, while M3, M6, and M9 also share similarities.
- (3)
- The reliability evaluation curves based on the accelerated model of the Arrhenius relation for M1, M4, and M7 are relatively close to the true curve, while the reliability evaluation curves based on the accelerated models of the power law relation and exponential relation deviate from the true curve. The analysis reveals that different stochastic processes can effectively describe the simulation data well at a single stress level. However, the limited three stress levels in the simulation case result in significant parameter estimation bias in the accelerated model, leading to substantial deviations in the degradation mean under normal stress conditions at 45 °C.
- (4)
- The reliability evaluation curve obtained by the model averaging method based on relative entropy weights closely matches the true reliability evaluation curve. The upper and lower boundaries of the model averaging evaluation method completely envelop the true reliability evaluation curve, demonstrating the feasibility of the Bayesian averaging evaluation method based on relative entropy.
- (5)
- The reliability evaluation curve of the incorrect models deviates from the true curve; their lesser contribution, due to lower relative entropy weights, minimally affects the evaluation model after averaging. Conversely, the correct models, with higher weights, have a greater influence on the model averaging evaluation method. Through model averaging, the robustness of reliability evaluation is improved. Although both the averaged model and the correct individual model M7 can effectively obtain the true reliability result in this case, it is very difficult to obtain the true ADT Bayesian model before evaluation in the small-sample evaluation process. Therefore, the Bayesian averaging evaluation method based on relative entropy weights would have a certain advantage.
- (6)
- If the ADT process of a product does not consistently follow a specific evaluation model, then applying the averaging evaluation method proposed in this paper for real-time evaluation of the product’s ADT would be highly meaningful. This approach avoids relying solely on individual models for evaluation. Under the averaging evaluation method considering model uncertainty, as data accumulates, the weight values will change based on the true model properties of the degradation data, thereby continuously approaching the true model and making the evaluation results more reliable.
5. Conclusions
- (1)
- Drawing from information entropy theory, relative entropy is proposed as a means to evaluate the quality of the ADT Bayesian model. A higher relative entropy value indicates that the model can offer more information gain with the same sample data, suggesting a better fit for the model. Subsequently, a new Bayesian averaging evaluation method for ADT based on relative entropy is developed, demonstrating theoretical feasibility.
- (2)
- Through an illustrative simulation case, a set of simulated data is generated using a lognormal process for the degradation model and an Arrhenius relation for the accelerated model. An uncertainty analysis of models is then conducted, and reliability evaluation curves are obtained under the averaging evaluation method based on relative entropy. The results demonstrate that the proposed method’s evaluation outcomes are consistent with the simulation hypothesis.
- (3)
- Synthesizing the findings from the simulation case study, it is observed that the Bayesian averaging evaluation method based on relative entropy weights can alleviate biases caused by incorrect model selection. It effectively addresses the issue of inaccurate evaluation due to model uncertainty, thus enhancing the robustness of the Bayesian method, which is particularly crucial when dealing with limited sample data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meeker, W.Q.; Hamada, M. Statistical tools for the rapid development and evaluation of high-reliability products. IEEE Trans. Reliab. 1995, 44, 187–198. [Google Scholar] [CrossRef]
- Nelson, W.B. Accelerated Testing: Statistical Models, Test Plans, and Data Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Meeker, W.Q.; Escobar, L.A.; Lu, C.J. Accelerated degradation tests: Modeling and analysis. Technometrics 1998, 40, 89–99. [Google Scholar] [CrossRef]
- Wang, L.; Pan, R.; Li, X.; Jiang, T. A Bayesian reliability evaluation method with integrated accelerated degradation testing and field information. Reliab. Eng. Syst. Saf. 2013, 112, 38–47. [Google Scholar] [CrossRef]
- Prakash, G. A Bayesian approach to degradation modeling and reliability assessment of rolling element bearing. Commun. Stat.-Theory Methods 2021, 50, 5453–5474. [Google Scholar] [CrossRef]
- Pang, Z.; Si, X.; Hu, C.; Du, D.; Pei, H. A Bayesian inference for remaining useful life estimation by fusing accelerated degradation data and condition monitoring data. Reliab. Eng. Syst. Saf. 2021, 208, 107341. [Google Scholar] [CrossRef]
- Fan, T.-H.; Dong, Y.-S.; Peng, C.-Y. A Complete Bayesian Degradation Analysis Based on Inverse Gaussian Processes. IEEE Trans. Reliab. 2023, 1–13. [Google Scholar] [CrossRef]
- Wu, J.-P.; Kang, R.; Li, X.-Y. Uncertain accelerated degradation modeling and analysis considering epistemic uncertainties in time and unit dimension. Reliab. Eng. Syst. Saf. 2020, 201, 106967. [Google Scholar] [CrossRef]
- Ye, Z.S.; Xie, M. Stochastic modelling and analysis of degradation for highly reliable products. Appl. Stoch. Models Bus. Ind. 2015, 31, 16–32. [Google Scholar] [CrossRef]
- Chhikara, R.S.; Folks, J.L. The inverse Gaussian distribution as a lifetime model. Technometrics 1977, 19, 461–468. [Google Scholar] [CrossRef]
- Whitmore, G.A.; Schenkelberg, F. Modelling accelerated degradation data using Wiener diffusion with a time scale transformation. Lifetime Data Anal. 1997, 3, 27–45. [Google Scholar] [CrossRef]
- Bagdonavicius, V.; Nikulin, M.S. Estimation in degradation models with explanatory variables. Lifetime Data Anal. 2001, 7, 85–103. [Google Scholar] [CrossRef]
- Lawless, J.; Crowder, M. Covariates and random effects in a gamma process model with application to degradation and failure. Lifetime Data Anal. 2004, 10, 213–227. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Q.; Zhou, J. Reliability evaluation based on normal-poisson process on condition of small sampling test. J.-Natl. Univ. Def. Technol. 2006, 28, 128. [Google Scholar]
- Tsai, C.-C.; Tseng, S.-T.; Balakrishnan, N. Mis-specification analyses of gamma and Wiener degradation processes. J. Stat. Plan. Inference 2011, 141, 3725–3735. [Google Scholar] [CrossRef]
- Caruso, H.; Dasgupta, A. A fundamental overview of accelerated testing analytical models. J. IEST 1998, 41, 16–20. [Google Scholar] [CrossRef]
- Kang, Q.; Lin, Y.; Tao, J. A Reliability Analysis of a MEMS Flow Sensor with an Accelerated Degradation Test. Sensors 2023, 23, 8733. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, S.; Kim, T.-W. Investigation of Mean-Time-to-Failure Measurements from AlGaN/GaN High-Electron-Mobility Transistors Using Eyring Model. Electronics 2021, 10, 3052. [Google Scholar] [CrossRef]
- Yang, X.; Sun, B.; Wang, Z.; Qian, C.; Ren, Y.; Yang, D.; Feng, Q. An alternative lifetime model for white light emitting diodes under thermal–electrical stresses. Materials 2018, 11, 817. [Google Scholar] [CrossRef] [PubMed]
- Hafez, E.H.; Riad, F.H.; Mubarak, S.A.; Mohamed, M.S. Study on Lindley distribution accelerated life tests: Application and numerical simulation. Symmetry 2020, 12, 2080. [Google Scholar] [CrossRef]
- Pan, Z.; Balakrishnan, N. Multiple-steps step-stress accelerated degradation modeling based on Wiener and gamma processes. Commun. Stat.-Simul. Comput. 2010, 39, 1384–1402. [Google Scholar] [CrossRef]
- Steel, M.F. Model averaging and its use in economics. J. Econ. Lit. 2020, 58, 644–719. [Google Scholar] [CrossRef]
- Anderson, D.; Burnham, K. Model Selection and Multi-Model Inference, 2nd ed.; Springer: New York, NY, USA, 2004; Volume 63, p. 10. [Google Scholar]
- Lindley, D.V. On a measure of the information provided by an experiment. Ann. Math. Stat. 1956, 27, 986–1005. [Google Scholar] [CrossRef]
- Busetto, A.G.; Ong, C.S.; Buhmann, J.M. Optimized expected information gain for nonlinear dynamical systems. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 97–104. [Google Scholar]
- Fisher, R.A. On the mathematical foundations of theoretical statistics. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. A Math. Phys. Character 1922, 222, 309–368. [Google Scholar]
- Park, C.; Padgett, W.J. Stochastic degradation models with several accelerating variables. IEEE Trans. Reliab. 2006, 55, 379–390. [Google Scholar] [CrossRef]
- Liu, L.; Li, X.-Y.; Zio, E.; Kang, R.; Jiang, T.-M. Model uncertainty in accelerated degradation testing analysis. IEEE Trans. Reliab. 2017, 66, 603–615. [Google Scholar] [CrossRef]
- Fan, T.H.; Chen, C.H. A Bayesian predictive analysis of step-Stress accelerated tests in Gamma degradation-based processes. Qual. Reliab. Eng. Int. 2017, 33, 1417–1424. [Google Scholar] [CrossRef]
- Liu, L.; Li, X.; Sun, F.; Wang, N. A general accelerated degradation model based on the Wiener process. Materials 2016, 9, 981. [Google Scholar] [CrossRef]
- Wang, X.; Wang, B.X.; Wu, W.; Hong, Y. Reliability analysis for accelerated degradation data based on the Wiener process with random effects. Qual. Reliab. Eng. Int. 2020, 36, 1969–1981. [Google Scholar] [CrossRef]
- Lim, H.; Sung, S.-I. Planning of Accelerated Degradation Tests: In the Case Where the Performance Degradation Characteristic Follows the Lognormal Distribution. J. Appl. Reliab. 2018, 18, 80–86. [Google Scholar] [CrossRef]
- Liu, L.; Li, X.Y.; Jiang, T.M.; Sun, F.Q. Utilizing accelerated degradation and field data for life prediction of highly reliable products. Qual. Reliab. Eng. Int. 2016, 32, 2281–2297. [Google Scholar] [CrossRef]
- Nelson, W. Analysis of accelerated life test data-part I: The arrhenius model and graphical methods. IEEE Trans. Electr. Insul. 1971, EI-6, 165–181. [Google Scholar] [CrossRef]
- Park, C.; Padgett, W. Accelerated degradation models for failure based on geometric Brownian motion and gamma processes. Lifetime Data Anal. 2005, 11, 511–527. [Google Scholar] [CrossRef] [PubMed]
- Sun, F.; Liu, L.; Li, X.; Liao, H. Stochastic modeling and analysis of multiple nonlinear accelerated degradation processes through information fusion. Sensors 2016, 16, 1242. [Google Scholar] [CrossRef] [PubMed]
- Ye, Z.-S.; Chen, N. The inverse Gaussian process as a degradation model. Technometrics 2014, 56, 302–311. [Google Scholar] [CrossRef]
- Bhattacharyya, G.; Fries, A. Fatigue Failure Models ߝ Birnbaum-Saunders vs. Inverse Gaussian. IEEE Trans. Reliab. 1982, 31, 439–441. [Google Scholar] [CrossRef]
- Csiszár, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Li, X.; Hu, Y.; Sun, F.; Kang, R. A Bayesian optimal design for sequential accelerated degradation testing. Entropy 2017, 19, 325. [Google Scholar] [CrossRef]
- Ntzoufras, I. Bayesian Modeling Using WinBUGS; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 698. [Google Scholar]
- Li, X.; Hu, Y.; Zio, E.; Kang, R. A Bayesian optimal design for accelerated degradation testing based on the inverse Gaussian process. IEEE Access 2017, 5, 5690–5701. [Google Scholar] [CrossRef]
- Gibbons, J.D.; Chakraborti, S. Nonparametric Statistical Inference: Revised and Expanded; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Values |
|---|---|
| Degradation process | Lognormal |
| Accelerated model | Arrhenius |
| Simulation parameter θ | a = 10, b = −5000, σ = 0.003 |
| Stress levels (Temperature/°C) | 65, 85, 100 |
| Normal stress level (Temperature/°C) | 45 |
| Sample size under each stress level | 6, 6, 6 |
| Monitor times | 10, 10, 10 |
| Failure threshold | 30 |
| Model | Arrhenius | Power Law | Exponential |
|---|---|---|---|
| Wiener | M1 | M2 | M3 |
| Gamma | M4 | M5 | M6 |
| Lognormal | M7 | M8 | M9 |
| Prior Distribution | a | b | σ |
|---|---|---|---|
| π(θ1) | unif (−100, 100) | unif (−10,000, 0) | unif (0, 1) |
| π(θ2) | unif (−100, 100) | unif (−100, 100) | unif (0, 1) |
| π(θ3) | unif (0, 10, 000) | unif (−100, 100) | unif (0, 1) |
| π(θ4) | unif (−100, 100) | unif (−10,000, 0) | unif (0, 1) |
| π(θ5) | unif (−100, 100) | unif (−100, 100) | unif (0, 1) |
| π(θ6) | unif (0, 10, 000) | unif (−100, 100) | unif (0, 1) |
| π(θ7) | unif (−100, 100) | unif (−10,000, 0) | unif (0, 1) |
| π(θ8) | unif (−100, 100) | unif (−100, 100) | unif (0, 1) |
| π(θ9) | unif (0, 10, 000) | unif (−100, 100) | unif (0, 1) |
| Posterior Distribution | a | b | σ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | 2.5% | 97.5% | Mean | Std | 2.5% | 97.5% | Mean | Std | 2.5% | 97.5% | |
| π(θ1|y,M1) | 10.4 | 1.739 | 7.77 | 12.93 | −5670 | 640.6 | −6602 | −4701 | 0.0027 | 0.00016 | 0.0024 | 0.003 |
| π(θ2|y,M2) | −0.3609 | 0.005783 | −0.3707 | −0.348 | 0.06264 | 0.0009843 | 0.06005 | 0.06392 | 0.0028 | 0.00015 | 0.0025 | 0.0031 |
| π(θ3|y,M3) | 3573 | 461.4 | 2810 | 4443 | −9.253 | 1.239 | −11.59 | −7.207 | 0.0028 | 0.00016 | 0.0025 | 0.0031 |
| π(θ4|y,M4) | 7.052 | 0.7313 | 5.78 | 8.414 | −4436 | 267.9 | −4934 | −3969 | 0.0027 | 0.00019 | 0.0023 | 0.0031 |
| π(θ5|y,M5) | −0.263 | 0.01206 | −0.2915 | −0.2492 | 0.04567 | 0.002061 | 0.04326 | 0.05049 | 0.0029 | 0.00021 | 0.0025 | 0.0033 |
| π(θ6|y,M6) | 2896 | 140.1 | 2666 | 3172 | −7.434 | 0.3759 | −8.174 | −6.819 | 0.0027 | 0.00017 | 0.0024 | 0.003 |
| π(θ7|y,M7) | 8.976 | 0.7286 | 7.369 | 10.17 | −5139 | 266.9 | −5577 | −4553 | 0.0031 | 0.0003 | 0.0026 | 0.0038 |
| π(θ8|y,M8) | −0.404 | 0.009927 | −0.4178 | −0.3821 | 0.07028 | 0.001697 | 0.0683 | 0.0744 | 0.0035 | 0.00025 | 0.003 | 0.004 |
| π(θ9|y,M9) | 3313 | 139 | 2987 | 3540 | −8.563 | 0.3715 | −9.172 | −7.696 | 0.0032 | 0.00027 | 0.0027 | 0.0038 |
| {Mv} | ωv |
|---|---|
| M1 | 0.121 |
| M2 | 0.07881 |
| M3 | 0.07391 |
| M4 | 0.1465 |
| M5 | 0.1033 |
| M6 | 0.08261 |
| M7 | 0.1888 |
| M8 | 0.1168 |
| M9 | 0.08827 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, T.; Wu, W.; Liu, K.; Wang, K.; Lv, C. Bayesian Averaging Evaluation Method of Accelerated Degradation Testing Considering Model Uncertainty Based on Relative Entropy. Sensors 2024, 24, 1426. https://doi.org/10.3390/s24051426
Zou T, Wu W, Liu K, Wang K, Lv C. Bayesian Averaging Evaluation Method of Accelerated Degradation Testing Considering Model Uncertainty Based on Relative Entropy. Sensors. 2024; 24(5):1426. https://doi.org/10.3390/s24051426
Chicago/Turabian StyleZou, Tianji, Wenbo Wu, Kai Liu, Ke Wang, and Congmin Lv. 2024. "Bayesian Averaging Evaluation Method of Accelerated Degradation Testing Considering Model Uncertainty Based on Relative Entropy" Sensors 24, no. 5: 1426. https://doi.org/10.3390/s24051426
APA StyleZou, T., Wu, W., Liu, K., Wang, K., & Lv, C. (2024). Bayesian Averaging Evaluation Method of Accelerated Degradation Testing Considering Model Uncertainty Based on Relative Entropy. Sensors, 24(5), 1426. https://doi.org/10.3390/s24051426