1. Introduction
Benefiting from the advancements in wireless power transfer (WPT) technology [
1,
2], wireless rechargeable sensor networks (WRSNs) equipped with wireless charging systems have emerged as an effective solution for addressing node energy constraints [
3,
4]. Unlike traditional approaches [
5,
6,
7], WRSN fundamentally overcomes the predicament of nodes relying solely on battery power. It provides a promising solution for the sustainable energy replenishment of nodes [
8,
9,
10]. WRSN normally includes one or more mobile charging vehicles (MCVs) and a base station (BS) for the battery replacement of MCVs. MCV can move autonomously and is equipped with a wireless charging device to replenish energy for nodes by wireless charging. However, in remote and harsh environments, e.g., farmlands, forests, or disaster areas, it becomes challenging for ground vehicles to enter designated areas and perform close-range wireless charging [
11,
12,
13]. Utilizing UAVs as aerial mobile vehicles to provide remote services to ground devices is considered to bring significant benefits to WRSN [
14]. UAV possesses excellent maneuverability, coverage capabilities, and relatively low operating costs. It can perform various tasks within the network coverage, such as routing, communication, data collection, and energy supply [
15,
16,
17,
18]. In UAV-assisted wireless rechargeable sensor networks (UAV-WRSNs), UAVs can serve both as energy transmitters and data transceivers. By continuously accessing and exchanging data with nodes within their communication range, they can forward the data to the BS. This eliminates the energy consumption caused by multihop transmissions between nodes. Additionally, UAVs provide range-based charging to ensure simultaneous data collection and energy replenishment.
Although UAV offers new possibilities for the future development of WRSN, more research is needed to consider the unified process of node energy replenishment and data collection in UAV-WRSN. There are still unresolved issues in UAV-WRSN. For example, in a one-on-one node service scenario, UAV must hover multiple times, increasing hover time and energy consumption, leading to subsequent node data overflow or energy depletion. Moreover, target node selection is crucial to enable UAV to cover more nodes with each hover. In practical environments, there is a significant difference in energy consumption among nodes, and some nodes may run out of energy earlier due to heavy loads. Therefore, balancing node energy consumption and solving the problem of energy imbalance among nodes are equally important. Based on the above issues, this paper proposes D-JERDG, which integrates node joint energy replenishment and data collection using deep reinforcement learning.
The main contributions of this study can be summarized as follows:
First, we consider deploying UAV in delay-tolerant WRSN and combining wireless power transfer (WPT) with wireless information transfer (WIT) technologies. To achieve the unified process of sensor node energy replenishment and mobile data collection, we propose a deep-reinforcement-learning-based method called D-JERDG for UAV-WRSN.
We introduce a cluster head selection algorithm based on an improved dynamic routing protocol to minimize the number of UAVs hovering and balance node energy consumption. Based on the obtained cluster head visiting sequence, we employ the simulated annealing algorithm [
19] to approximate the optimal solution for the traveling salesman problem (TSP), thereby reducing the UAV flight distance. We then employ the DRL model MODDPG [
20] and design a multiobjective optimized reward function to control the UAV instantaneous speed and heading, aiming to minimize the node death rate and the UAV’s average energy consumption.
Simulation results are conducted to evaluate the feasibility and effectiveness of D-JERDG. The results demonstrate that D-JERDG outperforms existing algorithms in node death rate, time utilization, and charging cost.
The remaining parts of this paper are as follows:
Section 2 introduces related work,
Section 3 describes the system model and problem formulation of UAV-WRSN,
Section 4 presents the cluster head selection algorithm based on an improved dynamic routing protocol and the MODDPG algorithm in D-JERDG,
Section 5 validates the effectiveness and feasibility of D-JERDG through comparative experiments, and
Section 6 summarizes the paper and discusses future research directions.
2. Related Work
In this section, we provide a brief overview of the existing work in three relevant domains: cluster-based networks [
21,
22,
23,
24,
25,
26,
27,
28], traditional algorithm-based UAV trajectory planning [
29,
30,
31,
32,
33,
34,
35,
36,
37], and DRL-based UAV trajectory planning [
38,
39,
40,
41,
42,
43].
In traditional WRSN, the one-to-one node charging mode can often lead to inefficient movement of MCV, resulting in wastage of energy. Moreover, the convergence nodes bear the primary data transmission tasks, leading to faster energy depletion and premature failure of nodes, thus affecting the overall network lifetime. To balance the energy consumption of nodes, the charging method often involves dividing the nodes into several clusters using a hierarchical clustering approach. Within each cluster, a few nodes closest to the base station (BS) are selected as cluster heads, and communication links are established between the cluster heads and the BS, such as LEACH [
21], K-means [
22], Hausdorff [
23], and HEED [
24]. These methods typically use a rotating cluster head approach to reduce energy consumption and extend network lifetime. For example, in [
25,
26,
27,
28], the authors studied the division of the network into multiple clusters using clustering algorithms. They employed a mobile charger (MC) to periodically replenish the energy of anchor nodes in each cluster according to the generated shortest visiting path. Wu et al. designed a joint solution that integrates both aspects and proposed a heuristic-based MC scheduling scheme to maximize the charging efficiency of the MC while minimizing its energy consumption [
25]. Li et al. proposed an energy-efficiency-oriented heterogeneous paradigm (EEHP), which is a routing protocol based on multihop data transmission. It reduces the energy consumption for data transmission by employing multihop data transfer and shortens the charging distance for the MC [
26]. Han et al. used the K-means clustering algorithm to divide the network into multiple clusters and proposed a semi-Markov model to update anchor nodes. They deployed two MCs that periodically moved in opposite directions to visit anchor nodes, charging the sensor nodes (SNs) within the charging range and collecting data from the cluster heads [
27]. Zhao et al. focused on achieving joint optimization of efficient charging and data collection in randomly deployed WRSN. They periodically selected anchor points and arranged MCV to visit these locations and charge the nodes sequentially [
28].
For sustainable monitoring, WRSN can be applied in remote and resource-limited areas, such as rural farmlands, forests, or disaster zones [
29]. In such harsh environments, UAVs can be used as auxiliary aerial base stations to efficiently collect data and replenish node energy, which significantly benefits WRSN [
30]. For example, in [
31,
32,
33,
34], researchers studied scheduling and designing UAV trajectories to improve the system charging efficiency. Xu et al. studied a new UAV-enabled wireless power transfer system to maximize the total energy received by considering the optimization of the trajectory of UAV under the maximum velocity constraint [
31]. Liu et al. proposed UAV-WRSN and solved the subproblems of UAV scheduling and trajectory optimization separately. They aimed to minimize the number of UAV hover points, SN with repeated coverage, and UAV flight distance [
32]. Wu et al. investigated the trajectory optimization problem for UAV in UAV-WRSN. They decomposed the problem of maximizing energy efficiency into an integer programming problem and a nonconvex optimization problem, effectively reducing the UAV flight distance and algorithm complexity and maximizing the energy utilization efficiency of the UAV [
33]. Zhao et al. proposed an improved ant colony algorithm to plan UAV flight trajectories, achieving shorter flight paths and network lifetimes [
34]. In [
35,
36,
37], researchers explored using UAVs as data collectors and mobile chargers, simultaneously providing data collection and energy transfer to the nodes. Baek et al. considered node energy consumption and replenishment to maximize the WRSN lifetime. They optimized the UAV hover locations and durations to maximize the remaining energy of the nodes [
35]. Lin et al. studied the collaboration between rechargeable sensors and UAVs to accomplish regular coverage tasks. They introduced a new concept of coverage called periodic area coverage, aiming to maximize the energy efficiency of the UAV [
36]. Hu et al. formulated a nonconvex optimization problem to minimize the average age of information (AoI). They divided it into a time allocation problem and UAV trajectory optimization problem and solved it optimally using dynamic programming and ant colony algorithms [
37].
DRL has proven to be an effective solution for decision-making problems on sequential data. It has been widely applied in various fields and has achieved notable results. In the context of UAV-WRSN, several studies are worth mentioning: Bouhamed et al. employed two reinforcement learning (RL) methods, namely, deep deterministic policy gradient (DDPG) and Q-learning (QL), to train UAV for data collection tasks. DDPG was utilized to optimize UAV flight trajectories in environments with obstacle constraints, while QL was used to determine the order of visiting nodes [
38]. Liu et al. proposed a UAV path planning based on reinforcement learning, which enables the UAV to respond to the position change of the cluster nodes, reduces the flight distance and the energy consumption, and increases the time utilization ratio [
39]. Li et al. proposed a flight resource allocation framework based on the DDPG algorithm. They optimized the UAV instantaneous heading, speed, and selection of target nodes. They utilized a state representation layer based on long short-term memory (LSTM) to predict network dynamics and minimize data packet loss [
40]. Shan et al. presented a DRL-based trajectory planning scheme for multi-UAVs in WRSN. They established a network model for multi-UAV path planning. They optimized the network model using an improved hybrid energy-efficient distributed (HEED) clustering algorithm to obtain the optimal charging path [
41]. Liu et al. considered WRSN assisted by UAVs and vehicles. In their study, UAVs served as mobile chargers to replenish energy for nodes, while mobile vehicles acted as mobile base stations to replace UAV batteries. The authors utilized a multiobjective deep Q-network (DQN) algorithm to minimize sensor downtime and optimize UAV energy consumption [
42]. Wang et al. proposed a dynamic spatiotemporal charging scheduling scheme based on deep reinforcement learning, given the discrete charging sequence planning and continuous charging duration adjustment in mobile charging scheduling, to improve the charging performance while avoiding the power death of nodes [
43].
Table 1 shows how the related work differs from our scheme.
3. System Model and Problem Formulation
In this section, we present the system model and problem formulation of UAV-assisted wireless rechargeable sensor networks (UAV-WRSNs). For the sake of clarity,
Table 2 lists the symbols used in this paper.
3.1. System Model
3.1.1. Network Model
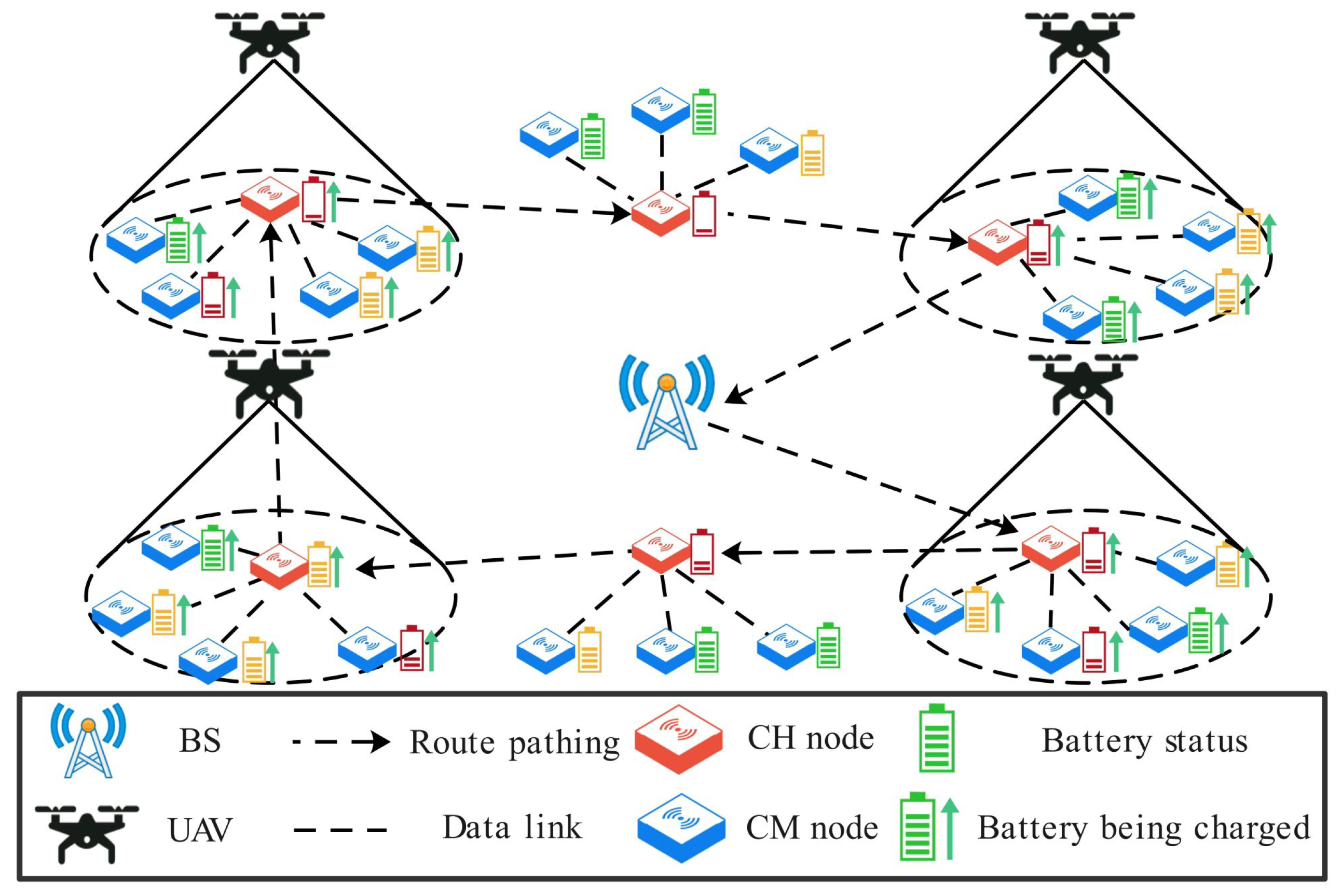
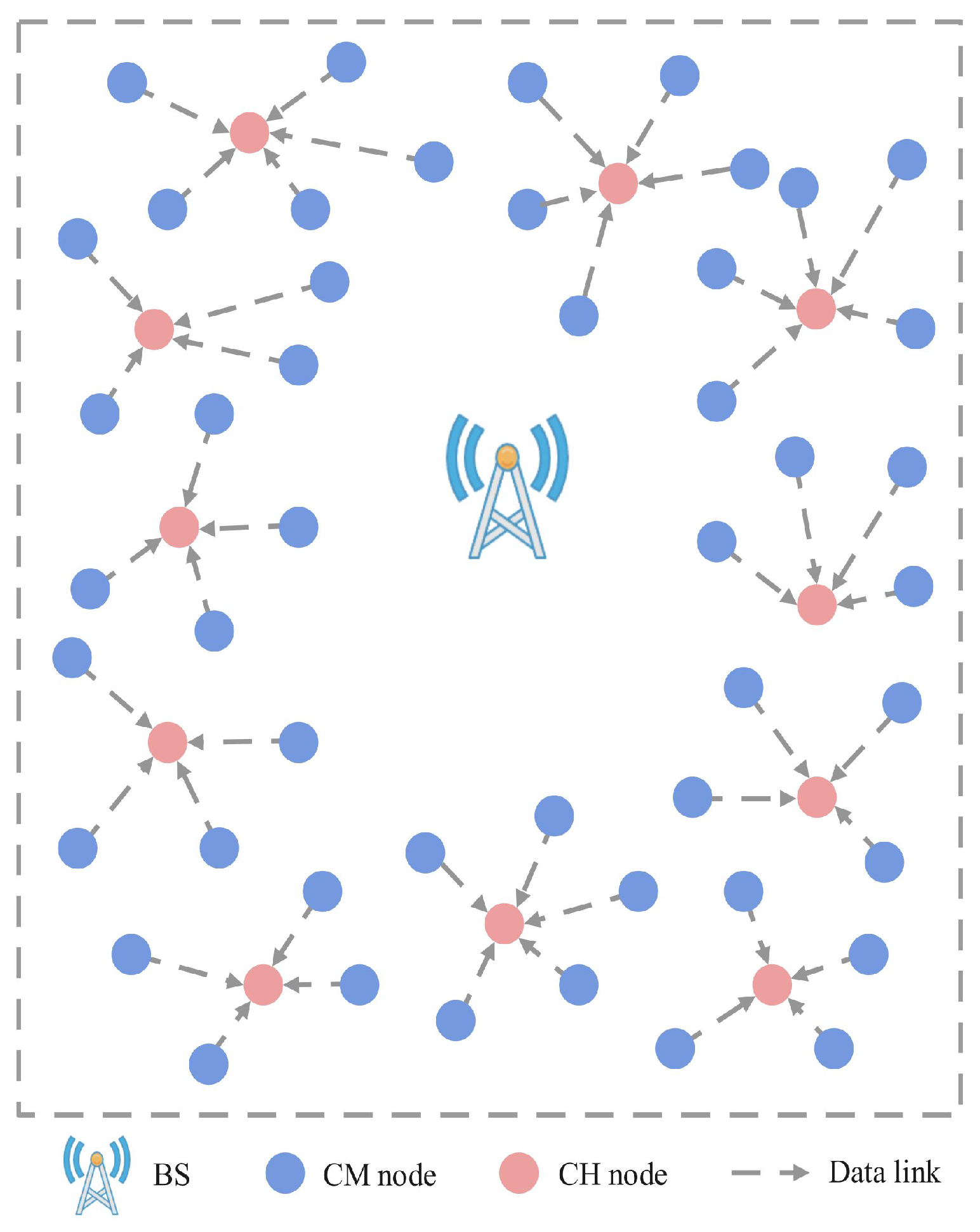
As shown in
Figure 1, the network is deployed in a two-dimensional area and consists of a UAV, a base station (BS), and randomly distributed sensor nodes. The UAV is assumed to have computing and wireless transmission capabilities, be equipped with a sufficiently charged battery, and be able to obtain its position through the Global Positioning System (GPS). The BS has ample energy and communication capabilities, enabling direct wireless communication with the UAV. The sensor nodes can monitor their remaining energy and data fusion capabilities. Cluster member (CM) nodes send data packets to cluster head (CH) nodes, which aggregate the data and store them in a data buffer. The UAV takes off from the BS and follows a “fly-hover” pattern to visit each CH node in a predetermined order continuously. The CH nodes consume energy to upload data packets to the UAV, while the UAV provides charging to the nodes within its coverage range using radio frequency transmission technology.
3.1.2. Sensor Node Model
The network deploys
k sensor nodes with fixed and known positions. Consider the set of nodes in the network as
. The CH nodes are denoted as
, and the CM nodes are denoted as
. Assuming that node batteries can be charged within a very short time compared with the data collection time by the UAV, we can neglect the charging time. Regarding the energy consumption of nodes in sleep mode, since this portion of energy consumption is very small and can be considered negligible, we have not included it as a significant influencing factor, and therefore, it has not been incorporated into the node energy consumption. Nodes only consume energy when receiving and transmitting data. The data buffer length of the CH node
at
t is denoted as
. Based on the literature [
43], assuming that, at any time
t, the energy consumption of the CM node
sending a unit data packet (where the unit data packet size
f is 1024 kb) to the CH node
can be given as follows:
where
indicates the energy consumption of transmitting unit data, the energy consumption of the CH node
can be divided into two parts: reception energy and transmission energy:
where
indicates the energy consumption of receiving unit data, and the remaining energy of the CM node
and the CH node
at
t can be respectively defined as follows:
3.1.3. UAV Model
The UAV maintains a fixed flight altitude of
H. It acquires the positions of all nodes before taking off from the base station and maintains communication with the base station throughout the operation. At
t, the three-dimensional coordinates of the UAV can be represented as
. The distance between the UAV and the node plays a crucial role in determining the link quality and the ability of the node to upload data. In our scenario, we assume that the UAV has limited communication and charging ranges, denoted as
(maximum data transmission radius) and
(maximum charging radius), respectively.
represents the distance between the UAV and the target CH node if
; the UAV enters the hovering state to collect data from the target CH node and charge all nodes within the charging range. The instantaneous speed
and the instantaneous heading angle
describe the flight control of the UAV. For safety reasons,
must be within the minimum and maximum speed limits.
This paper employs a rotor-wing UAV, and the energy consumption of the UAV can be divided into propulsion energy consumption and communication energy consumption. The propulsion energy consumption is further divided into flight energy consumption and hovering energy consumption [
20]. When the UAV has an instantaneous speed
, the propulsion energy consumption model of the UAV can be given as follows:
where
and
are constants that represent the blade profile power and induced power in hovering status, respectively;
indicates the tip speed of the rotor blade;
denotes the mean rotor-induced speed; and
,
,
, and
, respectively, denote the fuselage drag ratio, air density, rotor solidity, and rotor disc area. At t, UAV speed is
, and the flight energy consumption is expressed as
. It is worth noting that the UAV is in hovering status with flight speed
and hovering energy consumption
. To facilitate the expression, we divide the time domain
T into
n time steps, where each time step is denoted as
; thus, the total flight energy consumption of the UAV at each time step
is given as follows:
the UAV’s average flight energy consumption is given as follows:
3.1.4. Transmission Model
The wireless communication link between the UAV and the nodes mainly consists of a line-of-sight (LoS) link and a non-line-of-sight (NLoS) link, similar to many existing works [
20,
39,
40]. Let the coordinate of the target CH node
be
; the free path loss of the LoS link between the UAV and
at
t is modeled as follows:
where the channel’s power gain at a reference distance of
m is denoted by
, and
denotes the Euclidean distance between the UAV and
at
t, where the path loss of the NLoS link is given as
, and
is the attenuation coefficient of the NLoS links.
At
t, the LoS link probability between the UAV and
is modeled as follows:
where
and
are constant sigmoid parameters that depend on the signal propagation environment and propagation distance.
is the elevation angle of the UAV and
in degree; it is given as
. The NLoS link probability is given as follows:
let
be the wireless channel gain between the UAV and
; it is modeled as follows:
in this paper, we assume that the uplink and downlink channels are approximately equal. As a result, the channel power gain between the UAV and
is given as follows:
Assuming that the UAV establishes a communication link with
at
t and
maintains a constant transmit power
to upload data to the UAV, according to Shannon’s formula [
44], the data transmission rate between the UAV and
can be given as follows:
where
B and
represent the channel bandwidth and noise power, respectively, and
denotes the transmit power of the node; hovering time (upload data time) is given as follows:
the energy consumption for
to upload data at time
t can be given as follows:
3.2. Problem Formulation
In the proposed D-JERDG, we consider the UAV capabilities of energy replenishment and data collection. The UAV departs from the BS and moves according to a planned flight path. It is responsible for collecting data generated by all cluster heads in the network. After completing a mission cycle, the UAV returns to the BS to recharge and transmit the collected data back to the BS. The flight path consists of the hovering positions and the CH node access sequence. First, to improve data collection efficiency, the UAV needs to serve as many nodes as possible within the maximum flight time T and collect data. Second, the charging strategy for the target CH node is crucial to minimize the node death rate and flight costs. To ensure that high-energy-consuming nodes and remote area nodes receive energy replenishment while reducing ineffective flight time, the UAV flight distance and speed need to be controlled.
In summary, the overall objective of D-JERDG is to minimize the UAV flight energy consumption and maximize its throughput while minimizing the node death rate. This problem is a multiobjective optimization problem, and the objective functions can be formulated as follows:
The constraint condition can be formulated as follows:
In objective functions, is denoted as the number of dead nodes, represents the total flight distance, and represents the UAV’s average flight energy consumption. In the constraint condition, Formula (18) represents the UAV with a maximum flight time of no more than T. Formula (19) represents the maximum data transmission range of the node into the UAV to establish a communication link with the UAV. Formula (20) indicates that nodes can harvest energy from the UAV within the maximum charging range of the UAV. Formula (21) represents the energy state. If , node i is considered a dead node. If , node i is in a normal state. Formulas (22) and (23) represent the size limit of the UAV’s speed and heading angle. Formulas (24) and (25) represent that the UAV’s flight range does not extend beyond the two-dimensional area.
5. Experimental Results
In this section, we conducted simulation results to validate the effectiveness of D-JERDG. Specifically, we provided numerical results and analyzed the convergence of D-JERDG by adjusting the number of CM nodes, CH nodes, and maximum charging radius. We compared D-JERDG with MODDPG and the random method. We analyzed the differences between the algorithms from five aspects: node death rate, data overflow rate, UAV throughput, average flight energy consumption, and time utilization. By comparing these metrics, we were able to evaluate and highlight the differences and advantages of D-JERDG over the other algorithms in terms of efficiency and performance.
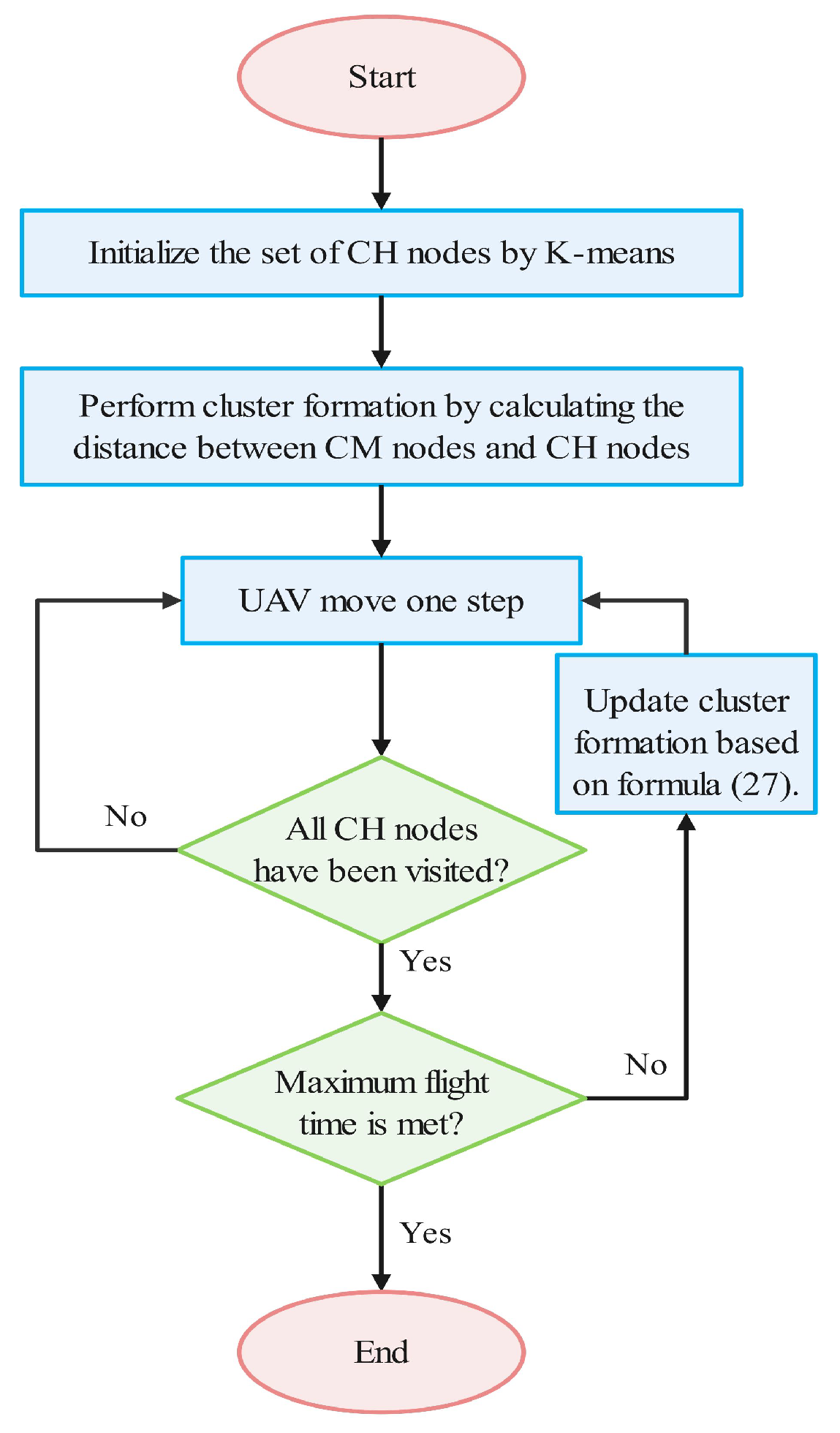
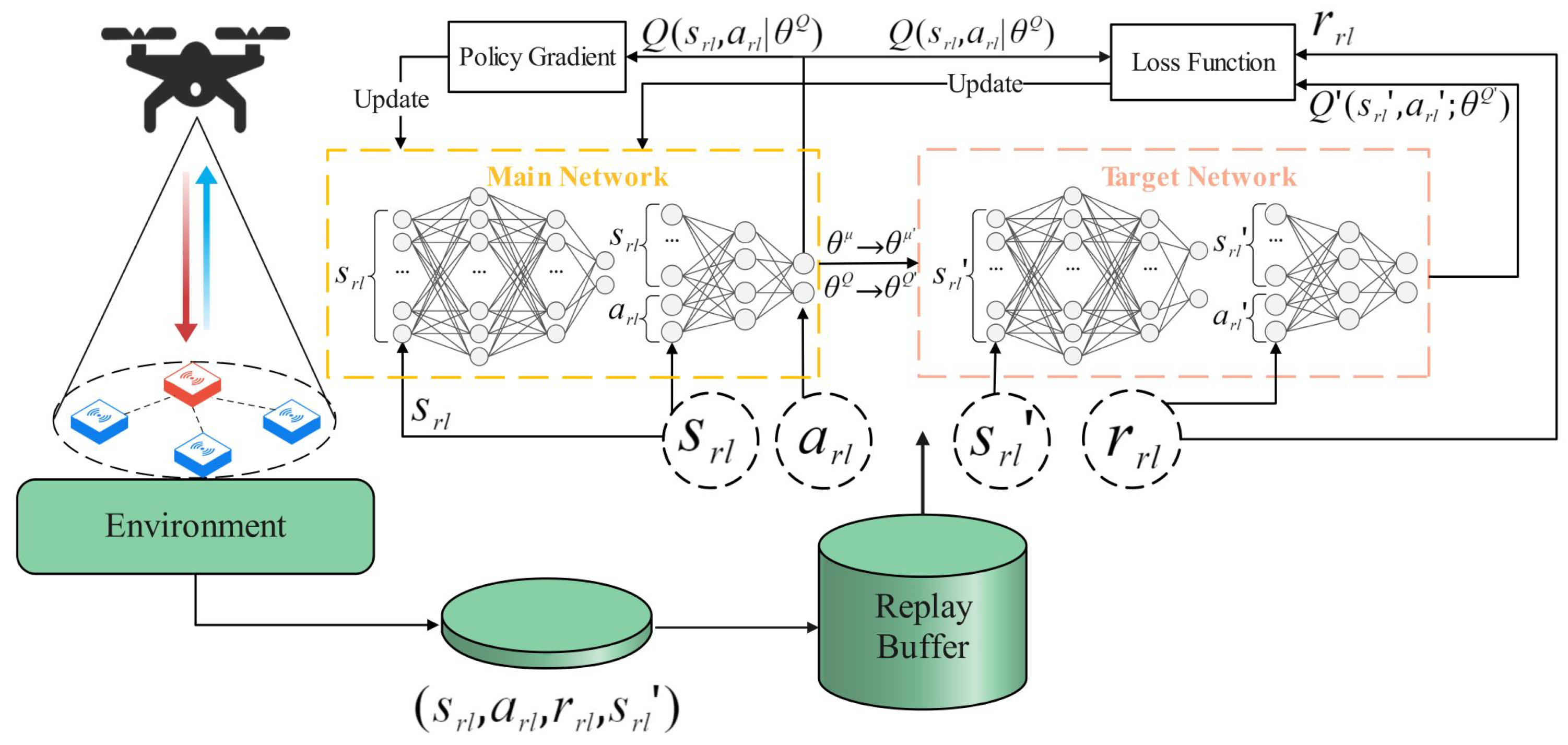
D-JERDG: D-JERDG uses the K-means clustering algorithm to divide nodes into multiple clusters, designing the CH node selection mechanism based on an improved dynamic routing protocol. The SA algorithm determines the CH node access sequence, and the UAV flight actions are controlled by inputting the UAV and network states into the DRL model MODDPG.
MODDPG (multiobjective deep deterministic policy gradient) [
20]: This method selects the node with the highest data volume as the target node. By observing the relative positions of the UAV and the target node, as well as the node states, a DRL model is established to control the UAV learning of all node positions. Through accessing the nodes, data collection and range-based charging are achieved.
Random: The method is based on the MODDPG [
20] definition, with the difference being that the random algorithm randomly selects a node as the target node and uses the DRL model to optimize the UAV’s flight trajectory.
5.1. Simulation Settings
We consider the UAV taking off from the BS, the maximum flight time
T to be set at 10 min. The sensor nodes are randomly distributed within a
square two-dimensional area. The UAV flies at an altitude of 10 m, with a maximum data transmission radius
m and a maximum charging radius
m. The maximum flight speed of the UAV is set to 20 m/s [
20]. The coordinates of the nodes are randomly generated and remain fixed. The nodes’ maximum data storage capacity is
Mb [
40]. The total energy of the nodes is set to
J [
40], and their initial energy is randomly generated within the range of [0 J, 800 J] [
40]. The transmission energy consumption for CM nodes is
J [
43], and the reception energy consumption for CH nodes is
J [
43].
Table 3 and
Table 4, respectively, show the network parameters of MODDPG and the main environmental parameters, as specified in reference [
20]. The operating system environment of the simulation experiment is TensorFlow 2.5.0, TensorLayer 2.2.5, and Python 3.7 on a Linux server with four NVIDIA 3090 GPUs.
5.2. Evaluation Metrics
We introduce five key performance metrics to analyze and compare the optimization effects of D-JERDG on UAV-WRSN in terms of system charging efficiency, data collection efficiency, and UAV flight energy consumption.
Node death rate: The node death rate is determined by the proportion of dead nodes, where node i is considered dead when . A lower node death rate indicates a higher system charging efficiency. This metric determines which charging strategy can maintain the maximum number of surviving nodes in the experiment.
Node data overflow rate: The node data overflow rate is determined by the proportion of nodes with data storage exceeding the maximum capacity, represented as . This metric measures the effectiveness of UAV data collection and the clustering algorithm.
UAV throughput: The UAV throughput is the ratio of the number of nodes accessed by the UAV to the total number of nodes within the maximum flight time. It measures the overall efficiency of the UAV-WRSN system.
Average flight energy consumption: The average flight energy consumption is defined as the ratio of the total energy consumption during UAV flight to the maximum flight time. It is a key indicator for evaluating the energy consumption of the UAV-WRSN system.
Time utilization rate: The time utilization rate represents the ratio of the hover time to the flight time of the UAV during a flight mission. A lower time utilization indicates a higher proportion of time occupied by UAV flights, serving as a metric for evaluating the data collection efficiency of the UAV. The time utilization rate
is given as follows:
5.3. Convergence and Stability
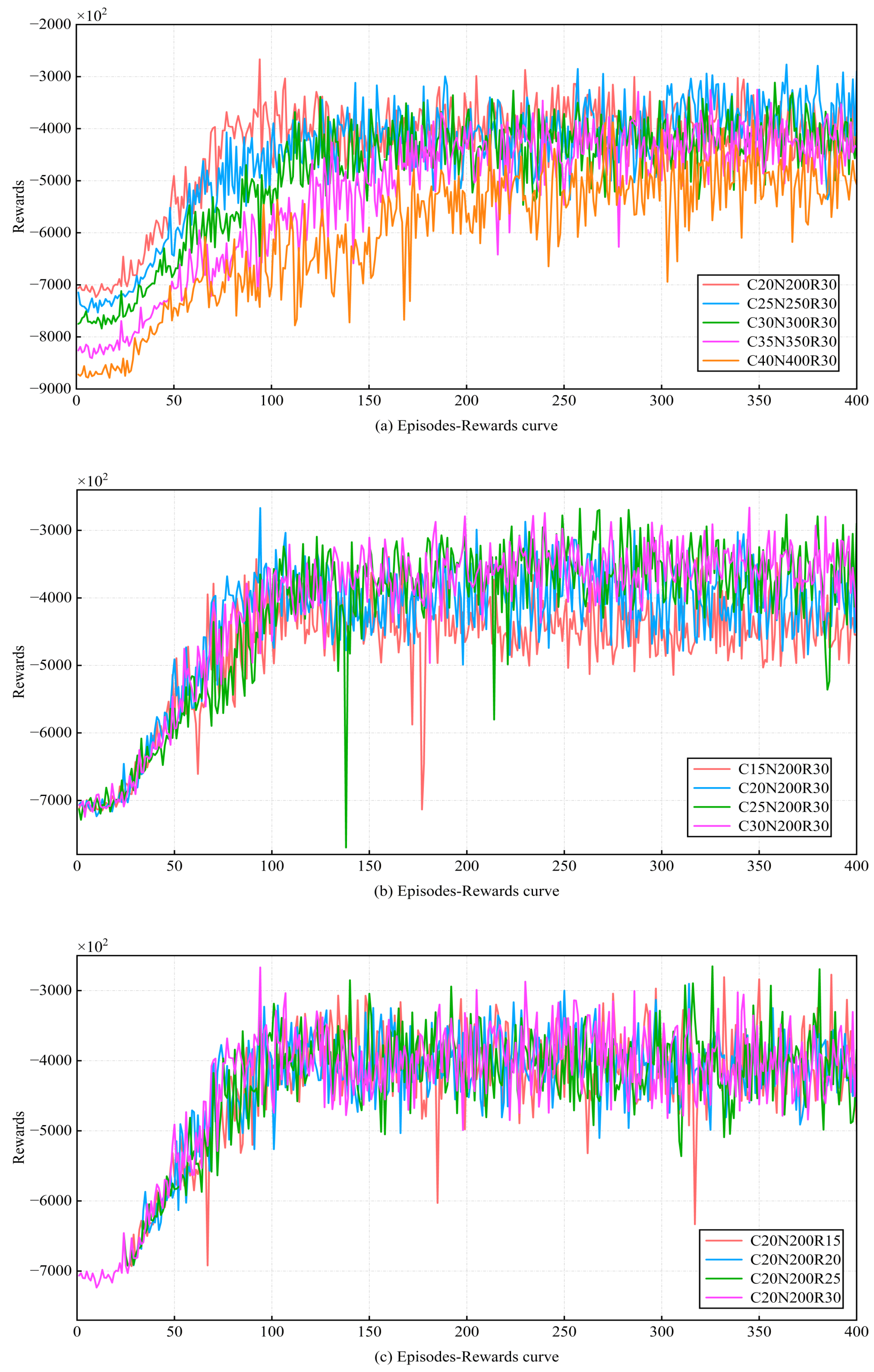
After D-JERDG is implemented, we first test the convergence and stability of the proposed model. The episode was set as 400, and the model of the number of different clusters, the number of nodes in each cluster, and the maximum charging radius of the UAV were trained. “C20N200R30” means that there are 20 CH nodes and 180 CM nodes, the maximum charging radius of UAV is
m, and the other sections in this chapter follow the same pattern. Then the functional relationship between episode and reward is shown in
Figure 5. As can be seen from
Figure 5, the reward of most models increased rapidly before 150 episodes. After 200 episodes, the value of rewards becomes stable and oscillates around a certain value until the training ends. The results indicate that the trained D-JERDG algorithm successfully converges and can make high-reward decisions in a dynamically changing network state.
Figure 5a shows the reward curves under different numbers of CH nodes and CM nodes, ranging from “C20N200R30” to “C40N400R30” experimental scenarios.
Figure 5b displays the reward curves for different numbers of CH nodes, with the experimental scenarios ranging from “C15N200R30” to “C30N200R30”.
Figure 5c illustrates the reward curves under different UAV charging radii, with the experimental scenarios ranging from “C20N200R15” to “C20N200R30”.
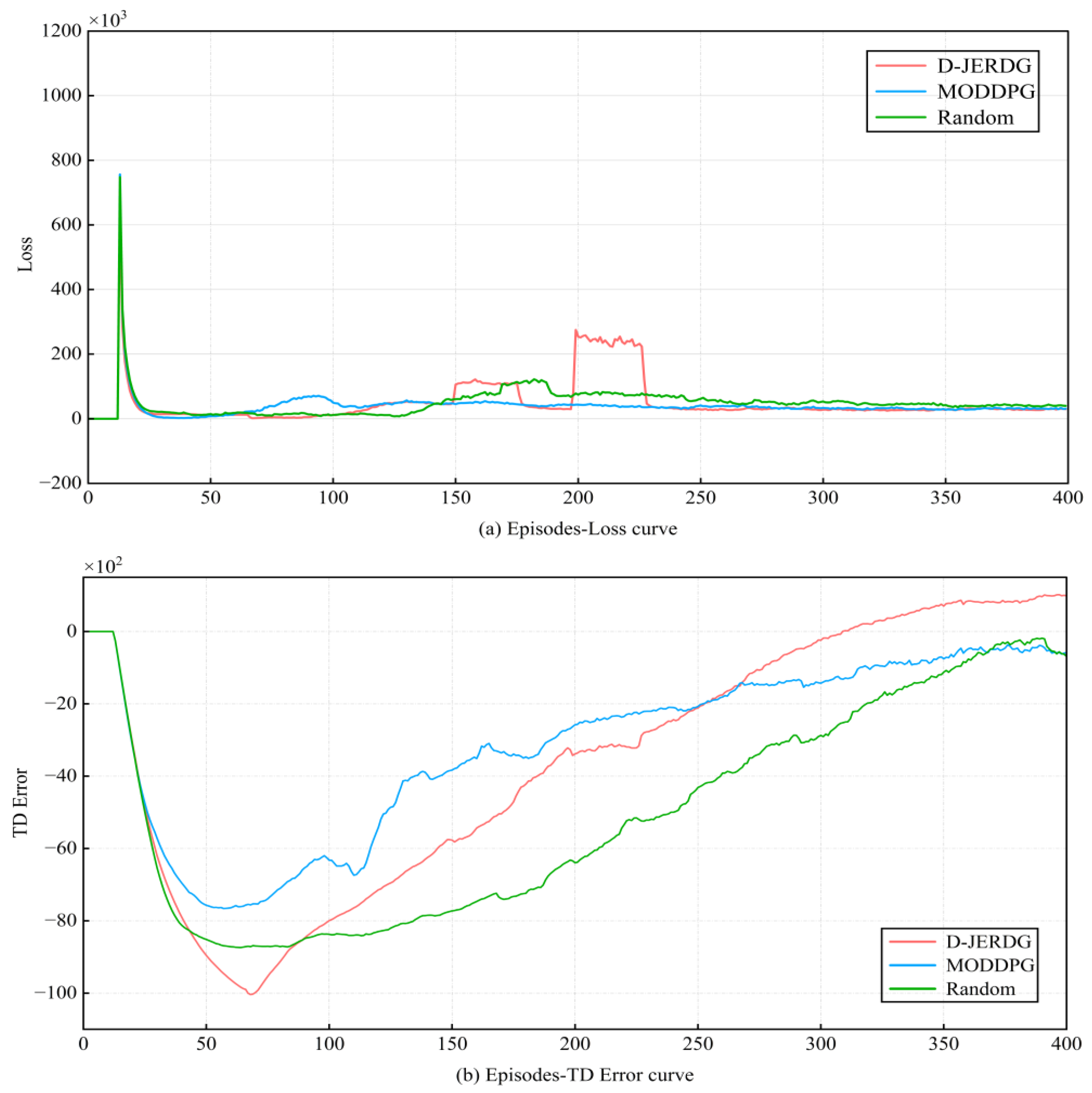
Additionally,
Figure 6 displays the loss curve and temporal difference error (TD error) curve of network training for the three algorithms, with the experimental scenario being “C20N200R30”. In
Figure 6a, the curve trends of the three algorithms are mostly consistent before 150 episodes. After that, due to the increased UAV throughput in D-JERDG, some fluctuations occur. However, overall, the loss curves of the three algorithms converge before 400 episodes. In
Figure 6b, we show the TD error curve of network training for the three algorithms. Overall, all three algorithms can converge before 400 iterations. However, before 100 episodes, D-JERDG has a slower convergence rate compared with the other two algorithms. Because we expect D-JERDG to learn the positions of more nodes in the early training episodes, we have implemented a strategy where the set of CH nodes initialized using the K-means algorithm is not fixed. The purpose of this approach is to ensure that D-JERDG can learn the positions of as many nodes as possible. By flexibly adjusting the CH node set, D-JERDG can better adapt to the varying node distributions in different environments, enhancing its performance and training effectiveness. After 100 episodes, as the rewards for D-JERDG start to increase and gradually converge, it also exhibits convergence in the TD error curve.
5.4. Performance Comparison
Specifically, without loss of generality, we conducted experiments with different numbers of nodes and varying UAV flight speeds. The number of nodes was set from “C10N100R30” to “C40N400R30”, with a maximum data transmission radius of m, a maximum charging radius of m, and a maximum flight speed ranging from 15 m/s to 20 m/s. With an increasing number of nodes, both the energy consumption and data volume of CH nodes increase within the same period. A larger flight speed allows the UAV to reach nodes faster, but it also increases energy consumption. On the other hand, a smaller speed can save energy but may sacrifice some throughput and result in a certain number of dead nodes, thereby affecting UAV throughput, the number of dead nodes, and time utilization. Additionally, as the number of nodes increases, in our proposed approach, the UAV flight time and distance are influenced by the increasing number of CH nodes, which also affects flight energy consumption. Based on these hypotheses, we conducted comparative experiments.
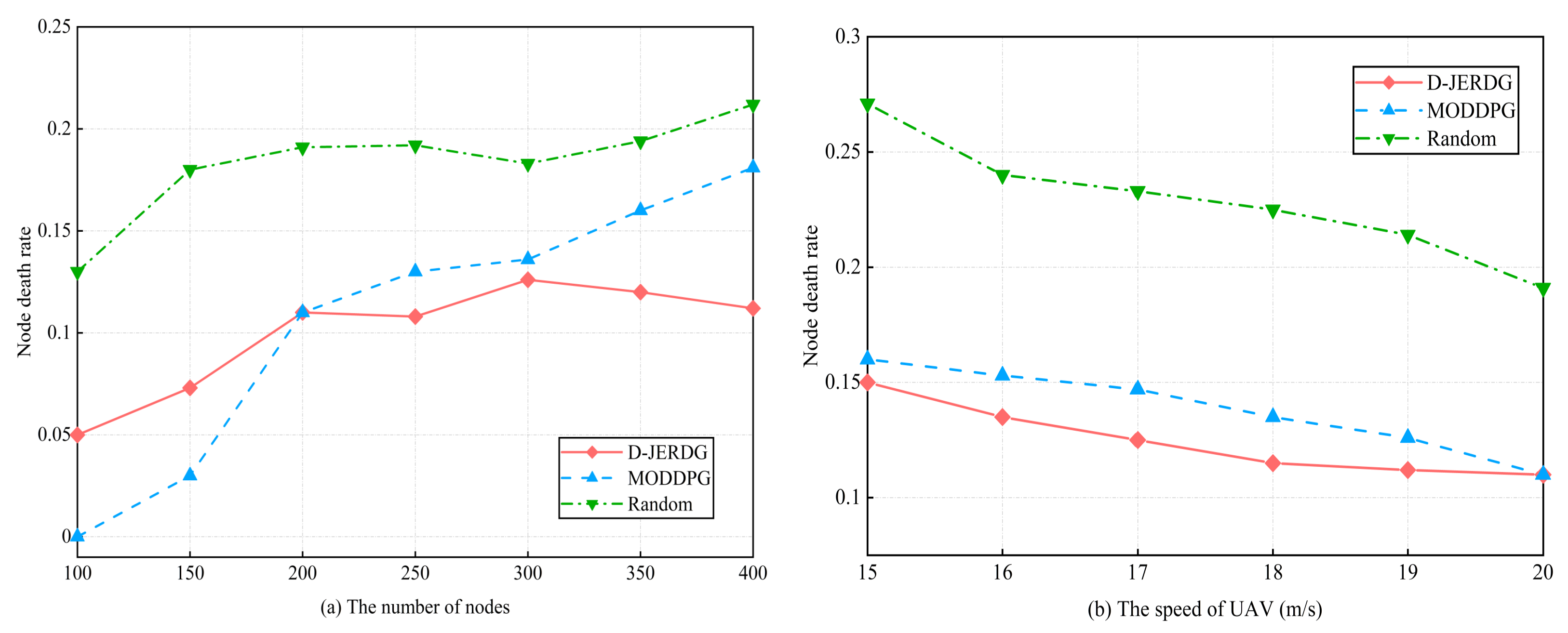
5.4.1. Node Death Rate
In this section, we compared the performances of different algorithms in terms of node death rate. Specifically, in the MODDPG experiment, we designated the node with the least remaining energy as the target node. The experimental results are shown in
Figure 7.
Figure 7a demonstrated a clear disparity in node death rates between D-JERDG and Random. Initially, MODDPG exhibited lower node death rates than D-JERDG for up to 200 nodes. This can be attributed to the advantage of the greedy-based node charging strategy in scenarios with a small number of nodes and low density. However, after reaching 200 nodes, D-JERDG demonstrated a lower node death rate than MODDPG, with a declining trend beyond 300 nodes. When the number of nodes is 250, compared with the MODDPG and random, D-JERDG can decrease the node death rate by about
and
, respectively. This improvement can be attributed to the clustering algorithm employed in D-JERDG, where several nodes closest to the CH node are selected as CM nodes. This approach ensures that the UAV covers more nodes during each hover, enhancing charging efficiency. The effectiveness of the proposed CH node selection mechanism was also validated, as it increased the likelihood of selecting CM nodes farther from the current CH node as new CH nodes. This enabled energy replenishment and reduced the node death rate of remote area nodes, making D-JERDG more suitable for large-scale networks aiming to maintain network connectivity. From
Figure 7b, we examined the variations in node death rates across different algorithms while considering different UAV flight speeds, with 200 nodes in the experiment. Overall, increasing the UAV flight speed resulted in reduced fluctuations in the node death rate, and D-JERDG consistently outperformed MODDPG and random by maintaining lower node death rates. When the speed of the UAV was 15 to 20, compared with MODDPG and random, the average decline rate of D-JEGDG in terms of node death rate was about
and
, respectively. Furthermore, as the flight speed increased, the node death rate exhibited a significant decrease. This highlights the advantageous performance of D-JERDG in terms of node death rate when compared with the other algorithms.
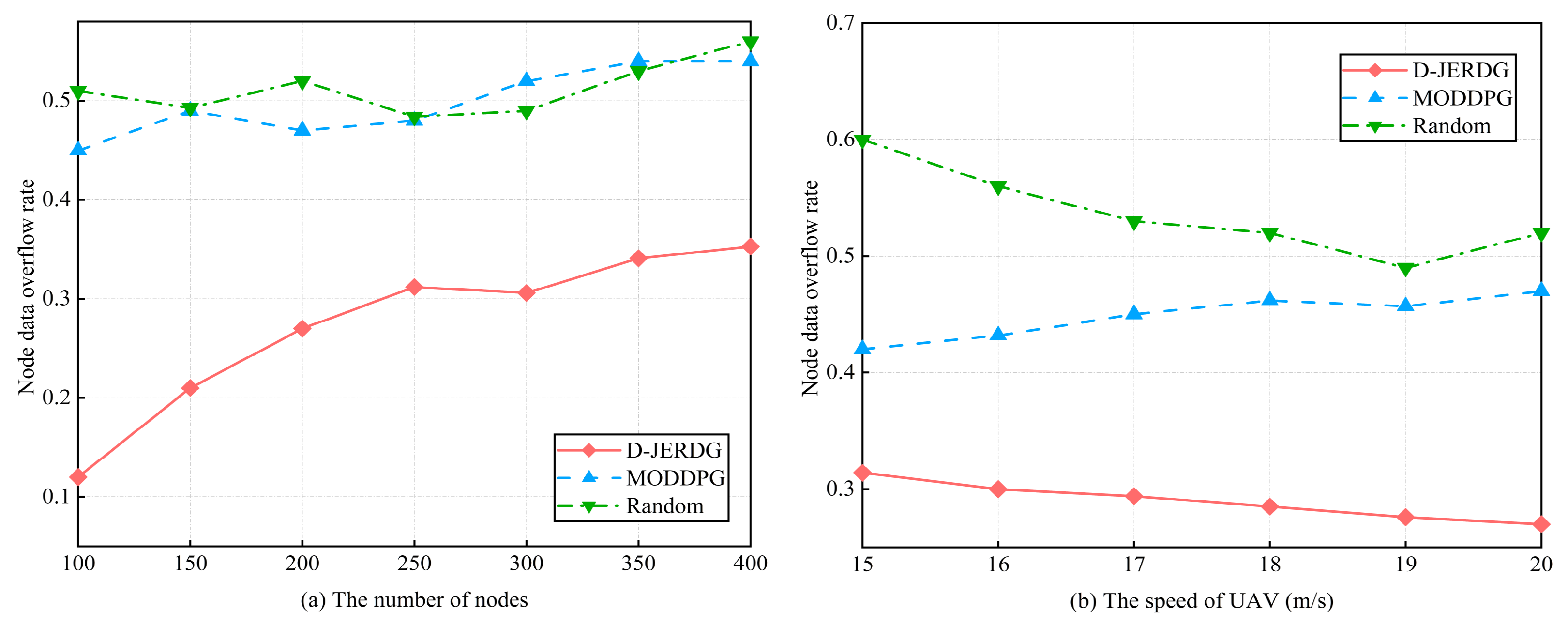
5.4.2. Node Data Overflow Rate
In this section, we analyze the differences in node data overflow rates among different algorithms. In the MODDPG experiment, we designate the node with the highest data volume as the target node, and the experimental results are shown in
Figure 8. In
Figure 8a,b, with an increasing number of nodes, compared with MODDPG and random, the average decline rate of D-JEGDG in terms of node overflow rate is about
and
, respectively. With an increasing speed of the UAV, it is about
and
, respectively. This is because the dynamic routing protocol periodically selects CM nodes as CH nodes, allowing CH nodes to gather data from CM nodes and reduce node data overflow. However, for MODDPG and random, the one-to-one data collection approach leads to lower efficiency and inevitable node data overflow.
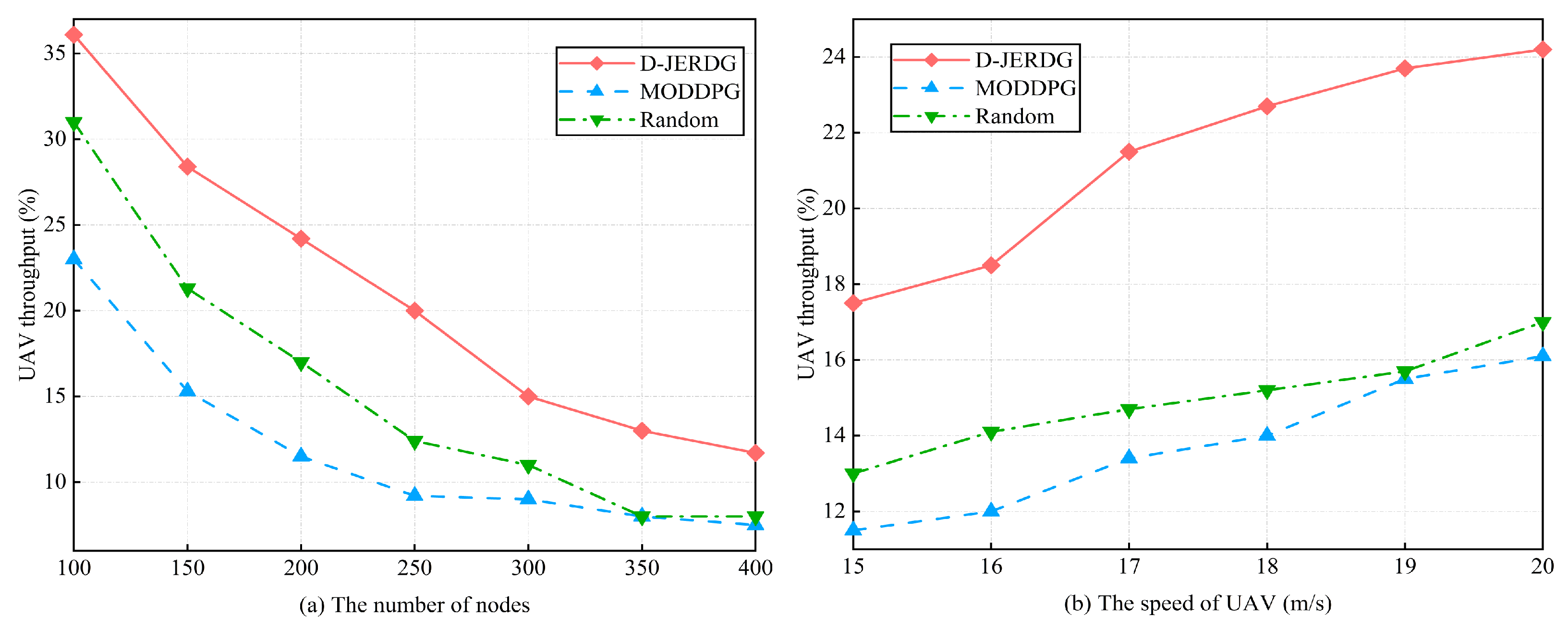
5.4.3. UAV Throughput
In this section, we compare the performances of different algorithms in terms of UAV throughput by changing the number of CH nodes and CM nodes in the network. The experimental results are shown in
Figure 9. In
Figure 9a, we observe that as the number of nodes increases, all algorithms experience a decrease in UAV throughput. However, D-JERDG consistently achieves the highest throughput among the algorithms. Compared with MODDPG and random, the average growth rate of D-JEGDG in terms of UAV throughput is about
and
, respectively. In D-JERDG, the use of a K-means-based clustering algorithm for CH node selection introduces randomness, allowing the UAV to quickly learn the positions of all nodes by obtaining different node coordinates in each training round. This enables D-JERDG to achieve a higher node access count within the same flight time. At 250 nodes, D-JERDG reaches a node access count of 50, indicating that it completes two rounds of CH node traversal. Beyond 300 nodes, D-JERDG throughput reaches a plateau and remains competitive with MODDPG. This can be attributed to the increased number of CH nodes requiring the UAV to spend more time hovering for data collection, leading to longer flight times and a decrease in node access count. In
Figure 9b, we analyze the impact of different UAV flight speeds on throughput with a fixed number of 200 nodes. Overall, compared with MODDPG and random, D-JERDG outperforms MODDPG and random algorithms, and the throughput significantly increases as the flight speed rises. The average growth rate of D-JEGDG in terms of UAV throughput is about
and
, respectively.
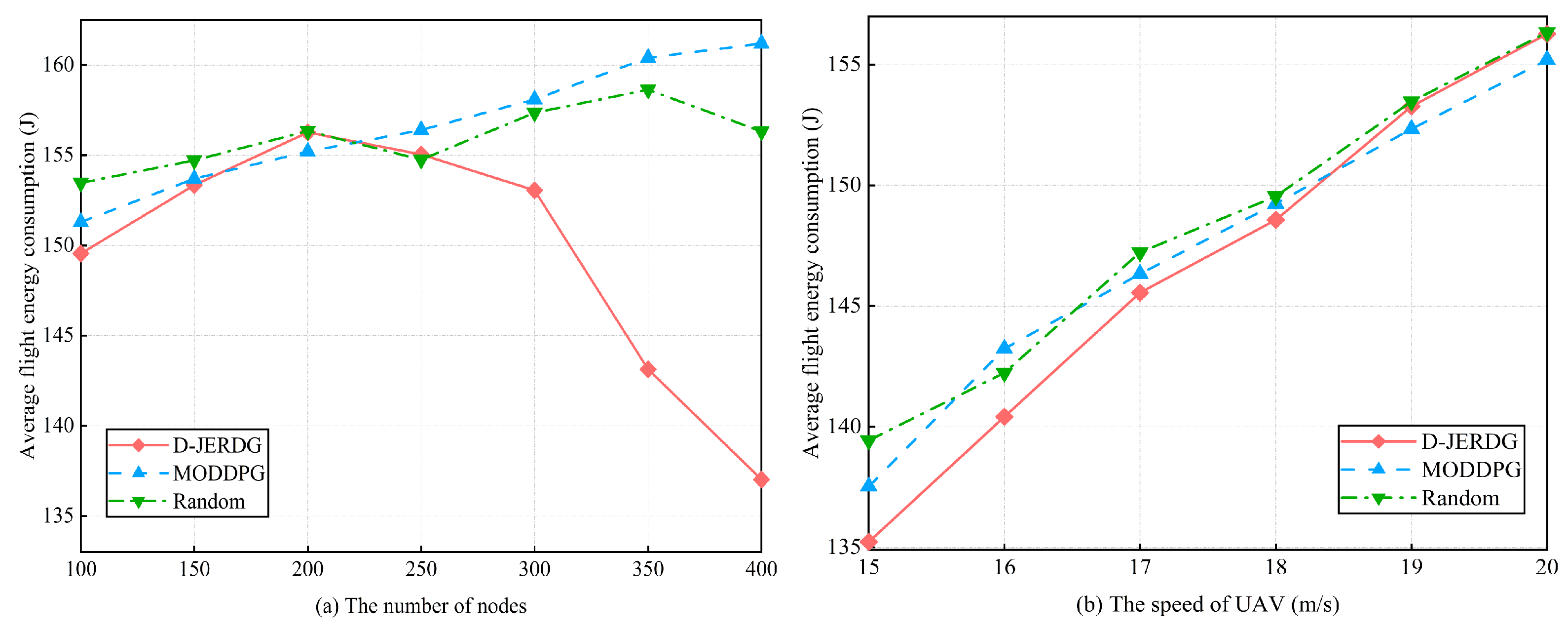
5.4.4. Average Flight Energy Consumption
In this section, we analyze the differences in average UAV flight energy consumption among three algorithms. The experimental results are depicted in
Figure 10. In
Figure 10a, we observe that the UAV energy consumption in D-JERDG initially increases and then decreases as the number of nodes increases. Before reaching 200 nodes, the larger distances between CH nodes prompt the UAV to adapt its flight speed to minimize the flight time and efficiently collect data, resulting in an increasing energy consumption curve. However, after 200 nodes, as the number and density of CH nodes increase, the distances between them become shorter. Compared with MODDPG and random, the average decline rate of D-JEGDG in terms of average flight energy consumption is about
and
, respectively. When the number of nodes is 350, D-JERDG can decrease the average flight energy consumption by about
and
, respectively. As a result, the UAV adjusts its flight speed by reducing it, which leads to longer flight times but decreases the overall UAV energy consumption. Compared with MODDPG and random, in
Figure 10b, we examine the impact of different flight speeds on average energy consumption under the three algorithms. Overall, there is no significant difference among the algorithms (D-JERDG, MODDPG, and random) in terms of average energy consumption. However, as the flight speed increases, the average energy consumption increases as well. Notably, D-JERDG consistently maintains a lower average UAV flight energy consumption compared with MODDPG and random algorithms under different flight speed conditions.
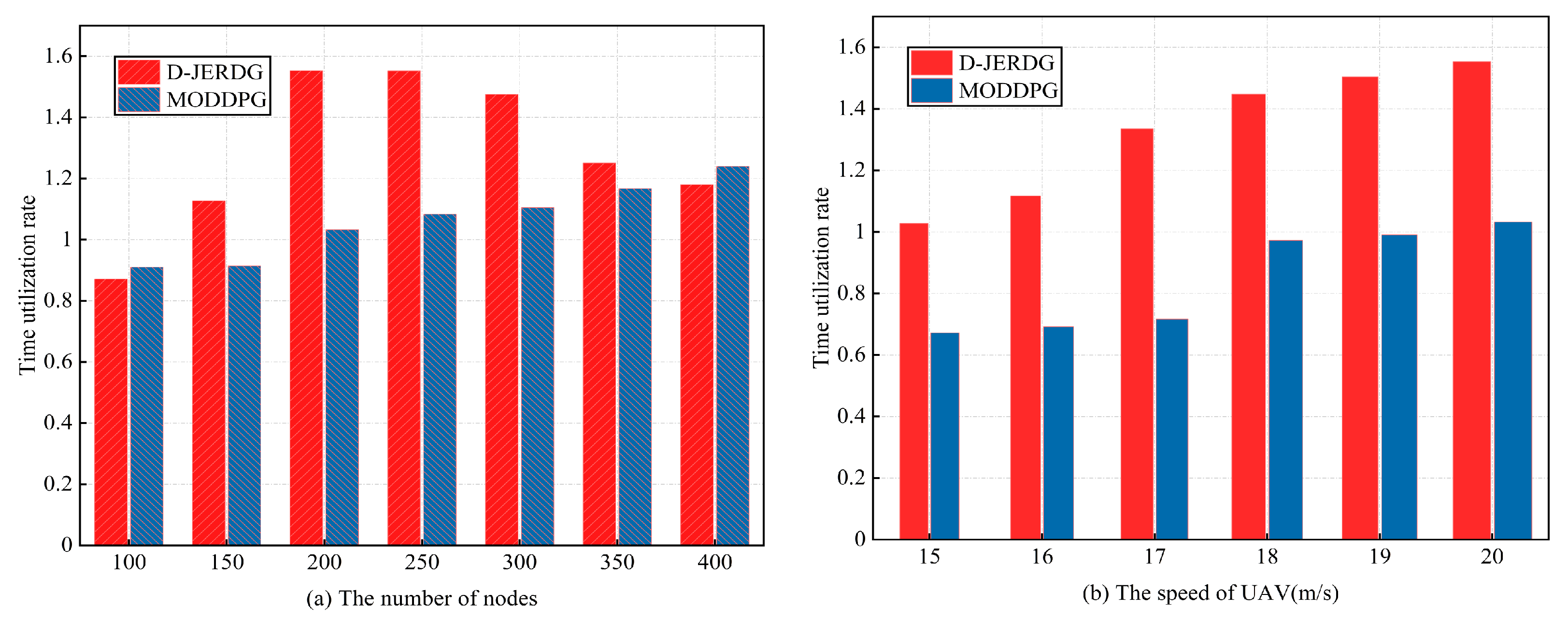
5.4.5. Time Utilization Rate
In this section, we compare the differences in time utilization rates between the D-JERDG and MODDPG algorithms. The experimental results are presented in
Figure 11. In
Figure 11a, we observe that the time utilization of D-JERDG initially increases and then decreases as the number of CH nodes varies. This trend aligns with the analysis discussed earlier. In general, D-JERDG exhibits a similar pattern to MODDPG, and after 300 nodes, their time utilization becomes comparable. When the number of nodes is 150 to 350, the average growth rate of D-JEGDG in terms of time utilization rates is about
. The reason behind this behavior lies in the D-JERDG method, which utilizes the SA algorithm to adjust the sequence of CH node visits, thereby reducing the UAV flight distance and time. Before reaching 300 nodes, with a smaller network size, the total flight time includes longer hover times. At 200 nodes, the time utilization reaches its peak, which aligns with the trend observed in the average UAV energy consumption curve. However, beyond 300 nodes, as the number of CH nodes increases, the flight time also increases. With the total flight time remaining constant, the time utilization decreases accordingly. In
Figure 11b, we examine the impact of UAV flight speed on time utilization under both algorithms. Notably, D-JERDG consistently achieves higher time utilization compared with MODDPG, maintaining the highest level throughout the different flight speeds. As the speed of UAV increases, the average growth rate of D-JEGDG in terms of time utilization rates is about
.
6. Conclusions
This study proposes a DRL-based method called D-JERDG for joint data collection and energy replenishment in UAV-WRSN. The main problems D-JERDG addresses are individual nodes’ low data collection efficiency and the imbalance in node energy consumption. D-JERDG optimizes the network to tackle these issues by considering node inefficiency, UAV flight energy consumption, and UAV throughput. The clustering algorithm based on K-means and an improved dynamic routing protocol is used to cluster the nodes in the network. CH nodes are selected based on the remaining energy and geographical locations of the nodes within the clusters, effectively adapting to the dynamic nature of node energy consumption. Furthermore, a simulated annealing algorithm is employed to determine the visiting sequence, and the DRL model MODDPG is introduced to control the UAV for node servicing. Through extensive simulation results, the evaluation metrics of node inefficiency, UAV throughput, and average flight energy consumption are used to assess the performance of D-JERDG. The results demonstrate that D-JERDG achieves joint optimization of multiple objectives. It outperforms the existing MODDPG approach by significantly reducing node inefficiency, saving flight costs, and improving data collection efficiency. Moreover, multiple research studies suggest that multiagent systems have significant advantages in accomplishing complex tasks. Therefore, Multi-UAV-WRSN is expected to be a primary research focus in the future.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}