
A Multi-Modal Egocentric Activity Recognition Approach towards Video Domain Generalization


Abstract
:1. Introduction
- We incorporate the audio modality in the process of egocentric recognition by using the spectrogram transformations of audio data and we demonstrate that this could significantly improve recognition performance;
- We propose a novel, target domain-flavored data augmentation process which aids in the domain generalization process.
2. Related Work
2.1. Supervised Activity Recognition
2.2. Domain Adaptation
- Domain adaptation through feature alignment: in this approach, the features of the source and target domains are aligned to reduce the distribution gap. This can be achieved through techniques such as (a) maximum mean discrepancy, as in, e.g., the work of Long et al. [41]; (b) correlation alignment, as in, e.g., the work of Sunet and Saenko [42]; and (c) adversarial training, as in, e.g., the work of Pei et al. [43]. The last technique is regarded as the prevalent method for domain adaptation through feature alignment.
- Instance re-weighting: this technique involves re-weighting training data to reduce the difference between the distributions of the source and target domains and may be achieved through approaches such as importance weighting and covariate shift. An example of the first approach is the work of Adel et al. [44] who used a covariate shift domain adaptation algorithm, considering that both source and target domain labeling functions are identical with a certain probability. Moreover, an example of the second approach is the work of Li et al. [45], where predictions of the training classifier are re-weighted based on their distance to the domain separator.
- Domain adaptation through data augmentation: in this approach synthetic data from the target domain are generated and added to the training data to improve model performance, e.g., as in the work of Sarwar and Murdock [46].
- Transfer learning: this approach involves the transfer of knowledge from a pre-trained model on a related task to the target domain and is typically countered with several strategies. For example, instead of training a model from scratch, transfer learning leverages the knowledge gained from a source task to improve performance on a target task [47].
2.3. Egocentric Activity Recognition
2.4. Multi-Modal Activity Recognition
3. Methodology
3.1. RGB Modality
3.2. Optical Flow Modality
3.3. Audio Modality
3.4. Sampling and Scaling
3.5. Data Augmentation
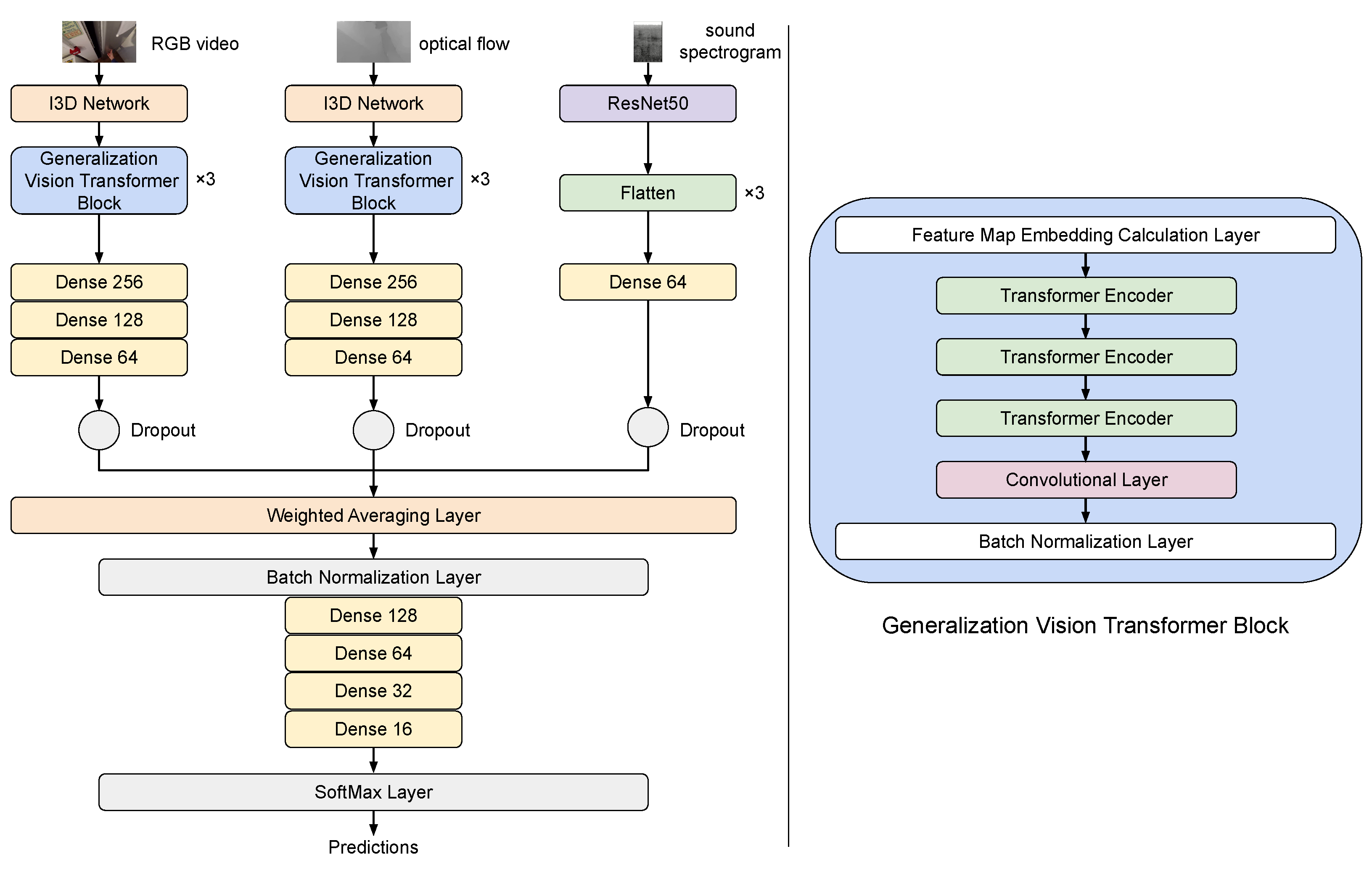
3.6. Machine Learning Model
3.6.1. Inflated 3D Convolutional Architecture
3.6.2. Vision Transformer (ViT)
3.6.3. ResNets for Spectrograms
3.6.4. Intermediate Fusion
3.7. Network Training
4. Experimental Results
4.1. Dataset
4.2. Experimental Protocol and Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| DFT | Discrete Fourier Transform |
| DL | Deep Learning |
| FPP | First Person Perspective |
| HAR | Human Activity Recognition |
| MDGAR | Multi-modal Domain Generalization model for Activity Recognition |
| ML | Machine Learning |
| ResNet | Residual Network |
| RGB | Red Green Blue |
| SAR | Supervised Activity Recognition |
| UDGAR | Unimodal Domain Generalization model for Activity Recognition |
| ViT | Vision Transformer |
References
- Liu, R.; Ramli, A.A.; Zhang, H.; Henricson, E.; Liu, X. An overview of human activity recognition using wearable sensors: Healthcare and artificial intelligence. In Proceedings of the International Conference on Internet of Things, Virtual, 10–14 December 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 1–14. [Google Scholar]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A review on human activity recognition using vision-based method. J. Health Eng. 2017, 2017, 1–31. [Google Scholar] [CrossRef] [PubMed]
- Koutrintzes, D.; Spyrou, E.; Mathe, E.; Mylonas, P. A multimodal fusion approach for human activity recognition. Int. J. Neural Syst. 2023, 33, 2350002. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, R.K.; Jalal, A.S.; Agrawal, S.C. Suspicious human activity recognition: A review. Artif. Intell. Rev. 2018, 50, 283–339. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. A depth video sensor-based life-logging human activity recognition system for elderly care in smart indoor environments. Sensors 2014, 14, 11735–11759. [Google Scholar] [CrossRef] [PubMed]
- Siddiqui, N.; Chan, R.H. A wearable hand gesture recognition device based on acoustic measurements at wrist. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Republic of Korea, 11–15 July 2017; pp. 4443–4446. [Google Scholar]
- Xie, L.; Wang, C.; Liu, A.X.; Sun, J.; Lu, S. Multi-touch in the air: Concurrent micromovement recognition using RF signals. IEEE/ACM Trans. Netw. 2017, 26, 231–244. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowl. Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Chen, L.; Nugent, C.D. Human Activity Recognition and Behaviour Analysis; Springer International Publishing: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Hussain, Z.; Sheng, M.; Zhang, W.E. Different approaches for human activity recognition: A survey. arXiv 2019, arXiv:1906.05074. [Google Scholar]
- Nunez-Marcos, A.; Azkune, G.; Arganda-Carreras, I. Egocentric vision-based action recognition: A survey. Neurocomputing 2022, 472, 175–197. [Google Scholar] [CrossRef]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 720–736. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Furnari, A.; Kazakos, E.; Ma, J.; Moltisanti, D.; Munro, J.; Perrett, T. Rescaling egocentric vision. arXiv 2020, arXiv:2006.13256. [Google Scholar]
- Grauman, K.; Westbury, A.; Byrne, E.; Chavis, Z.; Furnari, A.; Girdhar, R.; Hamburger, J.; Jiang, H.; Liu, M.; Liu, X.; et al. Ego4d: Around the world in 3000 hours of egocentric video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18995–19012. [Google Scholar]
- Dunnhofer, M.; Furnari, A.; Farinella, G.M.; Micheloni, C. Visual object tracking in first person vision. Int. J. Comput. Vis. 2023, 131, 259–283. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. CSUR 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. Pku-mmd: A large scale benchmark for continuous multi-modal human action understanding. arXiv 2017, arXiv:1703.07475. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A short note on the kinetics-700 human action dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar]
- Papadakis, A.; Mathe, E.; Spyrou, E.; Mylonas, P. A geometric approach for cross-view human action recognition using deep learning. In Proceedings of the 2019 11th International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 23–25 September 2019; pp. 258–263. [Google Scholar]
- Papadakis, A.; Mathe, E.; Vernikos, I.; Maniatis, A.; Spyrou, E.; Mylonas, P. Recognizing human actions using 3d skeletal information and CNNs. In Proceedings of the Engineering Applications of Neural Networks, 20th International Conference 2019, EANN 2019, Xersonisos, Greece, 24–26 May 2019; Proceedings 20. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 511–521. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Ji, X.; Zhao, Q.; Cheng, J.; Ma, C. Exploiting spatio-temporal representation for 3D human action recognition from depth map sequences. Knowl. Based Syst. 2021, 227, 107040. [Google Scholar] [CrossRef]
- Meng, H.; Pears, N.; Bailey, C. A human action recognition system for embedded computer vision application. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–6. [Google Scholar]
- Fan, L.; Wang, Z.; Wang, H. Human activity recognition model based on decision tree. In Proceedings of the 2013 International Conference on Advanced Cloud and Big Data, Nanjing, China, 13–15 December 2013; pp. 64–68. [Google Scholar]
- Zhou, Y.; Sun, X.; Zha, Z.J.; Zeng, W. Mict: Mixed 3d/2d convolutional tube for human action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 449–458. [Google Scholar]
- Pham, H.H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Exploiting deep residual networks for human action recognition from skeletal data. Comput. Vis. Image Underst. 2018, 170, 51–66. [Google Scholar] [CrossRef]
- Tu, Z.; Xie, W.; Qin, Q.; Poppe, R.; Veltkamp, R.C.; Li, B.; Yuan, J. Multi-stream CNN: Learning representations based on human-related regions for action recognition. Pattern Recognit. 2018, 79, 32–43. [Google Scholar] [CrossRef]
- Basly, H.; Ouarda, W.; Sayadi, F.E.; Ouni, B.; Alimi, A.M. CNN-SVM learning approach based human activity recognition. In Proceedings of the Image and Signal Processing: 9th International Conference, ICISP 2020, Marrakesh, Morocco, 4–6 June 2020; Proceedings 9. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 271–281. [Google Scholar]
- Shuvo, M.M.H.; Ahmed, N.; Nouduri, K.; Palaniappan, K. A hybrid approach for human activity recognition with support vector machine and 1D convolutional neural network. In Proceedings of the 2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2020; pp. 1–5. [Google Scholar]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial temporal transformer network for skeleton-based action recognition. In Proceedings of the Pattern Recognition, ICPR International Workshops and Challenges Part III, Virtual, 10–15 January 2021; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 694–701. [Google Scholar]
- Spyrou, E.; Mathe, E.; Pikramenos, G.; Kechagias, K.; Mylonas, P. Data augmentation vs. domain adaptation—A case study in human activity recognition. Technologies 2020, 8, 55. [Google Scholar] [CrossRef]
- Pikramenos, G.; Spyrou, E.; Perantonis, S.J. Extending Partial Domain Adaptation Algorithms to the Open-Set Setting. Appl. Sci. 2022, 12, 10052. [Google Scholar] [CrossRef]
- Redko, I.; Morvant, E.; Habrard, A.; Sebban, M.; Bennani, Y. Advances in Domain Adaptation Theory; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Goodman, S.; Greenspan, H.; Goldberger, J. Supervised Domain Adaptation by transferring both the parameter set and its gradient. Neurocomputing 2023, 560, 126828. [Google Scholar] [CrossRef]
- Liu, J.; Tian, Y.; Zhang, R.; Sun, Y.; Wang, C. A two-stage generative adversarial networks with semantic content constraints for adversarial example generation. IEEE Access 2020, 8, 205766–205777. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Yu, Y.C.; Lin, H.T. Semi-Supervised Domain Adaptation with Source Label Adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 24100–24109. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Unsupervised domain adaptation with residual transfer networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–10. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; Part III 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-adversarial domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Adel, T.; Wong, A. A probabilistic covariate shift assumption for domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. No. 1. [Google Scholar]
- Li, S.; Song, S.; Huang, G. Prediction reweighting for domain adaptation. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1682–1695. [Google Scholar] [CrossRef] [PubMed]
- Sarwar, S.M.; Murdock, V. Unsupervised domain adaptation for hate speech detection using a data augmentation approach. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 6–9 June 2022; Volume 16, pp. 852–862. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Munro, J.; Damen, D. Multi-modal domain adaptation for fine-grained action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 122–132. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Yang, L.; Huang, Y.; Sugano, Y.; Sato, Y. Interact before align: Leveraging cross-modal knowledge for domain adaptive action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022; pp. 14722–14732. [Google Scholar]
- Li, Y.; Wang, N.; Shi, J.; Hou, X.; Liu, J. Adaptive batch normalization for practical domain adaptation. Pattern Recognit. 2018, 80, 109–117. [Google Scholar] [CrossRef]
- Wei, P.; Kong, L.; Qu, X.; Ren, Y.; Xu, Z.; Jiang, J.; Yin, X. Unsupervised Video Domain Adaptation for Action Recognition: A Disentanglement Perspective. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems, New Orleans, LO, USA, 10–16 December 2023. [Google Scholar]
- Terreran, M.; Lazzaretto, M.; Ghidoni, S. Skeleton-based action and gesture recognition for human-robot collaboration. In Proceedings of the International Conference on Intelligent Autonomous Systems, Zagreb, Croatia, 3–16 June 2022; Springer Nature: Cham, Switzerland; pp. 29–45. [Google Scholar]
- Zhu, W.; Doshi, K.; Yi, J.; Sun, X.; Liu, Z.; Liu, L.; Xiang, H.; Wang, X.; Omar, M.; Saad, A. Multiscale Multimodal Transformer for Multimodal Action Recognition. 2022. Available online: https://openreview.net/forum?id=aqP3WFwMPbe (accessed on 12 February 2024).
- Ijaz, M.; Diaz, R.; Chen, C. Multimodal transformer for nursing activity recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022; pp. 2065–2074. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Kim, G.; Han, D.K.; Ko, H. Specmix: A mixed sample data augmentation method for training withtime-frequency domain features. arXiv 2021, arXiv:2108.03020. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Boulahia, S.Y.; Amamra, A.; Madi, M.R.; Daikh, S. Early, intermediate and late fusion strategies for robust deep learning-based multimodal action recognition. Mach. Vis. Appl. 2021, 32, 121. [Google Scholar] [CrossRef]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3723–3732. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | D1 | D2 | D3 |
|---|---|---|---|
| Kitchen | P08 | P01 | P22 |
| Training Action Segments | 1543 | 2495 | 3897 |
| Test Action Segments [48] | 435 | 750 | 974 |
| Test Action Segments (ours) | 412 | 713 | 990 |
| Difference (%) | −5.3 | −4.9 | +1.6 |
| Methodogy | Domain Adaptation Scenario | |||||
|---|---|---|---|---|---|---|
| D1→D2 | D2→D1 | D2→D3 | D1→D3 | D3→D1 | D3→D2 | |
| MM Source-only [48] | 42.0 | 42.5 | 46.5 | 41.2 | 44.3 | 56.3 |
| AdaBN [51] | 47.0 | 44.6 | 48.8 | 40.3 | 47.8 | 54.7 |
| MMD [49] | 46.6 | 43.1 | 48.5 | 39.2 | 48.3 | 55.2 |
| MCD [63] | 46.5 | 42.1 | 51.0 | 43.5 | 47.9 | 52.7 |
| MM-SADA [48] | 49.5 | 48.2 | 52.7 | 44.1 | 50.9 | 56.1 |
| TransVAE [52] | 50.5 | 50.3 | 58.6 | 50.3 | 48.0 | 58.0 |
| CIA [50] | 52.5 | 49.8 | 53.2 | 47.8 | 52.2 | 57.6 |
| UDGAR (RGB) | 54.6 | 76.7 | 69.6 | 60.1 | 88.9 | 48.4 |
| UDGAR (Optical Flow) | 64.2 | 66.7 | 69.9 | 59.0 | 81.7 | 80.1 |
| UDGAR (Audio) | 82.1 | 86.0 | 77.4 | 86.8 | 75.7 | 81.1 |
| MDGAR | 84.6 | 88.0 | 85.2 | 84.4 | 76.8 | 59.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadakis, A.; Spyrou, E. A Multi-Modal Egocentric Activity Recognition Approach towards Video Domain Generalization. Sensors 2024, 24, 2491. https://doi.org/10.3390/s24082491
Papadakis A, Spyrou E. A Multi-Modal Egocentric Activity Recognition Approach towards Video Domain Generalization. Sensors. 2024; 24(8):2491. https://doi.org/10.3390/s24082491
Chicago/Turabian StylePapadakis, Antonios, and Evaggelos Spyrou. 2024. "A Multi-Modal Egocentric Activity Recognition Approach towards Video Domain Generalization" Sensors 24, no. 8: 2491. https://doi.org/10.3390/s24082491
APA StylePapadakis, A., & Spyrou, E. (2024). A Multi-Modal Egocentric Activity Recognition Approach towards Video Domain Generalization. Sensors, 24(8), 2491. https://doi.org/10.3390/s24082491