
Adaptive Cruise Control Based on Safe Deep Reinforcement Learning


Abstract
:1. Introduction
2. Problem Definition and Methodological Framework
2.1. Problem Definition
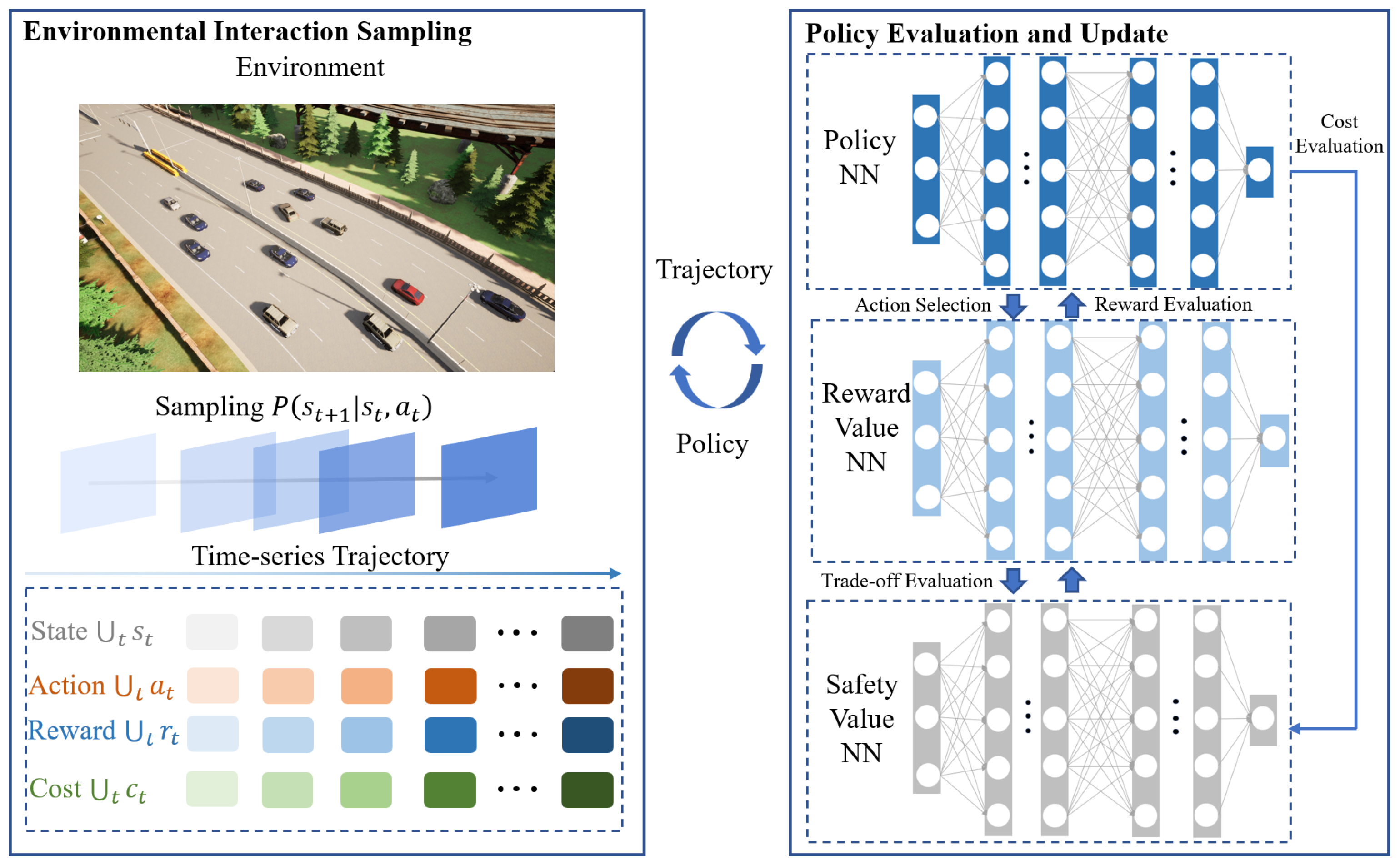
2.2. Methodological Framework
3. SFRL-ACC Algorithm
3.1. Representation of ACC Problem to a Safe DRL Formulation CMDP
3.1.1. Constrained Markov Decision Process
- is the state space, which is composed of the concatenation of local states observed by the agent and optionally, global non-redundant states;
- A represents the set of action space of the agent, where an action at the discrete time step t;
- represents the reward function that describes the instant reward from a state by taking an action to the next state ;
- represents the set of safe functions defined by the specific environment safety constraints (there are safe functions), maps the transition tuples to a safe value with thresholds ;
- represents the transition probability distribution from a state by taking an action to the next state at the discrete time step t;
- represents the initial state distribution.
3.1.2. Converting ACC to Safe DRL Model through CMDP
3.2. Evaluation and Updating of the Policy
3.2.1. Policy Neural Network Optimization
3.2.2. Reward and Cost Value Networks Optimization
| Algorithm 1 SFRL-ACC |
|
3.3. Algorithm Overview
4. Experiment
4.1. Experimental Setting
4.2. Analysis of Performance during Training Process
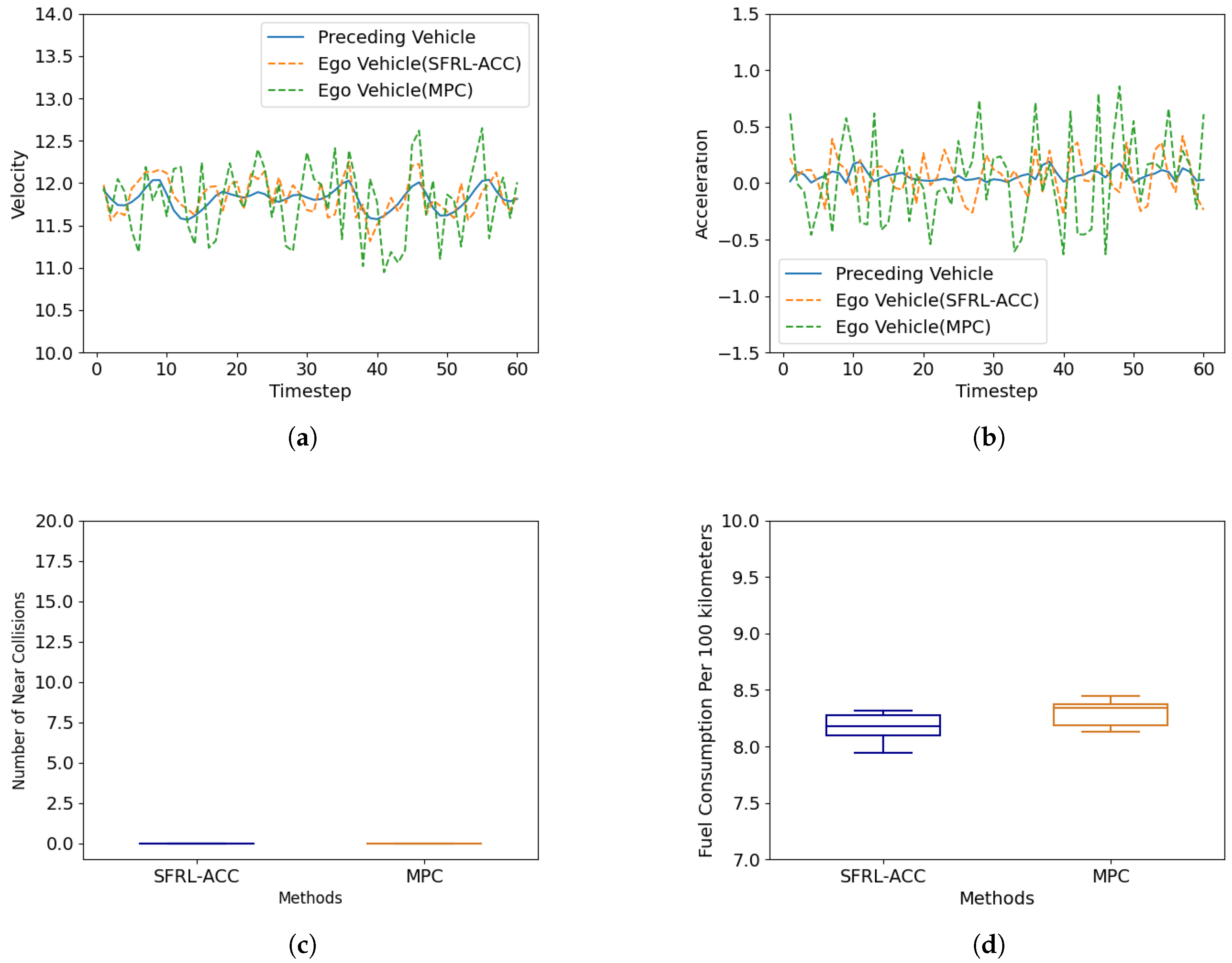
4.3. Performance Comparison Post-Policy Deployment
4.3.1. Constant Speed Follow Scenario
4.3.2. Preceding Vehicle Braking Scenario
4.3.3. Cut-In Scenario
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Althoff, M.; Maierhofer, S.; Pek, C. Provably-correct and comfortable adaptive cruise control. IEEE Trans. Intell. Veh. 2020, 6, 159–174. [Google Scholar] [CrossRef]
- Wang, C.; Gong, S.; Zhou, A.; Li, T.; Peeta, S. Cooperative adaptive cruise control for connected autonomous vehicles by factoring communication-related constraints. Transp. Res. Part C Emerg. Technol. 2020, 113, 124–145. [Google Scholar] [CrossRef]
- Rezaee, H.; Zhang, K.; Parisini, T.; Polycarpou, M.M. Cooperative Adaptive Cruise Control in the Presence of Communication and Radar Stochastic Data Loss. IEEE Trans. Intell. Transp. Syst. 2024. [Google Scholar] [CrossRef]
- Wu, D.; Qiao, B.; Du, C.; Zhu, Y.; Yan, F.; Liu, C.; Li, J. Multi-objective dynamic coordinated Adaptive Cruise Control for intelligent electric vehicle with sensors fusion. Mech. Syst. Signal Process. 2024, 209, 111125. [Google Scholar] [CrossRef]
- Lefeber, E.; Ploeg, J.; Nijmeijer, H. Cooperative adaptive cruise control of heterogeneous vehicle platoons. IFAC-PapersOnLine 2020, 53, 15217–15222. [Google Scholar] [CrossRef]
- Yang, F.; Li, H.; Lv, M.; Hu, J.; Zhou, Q.; Ghosh, B.K. Enhancing Safety in Nonlinear Systems: Design and Stability Analysis of Adaptive Cruise Control. arXiv 2024, arXiv:2401.11961. [Google Scholar] [CrossRef]
- Das, L.; Won, M. D-ACC: Dynamic adaptive cruise control for highways with on-ramps based on deep qlearning. arXiv 2020, arXiv:2006.01411. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Rout, M.K.; Sain, D.; Swain, S.K.; Mishra, S.K. PID controller design for cruise control system using genetic algorithm. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016. [Google Scholar]
- Chaturvedi, S.; Kumar, N. Design and implementation of an optimized PID controller for the adaptive cruise control system. IETE J. Res. 2021, 69, 7084–7091. [Google Scholar] [CrossRef]
- Bauer, K.L.; Gauterin, F. A Two-Layer Approach for Predictive Optimal Cruise Control; SAE Technical Paper; SAE 2016 World Congress and Exhibition; SAE International: Warrendale, PA, USA, 2016. [Google Scholar]
- Sakhdari, B.; Azad, N.L. Adaptive tube-based nonlinear MPC for economic autonomous cruise control of plug-in hybrid electric vehicles. IEEE Trans. Veh. Technol. 2018, 67, 11390–11401. [Google Scholar] [CrossRef]
- Lin, Y.; McPhee, J.; Azad, N.L. Comparison of deep reinforcement learning and model predictive control for adaptive cruise control. IEEE Trans. Intell. Veh. 2020, 6, 221–231. [Google Scholar] [CrossRef]
- Luo, L.H.; Liu, H.; Li, P.; Wang, H. Model predictive control for adaptive cruise control with multi-objectives: Comfort, fuel-economy, safety and car-following. J. Zhejiang Univ. Sci. A 2010, 11, 191–201. [Google Scholar] [CrossRef]
- Stanger, T.; del Re, L. A model predictive cooperative adaptive cruise control approach. In Proceedings of the 2013 American Control Conference, Washington, DC, USA, 17–19 June 2013. [Google Scholar]
- Moser, D.; Waschl, H.; Kirchsteiger, H.; Schmied, R.; Del Re, L. Cooperative adaptive cruise control applying stochastic linear model predictive control strategies. In Proceedings of the 2015 European Control Conference (ECC), Linz, Austria, 15–17 July 2015. [Google Scholar]
- Naus, G.J.L.; Ploeg, J.; Van de Molengraft, M.J.G.; Heemels, W.P.M.H.; Steinbuch, M. Design and implementation of parameterized adaptive cruise control: An explicit model predictive control approach. Control Eng. Pract. 2010, 18, 882–892. [Google Scholar] [CrossRef]
- Takahama, T.; Akasaka, D. Model predictive control approach to design practical adaptive cruise control for traffic jam. Int. J. Automot. Eng. 2018, 9, 99–104. [Google Scholar] [CrossRef]
- Munir, U.; Junzhi, Z. Weight changing model predictive controller for adaptive cruise control with multiple objectives. In Proceedings of the 2018 IEEE International Conference on Mechatronics, Robotics and Automation (ICMRA), Hefei, China, 18–21 May 2018. [Google Scholar]
- Nie, Z.; Farzaneh, H. Adaptive cruise control for eco-driving based on model predictive control algorithm. Appl. Sci. 2020, 10, 5271. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, Y.; Qin, Y.; Dong, M.; Gao, L.; Hashemi, E. A new adaptive cruise control considering crash avoidance for intelligent vehicle. IEEE Trans. Ind. Electron. 2023, 71, 688–696. [Google Scholar] [CrossRef]
- Li, G.; Görges, D. Ecological adaptive cruise control and energy management strategy for hybrid electric vehicles based on heuristic dynamic programming. IEEE Trans. Intell. Transp. Syst. 2018, 20, 3526–3535. [Google Scholar] [CrossRef]
- Bradford, E.; Imsl, L. Stochastic nonlinear model predictive control using Gaussian processes. In Proceedings of the 2018 European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018. [Google Scholar]
- Wang, Z.; Zhou, X.; Wang, J. Extremum-seeking-based adaptive model-free control and its application to automated vehicle path tracking. IEEE/ASME Trans. Mechatron. 2022, 27, 3874–3884. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Found. Trends® Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A brief survey of deep reinforcement learning. arXiv 2017, arXiv:1708.05866. [Google Scholar] [CrossRef]
- Wu, J.; Huang, Z.; Huang, C.; Hu, Z.; Hang, P.; Xing, Y.; Lv, C. Human-in-the-loop deep reinforcement learning with application to autonomous driving. arXiv 2021, arXiv:2104.07246. [Google Scholar]
- Li, G.; Li, S.; Li, S.; Qin, Y.; Cao, D.; Qu, X.; Cheng, B. Deep reinforcement learning enabled decision-making for autonomous driving at intersections. Automot. Innov. 2020, 3, 374–385. [Google Scholar] [CrossRef]
- Chib, P.S.; Singh, P. Recent advancements in end-to-end autonomous driving using deep learning: A survey. IEEE Trans. Intell. Veh. 2023, 9, 103–118. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. arXiv 2017, arXiv:1704.02532. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, B.; Tomizuka, M. Model-free deep reinforcement learning for urban autonomous driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Das, L.; Won, M. D-ACC: Dynamic Adaptive Cruise Control for Highways with Ramps Based on Deep Q-Learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Das, L.C.; Won, M. Saint-acc: Safety-aware intelligent adaptive cruise control for autonomous vehicles using deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Kakade, S.; Langford, J. Approximately optimal approximate reinforcement learning. In Proceedings of the Nineteenth International Conference on Machine Learning, Sydney, Australia, 8–12 July 2002. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6 July 2015. [Google Scholar]
- ISO 15622:2018; Adaptive Cruise Control Systems Performance Requirements and Test Procedures (Intelligent Transport Systems, USA). Available online: https://www.iso.org/standard/71515.html (accessed on 21 March 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| CARLA Simulator | - |
| Time step | 0.1 s |
| Road width and lane width | 14 m, 3.5 m |
| SFRL-ACC | - |
| Discount factor | 0.99 |
| Learning rate | 1 × → 0 (linearly) |
| Max KL divergence | 0.001 |
| Damping coefficient | 0.01 |
| Time steps | 500 |
| Epoch | 2000 |
| Cost limit | 1 |
| Hidden layer number | 2 |
| Hidden layer units | 128 |
| Policy std | 1 → 0 (exponentially) |
| Policy std decrease index | 1.5 × |
| Coefficient of std | 1 |
| Optimizer | Adam |
| TTC safety threshold | 4 s |
| MPC | - |
| Predictive horizon T | 5 |
| Velocity range | [0 m/s, 25 m/s] |
| Expect velocity | 16 m/s |
| Risk parameter | 0.005 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, R.; Wang, K.; Che, W.; Li, Y.; Fan, Y.; Gao, F. Adaptive Cruise Control Based on Safe Deep Reinforcement Learning. Sensors 2024, 24, 2657. https://doi.org/10.3390/s24082657
Zhao R, Wang K, Che W, Li Y, Fan Y, Gao F. Adaptive Cruise Control Based on Safe Deep Reinforcement Learning. Sensors. 2024; 24(8):2657. https://doi.org/10.3390/s24082657
Chicago/Turabian StyleZhao, Rui, Kui Wang, Wenbo Che, Yun Li, Yuze Fan, and Fei Gao. 2024. "Adaptive Cruise Control Based on Safe Deep Reinforcement Learning" Sensors 24, no. 8: 2657. https://doi.org/10.3390/s24082657
APA StyleZhao, R., Wang, K., Che, W., Li, Y., Fan, Y., & Gao, F. (2024). Adaptive Cruise Control Based on Safe Deep Reinforcement Learning. Sensors, 24(8), 2657. https://doi.org/10.3390/s24082657