1. Introduction
Explainable machine learning has garnered significant attention in recent years. It refers to the ability of a machine learning model to provide an easily understandable causal relationship that explains the process of model prediction, thereby enhancing human confidence and facilitating model debugging for downstream tasks [
1,
2].
Explainability in deep learning models can be categorized into two main types [
2]. The first category is intrinsic interpretability, which includes models with relatively simple structures like decision trees [
3], logistic regression [
4], and linear regression [
5]. These models have transparent internal logic structures that can be readily understood during the model design process. However, their accuracy is generally lower compared to mainstream deep learning models. The second category is post hoc explainability, which involves employing various techniques to extract learned information from trained black box models, thereby enhancing their explainability. This type of explainability is particularly relevant for models with complex structures, such as convolutional neural networks (CNNs) [
6,
7,
8,
9,
10] and vision transformers (ViTs) [
11,
12,
13,
14,
15,
16,
17]. These models typically consist of billions of parameters, making it difficult to discern the direct causal relationships between the outputs and the internal structure of the model.
In the field of computer vision, a large amount of work has focused on increasing the explainability of CNNs by post hoc visualization of discriminative regions associated with targets in input images.
The emergence of vision transformers (ViTs) has revolutionized computer vision. Transformer-based methods such as Swin-transformer [
15] and PVT [
14] have surpassed traditional techniques and have achieved state-of-the-art (SOTA) performance in various computer vision tasks, including image classification, object detection, and semantic segmentation. Moreover, transformers have played a critical role in advancing multi-modal models such as CLIP [
18], ALBEF [
19], BLIP [
20], and GLIP [
21]. Additionally, transformers have been instrumental in the development of large language models (LLMs) [
22], which have gained widespread popularity. However, as the application of transformers expands, the need for explainability methods becomes crucial. These methods enhance users’ confidence in model results and facilitate the debugging process, ultimately leading to improved performance in downstream tasks. Exploring explainability methods for transformers is a promising avenue to refine and optimize the performance of these models.
Despite these advancements, there are few contributions exploring the explainability of the ViT series of models. Most existing approaches only consider the direct use of the raw-attention map corresponding to the class token in the multi-head self-attention (MHSA) module to directly generate explainability maps in ViT [
23,
24,
25]. However, these methods often adopt a class-agnostic approach, and the generated explainability maps tend to emphasize salient features while containing substantial noise. To address the noise problem associated with explainability methods based on the self-attention map, Abnar et al. proposed a method called attention rollout [
26]. Although this approach improves the noise problem of raw attention to some extent, it often struggles to distinguish between true foreground and background regions.
Another approach was proposed by Chefer et al., it utilizes the deep Taylor decomposition principle to assign relevance and improve the problem mentioned above [
27]. By combining the information from back-propagation gradients, this method achieves class-specific explainability. However, the presence of activation functions in the back-propagation process can lead to gradient vanishing and other issues, resulting in sparse and noisy explainability feature maps as outputs.
In our research, we propose a post hoc visualization explainability method called relationship weighted out and cut (R-Cut) with the objective of generating dense, low-noise, and class-specific explainability images for visual domain transformers and their derivative models. R-Cut consists of a two-stage extraction method, as illustrated in
Figure 1. In the first stage, we propose a module called “Relationship Weighted Out (R-Out)” to extract the class-specific semantic features from the intermediate vectors. In the second stage, we propose a feature decomposition technique called “Cut” to decompose the class-specific semantic features into fine-grained foreground and background components.
To validate the effectiveness of our method, we conducted qualitative and quantitative experiments on the widely used ImageNet1K dataset [
28] and compared the results with those of other SOTA methods. We also conducted experiments on the LRN dataset [
29] designed for automated driving hazard alerts, which we created to test the explainability of our method in the presence of complex backgrounds. Furthermore, we performed ablation experiments to verify the effectiveness of the different modules proposed in our approach. Moreover, we conducted comparative experiments on various hyperparameters to validate their effectiveness. These comprehensive experiments aimed to provide evidence supporting the superiority of our method compared to existing approaches in terms of performance on standard benchmarks and its ability to handle complex scenarios.
This paper makes three main contributions:
We propose a dense, low-noise, class-specific post hoc visualization explainability method for transformer-based models and their derivative models.
We conducted various explainability tests on the largest image classification dataset in the world, demonstrating the superiority of our approach.
We conducted extensive explainability experiments to validate the effectiveness of the proposed method in the context of autonomous driving scenarios with complex backgrounds. This contribution highlights the practical application of the method in real-world scenarios and demonstrates its ability to provide meaningful explanations even in challenging and intricate environments.
3. Methods
This section provides an overview of the vision transformer and then introduces our proposed R-Cut method.
3.1. Vision Transformer (ViT)
The model is a popular approach for image classification tasks that uses a transformer-based architecture. Given an input image with resolution . The network first splits into several non-overlapping patches. If the size of each patch is , the total number of patches will be . Each patch is then flattened and linearly embedded into a token vector , where D is the dimension of each token vector.
To enable the network to learn global features, a randomly initialized class token is added to the tokens. Finally, the position embeddings are added to each of the tokens to form the input of the transformer block. If there are L cascaded transformer blocks, the input to each transformer block would be , where . In the vision transformer () architecture, each transformer block follows a specific arrangement of components. These components include layer normalization, an MHSA, a skip connection, and a multilayer perceptron layer (MLP). The input and output of each block consists of discrete patch tokens; however, each attention head only processes subspace tokens ; if the number of heads in the MHSA is H, the dimension of should be and .
The MHSA of each layer
is calculated as follows:
where
,
, and
are linear transformation layers in the
l-th block.
is the self-attention map of the input tokens from the
h-th head in the
l-th layer block.
is the output of the head. The outputs
of all heads are concatenated and fed into an MLP block.
From the last transformer block, the output class token is used to obtain the category probability vector ; if there are C categories, .
The vector
is generated as follows:
where MLP denotes the classification head implemented by the MLP block. The corresponding class can be selected by taking the maximum value in the generated vector
.
3.2. Relationship Weighted Out and Cut
The method consists of two main stages, as depicted in
Figure 2. In the first stage, called “Relationship Weighted Out”, the objective is to extract class-aware semantic information about the output results from the discrete intermediate tokens. The second stage, comprising fine-grained feature decomposition and named “Cut”, involves utilizing the class-specific intermediate vectors obtained in the first stage to construct a novel graph. Subsequently, graph cut operations are performed on the graph to derive foreground information that corresponds to the target. By leveraging these operations, the method generates a visual explainability map specific to the class based on the foreground information. The primary computational process is represented as follows:
Generate alternative activation maps from discrete tokens ;
Generate perturbation maps from alternative activation maps and input image ;
Calculate the class-aware weighting scores based on perturbation maps ;
Extract class-aware patch tokens based on the discrete tokens and class-aware weighting scores ;
Construct a class-aware weighted graph based on the class-aware patch tokens ;
Get the class-aware solution eigenvector of the class-aware weighted graph ;
Generate the explainability visualization map by partitioning the class-aware solution eigenvector .
3.2.1. Relationship Weighted Out
In this stage, we extract the class-aware semantic information related to the output results from the discrete patch tokens. Since directly extracting class-aware semantic information from the discrete tokens is challenging, we propose a perturbation-map-based approach to obtain the class-aware weight information. This approach consists of two main parts: generating alternative activation maps and calculating the class-aware weighting scores to extract class-aware patch tokens .
Generate alternative activation maps
: As discussed in
Section 3.1,
utilizes discrete tokens to convey information. The intermediate discrete tokens involved in the forward transmission process carry semantic information of the corresponding category as the network propagates category information during forward propagation. However, within each transformer block, there are multiple intermediate tokens. To address the interference caused by the skip connection, we select the output of the normalization layer after the skip connection in the last block to extract semantic information. We firstly generate the patch tokens
by removing the last layer’s class token
from the output of the last layer’s normalization
. Then, the alternative activation maps
will be generated from patch tokens
as follows:
where
denotes a deserialization operation that can regroup the discrete patch tokens into a matrix map format,
represents bi-linear interpolation for up-sampling with a scale factor of
p, and
.
Generate perturbation maps
: In this method, we consider
as
D heat maps and perturb the original input image
through those heat maps to obtain perturbation maps
. The formula is shown as follows:
where ⊙ denotes element-wise multiplication.
Calculate the class-aware weighting scores
: To compute the weight scores
for each perturbation map
, we input both the perturbation map matrix
and the original image
into the pre-trained
model. Then, we use the similarity between the output vectors to compute the weight scores
for each perturbation map
. A higher similarity between the output vectors indicates a stronger contribution of the corresponding perturbation map to the target class, which is calculated as follows:
where
is a row vector of size
D,
D is the number of perturbation maps,
denotes the output vector of the
model, and
C represents the length of the output vector.
Extracte class-aware patch tokens
: Since the perturbation maps
are generated based on the original patch tokens
, the weight of each dimension of
regarding the original output result is equivalent to the weight of each dimension of the patch tokens
regarding the original output result. Therefore, we can extract
using the following formula:
3.2.2. Fine-Grained Feature Decomposition
In this section, we discuss how to finely partition the foreground and background information related to the category from the discrete tokens
obtained from
Section 3.2.1. In our previous research [
29], we experimented with a simple method of summing all the dimensions of
and reshaping the result to obtain the explainability feature map. The result shows that even when using such a simple method, we can also get a good result. However, this straightforward method does not consider the spatial position relationship of the discrete patch tokens, and it may not effectively address the issue of local discontinuities in the generated explainability map. To overcome these limitations and achieve more precise foreground–background partitioning, we propose a new method based on the graph cut technique discussed in
Appendix B.
Firstly, we generate a class-aware weighted graph using the class-aware patch tokens . This graph considers both the direct relationship between nodes and the positional embedding relationship between the patch tokens. Next, we perform graph cut operations on this weighted graph to decompose it and obtain the corresponding class-specific eigenvector . By leveraging the class-specific eigenvector , we can identify the foreground vector associated with the target class.
Construct a class-aware weighted graph
: We generate the corresponding graph based on the class-aware patch tokens
. Specifically, we select the
S class-aware patch token vectors (
) in
as the
S nodes in the graph, resulting in
. Next, we define the edge
between two tokens
and
as the cosine similarity between them, incorporating both semantic and spatial information. By computing these similarities, we can obtain
. The formula for calculating the edge weights is as follows:
where
is a settable hyperparameter representing a constraint on the edges; we consider two nodes to be related only if the similarity between them exceeds
.
Get the eigenvector
: To obtain the eigenvector
, we apply the normalized cut (Ncut) method described in
Appendix B to partition the class-aware weighted graph
. This involves computing the generalized eigensystem
of
and extracting the second-smallest eigenvector
.
Appendix B provides a proof that the eigenvector
is the Ncut of the class-aware solution of
, which is the class-aware vector we need corresponding to the target class.
Generate the explainability visualization map by partitioning the class-specific foreground and background information: To achieve this, we determine the splitting point by taking the mean value of the continuous eigenvector . Then, we define the foreground set as and the background set as .
To eliminate the interference brought by the background information, we set all nodes in the background set to 0. The class-specific vector is obtained by keeping the information of the foreground set unchanged.
Finally, we can obtain our class-specific explainability visualization map
as follows:
where
represents the weight of the weighted-add, and ∗ represents multiplication.
5. Discussion
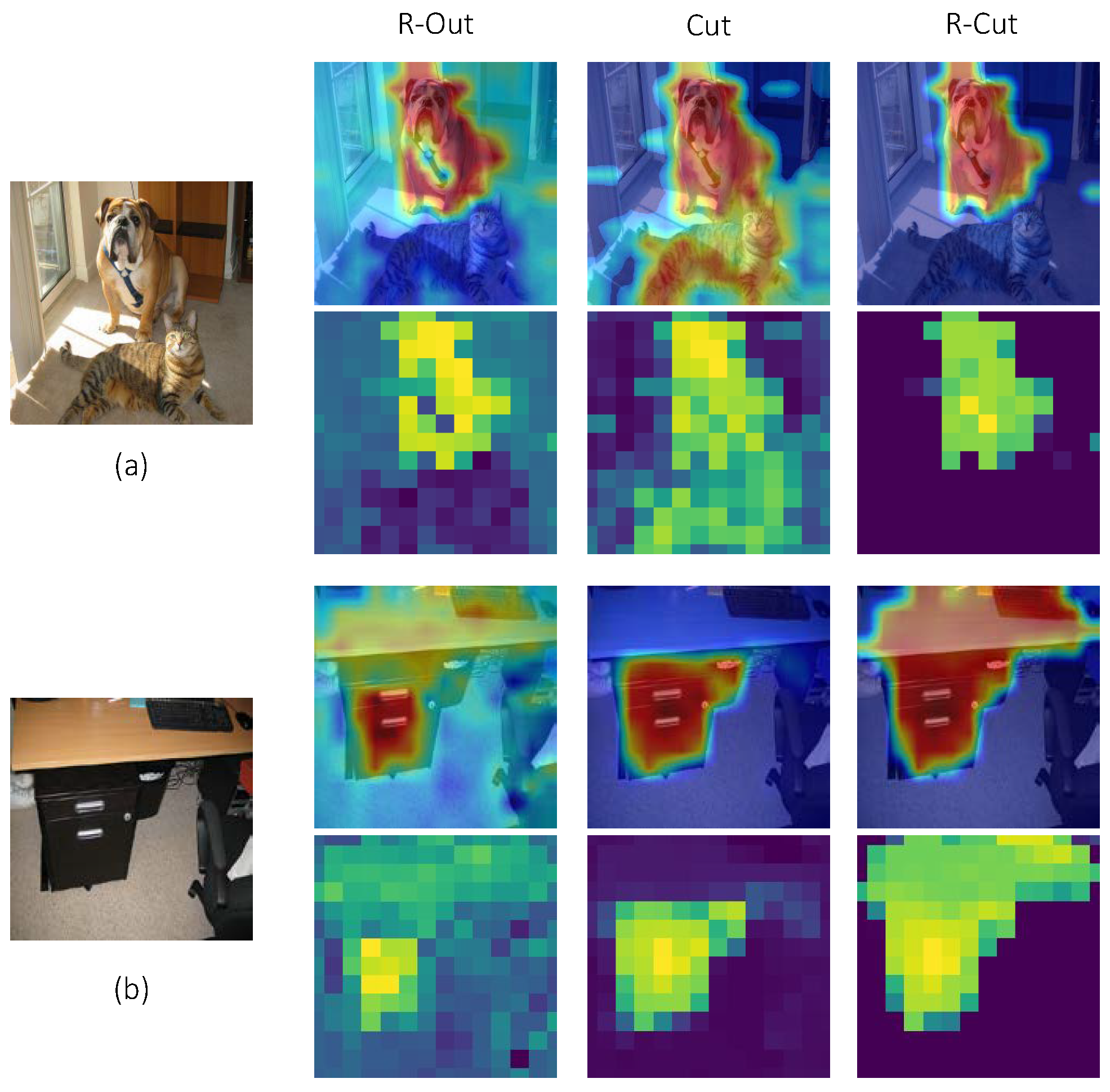
Based on multiple previous experiments, it is evident that our method stands out compared to others. Not only does it generate class-specific explainability maps tailored to multi-object categories, but it also yields more refined results. The heatmaps produced are clearer and more continuous and do not have the occurrence of solely detecting discriminative regions in fine-grained images. Clearly, our approach provides effective and rational explainability for the model. While our algorithm demonstrates remarkable explainability results on both the ImageNet and LRN datasets, our study also reveals certain limitations. Primarily, our method necessitates substantial computational overhead, which is compounded by its intricate procedural steps. As a consequence, each explainability iteration demands a significant time investment. Hence, our forthcoming endeavors are focused on optimizing the algorithm’s speed to alleviate these concerns. Furthermore, we recognize that our current explainability framework overlooks applications within the multimodal domain. As our next trajectory, we aim to delve deeper into the realm of multimodal explainability with the aim of more nuanced explorations and implementations in this domain.
6. Conclusions
This paper introduces a novel post hoc visualization explainability method for transformer-based image classification tasks. Our method addresses the crucial need for trust and understanding in classification results. Through our proposed “Relationship weighted out” module, we can obtain class-specific information from intermediate layers, enhancing the class-aware explainability of the discrete tokens. Additionally, our “Cut” module enables fine-grained feature decomposition. By combining the two modules, we can generate dense class-specific visual explainability maps.
We extensively evaluated our explainability method on the ImageNet dataset, conducting both qualitative and quantitative analyses. Furthermore, we tested the explainability of our method in complex backgrounds by performing numerous experiments on the LRN dataset for automatic driving danger alerts.
The results of both sets of explainability experiments demonstrate significant improvement of our method compared to previous SOTA approaches. Additionally, through ablation explainability experiments, we provide further validation of the effectiveness of the different modules proposed in our method.
Overall, our method not only enhances trust in transformer-based image classification but also contributes to the comprehension of the model, benefiting downstream tasks. In the future, we plan to extend our work to perform explainability experiments on multi-modal tasks.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}