A Novel Vehicle Classification Using Embedded Strain Gauge Sensors

Abstract
:
1. Introduction
2. Instrumental Pavement Test Bench and Strain-Vehicle Database
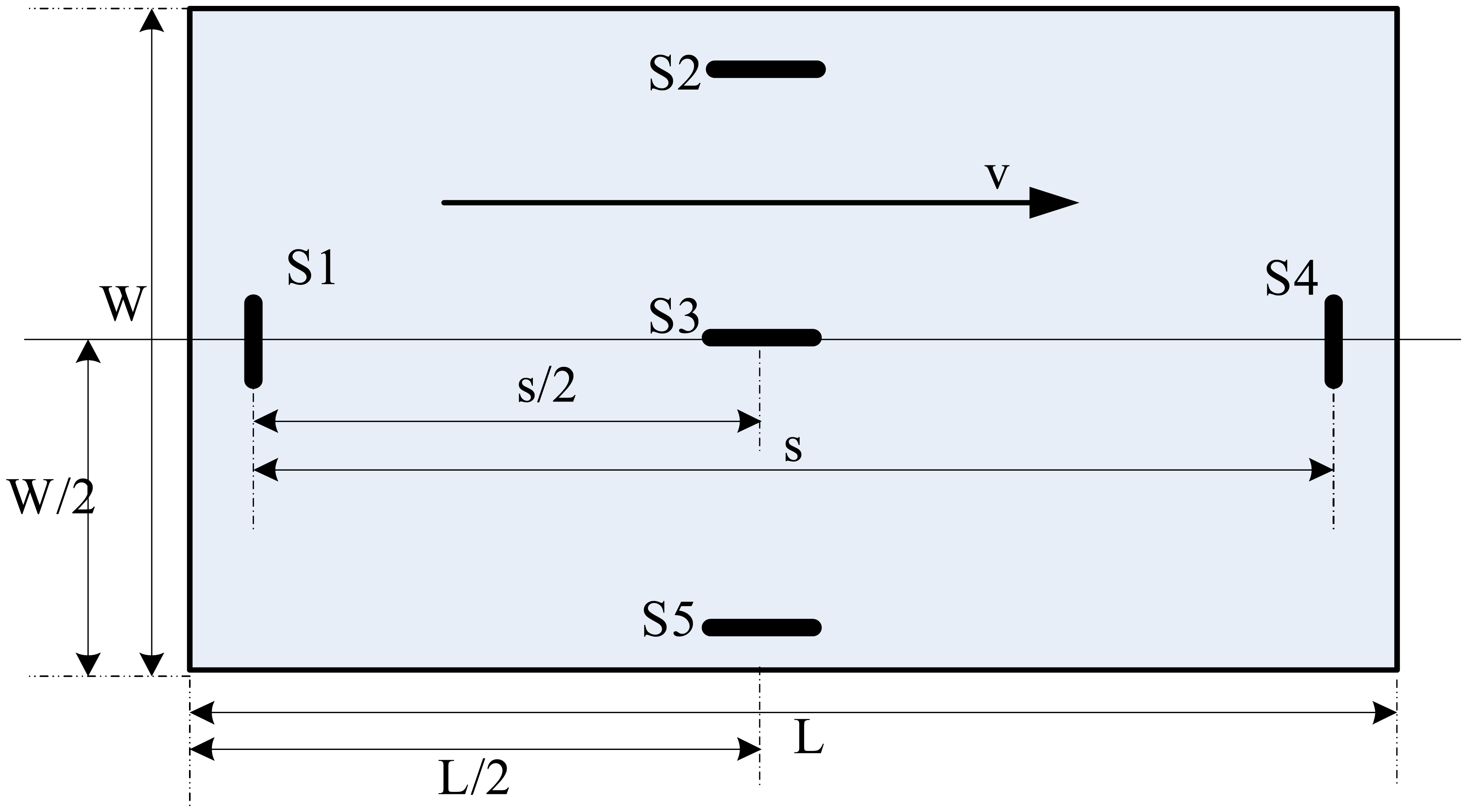
2.1 Description of the testing bench
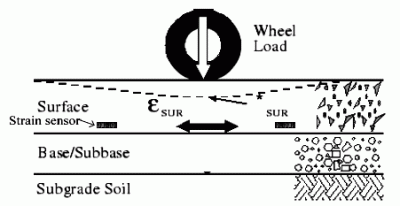
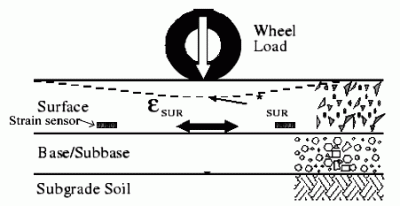
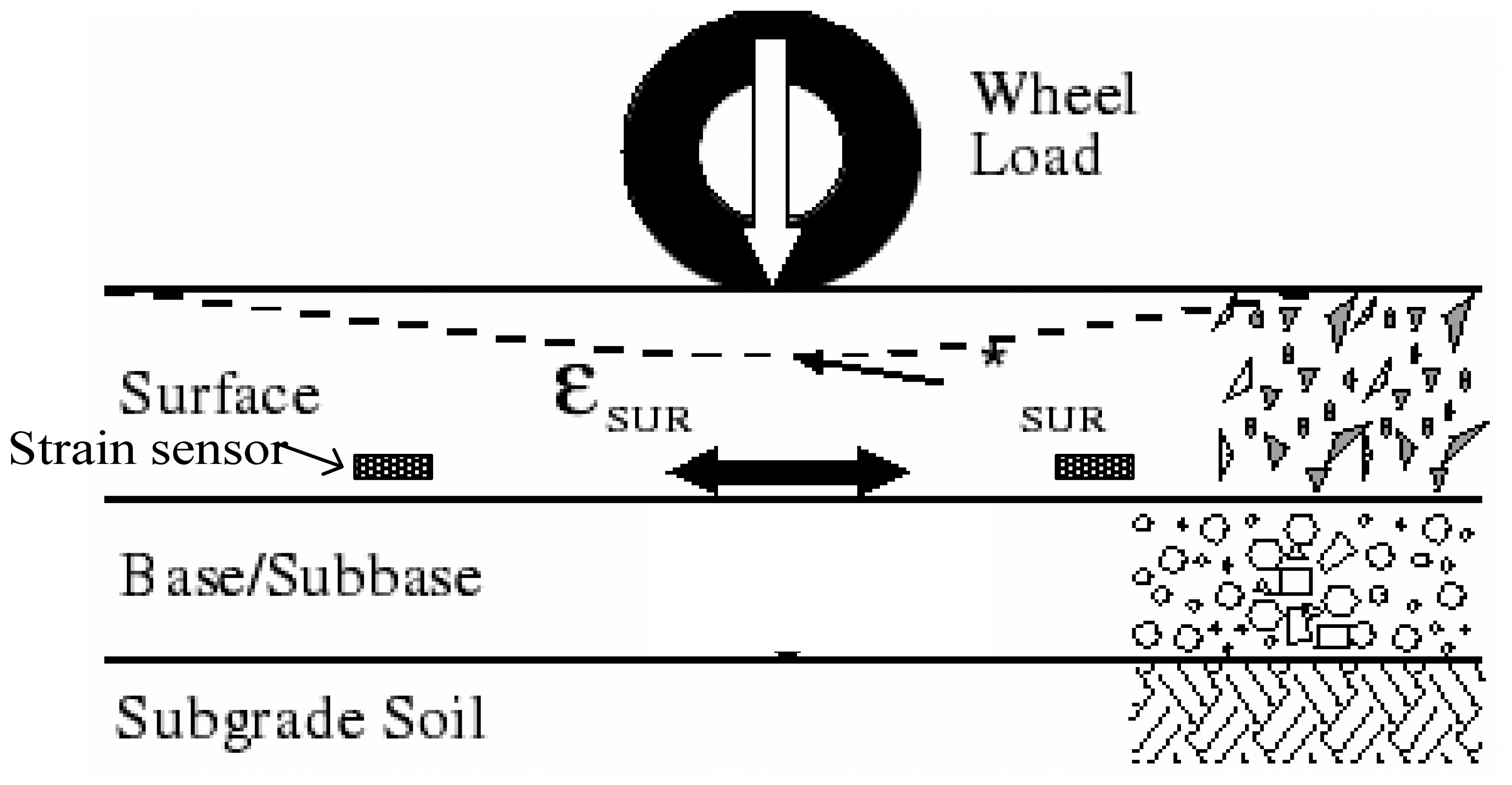
2.1 Pavement strain measurement
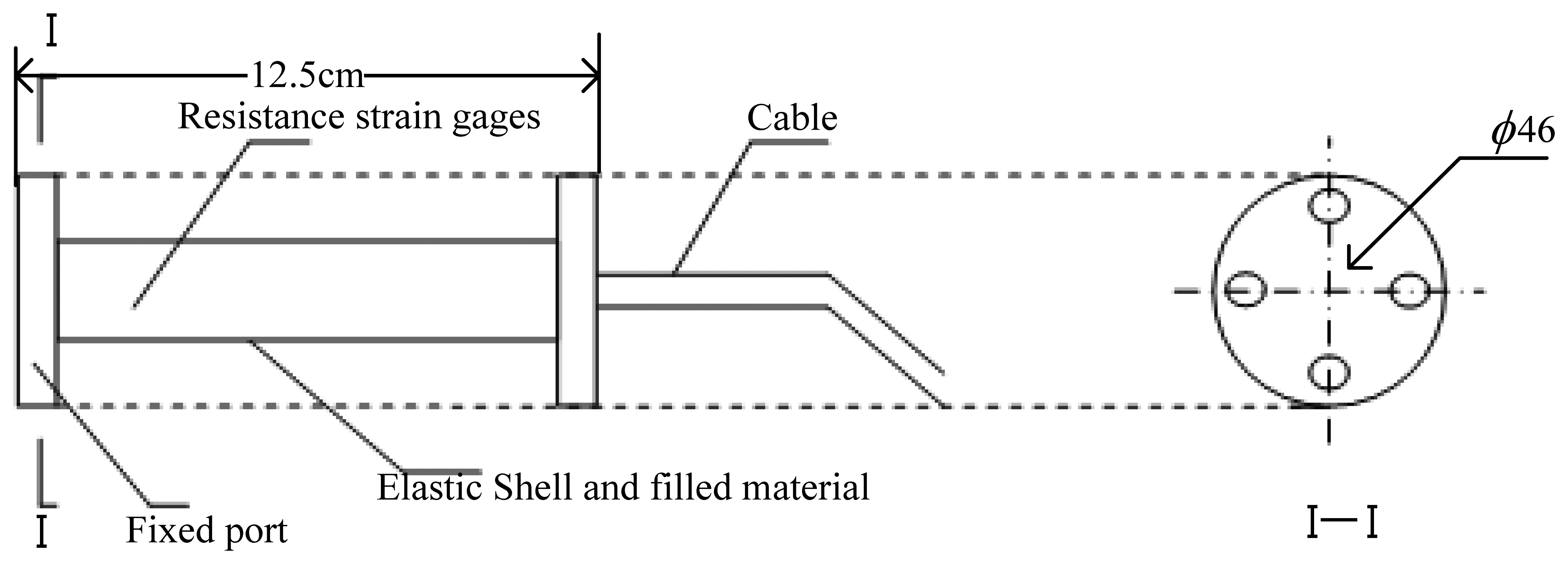
2.2 Embedded Strain Gauge Sensor
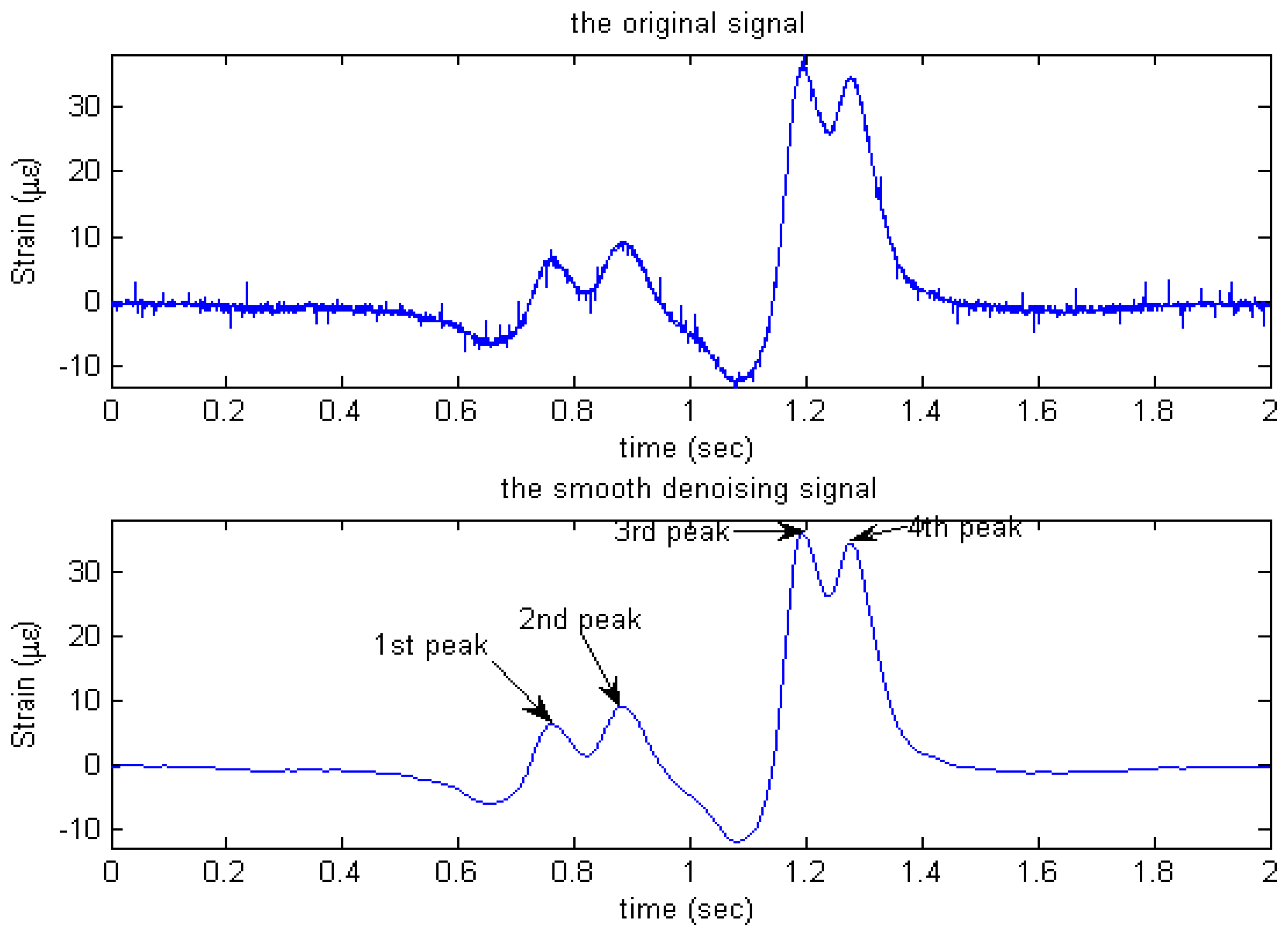
2.3 Characteristics of Traffic-Induced Pavement Strain Response
3. Preliminary Experiments
3.1 Description of the experiments
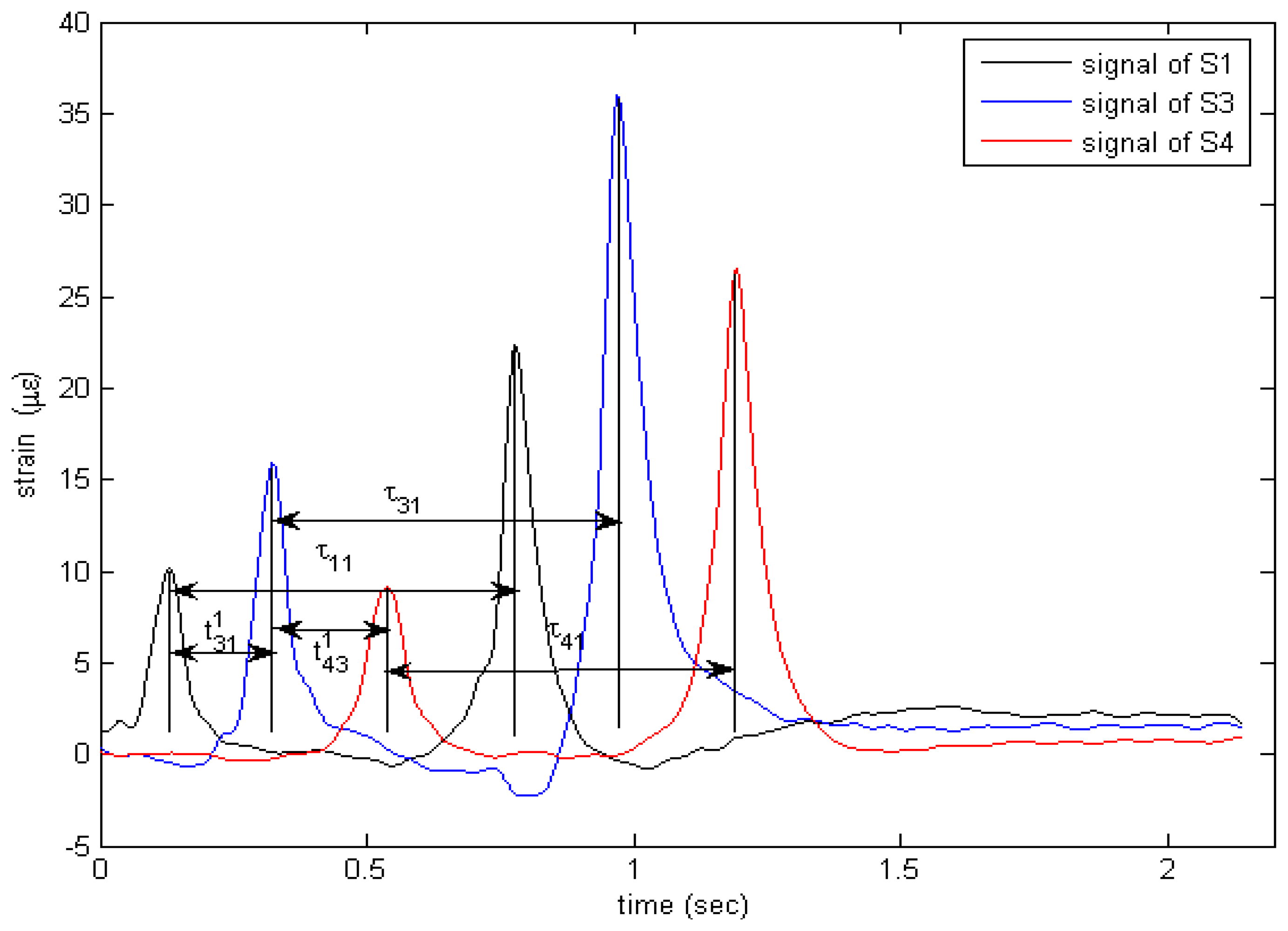
3.2 The calculation of vehicle parameters
3.3 Variables that affect a vehicle classification
3.4. Two-axle truck experimental results and discussion
4. Description of SVM fusion classification
4.2. Support vector classification
4.2.1. Principle of Support vector Classification
4.2.2. Support vector classification training
4.2.3 Multi-class Support Vector Machines
4.2.4 Kernel selection
4.2.5 Cross-validation
4.2.6 Model training process
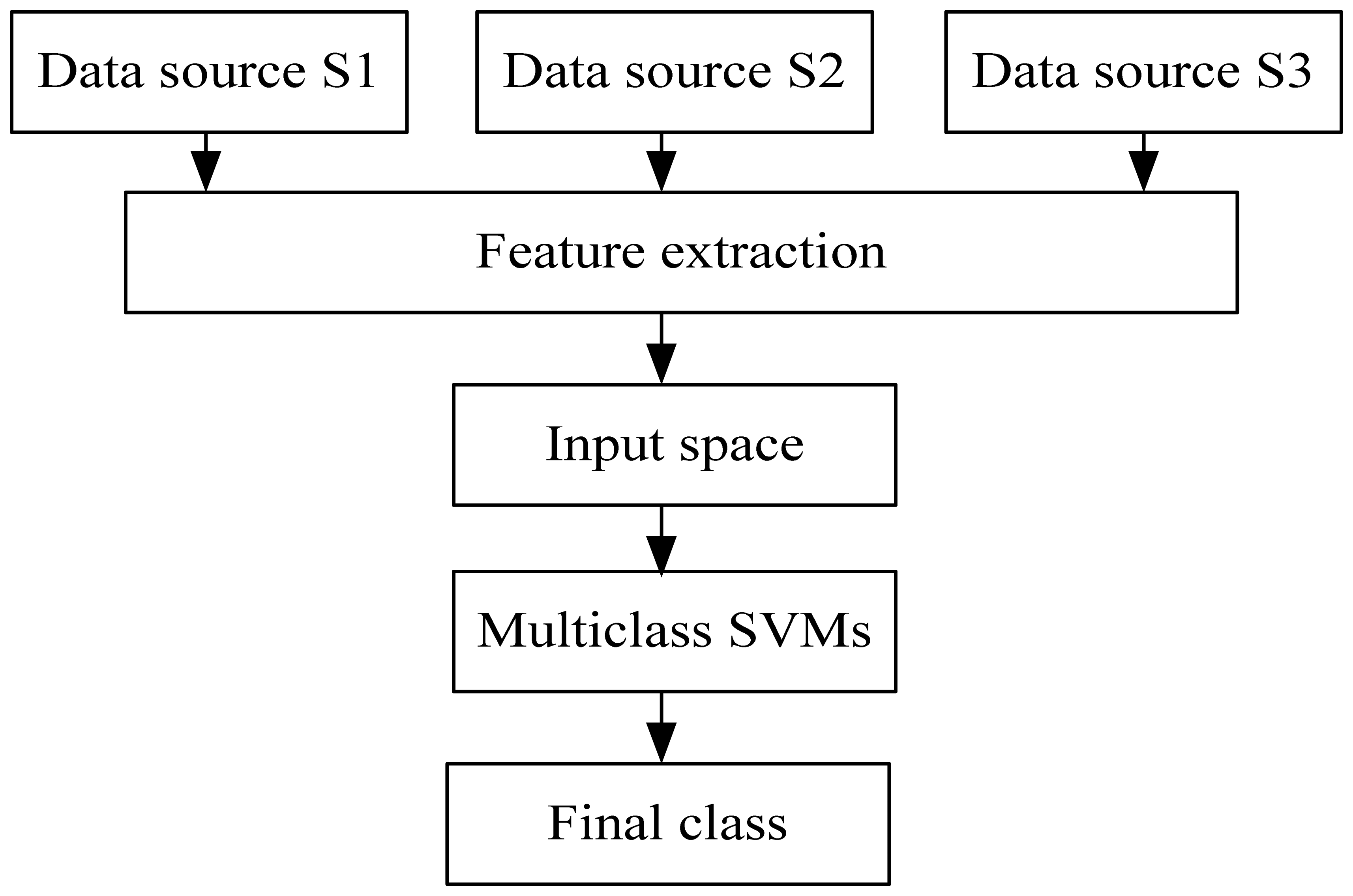
4.2.7 Data Fusion Classification Strategies
5. Experimental Results
6. Conclusions
Acknowledgments
References and Notes
- Bajaj, P.; Sharma, P.; Deshmukh, A. Vehicle Classification for Single Loop Detector with Neural Genetic Controller: A Design Approach. Intelligent Transportation Systems Conference, Seattle, Washington, USA, Sept. 30-Oct. 3, 2007; pp. 721–725.
- Gajda, J.; oka, R.; Stencel, M.; Wajda, A.; Zeglen, T. A vehicle classification based on inductive loop detectors. Instrumentation and Measurement Technology Conference, Budapest, Hungary, May 21-23, 2001; pp. 460–464.
- Ki, Y.K.; Baik, D.K. Vehicle-Classification Algorithm for Single-Loop Detectors Using Neural Networks. Vehicular Technology Conference, Melbourne, Australia, May 7-10, 2006; pp. 1704–711.
- Lin, P.Q.; Xu, J.M. Adaptive Vehicle Classification Based on Information Gain and Multi-branch BP Neural Networks. Intelligent Control and Automation, Dalian, China, June 21-23, 2006; pp. 8687–8691.
- Hussain, K.F.; Moussa, G.S. Automatic vehicle classification system using range sensor. ITCC'05 2005, 2, 107–112. [Google Scholar]
- Ha, D.M.; Lee, J.-M.; Kim, Y.-D. Neural-edge-based vehicle detection and traffic parameter extraction. Imag. Vis. Comp. 2004, 22, 899–907. [Google Scholar]
- Stefano Messelodi, S.; Modena, C.M.; Cattoni, G. Vision-based bicycle/motorcycle classification. Patt. Rec. Lett. 2007, 28, 1719–1726. [Google Scholar]
- Fernández-Caballero, A.; Gómez, F.J.; López-López, J. Road-traffic monitoring by knowledge-driven static and dynamic image analysis. Expert Syst. Appl. 2008, 35, 701–719. [Google Scholar]
- Klausner, A.; Tengg, A.; Rinner, B. Vehicle Classification on Multi-Sensor Smart Cameras Using Feature-and Decision-Fusion. ICDSC '07 2007, 67–74. [Google Scholar]
- Gupte, S.; Masoud, O.; Papanikolopoulos, P. Vision-based vehicle classification. ITS 2000, 46–51. [Google Scholar]
- Goyal, A.; Verma, B. A Neural Network based Approach for the Vehicle Classification. Computational Intelligence in Image and Signal Processing 2007, 226–231. [Google Scholar]
- Junghans, M.; Jentschel, H.-J. Qualification of traffic data by Bayesian network data fusion. Inf. Fusion 2007, 1–7. [Google Scholar]
- Sroka, R. Data fusion methods based on fuzzy measures in vehicle classification process. Instrumentation and Measurement Technology Conference, Como, Italy, May 18-20, 2004; pp. 2234–2239.
- Gunn, S.R.; Brown, M.; Bossley, K.M. Network performance assessment for Neuro-fuzzy data modeling. Intell. Data Anal. 1997, 1208, 313–323. [Google Scholar]
- Castro, L.N.; Iyoda, E.M.; Zuben, F.V.; Gudwin, R. Feedforward Neural Network Initialization: an evolutionary approach. SBRN, Belo Hoizonte, Brazil, Dec 9-11, 1998; pp. 43–48.
- Zhang, W.B.; Wang, Q.; Ma, S.L.; Li, X.K. Field experimental study on measurement and analysis strain on the rigid pavement slab subjected to moving vehicle loads. The First International Conference of Transportation Engineering, Chengdu, China, Jul 22-24, 2007; pp. 2741–2746.
- Zhang, W.B.; Wang, Q.; Ma, S.L.; Li, X.K. A novel multisensor system for moving vehicle classification. J. TianJin University 2008, 41, 194–198. [Google Scholar]
- Brailvosky, V.L.; Barzilay, O.; Shahave, R. On global, local and mixed neighborhood kennels for support vector machines. Patt. Rec. Lett. 1999, 20, 1183–1190. [Google Scholar]
- Madevska-Bogdanova, A.; Nikolik, D.; Curfs, L. Probabilistic SVM output for pattern recognition using analytical geometry. Neurocomputing 2004, 62, 293–303. [Google Scholar]
- Paysan, P. Stereovision based vehicle classification using support vector machines. Thesis, Massachusetts Institute of Technology, Cambridge University, Cambridge, Massachusetts, 2004. [Google Scholar]
- Schölkopf, B.; Burges, D.J.C.; Somla, A.J. Advances in Kernel Methods; The Massachusetts Institute of Technology Press: Cambridge, Massachusetts, 1999. [Google Scholar]
- Rifkin, R.; Klautau, A. In Defense of One-Vs-All Classification. J. Mach. Learn. Res. 2004, 5, 101–141. [Google Scholar]
- Guermeur, Y.; Elisseeff, A.; Zelus, D. A comparative study of multi-class support vector machines in the unifying framework of large margin classifiers. Appl. Stochastic Model. Bus. Ind. 2005, 21, 199–214. [Google Scholar]
- Bredensteiner, E. J.; Bennett, K. P. Multicategory classification by support vector machines. Comput. Optimiz. Appl. 1999, 53–79. [Google Scholar]
- Friedman, J. Another approach to polychotomous classification; Technical report. Department of Statistics, Stanford University, 1996. Available at http://www-stat.stanford.edu/reports/friedman/poly.ps.z.
- The SVM-KM toolbox. http://asi.insa-rouen.fr/enseignants/arakotom/toolbox/index.html.
- Hsu, C.; Chang, C.; Lin, C. A practical guide to support vector classification. Available at http://www.csie.ntu.tw/∼cjlin/libsvm/index.html (10/14/2005).
- Sun, C.; Ritchie, S.G.; Oh, S. Inductive classifying artificial network for vehicle type categorization. Comput.-Aided Civ. Inf. Eng. 2003, 161–172. [Google Scholar]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar]
- Schölkopf, B.; Smola, A. Learning With Kernels.; MIT Press: Cambridge, MA, 2002. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle type | Notation | Number of axles | Distribution of axles1 | Vehicle types | FHWA vehicle categories |
|---|---|---|---|---|---|
| Small vehicles | C1 | 2 | 1F+1R | Passenger car, Minivan, van, SUV, pickup truck | Passenger car, other 2-axle 4-tire vehicles |
| Medium trucks | C2 | 2 | 1F+1R | Medium single-unit 2-axle truck | Other 2-axle 4-tire vehicles |
| Buses/Large trucks | C3 | 2 | 1F+1R | Buses, large single-unit 2-axle trucks | Bus, single-unit 2-axle, 6-tire or more truck |
| 3-axle trucks | C4 | 3 | 1F+2R | Single-unit 3-axle trucks | single-unit 2-axle 6-tire or more trucks |
| Combination trucks | C5 | 3-6 | 1F+1M+1R 1F+2M+1R 1F+1M+2R 1F+2M+2R 1F+2M+3R | Semi-trailer, truck, trucks with trailer | combination trucks |
| Number | τ11(sec) | τ31(sec) | τ41(sec) | v1(m/s) | v2(m/s) | v(m/s) | WB(m) | Actual WB (m) | WB Error |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.54 | 0.52 | 0.53 | 12.24 | 12.44 | 12.34 | 6.58 | 6.67 | -1.3% |
| 2 | 0.42 | 0.42 | 0.42 | 15.27 | 15.19 | 15.23 | 6.45 | 6.67 | -3.2% |
| 3 | 0.45 | 0.45 | 0.45 | 14.01 | 14.21 | 14.11 | 6.39 | 6.67 | -4.1% |
| 4 | 0.51 | 0.52 | 0.52 | 13.34 | 13.14 | 13.24 | 6.82 | 6.67 | 0.7% |
| 5 | 0.43 | 0.43 | 0.43 | 15.11 | 14.91 | 15.01 | 6.49 | 6.67 | -2.6% |
| 6 | 0.59 | 0.59 | 0.59 | 11.28 | 11.34 | 11.31 | 6.72 | 6.67 | -0.7% |
| 7 | 0.51 | 0.51 | 0.51 | 12.79 | 12.96 | 12.85 | 6.59 | 6.67 | -1.1% |
| 8 | 0.54 | 0.54 | 0.54 | 12.87 | 12.67 | 12.77 | 6.88 | 6.67 | 1.7% |
| 9 | 0.61 | 0.61 | 0.61 | 10.75 | 10.95 | 10.85 | 6.61 | 6.67 | -0.8% |
| 10 | 0.52 | 0.52 | 0.52 | 12.75 | 12.95 | 12.85 | 6.69 | 6.67 | 0.3% |
| Vehicle type | Total | Training set | Validation set | Test set |
|---|---|---|---|---|
| C1 | 72 | 36 | 18 | 18 |
| C2 | 68 | 34 | 17 | 17 |
| C3 | 174 | 88 | 42 | 42 |
| C4 | 84 | 42 | 21 | 21 |
| C5 | 204 | 102 | 51 | 51 |
| Multiclass SVMs | Single sensor data source | S.I | S.II | ||
|---|---|---|---|---|---|
| D1 | D2 | D3 | |||
| One-Against-All (%) | 89.5 | 92.3 | 90.9 | 94.6 | 95.5 |
| One-Against-One (%) | 91.4 | 91.8 | 91.2 | 94.4 | 96.4 |
© 2008 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Zhang, W.; Wang, Q.; Suo, C. A Novel Vehicle Classification Using Embedded Strain Gauge Sensors. Sensors 2008, 8, 6952-6971. https://doi.org/10.3390/s8116952
Zhang W, Wang Q, Suo C. A Novel Vehicle Classification Using Embedded Strain Gauge Sensors. Sensors. 2008; 8(11):6952-6971. https://doi.org/10.3390/s8116952
Chicago/Turabian StyleZhang, Wenbin, Qi Wang, and Chunguang Suo. 2008. "A Novel Vehicle Classification Using Embedded Strain Gauge Sensors" Sensors 8, no. 11: 6952-6971. https://doi.org/10.3390/s8116952
APA StyleZhang, W., Wang, Q., & Suo, C. (2008). A Novel Vehicle Classification Using Embedded Strain Gauge Sensors. Sensors, 8(11), 6952-6971. https://doi.org/10.3390/s8116952