1. Introduction
With the capability of sensing, computing and communication embedded on the sensor node, the wireless sensor network (WSN) is a promising technology to probe and collect environmental information. Without the necessity of expensive wiring cost for constructing the sensor network, the WSN could deploy sensor nodes at any location more efficiently [
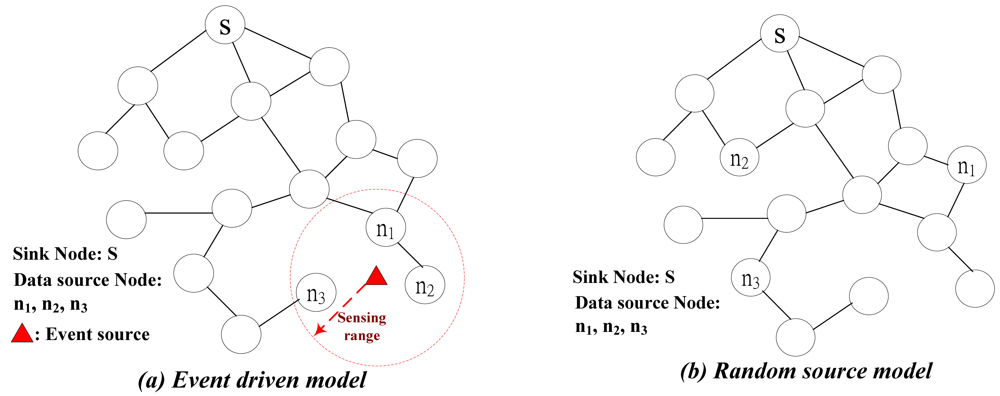
1]. A representative WSN is shown in
Figure 1. Sensor nodes are usually scattered in a
sensor field. When any event occurs, such as surging irradiation or temperature declining below certain threshold, sensor nodes within specific
sensing range (data source nodes) detect this event and collect data which would be transmitted to the sink node for taking further processing.
The application scenario described above is called
event-driven that sensors are assigned to detect a particular event, which is shown in
Figure 1(a). There are two other different applications of wireless sensor networks, which are namely
periodic and
query-based. These two applications could be classified as
random-source, which is shown in
Figure 1(b). Periodic scenario sensors probe environmental information periodically and report their measurements back to the sink node. All sensors in this kind of networks are necessitated to be synchronized such that all sensors sense information and report it simultaneously. Query-based scenario is applied to user-oriented applications. User can query information from certain area of sensors to require measurements that he is interested in. As can be seen in
Figure 1(b), the data source nodes in random source model are not clustered as in event driven model.
Power efficient communication in the WSN is an interesting and blooming research area [
2]. It is almost impossible to replace the battery in the sensor node due to the limited energy power in the sensor node. In traditional wireless network, the data transmission is unicasting (one to one) or multicasting (one to many). In the WSN, multiples data source nodes sense the data and send them back to only one sink node. Hence, the data communication in the WSN is a kind of
reverse multicasting (
many to one), also known as
data aggregation routing. This makes power efficient communication in the WSN different from traditional wireless network.
For data aggregation routing, raw data from multiple children sensor nodes are collected and processed before transmission. Data aggregation can minimize the number of transmission by eliminating redundant data from different source nodes [
3-
5].
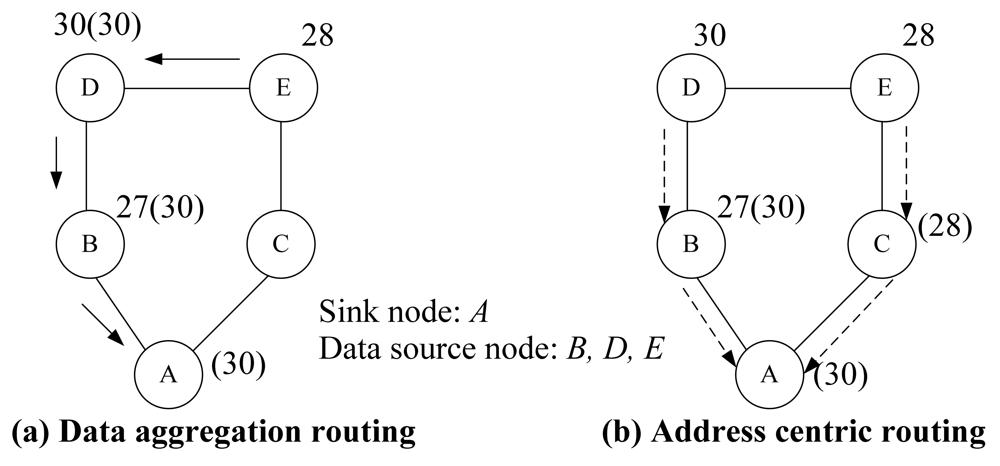
Figure 2 gives an example of data aggregation routing and address centric routing where the maximum temperature is reported to a sink node. Label
x(y) at each node represents the local temperature measurement is
x while the aggregated (maximum) value so far is
y. For example, at node 27(30), the maximum temperature up to now is MAX (27, 30) = 30. Assume the transmission cost on each link is equal to 1.0. In traditional address centric routing shown in
Figure 2(b), each Origin-Destination (OD) pair follows the shortest path. Then the total cost for these three OD pairs is 4.0. However, with the capability of data aggregation at each sensor node, a more power efficient transmission is shown in
Figure 2(a) via data aggregation routing where the total cost is 3.0.
Although data aggregation in the WSN could reduce the number of transmissions to save transmission cost, it could introduce additional MAC layer retransmission energy loss. Based on the CSMA/CA protocol, data transmission from multiple sensor nodes to the same sensor node for data aggregation will incur
collision. When there is collision, retransmission is required to ensure that the data is successfully received at the aggregation node and this will incur additional energy consumption. Basically, the more flows are aggregated at the sensor node, the higher probability that the senders will incur data retransmission. In
Figure 3(a), a node
n5 (with three children nodes) will suffer severe collisions which results in more retransmission times as compared to a node
n5 (with two children nodes) in
Figure 3(b). Besides extra energy consumption, retransmission also incurs additional latency, which is unacceptable in delay sensitive applications. The extra energy consumption and additional latency from retransmission will jeopardize the advantage from data aggregation.
By assigning different
channels to the sensor nodes that are within each other's interference range, the retransmission problem caused by collision could be circumvented. If there is sufficient number of channels, then we could assign a different channel to every sensor node on the aggregation tree such that there is no extra energy loss from retransmission. In the meantime, the latency could also be minimized. However, the number of channels is a limited and valuable resource in wireless networks. For instance, in IEEE 802.11b, there are only three non-overlapping channels [
6]. Hence, the question is how to assign the limited channels to the sensor nodes on the aggregation tree such that the total transmission power could be minimized.
Besides limited number of available non-overlapping channels,
number of radios on each sensor node is also a limited resource. If two children sensor nodes use two different channels transmit data back to the same sensor node, then this sensor node will need two radios to receive data simultaneously. Otherwise, it will incur larger latency for a single radio sensor node to switch different channel to receive from its children nodes. Hence, from the
latency point of view, for any sensor node that is on the data aggregation tree, the number of radios equipped on this node must be greater than or equal to the number of children nodes. In
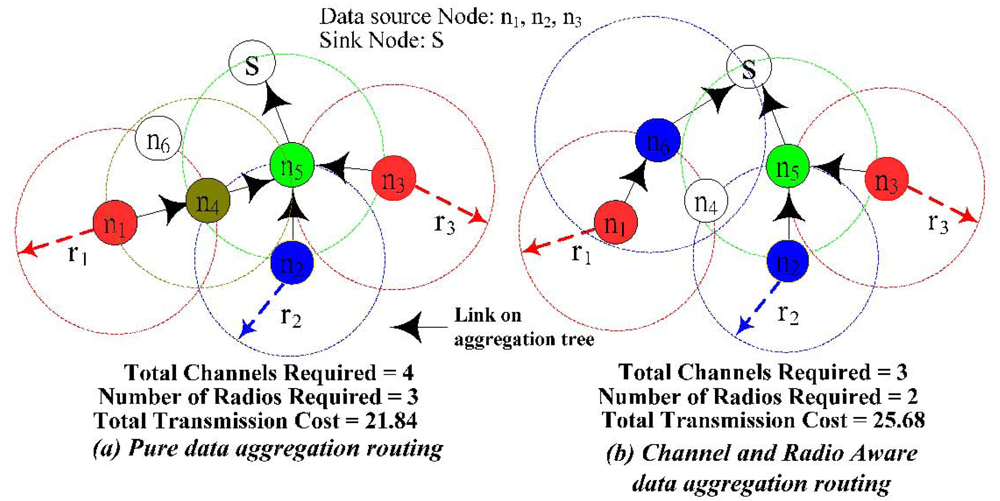
Figure 3, I illustrate an example where the sensor nodes are randomly placed in a 15 × 15 area. In this example, the transmission cost is equal to the square of the Euclidean distance of the transmission radius. The sensor nodes with the same color are assigned with the same channel (e.g.,
n1 and
n3). To prevent collision, any two sensor nodes that are within each other's transmission range could not assign the same channel (e.g.,
n2 and
n5). In addition, even though
n3 and
n4 are not within each other's transmission range,
n3 still could not reuse
n4's channel because of
n5. This is referred to as the hidden node problem. In this case, we say
n3 and
n4 are within each other's interference range. It is important to note that interference range is larger than the transmission range because of the hidden node problem. If every sensor node has the same transmission radius, then interference range is equal to the twice of transmission range in order to capture the co-channel interference from hidden nodes. In
Figure 3(a), when the number of channels and radio is unlimited, the minimum total transmission cost is 21.84. The total number of channels required is 4 and the number of radios required for a node
n5 is 3. If the total number of channels is limited to 3 or the number of radios on each node is limited to 2, then
Figure 3(a) is not a feasible solution. In
Figure 3(b), it shows the data aggregation tree for channel and radio aware data aggregation routing when the total number of channels is limited to be 3 and the number of radios on each sensor node is limited to 2. The transmission cost is 25.68, which is slightly larger than
Figure 3(a).
To perform Channel and Radio Constrained Data Aggregation Routing (CRDAR) in the WSN is even more challenging than pure data aggregation routing in the WSN. The channel assignment in wireless network could be modeled as a graph coloring problem in graph theory where adjacent nodes could not be assigned with the same color. This graph coloring problem is proven to be a NP-hard problem [
7]. CRDAR that contains the channel assignment problem is also an NP-hard problem. In this paper, for the first time, I first model the CRDAR problem as a mixed integer linear programming (MILP) problem. Then I relax some of the constraints and derive a set of independent subproblems. By optimally solving each independent subproblem and adjusting the Lagrangean multipliers at each iteration by the subgradient method, we get the tightest lower bound of the CRDAR problem. By utilizing the solution to the Lagrangean dual problem and the information from the Lagrangean multipliers, a getting primal heuristic algorithm (LGR) is devised to identify the channel and radio constrained minimum transmission cost data aggregation tree.
Note that this integrated channel assignment and routing problem is also an important issue in multi-radio wireless networks. Hence, the proposed optimization-based algorithm could also be applied to general wireless networks. The reason that I specifically focus on the WSN is because the nature of “many-to-one” communication from multiple data source nodes to one sink in the WSN is different from “one-to-many” communication in the wireless networks. This many-to-one communication will increase the probability of co-channel interference so as to make the integrated channel assignment and routing problem in the multi-radio WSN more challenging than the traditional wireless network.
The remainder of this paper is organized as follows. In Section 2, existing literature on data aggregation routing and channel assignment problem in wireless networks is surveyed. In Section 3, I formulate the CRDAR problem as the MILP mathematical problem. In Section 4, Lagrangean relaxation scheme is applied to relax some constraints and algorithms are proposed to solve the Lagrangean dual problem optimally. In Section 5, the novel optimization-based heuristics are devised to get the primal feasible solution. In Section 6, the numerical results and performance comparisons are demonstrated. Finally, concluding remarks are summarized in Section 7.
2. Related Works
In wireless network, if the transmission radius of a node is
r, then the power consumption is measured as
rα +
c, where
α is a signal attenuation constant (usually between 2 to 4) and
c is a positive constant that represents signal processing [
3]. In [
8], they study the tradeoff between power consumption transmission radius and coverage of the transmission node. For long transmission radius, more sensor nodes could be covered so that the total number of transmission could be reduced. However, long transmission radius incurs significant power consumption, especially for large
α, that would sacrifice the gain from reduced total number of transmission.
Pure data aggregation routing problem in the WSN has been studied by several works. In [
8], they propose centralized heuristic based on Prim's shortest path algorithm to construct a data aggregation tree. However, as shown in [
9], the data aggregation tree constructed by shortest path algorithm (shortest path tree, SPT) does not facilitate the data aggregation advantage. In [
5], three interesting suboptimal aggregation heuristics, Shortest Paths Tree (SPT), Center at Nearest Source (CNS), and Greedy Incremental Tree (GIT), are proposed. It is shown that GIT could get the best results. The idea of GIT scheme is initially the only member in the tree is the sink node. Each data source find the shortest hop path to this tree and the data source with the minimum hop along with the intermediate nodes on this path are included in this tree. This process is repeated until all source nodes are included in the tree.
In [
3,
9], they propose a rigorous MILP formulation for data aggregation routing problem and propose solution approaches based on Lagrangean relaxation. Optimization-based heuristic are proposed to solve the pure data aggregation routing problem. From the computational experiments, their optimization-based algorithm is superior to the SPT, CNS and GIT [
5] in both random-source model and event-driven model. In [
4], they consider the MAC aware data aggregation routing in the WSN. They capture the energy consumption tradeoffs between the data aggregation and retransmission in the CSMA/CA MAC protocol by proposing an interesting optimization-based heuristics. It is shown that proposed algorithms could construct more energy efficient data aggregation tree with considering MAC layer retransmission mechanism than existing data aggregation algorithms.
In [
11], the channel assignment problem is modeled as a graph coloring problem and proposes an optimization-based heuristics to tackle this issue. However, the hidden node problem is not addressed in [
11]. Joint channel assignment and routing in multi-hop wireless networks has been studied in [
12,
13]. They address the interference problem in wireless network by jointly channel assignment and routing algorithm in order to achieve maximum throughput/system capacity. However, power efficient communication is not addressed in [
12,
13]. In addition, they addressed the unicasting routing problem which is not applicable to data aggregation routing problem in the WSN.
In [
14], they study the tradeoff between data aggregation and latency in the WSN. Data aggregation tree is constructed by using the earliest-first, randomized, nearest-first and weighted-randomized to identify the parent node to relay the data from the data source node back to the sink node. Basically, by assigning different time slot (i.e., channel) to every sensor node on data aggregation tree that has the same parent node, there will be no collision but introducing large latency. Hence, there is a tradeoff between data aggregation and latency. In [
15], they consider the latency issue in constructing a minimum energy data aggregation tree. A data aggregation tree is a balanced binary tree where initially the sink node finds the nearest two sensor nodes as its children, and each children node identifies another two nearest nodes as its children node. This process is repeated until all data source nodes are included in this balanced data aggregation tree. After the data aggregation tree is determined, channel assignment is performed to minimize latency and transmission power. This two-phase approach is also shown in [
16]. However, restricting the data aggregation tree to be the balanced binary tree might lead to long data aggregation tree that has larger transmission cost.
In [
17], they show how to minimize energy consumption by using the prioritized channel assignment and scheduling the listen and sleep time. Sensor nodes with less residual power are assigned with higher priority for channel assignment. Sensor nodes with low priority are scheduled to sleep to save energy loss. However, data aggregation routing is not addressed in [
17]. In [
18], sensor networks are partitioned into clusters and each sensor node sends its data to its cluster head before transmitting outside the cluster. All inter-cluster communication is done by the cluster head. However, channel reuse for better channel utilization is not addressed in [
18].
In [
19], they propose four interesting heuristic algorithms (SPT, GIT, CAGIT and ICADAR) to solve the channel constrained data aggregation routing problem. The first three heuristics are first to identify the data aggregation tree and then perform channel assignment to satisfy the channel constraint, which is a one-shot algorithm. The fourth algorithm is is an iterative procedure where routing and channel assignment may perform several times to identify a feasible and energy efficient data aggregation tree. However, the radio constraint is not addressed in [
19] such that it might not be feasible in the radio-constrained WSN.
4. Solution Approach—Lagrangean Relaxation
Constraints
(1),
(3),
(6),
(9),
(10),
(11) and
(13) in (P) are relaxed to get the following Lagrangean relaxation problem, where (
) represents the Lagrangean multiplier. Basically, the more constraints are relaxed, the looser duality gap between the solutions to the dual problem and the primal problem. Loose duality gap might indicate that the solution to the primal problem might be too far from the optimal solution. On the other hand, if too little constraints are relaxed, we might not be able to solve the Lagrangean dual problem optimally. Then the solution to the dual problem is not the true lower bound of the primal problem. As I will show in the following paragraph that by relaxing these seven constraints in (P) guarantee that the dual problem is optimally solved and in the meantime to obtain a tighter duality gap.
Problem (LR)
Subproblem 1: for Cl
Subproblem 2: for ygl.
Subproblem 3: for xgpd.
Subproblem 4: for mij.
Subproblem 5: for ni.
Subproblem 1 is to determine decision variable Cl. It can be further decomposed into |L| independent problems. For each link l ∈ L, when the coefficient of Cl (i.e.
) is positive, let Cl = 0. When the coefficient of Cl (i.e.
) is negative, let Cl = |G|. The computational complexity for this algorithm is O(1) for each link.
Sub-problem 2 is to determine decision variable
ygl. It can be further decomposed into |
G| independent problems. For each multicast group
g ∈
G,
subject to:
The algorithm to optimally solve
(SUB2.1) is shown as follows.
Step1. For every link l where its termination node is sensor node j, the coefficient for ygl on this link l is
. For every link l where its source node is the sensor node j, the coefficient for ygl on this link l is
.Then calculate the number of links whose coefficient is negative.
Step2. For each multicast group g∈ G, if the number of negative coefficient links is greater than ore equal to max{hg, |Dg|}, then for these negative coefficient links, assign the corresponding ygl = 1 and let other ygi = 0.
Step3. If the number of negative coefficient links (assume the number is θ) is smaller than max{hg, |Dg|}, assign the corresponding ygl = 1 for these negative coefficient links. Then sort those links that have positive coefficient in ascending order. Assign {max{hg, |Dg|}-θ} number of smallest positive coefficient and let ygl = 1. Finally, let the other ygl = 0.
The computational complexity of above algorithm is O(|L(|Dg|+log|L|)) for each multicast group.
Subproblem 3 is to determine decision variable xgpd. It can be further decomposed into
independent shortest path problems with non-negative arc weights
. They can be effectively solved by the Dijkstra's algorithm. The computational complexity of the Dijkstra's algorithm is O(|N|2) for each data source node of the multicast group.
Sub-problem 4 is to determine decision variable
mij. It could be further decomposed into |
N| independent subproblems. For each node
j ∈
N,
subject to:
In the objective function of
(SUB4.1), the coefficient for
mij is
. Because of Constraint
(17), at most
Rj number of channels could be selected for a node
j. If the number of negative coefficient is smaller than
Rj, then assign
mij = 1 for those channels that have negative coefficient. If the number of negative coefficient is greater than or equal to
Rj, then assign
mij = 1 for those
Rj channels that have smallest negative coefficient. Then assign
mij = 0 for the rest of the channels. The computational complexity is
O(|
F|log|
F) for each node
j ∈
N.
Sub-problem 5 is to determine decision variable
ni. For each channel
i ∈
F, since the Lagrangean multiplier
is positive, so the coefficient of
ni (i.e.
is negative.Constraint
(14) enforce that we can at most select
ω number of
ni such that
ni = 1. First, we initialize every
ni = 0. Then by sorting these coefficient for each niin ascending order, we select
ω number of
ni whose correspond coefficient are the smallestand let these
ni = 1. In this way, we could have minimum objective value in
(SUB5). The computational complexity is O(|F|log|F).
Applying the above algorithms, we can solve the Lagrangean dual problem (LR) optimally. According to weak duality theorem, that is, the objective value of LR is a legitimate lower bound to the original problem (P). One can calculate the tightest lower bound and solve the dual problem by using the subgradient method [
20]. Note that the solutions to the dual problem may not be feasible to the primal problem due to several constraints are relaxed. In the sequel, I propose the heuristic for getting the primal feasible solution.
5. Obtaining Primal Feasible Solutions
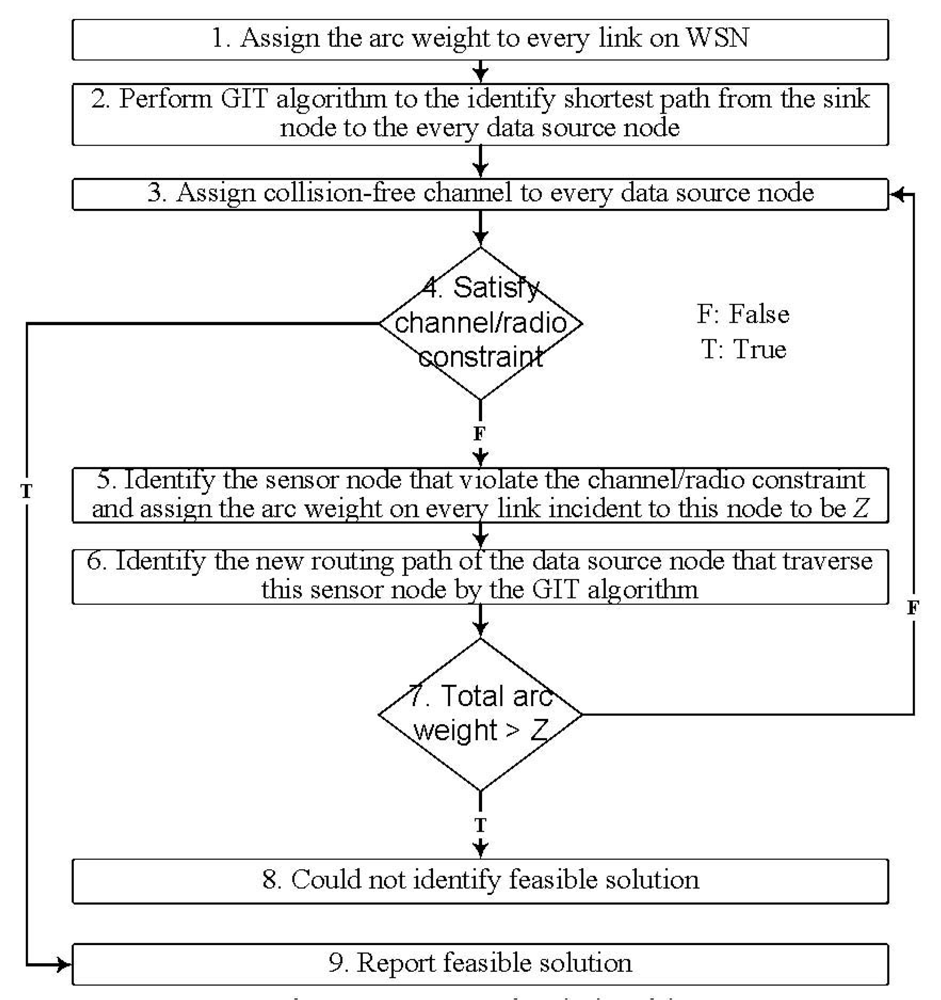
The basic idea of getting primal feasible solution (LGR-Primal) is first to identify the energy efficient data aggregation and then adjust the routing path to meet the channel/radio resource constraint. This is a kind of iterative algorithm which is particularly useful under stringent resource constraint (i.e., limited channels and radios). In order to facilitate this idea, the LGR-Primal algorithm is first to identify efficient data aggregation tree by using the GIT algorithm. Then perform the channel and radio assignment algorithm. If the channel and radio constraint is satisfied, then report the data aggregation tree. Otherwise, identify another data aggregation routing path such that the channel and radio constraint could be satisfied, this process is repeated until feasible data aggregation tree is identified.
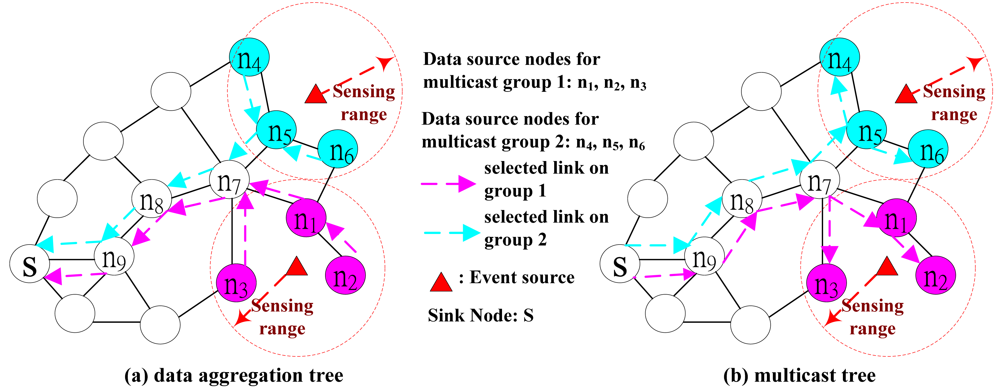
In
Figure 5, the data aggregation tree is first determined by the GIT algorithm, and then performs channel/radio assignment for every sensor node on the data aggregation tree. The channel/radio assignment order has significant impact on the solution quality. According to [
19], the data source node with shorter hop count on the data aggregation tree to the sink is more likely to aggregate data than the data source node with longer hop count. Then by first assigning the channel to the data source node with shorter hop count, the data source node with longer hop count could reuse the channel more efficiently without violating the co-channel interference constraint. Leverageon this observation, at Step 3 of
Figure 5, the data source node with shorter hop count to the sink has higher priority for channel and radio assignment than the data source node with longer hop count.
At Step 5, it specifies that if we could not assign feasible channel orradio to any sensor node along the routing path of the data source node, then we identify another routing path which bypasses the sensor nodes that violate the channel or radio constraint for this data source node. By assigning the very large arc weight (Z) to the links incident to these sensor nodes, the data source node could bypass these sensor nodes by running GIT algorithm again. If the total arc weight for the data source node exceeds Z, then we could conclude that there is no feasible channel/radio constrained routing path for this data source node. Note that, by assigning the very large arc weight (Z) to the links incident to the sensor nodes that violate the channel/radio constraint, the maximum number of traversed routing paths for any data source node is limited to be |N|-2, where |N|-2 represent the number of sensor nodes in the network besides the sink node and the data source node. In other words, at Step 7, the times of negative decision to go back to Step 3 is bounded to be |N|-2. Hence, we do not have an infinite looping problem.
At step 1 of
Figure 5, the link arc weight for multicast group
g on each link
l is setting to be:
The first two terms are from the subproblem 3 where the physical meaning for these two multipliers is the tree constraint violation cost for multicast group g. Note that I do a summation of
with all the data source nodes of multicast group g. By this summation, we could ensure the link arc weight is the same for every data source node d. As a consequence, the union of the routing paths for every data source node becomes a tree. The third term is the power transmission cost. The forth term is cost of violating the transmitting and receiving channel assignment.
The fifth term is the cost of violating the co-channel interference for the termination node of link l. If j″ is the termination node of link l, then
.
calculates the channel violation cost of the sensor nodes that are within sensor node j″ interference range (i.e., εj″k = 1) that use the same channel i. By summation over all the available channels,
is the cost of violating the co-channel interference for the termination node of link l. In other words, if the termination node of link l violates the co-channel interference constraint, the
cost will be high enough such that this link l will be unlikely to be selected again in the next iteration of the Lagrangean solution process. To summarize, by this link arc weight setting, I try to identify the multicast tree not only from minimizing transmission power point of view but also considering the channel assignment and co-channel interference.
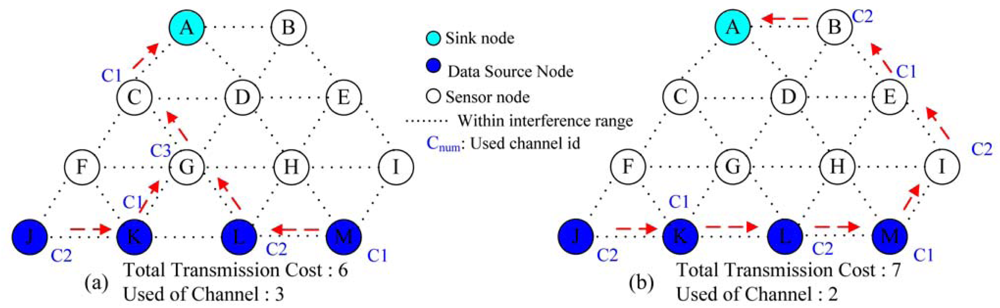
An illustrative example is given in
Figure 6. In
Figure 6, each sensor node is assumed to be equipped with two radios. The transmission cost on each link is assumed to be 1. In
Figure 6(a), it shows the final data aggregation tree and the channel assignment when
ω = 3. If we have only two available non-overlapping channels, then data aggregation tree in
Figure 6(a) is not a feasible solution. According to Step 5 in
Figure 5, all the five incident links to a node
G will be assigned with arc weight
Z such that the new routing path will skip a node
G. Similarly, the next routing path traverse via a node
F or a node
H will also be infeasible due to channel constraint. This is because for the node
F or node
H, there are two incident data source nodes such that there is no feasible channel for the node
F or node
H under two available channels. So all the incident links to the nodes
F and
H will be assigned with arc weight
Z such that the next routing path will skip the node
F or node
H. Finally, we could have a feasible data aggregation tree that traverse a node
I as indicated in
Figure 6(b). Note that if a node
I is taken away from
Figure 6, then we will not have a feasible solution since the total arc weight on the data aggregation tree will exceed
Z as shown in Step 7 in
Figure 5. In this case, after traversing three routing paths (i.e., traversing via
G, F or
H), we can conclude that there is no feasible solution when a node
I is taken away from
Figure 6.
The computational complexity for the GIT algorithm is
O(|
N|
2) for each data source node. The channel assignment (i.e., step 3 of
Figure 5) for any sensor node on the data aggregation tree needs to identify the channel assignment for the other sensor nodes that are within its interference range. Hence, the computational complexity is
O(|
F‖
N|) for each data source node. Note that, for any data source node, the maximum number of iterations (Step 7 to Step 3 in
Figure 5) to identify the channel/radio constrained routing paths is limited to be |
N|-2, where |
N|-2 represent the number of sensor nodes in the network besides the sink node and data source node. In other words, at Step 7, the times of negative decision to go back to Step 3 is bounded to be |
N|-2. The computational complexity is
O(|
F‖
N|
2) for each data source node.
In the following, I show the complete algorithm (denoted as LGR) to solve Problem (P). The computational complexity of the above LGR algorithm is
for each iteration.
| Algorithm 1: LGR Algorithm. |
| Begin |
| Input: Network topology, data source nodes |
| Output: Data aggregation tree |
| Initialize Lagrangean multiplier vectors ui(0) = 0, ∀i = 1,.…,6. |
|
and LB = a very large negative number (e.g., −∞) //upper and lower bounds, respectively |
| quiescence_age = 0, and step_size = 2. |
| For iteration = 1 to Max_Iteration_Number, perform the following: |
| Solve subproblem 1, subproblem 2, subproblem 3, subproblem 4, subproblem 5. |
| Compute ZLR in (LR). |
| If ZLR (u) > LB |
| LB = ZLR(u) and quiescence_age = 0. |
| Else quiescence_age = quiescence_age + 1. |
| If quiescence_age = Quiescence_Threshold |
| step_size = step_size/2 and quiescence_age = 0. |
| Run LGR-Primal algorithm (Figure 5). |
| Compute the new upper bound ub. |
| If ub < UB then UB = ub. |
| Update the step_size. |
| Update the Lagrangean multiplier vectors. |
| End For |
| End |
6. Computational Experiments
The sensor nodes are randomly placed in a 1 × 1 area. Sensor nodes are uniformly distributed on the deployment area. If there are 100 sensor nodes, the deployment area will be partitioned into 100 grids with the same size and each sensor node is placed in the center of the grid. The most top left node is selected as the sink node such that we could have a data aggregation tree with larger depth. The transmission cost is equal to the square of the Euclidean distance of the link (i.e., signal attenuation constant α = 2). Two different types of data source nodes are simulated. The first one is event-driven where neighboring sensor nodes beside the event will become the data source nodes. The second one is random-source where data source nodes are determined in random. Hence, the data source nodes in event-driven are clustered but the data source nodes in random-source are randomly placed in the deployment area.
For LGR,
Max_Iteration_Number and
Quiesceince_Threshold are set to 1,000 and 30, respectively. The
step_size_coefficient is initialized to be 2 and will be halved when the objective function value of the dual problem does not improve for iterations up to
Quiesceince_Threshold. The experimental results are within minutes of computation time. All of the experiments were running in a PC with INTEL™ P4 1.8 GHz CPU. In order to evaluate the solution quality of LGR algorithm, I compare LGR with the other four algorithms proposed in [
19] under different varieties of parameters.
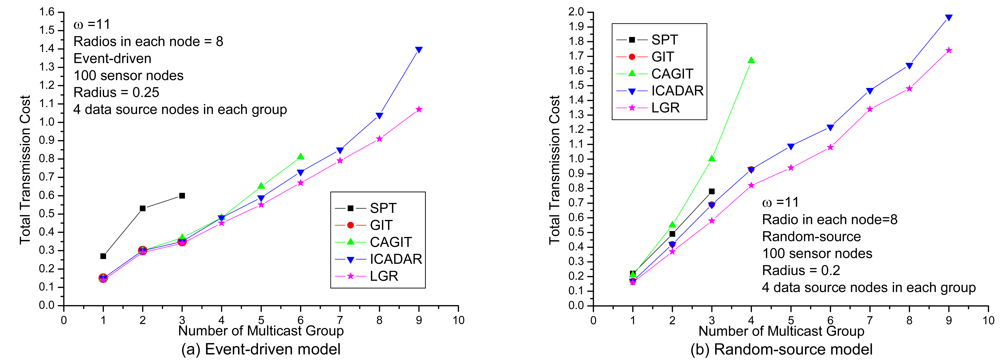
In
Figure 7, it shows the results under increasing number of multicast groups with respect to loose channel and radio constraints. There are two important observations. First observation is that the LGR algorithm is superior to the other four algorithms with respect to total transmission cost. Second observation is that in random source model, the solution quality of LGR is constantly superior to ICADAR in random source model for both light and heavy traffic demands. In event-driven model, the LGR outperforms ICADAR especially in heavy traffic demands. Recall that in event-driven model, the data source nodes are clustered so that it will consume more radios and channels as compared to random-source model. In event-driven model, the channel and radio constraint will be more stringent at heavy traffic demands (e.g., 9 multicast groups). This indicates that to incorporate penalty cost for violating channel assignment and co-channel interference constraint on the arc weight, the selected data aggregation trees are resilient to more stringent channel and radio constraints than the other four algorithms.
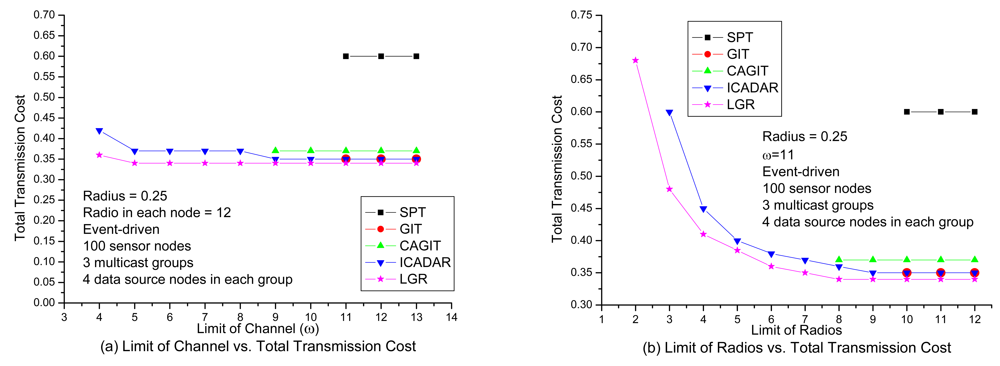
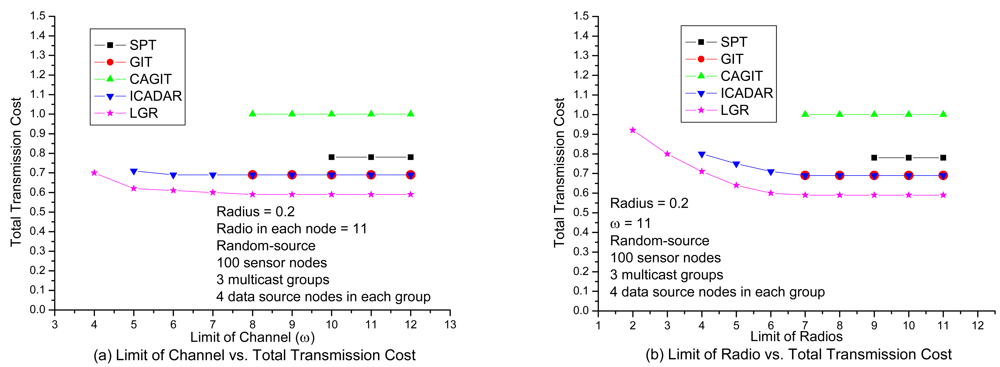
In
Figure 8(a), it shows the transmission cost with respect to number of available channels under loose number of radios. It is expected that the total transmission cost will be increased at small available channels due to more stringent channel constraint. It is interesting to observe that, for SPT, GIT and CAGIT algorithms, the total transmission cost remains the same when
ω is decreasing. It is because that they belong to an one shot algorithm, which will not alter its routing decision with respect to different
ω. On the other hand, ICADAR and LGR algorithms could choose its routing decision not to aggregate under stringent channel constraint. Such kind of behavior is also observed in
Figure 8(b). In addition, it is interesting to observe that stringent radio constraint incurs even significant increasing in transmission cost as compared to stringent channel constraint. It is because the maximum number of predecessor (i.e., incoming links) for each sensor node is limited by the number of radios on the sensor node. Then in stringent radio constraint, it results in longer data aggregation tree which makes it difficult to perform data aggregation. LGR algorithm is superior to the other four heuristics in both
Figure 8(a) and Figure 8(b), and it is significant in stringent channel and radio constraint.
In
Figure 9, it shows the performance comparison with respect to the channel and radio in random-source. As compared to
Figure 8, the solution quality of LGR over the other four heuristics is more significant. In
Figure 9(a), besides LGR could get much lower transmission cost data aggregation tree, LGR could locate feasible data aggregation tree under stringent channel constraint (4 channels). We also observe the same performance improvement of LGR in
Figure 9(b). As compared to ICADAR could only locate feasible data aggregation tree with at least 4 radios, LGR could locate the feasible solution even with 2 radios. By carefully examine the difference between
Figure 8 and
Figure 9, we could conclude that LGR outperforms the other heuristics under stringent channel and radio constraint, especially in random-source model.
Institutively, in the dense WSN (i.e., large network size), the number of feasible data aggregation trees will also be increasing. In
Figure 10, we could observe that the total communication cost is decreasing with respect to increasing network size. Recall that transmission cost is defined to be the square of the Euclidean distance of the link. From the objective function point of view, a concatenation of multiple links with shorter distance is preferable than a single link with longer distance. However, co-channel interference will be more significant such that it is not easy to identify feasible solutions.
When network size is above a certain threshold, we could not get feasible solutions due to the co-channel interference constraint will not be satisfied. LGR and ICADAR algorithms could identify feasible solution even when the number of sensor nodes is 196. In addition, LGR could locate lowest cost aggregation tree. This reveals that with capturing the penalty cost of co-channel interference to construct the multicast tree, LGR algorithm is superior to the other four heuristics under variety of network size. From the comparison between event-driven and random-source model, it indicates that it is not easy to identify another routing path for a randomly distributed data source node under stringent channel constraint. As compared to
ω = 8 in
Figure 10(a), we have
ω = 10 in
Figure 10(b). In other words, we need more channels to have feasible solutions for sparse and dense sensor network in random-source model.
In
Figure 11, it investigates the total transmission cost under different communication radius. It could be expected that with increasing the communication radius, it increases the probability of co-channel interference. Hence, it will be more difficult to identify the feasible channel assignment on the data aggregation tree. It might need to identify another routing path not to violate channel constraint (i.e., longer routing path that is out of the interference range of the other paths) under larger communication radius. We could observe that LGR algorithm outperforms the other heuristic algorithms in event-driven and random-source. As compared to ICADAR algorithm will rapidly increase the total transmission cost, we have more mild increase total transmission cost for LGR algorithm at large communication radius. This indicates that by incorporating penalty cost for violating the co-channel interference on the arc weight of each link, LGR could identify more cost efficient data aggregation tree to meet the co-channel interference under large communication radius.
From
Figure 7 to
Figure 11, we observe that LGR algorithm outperforms the other four heuristics. Besides more efficient transmission cost, LGR algorithm can locate feasible solutions at high network load, stringent channel/radio constraint, dense sensor network, and stringent co-channel interference. We define an
improvement ratio = ((L-M)/M × 100%)to be the performance metric, where
M stands for the total transmission cost from LGR and
L stands for the transmission cost from the other four heuristics. When there are no feasible solutions for the other heuristics (e.g., in
Figure 8(a) no feasible solution when the number of multicast groups is larger than 6 for SPT, GIT and CAGIT),
L stands for the largest feasible X-axis value from LGR and
M stands for the largest feasible X-axis value from the other three heuristics. Note that in
Figure 9(a), smaller
ω indicate stringent channel constraint,
L stands for the smallest feasible X-axis value from four heuristics and
M stands for the smallest feasible X-axis value from the LGR. I summarize the computational experiments in
Table 1. The first number in the parenthesis is LGR improvement ratio in event-driven and the second number is in random-source.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}