
Application Study of Comprehensive Forecasting Model Based on Entropy Weighting Method on Trend of PM2.5 Concentration in Guangzhou, China

Abstract
:1. Introduction
2. Related Theory
2.1. ARIMA Model
- (1)
- Sample pretreatment. The establishment of the ARIMA model requests that the time series data should be stationary stochastic process. Thus the data should be tested for stationary before modeling.
- (2)
- Pattern recognition. After the differential transform for the non-stationary time series, the key step is to determine the order of the ARIMA model. There are four methods to determine the order: (i) Auto Correlation Function (ACF) and Partial Auto Correlation Function (PACF) method; (ii) Final Prediction Error (FPE) method; (iii) Aikake Information Criterion (AIC) method; (iv) Aikake Information Corrected Criterion (AICC) method. The ACF and PACF method were used to master the direction of the general model to determine the order in this study.
- (3)
- Model testing. After the order determination and parameter estimation, the applicability of the model established should be tested. If the model error is white noise, the obtained model is qualified. Otherwise, the order re-determination and parameter re-estimation are needed.
- (4)
- Prediction. The time series data are forecasted in this step. The processes of model identification, parameter estimation, and model diagnosis are often improved gradually. The initial choices need to be constantly adjusted according to concrete problems.
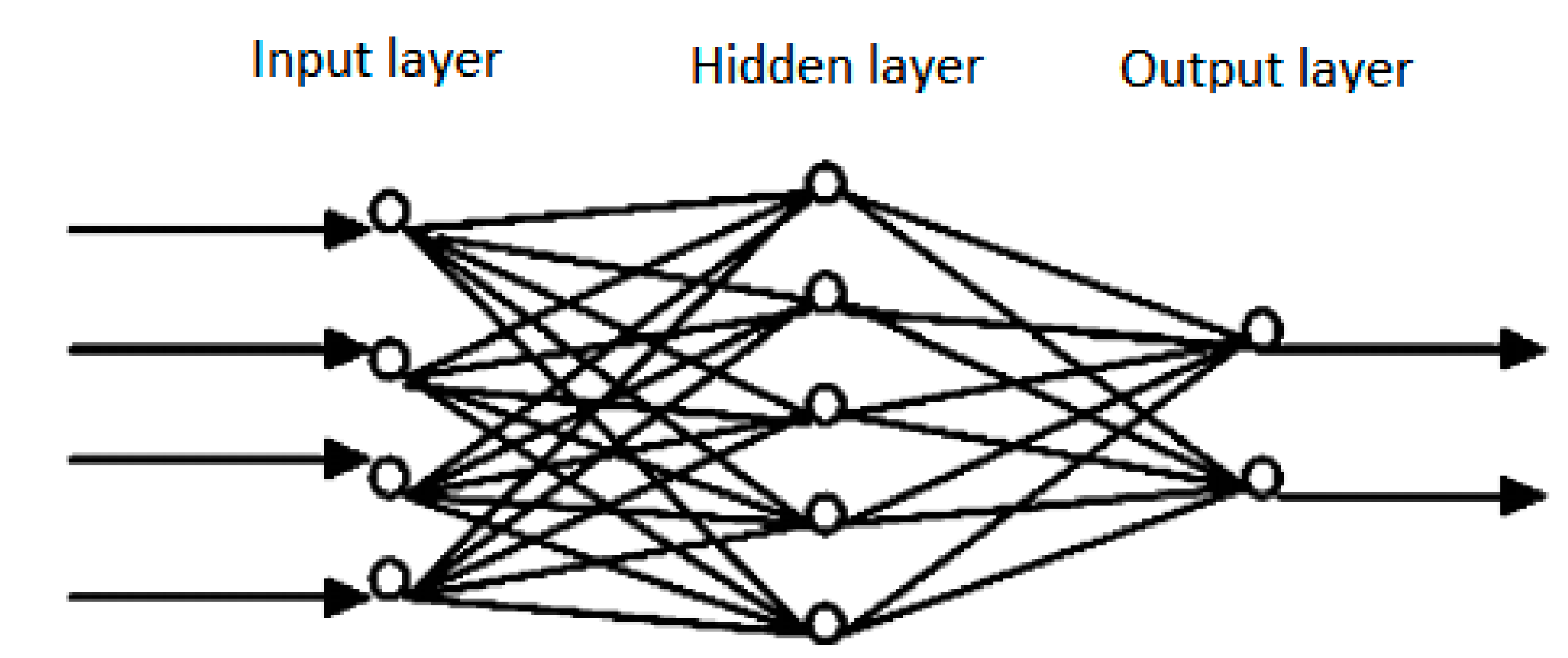
2.2. Artificial Neural Networks Model

2.3. Exponential Smoothing Method
2.4. Entropy Weighting Method
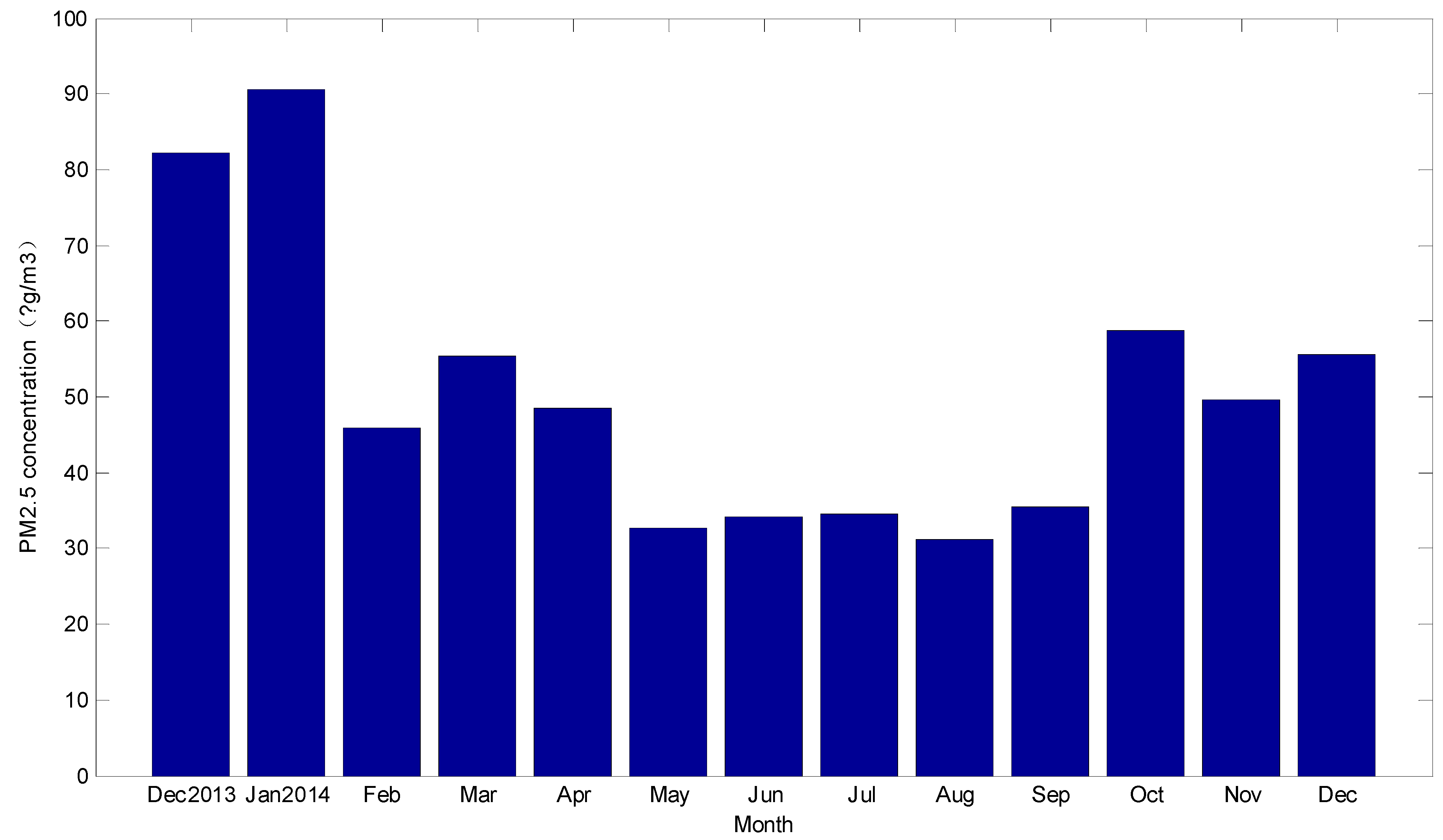
3. Simulation Data and Qualitative Trend Analysis

4. Simulation Results Based on Comprehensive Forecasting Model
4.1. Comprehensive Forecasting Model
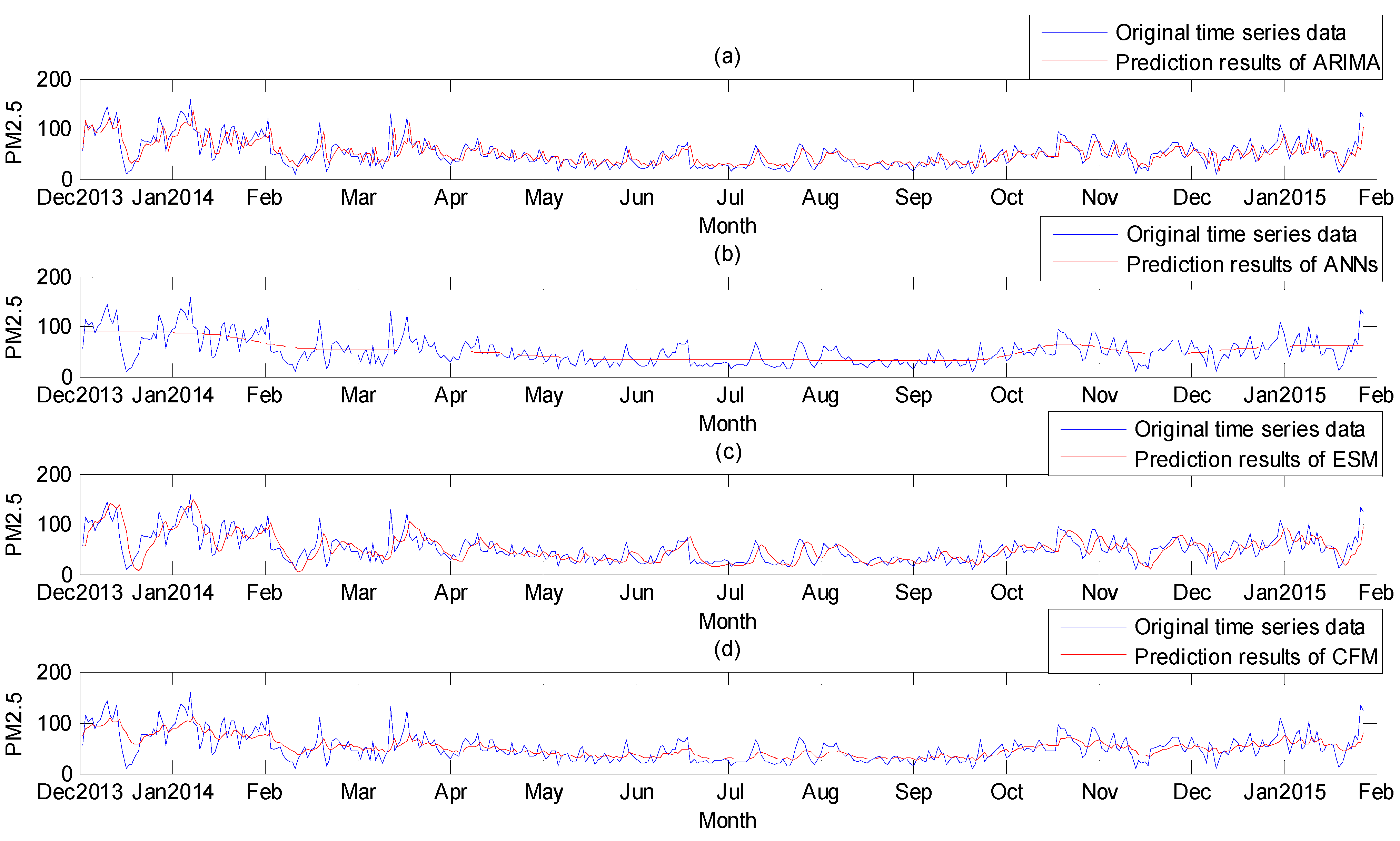
4.2. Simulation Results

4.3. Accuracy Test

{kind=link}
{kind=link}
{kind=link}
| No. | Index | Formula | Function |
|---|---|---|---|
| 1 | MAE | It can describe the system errors, and is an absolute index. | |
| 2 | MPE | It can describe the system errors, and is a relative index and dimensionless. | |
| 3 | RMSE | It can describe the system errors, and is an absolute index. | |
| 4 | Theil inequality coefficient | It can describe the system errors, and is a relative index and dimensionless. | |
| 5 | Bias ratio | It can measure the deviation degree of the average between the forecasting sequence and original sequence. | |
| 6 | Variance ratio | It can measure the deviation degree of the variance between the forecasting sequence and original sequence. |
| No. | Index | ARIMA | ANNs | ESM | CFM |
|---|---|---|---|---|---|
| 1 | MAE (µg/m3) | 12.6578 | 15.4849 | 15.8016 | 13.3090 |
| 2 | MPE | 0.3212 | 0.4159 | 0.3821 | 0.3522 |
| 3 | RMSE (µg/m3) | 17.4596 | 20.7186 | 21.3586 | 18.0247 |
| 4 | Theil inequality coefficient | 0.0050 | 0.0071 | 0.0058 | 0.0060 |
| 5 | Bias ratio | 6.12 × 10−7 | 2.69 × 10−5 | 2.56 × 10−4 | 5.70 × 10−5 |
| 6 | Variance ratio | 0.1212 | 0.2201 | 0.0021 | 0.2338 |
4.4. Prediction of Next Ten Days
| No. | Date | Actual Observation Value (µg/m3) | ARIMA (µg/m3) | ANNs (µg/m3) | ESM (µg/m3) | CFM (µg/m3) |
|---|---|---|---|---|---|---|
| 1 | 2015/1/22 | 58.2 | 101.6861 | 61.6869 | 114.865 | 82.8862 |
| 2 | 2015/1/23 | 64.4 | 37.9755 | 61.6923 | 98.6254 | 64.0614 |
| 3 | 2015/1/24 | 73.6 | 56.3128 | 61.6964 | 89.1382 | 66.3927 |
| 4 | 2015/1/25 | 68.8 | 43.7694 | 61.6993 | 86.038 | 62.7086 |
| 5 | 2015/1/26 | 68.3 | 41.9564 | 61.7012 | 81.2968 | 61.2402 |
| 6 | 2015/1/27 | 64.8 | 43.2804 | 61.7021 | 77.4207 | 60.7125 |
| 7 | 2015/1/28 | 49.3 | 38.7611 | 61.7022 | 72.8985 | 58.6417 |
| 8 | 2015/1/29 | 51.7 | 41.4545 | 61.7016 | 62.6025 | 57.0409 |
| 9 | 2015/1/30 | 32.8 | 38.5742 | 61.7004 | 56.4024 | 54.9964 |
| 10 | 2015/1/31 | 35.6 | 40.069 | 61.6986 | 43.6473 | 52.5709 |
| No. | Index | ARIMA | ANNs | ESM | CFM |
|---|---|---|---|---|---|
| 1 | MAE(µg/m3) | 19.1119 | 11.2298 | 21.5435 | 10.3321 |
| 2 | MPE | 0.3188 | 0.2571 | 0.3987 | 0.2229 |
| 3 | RMSE(µg/m3) | 22.2286 | 14.2652 | 25.5865 | 12.8903 |
| 4 | Theil inequality coefficient | 0.0033 | 0.0032 | 0.0034 | 0.0025 |
| 5 | Bias ratio | 0.1417 | 0.1203 | 0.7089 | 0.1739 |
| 6 | Variance ratio | 0.0522 | 0.8789 | 0.0616 | 0.1757 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sun, Y.L.; Wang, Z.F.; Fu, P.Q.; Yang, T.; Jiang, Q.; Dong, H.B.; Li, J.J. Aerosol composition sources and process during wintertime in Beijing, China. Atmos. Chem. Phys. 2013, 13, 4577–4592. [Google Scholar] [CrossRef]
- World Health Organization. Air Quality Guidelines; WHO Press: Geneva, Switzerland, 2005; volume 10. [Google Scholar]
- Wang, Z.F.; Li, J.; Wang, Z.; Yang, W.Y.; Tang, X.; Ge, B.Z.; Yan, P.Z.; Zhu, L.L.; Chen, X.S.; Chen, H.S. Modeling study of regional severe hazes over Mid-eastern China in January 2013 and its implications on pollution prevention and control. Sci. China Earth Sci. 2014, 57, 3–13. [Google Scholar] [CrossRef]
- Zhao, P.S.; Dong, F.; He, D.; Zhao, X.J.; Zhang, X.L.; Zhang, W.Z.; Yao, Q.; Liu, H.Y. Characteristics of concentrations and chemical compositions for PM2.5 in the region of Beijing, Tianjin, and Hebei, China. Atmos. Chem. Phys. 2013, 13, 4631–4644. [Google Scholar] [CrossRef]
- Che, H.; Xia, X.; Zhu, J.; Li, Z.; Dubovic, O.; Holben, B.; Goloub, P.; Chen, H.; Estelles, V.; Cuevas-Agulló, E.; et al. Column aerosol optical properties and aerosol radiative forcing during a serious haze-fog month over North China Plain in 2013 based on ground-based sunphotometer measurements. Atmos. Chem. Phys. 2013, 13, 29685–29720. [Google Scholar] [CrossRef]
- Tao, J.; Zhang, L.; Ho, K.; Zhang, R.; Lin, Z.; Zhang, Z.; Zhang, Z.S.; Lin, M.; Cao, J.J.; Liu, S.X.; et al. Impact of PM2.5 chemical compositions on aerosol light scattering in Guangzhou—The largest megacity in South China. Atmos. Res. 2014, 135, 48–58. [Google Scholar] [CrossRef]
- Shen, G.F.; Yuan, S.Y.; Xie, Y.N.; Xia, S.J.; Li, L.; Yao, Y.K.; Qiao, Y.Z.; Zhang, J.; Zhao, Q.Y.; Ding, A.J.; et al. Ambient levels and temporal variations of PM2.5 and PM10 at a residential site in the mega-city, Nanjing, in the western Yangtze River Delta, China. J. Environ. Sci. Health 2014, 49, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Kloog, I.; Chudnovsky, A.A.; Just, A.C.; Nordio, F.; Koutrakis, P.; Coull, B.A.; Lyapustin, A.; Wang, Y.; Schwartz, J. A new hybrid spatio-temporal model for estimating daily multi-year PM2.5 concentrations across northeastern USA using high resolution aerosol optical depth data. Atmos. Environ. 2014, 95, 581–590. [Google Scholar] [CrossRef]
- Ministry of Environmental Protection. Ambient Air Quality Standards (GB 3095-2012), 2012. Available online: http://www.zzemc.cn/em_aw/Content/GB3095-2012.pdf (accessed on 29 February 2012).
- Liu, D.Y.; Yang, J.; Niu, S.J.; Li, Z.H. On the evolution and structure of a radiation fog event in Nanjing. Adv. Atmos. Sci. 2011, 28, 223–237. [Google Scholar] [CrossRef]
- Quan, J.; Zhang, Q.; He, H.; Liu, J.; Huang, M.; Jin, H. Analysis of the formation of fog and Haze in North China Plain. Atmos. Chem. Phys. 2011, 11, 8205–8214. [Google Scholar] [CrossRef]
- Liu, X.; Li, J.; Qu, Y.; Han, T.; Hou, L.; Gu, J.; Chen, C.; Yang, Y.; Liu, X.; Yang, T.; et al. Formation and evolution mechanism of regional haze: A case study in the megacity Beijing, China. Atmos. Chem. Phys. 2013, 13, 4501–4514. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, Y.; Zhu, W.; Rao, R. Aerosol characteristics during summer haze episodes from different source regions over the coast city of North China Plain. J. Quant. Spectrosc. Radiat. Transf. 2013, 122, 180–193. [Google Scholar] [CrossRef]
- Zhou, M.; Chen, C.; Qiao, L.; Lou, S.; Wang, H.; Huang, H.; Wang, Q.; Chen, M.; Chen, Y. The chemical characteristics of particulate matters in Shanghai during heavy air pollution episode in Central and Eastern China in January 2013. Acta Sci. Circumst. 2013, 33, 3118–3126. [Google Scholar]
- Wang, H.; Tan, S.C.; Wang, Y.; Jiang, C.; Shi, G.Y.; Zhang, M.X.; Che, H.Z. A multisource observation study of the severe prolonged regional haze episode over eastern China in January 2013. Atmos. Environ. 2014, 89, 807–815. [Google Scholar] [CrossRef]
- Li, M.N.; Zhang, L.L. Haze in China: Current and future challenges. Environ. Pollut. 2014, 189, 85–86. [Google Scholar] [CrossRef] [PubMed]
- Soltani, S.; Modarres, R.; Eslamian, S.S. The use of time series modeling for the determination of rainfall climates of Iran. Int. J. Climatol. 2007, 27, 819–829. [Google Scholar] [CrossRef]
- Liang, W.M.; Wei, H.Y.; Kuo, H.W. Association between daily mortality from respiratory and cardiovascular diseases and air pollution in Taiwan. Environ. Res. 2009, 109, 51–58. [Google Scholar] [CrossRef] [PubMed]
- Chattopadhyay, G.; Chattopadhyay, S. Autoregressive forecast of monthly total ozone concentration—A neurocomputing approach. Comput. Geosci. 2009, 35, 1925–1932. [Google Scholar] [CrossRef]
- Chelani, A.B.; Devotta, S. Air quality forecasting using a hybrid autoregressive and nonlinear model. Atmos. Environ. 2006, 40, 1774–1780. [Google Scholar] [CrossRef]
- Prybutok, V.R.; Yi, J.; Mitchell, D. Comparison of neural network models with ARIMA and regression models for prediction of Houston’s daily maximum ozone concentrations. Eur. J. Oper. Res. 2000, 122, 31–40. [Google Scholar] [CrossRef]
- Stadlober, E.; Hormann, S.; Pfeiler, B. Quality and performance of a PM10 daily forecasting model. Atmos. Environ. 2008, 42, 1098–1109. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Abish, B.; Mohanakumar, K. A stochastic model for predicting aerosol optical depth over the north Indian region. Int. J. Remote Sens. 2013, 34, 1449–1458. [Google Scholar] [CrossRef]
- Soni, K.; Kapoor, S.; Parmar, K.S.; Kaskaoutis, D.G. Statistical analysis of aerosols over the Gangetic–Himalayan region using ARIMA model based on long-term MODIS observations. Atmos. Res. 2014, 149, 174–192. [Google Scholar] [CrossRef]
- Díaz-Robles, L.A.; Ortega, J.C.; Fu, J.S.; Reed, G.D.; Chow, J.C.; Watson, J.G.; Moncada-Herrera, J.A. A hybrid ARIMA and artificial neural networks model to forecast particulate matter in urban areas: The case of Temuco, Chile. Atmos. Environ. 2008, 42, 8331–8340. [Google Scholar] [CrossRef]
- Venkadesh, S.; Hoogenboom, G.; Potter, W.; McClendon, R. A genetic algorithm to refine input data selection for air temperature prediction using artificial neural networks. Appl. Soft Comput. 2013, 13, 2253–2260. [Google Scholar] [CrossRef]
- Ibarra-Berastegi, G.; Elias, A.; Barona, A.; Saenz, J.; Ezcurra, A.; de Argandoña, J.D. From diagnosis to prognosis for forecasting air pollution using neural networks: Air pollution monitoring in Bilbao. Environ. Model. Softw. 2008, 23, 622–637. [Google Scholar] [CrossRef]
- Sahin, M. Modelling of air temperature using remote sensing and artificial neural network in Turkey. Adv. Space Res. 2012, 50, 973–985. [Google Scholar] [CrossRef]
- Wahid, H.; Ha, Q.P.; Duc, H.; Azzi, M. Neural network-based meta-modelling approach for estimating spatial distribution of air pollutant levels. Appl. Soft Comput. 2013, 13, 4087–4096. [Google Scholar] [CrossRef]
- Xu, G.X. Statistical Forecasting and Decision-making; Shanghai University of Finance and Economics Press: Shanghai, China, 2004; pp. 127–130. [Google Scholar]
- Liu, L.; Zhou, J.Z.; An, X.L.; Zhang, Y.C.; Yang, L. Using fuzzy theory and information entropy for water quality assessment in Three Gorges region, China. Expert Syst. Appl. 2010, 37, 2517–2521. [Google Scholar] [CrossRef]
- Zou, Z.H.; Yun, Y.; Sun, J.N. Entropy method for determination of weight of evaluating indicators in fuzzy synthetic evaluation for water quality assessment. J. Environ. Sci. 2006, 18, 1020–1023. [Google Scholar] [CrossRef]
- Historical Data of PM2.5. Available online: http://www.aqistudy.cn/historydata/ (accessed on 1 March 2015).
- Granger, C.W.J.; Bates, J. The combination of forecasts. Oper. Res. Q. 1969, 20, 451–468. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.-j.; Li, L. Application Study of Comprehensive Forecasting Model Based on Entropy Weighting Method on Trend of PM2.5 Concentration in Guangzhou, China. Int. J. Environ. Res. Public Health 2015, 12, 7085-7099. https://doi.org/10.3390/ijerph120607085
Liu D-j, Li L. Application Study of Comprehensive Forecasting Model Based on Entropy Weighting Method on Trend of PM2.5 Concentration in Guangzhou, China. International Journal of Environmental Research and Public Health. 2015; 12(6):7085-7099. https://doi.org/10.3390/ijerph120607085
Chicago/Turabian StyleLiu, Dong-jun, and Li Li. 2015. "Application Study of Comprehensive Forecasting Model Based on Entropy Weighting Method on Trend of PM2.5 Concentration in Guangzhou, China" International Journal of Environmental Research and Public Health 12, no. 6: 7085-7099. https://doi.org/10.3390/ijerph120607085
APA StyleLiu, D. -j., & Li, L. (2015). Application Study of Comprehensive Forecasting Model Based on Entropy Weighting Method on Trend of PM2.5 Concentration in Guangzhou, China. International Journal of Environmental Research and Public Health, 12(6), 7085-7099. https://doi.org/10.3390/ijerph120607085