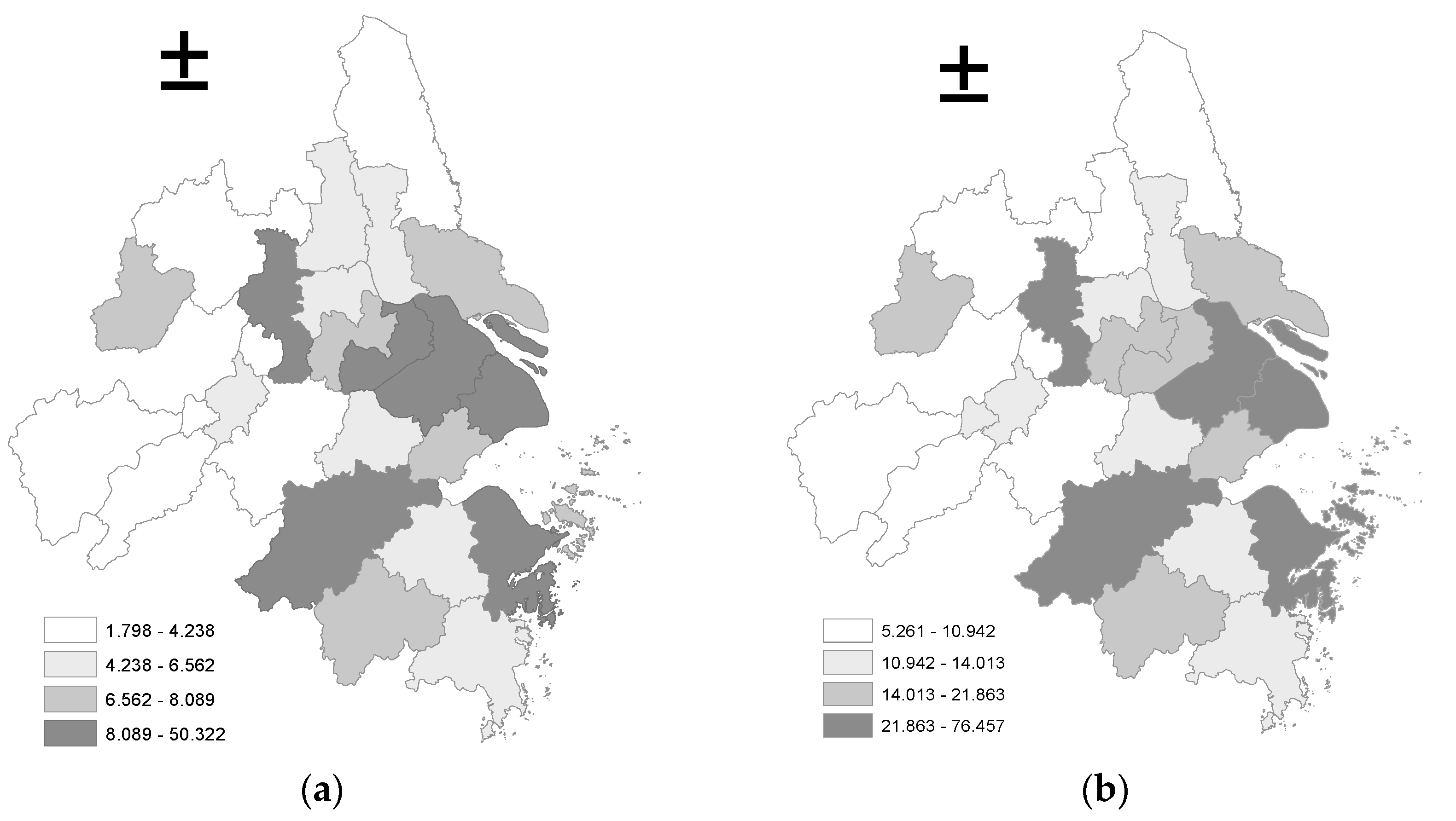
2.2.1. Evaluation on the Development Level of the Logistics Industry
The measure of direct impact and spatial spillover effect of the development of the logistics industry on economic growth relies on the reasonable evaluation of the development level of the regional logistics industry. On the basis of studies of Tang et al. (2015) [
14] and Cai et al. (2016) [
15], the rationality and availability of index data and the characteristics of the target regions are considered in this paper; a comprehensive evaluation index system of logistics industry development level in Yangtze River delta is constructed from four aspects: industrial scale, infrastructure, human resources, and industry support. The specific index system is shown in
Table 1.
Given that the entropy method is an objective evaluation method based on the index variability, it has been widely used in the evaluation of the development level of the logistics industry [
16,
17]. However, the traditional entropy method has a limitation. It can only be used to analyze two-dimensional data tables including regions and time points, and can not analyze three-dimensional data tables including indices, time points, and regions. Therefore, this paper draws on the overall entropy methods used by Pan et al. (2015) [
18] to evaluate the development level of logistics industry in urban agglomeration on the basis of above index system. Specific steps are shown below in Steps 1–6.
Step 1: According to the
evaluation indices of
regions and
years, the measurement of the development level of the logistics industry is carried out, and the
-section data tables are arranged in chronological order to construct a judgment matrix
p of
, which is shown as Formula (1),
Step 2: The judgment matrix
is normalized.
In Formulas (2) and (3), represents the normalized value, and represent, the minimum and maximum, respectively of the index. The positive indicator should be standardized by Formula (2); otherwise, it is standardized by Formula (3).
Step 3: Calculate the
indicator of entropy.
Step 4: Calculate the difference coefficient of the
indicator.
Step 5: Calculate the weight of the
indicator.
Step 6: Calculate the level of development of logistics industry.
2.2.2. Spatial Autocorrelation Test
On the basis of the above steps, the spatial autocorrelation of the logistics industry and the spatial autocorrelation of regional economic growth are tested by using the spatial statistical data box in ArcGIS10.2 software (Redlands, CA, USA); the test of Moran’s Index is used to determine necessity of introducing the spatial econometric model. When the Moran’s Index of the explanatory variable exists and can be tested by the significance test, it is necessary to introduce the spatial econometric model, because the variable does not satisfy the classical hypothesis of a homogeneous distribution. The Moran’s Index is shown in Formula (8),
where
and
represent the observed values of region
and region
, respectively,
is the number of objects to be observed,
, and
is the spatial weight matrix. This paper uses the row-standardized classical 0–1 matrix to conduct the study. The matrix form is shown in Formula (9),
Except that the diagonal elements of the matrix are all 0; when the region
is adjacent to the region
,
and when the region
is not adjacent to the region
,
. The range of Moran’s Index converges approximately to
, as the 0–1 spatial weight matrix is row-standardized [
19]. When the Moran’s Index is positive, it indicates that there is a spatial positive correlation, and there is a spatial negative correlation when the value is negative, while the greater the absolute value of Moran’s Index, the greater the degree of spatial correlation. Confirm that “index“ was intended here.
2.2.3. Spatial Spillover Effect Measuring Model Construction and Relevant Testing Steps
Taking into account the impact of the regional logistics industry on the economic growth of local and surrounding areas, the spatial durbin model (SDM) fits both theory and reality more well. Of course, based on rigorous consideration, this paper will also construct a spatial lag model (SAR) and spatial error model (SEM), and illustrate the selection of spatial econometric models and relevant testes. At the same time, in order to overcome the possible endogenous problems of the model, this paper takes the time lag of all the explanatory variables as its surrogate variables, and takes the natural logarithm of variables to reduce possible heteroscedasticity problems. Thus, the spatial econometric models based on the C–D production function are shown in Equations (10)–(12),
- (1)
Spatial Lag Model (SAR) is mainly used to study the spatial spillover effect of dependent variables on the surrounding areas.
- (2)
Spatial Error Model (SEM) mainly concentrates on the spatial interaction effect of the missing items in the modeling process.
- (3)
Spatial Error Model (SDM) takes both the spatial lag items of explanatory and explanatory variables into account.
where stands for regional economic growth, represents the level of development of the logistics industry, represents labor input, represents material capital investment, represents the level of opening to the outside world, represents government function, is 0–1 spatial weight matrix, is spatial autoregressive coefficient reflects the effect of the spatial hysteresis on the explained variables. is the spatial autocorrelation coefficient of the error term. and are the regression coefficients and the spatial correlation coefficients, respectively, of the explanatory variables, is the fixed-space effect, is the fixed-time effect, is the random error term.
After building the spatial econometric model, a series of related model tests are necessary to ensure the reliability of the regression results. The main test steps are shown as Steps 1–3.
Step 1: Before the regression analysis, in order to avoid serious multiple collinearity problems between the variables, the correlation coefficient matrix is provided and Variance Inflation Factor (VIF) of each variable is calculated. If the VIF is less than the empirical value of 10, the model can basically be judged to be free of serious multicollinearity problems.
Step 2: According to the non-space panel model, the likelihood ratio test (LR) is used to investigate the existence and significance of the time and space fixed in the model. At the same time, according to the Lagrange Multiplier test (LM) and Robust Lagrange Multiplier test (Robust LM), it is further judged whether there exist spatial lag or spatial error terms in the model. If the null hypothesis that there is no space lag or space error is rejected, LM-lag is superior to LM-error, while Robust LM-lag test is superior to Robust LM-error; in this case, the SAR model should be selected instead of SEM model [
20].
Step 3: If the above test indicates the necessity of the inclusion of the spatial factor, the applicability of the SDM model will be further evaluated using the Wald and LR tests. If the null hypotheses and are rejected, it is shown that the SDM model can not be simplified to the SAR or the SEM. Therefore, the SDM model is better able to describe the relationship between the development of the logistics industry and economic growth in the Yangtze River Delta urban agglomeration.
On the basis of the above tests, the spatial econometric models will be estimated by the maximum likelihood estimation (ML) [
21], the spatial spillover effect of the explanatory variables is measured by the partial differential method proposed by Lesage et al. [
22]. The model is introduced into the inverse matrix to transform the SDM model as shown in Formula (13),
The average effect of the kth explanatory variable is obtained by
Dth extraction, forming a partial differential matrix equation, as shown in Formula (14),
Among them, the mean value of the diagonal elements of the matrix represents the direct effect of the explanatory variables, and the mean of the diagonal elements represents the spatial spillover effect of the explanatory variables.





{kind=link}
{kind=link}