Evaluation of an Agricultural Meteorological Disaster Based on Multiple Criterion Decision Making and Evolutionary Algorithm


Abstract
:1. Introduction
2. Related Works
3. Methodology
3.1. AHP
3.2. Proposed Algorithm Based on DE and Evolution Strategy
3.2.1. Conventional DE
- (1)
- Mutation
- (2)
- Crossover
- (3)
- Selection
3.2.2. The Proposed Algorithm Based on DE
3.3. Proposed Evaluation Model Based on TOPSIS
3.3.1. TOPSIS
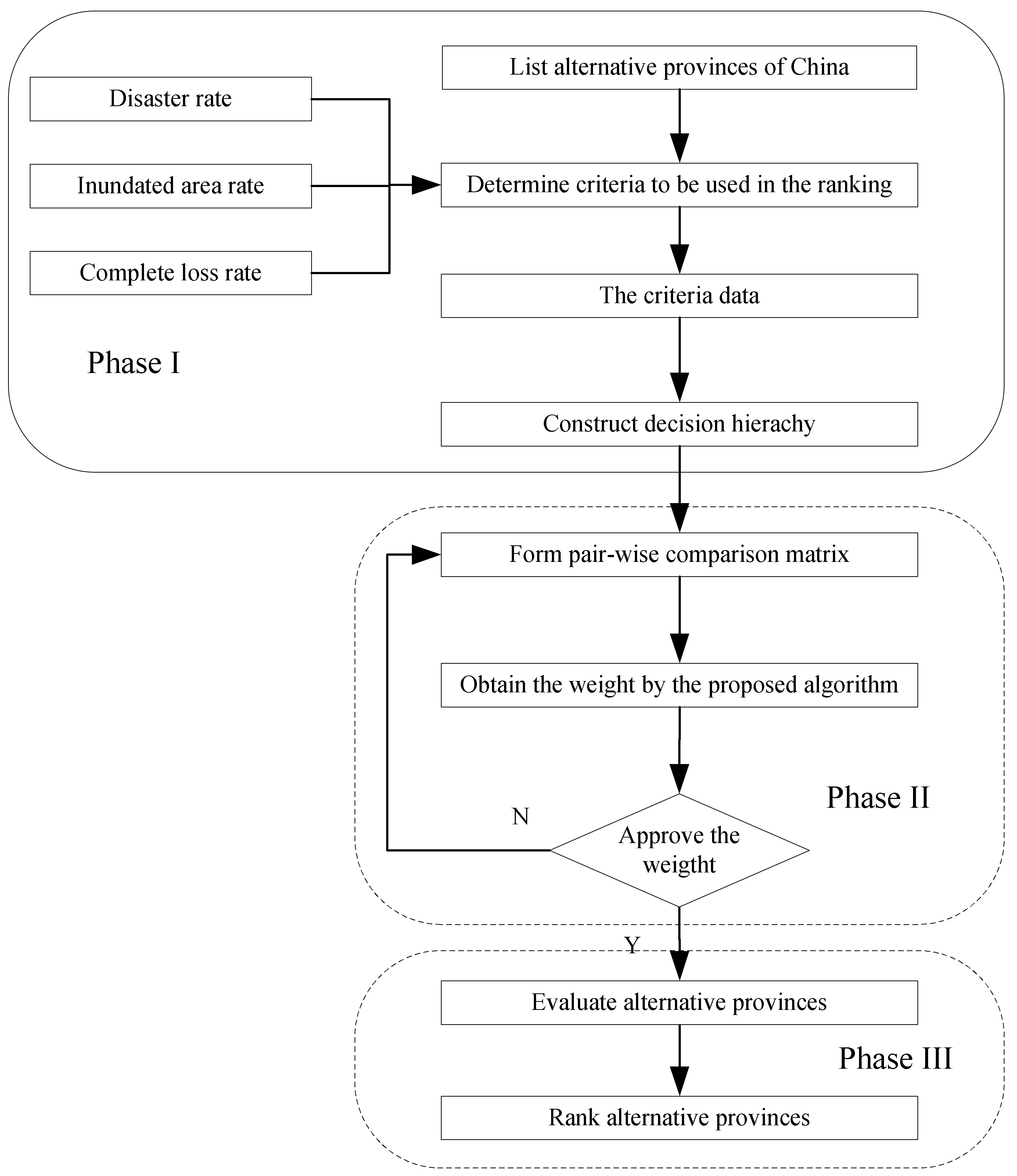
3.3.2. The Proposed Model
- (1)
- Identify the criteria and acquire the data
- (2)
- Calculate the criteria weights using the proposed algorithm
- (3)
- Evaluate the disaster and determinate the final ranks using TOPSIS
4. Results
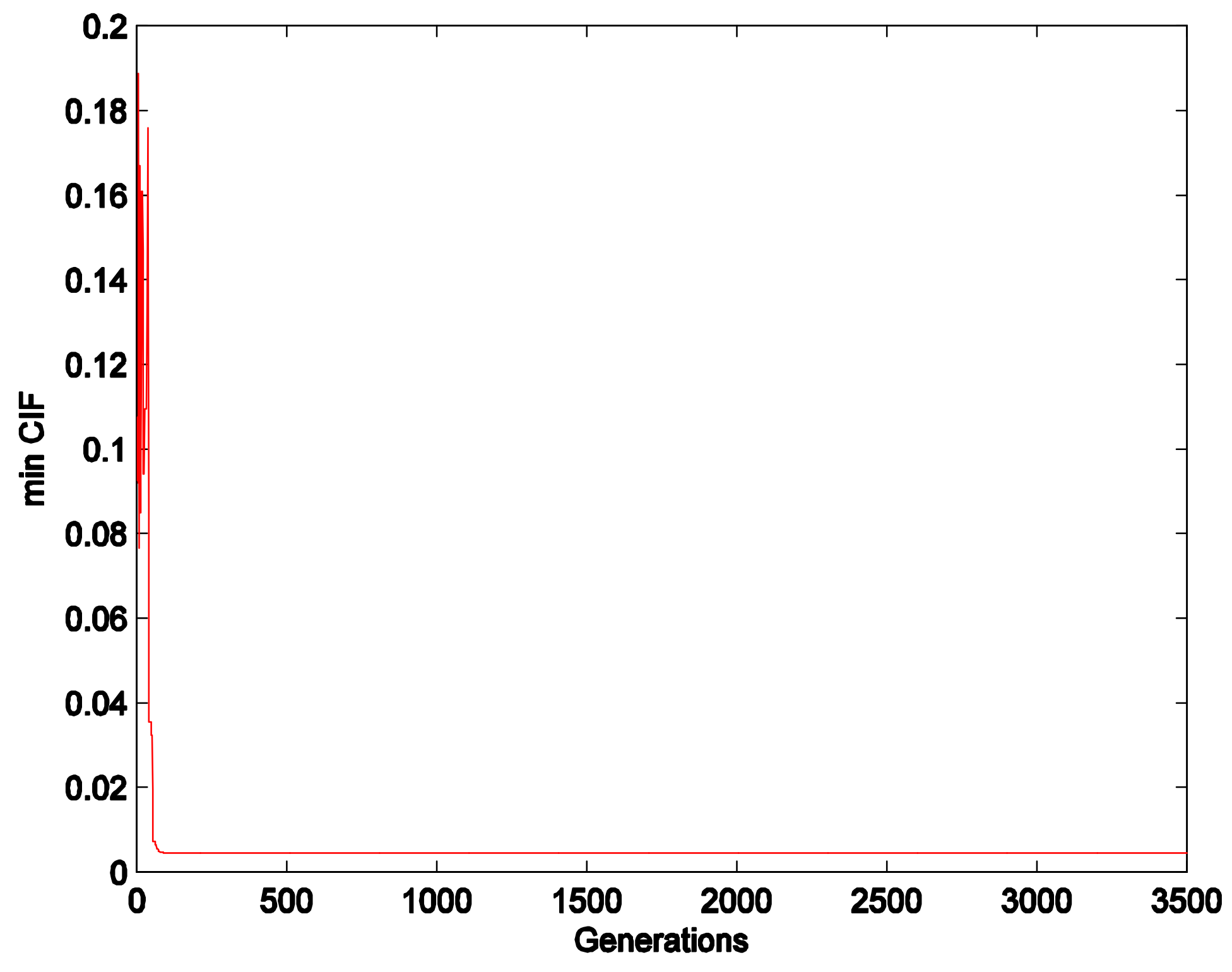
4.1. Algorithm Experiment
4.2. Acquire the Relative Weights among Different Criteria
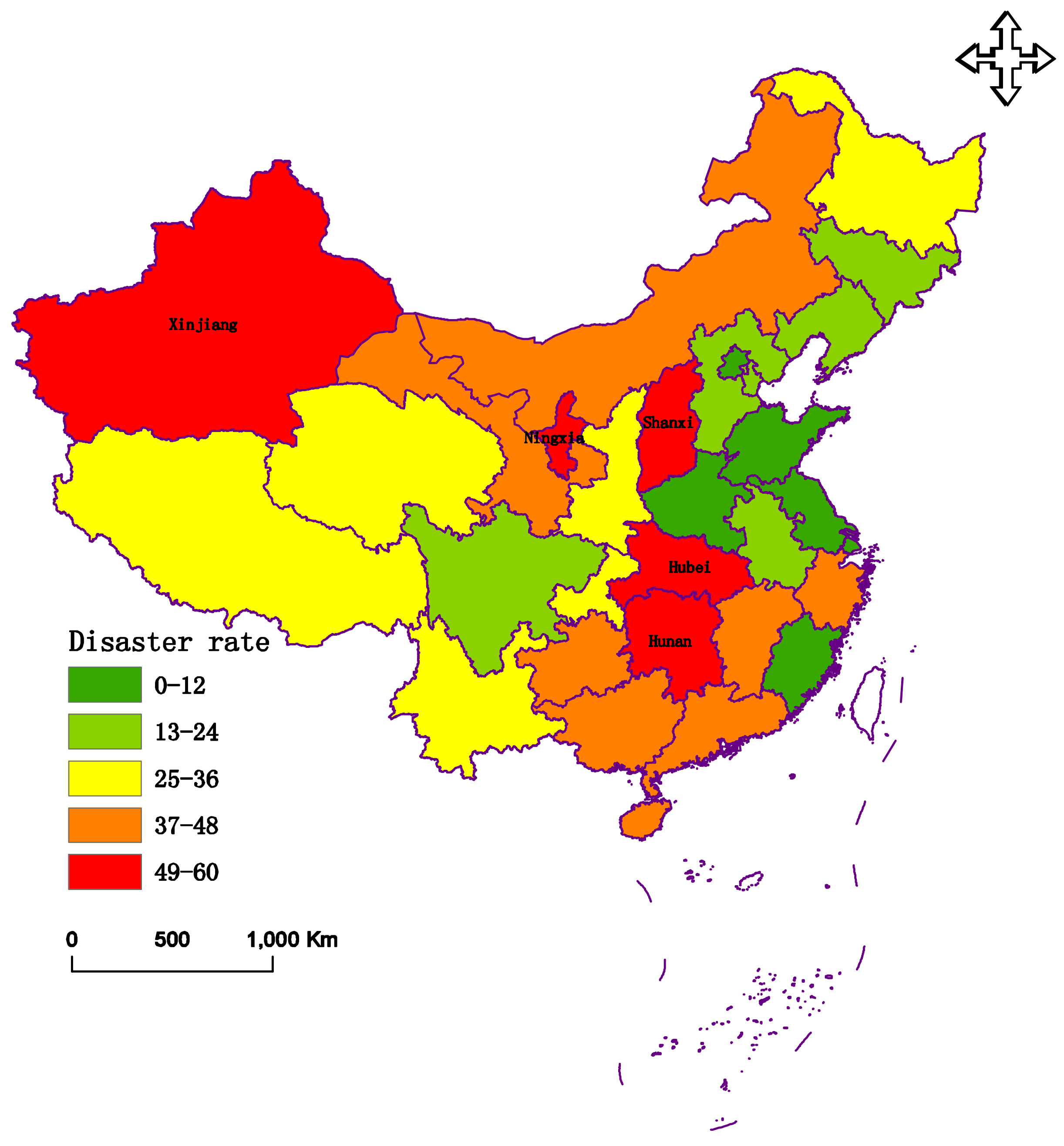
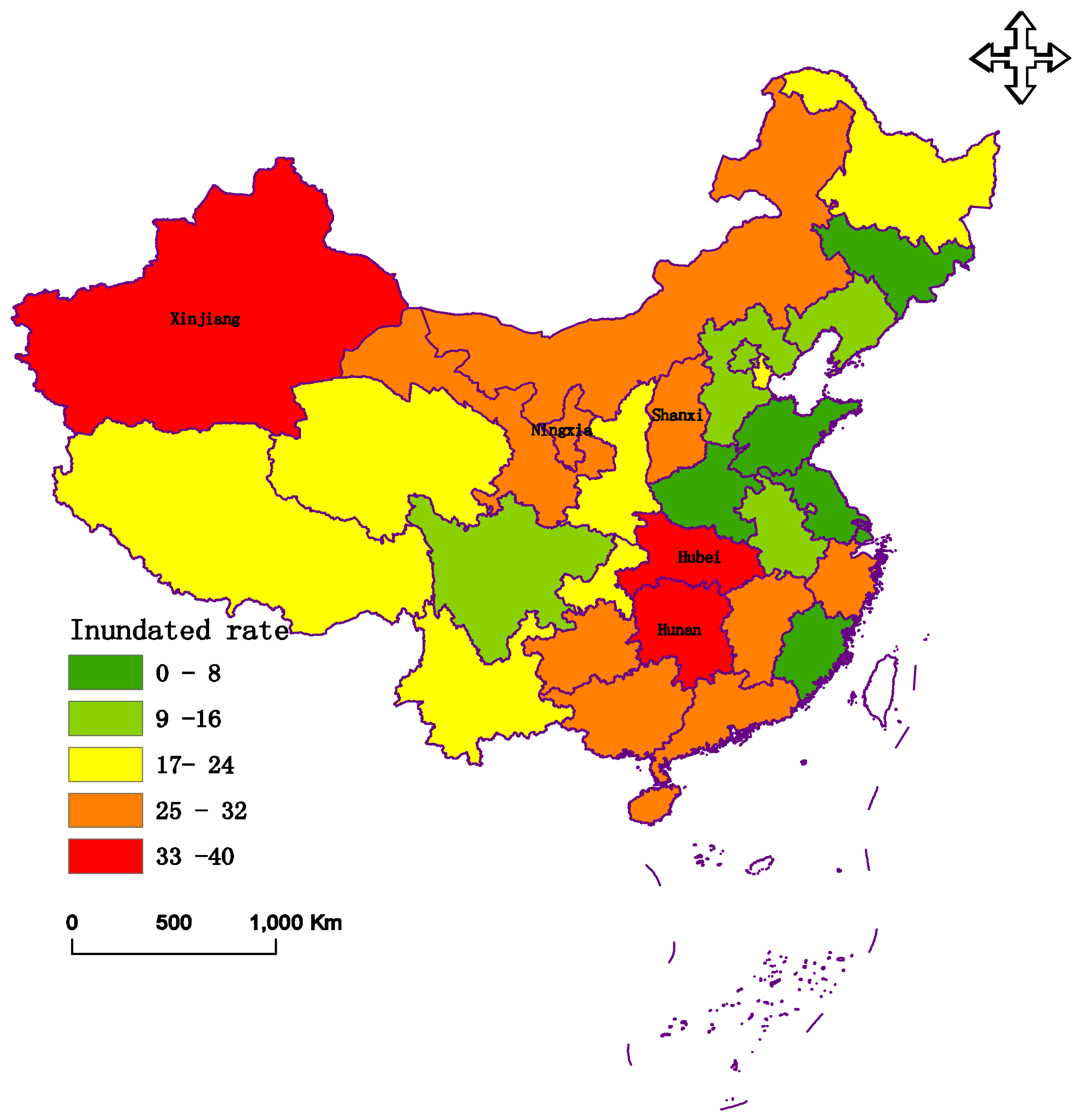
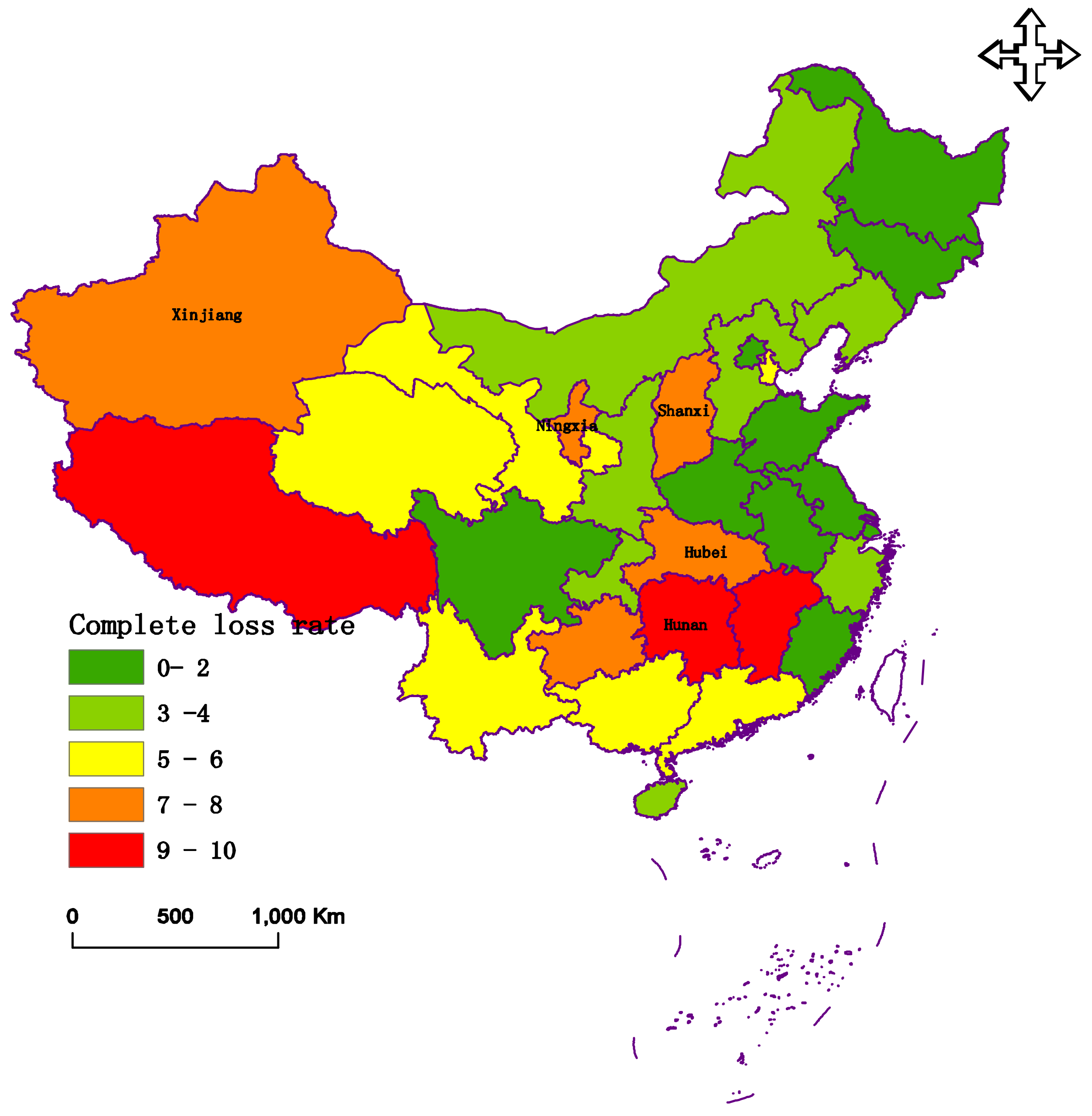
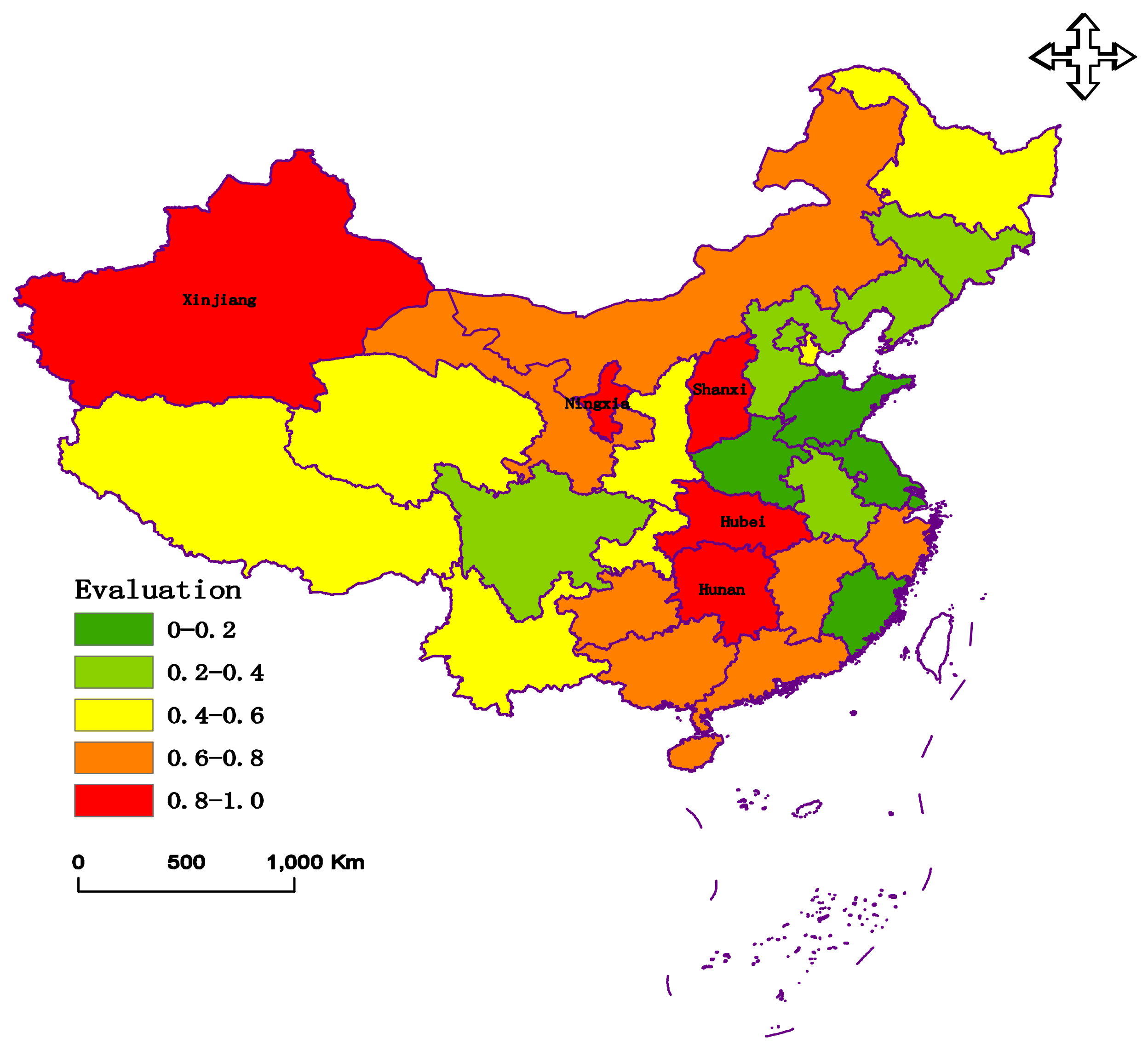
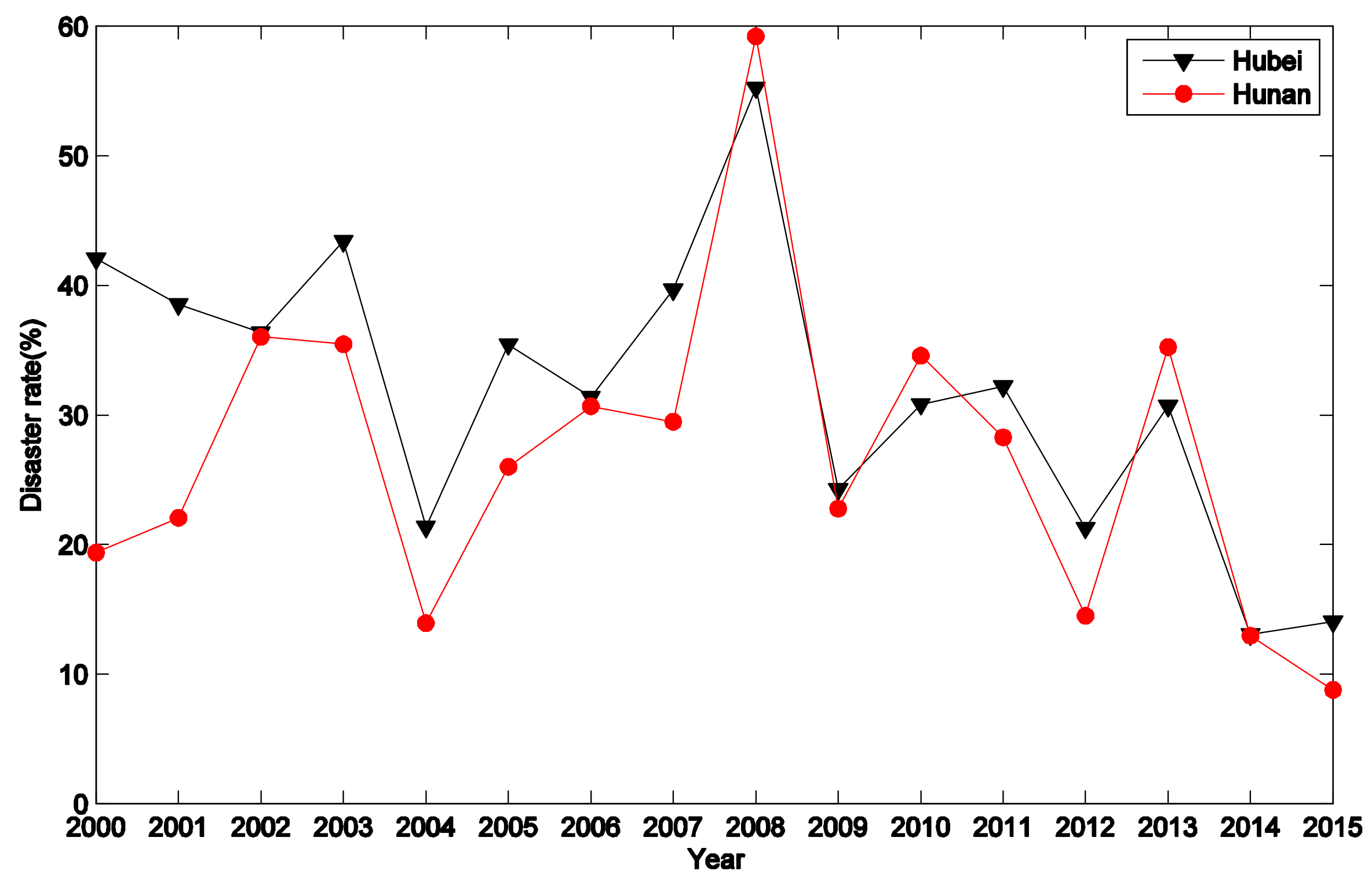
4.3. Evaluation Results
5. Discussion
- (1)
- Speed up the establishment of the disaster warning mechanism, and improve the ability of agricultural natural disaster forecasting.
- (2)
- Further strengthen the infrastructure construction of farmland, and enhance the natural disaster prevention ability.
- (3)
- Strongly promote practical agricultural technology, and improve the level of science and technology in order to improve the ability of agriculture to defend against natural disasters.
- (4)
- Establish the emergency plan for major disasters and improve the ability of emergency responses to natural disasters.
- (5)
- Increase the support for agricultural disaster recovery and make an effort to reduce agricultural disaster losses.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rojas, O.; Vrieling, A.; Rembold, F. Assessing drought probability for agricultural areas in Africa with coarse resolution remote sensing imagery. Remote Sens. Environ. 2011, 115, 343–352. [Google Scholar] [CrossRef]
- Zhang, H.; Xiong, L.; Qiu, Y.; Zhou, D. How have political incentives for local officials reduced environmental pollution in resource-depleted cities? Sustainability 2017, 9, 1941. [Google Scholar] [CrossRef]
- Li, Q.; Yang, Y.; Chen, R.; Kan, H.; Song, W.; Tan, J.; Xu, F.; Xu, J. Ambient air pollution, meteorological factors and outpatient visits for eczema in Shanghai, China: A time-series analysis. Int. J. Environ. Res. Public Health 2016, 13, 1106. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Gong, Z. Priority of a hesitant fuzzy linguistic preference relation with a normal distribution in meteorological disaster risk assessment. Int. J. Environ. Res. Public Health 2017, 14, 1203. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Xiao, G.; Wang, J.; Zhang, X.; Liang, J. Spatiotemporal risk of bacillary dysentery and sensitivity to meteorological factors in Hunan province, China. Int. J. Environ. Res. Public Health 2017, 15, 47. [Google Scholar] [CrossRef] [PubMed]
- Nivolianitou, Z.S.; Synodinou, B.M.; Aneziris, O.N. Important meteorological data for use in risk assessment. J. Loss Prev. Process Ind. 2004, 17, 419–429. [Google Scholar] [CrossRef]
- Palerme, C.; Claud, C.; Dufour, A.; Genthon, C.; Wood, N.B.; L’Ecuyer, T. Evaluation of antarctic snowfall in global meteorological reanalyses. Atmos. Res. 2017, 190, 104–112. [Google Scholar] [CrossRef]
- Wang, J.; Fang, F.; Zhang, Q.; Wang, J.; Yao, Y.; Wang, W. Risk evaluation of agricultural disaster impacts on food production in southern China by probability density method. Nat. Hazards 2016, 83, 1605–1634. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, J.; Zhang, Q.; Hu, Y.; Yan, D.; Wang, C. Integrated risk zoning of drought and waterlogging disasters based on fuzzy comprehensive evaluation in Anhui province, China. Nat. Hazards 2013, 71, 1639–1657. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, Z.; Wang, W.; Luo, K. The comprehensive risk evaluation on rainstorm and flood disaster losses in China mainland from 2004 to 2009: Based on the triangular gray correlation theory. Nat. Hazards 2013, 71, 1001–1016. [Google Scholar] [CrossRef]
- Bathrellos, G.D.; Gaki-Papanastassiou, K.; Skilodimou, H.D.; Papanastassiou, D.; Chousianitis, K.G. Potential suitability for urban planning and industry development using natural hazard maps and geological–geomorphological parameters. Environ. Earth Sci. 2011, 66, 537–548. [Google Scholar] [CrossRef]
- Bathrellos, G.D.; Skilodimou, H.D.; Chousianitis, K.; Youssef, A.M.; Pradhan, B. Suitability estimation for urban development using multi-hazard assessment map. Sci. Total Environ. 2017, 575, 119–134. [Google Scholar] [CrossRef] [PubMed]
- Bathrellos, G.D.; Karymbalis, E.; Skilodimou, H.D.; Gaki-Papanastassiou, K.; Baltas, E.A. Urban flood hazard assessment in the basin of Athens metropolitan city, Greece. Environ. Earth Sci. 2016, 75, 319. [Google Scholar] [CrossRef]
- Bathrellos, G.D.; Gaki-Papanastassiou, K.; Skilodimou, H.D.; Skianis, G.A.; Chousianitis, K.G. Assessment of rural community and agricultural development using geomorphological–geological factors and GIS in the Trikala prefecture (central Greece). Stoch. Environ. Res. Risk Assess. 2012, 27, 573–588. [Google Scholar] [CrossRef]
- He, Y.; Gong, Z. China’s regional rainstorm floods disaster evaluation based on grey incidence multiple-attribute decision model. Nat. Hazards 2013, 71, 1125–1144. [Google Scholar] [CrossRef]
- Xie, Z.; Liu, H. Evolution characteristics of agricultural drought disasters in China. In Proceedings of the Ninth International Conference on Management Science and Engineering Management; Xu, J., Nickel, S., Machado, V., Hajiyev, A., Eds.; Intelligent Systems and Computing, Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Sun, Z.; Zhang, J.; Yan, D.; Wu, L.; Guo, E. The impact of irrigation water supply rate on agricultural drought disaster risk: A case about maize based on epic in Baicheng city, China. Nat. Hazards 2015, 78, 23–40. [Google Scholar] [CrossRef]
- Hao, L.; Zhang, X.; Liu, S. Risk assessment to China’s agricultural drought disaster in county unit. Nat. Hazards 2011, 61, 785–801. [Google Scholar] [CrossRef]
- Lu, H.; Wu, Y.; Li, Y.; Liu, Y. Effects of meteorological droughts on agricultural water resources in southern China. J. Hydrol. 2017, 548, 419–435. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, Q.; Zhang, J.; Zhao, L.; Sun, W.; Jin, Y.-X. Extreme meteorological disaster effects on grain production in Jilin province, China. J. Integr. Agric. 2017, 16, 486–496. [Google Scholar] [CrossRef]
- Guan, Y.; Zheng, F.; Zhang, P.; Qin, C. Spatial and temporal changes of meteorological disasters in China during 1950–2013. Nat. Hazards 2014, 75, 2607–2623. [Google Scholar] [CrossRef]
- Xie, N.; Xin, J.; Liu, S. China’s regional meteorological disaster loss analysis and evaluation based on grey cluster model. Nat. Hazards 2013, 71, 1067–1089. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, N.; Wu, W.; Wu, J.; Gu, X.; Ji, Z. Exploring the characteristics of major natural disasters in China and their impacts during the past decades. Nat. Hazards 2013, 69, 829–843. [Google Scholar] [CrossRef]
- Zhang, J. Risk assessment of drought disaster in the maize-growing region of Songliao plain, China. Agric. Ecosyst. Environ. 2004, 102, 133–153. [Google Scholar] [CrossRef]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making—The analytic hierarchy and network processes (AHP/ANP). J. Syst. Sci. Syst. Eng. 2004, 13, 1–35. [Google Scholar] [CrossRef]
- Yu, X.; Lu, Y.; Wang, X.; Luo, X.; Cai, M. An effective improved differential evolution algorithm to solve constrained optimization problems. Soft Comput. 2017. [Google Scholar] [CrossRef]
- Mallipeddi, R.; Suganthan, P.N.; Pan, Q.K.; Tasgetiren, M.F. Differential evolution algorithm with ensemble of parameters and mutation strategies. Appl. Soft Comput. 2011, 11, 1679–1696. [Google Scholar] [CrossRef]
- Jingqiao, Z.; Sanderson, A.C. Jade: Adaptive differential evolution with optional external archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Jia, G.; Wang, Y.; Cai, Z.; Jin, Y. An improved (μ + λ)-constrained differential evolution for constrained optimization. Inf. Sci. 2013, 222, 302–322. [Google Scholar] [CrossRef]
- Hwang, C.L.; Yoon, K.P. Multiple Attribute Decision Making: Methods and Applications; Springer: New York, NY, USA, 1981. [Google Scholar]
- Yoon, K.P.; Hwang, C.L. Multiple Attribute Decision Making; Sage Publication: Thousand Oaks, CA, USA, 1995. [Google Scholar]
- Behzadian, M.; Khanmohammadi Otaghsara, S.; Yazdani, M.; Ignatius, J. A state-of the-art survey of topsis applications. Expert Syst. Appl. 2012, 39, 13051–13069. [Google Scholar] [CrossRef]
- Liang, J.J.; Runarsson, T.P.; Mezura-Montes, E.; Clerc, M.; Suganthan, P.N.; Coello, C.C.; Deb, K. Problem Definitions and Evaluation Criteria for the CEC 2006 Special Session on Constrained Real-Parameter Optimization; Nanyang Technological University: Singapore, 2006; Volume 41, pp. 1–24. [Google Scholar]
- Runarsson, T.P.; Yao, X. Search biases in constrained evolutionary optimization. IEEE Trans. Syst. Man Cybern. Part C 2005, 35, 233–243. [Google Scholar] [CrossRef]
- Ho, P.Y.; Shimizu, K. Evolutionary constrained optimization using an addition of ranking method and a percentage-based tolerance value adjustment scheme. Inf. Sci. 2007, 177, 2985–3004. [Google Scholar] [CrossRef]
- Elfeky, E.Z.; Sarker, R.A.; Essam, D.L. Analyzing the simple ranking and selection process for constrained evolutionary optimization. J. Comput. Sci. Technol. 2008, 23, 19–34. [Google Scholar] [CrossRef]
- Yong, W.; Zixing, C.; Yuren, Z.; Wei, Z. An adaptive tradeoff model for constrained evolutionary optimization. IEEE Trans. Evol. Comput. 2008, 12, 80–92. [Google Scholar] [CrossRef]
- Venkatraman, S.; Yen, G.G. A generic framework for constrained optimization using genetic algorithms. IEEE Trans. Evol. Comput. 2005, 9, 424–435. [Google Scholar] [CrossRef]
- Lin, C.-H. A rough penalty genetic algorithm for constrained optimization. Inf. Sci. 2013, 241, 119–137. [Google Scholar] [CrossRef]
- Sheng, J.; Webber, M. Incentive-compatible payments for watershed services along the Eastern Route of China’s South-North Water Transfer Project. Ecosyst. Serv. 2017, 25, 213–226. [Google Scholar] [CrossRef]
- Gong, Z.W.; Chen, X.Q. Analysis of interval data envelopment efficiency model considering different distribution characteristics-based on environmental performance evaluation of the manufacturing industry. Sustainability 2017, 9, 2080. [Google Scholar] [CrossRef]
- Liu, J.; Cheng, Z.H.; Zhang, H.M. Does industrial agglomeration promote the increase of energy efficiency in China? J. Clean. Prod. 2017, 164, 30–37. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Function | n | Objective Function | LI | NI | LE | NE | |||
|---|---|---|---|---|---|---|---|---|---|
| g01 | 13 | quadratic | 0.0111% | 9 | 0 | 0 | 0 | 6 | −15.0000000000 |
| g02 | 20 | nonlinear | 99.9971% | 0 | 2 | 0 | 0 | 1 | −0.8036191042 |
| g03 | 10 | polynomial | 0.0000% | 0 | 0 | 0 | 1 | 1 | −1.0005001000 |
| g04 | 5 | quadratic | 51.1230% | 0 | 6 | 0 | 0 | 2 | −30,665.5386717834 |
| g05 | 4 | cubic | 0.0000% | 2 | 0 | 0 | 3 | 3 | 5126.4967140071 |
| g06 | 2 | cubic | 0.0066% | 0 | 2 | 0 | 0 | 2 | −6961.8138755802 |
| g07 | 10 | quadratic | 0.0003% | 3 | 5 | 0 | 0 | 6 | 24.3062090681 |
| g08 | 2 | nonlinear | 0.8560% | 0 | 2 | 0 | 0 | 0 | −0.0958250415 |
| g09 | 7 | polynomial | 0.5121% | 0 | 4 | 0 | 0 | 2 | 680.6300573745 |
| g10 | 8 | linear | 0.0010% | 3 | 3 | 0 | 0 | 0 | 7049.2480205286 |
| g11 | 2 | quadratic | 0.0000% | 0 | 0 | 0 | 1 | 1 | 0.7499000000 |
| Function | Proposed | ATMES | TC | YK | ISR | HS |
|---|---|---|---|---|---|---|
| g01 | 0 × 100 | 0 × 100 | 0 × 100 | 0 × 100 | 0 × 100 | 0 × 100 |
| g02 | 6.7 × 10−3 | 1.3 × 10−2 | 7.6 × 10−3 | 1.3 × 10−2 | 2.1 × 10−2 | 2.6 × 10−2 |
| g03 | 0 × 100 | 5.0 × 10−4 | 5.0 × 10−4 | 1.0 × 10−35 | 5.0 × 10−4 | 5.0 × 10−4 |
| g04 | 7.64 × 10−11 | 3.2 × 10−4 | 7.7 × 10−3 | 3.3 × 10-4 | 3.3 × 10−4 | 3.10 × 10−1 |
| g05 | 1.10 × 102 | 1.15 × 100 | 1.62 × 102 | 2.17 × 100 | 2.86 × 10−5 | 3.47 × 102 |
| g06 | 3.37 × 10−11 | 1.2 × 10−4 | 1.20 × 10−4 | 6.69 × 101 | 1.20 × 10−4 | 6.55 × 101 |
| g07 | 7.26 × 10−6 | 9.8 × 10−3 | 1.68 × 100 | 1.68 × 10−2 | 2.10 × 10−4 | 1.11 × 10−1 |
| g08 | 8.20 × 10−11 | 9.8 × 10−3 | 1.68 × 100 | 1.7 × 10−2 | 2.1 × 10−4 | 1.1 × 10−1 |
| g09 | 0 × 100 | 8.9 × 10−3 | 3.3 × 10−2 | 4.9 × 10−3 | 5.7 × 10−5 | 3.3 × 10−2 |
| g10 | 4.38 × 10−2 | 2.01 × 102 | 8.43 × 102 | 1.32 × 102 | 2.0 × 10−3 | 3.16 × 102 |
| g11 | 0 × 100 | 1.0 × 10−4 | 1.0 × 10−4 | 1.0 × 10−4 | 6.1 × 10−3 | 7.71 × 10−2 |
| Area | Province and City | D+ | D− | CC |
|---|---|---|---|---|
| North | Beijing | 0.1974 | 0.0223 | 0.1015 |
| Tianjin | 0.1647 | 0.0540 | 0.2469 | |
| Hebei | 0.1834 | 0.0354 | 0.1618 | |
| Shanxi | 0.0338 | 0.2006 | 0.8558 | |
| Northeast | Inner Mongolia | 0.0993 | 0.1205 | 0.5482 |
| Liaoning | 0.1814 | 0.0369 | 0.1690 | |
| Jilin | 0.1949 | 0.0237 | 0.1084 | |
| Heilongjiang | 0.1621 | 0.0566 | 0.2588 | |
| East | Shanghai | 0.2183 | 0 | 0 |
| Jiangsu | 0.2121 | 0.0067 | 0.0306 | |
| Zhejiang | 0.0773 | 0.1450 | 0.6523 | |
| Anhui | 0.1840 | 0.0344 | 0.1575 | |
| Fujian | 0.2005 | 0.0184 | 0.0841 | |
| Jiangxi | 0.0694 | 0.1527 | 0.6875 | |
| Shandong | 0.2153 | 0.0035 | 0.0160 | |
| South central | Henan | 0.2104 | 0.0089 | 0.0406 |
| Hubei | 0.0194 | 0.2029 | 0.9127 | |
| Hunan | 0.0044 | 0.2177 | 0.9802 | |
| South | Guangdong | 0.1003 | 0.1194 | 0.5435 |
| Guangxi | 0.0864 | 0.1346 | 0.6090 | |
| Hainan | 0.0724 | 0.1513 | 0.6764 | |
| Southwest | Chongqing | 0.1567 | 0.0617 | 0.2825 |
| Sichuan | 0.1822 | 0.0365 | 0.1669 | |
| Guizhou | 0.0869 | 0.1314 | 0.6019 | |
| Yunnan | 0.1423 | 0.0760 | 0.3481 | |
| Xizang | 0.1437 | 0.0784 | 0.3530 | |
| Northwest | Shanxi | 0.1435 | 0.0757 | 0.3553 |
| Gansu | 0.1005 | 0.1180 | 0.5400 | |
| Qinghai | 0.1438 | 0.0745 | 0.3413 | |
| Ningxia | 0.0444 | 0.1876 | 0.8086 | |
| Xinjiang | 0.0467 | 0.1723 | 0.7868 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Yu, X.; Lu, Y. Evaluation of an Agricultural Meteorological Disaster Based on Multiple Criterion Decision Making and Evolutionary Algorithm. Int. J. Environ. Res. Public Health 2018, 15, 612. https://doi.org/10.3390/ijerph15040612
Yu X, Yu X, Lu Y. Evaluation of an Agricultural Meteorological Disaster Based on Multiple Criterion Decision Making and Evolutionary Algorithm. International Journal of Environmental Research and Public Health. 2018; 15(4):612. https://doi.org/10.3390/ijerph15040612
Chicago/Turabian StyleYu, Xiaobing, Xianrui Yu, and Yiqun Lu. 2018. "Evaluation of an Agricultural Meteorological Disaster Based on Multiple Criterion Decision Making and Evolutionary Algorithm" International Journal of Environmental Research and Public Health 15, no. 4: 612. https://doi.org/10.3390/ijerph15040612
APA StyleYu, X., Yu, X., & Lu, Y. (2018). Evaluation of an Agricultural Meteorological Disaster Based on Multiple Criterion Decision Making and Evolutionary Algorithm. International Journal of Environmental Research and Public Health, 15(4), 612. https://doi.org/10.3390/ijerph15040612