Applying Deep Neural Networks and Ensemble Machine Learning Methods to Forecast Airborne Ambrosia Pollen



Abstract
:1. Introduction
2. Materials and Methods
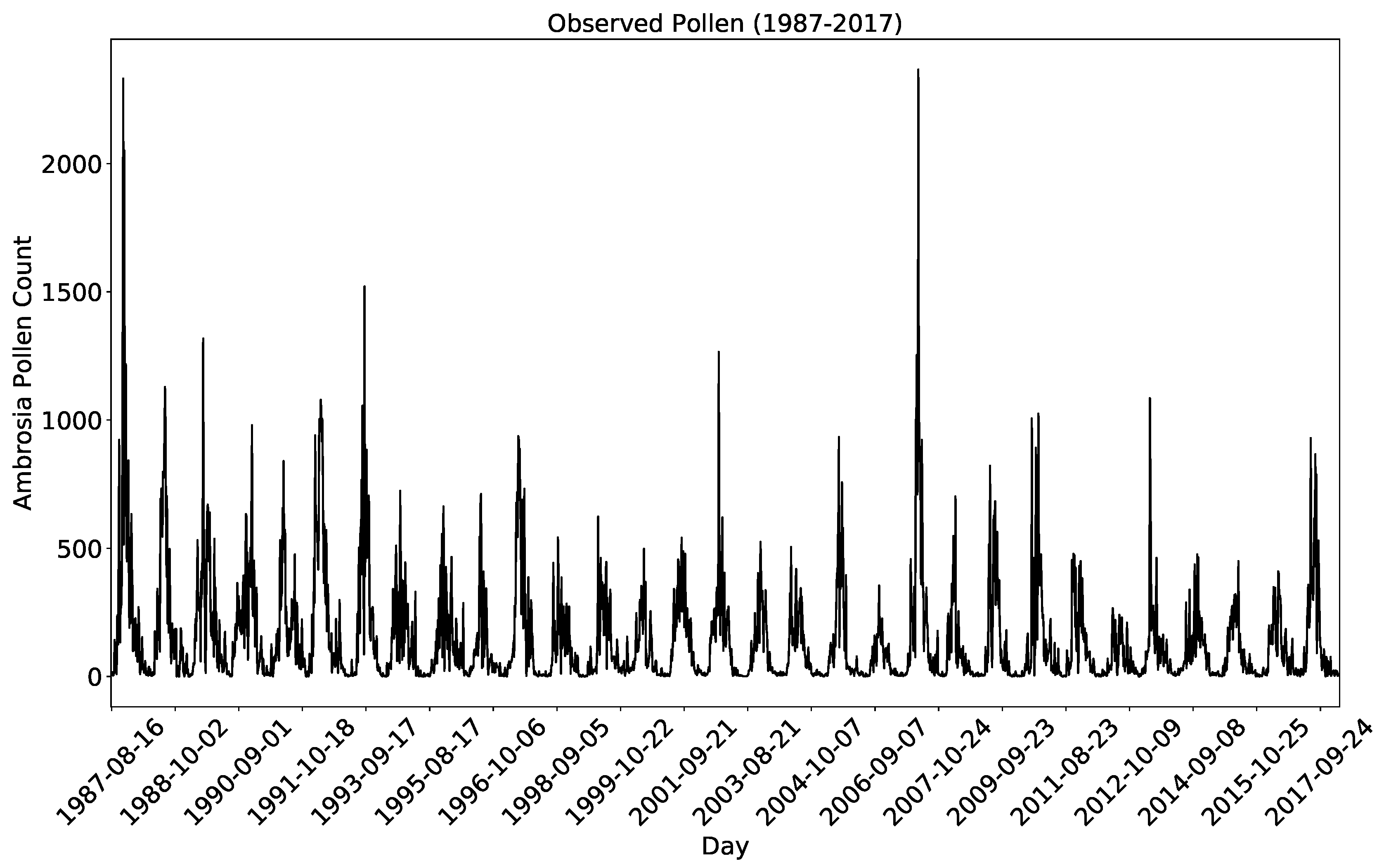
2.1. Pollen Samples
2.2. ECMWF Data Description
2.3. Machine Learning Methods
2.4. Procedure
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nowosad, J. Spatiotemporal models for predicting high pollen concentration level of Corylus, Alnus, and Betula. Int. J. Biometeorol. 2016, 60, 843–855. [Google Scholar] [CrossRef] [PubMed]
- D’amato, G.; Cecchi, L.; Bonini, S.; Nunes, C.; Annesi-Maesano, I.; Behrendt, H.; Liccardi, G.; Popov, T.; Van Cauwenberge, P. Allergenic pollen and pollen allergy in Europe. Allergy 2007, 62, 976–990. [Google Scholar] [CrossRef] [PubMed]
- Howard, L.E.; Levetin, E. Ambrosia pollen in Tulsa, Oklahoma: Aerobiology, trends, and forecasting model development. Ann. Allergy Asthma Immunol. 2014, 113, 641–646. [Google Scholar] [CrossRef] [PubMed]
- Oswalt, M.L.; Marshall, G.D. Ragweed as an example of worldwide allergen expansion. Allergy Asthma Clin. Immunol. 2008, 4, 130. [Google Scholar] [CrossRef] [PubMed]
- Lake, I.R.; Jones, N.R.; Agnew, M.; Goodess, C.M.; Giorgi, F.; Hamaoui-Laguel, L.; Semenov, M.A.; Solomon, F.; Storkey, J.; Vautard, R.; et al. Climate change and future pollen allergy in Europe. Environ. Health Perspect. 2017, 125, 385. [Google Scholar] [CrossRef] [PubMed]
- Acevedo, N.; Sánchez, J.; Zakzuk, J.; Bornacelly, A.; Quiróz, C.; Alvarez, Á.; Puello, M.; Mendoza, K.; Martínez, D.; Mercado, D.; et al. Particular characteristics of allergic symptoms in tropical environments: Follow up to 24 months in the FRAAT birth cohort study. BMC Pulm. Med. 2012, 12, 13. [Google Scholar] [CrossRef] [PubMed]
- Laaidi, M.; Laaidi, K.; Besancenot, J.P.; Thibaudon, M. Ragweed in France: An invasive plant and its allergenic pollen. Ann. Allergy Asthma Immunol. 2003, 91, 195–201. [Google Scholar] [CrossRef]
- Lewis, W.H.; Vinay, P.; Zenger, V.E. Airborne and Allergenic Pollen of North America; Johns Hopkins University Press: Baltimore, MD, USA, 1983. [Google Scholar]
- Esch, R.E.; Hartsell, C.J.; Crenshaw, R.; Jacobson, R.S. Common allergenic pollens, fungi, animals, and arthropods. Clin. Rev. Allergy Immunol. 2001, 21, 261–292. [Google Scholar] [CrossRef]
- Andrews, C.P.; Ratner, P.H.; Ehler, B.R.; Brooks, E.G.; Pollock, B.H.; Ramirez, D.A.; Jacobs, R.L. The mountain cedar model in clinical trials of seasonal allergic rhinoconjunctivitis. Ann. Allergy Asthma Immunol. 2013, 111, 9–13. [Google Scholar] [CrossRef]
- Ramirez, D.A. The natural history of mountain cedar pollinosis. J. Allergy Clin. Immunol. 1984, 73, 88–93. [Google Scholar] [CrossRef]
- Low, R.B.; Bielory, L.; Qureshi, A.I.; Dunn, V.; Stuhlmiller, D.F.; Dickey, D.A. The relation of stroke admissions to recent weather, airborne allergens, air pollution, seasons, upper respiratory infections, and asthma incidence, September 11, 2001, and day of the week. Stroke 2006, 37, 951–957. [Google Scholar] [CrossRef] [PubMed]
- Stickley, A.; Ng, C.F.S.; Konishi, S.; Koyanagi, A.; Watanabe, C. Airborne pollen and suicide mortality in Tokyo, 2001–2011. Environ. Res. 2017, 155, 134–140. [Google Scholar] [CrossRef] [PubMed]
- Hanigan, I.; Johnston, F.H. Respiratory hospital admissions were associated with ambient airborne pollen in Darwin, Australia, 2004–2005. Clin. Exp. Allergy 2007, 37, 1556–1565. [Google Scholar] [CrossRef] [PubMed]
- Bosch-Cano, F.; Bernard, N.; Sudre, B.; Gillet, F.; Thibaudon, M.; Richard, H.; Badot, P.M.; Ruffaldi, P. Human exposure to allergenic pollens: A comparison between urban and rural areas. Environ. Res. 2011, 111, 619–625. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garuma, G.F. Review of urban surface parameterizations for numerical climate models. Urban Clim. 2017, 24, 830–851. [Google Scholar] [CrossRef]
- Nicolaou, N.; Siddique, N.; Custovic, A. Allergic disease in urban and rural populations: Increasing prevalence with increasing urbanization. Allergy 2005, 60, 1357–1360. [Google Scholar] [CrossRef] [PubMed]
- Armentia, A.; Lombardero, M.; Callejo, A.; Barber, D.; Gil, F.M.; Martin-Santos, J.; Vega, J.; Arranz, M. Is Lolium pollen from an urban environment more allergenic than rural pollen? Allergol. Immunopathol. 2002, 30, 218–224. [Google Scholar] [CrossRef]
- Breton, M.C.; Garneau, M.; Fortier, I.; Guay, F.; Louis, J. Relationship between climate, pollen concentrations of Ambrosia and medical consultations for allergic rhinitis in Montreal, 1994–2002. Sci. Total Environ. 2006, 370, 39–50. [Google Scholar] [CrossRef]
- Damialis, A.; Gioulekas, D.; Lazopoulou, C.; Balafoutis, C.; Vokou, D. Transport of airborne pollen into the city of Thessaloniki: The effects of wind direction, speed and persistence. Int. J. Biometeorol. 2005, 49, 139–145. [Google Scholar] [CrossRef]
- Csépe, Z.; Makra, L.; Voukantsis, D.; Matyasovszky, I.; Tusnády, G.; Karatzas, K.; Thibaudon, M. Predicting daily ragweed pollen concentrations using Computational Intelligence techniques over two heavily polluted areas in Europe. Sci. Total Environ. 2014, 476, 542–552. [Google Scholar] [CrossRef]
- Wu, D.; Zewdie, G.K.; Liu, X.; Kneen, M.A.; Lary, D.J. Insights Into the Morphology of the East Asia PM2.5 Annual Cycle Provided by Machine Learning. Environ. Health Insights 2017, 11, 1178630217699611. [Google Scholar] [CrossRef] [PubMed]
- Lary, D.J.; Faruque, F.S.; Malakar, N.; Moore, A.; Roscoe, B.; Adams, Z.L.; Eggelston, Y. Estimating the global abundance of ground level presence of particulate matter (PM2.5). Geospat. Health 2014, 8, 611–630. [Google Scholar] [CrossRef] [PubMed]
- Debry, E.; Mallet, V. Ensemble forecasting with machine learning algorithms for ozone, nitrogen dioxide and PM10 on the Prev’Air platform. Atmos. Environ. 2014, 91, 71–84. [Google Scholar] [CrossRef]
- Castellano-Méndez, M.; Aira, M.; Iglesias, I.; Jato, V.; González-Manteiga, W. Artificial neural networks as a useful tool to predict the risk level of Betula pollen in the air. Int. J. Biometeorol. 2005, 49, 310–316. [Google Scholar] [CrossRef] [PubMed]
- Puc, M. Artificial neural network model of the relationship between Betula pollen and meteorological factors in Szczecin (Poland). Int. J. Biometeorol. 2012, 56, 395–401. [Google Scholar] [CrossRef]
- Lary, D.J.; Zewdie, G.K.; Liu, X.; Wu, D.; Levetin, E.; Allee, R.J.; Malakar, N.; Walker, A.; Mussa, H.; Mannino, A.; et al. Machine Learning Applications for Earth Observation. In Earth Observation Open Science and Innovation; Springer: Cham, Switzerland, 2018; pp. 165–218. [Google Scholar] [Green Version]
- Liu, X.; Wu, D.; Zewdie, G.K.; Wijerante, L.; Timms, C.I.; Riley, A.; Levetin, E.; Lary, D.J. Using machine learning to estimate atmospheric Ambrosia pollen concentrations in Tulsa, OK. Environ. Health Insights 2017, 11, 1178630217699399. [Google Scholar] [CrossRef] [PubMed]
- Zewdie, G.K.; Lary, D.J.; Liu, X.; Wu, D.; Levetin, E. Estimating the Daily Pollen Concentration in the Atmosphere Using Machine Learning and NEXRAD Weather Radar Data. Environ. Monit. Assess. 2019, in press. [Google Scholar]
- Zewdie, G.K.; Liu, X.; Wu, D.; Lary, D.J. Applying Machine Learning to Forecast Daily Ambrosia Pollen Using Environmental and NEXRAD radar Parameters. Environ. Monit. Assess. 2019, in press. [Google Scholar]
- Lorenzo, C.; Marco, M.; Paola, D.M.; Alfonso, C.; Marzia, O.; Simone, O. Long distance transport of ragweed pollen as a potential cause of allergy in central Italy. Ann. Allergy Asthma Immunol. 2006, 96, 86–91. [Google Scholar] [CrossRef]
- Kiss, L.; Béres, I. Anthropogenic factors behind the recent population expansion of common ragweed (Ambrosia artemisiifolia L.) in Eastern Europe: Is there a correlation with political transitions? J. Biogeogr. 2006, 33, 2156–2157. [Google Scholar] [CrossRef]
- Bogawski, P.; Jenerowicz, D.; Czarnecka-Operacz, M.; Šikoparija, B.; Skjøth, C.; Smith, M. Mesoscale atmospheric transport of ragweed pollen allergens from infected to uninfected areas. Int. J. Biometeorol. 2016, 60, 1493–1500. [Google Scholar] [Green Version]
- Smith, M.; Emberlin, J.; Kress, A. Examining high magnitude grass pollen episodes at Worcester, United Kingdom, using back-trajectory analysis. Aerobiologia 2005, 21, 85–94. [Google Scholar] [CrossRef]
- Šauliene, I.; Veriankaite, L. Application of backward air mass trajectory analysis in evaluating airborne pollen dispersion. J. Environ. Eng. Landsc. Manag. 2006, 14, 113–120. [Google Scholar] [CrossRef]
- Kasprzyk, I. Non-native Ambrosia Pollen Atmos. Rzesz. (SE Poland); Eval. Eff. Weather Cond. Dly. Conc. Start. Dates Pollen Seas. Int. J. Biometeorol. 2008, 52, 341–351. [Google Scholar] [CrossRef] [PubMed]
- Hirst, J. An automatic volumetric spore trap. Ann. Appl. Biol. 1952, 39, 257–265. [Google Scholar] [CrossRef]
- Dee, D.P.; Uppala, S.; Simmons, A.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.; Balsamo, G.; Bauer, d.P.; et al. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Coakley, J. Reflectance and albedo, surface. In Encyclopedia of the Atmosphere; Academic Press: Cambrigde, MA, USA, 2003; pp. 1914–1923. [Google Scholar]
- Ball, N.M.; Brunner, R.J. Data mining and machine learning in astronomy. Int. J. Mod. Phys. D 2010, 19, 1049–1106. [Google Scholar] [CrossRef]
- Guzella, T.S.; Caminhas, W.M. A review of machine learning approaches to spam filtering. Expert Syst. Appl. 2009, 36, 10206–10222. [Google Scholar] [CrossRef]
- Chollet, F. Keras: Deep Learning Library for Theano and Tensorflow. 2015. Available online: https://keras.io/k (accessed on 10 March 2019).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the OSDI’16: 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Stein, A.; Draxler, R.R.; Rolph, G.D.; Stunder, B.J.; Cohen, M.; Ngan, F. NOAA’s HYSPLIT atmospheric transport and dispersion modeling system. Bull. Am. Meteorol. Soc. 2015, 96, 2059–2077. [Google Scholar] [CrossRef]
- Pasken, R.; Pietrowicz, J.A. Using dispersion and mesoscale meteorological models to forecast pollen concentrations. Atmos. Environ. 2005, 39, 7689–7701. [Google Scholar] [CrossRef]
- Hamaoui-Laguel, L.; Vautard, R.; Liu, L.; Solmon, F.; Viovy, N.; Khvorostyanov, D.; Essl, F.; Chuine, I.; Colette, A.; Semenov, M.A.; et al. Effects of climate change and seed dispersal on airborne ragweed pollen loads in Europe. Nat. Clim. Chang. 2015, 5, 766. [Google Scholar] [CrossRef]
- Rodriguez-Rajo, F.J.; Dopazo, A.; Jato, V. Environmental factors affecting the start of pollen season and concentrations of airborne Alnus pollen in two localities of Galicia (NW Spain). AAEM 2004, 11, 35–44. [Google Scholar] [PubMed]
- Pérez, C.F.; Gassmann, M.I.; Covi, M. An evaluation of the airborne pollen–precipitation relationship with the superposed epoch method. Aerobiologia 2009, 25, 313–320. [Google Scholar] [CrossRef]
- Nowosad, J.; Stach, A.; Kasprzyk, I.; Chłopek, K.; Dąbrowska-Zapart, K.; Grewling, Ł.; Latałowa, M.; Pędziszewska, A.; Majkowska-Wojciechowska, B.; Myszkowska, D.; et al. Statistical techniques for modeling of Corylus, Alnus, and Betula pollen concentration in the air. Aerobiologia 2018, 34, 301–313. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Unit | Parameter Name | Unit |
|---|---|---|---|
| 2 m temperature | K | 2 m dew point temperature | K |
| Vol. soil water layer 1 | m m | Soil temperature level 2 | K |
| Vol. soil water layer 2 | m m | Soil temperature level 3 | K |
| Surface air pressure | Pa | Low cloud cover | 0–1 |
| Total column water | kg m | Medium cloud cover | 0–1 |
| Total column water vapour | kg m | High cloud cover | 0–1 |
| Surface temperature | K | Skin reservoir content | m |
| Mean sea level Pressure | Pa | Total column ozone | kg m |
| Total Cloud cover | 0–1 | Skin temperature | K |
| 10 m U wind component | ms | Soil temperature level 4 | K |
| 10 m V wind component | ms | Surface Albedo | 0–1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zewdie, G.K.; Lary, D.J.; Levetin, E.; Garuma, G.F. Applying Deep Neural Networks and Ensemble Machine Learning Methods to Forecast Airborne Ambrosia Pollen. Int. J. Environ. Res. Public Health 2019, 16, 1992. https://doi.org/10.3390/ijerph16111992
Zewdie GK, Lary DJ, Levetin E, Garuma GF. Applying Deep Neural Networks and Ensemble Machine Learning Methods to Forecast Airborne Ambrosia Pollen. International Journal of Environmental Research and Public Health. 2019; 16(11):1992. https://doi.org/10.3390/ijerph16111992
Chicago/Turabian StyleZewdie, Gebreab K., David J. Lary, Estelle Levetin, and Gemechu F. Garuma. 2019. "Applying Deep Neural Networks and Ensemble Machine Learning Methods to Forecast Airborne Ambrosia Pollen" International Journal of Environmental Research and Public Health 16, no. 11: 1992. https://doi.org/10.3390/ijerph16111992
APA StyleZewdie, G. K., Lary, D. J., Levetin, E., & Garuma, G. F. (2019). Applying Deep Neural Networks and Ensemble Machine Learning Methods to Forecast Airborne Ambrosia Pollen. International Journal of Environmental Research and Public Health, 16(11), 1992. https://doi.org/10.3390/ijerph16111992