Assessing the Retail Food Environment in Madrid: An Evaluation of Administrative Data against Ground Truthing

 ,
, 
 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design and Sampling Approach
2.2. Ground Truthing
2.3. Secondary Administrative Dataset
2.4. Area-Level Socioeconomic Status and Demographic Data
2.5. Outlet Matching Process
2.6. Statistical Analysis
3. Results
3.1. Completeness
3.2. Accuracy
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Glanz, K.; Sallis, J.F.; Saelens, B.E.; Frank, L.D. Healthy nutrition environments: Concepts and measures. Am. J. Heal. Promot. 2005, 19, 330–333. [Google Scholar]
- Story, M.; Kaphingst, K.M.; Robinson-O’Brien, R.; Glanz, K. Creating healthy food and eating evironments: Policy and environmental approaches. Annu. Rev. Public Health 2008, 29, 253–272. [Google Scholar] [PubMed]
- Bilal, U.; Jones-Smith, J.; Diez, J.; Lawrence, R.S.; Celentano, D.D.; Franco, M. Neighborhood social and economic change and retail food environment change in Madrid (Spain): The heart healthy hoods study. Health Place 2018, 51, 107–117. [Google Scholar] [PubMed]
- Hawkes, C.; Smith, T.G.; Jewell, J.; Wardle, J.; Hammond, R.A.; Friel, S.; Thow, A.M.; Kain, J. Smart food policies for obesity prevention. Lancet 2015, 385, 2410–2421. [Google Scholar] [PubMed]
- Caspi, C.E.; Sorensen, G.; Subramanian, S.V.; Kawachi, I. The local food environment and diet: A systematic review. Health Place 2012, 18, 1172–1187. [Google Scholar] [PubMed] [Green Version]
- Cobb, L.K.; Appel, L.J.; Franco, M.; Jones-Smith, J.C.; Nur, A.; Anderson, C.A.M. The relationship of the local food environment with obesity: A systematic review of methods, study quality, and results. Obesity 2015, 23, 1331–1344. [Google Scholar] [PubMed]
- Williams, J.; Scarborough, P.; Matthews, A.; Cowburn, G.; Foster, C.; Roberts, N.; Rayner, M. A systematic review of the influence of the retail food environment around schools on obesity-related outcomes. Obes. Rev. 2014, 15, 359–374. [Google Scholar] [PubMed]
- Wilkins, E.L.; Morris, M.A.; Radley, D.; Griffiths, C. Using Geographic Information Systems to measure retail food environments: Discussion of methodological considerations and a proposed reporting checklist (Geo-FERN). Heal. Place 2017, 44, 110–117. [Google Scholar]
- Glanz, K.; Johnson, L.; Yaroch, A.L.; Phillips, M.; Ayala, G.X.; Davis, E.L. Measures of retail food store environments and sales: Review and implications for healthy eating initiatives. J. Nutr. Educ. Behav. 2016, 48, 280–288. [Google Scholar]
- Lebel, A.; Daepp, M.I.G.; Block, J.P.; Walker, R.; Lalonde, B.; Kestens, Y.; Subramanian, S.V. Quantifying the foodscape: A systematic review and meta-analysis of the validity of commercially available business data. PLoS ONE 2017, 12, 1–17. [Google Scholar]
- Lytle, L.A.; Sokol, R.L. Measures of the food environment: A systematic review of the field, 2007–2015. Heal. Place 2017, 44, 18–34. [Google Scholar]
- Wilkins, E.; Radley, D.; Morris, M.; Hobbs, M.; Christensen, A.; Marwa, W.L.; Morrin, A.; Griffiths, C. A systematic review employing the GeoFERN framework to examine methods, reporting quality and associations between the retail food environment and obesity. Health Place 2019, 57, 186–199. [Google Scholar] [PubMed]
- Paquet, C.; Daniel, M.; Kestens, Y.; Léger, K.; Gauvin, L. Field validation of listings of food stores and commercial physical activity establishments from secondary data. Int. J. Behav. Nutr. Phys. Act. 2008, 5, 5–12. [Google Scholar]
- Glanz, K.; Handy, S.L.; Henderson, K.E.; Slater, S.J.; Davis, E.L.; Powell, L.M. Built environment assessment: Multidisciplinary perspectives. Popul. Health 2016, 2, 24–31. [Google Scholar] [Green Version]
- Fleischhacker, S.E.; Evenson, K.R.; Sharkey, J.; Pitts, S.B.J.; Rodriguez, D.A. Validity of secondary retail food outlet data: A systematic review. Am. J. Prev. Med. 2013, 45, 462–473. [Google Scholar]
- Lake, A.A.; Burgoine, T.; Greenhalgh, F.; Stamp, E.; Tyrrell, R. The foodscape: Classification and field validation of secondary data sources. Health Place 2010, 16, 666–673. [Google Scholar] [PubMed] [Green Version]
- Liese, A.D.; Colabianchi, N.; Lamichhane, A.P.; Barnes, T.L.; Hibbert, J.D.; Porter, D.E.; Nichols, M.D.; Lawson, A.B. Validation of 3 food outlet databases: Completeness and geospatial accuracy in rural and urban food environments. Am. J. Epidemiol. 2010, 172, 1324–1333. [Google Scholar] [PubMed]
- Powell, L.M.; Han, E.; Zenk, S.N.; Khan, T.; Quinn, C.M.; Gibbs, K.P.; Pugach, O.; Barker, D.C.; Resnick, E.A.; Myllyluoma, J.; et al. Field validation of secondary commercial data sources on the retail food outlet environment in the US. Health Place 2011, 17, 1122–1131. [Google Scholar]
- Lo, B.K.; Minaker, L.M.; Mah, C.L.; Cook, B. Development and testing of the Toronto nutrition environment measures survey-store. J. Nutr. Educ. Behav. 2016, 48, 723–729. [Google Scholar]
- Minaker, L.M.; Shuh, A.; Olstad, D.L.; Engler-Stringer, R.; Black, J.L.; Mah, C.L. Retail food environments research in Canada: A scoping review. Can. J. Public Health 2016, 107, 4–13. [Google Scholar]
- Seliske, L.; Pickett, W.; Bates, R.; Janssen, I. Field validation of food service listings: A comparison of commercial and online Geographic Information System databases. Int. J. Environ. Res. Public Health 2012, 9, 2601–2607. [Google Scholar] [PubMed]
- Murphy, M.; Badland, H.; Jordan, H.; Koohsari, M.; Giles-Corti, B. Local food environments, suburban development, and BMI: A mixed methods study. Int. J. Environ. Res. Public Health 2018, 15, 1392–1411. [Google Scholar]
- Feng, X.; Astell-Burt, T.; Badland, H.; Mavoa, S.; Giles-Corti, B. Modest ratios of fast food outlets to supermarkets and green grocers are associated with higher body mass index: Longitudinal analysis of a sample of 15,229 Australians aged 45 years and older in the Australian National Liveability Study. Health Place 2018, 49, 101–110. [Google Scholar] [PubMed]
- Diez, J.; Bilal, U.; Cebrecos, A.; Buczynski, A.; Lawrence, R.S.; Glass, T.; Escobar, F.; Gittelsohn, J.; Franco, M. Understanding differences in the local food environment across countries: A case study in Madrid (Spain) and Baltimore (USA). Prev. Med. 2016, 89, 237–244. [Google Scholar] [PubMed]
- Flavián, C.; Haberberg, A.; Polo, Y. Food retailing strategies in the European union. A comparative analysis in the UK and Spain. J. Retail. Consum. Serv. 2002, 9, 125–138. [Google Scholar]
- Díez, J.; Bilal, U.; Franco, M. Unique features of the Mediterranean food environment: Implications for the prevention of chronic diseases Rh: Mediterranean food environments. Eur. J. Clin. Nutr. 2018, 72, 71–75. [Google Scholar]
- Hees, S.; Horstman, K.; Jansen, M.; Ruwaard, D. Photovoicing the neighbourhood: Understanding the situated meaning of intangible places for ageing-in-place. Health Place 2017, 48, 11–19. [Google Scholar] [PubMed]
- Pinho, M.; Mackenbach, J.; Oppert, J.-M.; Charreire, H.; Bárdos, H.; Rutter, H.; Compernolle, S.; Beulens, J.; Brug, J.; Lakerveld, J. Exploring absolute and relative measures of exposure to food environments in relation to dietary patterns among European adults. Public Health Nutr. 2019, 22, 1037–1047. [Google Scholar] [PubMed]
- Svastisalee, C.M.; Nordahl, H.; Glümer, C.; Holstein, B.E.; Powell, L.M.; Due, P. Supermarket and fast-food outlet exposure in Copenhagen: Associations with socio-economic and demographic characteristics. Public Health Nutr. 2011, 14, 1618–1626. [Google Scholar] [PubMed]
- Achón, M.; Serrano, M.; García-González, Á.; Alonso-Aperte, E.; Varela-Moreiras, G. Present food shopping habits in the Spanish adult population: A cross-sectional study. Nutrients 2017, 9, 508–522. [Google Scholar]
- Odoms-Young, A.M.; Zenk, S.; Mason, M. Measuring food availability and access in African-American communities. Am. J. Prev. Med. 2009, 36, 145–150. [Google Scholar]
- Rummo, P.E.; Gordon-Larsen, P.; Albrecht, S.S. Field validation of food outlet databases: The Latino food environment in North Carolina, USA. Public Health Nutr. 2015, 18, 977–982. [Google Scholar] [PubMed]
- Gomez-Lopez, I.N.; Clarke, P.; Hill, A.B.; Romero, D.M.; Goodspeed, R.; Berrocal, V.J.; Vinod Vydiswaran, V.G.; Veinot, T.C. Using social media to identify sources of healthy food in urban neighborhoods. J. Urban Heal. 2017, 94, 429–436. [Google Scholar]
- Sharkey, J.R.; Horel, S. Neighborhood socioeconomic deprivation and minority composition are associated with better potential spatial access to the ground-truthed food environment in a large rural area. J. Nutr. 2008, 138, 620–627. [Google Scholar] [PubMed]
- Mendez, D.D.; Kim, K.H.; Hardaway, C.R.; Fabio, A. Neighborhood racial and socioeconomic disparities in the food and alcohol environment: Are there differences by commercial data sources? J. Racial Ethn. Heal. Disparities 2016, 3, 108–116. [Google Scholar]
- Carré, H. Statistical Classification of Economic Activities in the European Community; Publications Office of the European Union: Luxembourg, 2008. [Google Scholar]
- Bilal, U.; Díez, J.; Alfayate, S.; Gullón, P.; Del Cura, I.; Escobar, F.; Sandín, M.; Franco, M. Population cardiovascular health and urban environments: The heart healthy hoods exploratory study in Madrid, Spain. BMC Med. Res. Methodol. 2016, 16, 104–116. [Google Scholar]
- Cebrecos, A.; Domínguez-Berjón, M.F.; Duque, I.; Franco, M.; Escobar, F. Geographic and statistic stability of deprivation aggregated measures at different spatial units in health research. Appl. Geogr. 2018, 95, 9–18. [Google Scholar]
- Sureda, X.; Bilal, U.; Fernández, E.; Valiente, R.; Escobar, F.J.; Navas-Acien, A.; Franco, M. Second-hand smoke exposure in outdoor hospitality venues: Smoking visibility and assessment of airborne markers. Environ. Res. 2018, 165, 220–227. [Google Scholar]
- Glanz, K.; Sallis, J.F.; Saelens, B.E.; Frank, L.D. Nutrition Environment Measures Survey in Stores (NEMS-S). Development and Evaluation. Am. J. Prev. Med. 2007, 32, 282–289. [Google Scholar]
- Honeycutt, S.; Davis, E.; Clawson, M.; Glanz, K. Training for and dissemination of the Nutrition Environment Measures Surveys (NEMS). Prev. Chronic Dis. 2010, 7, 126–136. [Google Scholar]
- Open Data Kit. Available online: https://opendatakit.org/ (accessed on 26 July 2019).
- Oliver, M.N.; Matthews, K.A.; Siadaty, M.; Hauck, F.R.; Pickle, L.W. Geographic bias related to geocoding in epidemiologic studies. Int. J. Health Geogr. 2005, 4, 29–37. [Google Scholar] [PubMed]
- Gullón, P.; Bilal, U.; Cebrecos, A.; Badland, H.M.; Galán, I.; Franco, M. Intersection of neighborhood dynamics and socioeconomic status in small-area walkability: The heart healthy hoods project. Int. J. Health Geogr. 2017, 16, 21–30. [Google Scholar] [PubMed]
- Burgoine, T.; Harrison, F. Comparing the accuracy of two secondary food environment data sources in the UK across socio-economic and urban/rural divides. Int. J. Health Geogr. 2013, 12, 2–10. [Google Scholar] [PubMed]
- Caspi, C.E.; Friebur, R. Modified ground-truthing: An accurate and cost-effective food environment validation method for town and rural areas. Int. J. Behav. Nutr. Phys. Act. 2016, 13, 37–45. [Google Scholar] [PubMed]
- Wilkins, E.L.; Radley, D.; Morris, M.A.; Griffiths, C. Examining the validity and utility of two secondary sources of food environment data against street audits in England. Nutr. J. 2017, 16, 82–95. [Google Scholar] [PubMed]
- Daepp, M.I.G.; Black, J. Assessing the validity of commercial and municipal food environment data sets in Vancouver, Canada. Public Health Nutr. 2017, 20, 2649–2659. [Google Scholar] [PubMed] [Green Version]
- Black, C.; Moon, G.; Baird, J. Dietary inequalities: What is the evidence for the effect of the neighbourhood food environment? Heal. Place 2014, 27, 229–242. [Google Scholar]
- Charreire, H.; Casey, R.; Salze, P.; Simon, C.; Chaix, B.; Banos, A.; Badariotti, D.; Weber, C.; Oppert, J.M. Measuring the food environment using geographical information systems: A methodological review. Public Health Nutr. 2010, 13, 1773–1785. [Google Scholar]
- Toft, U.; Erbs-Maibing, P.; Glümer, C. Identifying fast-food restaurants using a central register as a measure of the food environment. Scand. J. Public Health 2011, 39, 864–869. [Google Scholar]
- Svastisalee, C.M.; Holstein, B.E.; Due, P. Validation of presence of supermarkets and fast-food outlets in Copenhagen: Case study comparison of multiple sources of secondary data. Public Health Nutr. 2012, 15, 1228–1231. [Google Scholar]
- Díez, J.; Cebrecos, A.; Rapela, A.; Borrell, L.N.; Bilal, U.; Franco, M. Socioeconomic inequalities in the retail food environment around schools in a southern European context. Nutrients 2019, 11, 1511–1525. [Google Scholar]
- Clary, C.M.; Kestens, Y. Field validation of secondary data sources: A novel measure of representativity applied to a Canadian food outlet database. Int. J. Behav. Nutr. Phys. Act. 2013, 10, 77–86. [Google Scholar] [PubMed]
- Rossen, L.M.; Pollack, K.M.; Curriero, F.C. Verification of retail food outlet location data from a local health department using ground truthing and remote-sensing technology: Assessing differences by neighborhood characteristics. Health Place 2012, 18, 956–962. [Google Scholar] [PubMed]



{kind=link}
{kind=link}
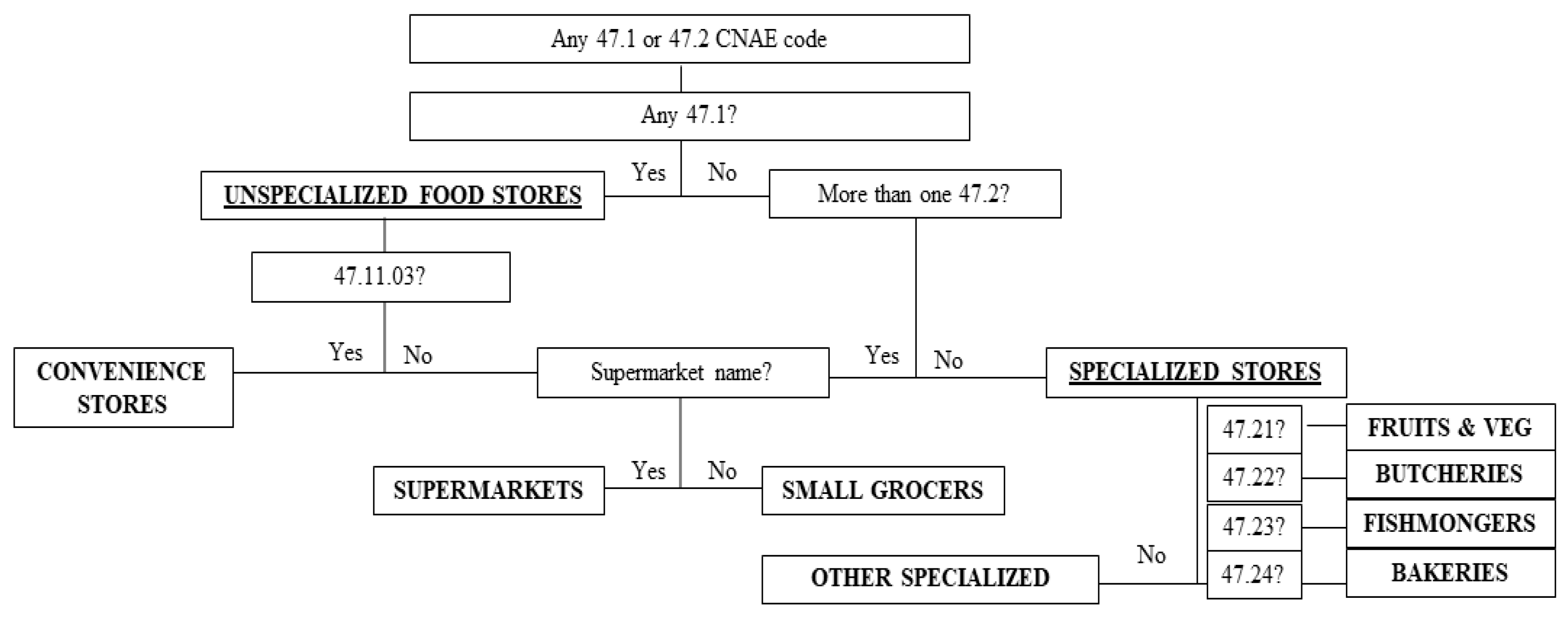
| Food Outlet Category | Characteristics |
|---|---|
| Unspecialized food outlets, including outlets primarily engaged in retailing a general line of foods | |
| Supermarkets | Full-line, self-service food outlets that allow the supply of a wide variety of products of daily consumption, food and non-food, without the intermediation of a person employed to serve the buyers (unless requested). This category includes both large chain, small and discount supermarkets. |
| Small grocers | Neighborhood stores, self-service outlets selling a variety of products and which are neither a specialized food store, a convenience store, nor a supermarket. |
| Convenience food stores | Outlets with a diversified product offering including food, drinks, snacks, or magazines. They usually open more than 18 hours a day, have two or fewer cash registers, and are often associated (in Spain) with gas stations. |
| Specialized food outlets, including outlets primarily engaged in retailing specialized lines of food | |
| Fruit & Vegetables stores | Specialized food outlet with retail sale of fresh, prepared or preserved fruits and vegetables. |
| Butcheries | Specialized food outlet with retail sale of fresh, frozen, or cured meat and meat products, including poultry and the retail sale of dairy products and eggs |
| Fishmongers | Specialized food outlet with retail sale of fresh, frozen, or cured fish and other seafood products |
| Bakeries | Specialized food outlet with retail sale of bread, cakes, flour confectionery and sugar confectionery |
| Other specialized food stores | Specialized food outlet that does not fit into any other category (e.g., gourmet food stores) |
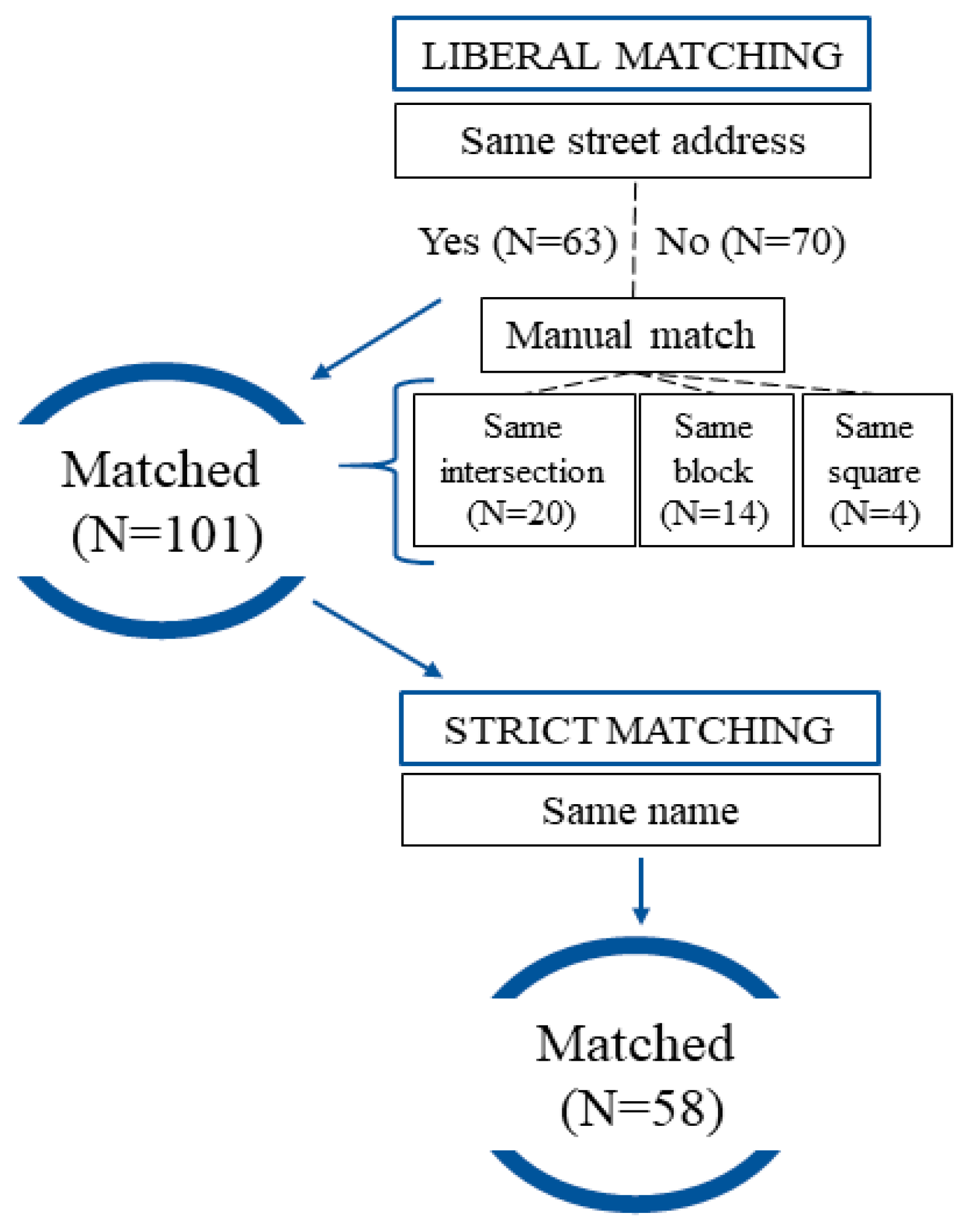
| Measure | Liberal Matching (n = 101) | Strict Matching (n = 58) | ||
|---|---|---|---|---|
| Est. 1 | 95% CI 2 | Est. 1 | 95% CI 2 | |
| Sensitivity | 0.95 | [0.89, 0.98] | 0.55 | [0.44, 0.64] |
| Positive Predictive Value | 0.79 | [0.70, 0.85] | 0.45 | [0.37, 0.54] |
| Area-Level Characteristic | Liberal Matching (n = 101) | Strict Matching (n = 58) | ||
|---|---|---|---|---|
| Sens. 1 | PPV 2 | Sens. 1 | PPV 2 | |
| Socioeconomic status | ||||
| Low | 0.93 [0.86, 0.99] | 0.92 [0.83, 1.00] | 0.44 [0.26, 0.63] | 0.44 [0.25, 0.63] |
| Middle | 0.98 [0.90, 1.00] | 0.63 [0.49, 0.77] | 0.69 [0.40, 0.98] | 0.69 [0.40, 0.98] |
| High | 0.98 [0.91, 1.00] | 0.70 [0.62, 0.78] | 0.78 [0.57, 0.99] | 0.78 [0.57, 0.99] |
| p = 0.64 3 | p = 0.04 3 | p = 0.09 3 | p = 0.09 3 | |
| Population density (103 residents/km2) | ||||
| Low | 0.97 [0.92, 1.00] | 0.79 [0.70, 0.88] | 0.71 [0.56, 0.86] | 0.71 [0.56, 0.86] |
| Middle | 0.91 [0.83, 0.99] | 0.78 [0.61, 0.95] | 0.35 [0.24, 0.49] | 0.37 [0.24, 0.49] |
| High | 0.95 [0.89, 1.00] | 0.78 [0.64, 0.92] | 0.51 [0.33, 0.69] | 0.51 [0.33, 0.69] |
| p = 0.41 3 | p = 0.99 3 | p = 0.008 3 | p = 0.008 3 | |
| Measure | Liberal Matching (n = 101) | Strict Matching (n = 58) | ||
|---|---|---|---|---|
| Est. 1 | 95% CI 2 | Est. 1 | 95% CI 2 | |
| Percent Agreement | 0.71 | [0.62, 0.80] | 0.77 | [0.66, 0.88] |
| Cohen’s Kappa | 0.62 | [0.57, 0.66] | 0.71 | [0.56, 0.85] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Díez, J.; Cebrecos, A.; Galán, I.; Pérez-Freixo, H.; Franco, M.; Bilal, U. Assessing the Retail Food Environment in Madrid: An Evaluation of Administrative Data against Ground Truthing. Int. J. Environ. Res. Public Health 2019, 16, 3538. https://doi.org/10.3390/ijerph16193538
Díez J, Cebrecos A, Galán I, Pérez-Freixo H, Franco M, Bilal U. Assessing the Retail Food Environment in Madrid: An Evaluation of Administrative Data against Ground Truthing. International Journal of Environmental Research and Public Health. 2019; 16(19):3538. https://doi.org/10.3390/ijerph16193538
Chicago/Turabian StyleDíez, Julia, Alba Cebrecos, Iñaki Galán, Hugo Pérez-Freixo, Manuel Franco, and Usama Bilal. 2019. "Assessing the Retail Food Environment in Madrid: An Evaluation of Administrative Data against Ground Truthing" International Journal of Environmental Research and Public Health 16, no. 19: 3538. https://doi.org/10.3390/ijerph16193538
APA StyleDíez, J., Cebrecos, A., Galán, I., Pérez-Freixo, H., Franco, M., & Bilal, U. (2019). Assessing the Retail Food Environment in Madrid: An Evaluation of Administrative Data against Ground Truthing. International Journal of Environmental Research and Public Health, 16(19), 3538. https://doi.org/10.3390/ijerph16193538