Bayesian Spatial Joint Model for Disease Mapping of Zero-Inflated Data with R-INLA: A Simulation Study and an Application to Male Breast Cancer in Iran

Abstract
:1. Introduction
2. Materials and Methods
2.1. The Spatial Models
2.1.1. BYM Model
2.1.2. BYM2 Model
2.2. Joint Model
2.2.1. Zero-Inflated Poisson Model Type1
2.2.2. Zero-Inflated Poisson Model Type0
> formula <- Y ~ 1 + mu.z + mu.o + f(idx1,model = "bym2", graph=g, scale.model = TRUE, constr = TRUE, hyper=list(phi = list(prior = "pc", param = c(0.5, 2/3), initial = 3), prec = list(prior = "pc.prec", param = c(1, 0.01), initial = 1.5))) + f(idx2, copy=’idx1’, fixed=FALSE) > r.bym2 <- inla(formula, family=c(’binomial’, ’poisson’), data= Diseasedata, E=E, verbose=F, control.predictor=list(compute=TRUE, link=fam), control.compute=list(dic=TRUE, cpo=TRUE)) |
3. Simulation Study
4. Case Study: Male Breast Cancer in Iran
5. Results
5.1. The Simulation Study
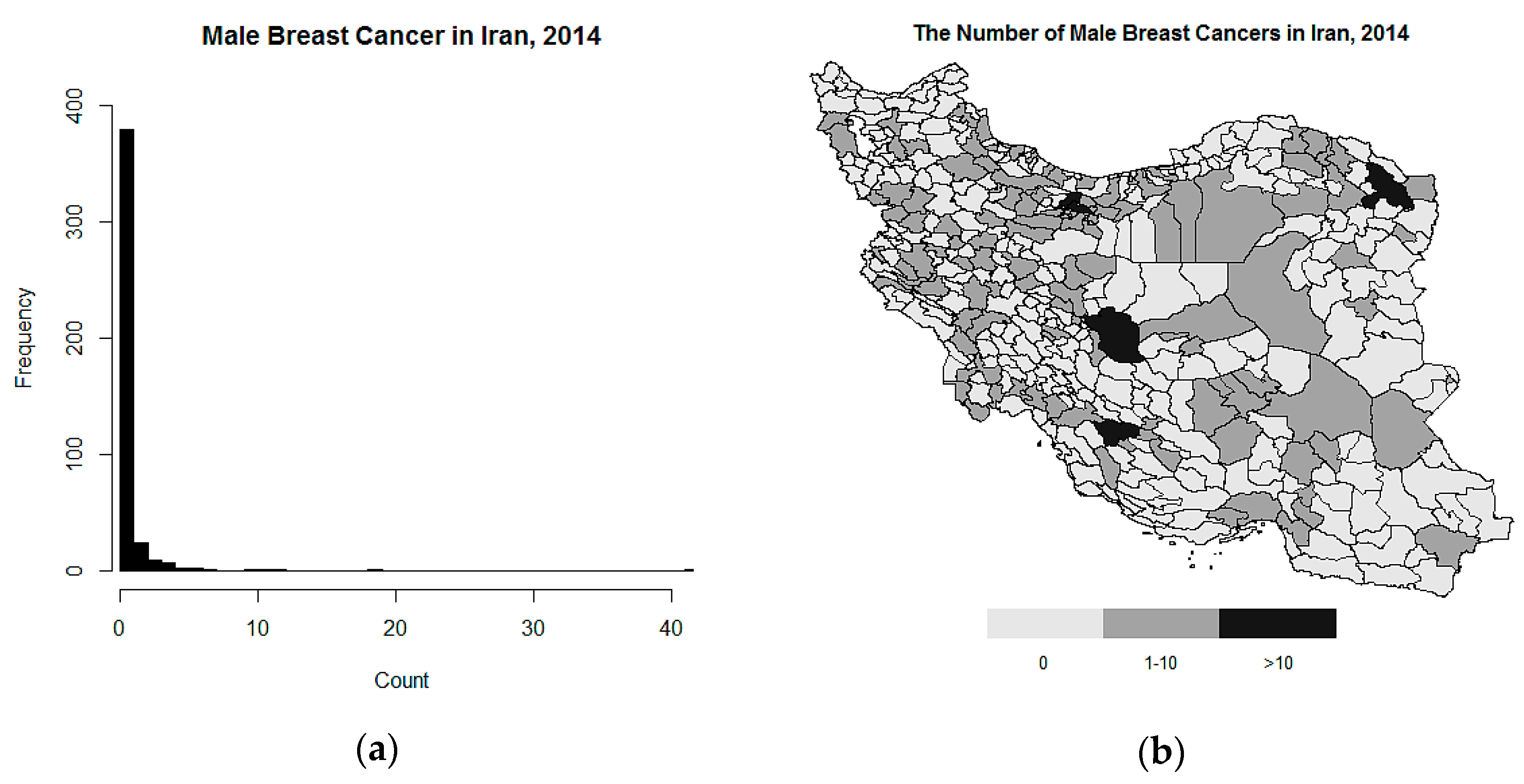
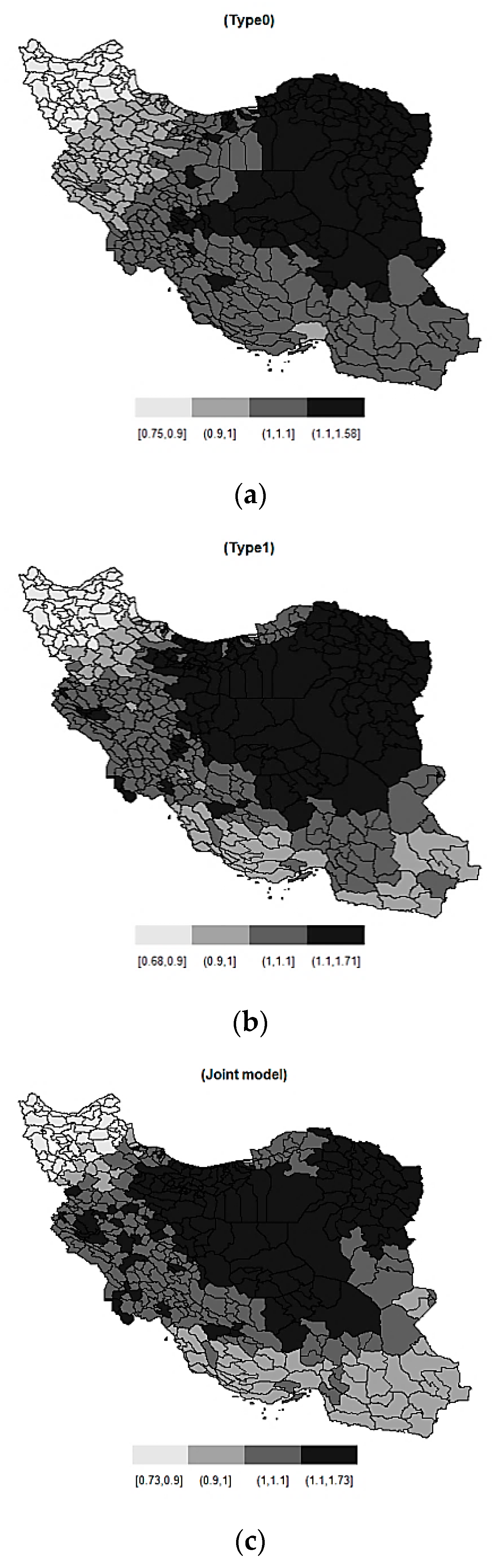
5.2. Analysis of Male Breast Cancer in Iran
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Blangiardo, M.; Cameletti, M. Spatial and Spatio-Temporal Bayesian Models with R-INLA; John Wiley & Sons: Chichester, West Sussex, UK, 2015. [Google Scholar]
- Ebrahimipour, M.; Budke, C.M.; Najjari, M.; Cassini, R.; Asmarian, N. Bayesian spatial analysis of the surgical incidence rate of human cystic echinococcosis in north-eastern Iran. Acta Trop. 2016, 163, 80–86. [Google Scholar] [CrossRef]
- Sharafi, Z.; Asmarian, N.; Hoorang, S.; Mousavi, A. Bayesian spatio-temporal analysis of stomach cancer incidence in Iran, 2003–2010. Stoch. Environ. Res. Risk Assess. 2018, 32, 2943–2950. [Google Scholar] [CrossRef]
- Martino, S.; Riebler, A. Integrated Nested Laplace Approximations (INLA). arXiv 2019, arXiv:1907.01248. [Google Scholar]
- Rue, H.; Martino, S.; Chopin, N. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2009, 71, 319–392. [Google Scholar] [CrossRef]
- Filippone, M.; Zhong, M.; Girolami, M. A comparative evaluation of stochastic-based inference methods for Gaussian process models. Mach. Learn. 2013, 93, 93–114. [Google Scholar] [CrossRef]
- Carroll, R.; Lawson, A.; Faes, C.; Kirby, R.; Aregay, M.; Watjou, K. Comparing INLA and OpenBUGS for hierarchical Poisson modeling in disease mapping. Spat. Spatio Temporal Epidemiol. 2015, 14, 45–54. [Google Scholar] [CrossRef] [PubMed]
- Simpson, D.; Rue, H.; Riebler, A.; Martins, T.G.; Sørbye, S.H. Penalising model component complexity: A principled, practical approach to constructing priors. Stat. Sci. 2017, 32, 1–28. [Google Scholar] [CrossRef]
- Winkelmann, R. Econometric Analysis of Count Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Agarwal, D.K.; Gelfand, A.E.; Citron-Pousty, S. Zero-inflated models with application to spatial count data. Environ. Ecol. Stat. 2002, 9, 341–355. [Google Scholar] [CrossRef]
- Gschlößl, S.; Czado, C. Modelling count data with overdispersion and spatial effects. Stat. Pap. 2008, 49, 531. [Google Scholar] [CrossRef]
- Arab, A. Spatial and spatio-temporal models for modeling epidemiological data with excess zeros. Int. J. Environ. Res. Public Health 2015, 12, 10536–10548. [Google Scholar] [CrossRef]
- Vergne, T.; Paul, M.C.; Chaengprachak, W.; Durand, B.; Gilbert, M.; Dufour, B.; Roger, F.; Kasemsuwan, S.; Grosbois, V. Zero-inflated models for identifying disease risk factors when case detection is imperfect: Application to highly pathogenic avian influenza H5N1 in Thailand. Prev. Vet. Med. 2014, 114, 28–36. [Google Scholar] [CrossRef] [PubMed]
- Zhu, H.; DeSantis, S.M.; Luo, S. Joint modeling of longitudinal zero-inflated count and time-to-event data: A Bayesian perspective. Stat. Methods Med. Res. 2018, 27, 1258–1270. [Google Scholar] [CrossRef] [PubMed]
- Illian, J.B.; Martino, S.; Sørbye, S.H.; Gallego-Fernández, J.B.; Zunzunegui, M.; Esquivias, M.P.; Travis, J.M. Fitting complex ecological point process models with integrated nested Laplace approximation. Methods Ecol. Evol. 2013, 4, 305–315. [Google Scholar] [CrossRef]
- Spiegelhalter, D.; Best, N.G.; Carlin, B.P.; van der Linde, A. Bayesian measures of model complexity and fit. Qual. Control Appl. Stat. 2003, 48, 431–432. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Besag, J.; York, J.; Mollié, A. Bayesian image restoration, with two applications in spatial statistics. Ann. Inst. Stat. Math. 1991, 43, 1–20. [Google Scholar] [CrossRef]
- Dean, C.; Ugarte, M.; Militino, A. Detecting interaction between random region and fixed age effects in disease mapping. Biometrics 2001, 57, 197–202. [Google Scholar] [CrossRef]
- Riebler, A.; Sørbye, S.H.; Simpson, D.; Rue, H. An intuitive Bayesian spatial model for disease mapping that accounts for scaling. Stat. Methods Med. Res. 2016, 25, 1145–1165. [Google Scholar] [CrossRef]
- Martynowicz, H.; Medraś, M.; Andrzejak, R. Occupational risk factors and male breast cancer. Med. Pracy 2005, 56, 405–410. [Google Scholar]
- Altman, A.M.; Kizy, S.; Yuan, J.; Denbo, J.W.; Jensen, E.H.; Hui, J.Y.; Tuttle, T.M.; Marmor, S. Distribution of 21-gene recurrence scores in male breast cancer in the United States. Ann. Surg. Oncol. 2018, 25, 2296–2302. [Google Scholar] [CrossRef]
- Siegel, R.; Naishadham, D.; Jemal, A. Cancer statistics for hispanics/latinos. 2012. CA Cancer J. Clin. 2012, 62, 283–298. [Google Scholar] [CrossRef] [PubMed]
- Shahidsales, S.; Fazl Ersi, M. Male breast cancer: A review of literature. Rev. Clin. Med. 2017, 4, 69–72. [Google Scholar]
- Ruddy, K.J.; Winer, E. Male breast cancer: Risk factors, biology, diagnosis, treatment, and survivorship. Ann. Oncol. 2013, 24, 1434–1443. [Google Scholar] [CrossRef] [PubMed]
- Roshandel, G.; Ghanbari-Motlagh, A.; Partovipour, E.; Salavati, F.; Hasanpour-Heidari, S.; Mohammadi, G.; Khoshaabi, M.; Sadjadi, A.; Davanlou, M.; Tavangar, S.-M. Cancer incidence in Iran in 2014: Results of the Iranian National Population-based Cancer Registry. Cancer Epidemiol. 2019, 61, 50–58. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| P | E | ||||
|---|---|---|---|---|---|
| Constant risk | |||||
| 0.50 | 1 | −0.02(0.10), −0.06(0.12) | 0.17(0.14) | 0.39(0.27) | 1.12(0.29) |
| 5 | 0.16(0.10), −0.03(0.03) | 0.07(0.04) | 0.36(0.29) | 0.98(0.30) | |
| 15 | 0.16(0.10), 0.01(0.02) | 0.02(0.008) | 0.25(0.23) | 0.93(0.32) | |
| 60 | 0.12(0.10), −0.01(0.01) | 0.01(0.004) | 0.26(0.24) | 0.91(0.33) | |
| 200 | −0.07(0.10), 0.004(0.006) | 0.02(0.02) | 0.36(0.23) | 0.85(0.36) | |
| 0.70 | 1 | −0.91(0.11), −0.21(0.17) | 0.05(0.02) | 0.28(0.23) | 0.99(0.31) |
| 5 | −0.53(0.11), 0.001(0.04) | 0.03(0.01) | 0.26(0.24) | 0.95(0.32) | |
| 15 | −0.82(0.11), −0.002(0.03) | 0.07(0.05) | 0.21(0.22) | 0.96(0.32) | |
| 60 | −0.85(0.11), −0.02(0.01) | 0.02(0.01) | 0.27(0.26) | 0.95(0.32) | |
| 200 | −1.03(0.12), −0.01(0.008) | 0.01(0.01) | 0.31(0.28) | 0.92(0.32) | |
| Spatially unstructured risk | |||||
| 0.50 | 1 | 0.12(0.11), 0.08(0.11) | 0.39(0.04) | 0.32(0.25) | 1.01(0.30) |
| 5 | −0.11(0.11), −0.20(0.07) | 0.40(0.03) | 0.07(0.08) | 1.11(0.26) | |
| 15 | 0.16(0.11), −0.18(0.05) | 0.49(0.0.4) | 0.06(0.07) | 1.12(0.21) | |
| 60 | −0.04(0.11), −0.12(0.05) | 0.45(0.04) | 0.05(0.05) | 1.13(0.14) | |
| 200 | 0.07(0.11), −0.13(0.04) | 0.43(0.05) | 0.03(0.03) | 1.32(0.08) | |
| 0.70 | 1 | −1.01(0.12), −0.43(0.26) | 0.50(0.03) | 0.14(0.13) | 1.28(0.26) |
| 5 | −0.82(0.12), −0.20(0.10) | 0.51(0.04) | 0.06(0.08) | 1.20(0.25) | |
| 15 | −0.83(0.12), −0.15(0.07) | 0.48(0.03) | 0.08(0.14) | 1.06(0.22) | |
| 60 | −0.70(0.11), 0.02(0.05) | 0.48(0.02) | 0.08(0.02) | 1.18(0.10) | |
| 200 | −0.98(0.12), −0.16(0.06) | 0.42(0.04) | 0.06(0.07) | 1.17(0.18) | |
| Spatially structured risk | |||||
| 0.50 | 1 | 0.08(0.11), −0.08(0.14) | 0.34(0.04) | 0.18(0.17) | 1.11(0.27) |
| 5 | 0.19(0.11), −0.06(0.05) | 0.52(0.03) | 0.89(0.08) | 1.60(0.21) | |
| 15 | 0.02(0.11), −0.10(0.03) | 0.55(0.03) | 0.84(0.11) | 1.46(0.22) | |
| 60 | −0.02(0.11), −0.06(0.02) | 0.53(0.03) | 0.89(0.08) | 1.37(0.21) | |
| 200 | −0.01(0.11), −0.07(0.02) | 0.48(0.04) | 0.95(0.05) | 1.48(0.21) | |
| 0.70 | 1 | −0.92(0.12), −0.28(0.20) | 0.36(0.02) | 0.26(0.25) | 1.04(0.31) |
| 5 | −0.78(0.11), −0.08(0.07) | 0.57(0.04) | 0.66(0.22) | 1.16(0.26) | |
| 15 | −0.85(0.11), −0.04(0.05) | 0.53(0.04) | 0.62(0.20) | 1.44(0.23) | |
| 60 | −0.95(0.12), −0.09(0.04) | 0.51(0.04) | 0.87(0.09) | 1.43(0.22) | |
| 200 | −0.82(0.11), −0.06(0.04) | 0.56(0.03) | 0.87(0.10) | 1.37(0.21) | |
| P | E | Type0 | Type1 | Joint Model | |||
|---|---|---|---|---|---|---|---|
| BYM2 (DIC,LS) | BYM (DIC,LS) | BYM2 (DIC,LS) | BYM (DIC,LS) | BYM2 (DIC,LS) | BYM (DIC,LS) | ||
| Constant risk | |||||||
| 0.50 | 1 | (881.9,1.20) | (881.5,3.31) | (714.3,0.95) | (714.7,0.95) | (888.0,1.39) | (892.5,1.81) |
| 5 | (1457.0,1.79) | (1459.3,1.79) | (1383.7,1.79) | (1382.3,1.79) | (1281.7,1.19) | (1367.4,1.19) | |
| 15 | (1513.4,2.08) | (1517.8,2.08) | (1513.4,2.09) | (1520.5,2.09) | (1595.1,1.39) | (1626.2,1.39) | |
| 60 | (1810.4,2.42) | (1818.2,2.43) | (1784.7,2.43) | (1801.4,2.44) | (1706.6,1.62) | (1823.4,1.62) | |
| 200 | (2035.4,2.73) | (2054.6,2.75) | (1998.5,2.72) | (2030.6,2.74) | (2062.9,1.82) | (1974.3,1.82) | |
| 0.70 | 1 | (683.5,0.93) | (683.2,2.20) | (476.6,0.68) | (476.6,0.68) | (646.2,1.69) | (650.5,1.72) |
| 5 | (933.4,1.27) | (933.3,1.27) | (880.2,1.26) | (883.3,1.26) | (997.8,0.98) | (1074.9,0.98) | |
| 15 | (1026.7,1.43) | (1029.3,1.44) | (1095.7,1.44) | (1097.2,1.45) | (1017.0,1.11) | (1092.3,1.11) | |
| 60 | (1036.3,1.66) | (1046.0,1.66) | (1228.0,1.65) | (1237.4,1.66) | (1140.7,1.28) | (1206.3,1.27) | |
| 200 | (1379.9,1.85) | (1399.0,1.86) | (1407.3,1.83) | (1427.4,1.85) | (1436.6,1.41) | (1205.8,1.41) | |
| Spatially unstructured risk | |||||||
| 0.50 | 1 | (904.5,1.34) | (904.2,2.21) | (709.6,1.01) | (709.8,1.01) | (942.2,1.52) | (949.6,1.92) |
| 5 | (1398.7,2.06) | (1398.6,2.06) | (1360.0,2.01) | (1360.1,2.09) | (1317.4,1.37) | (1454.4,1.36) | |
| 15 | (1700.5,2.65) | (1700.2,2.66) | (1757.8,2.67) | (1757.7,2.67) | (1733.4,1.76) | (1784.3,1.76) | |
| 60 | (1930.1,3.18) | (1930.1,3.18) | (1984.0,3.19) | (1984.2,3.19) | (1890.0,2.10) | (1921.2,2.10) | |
| 200 | (2124.2,3.45) | (2124.2,3.45) | (2177.2,3.44) | (2177.4,3.44) | (2165.2,2.30) | (2222.3,2.30) | |
| 0.70 | 1 | (713.2,1.02) | (718.6,1.26) | (570.2,0.73) | (570.4,0.73) | (701.2,2.21) | (657.6,2.83) |
| 5 | (1025.7,1.45) | (1025.6,1.45) | (995.1,1.40) | (995.2,1.56) | (1032.5,1.11) | (1031.7,1.11) | |
| 15 | (1120.1,1.80) | (1119.9,1.80) | (1210.5,1.81) | (1210.3,1.81) | (1193.2,1.37) | (1186.5,1.36) | |
| 60 | (1387.4,2.10) | (1387.4,2.10) | (1265.5,2.11) | (1265.5,2.11) | (1120.1,1.60) | (1462.8,1.60) | |
| 200 | (1492.4,2.28) | (1492.4,2.28) | (1326.3,2.27) | (1326.3,2.27) | (1362.4,1.74) | (1375.1,1.74) | |
| Spatially structured risk | |||||||
| 0.50 | 1 | (860.8,1.43) | (861.4,1.38) | (707.2,1.00) | (707.2,1.00) | (922.6,1.49) | (931.0,1.90) |
| 5 | (1352.5,1.93) | (1351.8,1.93) | (1327.7,1.89) | (1326.3,1.89) | (1363.6,1.29) | (1438.7,1.30) | |
| 15 | (1592.9,2.41) | (1592.2,2.41) | (1636.7,2.35) | (1635.8,2.35) | (1642.0,1.62) | (1652.5,1.63) | |
| 60 | (1800.8,2.91) | (1800.4,2.91) | (1829.6,2.93) | (1829.3,2.93) | (1772.4,2.01) | (1920.0,2.01) | |
| 200 | (2304.5,3.34) | (2304.5,3.34) | (2097.2,3.35) | (2096.7,3.35) | (2223.6,2.29) | (2166.3,2.28) | |
| 0.70 | 1 | (698.8,1.02) | (699.1,3.11) | (521.7,0.72) | (522.8,1.26) | (691.1,2.11) | (648.3,2.79) |
| 5 | (941.6,1.36) | (939.9,1.36) | (983.7,1.34) | (983.4,1.34) | (949.2,1.05) | (1019.8,1.05) | |
| 15 | (1244.3,1.65) | (1243.7,1.65) | (1119.9,1.61) | (1119.0,1.61) | (1137.5,1.27) | (1158.2,1.28) | |
| 60 | (1265.8,1.95) | (1265.4,1.94) | (1289.2,1.95) | (1289.1,1.95) | (1341.9,1.55) | (1252.4,1.57) | |
| 200 | (1380.9,2.24) | (1380.8,2.24) | (1499.0,2.21) | (1498.9,2.21) | (1319.2,1.74) | (1500.8,1.74) | |
| BYM Model | BYM2 Model | BYM Model | BYM2 Model | |
|---|---|---|---|---|
| Joint model | (0.09, 0.19, 1.03) | (0.20, 0.56, 0.95) | (797.6, 0.73) | (794.9, 0.72) |
| BYM Model | BYM2 Model | BYM Model | BYM2 Model | |
|---|---|---|---|---|
| Type0 model | (0.70, 0.11, 0.63) | (0.70, 0.15, 0.51) | (795.5, 0.93) | (796.6, 0.93) |
| Type1 model | (0.08, 0.09, 0.21) | (0.08, 0.26, 0.61) | (666.9, 0.78) | (668.1, 0.78) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asmarian, N.; Ayatollahi, S.M.T.; Sharafi, Z.; Zare, N. Bayesian Spatial Joint Model for Disease Mapping of Zero-Inflated Data with R-INLA: A Simulation Study and an Application to Male Breast Cancer in Iran. Int. J. Environ. Res. Public Health 2019, 16, 4460. https://doi.org/10.3390/ijerph16224460
Asmarian N, Ayatollahi SMT, Sharafi Z, Zare N. Bayesian Spatial Joint Model for Disease Mapping of Zero-Inflated Data with R-INLA: A Simulation Study and an Application to Male Breast Cancer in Iran. International Journal of Environmental Research and Public Health. 2019; 16(22):4460. https://doi.org/10.3390/ijerph16224460
Chicago/Turabian StyleAsmarian, Naeimehossadat, Seyyed Mohammad Taghi Ayatollahi, Zahra Sharafi, and Najaf Zare. 2019. "Bayesian Spatial Joint Model for Disease Mapping of Zero-Inflated Data with R-INLA: A Simulation Study and an Application to Male Breast Cancer in Iran" International Journal of Environmental Research and Public Health 16, no. 22: 4460. https://doi.org/10.3390/ijerph16224460
APA StyleAsmarian, N., Ayatollahi, S. M. T., Sharafi, Z., & Zare, N. (2019). Bayesian Spatial Joint Model for Disease Mapping of Zero-Inflated Data with R-INLA: A Simulation Study and an Application to Male Breast Cancer in Iran. International Journal of Environmental Research and Public Health, 16(22), 4460. https://doi.org/10.3390/ijerph16224460