2. Cross-Sectional and Between/Within-Subject Linear Models with Repeated Measures
We begin here with some notation. Consider repeated measures on n subjects denoted by i = 1,2, …, n. The “subjects” can either be persons with longitudinal repeated measures, or, as is common in environmental epidemiology, can be cities, schools, neighborhoods, census tracks, hospitals, etc. Each subject has Ji different observations enumerated by j = 1, …, Ji. For example, these Ji different observations could be taken at times ti1 < ti2 <… < tiJi, on the same person when the “subject” is a person or from Ji different persons living in the same neighborhood when the “subject” is a neighborhood. For Ji constant across i, (i.e., always the same number of repeat measures for a subject), we drop the “i” subscript and denote J. Let us consider that the observations have continuous outcomes Yij and K predictor (or exposure) variables . When K = 1, we drop the “K” enumeration, using Xij for the only predictor. Linear regression models for E[Yij| ] or E[Yij|Xij] are fit in the analyses described here. However, the overall conclusions we obtain on these linear regression models can be generalized to discrete outcomes (i.e., logistic regression) and survival analyses.
2A Cross-Sectional (CS) Regression. The most commonly fitted linear regression model on repeated measures does not separate within- and between-subject associations and is usually written out as
Yij = α + β1X1,ij + β2X2,ij + … + βKXK,ij +
εij. This is denoted as “cross-sectional (CS) regression” particularly for longitudinal repeated measures. We add a subscripted “CS” to the β’s to distinguish these slopes from between-subject (BS) and within-subject (WS) slopes defined in
Section 2B. The CS regression model here is thus denoted as
where
are parameters (fixed effects), while
εij is error with E[ε
ij] = 0 that is independent between different subjects
i and
i’, but may be correlated for
j ≠ j’ within the same subject. It should be noted that the intercept is fixed at the same
for each subject. Should the actual intercepts differ between subjects (i.e., be
) as random intercepts, then for both MM and GEE, the difference
is incorporated into the error term
εij of (1) and the within-subject correlation of that error [
1]. Using (vs. not using) random intercepts does not influence the point estimates of
or the variance of these estimates for mixed models [
1]. However, for GEE using a different intercept on each subject (with each intercept now adding a new parameter) creates too many parameters for the asymptotic properties of GEE model to hold in our examples (and in general) which destabilizes parameter estimates [
2].
Again for K = 1, the subscript for K is dropped and the model is + εij. The main goal of CS regression is to first obtain estimates for and then input into (1) in order to estimate future unobserved Y’s from observed ’s as . Cross-sectional regression is also used to make adjusted (causal) inference on the covariate associations in , but, as we show later, doing this may be problematic.
Table 1 presents parameter estimates from repeated measure cross-sectional regression (1) to a clinical measure of glomerular filtration rate (EGFR) from the Modification of Diet in Renal Disease Study (MDRD) [
3]. Formula (1) with EGFR as the outcome Y and three predictor variables (X
1, X
2, X
3) =
(HIV infection, serum albumin, blood urea nitrogen (BUN)) was fit to 10,782 semi-annual measures of 584 women at the Bronx-site of the Women’s Interagency HIV Study (WIHS) [
4]. Higher EGFR values indicate better renal function. The models assume that the within- and between-subject associations of the predictor variables are the same. We later show this assumption is incorrect. The parameter estimates of
Table 1 were calculated using GEE [
1] with both independence (GEE-IND) in columns 2–4 and equicorrelation (GEE-E) columns 5–7 for the working correlation structure of model residuals from repeated measures in the same person. We again note that this model (1) has a fixed intercept across all subjects with the error term being independent between different subjects. However, otherwise in
Table 1 (and elsewhere in the paper) the within subject correlation structure of the error is allowed to be either (i) independent within the same subject (GEE-IND) or (ii) to have the same correlation for all outcomes within the same subject (GEE-E). The second condition (i.e., equicorrelation) is equivalent to fitting a random subject intercept model [
1].
Most of today’s literature providing guidance on fitting repeated measures linear regression (i.e., [
5,
6,
7,
8,
9,
10,
11,
12,
13]) qualitatively describes working correlation as a “nuisance factor” that does not alter model parameters and states that “
the working correlation that minimizes variance of parameter estimates should be chosen”. However, in
Table 1, the parameter estimates for BUN (per g/dL), from GEE-E, of −1.22; 95% confidence interval (CI) (−1.46, −0.99) is both qualitatively and statistically higher than the corresponding GEE-IND estimate of −1.87; 95% CI (−2.12, −1.62). For HIV, the parameter estimates of −3.86,
p = 0.0081 from GEE-E is qualitatively lower than that from GEE-IND −2.04 and
p = 0.19. Clearly, changing the working correlation from independence to equicorrelation qualitatively and statistically changes the parameter estimates. Thus, this correlation structure is not a nuisance factor.
When faced with such a dilemma of qualitatively and statistically different parameter estimates from the same model fit to the same data with only the working correlation structure changed (as is shown in
Table 1), investigators typically go to published guidance on which correlation structure to use. To that end, based on the within-subject correlation of residuals being 0.45 in GEE-E (and in MM-E), and the quasi-likelihood independence criteria goodness of fit statistic (QIC) = 10,836.27 for GEE-E being smaller than the QIC = 10,847.14 for GEE-IND (or the Akaike information criteria goodness of fit statistic (AIC) from a mixed model using equicorrelation (MM-E) of (AIC = 94,934.5) being smaller than AIC = 99,374.5 from a mixed model using independence (MM-IND) as shown in
Table A1 in
Appendix A), almost all articles providing model fitting guidance [
5,
6,
7,
8,
9,
10,
11,
12,
13] point towards using equicorrelation as the working correlation structure. However, as the rest of
Section 2 describes in detail, this guidance is problematic as only the parameter estimates obtained by using independence working correlation can have any meaning for cross-sectional regression.
But first we make two brief asides. First, we note that if MM, rather than GEE are used for
Table 1, the corresponding parameter point estimates in
Table 1 using independence correlation (MM-IND) and equicorrelation (MM-E) are essentially unchanged [
1]. (See
Appendix A for details on parameter estimates from MM fit to this data with independence and equicorrelation correlations structures). However, due to non-robustness of MM, GEE is preferable for this specific example. Second, we note that the differences observed in
Table 1 occur not only between independence and equicorrelation. Any different choice of correlation structure, such as AR(1), Toeplitz, unstructured, etc. will result in different parameter estimates (results not shown). For simplicity, we focus this article on only two structures: independence and equicorrelation.
2B Between-/Within-Subject Slope (BS/WS) Regression. While investigators almost never consider this in practice, it has long been noted that slopes on changes of
Xij within the same subject
i differ from cross-sectional slopes on between subject-measure differences in
Xij [
14,
15,
16,
17]. To illustrate this, consider the cross-sectional model of a laboratory measure cholesterol (
Yij), which is well known to be higher in people with more body fat. To that end, the predictor is body weight (
Xij) with
E[
Yij] =
. As described in the Introduction, the cross-sectional slope
βCS for association of a 10 lbs. weight difference between two different adults for cholesterol is less than the slope for association of a 10 lbs. within-subject weight change for the same adult on cholesterol, which we denote as
βWS. Again, the reason
βCS is less than
βWS is that: (i) a 10 lb. cross-sectional weight difference between two adults often reflects greater height in one of the persons, but (ii) a 10 lbs. weight increase in the same adult is not influenced by height difference and thus is more likely due to more body fat after the 10-lbs weight gain. Thus, since greater body fat is what is directly associated with more cholesterol, the within-person association of a 10-lb. weight increase with cholesterol is greater than the cross-sectional repeated measures association with a 10-lb. weight difference between two persons.
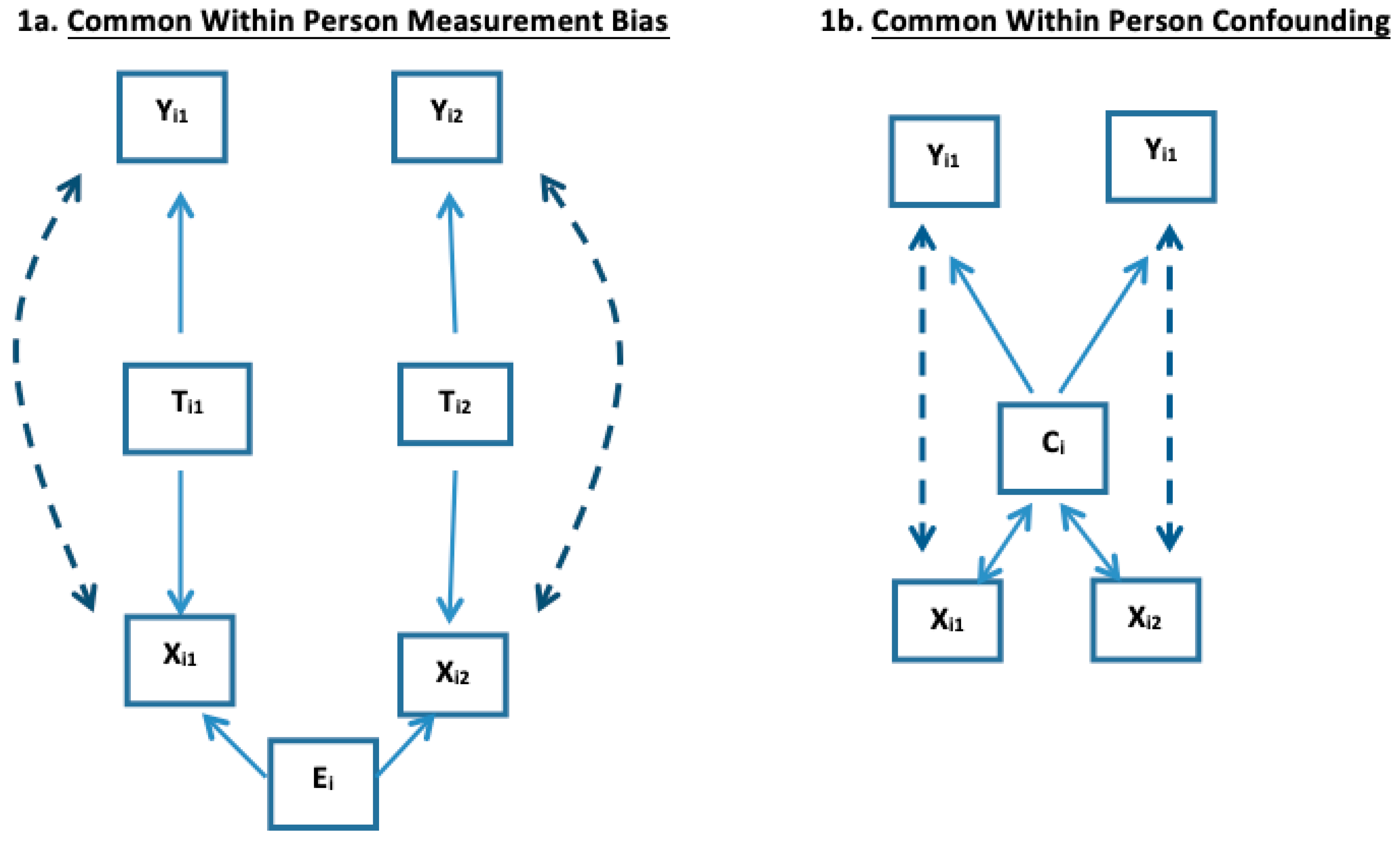
Common within-person height creates a shared within-subject measurement bias from this extraneous factor for subject
i (denoted
Ei) on weight as a predictor of cholesterol. To that end, many investigators adjust weight for height using body mass index =
wt/ht2 to remove this effect of height on weight. As
Figure 1a illustrates, if
TXij = body mass index (
wt/ht2) were the true predictor of
Yij, and
Hi = height (which does not change with
j in the same
i), then
Xij = TXij * (Hi)2 contains this shared within-subject measurement bias from common
Hi which again we denote as
Ei in
Table 1a to confer it is an extraneous within-subject bias.
Section 4 describes more settings where
.
While for weight it is possible to remove the common shared within-subject bias from height by dividing by
ht2, this is not the case for less well-understood causal relationships. Therefore, to model and account for a bias such as this, linear regression models fit for making causal inference can decompose the associations into “within-subject” slopes (
), described above, and “between-subject” slopes (
), described below, which capture associations of subjects’ central tendencies of the exposure. To do this, subject means of the predictor variables
are calculated, where
. Then
Yij is modeled as a combination of “between-subject” slopes from
(that could be influenced by the common person measurement bias in
Figure 1) and “within-subject” slopes from deviations of
Xk,ij about
which will be free of such a bias, since the comparison is within person.
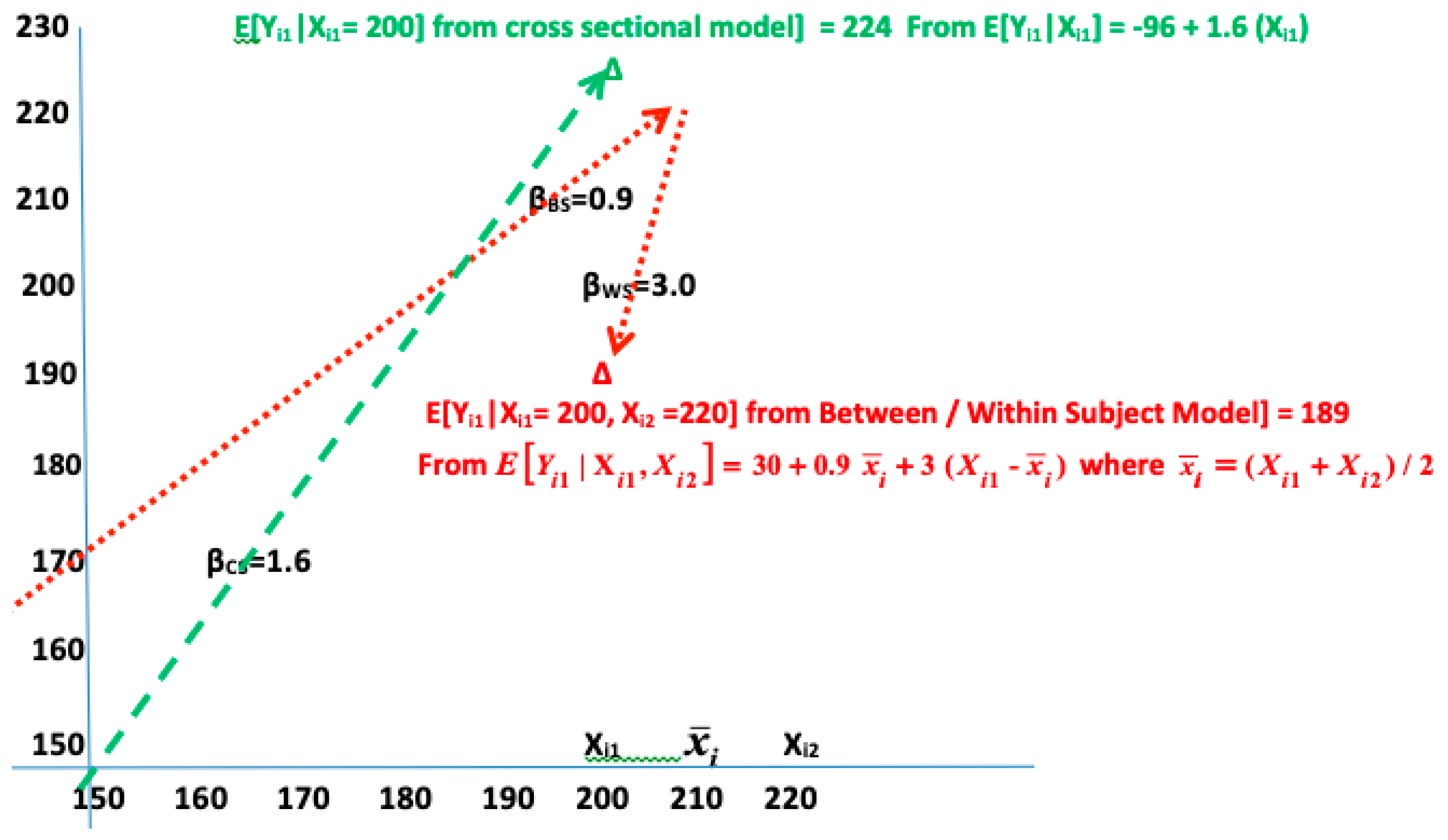
As described for (1), this is a fixed intercept model that is functionally equivalent to a random intercept model for MM. When K = 1, we have . To illustrate this for our earlier example with Yij = cholesterol and Xij = weight, let , βBS = 0.9 and βWS = 3, such that . If person i had an average value of = 210 across all Ji measures with the jth measure being Xij = 200, then for the person-visit at time tij, E[Yij] = 30 + 0.9(210) + 3(200-210) = 189.
Now we make some technical asides. First, the choice of the observed
as the “central tendency” of
Xk,ij for subject
i is necessary as
a person’s “true average weight” over the entire time period is unknown, but for
Ji large enough,
should be close to
. Thus, while
βk,WS only captures association with within-subject change in
Xk,ij, βk,BS inherently contains some
βk,WS from deviation of (
); especially for small
Ji. This situation is described for occupational epidemiology research, where often an average of personal exposure measurements is computed as estimate of true exposure of a “subject”, defined as either an individual, or group of individuals that share a job [
18]. Second, the implicit assumption that
βk,WS is well defined may also not always be true. For example, “
βk,WS” could differ by time separation t
ij – ti
j’. Perhaps for
k = weight, a weight gain of 10 lbs. in one month creates a shock that hyper-elevates cholesterol, but a 10 lbs. weight gain over 12 months does not, in which case
. Third, if the investigator is only interested in the within-subject slopes he/she can substitute as a
fixed effect a different subject intercept
for the between-subject slopes in (2) with the model reducing to
.
Despite these technical caveats, the within- vs. between-subject decomposition in (2) is used to test whether
so that, as shown in
Section 2C, they also equal
and thus the separated
WS vs.
BS decomposition can be collapsed to (1). Due to the orthogonal decomposition of
Xk,ij about
this previous test for collapsing the within- vs. between-subject decomposition is a two-sample z-test of parameter estimates from fitted models comparing
to
Z1-α/2 [
17]. The within- vs. between-subject decomposition is mostly used for inference on adjusted (causal) associations of the
Xk,ij’s on
Yij’s. It is typically not used to produce models to estimate future unknown
Yij from known
as such estimation often only happens in settings where just one observation per subject is available, hence
.
We refit the analyses of
Table 1 to illustrate that the impact of choice of correlation structure (i.e., GEE-IND vs. GEE-E working correlation structure) is eliminated in our example after making a within- vs. between-subject decomposition. Please note that there were no new HIV infections after study entry; so
meaning that the within-subject association of change of HIV infection status cannot be modeled. For within-subject associations of BUN and albumin, GEE-IND and GEE-E gave identical point estimates, because centering about
makes comparisons entirely within-subject and invariant to these correlation structure choices (although within-subject estimates could differ slightly if autoregressive (AR (1)) or other formulations for intra-subject correlation of residuals had been used). There were small GEE-IND vs. GEE-E differences on the between-subject slopes as was observed elsewhere [
19]. For example, the point estimate for between-subject HIV status is −1.16; 95% CI (−4.21, 1.88) in the GEE-IND of
Table 2 versus −1.57; 95% CI (−4.47, 1.33) with GEE-E.
From now on, we only examine GEE-IND results for within- between-subject decomposition models, as GEE-E results are similar. For BUN and GEE-IND, the within-subject = −1.11, 95% CI (−1.34, −0.88) is qualitatively and statistically closer to 0 than is the corresponding between-subject slope = −2.72, 95% CI (−3.10, −2.33). However, serum albumin goes the other way: the within-subject slope = −10.70, 95% CI (−12.99, −8.40) is statistically further from 0 than is the corresponding between-subject GEE-IND = −3.27 with a 95% CI (−7.88, 1.33) that overlaps 0. The QIC is lower (10,857.62) for equicorrelation than for independence (10,866.64) which perhaps now indicates an advantage to the former correlation structure in this setting where the slopes have been correctly decomposed.
One might wonder how to interpret differences in the within- and between-subject slopes for causal inference, including the reasons that these slopes were different? This in part will depend on the hypotheses of interest (and we did not have any for this illustrative example). However, general rules also apply, although we are unaware of any systematic exploration of reasons why the between-subject slopes (or βBS for K = 1) could differ from within-subject slopes (or βWS for K = 1). and the resultant implications for causal inference. Before outlining these rules, it is important to note an important relationship among cross-sectional, within-subject and between-subject slopes.
2C Relationship between , and . Now
averages
and
according to relative variances of the subject means (i.e., the
) vs. the variance of the repeated measures about those sample means (i.e., the
) [
17]. For example, with
K = 1, if
is the population variance of the within-person mean
and
is the population variance of the deviations of differences of the repeat measures
Xij from their
, then
In the previous example of weight and cholesterol with = 0.9, = 3 and , if and , then from (3) = 0.9*400/(100+400)+3*100/(100+400) = 1.32. If the between-person sample means are more homogeneous in weight with but the within- person is still 100, then again using (3) moves closer to ; = 0.9*200/(100+200)+3*100/(100+200) = 1.60.
2D Working Correlation Structures for Model Residuals Other than Independence Can Lead to Unusable Results for Cross-Sectional Regression. As noted earlier, fitting both MM and GEE repeated measure regression models involves specification of correlation (or working correlation) structure of
εij within the same subject
i. We denote the working correlation structure by matrix
Vi. Typical choices for
Vi are the ones we used in the illustrative examples of
Table 1 and
Table 2; equicorrelation (E), with correlation of
εij and
εij’ for j ≠ j’ always the same value ρ (this common value of ρ is estimated in the model fitting process based on the residuals in the model fitting process), and independence (IND), with correlation of ε
ij and ε
ij’ ≡ 0. However, other structures are used such as AR(1) where correlation of
εij and
εij’ is
ρ|j-j’| with the value of
ρ being estimated from the residuals [
1]. Again, current guidance [
5,
6,
7,
8,
9,
10,
11,
12,
13] emphasizes choosing the
Vi that most closely fits the true covariance structure of the residuals within
i and/or by model fit criteria such as having lowest QIC for GEE and AIC for MM, because doing so often improves precision of the model parameter estimates. However, we just observed that this approach may be wrong for CS regression, because using any correlation structure other than IND can introduce structural bias into
[
20,
21] and, unfortunately, AIC and QIC do not account for this bias.
To that end, Pepe and Anderson (1994) [
20], developed a general rule for when IND is (and is not) the only correlation structure that should be used for CS regression that we now present. Specifically, they show that if a predictor
varies (i.e., takes on different values) within the same subject
i and,
then, no matter what true correlation structure of ε
ij among repeated measures within a subject is, GEE-IND gives unbiased estimates for
, but any MM or GEE model not using
Vi = IND, gives biased estimates of
. Thus, the only working correlation structure that should be used to estimate
is
Vi = IND. However, if (4) does not hold, then any working correlation structure obtains unbiased estimates for
in which case, choosing the
Vi that most accurately fits the correlation structure of ε
ij minimizes the variance of
.
Our paper only focuses on equicorrelation as the alternate to independence in order to keep the presentation from becoming too cumbersome, given the large number of possible correlation structures. However, the previous paragraph and (4) apply to any non-independence correlation structure.
As one (of many) examples of where (4) holds, let k = 1 and Yij and Xij be the degree of airway obstruction and inhalation of tobacco smoke of subject i at time j, respectively. One would expect that, because smoking effect on the lung is cumulative, historical smoking in a current smoker or non-smoker would lead to poorer lung function. Thus, E[Yij|Xij’] for a smoker at time j’ < j would poorer irrespective of Xij.
We now present an easier way to visualize (4). If repeated measures j and j’ are thought of as “siblings” and the predictors as “exposures” then (4) means that even after considering the “self-exposure” of the current measure j through the outcome Y has “Conditional Dependence On Sibling Exposures” (Co-DOSE) (i.e., on ). Thus, the sibling exposure could be thought of as a Co-DOSE beyond the “dose” from the “self-exposure”. Hence, from now on we use the term Co-DOSE to denote that (4) occurs.
Also, while this point has not been very well made, for CS regression, Co-DOSE in (4) largely occurs if and only if within- and between-subject slopes differ. If within- and between-subject slopes differ
for any predictor (i.e.,
) then Co-DOSE (4) happens. However, if the within- and between-subject slopes are equal
for all predictors (i.e.,
) then Co-DOSE (4) does not occur. More details on this and an illustration are given in
Appendix B, but one trivial case arises if the predictors are invariant within the same subject (i.e.,
) such that the within-subject slopes are not defined (since
) and for the same reason Co-DOSE in (4) cannot occur. While the mathematical details are beyond this paper, if
and
Vi = IND, then non-zero covariance
ρij > 0 besides adjusting for within-
i collinearity of
εij also over-weights the
relative to
in (3), thereby pushing CS regression parameter estimates away from
towards
[
17]. Since robust covariance methods exist to adjust for impact of misspecification of
Vi = IND from collinearity of the residuals
εij’s on variance estimates, in particular for GEE [
1],
Vi = IND can eliminate bias in estimating
while providing conservative variances for the parameter estimates.
2E Implications for Applied Research and Statistical Practice. Much of what has been presented above is not commonly understood and implemented in applied research and statistical practice. CS models are typically fit, with
interpreted to also be
and
, without checking if these slopes are equal. Non-independence
Vi is often used for CS regression without checking if Co-DOSE (in (4)) exists. Perhaps in part this occurs because systematic epidemiological descriptions of causal mechanisms for why between- and within-subject slopes can differ are lacking, which hinders awareness of this possibility. We endeavor to fill this gap in
Section 3.
3. Epidemiological Reasons for Between- and Within-Subject Slopes to Differ
To make it easier for investigators to identify what could cause βk,WS ≠ βk,BS (or equivalently Co-DOSE) in a given setting, we classify major reasons why this can happen. For simplicity, let K = 1 unless otherwise noted, as the following principles extend to multivariate settings.
3A. Change Effects. We propose that the effect of a longitudinal within-subject change in the predictor X could have a greater (or less) direct impact on Y than a long-term standing difference in X between two different subjects (hence
βWS ≠
βBS) and define this as a (c.f. short term) “change effect”. Returning to the example of weight and cholesterol, consider two identical twins, “A” has lived his adult life at
= 190 lbs. and “B” at
= 180 lbs. If “B” undergoes a short-term weight gain of 10 lbs. to 190 (
= 10), assuming
not impacted by the rapid change, while A remains at 190 lbs. (
= 0), the shock or corollaries of this rapid change in B may raise his cholesterol level above that of A’s even though they both now weigh 190 lbs., meaning that
βWS >
βBS and Co-DOSE in (4) occurs. However, it should be noted that as was mentioned in
Section 2B, in this setting,
βWS would be somewhat undefined if, e.g., a 10 lbs. gain in a shorter time period (i.e., 1 month) increases
βWS more than does a 10 lbs. gain over a longer time period (i.e., 12 months).
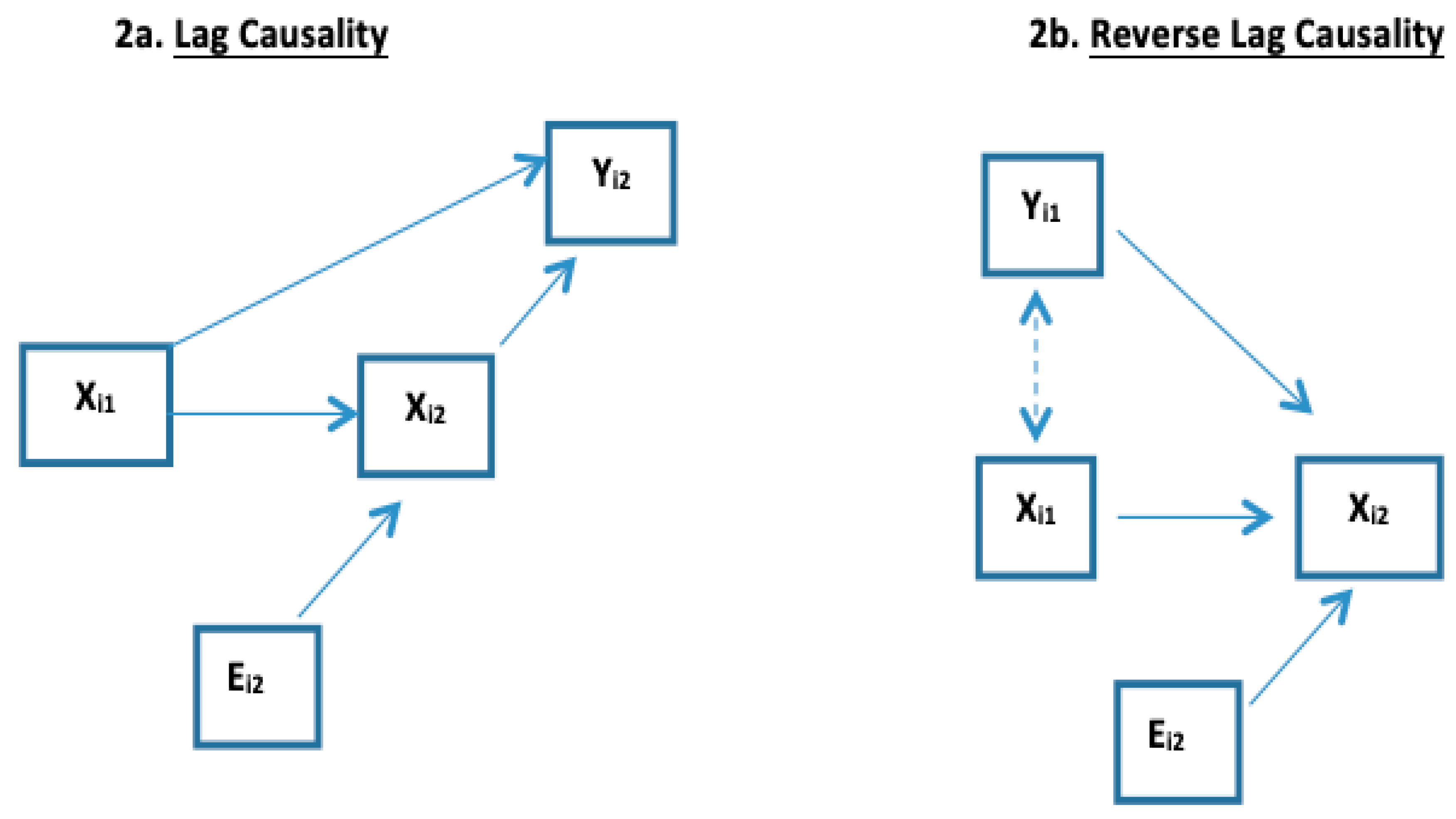
3B Lag Causality of X on Future Y. The effect of historical levels of
X on
Y may independently project into the future (i.e., beyond that effect of the current level of X). For example, consider an HIV-infected person and two time points
t1 <
t2; let
Xij be HIV viral load and
Yij be CD4 count. High HIV levels destroy CD4 blood cells into the future. Therefore, as illustrated in
Figure 2a, high HIV viral load at
t1 may affect CD4 loss from t
1 to t
2 so that even if the person’s HIV viral load is low at t
2, the high viral load at t
1 is predictive of lower CD4 at t
2 through higher viral load at t
1 having created more CD4 destruction between t
1 and t
2 (i.e., lag causality of X at t
1 on Y at t
2). Thus,
Yi2|Xi2 at
t2 is not independent of
Xi1 at t
1; Co-DOSE in (4) occurs and the within- and between- subject slopes differ (
βWS ≠
βBS). In
Figure 2a,b,
Ei2 denotes that
Xi2 differs from
Xi1 due to an extraneous process that is causing
Xi to change over time. Lag causality is often considered when serial measures of
X represent long-term environmental exposures (such as air pollution and cigarette smoke) that effect chronic conditions
Y (such as lung function) are obtained [
1,
18,
22].
3C Reverse-Lag Causality of X on Future Y. The setting in
Section 3B also manifests in the opposite direction if
X is being used as to estimate
Y that is causal for future
X. Reversing the previous example with
X now being CD4 used to predict HIV viral load as Y, as
Figure 2b illustrates, high viral load (
Yi1) at t
1 may have degraded the CD4 count from t
1 to t
2. Thus,
Yi1|Xi1 at
t1 is not independent of
Xi2 at
t2: Co-DOSE in (4) occurs and within- and between-subject slopes differ (
βWS ≠
βBS).
3D Spillover Causality of X on Adjacent Y. An analogous setting to those of 3B and 3C can also manifest in repeated measure cross-sectional settings based on geographical proximities. Let the subjects i now be cities and j enumerate different neighborhoods in these cities. The repeated measures are average air pollution (Xij) of neighborhood j in city i and average lung function of all residents living within neighborhood j of city i (Yij). A resident living in neighborhood j may work in a different neighborhood j’ of the same city and thus have “spillover exposure” to air in the neighborhood they work in, for a given city i, thus Yij|Xij is not independent of Xij’ and hence Co-DOSE in (4) occurs.
3E Common Within-Subject Measurement Bias. Shared
within-subject measurement bias occurs if all repeat measures from the same subject have the same correlated measurement bias. This was the setting described in
Section 2B and
Figure 1a with weight as exposure for cholesterol. Here with weight as a surrogate for body fat, the measurement bias was mediated by height with taller adults being heavier independently of body fat than shorter adults, which leads to
βWS >
βCS and Co-DOSE in (4) when weight was a predictor of cholesterol. In this setting, height is a
measurement bias not a confounder as height itself is not associated with cholesterol. We now present a similar setting where the un-modeled variable is a confounder.
3F Common Within-Subject Confounding. Figure 1b shows
common within-subject confounding, that causes
βWS ≠
βCS and Co-DOSE in (4). This phenomenon is diagrammatically similar to
common measurement bias that was described in
Section 2B. However, rather than a common measurement bias, the extraneous factor, shared by the repeated measures of the same subject, is a confounder that is associated with both X and Y. For example, let the confounder variable
Ci be sex of subject
i (which does not change with j) not be in the model and the outcome
Yij be a linear score for male pattern baldness at time j with again
Xij being weight at time j. Adult men are both on average heavier and, independently of weight, have greater male pattern baldness than do adult women. So
Ci is associated with both the exposure and the outcome. Here a 10 lbs. weight difference in two adults, but not a within-adult increase of 10 lbs., could be informative of the heavier adult more likely being male. Hence for this example,
βWS = 0 (assuming within adult weight does not influence baldness), but
βCS > 0 (and thus
βBS > 0) as males are more likely to be both heavier and bald compared to women. Hence also
βCS > 0, reflecting unaddressed between-subject confounding from heavier adults more likely being men.
Similarly, Mancl, Leroux and DeRouen proposed that in a study with repeated dental predictor and outcome pairs as (
Xij,Yij) measured on teeth (i.e., enumerated by
j) on the same persons (i.e., enumerated by
i) that better compliance with dental treatment by some persons was a confounder that could lead to differences in slopes within and between subjects [
19]. In a non-longitudinal setting where
i denotes clusters (for example schools) and
j denotes repeated subjects within that cluster (for example students), common within-subject confounding is referred to as “contextual effects” [
23,
24]. For example, as Robinson (1950) [
14] observed, when X was race of the student and
Y was achievement-score, a higher
(here: portion of a school’s students that were non-White) indicated weaker financial support for that school (weaker financial support being the confounder) and thus worse achievement-scores overall for that school:
βBS was negative. However, within the same school, race had no impact on the achievement score (
βWS = 0). Begg and Parides [
25] identify a similar setting in birthweight and intelligence quotient in families.
3G Measurement Error in Xij Makes E[Yij|Xij] Dependent on Xij’ In many settings, the predictor we observe is
X =
TX +
M where
TX is the true value of the predictor and
M is measurement error that is independent of
TX (i.e., classical measurement error). It has been shown that, measurement error in
X that is either independent of [
26], or correlated with
Y [
27], biases estimates for the slope that relates
TX with
Y. Measurement error can arise either from imprecision in an analysis instrument, such as in a machine quantifying components of serum, or
in data collection process, such as the chemical composition of blood samples being non-informatively influenced by diurnal and other nuisance processes. If
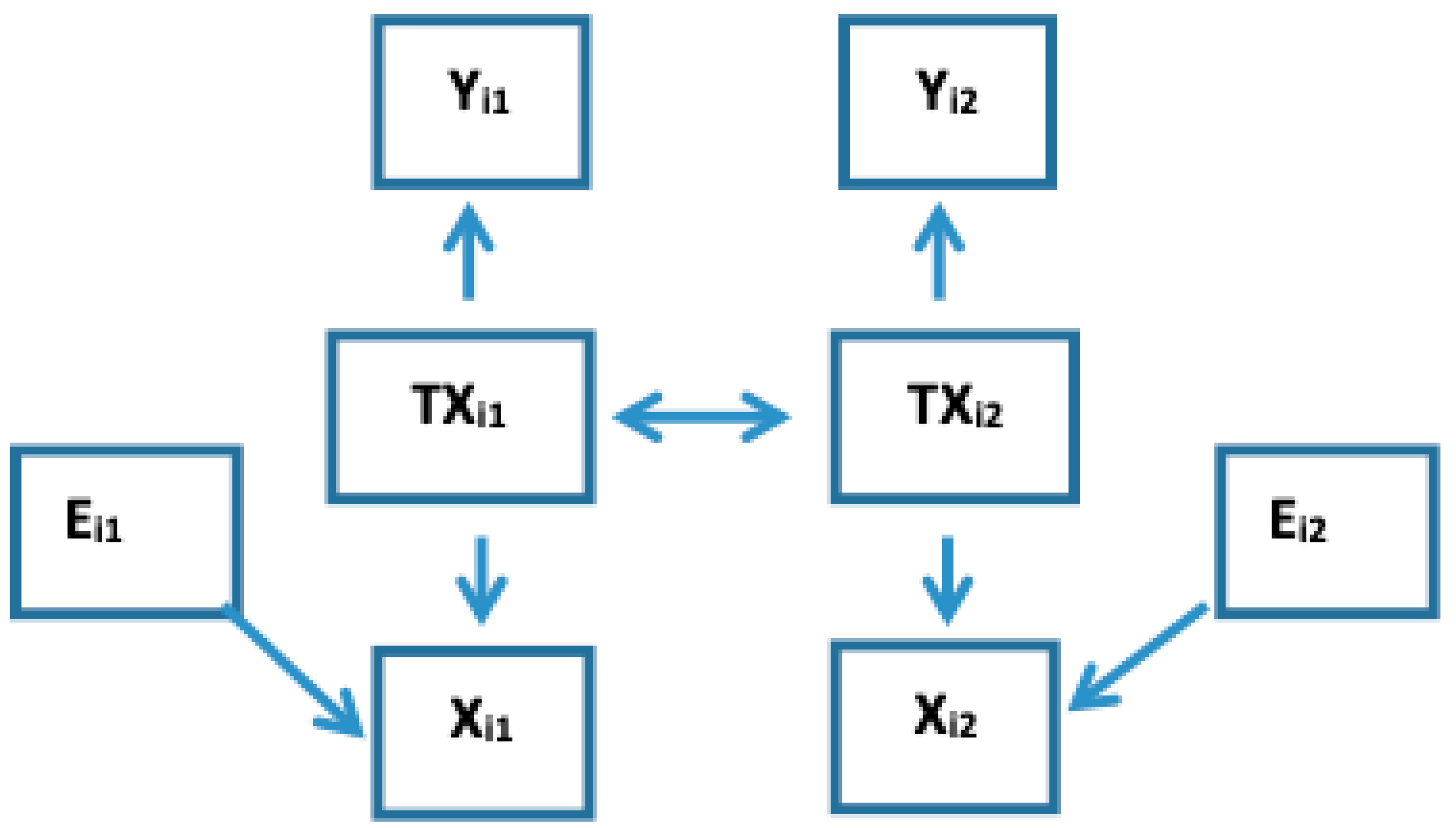
Xij is incorrectly quantified due to such measurement error, then Co-DOSE in (4) occurs and the observed within- and between-subject slopes differ, because, as illustrated in
Appendix C, the biases being created from the measurement error distribute differentially to different slopes. As
Figure 3 shows and the paragraph below it describes using an illustrative example, if
Xi1 incompletely measures the true state
TXi1 (i.e., true BUN) due to classical measurement error as the extraneous influence then
Xi2, is informative for
TXi1 even after considering
Xi1. Please note that in
Figure 3 there are two times subscripts on the extraneous influence, because
Ei1 and
Ei2 are two independent measure errors.
For example, going back to the analysis of
Table 1, let
Xij be BUN and
Yij be EGFR. Consider two persons who have BUN of
Xi1 = 10 mg/dL measured with error today. Also assume that the true BUN state changes slowly. If so, and after 6 months one of these persons measures
Xi2 = 20 mg/dL while the other measures
Xi2 = 5 mg/dL, we can then surmise that since BUN changes slowly, it is more likely that the true BUN today (
TXi1) of the former person is > 10 mg/dL and that of the latter is < 10 mg/dL. Thus, since (i) EGFR (
Yi1) directly depends on
TXi1 not
Xi1, and (ii)
Xi2 is informative on
TXi1 after considering
Xi1, then (iii)
Yi1|Xi1 is not independent of
Xi2 and similarly
Yi2|Xi2 not independent of
Xi1 meaning Co-DOSE in (4) occurs and the observed within- between-subject slopes differ.
Appendix C shows that measurement error in the exposure that is independent of the outcome pushes both
βWS and
βBS towards 0, but more so for β
WS. Such tempering from averaged measurement error has been proposed as a reason |
βWS| < |
βBS| was observed in dental research [
19] and occupational epidemiology [
28,
29].
However, if
Mij is correlated with
Yij (most likely being correlated with measurement error on
Yij [
27]) the tempering of
β’s from
Mij will not be to 0. For example, consider
TX = CD8 and
TY = CD4 cells which together are the almost exclusive components of serum lymphocytes (
TZ) (i.e.,
. Physiologically,
TZ is constrained to create a negative
βBS,
βWS and
βCS for
TYij on
TXij: subjects with a higher CD8 component of serum lymphocytes by converse must a have lower CD4 components. However, the measured lymphocyte count (
Z) is subject to a correlated measurement error that equally spreads onto
X and
Y. For example, if a person is dehydrated, the entire measured lymphocyte (meaning both CD8 = X and CD4 = Y) portion of blood becomes artificially higher due to reduction of the percentage of water in the blood. If a person has a high (or low) measured lymphocyte count
Zij =
TZij +
Mij due to such measurement error, then
Mij contributes to both CD4 (
Xij) and CD8 (
Yij), making both simultaneously artificially higher (or lower). Consequently, within person, a higher measured CD4 count due to positive
Mij is associated with higher measured CD8. Because in this case the measurement error is shared, naïve regression analysis tends to draw
βWS towards being positive. On the other hand,
βBS, which tempers down
Mij on both
X and
Y through averaging as shown in
Appendix C, is less affected by the shared bias due to measurement error.
We have only considered classical measurement error so far. The other common type of measurement error is known as Berkson error [
30]. It is approximated by some exposure assessment procedures commonly used in environmental and occupational epidemiology (see semi-ecological design and group-based exposure assessment) [
18]. While this is an aside to the main points of this paper, when Berkson measurement error exists, only the between-subject slope,
βBS, is estimable. More details are in
Appendix D.
5. Discussion
Numerous published papers fit GEE and MM cross-sectional regression models with repeated measures having time varying predictors that either use non-independence working correlations structures or do not state the correlation structure. These papers, which continue to be published, do not show awareness of the points presented in
Section 1,
Section 2,
Section 3 and
Section 4, above. Specifically, they:
- (a)
Neither specify whether the coefficients of interest are , or, nor check whether ;
- (b)
Make potentially invalid interpretations of from MM and GEE using non-independence correlation Vi’s; and/or;
- (c)
Do not justify the choice of non-independence working correlation structures Vi in light of potential differences between , and .
We have identified almost 45 such papers including some authored by us prior to becoming aware of these issues. This is almost certainly only a fraction of the total number of such papers.
Yet papers published up to 65 years ago either warn against using non-independence working correlation structure in cross-sectional regression with repeated measures [
19,
20], or instruct to decompose the associations into within-subject (
) and between-subject (
) slopes to make causal inference [
14,
15,
16,
17]. Numerous examples where
have been presented [
14,
15,
16,
17,
18,
19,
20,
22,
23,
24,
25]. While it was not covered in our paper, this includes fitting GEE models of binary outcomes where the issues discussed here also apply [
19,
31]. However, these points are still not well known or emphasized in statistical software documentation and papers providing guidance on GEE and MM analyses (i.e., [
5,
6,
7,
8,
9,
10,
11,
12,
13]).
One problem that impedes acceptance of within- and between-subject decomposition is that it necessitates much more complicated models that are difficult to explain. Still, some air pollution epidemiologic studies have attempted within- and between-subject decompositions using cities as the subject and neighborhoods as the repeated measures within the city [
32,
33,
34]. Most often in these studies, the magnitude was greater for within-subject slope |β
WS| > |β
BS| but sometimes |β
BS| > |β
WS| was observed meaning that possibly multiple causes for slope differences are involved. Those papers that did attempt to explain the reasons for the differences described only “common within-subject confounding” (
Section 3E) as a potential reason; such as un-modeled pollutants that were correlated between (but not within) cities with the modeled pollutants of interest. Other studies in environmental research have considered the mechanism described in
Section 3B, namely, lag causality in longitudinal analyses of association of air pollution on health measures [
1]. Nevertheless, having to explain complicated and unknown mechanisms for biases such as these can appear to detract from the main purpose of the research and cast doubt on the overall findings, making the paper harder to publish. In other words, there appears to be neither incentive, nor guidance on how to engage with these issues for applied researchers.
We concur with others [
19,
20], that cross-sectional regression with repeated measures should use independence as the default working correlation unless justification is given to use other
Vi. While non-independence
Vi can improve precision and thus be desirable [
21], they can considerably bias estimates for cross-sectional parameters,
, including perhaps towards what the investigator wants to see. For example, in
Table 1,
p < 0.01 was observed for association with HIV with worse EGFR in GEE-E compared to the more appropriate
p = 0.19 from GEE-IND. An investigator who was expecting HIV to be associated with worse EGFR might thus be tempted to use the results from GEE-E for this reason.
While showing this is beyond the scope of our paper, when
Vi is not independence, factors such as the values of
Ji and magnitude/structure of
εij strongly influence parameter estimate values for
from the miss-fitted cross-sectional models, allowing the miss-fitted estimate to arbitrarily range from
to
[
17]. Standardization is important and, as such factors will arbitrarily vary between studies, parameter estimates of
become harder to compare across studies when
Vi differs at discretion of investigators. Therefore, the working correlation structure used in cross-sectional regressions using repeated measures should always be justified and reported.
We also concur with others [
14,
15,
16,
17,
18,
19,
23,
24,
25] that despite the difficulties in identifying why within- and between-subject slopes differ, causal inference analyses with repeated measures should initially make such decompositions. Investigators should then be wary if there are qualitative differences between
and
. For example,
Table 2 with 584 subjects and 10,782 measurements demonstrated need for
,
decomposition to make causal inference (as well as for using GEE-IND in cross-sectional regression). However, a smaller study could have been less clear-cut. If the same point estimates for
and
seen in
Table 2 were observed but did not statistically differ, one would be tempted to merge
and
into a combined
at least for some variables, because standard model-fitting practice promotes parsimony when statistical significance is not observed. This would be particularly true if for a given variable,
k, neither
nor
statistically differed from 0, but
did. If such collapsing is done, it may still be important to report
and
for comparison to future studies and target potential mechanisms for within- between-subject slope differences as described in
Section 3.
Unfortunately, the within- and between-subject slope decomposition expands required analyses and presentation. Statistical software mostly does not have standard subroutines to do this. Decomposition can be tedious if
is recalculated to maintain orthogonal decomposition of
Xk,ij as new models are fit if observations are excluded from the
Ji due to missing values of newly included variables. The fact that the
are ill-defined by averaging the
Xk,ij rather than being true means for subject
i creates confusion about interpretation of
that can also be influenced by within-subject slopes as was noted in
Section 2B.
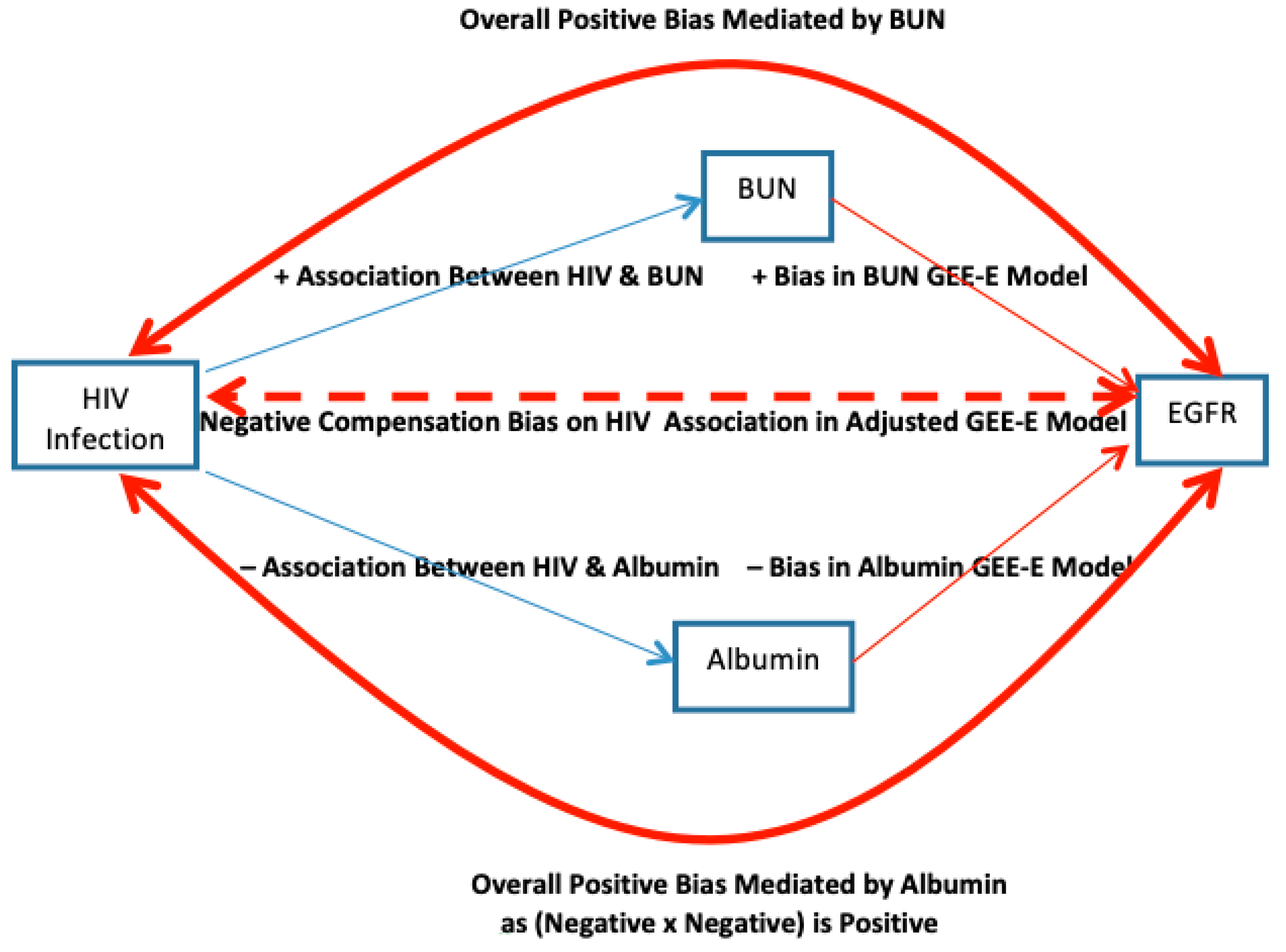
When
and
differ, the causal mechanisms as to why this happens should be explored. For example, in our analysis presented in
Table 2 with EGFR as the outcome, for BUN the between-subject slope
(from GEE-IND) was statistically further from 0 in the expected direction of association than was the within-subject slope
. However, the albumin went the other way: between-subject slope
was statistically closer to 0 than was within-subject slope
with again both slopes being in the expected direction from zero. So what are the potential reasons for this? While lag/reverse-lag causality (
Section 3B,C) between BUN and creatinine (the main component of calculated EGFR) could reduce magnitude of β
BUN,WS vs. β
BUN,BS, this was unlikely given the separation of visits was 6 months and internal biochemistry operates over shorter time periods. However, independent measurement error on BUN (
Section 3G) would temper |β
BUN,WS| towards 0 relative to |β
BUN,BS|. To that end, several articles find greater coefficient of variation [
35,
36], within-person change [
35,
36], assay error [
36], and sample degradation for BUN vs. albumin measures [
37], all of which could reflect BUN having larger independent measurement error than does albumin that would selectively attenuate
towards 0 (i.e., more than it did to
). Conversely, serum creatinine and albumin are both constrained into the intravascular fluid compartment and will non-informatively increase together with greater hydration and decrease with less hydration of this compartment, inducing positively correlated measurement error, as in the case for measured CD4 and CD8 cells in the last paragraph of
Section 3G. As creatinine factors inversely into the EGFR calculation, this would constitute negative correlation of measurement error between albumin and EGFR and selectively bias
to be more negative than
. However, BUN, which crosses across all body compartments, is less subject to such correlation in measurement error with creatinine and thus with EGFR.
As is illustrated in the previous paragraph, we believe that the systematic epidemiological description of reasons for within- and between subject slopes to differ in
Section 3 will provide some basis for future studies to explore this. That may lead to greater recognition and understanding of this phenomenon. However, our list of reasons for these slopes to differ may not be exhaustive. Furthermore, these mechanisms are quite complicated including that limited resources may be available to investigate them in given studies given the other tasks that need to be done and limited funding/personnel.
When between- and within-subject slopes differ,
, it is unclear which is the “least confounded or biased”, including the possibility that by “averaging” the different biases in each would make
be the least biased. There may be a heuristic perception that by “matching within the same subject”,
is superior to
and
, but this is not necessarily true as measurement error in X (
Section 3G) and lag/reverse-lag and spillover causality (
Section 3B–D) can in fact bias
to a larger degree than they do for
and
.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




