Cluster-Based Analysis of Infectious Disease Occurrences Using Tensor Decomposition: A Case Study of South Korea



Abstract
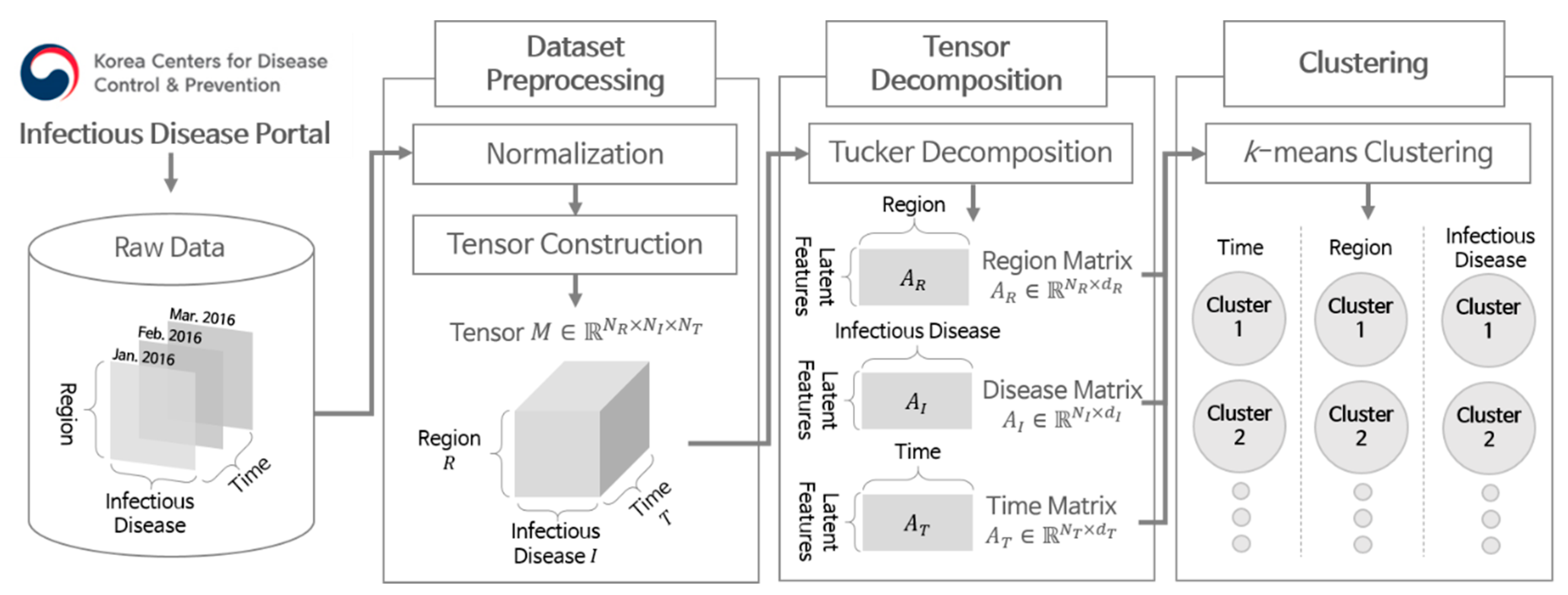
:1. Introduction
- We propose an analysis scheme for infectious disease occurrences based on the Tucker decomposition and k-means clustering by identifying elements with similar patterns of disease occurrence in terms of time, region, and disease.
- We show how to interpret the commonalities and differences between clusters in terms of time, region, and disease. By doing so, we can discover possible factors that can affect the pattern of disease occurrences.
- We reveal the effectiveness of our scheme by conducting a case study on the infectious disease occurrence patterns in South Korea.
2. Methods
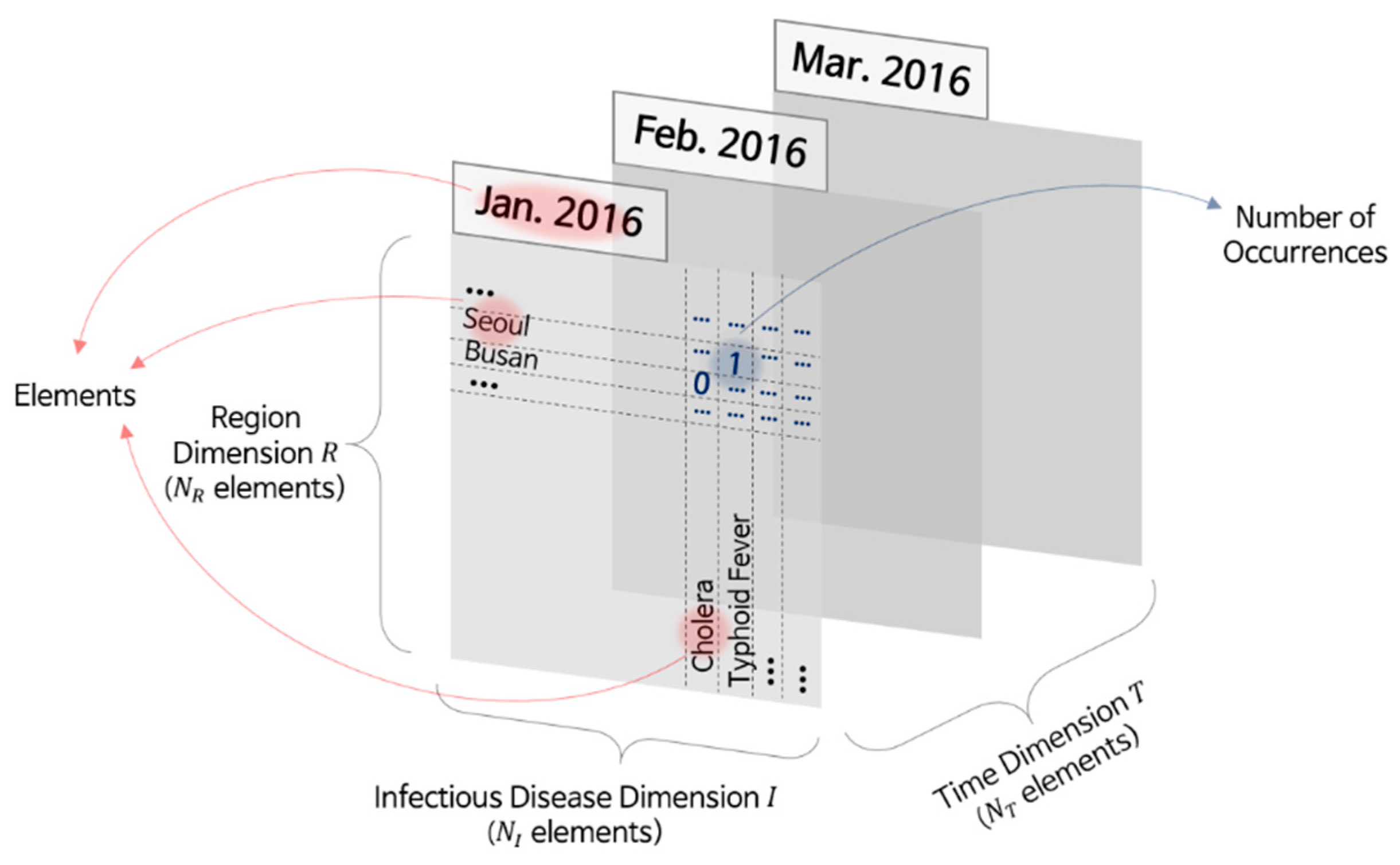
2.1. Dataset Collection and Preprocessing
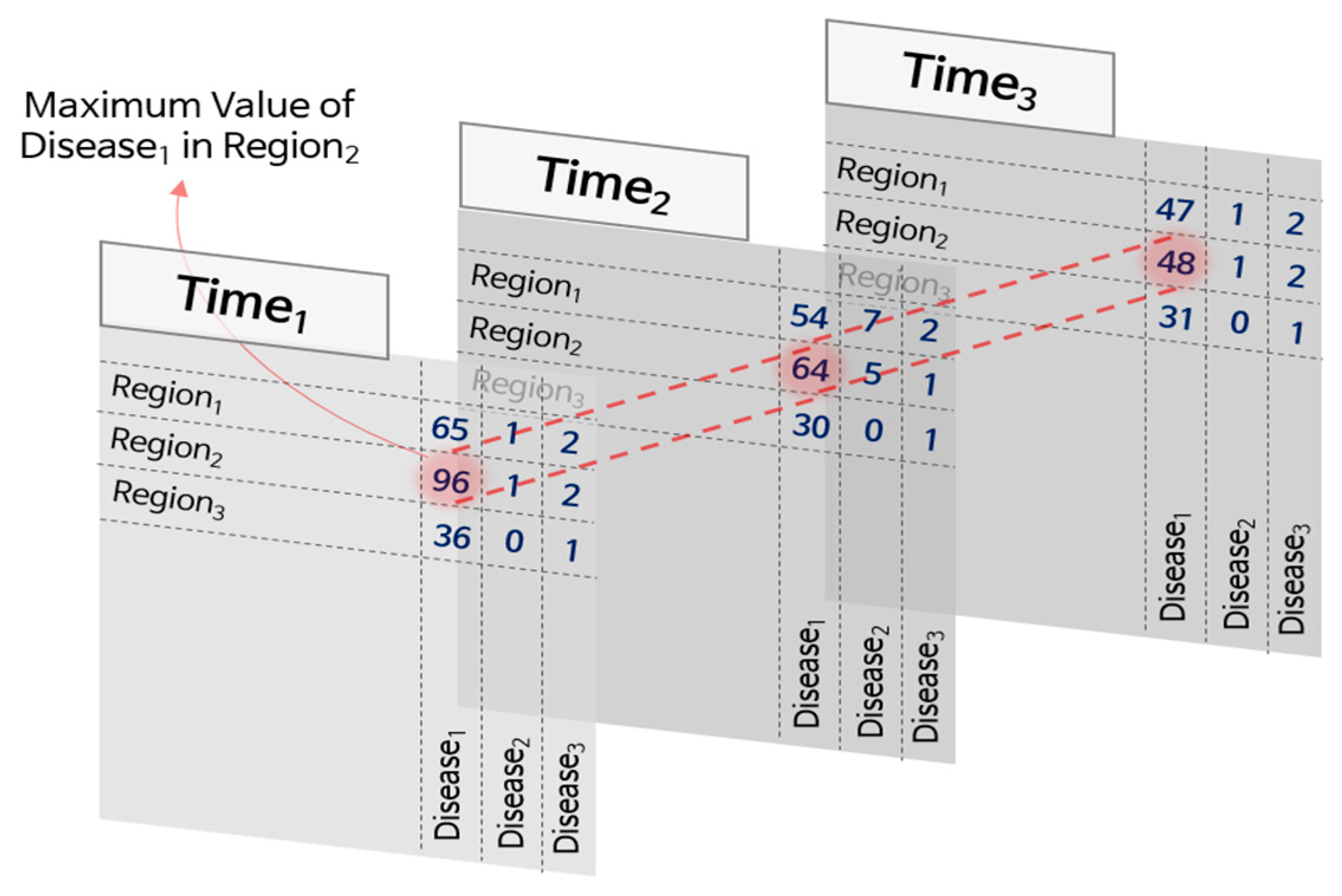
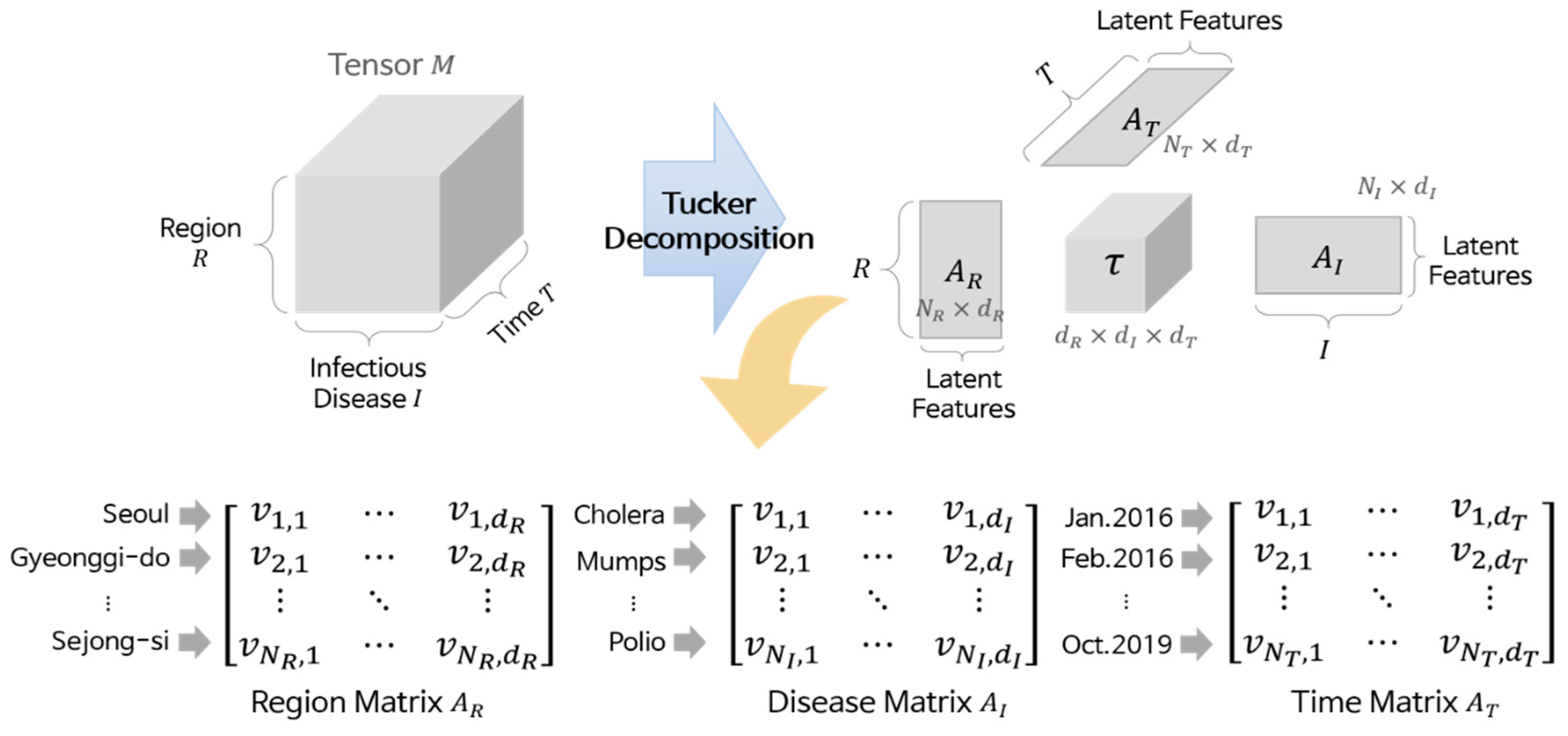
2.2. Tensor Decomposition
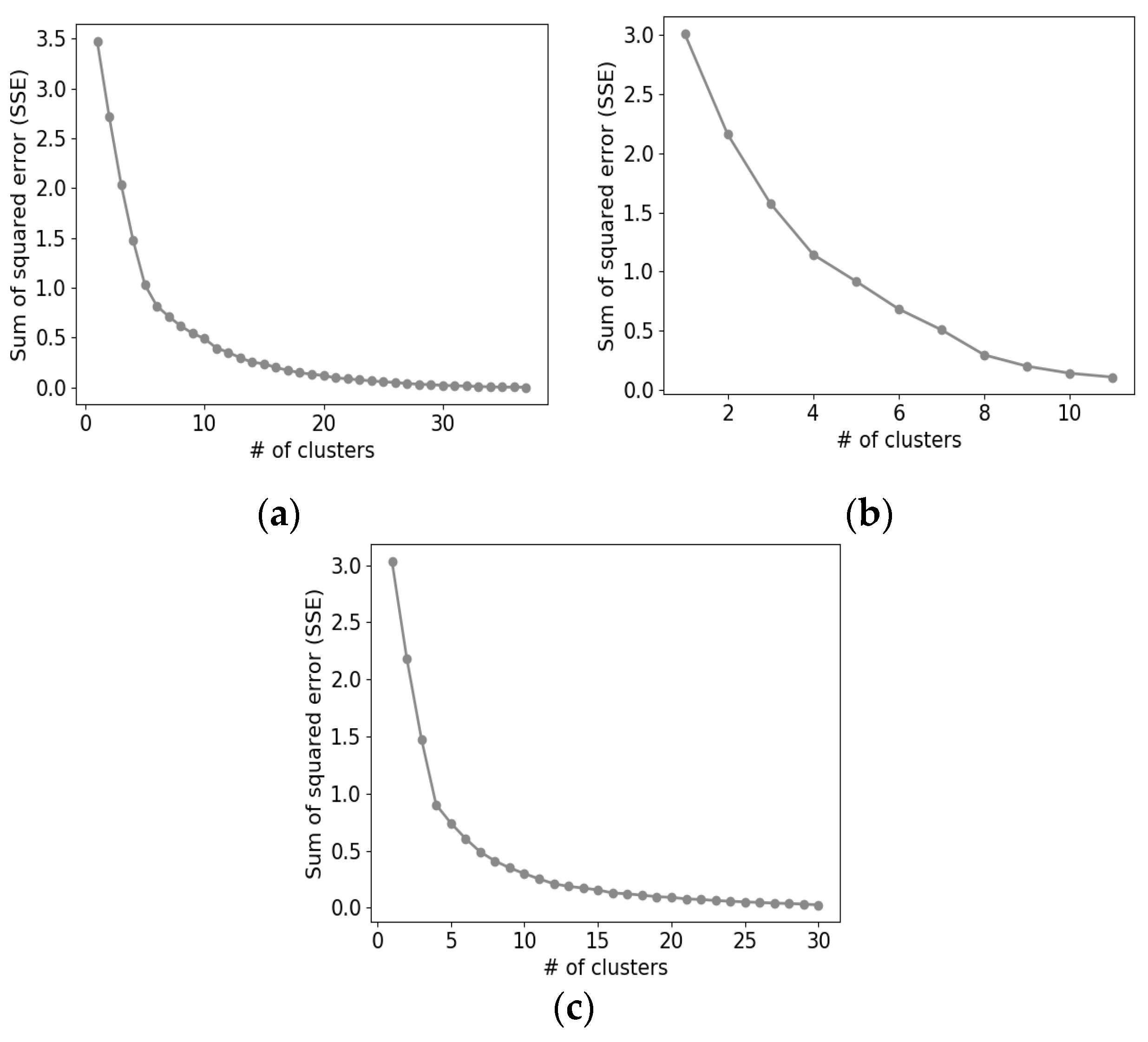
2.3. Clustering
- Acquire all element vectors in D from the matrix AD.
- Set the number of clusters, k.
- Generate center vectors of k clusters randomly.
- For each element vector in D, calculate the Euclidean distances to the center vectors, and obtain the nearest center vector.
- Assign each element vector to the cluster with the nearest center vector.
- Recalculate the center vector of each cluster.
- Repeat Steps 4 to 6 until no more changes occur in the cluster assignment.
3. Results
3.1. Experimental Setup
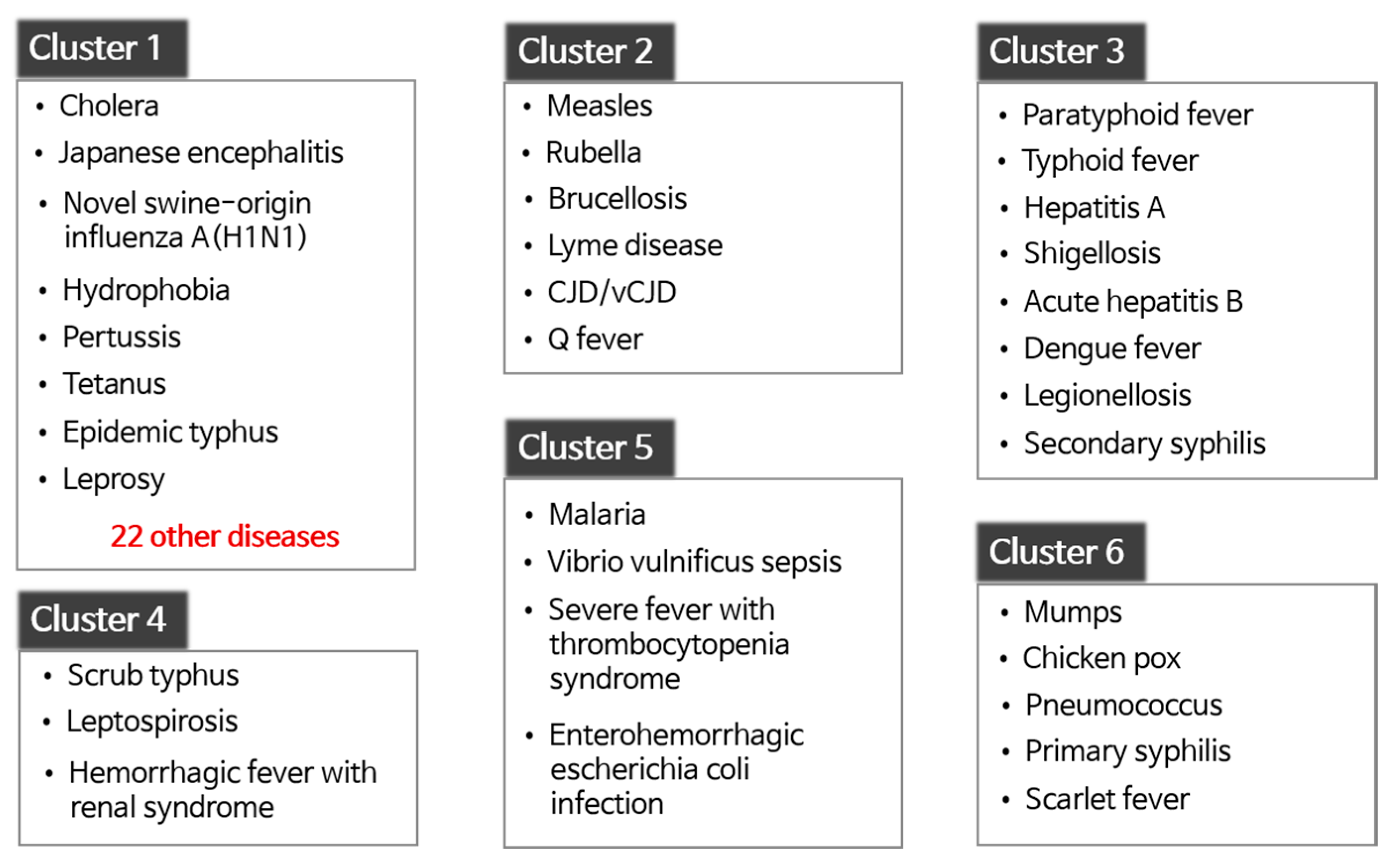
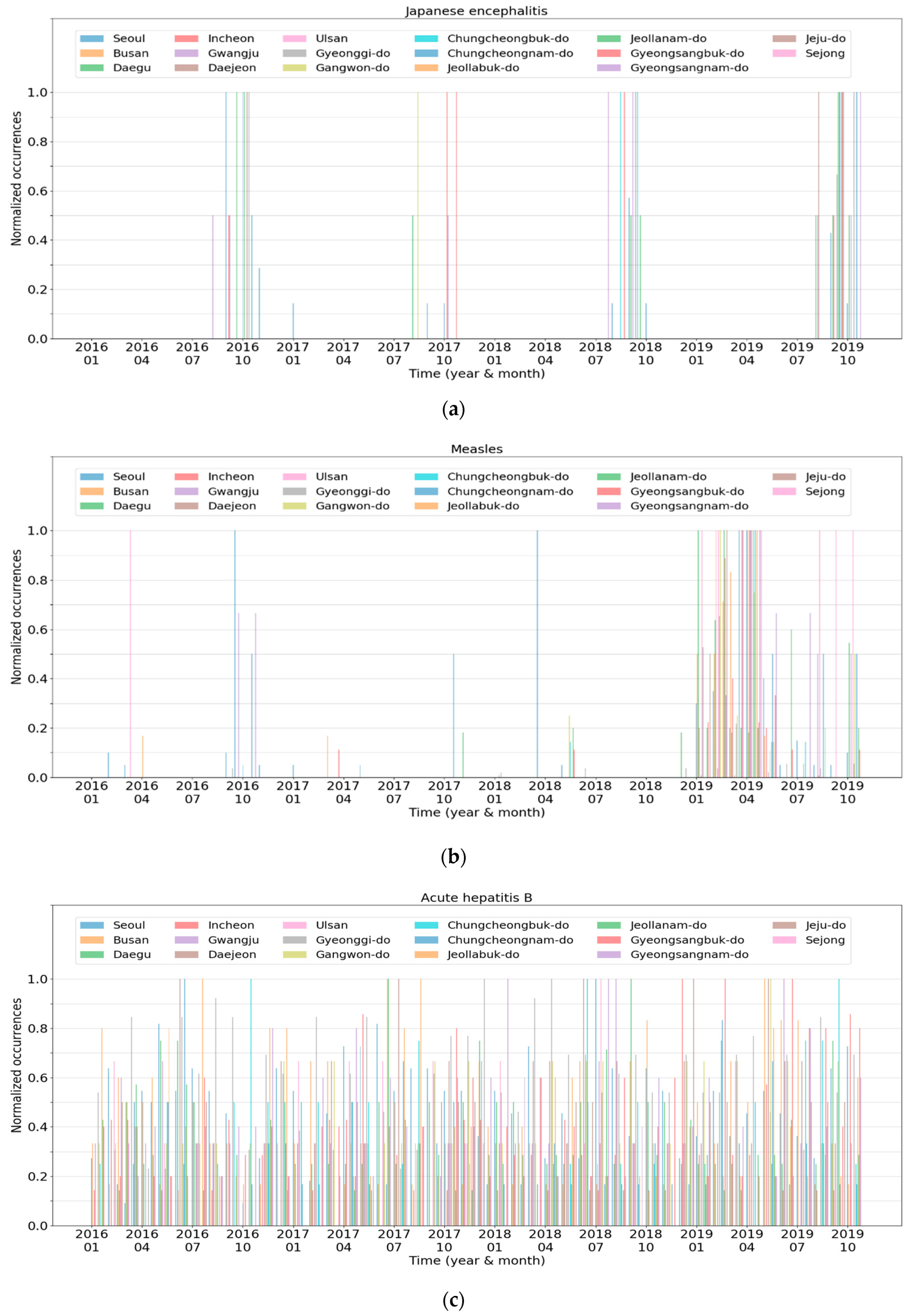
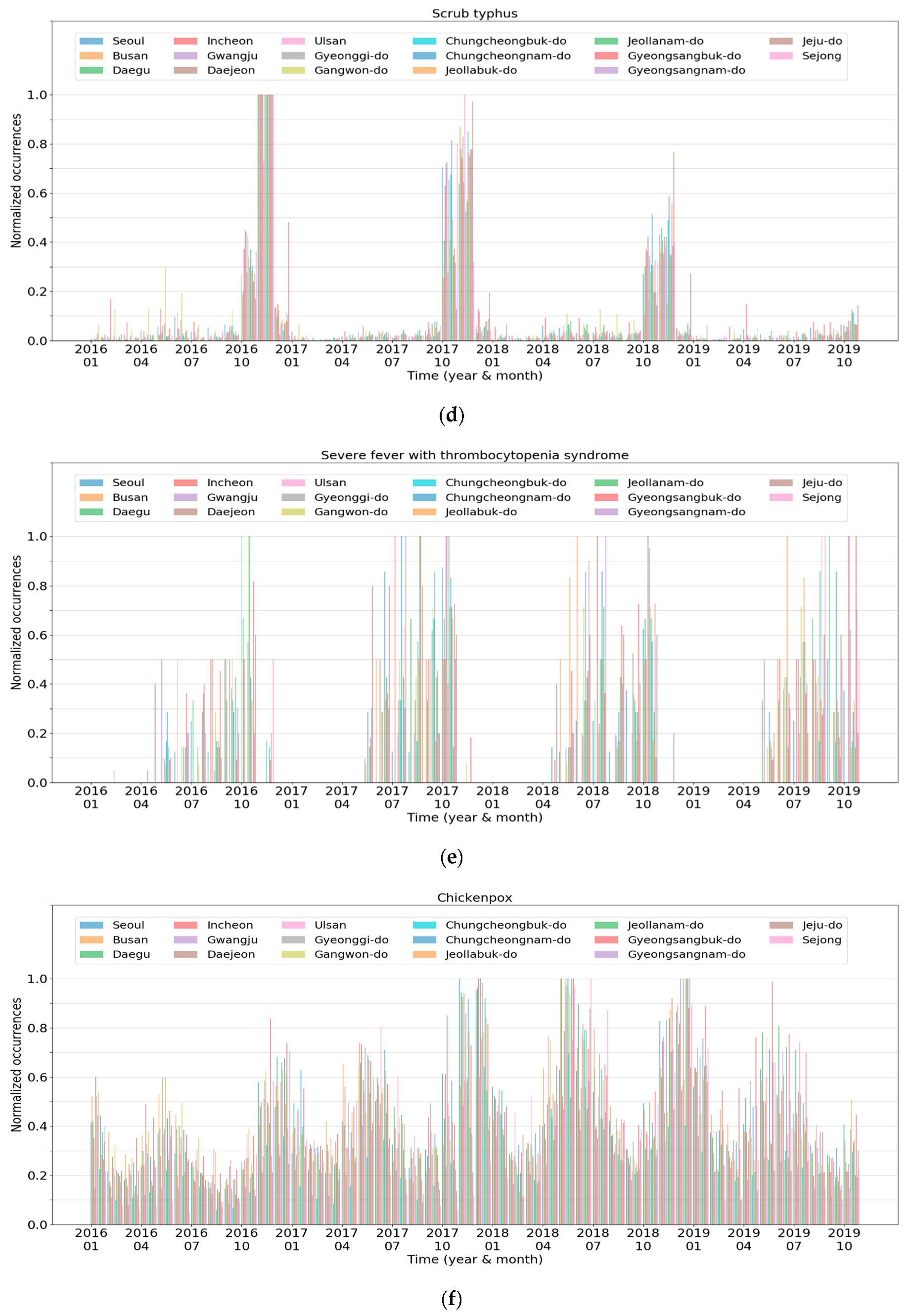
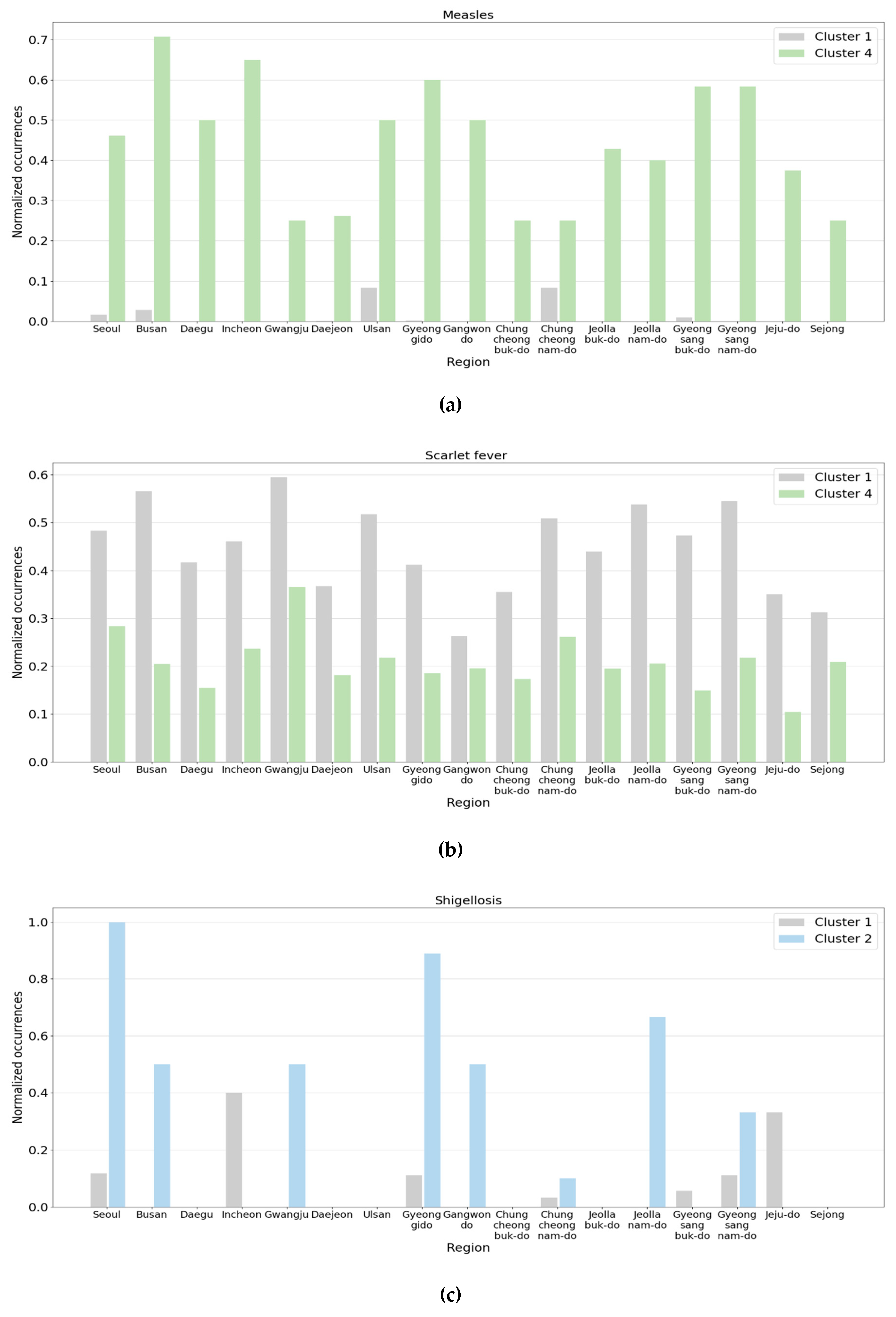
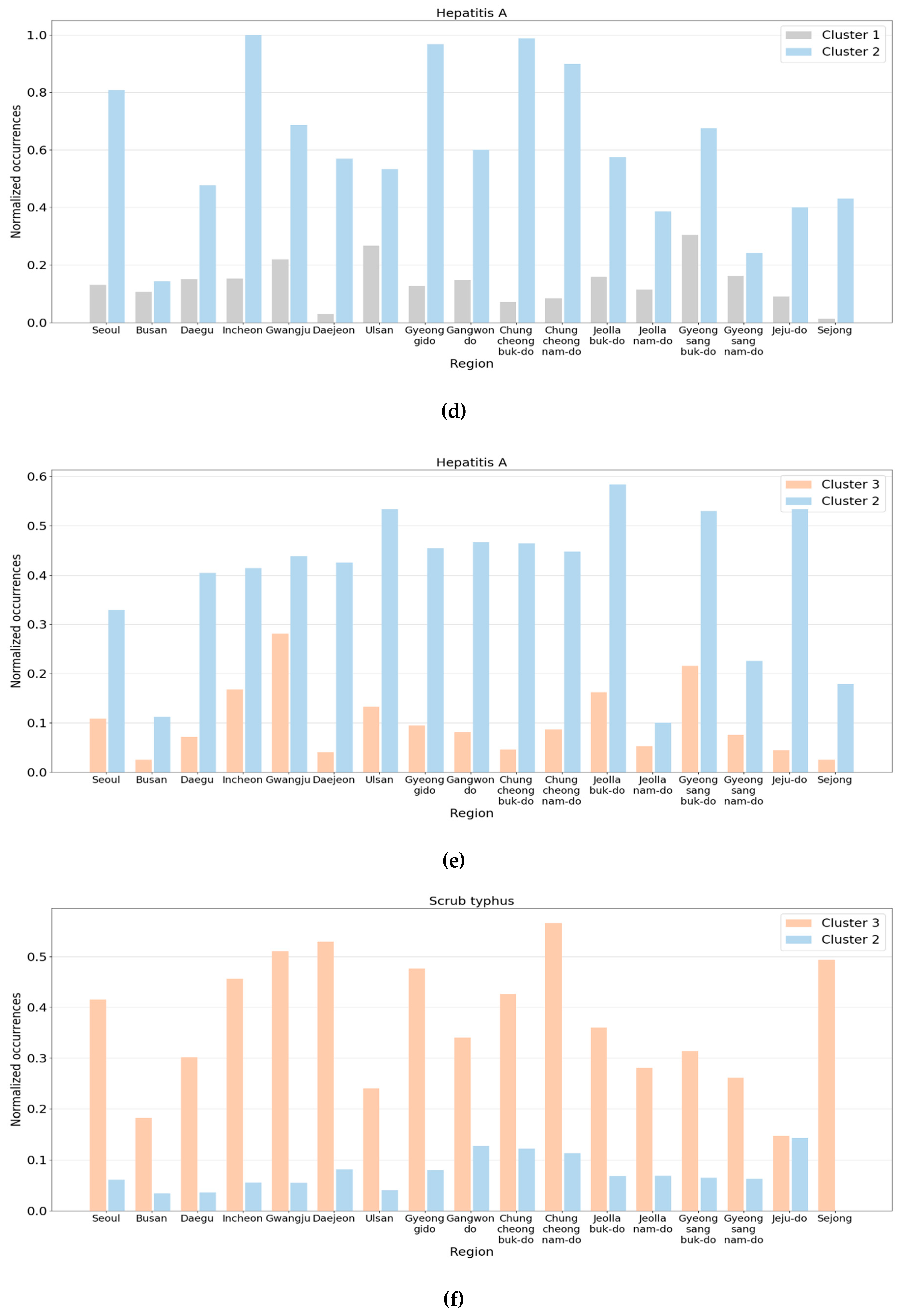
3.2. Analysis of Disease-Based Clustering
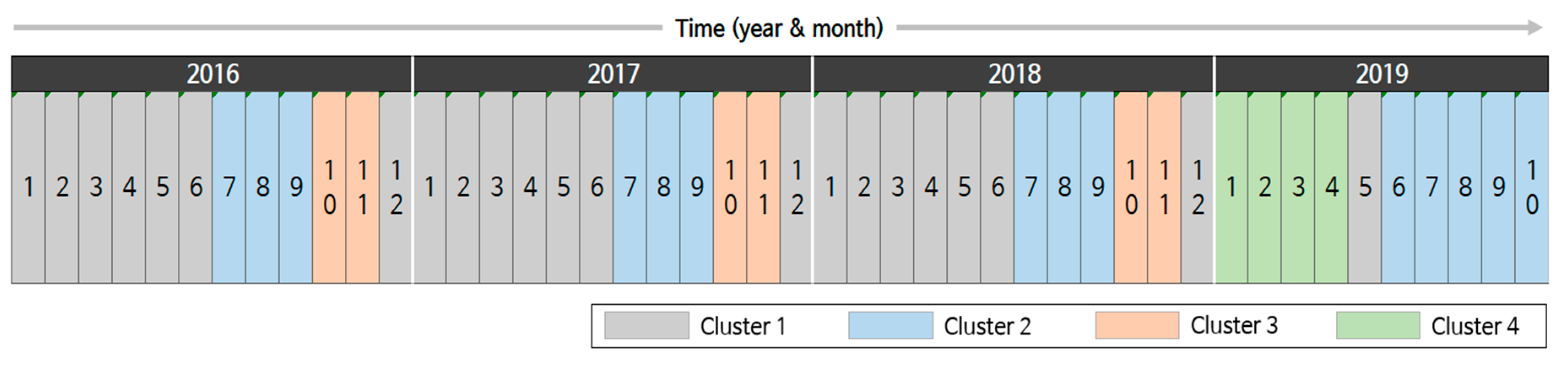
3.3. Analysis of Time-Based Clustering
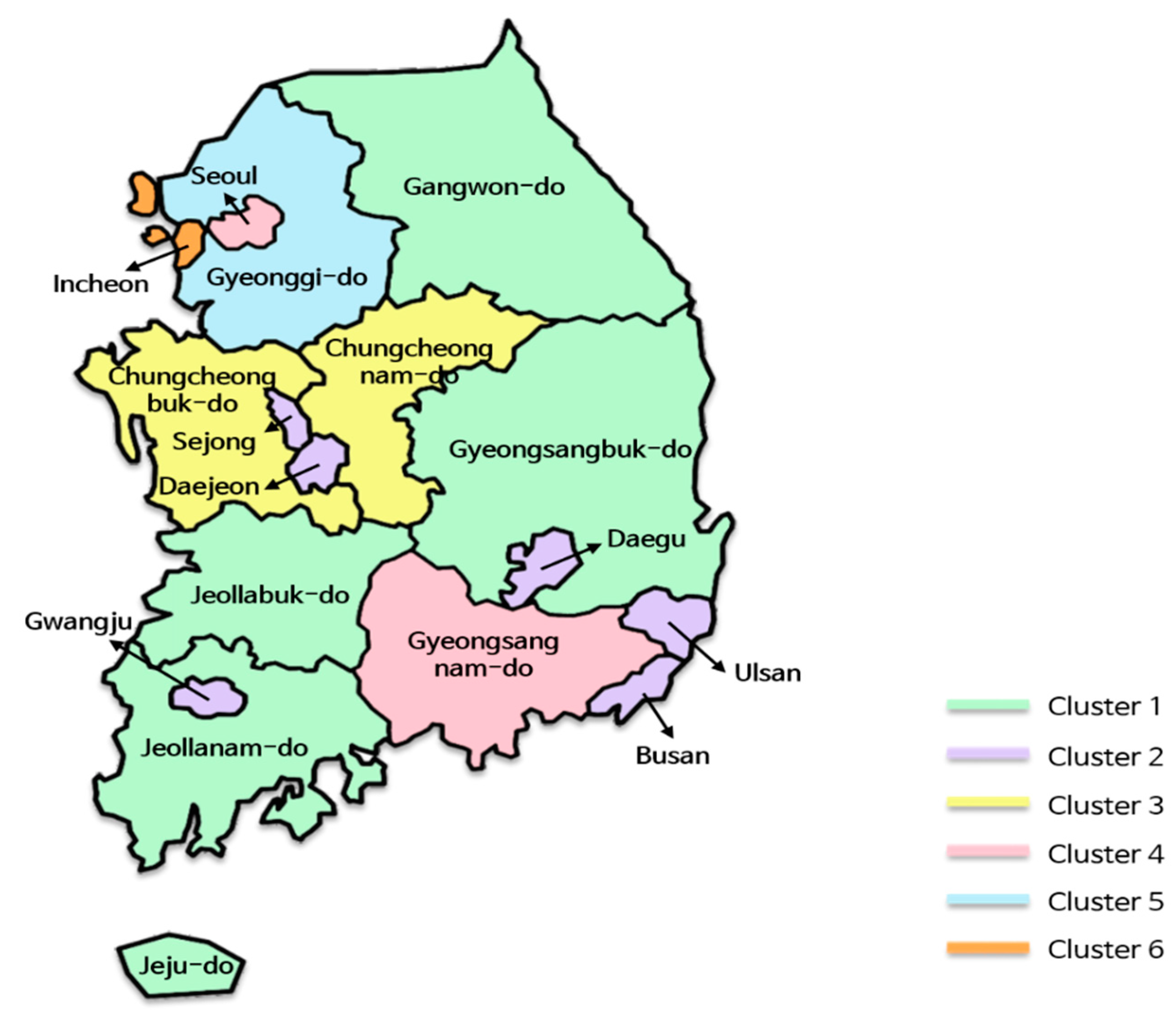
3.4. Analysis of Region-Based Clustering
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Global Health Estimates 2016: Deaths by Cause, Age, Sex, by Country and by Region, 2000–2016. Geneva. Available online: https://www.who.int/healthinfo/global_burden_disease/estimates/en/ (accessed on 7 April 2020).
- Jang, B.; Lee, M.; Kim, J.W. PEACOCK: A Map-Based Multitype Infectious Disease Outbreak Information System. IEEE Access 2019, 7, 82956–82969. [Google Scholar] [CrossRef] [PubMed]
- Qiu, W.; Chu, C.; Mao, A.; Wu, J. The Impacts on Health, Society, and Economy of SARS and H7N9 Outbreaks in China: A Case Comparison Study. J. Environ. Public Health 2018, 2018, 2710185. [Google Scholar] [CrossRef] [PubMed]
- Jia, W.; Wan, Y.; Li, Y.; Tan, K.; Lei, W.; Hu, Y.; Ma, Z.; Li, X.; Xie, G. Integrating Multiple Data Sources and Learning Models to Predict Infectious Diseases in China. In Proceedings of the AMIA Joint Summits on Translational Science, San Francisco, CA, USA, 25–28 March 2019; pp. 680–685. [Google Scholar]
- Area, I.; Batarfi, H.; Losada, J.; Nieto, J.J.; Shammakh, W.; Torres, Á. On a Fractional Order Ebola Epidemic Model. Adv. Differ. Equ. 2015, 2015, 278. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Wu, J.T. Characterizing the Dynamics Underlying Global Spread of Epidemics. Nat. Commun. 2018, 9, 218. [Google Scholar] [CrossRef] [Green Version]
- Kraemer, M.U.G.; Golding, N.; Bisanzio, D.; Bhatt, S.; Pigott, D.M.; Ray, S.E.; Brady, O.J.; Brownstein, J.S.; Faria, N.R.; Cummings, D.A.T.; et al. Utilizing General Human Movement Models to Predict the Spread of Emerging Infectious Diseases in Resource Poor Settings. Sci. Rep. 2019, 9, 5151. [Google Scholar] [CrossRef] [Green Version]
- Junqué de Fortuny, E.; Martens, D.; Provost, F. Predictive Modeling with Big Data: Is Bigger Really Better? Big Data 2013, 1, 215–226. [Google Scholar] [CrossRef]
- Rodó, X.; Pascual, M.; Doblas-Reyes, F.J.; Gershunov, A.; Stone, D.A.; Giorgi, F.; Hudson, P.J.; Kinter, J.; Rodríguez-Arias, M.; Stenseth, N.; et al. Climate Change and Infectious Diseases: Can We Meet the Needs for Better Prediction? Clim. Chang. 2013, 118, 625–640. [Google Scholar] [CrossRef]
- Vazquez-Prokopec, G.M.; Bisanzio, D.; Stoddard, S.T.; Paz-Soldan, V.; Morrison, A.C.; Elder, J.P.; Ramirez-Paredes, J.; Halsey, E.S.; Kochel, T.J.; Scott, T.W.; et al. Using GPS Technology to Quantify Human Mobility, Dynamic Contacts and Infectious Disease Dynamics in a Resource-Poor Urban Environment. PLoS ONE 2013, 8, e58802. [Google Scholar] [CrossRef] [Green Version]
- Goscé, L.; Johansson, A. Analysing the Link between Public Transport Use and Airborne Transmission: Mobility and Contagion in the London Underground. Environ. Health 2018, 17, 84. [Google Scholar] [CrossRef] [Green Version]
- Grassly, N.C.; Fraser, C. Seasonal Infectious Disease Epidemiology. Proc. R. Soc. Lond. B Biol. Sci. 2006, 273, 2541–2550. [Google Scholar] [CrossRef] [Green Version]
- Morse, S.S. Factors in the Emergence of Infectious Diseases. In Plagues and Politics; Palgrave Macmillan: London, UK, 2001; pp. 8–26. [Google Scholar]
- Deyle, E.R.; Maher, M.C.; Hernandez, R.D.; Basu, S.; Sugihara, G. Global Environmental Drivers of Influenza. Proc. Natl. Acad. Sci. USA 2016, 113, 13081–13086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, X.; Lu, Y.; Zhou, S.; Chen, L.; Xu, B. Impact of Climate Change on Human Infectious Diseases: Empirical Evidence and Human Adaptation. Environ. Int. 2016, 86, 14–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, N.; Sun, S.; OuYang, D. Business Process Modeling Abstraction Based on Semi-Supervised Clustering Analysis. Bus. Inf. Syst. Eng. 2018, 60, 525–542. [Google Scholar] [CrossRef]
- Nen-Fu, H.; Hsu, I.; Chia-An, L.; Hsiang-Chun, C.; Jian-Wei, T.; Tung-Te, F. The Clustering Analysis System Based on Students’ Motivation and Learning Behavior. In Proceedings of the 2018 Learning with MOOCS (LWMOOCS), Madrid, Spain, 26–28 September 2018; pp. 117–119. [Google Scholar]
- Durán, A.H.; Greco, T.M.; Vollmer, B.; Cristea, I.M.; Grünewald, K.; Topf, M. Protein Interactions and Consensus Clustering Analysis Uncover Insights into Herpesvirus Virion Structure and Function Relationships. PLoS Biol. 2019, 17, e3000316. [Google Scholar]
- Xiao, X.; Van Hoek, A.J.; Kenward, M.G.; Melegaro, A.; Jit, M. Clustering of Contacts Relevant to the Spread of Infectious Disease. Epidemics 2016, 17, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sloan, C.; Chandrasekhar, R.; Mitchel, E.; Ndi, D.; Miller, L.; Thomas, A.; Bennett, N.M.; Chai, S.; Spencer, M.; Eckel, S.; et al. Spatial and Temporal Clustering of Patients Hospitalized with Laboratory-Confirmed Influenza in the United States. Epidemics 2020, 31, 100387. [Google Scholar] [CrossRef] [PubMed]
- McCloskey, R.M.; Poon, A.F. A Model-Based Clustering Method to Detect Infectious Disease Transmission Outbreaks from Sequence Variation. PLoS Comput. Biol. 2017, 13, e1005868. [Google Scholar] [CrossRef] [Green Version]
- Guilamet, M.C.V.; Bernauer, M.; Micek, S.T.; Kollef, M.H. Cluster Analysis to Define Distinct Clinical Phenotypes among Septic Patients with Bloodstream Infections. Medicine 2019, 98, e15276. [Google Scholar] [CrossRef]
- You, C.Z.; Palade, V.; Wu, X.J. Robust Structure Low-Rank Representation in Latent Space. Eng. Appl. Artif. Intell. 2019, 77, 117–124. [Google Scholar] [CrossRef]
- Zhou, Y.; Gu, K.; Huang, T. Unsupervised Representation Adversarial Learning Network: From Reconstruction to Generation. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Liu, Y.; Jun, E.; Li, Q.; Heer, J. Latent Space Cartography: Visual Analysis of Vector Space Embeddings. Comput. Graph. Forum 2019, 38, 67–78. [Google Scholar] [CrossRef]
- Infectious Disease Portal. Available online: http://www.cdc.go.kr/npt/ (accessed on 7 April 2020).
- Oh, M.D.; Park, W.B.; Park, S.W.; Choe, P.G.; Bang, J.H.; Song, K.H.; Kim, E.S.; Kim, H.B.; Kim, N.J. Middle East Respiratory Syndrome: What We Learned from the 2015 Outbreak in the Republic of Korea. Korean J. Intern. Med. 2018, 33, 233. [Google Scholar] [CrossRef] [PubMed]
- Gahrooei, M.R.; Yan, H.; Paynabar, K.; Shi, J. Multiple Tensor-on-Tensor Regression: An Approach for Modeling Processes with Heterogeneous Sources of Data. Technometrics 2020, 1–23. [Google Scholar] [CrossRef]
- Xia, S.; Jiang, H.; Zhang, Y.; Peng, D. Internet Advertising Investment Analysis Based on Beijing and Jinhua Signaling Data. In Proceedings of the 2019 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), New York, NY, USA, 1–3 August 2019; pp. 419–426. [Google Scholar]
- Mitenkova, A.; Kossaifi, J.; Panagakis, Y.; Pantic, M. Valence and Arousal Estimation In-The-Wild with Tensor Methods. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–7. [Google Scholar]
- Ratre, A.; Pankajakshan, V. Tucker Tensor Decomposition-Based Tracking and Gaussian Mixture Model for Anomaly Localisation and Detection in Surveillance Videos. IET Comput. Vis. 2018, 12, 933–940. [Google Scholar] [CrossRef]
- Cong, F.; Lin, Q.H.; Kuang, L.D.; Gong, X.F.; Astikainen, P.; Ristaniemi, T. Tensor Decomposition of EEG Signals: A Brief Review. J. Neurosci. Methods 2015, 248, 59–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Han, Y.; Jiang, J. Tucker Decomposition-Based Tensor Learning for Human Action Recognition. Multimed. Syst. 2016, 22, 343–353. [Google Scholar] [CrossRef]
- Chen, H.; Li, J. Modeling Relational Drug-Target-Disease Interactions via Tensor Factorization with Multiple Web Sources. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 218–227. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. On the Best Rank-1 and Rank-(r1, r2,…,rn) Approximation of Higher-Order Tensors. SIAM J. Matrix Anal. Appl. 2000, 21, 1324–1342. [Google Scholar] [CrossRef]
- Janson, S.; Merkle, D.; Middendorf, M. Molecular Docking with Multi-Objective Particle Swarm Optimization. Appl. Soft Comput. 2008, 8, 666–675. [Google Scholar] [CrossRef]
- Sesto-Castilla, D.; Garcia-Villegas, E.; Lyberopoulos, G.; Theodoropoulou, E. Use of Machine Learning for Energy Efficiency in Present and Future Mobile Networks. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakech, Morocco, 15–19 April 2019; pp. 1–6. [Google Scholar]
- Raykov, Y.P.; Boukouvalas, A.; Baig, F.; Little, M.A. What to Do When K-means Clustering Fails: A Simple Yet Principled Alternative Algorithm. PLoS ONE 2016, 11, e0162259. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, J.; Zhou, C.; Zhang, Q. Installation Planning in Regional Thermal Power Industry for Emissions Reduction Based on an Emissions Inventory. Int. J. Environ. Res. Public Health 2019, 16, 938. [Google Scholar] [CrossRef] [Green Version]
- Bholowalia, P.; Kumar, A. EBK-means: A Clustering Technique Based on Elbow Method and K-means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Kossaifi, J.; Panagakis, Y.; Anandkumar, A.; Pantic, M. Tensorly: Tensor Learning in Python. J. Mach. Learn. Res. 2019, 20, 925–930. [Google Scholar]
- Wesolowski, A.; Zu Erbach-Schoenberg, E.; Tatem, A.J.; Lourenço, C.; Viboud, C.; Charu, V.; Eagle, N.; Engø-Monsen, K.; Qureshi, T.; Buckee, C.O.; et al. Multinational Patterns of Seasonal Asymmetry in Human Movement Influence Infectious Disease Dynamics. Nat. Commun. 2017, 8, 2069. [Google Scholar] [CrossRef] [PubMed]
- Neiderud, C.J. How Urbanization Affects the Epidemiology of Emerging Infectious Diseases. Infect. Ecol. Epidemiol. 2015, 5, 27060. [Google Scholar] [CrossRef]
- Feikin, D.R.; Olack, B.; Bigogo, G.M.; Audi, A.; Cosmas, L.; Aura, B.; Burke, H.; Njenga, M.K.; Williamson, J.; Breiman, R.F. The Burden of Common Infectious Disease Syndromes at the Clinic and Household Level from Population-Based Surveillance in Rural and Urban Kenya. PLoS ONE 2011, 6, e16085. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Infectious Disease | # | Infectious Disease |
|---|---|---|---|
| 1 | Cholera | 29 | Paratyphoid fever |
| 2 | Enterohemorrhagic Escherichia coli infection | 30 | Diphtheria |
| 3 | Tetanus | 31 | Mumps |
| 4 | Polio | 32 | Chickenpox |
| 5 | Haemophilus influenzae type b | 33 | Malaria |
| 6 | Leprosy | 34 | Legionellosis |
| 7 | Epidemic typhus | 35 | Scrub typhus |
| 8 | Brucellosis | 36 | Hydrophobia |
| 9 | Primary syphilis | 37 | Congenital syphilis |
| 10 | Plague | 38 | Dengue fever |
| 11 | Smallpox | 39 | Severe acute respiratory syndrome |
| 12 | Novel swine-origin influenza A(H1N1) | 40 | Q fever |
| 13 | Lyme disease | 41 | Melioidosis |
| 14 | Emerging infectious diseases | 42 | Middle East respiratory syndrome coronavirus |
| 15 | Typhoid fever | 43 | Shigellosis |
| 16 | Hepatitis A | 44 | Pertussis |
| 17 | Measles | 45 | Rubella |
| 18 | Japanese encephalitis | 46 | Acute hepatitis B |
| 19 | Pneumococcus | 47 | Scarlet fever |
| 20 | Neisseria meningitidis | 48 | Vibrio vulnificus sepsis |
| 21 | Murine typhus | 49 | Leptospirosis |
| 22 | Anthrax | 50 | Hemorrhagic fever with renal syndrome |
| 23 | Secondary syphilis | 51 | Creutzfeldt–Jakob disease (CJD)/variant CJD |
| 24 | Yellow fever | 52 | Viral hemorrhagic fevers |
| 25 | Botulinum toxin | 53 | Avian influenza |
| 26 | Tularemia | 54 | West Nile fever |
| 27 | Tick-borne viral encephalitis | 55 | Chikungunya fever |
| 28 | Severe fever with thrombocytopenia syndrome | 56 | Zika virus infection |
| # | Region | # | Region |
|---|---|---|---|
| 1 | Seoul | 10 | Chungcheongbuk-do |
| 2 | Busan | 11 | Chungcheongnam-do |
| 3 | Daegu | 12 | Jeollabuk-do |
| 4 | Incheon | 13 | Jeollanam-do |
| 5 | Gwangju | 14 | Gyeongsangbuk-do |
| 6 | Daejeon | 15 | Gyeongsangnam-do |
| 7 | Ulsan | 16 | Jeju-do |
| 8 | Gyeonggi-do | 17 | Sejong |
| 9 | Gangwon-do |
| Variable | Description | Value |
|---|---|---|
| NR | The number of elements in the region dimension | 17 |
| NI | The number of elements in the infectious disease dimension | 56 |
| NT | The number of elements in the time dimension | 46 |
| dR | The number of latent features in the region dimension | 4 |
| dI | The number of latent features in the infectious disease dimension | 4 |
| dT | The number of latent features in the time dimension | 4 |
| kR | The number of clusters in the region dimension | 6 |
| kI | The number of clusters in the infectious disease dimension | 6 |
| kT | The number of clusters in the time dimension | 4 |
| Cluster | Region | Features | |||
|---|---|---|---|---|---|
| F1 | F2 | F3 | F4 | ||
| 1 | Gangwon-do | 0.218 | −0.153 | 0.269 | −0.212 |
| Gyeongsangbuk-do | 0.258 | −0.065 | 0.285 | −0.233 | |
| Jeollabuk-do | 0.234 | −0.256 | 0.147 | −0.210 | |
| Jeollanam-do | 0.216 | −0.139 | −0.045 | −0.392 | |
| Jeju-do | 0.177 | −0.117 | −0.182 | −0.335 | |
| Average | 0.220 | −0.146 | 0.095 | −0.277 | |
| 2 | Daejeon | 0.216 | −0.047 | 0.004 | 0.193 |
| Daegu | 0.243 | −0.044 | −0.162 | −0.034 | |
| Gwangju | 0.201 | −0.176 | −0.098 | 0.238 | |
| Busan | 0.257 | −0.044 | −0.327 | −0.127 | |
| Ulsan | 0.214 | −0.093 | −0.392 | 0.314 | |
| Sejong | 0.132 | −0.587 | −0.192 | 0.136 | |
| Average | 0.211 | −0.165 | −0.194 | 0.120 | |
| 3 | Chungcheongbuk-do | 0.205 | −0.098 | 0.256 | 0.250 |
| Chungcheongnam-do | 0.261 | −0.187 | 0.396 | 0.186 | |
| Average | 0.233 | −0.143 | 0.326 | 0.218 | |
| 4 | Seoul | 0.331 | 0.305 | −0.003 | 0.352 |
| Gyeongsangnam-do | 0.261 | 0.201 | −0.178 | 0.184 | |
| Average | 0.296 | 0.253 | −0.091 | 0.268 | |
| 5 | Gyeonggi-do | 0.337 | 0.420 | 0.318 | −0.025 |
| 6 | Incheon | 0.276 | 0.359 | −0.319 | −0.326 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, S.; Moon, J.; Hwang, E. Cluster-Based Analysis of Infectious Disease Occurrences Using Tensor Decomposition: A Case Study of South Korea. Int. J. Environ. Res. Public Health 2020, 17, 4872. https://doi.org/10.3390/ijerph17134872
Jung S, Moon J, Hwang E. Cluster-Based Analysis of Infectious Disease Occurrences Using Tensor Decomposition: A Case Study of South Korea. International Journal of Environmental Research and Public Health. 2020; 17(13):4872. https://doi.org/10.3390/ijerph17134872
Chicago/Turabian StyleJung, Seungwon, Jaeuk Moon, and Eenjun Hwang. 2020. "Cluster-Based Analysis of Infectious Disease Occurrences Using Tensor Decomposition: A Case Study of South Korea" International Journal of Environmental Research and Public Health 17, no. 13: 4872. https://doi.org/10.3390/ijerph17134872
APA StyleJung, S., Moon, J., & Hwang, E. (2020). Cluster-Based Analysis of Infectious Disease Occurrences Using Tensor Decomposition: A Case Study of South Korea. International Journal of Environmental Research and Public Health, 17(13), 4872. https://doi.org/10.3390/ijerph17134872