Machine Learning-Based Activity Pattern Classification Using Personal PM2.5 Exposure Information



Abstract
:1. Introduction
2. Methods and Materials
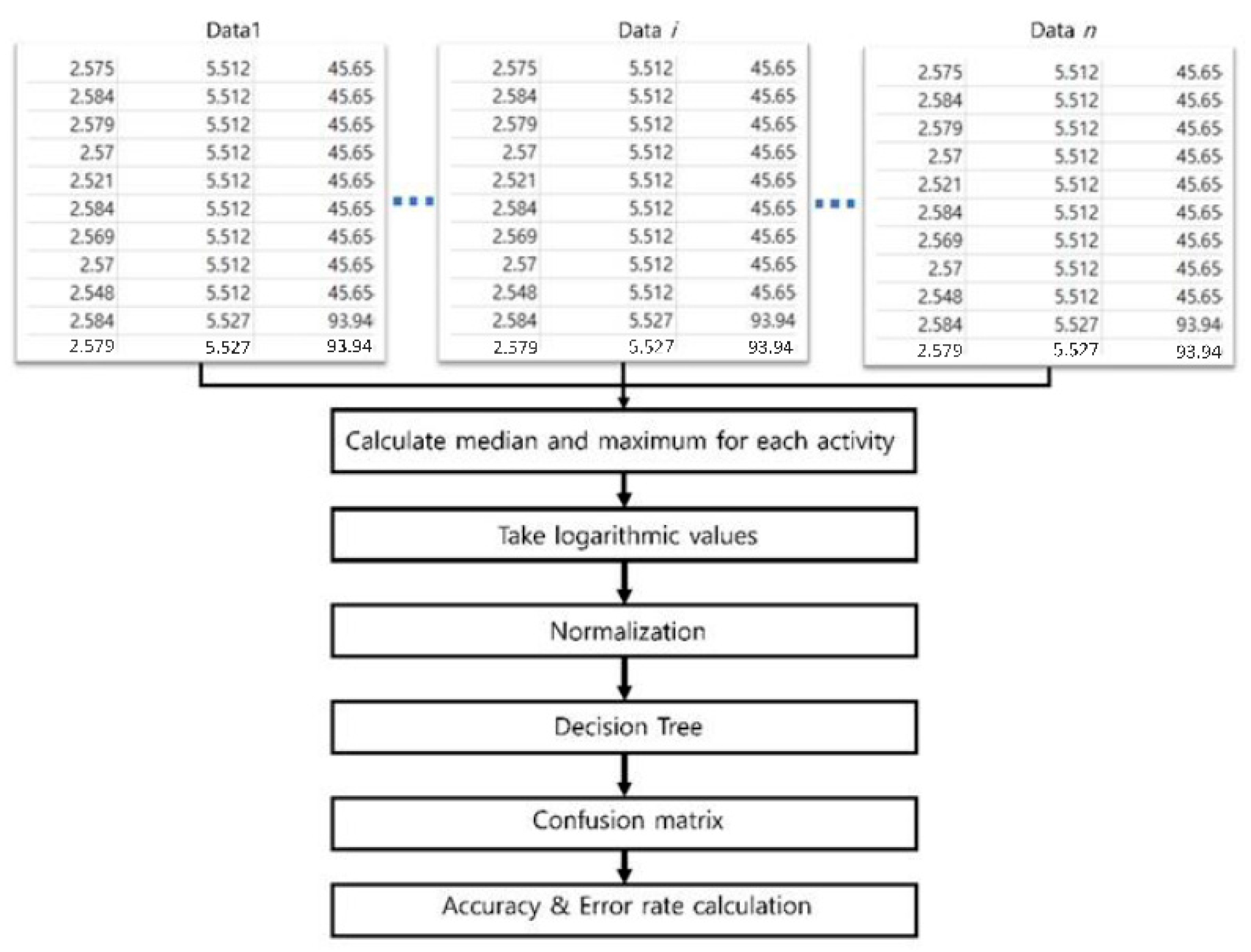
2.1. Machine-Learning-Based Activity-Pattern Detection
2.2. Strategy for Obtaining Training Data
2.3. Data Analysis with Decision-Tree-Based Classfication
2.4. Dataset and Experimental Setup
3. Results
3.1. Features for Classification
3.2. Logarithmic Transformation of Data
3.3. Experiments Using a Real PM2.5 Dataset
3.4. Experiments Using Statistical PM2.5 Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Klepeis, N.E.; Nelson, W.C.; Ott, W.R.; Robinson, J.P.; Tsang, A.M.; Switzer, P.; Behar, J.V.; Hern, S.C.; Engelmann, W.H. The National Human Activity Pattern Survey (NHAPS): A resource for assessing exposure to environmental pollutants. J. Expo. Sci. Environ. Epidemiol. 2001, 11, 231–252. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, J.; Zhang, S.; Xia, L.; Yu, Y.; Hu, S.; Sun, J.; Zhou, P.; Chen, P. Physical activity, a critical exposure factor of environmental pollution in children and adolescents health risk assessment. Int. J. Environ. Res. Public Health 2018, 15, 176. [Google Scholar] [CrossRef] [Green Version]
- Lima, W.S.; Souto, E.; El-Khatib, K.; Jalali, R.; Gama, J. Human activity recognition using inertial sensors in a smartphone: An overview. Sensors 2019, 19, 3213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ehatisham-Ul-Haq, M.; Azam, M.A. Opportunistic sensing for inferring in-the-wild human contexts based on activity pattern recognition using smart computing. Future. Gener. Comput. Syst. 2020, 106, 374–392. [Google Scholar] [CrossRef]
- Pires, I.M.; Marques, G.; Garcia, N.M.; Flórez-Revuelta, F.; Teixeira, M.C.; Zdravevski, E.; Spinsante, S.; Coimbra, M.T. Pattern recognition techniques for the identification of activities of daily living using a mobile device accelerometer. Electronics 2020, 9, 509. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.M.; Tufail, A.; Khattak, A.M.; Laine, T.H. Activity recognition on smartphones via sensor-fusion and KDA-Based SVMs. Int. J. Distrib. Sens. Netw. 2014, 10, 1–16. [Google Scholar] [CrossRef]
- Reddy, S.; Mun, M.; Burke, J.; Estrin, D.; Hansen, M.; Srivastava, M. Using mobile phones to determine transportation modes. ACM Trans. Sens. Netw. 2010, 6, 1–27. [Google Scholar] [CrossRef]
- Martín, H.; Bernardos, A.M.; Iglesias, J.; Casar, J.R. Activity logging using lightweight classification techniques in mobile devices. Pers. Ubiquitous Comput. 2012, 17, 675–695. [Google Scholar] [CrossRef]
- Das, B.; Seelye, A.M.; Thomas, B.L.; Cook, D.J.; Holder, L.B.; Schmitter-Edgecombe, M. Using smart phones for context-aware prompting in smart environments. In Proceedings of the 2012 IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 399–403. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Time series classification using multi-channels deep convolutional neural networks. In Proceedings of the Conference on Web-Age Information Management, Macau, China, 16–18 June 2014; Springer: Cham, Switzerland, 2014; pp. 298–310. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Zhang, L.; Liu, Z.; Liu, K.; Li, X.; Liu, Y. Lasagna: Towards deep hierarchical understanding and searching over mobile sensing data. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 3–7 October 2016; pp. 334–347. [Google Scholar]
- Li, F.; Shirahama, K.; Nisar, M.A.; Koping, L.; Grzegorzek, M.; Li, F. Comparison of feature learning methods for human activity recognition using wearable sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef] [Green Version]
- Almaslukh, B.; Almuhtadi, J.; Artoli, A. An effective deep autoencoder approach for online smartphone-based human activity recognition. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 160–165. [Google Scholar]
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep activity recognition models with triaxial accelerometers. In Proceedings of the Workshops of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–13 February 2016; pp. 8–13. [Google Scholar]
- Hafezi, M.H.; Liu, L.; Millward, H. A time-use activity-pattern recognition model for activity-based travel demand modeling. Transportation 2017, 46, 1369–1394. [Google Scholar] [CrossRef]
- Rasouli, S.; Timmermans, H. Activity-based models of travel demand: Promises, progress and prospects. Int. J. Urban Sci. 2013, 18, 31–60. [Google Scholar] [CrossRef]
- Wu, Y.; Song, G. The impact of activity-based mobility pattern on assessing fine-grained traffic-induced air pollution exposure. Int. J. Environ. Res. Public Health 2019, 16, 3291. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, S.-H.; Ihm, S.-Y.; Park, Y.-H.; Lee, W.; Choi, W.; Jung, S.; Song, M. A study on adjustable dissimilarity measure for efficient piano learning. In Proceedings of the 7th International Conference on Emerging Databases, Busan, Korea, 14 October 2017; pp. 111–118. [Google Scholar]
- Sajid, S.; Von Zernichow, B.M.; Soylu, A.; Roman, D. Predictive data transformation suggestions in grafterizer using machine learning. In Proceedings of the 13th International Conference MTSR 2019, Rome, Italy, 28–31 October 2019; pp. 137–149. [Google Scholar]
- Narita, M.; Igarashi, T. Programming-by-example for data transformation to improve machine learning performance. In Proceedings of the IUI 2019, Los Angeles, CA, USA, 17–20 March 2019. [Google Scholar]
- Jin, Z.; Anderson, M.R.; Cafarella, M.; Jagadish, H.V. Foofah: A programming-by-example system for synthesizing data transformation programs. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017. [Google Scholar] [CrossRef] [Green Version]
- Utgoff, P.E. Incremental induction of decision trees. Mach. Learn. 1989, 4, 161–186. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1993. [Google Scholar]
- Gordon, A.D.; Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman & Hall/CRC: New York, NY, USA, 1984. [Google Scholar]
- Chi-Square Automatic Interaction Detection. Available online: https://en.wikipedia.org/wiki/Chi-square_automatic_interaction_detection (accessed on 17 March 2020).
- Friedman, J.H. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Hothorn, T.; Hornik, K.; Zeileis, A. Ctree: Conditional Inference Trees. The Comprehensive R Archive Network. 2015. Available online: https://cran.r-project.org/web/packages/partykit/vignettes/ctree.pdf (accessed on 17 March 2020).
- Decision Tree Ensembles—Bagging and Boosting. Available online: https://towardsdatascience.com/decision-tree-ensembles-bagging-and-boosting-266a8ba60fd9 (accessed on 17 March 2020).
- Tutorial The Gini Impurity Index and What It Means and How to Calculate It. Available online: https://www.researchgate.net/publication/327110793_Tutorial_The_Gini_Impurity_index_and_what_it_means_and_how_to_calculate_it (accessed on 17 March 2020).
- A Simple Explanation of Information Gain and Entropy. Available online: https://victorzhou.com/blog/information-gain/ (accessed on 17 March 2020).
- Woo, J.; Rudasingwa, G.; Kim, S.R. Assessment of daily personal PM2.5 exposure level according to four major activities among children. Appl. Sci. 2019, 10, 159. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Kim, S.R. Improved interpolation and anomaly detection for personal PM2.5 measurement. Appl. Sci. 2020, 10, 543. [Google Scholar] [CrossRef] [Green Version]
- Rousseeuw, P.; Hubert, M. Robust statistics for outlier detection. WIREs Data Min. Knowl. Discov. 2011, 1, 73–79. [Google Scholar] [CrossRef]
- Hussain, G.; Maheshwari, M.K.; Memon, M.L.; Jabbar, M.S.; Khan, M.K.J. A CNN based automated activity and food recognition using wearable sensor for preventive healthcare. Electronics 2019, 8, 1425. [Google Scholar] [CrossRef] [Green Version]
- Amancio, D.R.; Comin, C.H.; Casanova, D.; Travieso, G.; Bruno, O.M.; Rodrigues, F.A.; Costa, L.D.F. A systematic comparison of supervised classifiers. PLoS ONE 2014, 9, e94137. [Google Scholar] [CrossRef] [PubMed]
- Tantithamthavorn, C.; McIntosh, S.; Hassan, A.E.; Matsumoto, K. Automated parameter optimization of classification techniques for defect prediction models. In Proceedings of the ICSE’16, Austin, TX, USA, 14–22 May 2016; Volume 16, pp. 321–332. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Contents | Details |
|---|---|---|
| 1 | No. of activity patterns | 9 |
| 2 | No. of features | 4 |
| 3 | No. of observations | 142,654 |
| 4 | Features to use | Raw PM2.5, median and max of PM2.5, temperature, humidity |
| 5 | Type of classifier | decision tree |
| 6 | Training to test data ratio | 8:2 (with replacement) |
| 7 | R packages | Stringr, dplyr, party |
| Predicted | Actual | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bus | Car | Commercial Building | Cooking | Education Building | Indoor-House | Outdoor | Restaurant | Walking | Total | |
| Bus | 89 | 1 | 19 | 0 | 7 | 27 | 0 | 0 | 4 | 147 |
| Car | 1 | 540 | 114 | 1 | 62 | 122 | 0 | 6 | 4 | 850 |
| Commercial building | 54 | 115 | 3194 | 8 | 243 | 986 | 0 | 3 | 149 | 4752 |
| Cooking | 0 | 1 | 5 | 184 | 19 | 74 | 1 | 0 | 3 | 287 |
| Education building | 69 | 397 | 291 | 33 | 9954 | 3216 | 25 | 4 | 249 | 14,238 |
| Indoor-house | 310 | 1036 | 2301 | 253 | 6687 | 80,757 | 216 | 106 | 1119 | 92,785 |
| Outdoor | 0 | 1 | 7 | 0 | 7 | 30 | 39 | 0 | 3 | 87 |
| Restaurant | 0 | 1 | 20 | 0 | 0 | 26 | 0 | 219 | 4 | 270 |
| Walking | 13 | 6 | 34 | 0 | 56 | 251 | 0 | 0 | 529 | 889 |
| Total | 536 | 2098 | 5985 | 479 | 17,035 | 85,489 | 281 | 338 | 2064 | 114,305 |
| Predicted | Actual | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bus | Car | Commercial Building | Cooking | Education Building | Indoor-House | Outdoor | Restaurant | Walking | Total | |
| Bus | 13 | 0 | 0 | 0 | 6 | 15 | 0 | 0 | 0 | 34 |
| Car | 1 | 109 | 43 | 0 | 17 | 53 | 0 | 1 | 0 | 224 |
| Commercial building | 9 | 28 | 732 | 6 | 67 | 258 | 0 | 2 | 30 | 1132 |
| Cooking | 0 | 0 | 1 | 31 | 13 | 25 | 0 | 0 | 0 | 70 |
| Education building | 16 | 89 | 94 | 8 | 2300 | 908 | 3 | 1 | 48 | 3467 |
| Indoor-house | 94 | 286 | 606 | 75 | 1835 | 19,905 | 53 | 25 | 254 | 23,133 |
| Outdoor | 0 | 0 | 3 | 0 | 3 | 7 | 11 | 0 | 0 | 24 |
| Restaurant | 0 | 0 | 7 | 0 | 0 | 12 | 0 | 50 | 0 | 69 |
| Walking | 10 | 1 | 11 | 0 | 11 | 64 | 0 | 0 | 99 | 196 |
| Total | 143 | 513 | 1497 | 120 | 4252 | 21,247 | 67 | 79 | 431 | 28,349 |
| Predicted | Actual | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bus | Car | Commercial Building | Cooking | Education Building | Indoor-House | Outdoor | Restaurant | Walking | Total | |
| Bus | 536 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 536 |
| Car | 0 | 2098 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2098 |
| Commercial building | 0 | 0 | 5985 | 0 | 0 | 1 | 0 | 0 | 0 | 5986 |
| Cooking | 0 | 0 | 0 | 479 | 0 | 0 | 0 | 0 | 0 | 479 |
| Education building | 0 | 0 | 0 | 0 | 17,035 | 0 | 0 | 0 | 0 | 17,035 |
| Indoor-house | 0 | 0 | 0 | 0 | 0 | 85,488 | 0 | 0 | 0 | 85,488 |
| Outdoor | 0 | 0 | 0 | 0 | 0 | 0 | 281 | 0 | 0 | 281 |
| Restaurant | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 338 | 0 | 338 |
| Walking | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2064 | 2064 |
| Total | 536 | 2098 | 5985 | 479 | 17,035 | 85,489 | 281 | 338 | 2064 | 114,305 |
| Predicted | Actual | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bus | Car | Commercial Building | Cooking | Education Building | Indoor-House | Outdoor | Restaurant | Walking | Total | |
| Bus | 142 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 142 |
| Car | 0 | 513 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 513 |
| Commercial building | 0 | 0 | 1497 | 0 | 0 | 2 | 0 | 0 | 0 | 1499 |
| Cooking | 0 | 0 | 0 | 120 | 0 | 0 | 0 | 0 | 0 | 120 |
| Education building | 0 | 0 | 0 | 0 | 4252 | 0 | 0 | 0 | 0 | 4252 |
| Indoor-house | 1 | 0 | 0 | 0 | 0 | 21,245 | 0 | 0 | 0 | 21,246 |
| Outdoor | 0 | 0 | 0 | 0 | 0 | 0 | 67 | 0 | 0 | 67 |
| Restaurant | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 79 | 0 | 79 |
| Walking | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 431 | 431 |
| Total | 143 | 513 | 1497 | 120 | 4252 | 21,247 | 67 | 79 | 431 | 28,349 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Kim, S. Machine Learning-Based Activity Pattern Classification Using Personal PM2.5 Exposure Information. Int. J. Environ. Res. Public Health 2020, 17, 6573. https://doi.org/10.3390/ijerph17186573
Park J, Kim S. Machine Learning-Based Activity Pattern Classification Using Personal PM2.5 Exposure Information. International Journal of Environmental Research and Public Health. 2020; 17(18):6573. https://doi.org/10.3390/ijerph17186573
Chicago/Turabian StylePark, JinSoo, and Sungroul Kim. 2020. "Machine Learning-Based Activity Pattern Classification Using Personal PM2.5 Exposure Information" International Journal of Environmental Research and Public Health 17, no. 18: 6573. https://doi.org/10.3390/ijerph17186573
APA StylePark, J., & Kim, S. (2020). Machine Learning-Based Activity Pattern Classification Using Personal PM2.5 Exposure Information. International Journal of Environmental Research and Public Health, 17(18), 6573. https://doi.org/10.3390/ijerph17186573