Place Effects and Chronic Disease Rates in a Rural State: Evidence from a Triangulation of Methods





Abstract
:1. Introduction
2. Literature Review
3. Data and Methods
3.1. Hot and Cold Spots (Place Effects)
3.2. Entropy Balancing
3.3. Data
4. Results
4.1. Descriptive Statistics
4.2. Results
4.3. Sensitivity Analysis
5. Discussion
6. Limitations
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
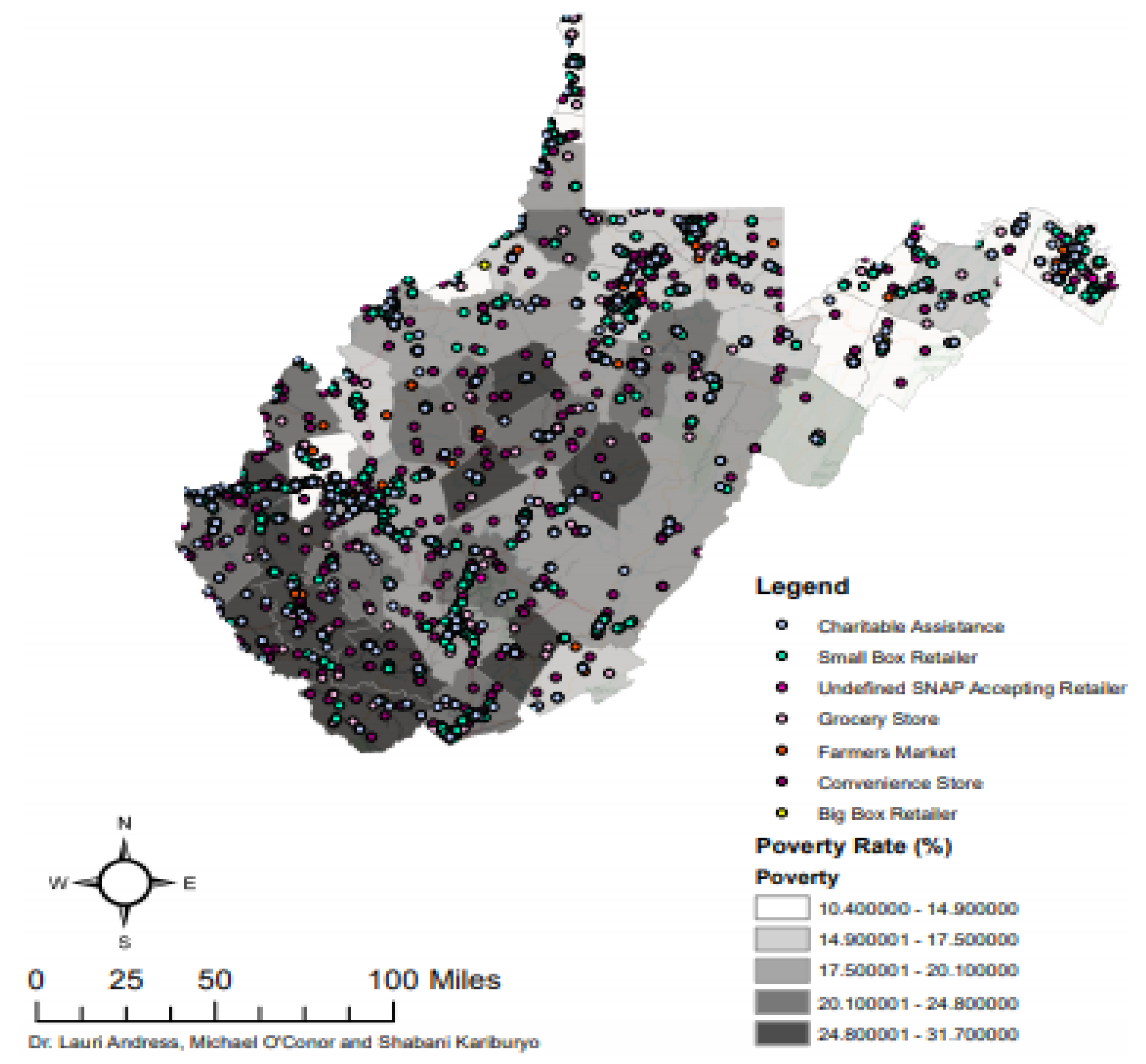
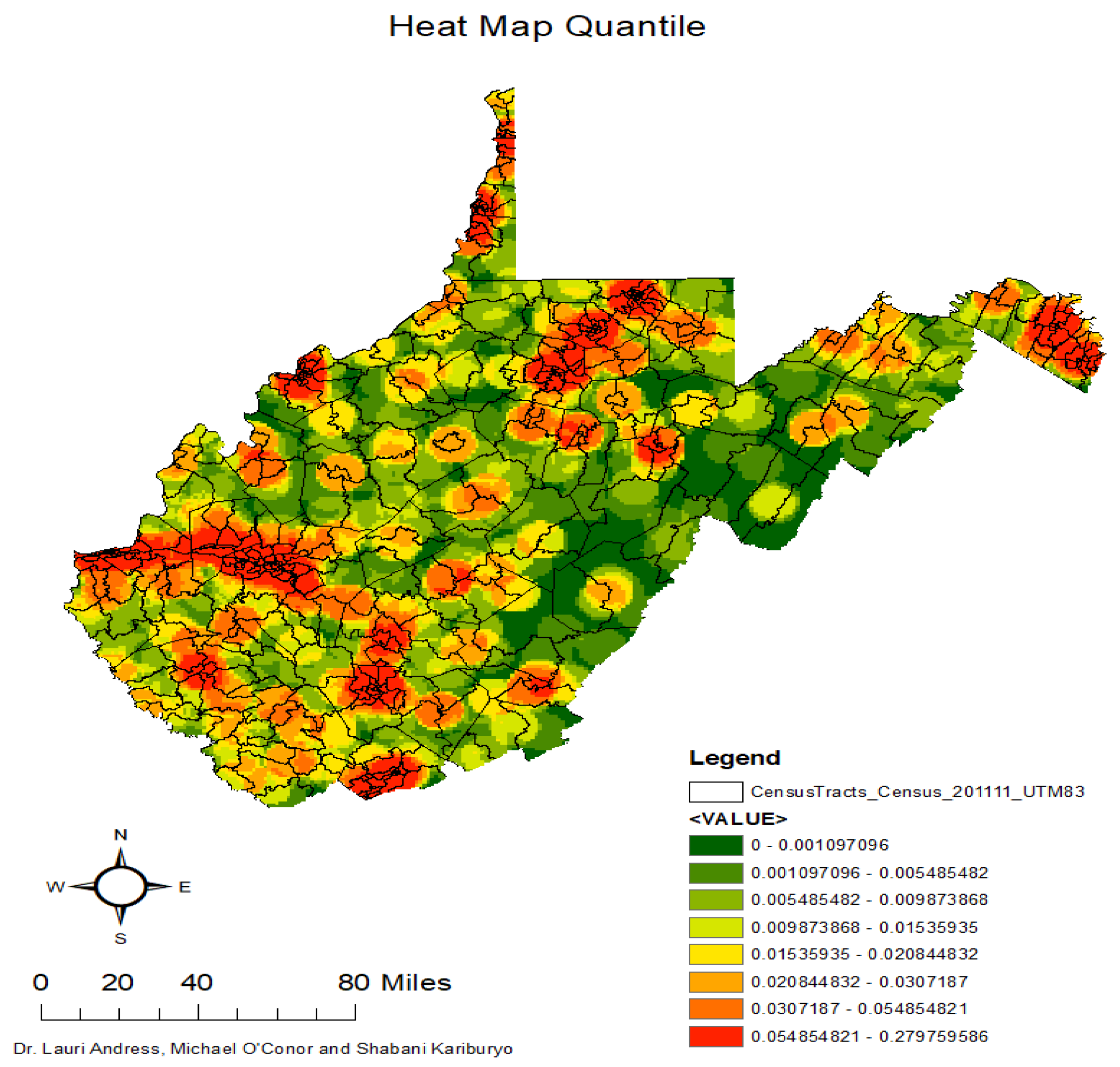
Appendix A. Figures and Tables



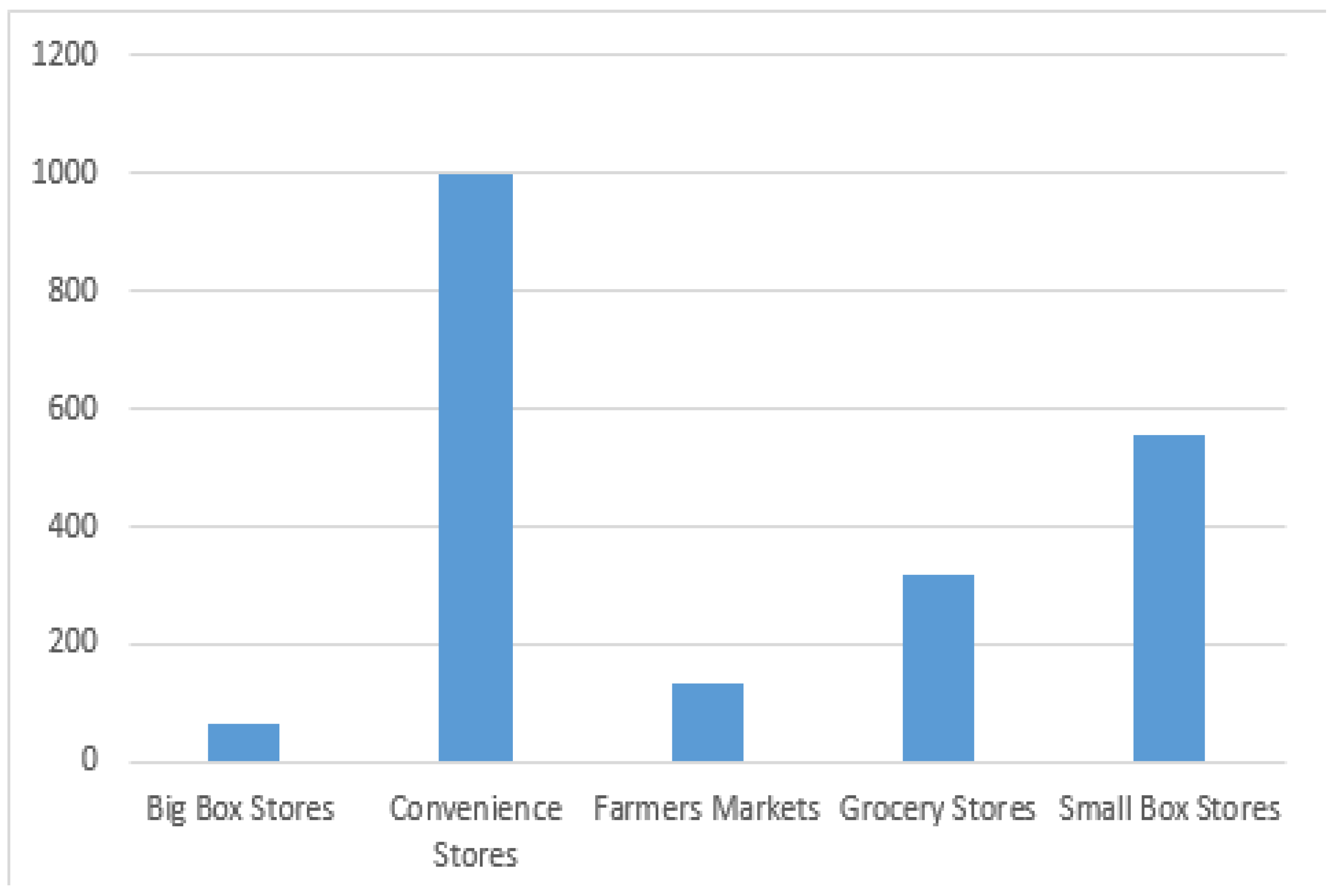{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hotspot (Mean) | Non-Hotspot (Mean) | Difference | Coldspot (Mean) | Non-Coldspot (Mean) | Difference | |
|---|---|---|---|---|---|---|
| Urban | 0.6333 | 0.2149 | −0.4183 (−10.0961) | 0.3043 | 0.4821 | 0.1777 (3.1104) |
| Family Households (Proportion) | 0.6149 | 0.6657 | 0.0508 (4.9497) | 0.6608 | 0.6319 | −0.0289 (−2.1837) |
| Unemployment (Proportion) | 0.0404 | 0.4235 | 0.0019 (1.0623) | 0.0388 | 0.0418 | 0.0029 (1.2688) |
| Health Insurance coverage (Proportion) | 0.9040 | 0.8965 | −0.0074 (−2.3575) | 0.8965 | 0.9017 | 0.0052 (1.2973) |
| Food stamp/Snap Benefits (Proportion) | 0.1588 | 0.1934 | 0.0345 (4.2315) | 0.1767 | 0.1735 | −0.0032 (−0.3095) |
| Mean Household Income (in 2016 dollars) | 72,467.74 | 59,389.27 | −13,078.47 (−7.2750) | 60,906.92 | 68,041.22 | 7134.2 (3.0039) |
| Vehicle available | 2350 | 2200 | 150 (−1.2173) | 2180 | 2310 | 130 (0.8650) |
| Bachelor degree (Proportion) | 0.1428 | 0.0861 | −0.0566 (−10.8271) | 0.0911 | 0.1240 | 0.0328 (4.5403) |
| Non-White (Proportion) | 0.0757 | 0.0372 | −0.0385 (−5.6177) | 0.0327 | 0.0648 | 0.0321 (3.6340) |
| Age < 19 (Proportion) | 0.1173 | 0.1116 | −0.0056 (−1.4515) | 0.1088 | 0.1162 | 0.0074 (1.5002) |
| Age > 59 (Proportion) | 0.1694 | 0.1901 | 0.02075 (6.2027) | 0.19425 | 0.1749 | −0.0193 (−4.4825) |
| Community Health Services (Count) | 0.2481 | 0.3878 | 0.1397 (3.3315) | 0.4130 | 0.2857 | −0.1273 (−2.3857) |
| Treatment Mean (Hot Spots) | Control Mean (Before Weighting) | Control Mean (After Weighting) | Treatment Mean (Cold Spots) | Control Mean (Before Weighting) | Control Mean (After Weighting) | |
|---|---|---|---|---|---|---|
| Proportion of Family Household | 0.6149 | 0.6658 | 0.615 | 0.6609 | 0.6319 | 0.6609 |
| Proportion of Unemployment | 0.0404 | 0.0423 | 0.0404 | 0.0388 | 0.0418 | 0.0388 |
| Proportion of Health Insurance Coverage | 0.9041 | 0.8966 | 0.9041 | 0.8965 | 0.9018 | 0.8965 |
| Proportion Food stamp/Snap benefits | 0.1588 | 0.1934 | 0.1588 | 0.1768 | 0.1735 | 0.11768 |
| Mean Household Income | 72,468 | 59,389 | 72,468 | 60,907 | 68,041 | 60,907 |
| Vehicle available | 2351.6 | 2350.3 | 2351.6 | 2182.3 | 2311.2 | 2182.3 |
| Proportion of Bachelor degree | 0.1428 | 0.08616 | 0.1428 | 0.0911 | 0.124 | 0.09118 |
| Proportion of Non-White | 0.0757 | 0.0372 | 0.07576 | 0.0327 | 0.06484 | 0.03272 |
| Proportion of age < 19 | 0.1173 | 0.1116 | 0.1173 | 0.1088 | 0.1162 | 0.1088 |
| Proportion of age > 59 | 0.1694 | 0.1902 | 0.1694 | 0.1942 | 0.1749 | 0.1942 |
| Community Health Services | 0.2481 | 0.3879 | 0.2482 | 0.413 | 0.2857 | 0.413 |
| Diabetes | (1) Unbalanced | (2) Balanced | (3) Unbalanced | (4) Balanced |
|---|---|---|---|---|
| Treatment: Hot Spots | −0.0041 *** (0.000) | −0.0054 *** (0.045) | ||
| Treatment: Cold Spots | 0.0052 *** (0.009) | 0.0057 *** (0.002) | ||
| Constant | 0.2236 *** (0.000) | 0.1354 *** (0.000) | 0.2190 *** (0.000) | 0.1388 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.3150 | 0.0216 | 0.2411 | 0.0322 |
| Obesity | (1) Unbalanced | (2) Balanced | (3) Unbalanced | (4) Balanced |
|---|---|---|---|---|
| Treatment: Hot Spots | −0.0128 *** (0.000) | −0.0188 *** (0.000) | ||
| Treatment: Cold Spots | 0.0052 *** (0.009) | 0.0137 *** (0.002) | ||
| Constant | 0.3639 *** (0.000) | 0.3533 *** (0.000) | 0.2190 *** (0.000) | 0.3483 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.3500 | 0.1162 | 0.3453 | 0.0660 |
| Diabetes | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0116 *** (0.001) | |||
| Treatment: Rural Hot Spots | 0.0127 ** (0.015) | |||
| Treatment: Urban Cold Spots | 0.0151 (0.143) | |||
| Treatment: Rural Cold Spots | 0.0293 *** (0.008) | |||
| Ln(Income) 25th percentile | −0.0069 *** (0.040) | −0.0017 (0.511) | −0.0131 (0.332) | −0.0101 (0.500) |
| 25th percentile * Treatment | 0.0096 * (0.064) | −0.0099 (0.173) | 0.0039 (0.783) | −0.0041 (0.793) |
| Ln (Income) 50th percentile | −0.0116 (0.002) | 0.0055 * (0.075) | −0.0016 (0.892) | −0.0025 (0.847) |
| 50th percentile * Treatment | −0.0131 ** (0.015) | -0.0109 (0.120) | −0.0047 (0.696) | −0.0218 (0.008) |
| Ln (Income) 75th percentile | −0.0200 *** (0.000) | −0.0114 *** (0.000) | −0.0218 * (0.057) | −0.0180 (0.134) |
| 75th percentile * Treatment | 0.0159 *** (0.004) | −0.0152 ** (0.027) | 0.0261 *** (0.027) | −0.0046 (0.699) |
| Proportion of AFHM | 0.0588 *** (0.003) | 0.0540 *** (0.001) | 0.2583 *** (0.000) | 0.1702 *** (0.001) |
| Constant | 0.1440 *** (0.000) | 0.1380 *** (0.000) | 0.1187 *** (0.000) | 0.1167 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.1440 | 0.1645 | 0.2881 | 0.3104 |
| Obesity | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0332 *** (0.000) | |||
| Treatment: Rural Hot Spots | 0.0117 (0.310) | |||
| Treatment: Urban Cold Spots | 0.0409 *** (0.000) | |||
| Treatment: Rural Cold Spots | 0.0523 *** (0.000) | |||
| Ln (Income) 25th percentile | −0.0132 ** (0.027) | −0.0015 (0.738) | −0.0052 (0.653) | −0.0014 (0.914) |
| 25th percentile * Treatment | 0.0290 *** (0.001) | −0.0112 (0.435) | 0.0088 (0.532) | −0.0249 (0.137) |
| Ln (Income) 50th percentile | −0.0077 (0.248) | 0.0059 (0.301) | −0.0059 (0.522) | −0.0131 (0.172) |
| 50th percentile * Treatment | −0.0249 *** (0.009) | −0.0219 (0.108) | −0.0212 * (0.072) | −0.0376 (0.007) |
| Ln (Income) 75th percentile | −0.0174 ** (0.015) | −0.0081 *** (0.136) | −0.0165 * (0.053) | −0.0099 (0.194) |
| 75th percentile * Treatment | 0.0221 ** (0.013) | −0.0138 (0.272) | 0.0186 (0.100) | −0.0047 (0.712) |
| Proportion of AFHM | 0.1233 *** (0.003) | 0.1548 *** (0.001) | 0.4877 *** (0.000) | 0.3388 *** (0.000) |
| Constant | 0.3561 *** (0.000) | 0.3411 *** (0.000) | 0.3069 *** (0.000) | 0.3033 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.2311 | 0.1649 | 0.3931 | 0.4253 |
| Diabetes | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0098 *** (0.008) | |||
| Treatment: Rural Hot Spots | 0.0129 ** (0.021) | |||
| Treatment: Urban Cold Spots | 0.0069 (0.404) | |||
| Treatment: Rural Cold Spots | 0.0146 *** (0.001) | |||
| Ln(Income) 25th percentile | −0.0049 (0.123) | −0.0007 (0.794) | −0.0053 * (0.093) | 0.0006 (0.870) |
| 25th percentile * Treatment | 0.0068 (0.203) | −0.0111 (0.122) | 0.0032 (0.745) | −0.0136 ** (0.029) |
| Ln (Income) 50th percentile | −0.0112 *** (0.000) | −0.0058 ** (0.016) | −0.0124 *** (0.000) | −0.0068 * (0.093) |
| 50th percentile * Treatment | −0.0123 ** (0.014) | −0.0088 (0.202) | 0.0072 (0.499) | −0.0105 * (0.098) |
| Ln (Income) 75th percentile | −0.0124 *** (0.000) | −0.0057 ** (0.019) | −0.0192 *** (0.000) | −0.0080 * (0.076) |
| 75th percentile * Treatment | 0.0095 ** (0.038) | −0.0194 *** (0.003) | 0.0203 * (0.057) | −0.0084 (0.492) |
| Proportion of AFHM | 0.0737 *** (0.000) | 0.0728 *** (0.001) | 0.0255 (0.252) | 0.0136 (0.530) |
| Constant | 0.1398 *** (0.000) | 0.1344 *** (0.000) | 0.1473 *** (0.000) | 0.1412 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.0876 | 0.0911 | 0.1311 | 0.1651 |
| Obesity | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0307 *** (0.000) | |||
| Treatment: Rural Hot Spots | 0.0187 ** (0.025) | |||
| Treatment: Urban Cold Spots | 0.0069 (0.619) | |||
| Treatment: Rural Cold Spots | 0.0383 *** (0.000) | |||
| Ln(Income) 25th percentile | −0.0131 *** (0.004) | −0.0113 (0.786) | −0.0017 (0.748) | 0.0179 (0.003) |
| 25th percentile * Treatment | 0.0272 *** (0.000) | −0.0135 (0.206) | 0.0095 (0.569) | −0.0413 ** (0.000) |
| Ln (Income) 50th percentile | −0.0008 (0.827) | −0.0058 ** (0.016) | −0.0042 (0.450) | 0.0114 * (0.078) |
| 50th percentile * Treatment | −0.0149 ** (0.039) | −0.0122 (0.001) | 0.0067 (0.708) | −0.0363 *** (0.098) |
| Ln (Income) 75th percentile | −0.0185 *** (0.000) | −0.0080 ** (0.029) | −0.0175 *** (0.032) | −0.0048 (0.498) |
| 75th percentile * Treatment | 0.0234 *** (0.000) | −0.0165 * (0.092) | 0.0140 (0.431) | −0.0280 (0.152) |
| Proportion of AFHM | 0.127 *** (0.000) | 0.1518 *** (0.000) | 0.0720 * (0.055) | 0.0386 (0.530) |
| Constant | 0.3524 *** (0.000) | 0.3339 *** (0.000) | 0.3527 *** (0.000) | 0.3387 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.2154 | 0.1649 | 0.0611 | 0.1859 |
| Diabetes | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0087 ** (0.050) | |||
| Treatment: Rural Hot Spots | 0.0137 ** (0.018) | |||
| Treatment: Urban Cold Spots | −0.0069 ** (0.031) | |||
| Treatment: Rural Cold Spots | 0.0127 *** (0.001) | |||
| Ln(Income) 25th percentile | 0.0008 (0.848) | 0.0009 (0.782) | −0.0076 *** (0.002) | −0.0030 (0.143) |
| 25th percentile * Treatment | 0.0001 (0.977) | −0.0025 (0.735) | 0.0043 (0.519) | −0.0098 * (0.058) |
| Ln (Income) 50th percentile | −0.0086 * (0.085) | −0.0033 (0.445) | −0.0108 *** (0.000) | −0.0055 * (0.009) |
| 50th percentile * Treatment | −0.0144 ** (0.025) | −0.0102 (0.164) | 0.0083 ** (0.030) | −0.0092 * (0.087) |
| Ln (Income) 75th percentile | −0.0179 *** (0.001) | −0.0086 * (0.052) | −0.0162 *** (0.000) | −0.0094 *** (0.001) |
| 75th percentile * Treatment | 0.0170 *** (0.013) | −0.0164 ** (0.026) | 0.0204 *** (0.000) | −0.0054 (0.348) |
| Proportion of AFHM | 0.0840 *** (0.001) | 0.0753 *** (0.001) | 0.0580 *** (0.000) | 0.0478 *** (0.001) |
| Constant | 0.1371 *** (0.000) | 0.1327 *** (0.000) | 0.1454 *** (0.000) | 0.1402 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.1462 | 0.1255 | 0.1646 | 0.1905 |
| Obesity | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0260 *** (0.001) | |||
| Treatment: Rural Hot Spots | 0.0212 ** (0.049) | |||
| Treatment: Urban Cold Spots | −0.0004 (0.946) | |||
| Treatment: Rural Cold Spots | 0.0284 *** (0.001) | |||
| Ln(Income) 25th percentile | 0.0005 (0.948) | 0.0036 (0.519) | −0.0090 * (0.084) | −0.0032 (0.485) |
| 25th percentile * Treatment | 0.0100 (0.302) | −0.0100 (0.458) | 0.0029 (0.742) | −0.0297 *** (0.002) |
| Ln (Income) 50th percentile | −0.0044 (0.652) | −0.0163 ** (0.043) | −0.0107 ** (0.040) | 0.00008 (0.985) |
| 50th percentile * Treatment | −0.0139 (0.222) | −0.0343 ** (0.010) | 0.0034 (0.639) | −0.0232 ** (0.018) |
| Ln (Income) 75th percentile | −0.0117 (0.174) | −0.0024 (0.671) | −0.0190 *** (0.002) | −0.0092 * (0.089) |
| 75th percentile*Treatment | 0.0186 * (0.059) | −0.0234 ** (0.045) | 0.0240 *** (0.003) | −0.0049 (0.642) |
| Proportion of AFHM | 0.1650 *** (0.000) | 0.2053 *** (0.000) | 0.1215 *** (0.000) | 0.0478 *** (0.001) |
| Constant | 0.3453 *** (0.000) | 0.3314 *** (0.000) | 0.3544 *** (0.000) | 0.3449 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.2515 | 0.2131 | 0.1266 | 0.2003 |
References
- Andress, L. Using a social ecological model to explore upstream and downstream solutions to rural food access for the elderly. Cogent Med. 2017, 4, 1393849. [Google Scholar] [CrossRef]
- Andress, L.; Fitch, C. Juggling the five dimensions of food access: Perceptions of rural low income residents. Appetite 2016, 105, 151–155. [Google Scholar] [CrossRef] [PubMed]
- Andress, L.; Hallie, S.S. Co-constructing food access issues: Older adults in a rural food environment in West Virginia develop a photo narrative. Cogent Med. 2017, 4, 1309804. [Google Scholar] [CrossRef]
- Jilcott Pitts, S.B.; McGuirt, J.T.; Carr, L.; Wu, Q.; Keyserling, T.C. Associations between body mass index, shopping behaviors, and characteristics of the neighborhood food environment among female adult Supplemental Nutrition Assistance Program (SNAP) participants in Eastern North Carolina. Ecol. Food Nutr. 2012, 51, 526–541. [Google Scholar] [CrossRef]
- Caspi, C.E.; Sorensen, G.; Subramanian, S.; Kawachi, I. The local food environment and diet: A systematic review. Health Place 2012, 18, 1172–1187. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Creel, J.S.; Sharkey, J.R.; McIntosh, A.; Anding, J.; Huber, J.C. Availability of healthier options in traditional and non-traditional rural fast-food outlets. BMC Public Health 2008, 8, 395. [Google Scholar] [CrossRef] [Green Version]
- Cummins, S.; Flint, E.; Stephen, A.M. New neighborhood grocery store increased awareness of food access but did not alter dietary habits or obesity. Health Aff. 2014, 33, 283–291. [Google Scholar] [CrossRef] [Green Version]
- Cooksey-Stowers, K.; Schwartz, M.B.; Brownell, K.D. Food swamps predict obesity rates better than food deserts in the united states. Int. J. Environ. Res. Public Health 2017, 14, 1366. [Google Scholar] [CrossRef] [Green Version]
- Allcott, H.; Diamond, R.; Dub’e, J.-P.H.; Bury, J.; Rahkovsky, I.; Schnell, M. Food deserts and the causes of nutritional inequality. Q. J. Econ. 2019, 134, 1793–1844. [Google Scholar] [CrossRef]
- Phillips, A.Z.; Rodriguez, H.P. US county food swamp severity and hospitalization rates among adults with diabetes: A nonlinear relationship. Soc. Sci. Med. 2020, 249, 112858. [Google Scholar] [CrossRef]
- Cummins, S.; Macintyre, S. “Food deserts”—Evidence and assumption in health policy making. Br. Med. J. 2002, 325, 436–438. [Google Scholar] [CrossRef] [PubMed]
- Sharkey, J.R.; Dean, W.R.; Nalty, C.C.; Xu, J. Convenience stores are the key food environment influence on nutrients available from household food supplies in Texas border colonias. BMC Public Health 2013, 13, 45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Currie, J.; Walker, R. Traffic congestion and infant health: Evidence from e-zpass. Am. Econ. J. Appl. Econ. 2011, 3, 65–90. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Jaenicke, E.C.; Volpe, R.J. Food environments and obesity: Household diet expenditure versus food deserts. Am. J. Public Health 2016, 106, 881–888. [Google Scholar] [CrossRef]
- Alviola, P.A., IV; Nayga, R.M., Jr.; Thomsen, M.R.; Wang, Z. Determinants offood deserts. Am. J. Agric. Econ. 2013, 95, 1259–1265. [Google Scholar] [CrossRef]
- Hager, E.R.; Cockerham, A.; OReilly, N.; Harrington, D.; Harding, J.; Hurley, K.M.; Black, M.M. Food swamps and food deserts in Baltimore city, md, usa: Associations with dietary behaviours among urban adolescent girls. Public Health Nutr. 2017, 20, 2598–2607. [Google Scholar] [CrossRef] [Green Version]
- Jang, S.; Kim, J. Remedying food policy invisibility with spatial intersectionality: A case study in the Detroit metropolitan area. J. Public Policy Mark. 2018, 37, 167–187. [Google Scholar] [CrossRef] [Green Version]
- Christine, P.J.; Auchincloss, A.H.; Bertoni, A.G.; Carnethon, M.R.; Sanchez, B.N.; Moore, K.; Adar, S.D.; Horwich, T.B.; Watson, K.E.; Roux, A.V.D. Longitudinal associations between neighborhood physical and social environments and incident type 2 diabetes mellitus: The multi-ethnic study of atherosclerosis (mesa). JAMA Intern. Med. 2015, 175, 1311–1320. [Google Scholar] [CrossRef] [Green Version]
- Gebreab, S.Y.; Hickson, D.A.; Sims, M.; Wyatt, S.B.; Davis, S.K.; Correa, A.; Diez-Roux, A.V. Neighborhood social and physical environments and type 2 diabetes mellitus in African Americans. Health Place 2017, 43, 128–137. [Google Scholar] [CrossRef]
- Handbury, J.; Rahkovsky, I.; Schnell, M. Is the focus on food deserts fruitless? In Retail Access and Food Purchases across the Socioeconomic Spectrum; Technical report; National Bureau of Economic Research: Cambridge, MA, USA, 2015. [Google Scholar]
- Johnson, D.B.; Quinn, E.; Sitaker, M.; Ammerman, A.; Byker, C.; Dean, W.; Fleischhacker, S.; Kolodinsky, J.; Pinard, C.; Pitts, S.B.J.; et al. Developing an agenda for research about policies to improve access to healthy foods in rural communities: A concept mapping study. BMC Public Health 2014, 14, 592. [Google Scholar] [CrossRef] [Green Version]
- Bailey, J.M. Rural Grocery Stores: Importance and Challenges; Center for Rural Affairs Rural Research and Analysis Program: Lyons, NE, USA, 2010. [Google Scholar]
- Marasteanu, I.J.; Jaenicke, E.C. Economic impact of organic agriculture hot spots in the United States. Renew. Agric. Food Syst. 2019, 34, 501–522. [Google Scholar] [CrossRef]
- Marcus, J. The effect of unemployment on the mental health of spouses—Evidence from plant closures in Germany. J. Health Econ. 2013, 32, 546–558. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hainmueller, J. Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies. Political Anal. 2012, 20, 25–46. [Google Scholar] [CrossRef] [Green Version]
- Neuenkirch, M.; Neumeier, F. The impact of us sanctions on poverty. J. Dev. Econ. 2016, 121, 110–119. [Google Scholar] [CrossRef]
- Grossman, D.S.; Humphreys, B.R.; Ruseski, J.E. Out of the outhouse: The impact of place-based policies on dwelling characteristics in Appalachia. J. Reg. Sci. 2019, 59, 5–28. [Google Scholar] [CrossRef] [Green Version]
- Smith, J.A.; Todd, P.E. Does matching overcome Lalonde’s critique of non-experimental estimators? J. Econ. 2005, 125, 305–353. [Google Scholar] [CrossRef] [Green Version]
- Deb, P.; Vargas, C. Who benefits from calorie labeling? In An Analysis of Its Effects on Body Mass; Technical Report; National Bureau of Economic Research: Cambridge, MA, USA, 2016. [Google Scholar]
- Deskins, J. The Economic Impact of Coal in West Virginia; Technical Report; Bureau of Business & Economic Research, College of Business and Economics, West Virginia University: Morgantown, WV, USA, 2018. [Google Scholar]
- Mactaggart, F.; McDermott, L.; Tynan, A.; Gericke, C. Examining health and well-being outcomes associated with mining activity in rural communities of high-income countries: A systematic review. Aust. J. Rural. Health 2016, 24, 230–237. [Google Scholar] [CrossRef]
- Caillavet, F.; Kyureghian, G.; Nayga, R.M., Jr.; Ferrant, C.; Chauvin, P. Does healthy food access matter in a french urban setting? Am. J. Agric. Econ. 2015, 97, 1400–1416. [Google Scholar] [CrossRef]


| Diabetes | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0084 * (0.095) | |||
| Treatment: Rural Hot Spots | 0.0156 *** (0.005) | |||
| Treatment: Urban Cold Spots | −0.0061 * (0.089) | |||
| Treatment: Rural Cold Spots | 0.01246 *** (0.001) | |||
| Ln (Income) 25th percentile | −0.0024 (0.629) | 0.0020 (0.581) | −0.0087 *** (0.001) | −0.0042 * (0.061) |
| 25th percentile * Treatment | 0.0043 (0.515) | −0.0142 (0.054) | 0.0062 (0.249) | −0.0081 (0.104) |
| Ln (Income) 50th percentile | −0.0086 * (0.097) | −0.0029 (0.427) | −0.0105 *** (0.000) | −0.0052 ** (0.012) |
| 50th percentile * Treatment | 0.0097 (0.144) | −0.0122 * (0.081) | 0.0053 (0.223) | −0.0116 ** (0.014) |
| Ln (Income) 75th percentile | −0.0164 *** (0.003) | −0.0078 ** (0.042) | −0.0207 *** (0.000) | −0.0094 *** (0.001) |
| 75th percentile * Treatment | 0.0135 * (0.054) | −0.0183 ** (0.010) | 0.0224 *** (0.000) | −0.0054 (0.226) |
| Proportion of AFHM | 0.0675 *** (0.007) | 0.0575 ** (0.011) | 0.0555 *** (0.001) | 0.0465 *** (0.002) |
| Constant | 0.1386 *** (0.000) | 0.1331 *** (0.000) | 0.1455 *** (0.000) | 0.1404 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.1066 | 0.1047 | 0.1798 | 0.1963 |
| Obesity | (1) | (2) | (3) | (4) |
|---|---|---|---|---|
| Treatment: Urban Hot Spots | −0.0278 *** (0.004) | |||
| Treatment: Rural Hot Spots | 0.0185 ** (0.077) | |||
| Treatment: Urban Cold Spots | 0.0034 (0.542) | |||
| Treatment: Rural Cold Spots | 0.0273 *** (0.000) | |||
| Ln(Income) 25th percentile | −0.0105 (0.275) | 0.0022 (0.700) | −0.0087 *** (0.0076) | −0.0024 (0.596) |
| 25th percentile * Treatment | 0.0234 ** (0.035) | -0.0159 (0.216) | 0.0004 (0.956) | −0.0248 *** (0.006) |
| Ln (Income) 50th percentile | -0.0013 (0.900) | -0.0123 (0.105) | −0.0100 *** (0.047) | −0.0003 ** (0.949) |
| 50th percentile * Treatment | -0.0146 (0.227) | −0.0295 ** (0.022) | −0.0010 (0.886) | −0.0244 *** (0.008) |
| Ln (Income) 75th percentile | −0.0122 (0.189) | −0.0023 (0.662) | −0.0267 *** (0.000) | −0.0065 *** (0.230) |
| 75th percentile * Treatment | 0.0159 (0.129) | −0.0193 * (0.086) | 0.0240 *** (0.002) | −0.0144 (0.113) |
| Proportion of AFHM | 0.1680 *** (0.000) | 0.02011 *** (0.000) | 0.1126 *** (0.001) | 0.0085 *** (0.001) |
| Constant | 0.3489 *** (0.000) | 0.3326 *** (0.000) | 0.3549 *** (0.000) | 0.3455 *** (0.000) |
| Observation | 484 | 484 | 484 | 484 |
| R-squared | 0.2184 | 0.1676 | 0.1346 | 0.1802 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kariburyo, M.S.; Andress, L.; Collins, A.; Kinder, P. Place Effects and Chronic Disease Rates in a Rural State: Evidence from a Triangulation of Methods. Int. J. Environ. Res. Public Health 2020, 17, 6676. https://doi.org/10.3390/ijerph17186676
Kariburyo MS, Andress L, Collins A, Kinder P. Place Effects and Chronic Disease Rates in a Rural State: Evidence from a Triangulation of Methods. International Journal of Environmental Research and Public Health. 2020; 17(18):6676. https://doi.org/10.3390/ijerph17186676
Chicago/Turabian StyleKariburyo, Mohamed Shabani, Lauri Andress, Alan Collins, and Paul Kinder. 2020. "Place Effects and Chronic Disease Rates in a Rural State: Evidence from a Triangulation of Methods" International Journal of Environmental Research and Public Health 17, no. 18: 6676. https://doi.org/10.3390/ijerph17186676
APA StyleKariburyo, M. S., Andress, L., Collins, A., & Kinder, P. (2020). Place Effects and Chronic Disease Rates in a Rural State: Evidence from a Triangulation of Methods. International Journal of Environmental Research and Public Health, 17(18), 6676. https://doi.org/10.3390/ijerph17186676