An Introduction to Probabilistic Record Linkage with a Focus on Linkage Processing for WTC Registries



Abstract
:1. Introduction
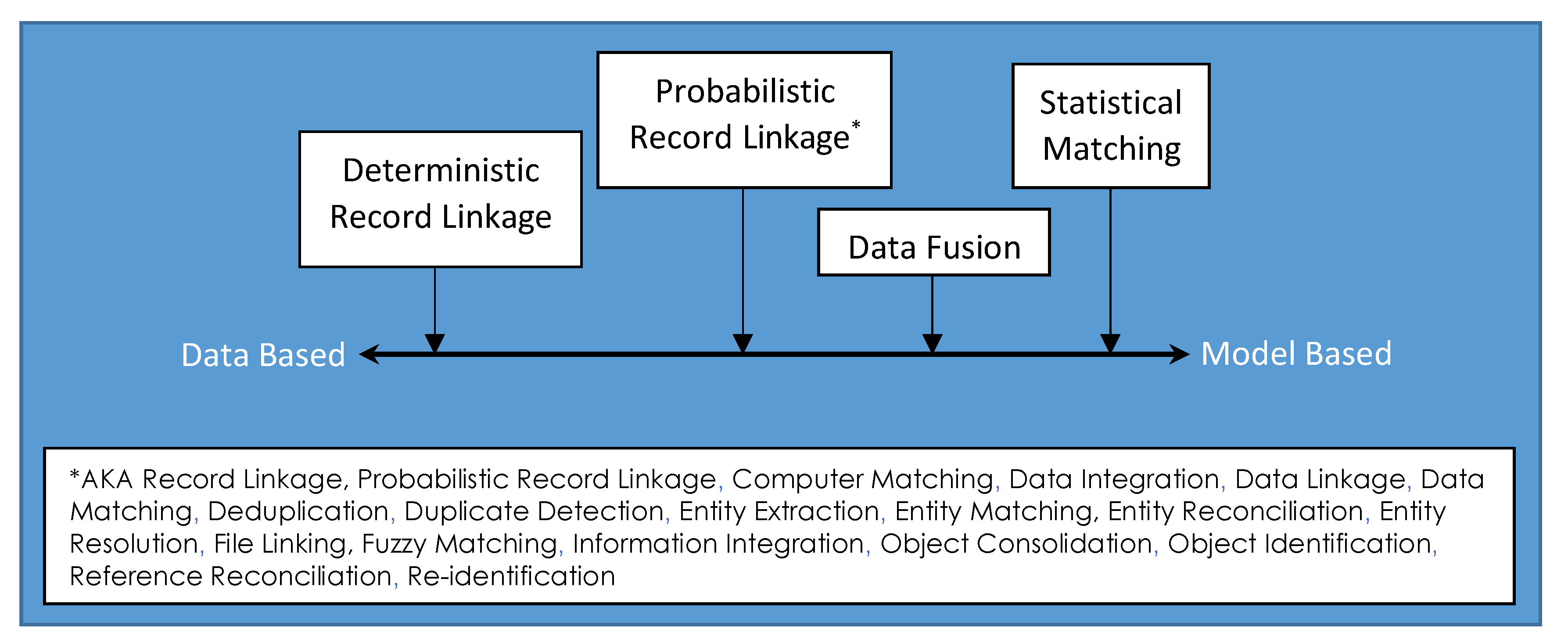
2. Data Combining Methods
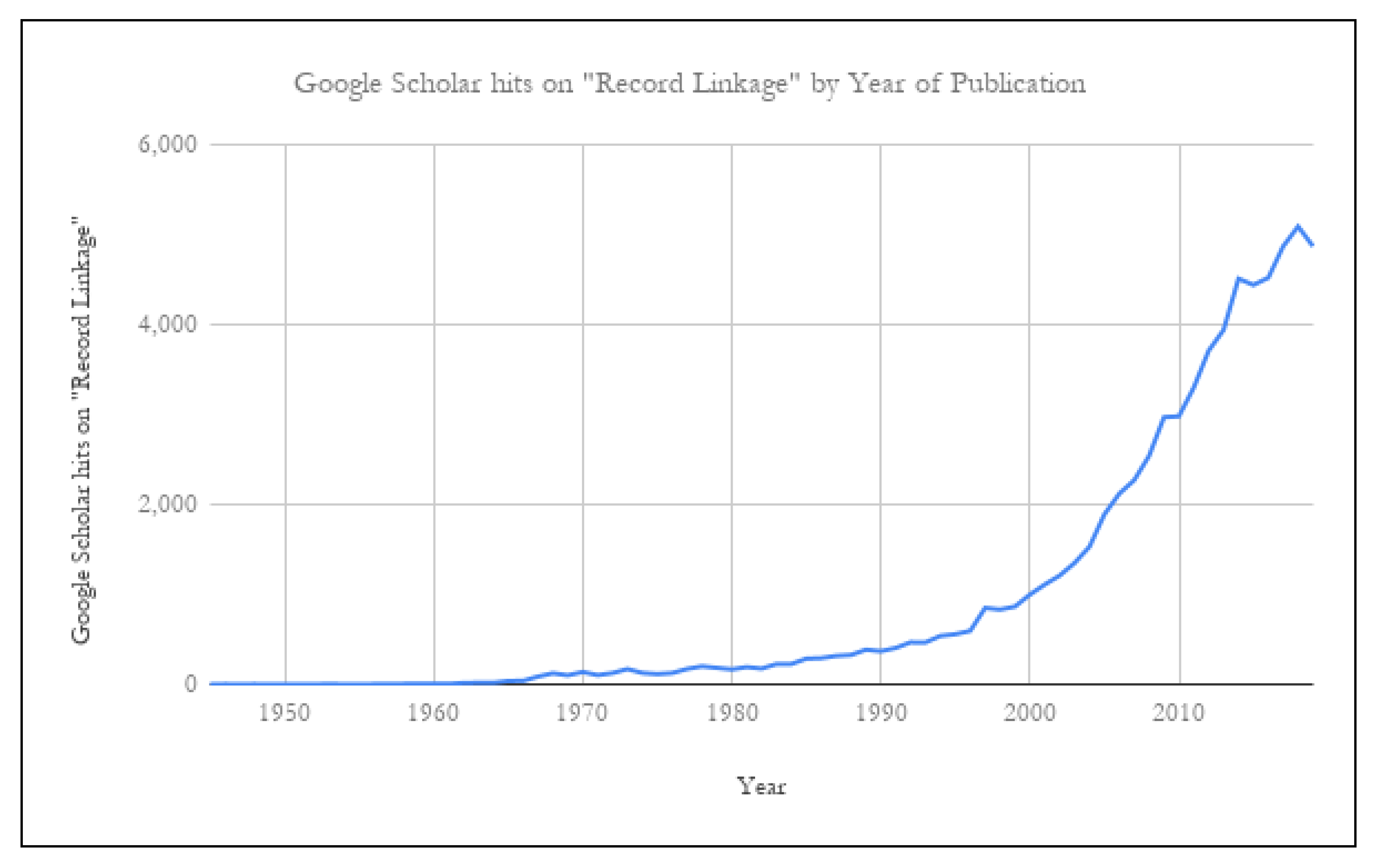
3. Historical Context
4. Methodologies
4.1. Fellegi-Sunter Model
4.2. Machine Learning
4.3. Bayesian Record Linkage Techniques
4.4. Open Research Questions
5. Practical Considerations
5.1. Data Cleaning and Standardization
5.2. Missing Data
5.3. Error Measurement
5.4. Software
5.5. Data Sharing
- Data format. If different organizations use different data management systems, direct transmission of files without conversion into a commonly accepted format will cause issues. As mentioned before, most statistical and/or record linkage software can accept a comma delimited file as input.
- Data description. A separate file describing the data should be included; information about a dataset is typically called the “metadata”. Metadata includes information on how the data were collected, a definition and value range for each variable in the dataset, and any restrictions on the data usage.
- Confidentiality agreement. All employees that will have access to the shared data should agree, preferably through signing a contract with the organization providing the data, to maintain the confidentiality of the data.
- Length of time data are available. If the data are only being shared for a limited time period, the parameters for that time period should be outlined prior to data transmission. In addition, requirements for the “disposal” of the data once the time period is over should be agreed upon in advance.
- Institutional Review Board (IRB) requirements. In some cases, IRBs have determined that record linkage does not fall under human subjects protections; in other cases, IRBs have regulated record linkage projects. Any IRB restrictions that are already in place regarding the data to be shared must be understood by all parties engaging in the record linkage process.
- Health Insurance Portability and Accountability Act (HIPAA) requirements. In some cases, IRBs have required that informed consent be obtained from the individuals whose data will be used in the record linkage process. If data are being transferred between organizations, a new informed consent agreement might be required.
- Secure transmission of data. The protocol for data transmission should be agreed upon in advance and should have appropriate security protocols. Record linkage projects sometimes have stringent security requirements. For example, sensitive de-identified datasets sometimes require researchers to use a computer within a secured data center, separate from the Internet.
5.6. Documentation of Record Linkage Processes
- The names of the individuals that complete the record linkage project.
- The purpose of the record linkage project; for what analysis will the linked data be used?
- The precedents of the record linkage project, if part of a longitudinal study, and where the documentation for previous iterations of the project can be found. Please note that even when record linkages are to be repeated at different time points with new data, each linkage should still have its own documentation.
- The metadata for each file to be linked, including:
- The names, file positions, and descriptions of the variables;
- The data collection process for the dataset;
- The organizational source (in house or outside organization) for the dataset;
- The date of acquisition of the dataset;
- The contact information for the person from which the dataset was obtained; and
- Any rules regarding the use and disposal of the dataset.
- The software that is used for the linkage.
- The methodology for the linkage, including:
- How many passes are performed when linking the data;
- If blocking is used, which variables are used as blocking factors during which passes;
- If parameters are set ahead of the process—for example, if prior values for m and u probabilities are required—what values are used for each pass.
- Any information as to how linked pairs, non-linked pairs and possible linked pairs are determined. For a standard Fellegi-Sunter process, this information includes the range of match weights for each of these groups; for a machine learning unsupervised clustering process, this information includes the mean value for each of these groups and the range of distances that determine which pairs are clustered into which groups.
- Some measurements of the error rate in the linkage process; ideally, these include a false-positive and false-negative rate.
- A definition for any new variables created during the linkage process.
- Any known limitations of the record linkage process, including issues with the data that might have made record linkage problematic, known methodological issues related to the algorithm used for the linkage, and specific issues that might have arisen during the record linkage project.
- The final disposition of the linked datasets, if they are not available indefinitely.
- In some cases, the linked data will be stripped of all identifiers, allowing the resulting dataset to be freely used without confidentiality constraints. If this is the case, the process of removal of identifying information should be outlined.
6. Ethical Considerations
6.1. Privacy Preserving Record Linkage
6.2. Biases in the Record Linkage Process
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Christensen, H.; Andrews, R.; Freiser, S. Falsification of Age at Marriage. Marriage Fam. Living 1953, 15, 301–304. [Google Scholar] [CrossRef]
- Dunn, H.L. Record linkage. Am. J. Publ. Health Nations Health 1946, 36, 1412–1416. [Google Scholar] [CrossRef]
- Schwartz, E.E. Some observations on the Canadian family allowances program. Soc. Serv Rev. 1946, 20, 451–473. [Google Scholar] [CrossRef]
- Marshall, J.T. Canada’s national vital statistics index. Popul. Stud. 1947, 1, 204–211. [Google Scholar] [CrossRef]
- Barrai, I.; Cavalli-Sforza, L.L.; Moroni, A. Record linkage from parish books. In Mathematics and Computer Science in Biology and Medicine; John Blackburn Ltd.: London, UK, 1965; pp. 51–60. [Google Scholar]
- Shryock, H.S., Jr. Development of postcensal population estimates for local areas. In Regional Income, Proceedings of the Conference on Research in Income and Wealth, Durham, NC, USA, 17–18 June 1955; Princeton University Press: Princeton, NJ, USA, 1957; pp. 377–400. [Google Scholar]
- Newcombe, H.B.; Kennedy, J.M.; Axford, S.J.; James, A.P. Automatic linkage of vital records. Science 1959, 130, 954–959. [Google Scholar] [CrossRef]
- Acheson, E.D. Oxford record linkage study: A central file of morbidity and mortality records for a pilot population. Br. J. Prev Soc. Med. 1964, 18, 8. [Google Scholar] [CrossRef] [Green Version]
- Gardner, E.A.; Miles, H.C.; Bahn, A.K.; Romano, J. All psychiatric experience in a community: A cumulative survey: Report of the first years’ experience. Arch. Gen. Psychiatry 1963, 9, 369–378. [Google Scholar] [CrossRef]
- Phillips, W., Jr.; Bahn, A.K. Experience with computer matching of names. In Proceedings of the American Statistical Association, Social Statistics Section, Cleveland, OH, USA, 4–7 September 1963; American Statistical Association: Arlington, VA, USA, 1963; pp. 26–38. [Google Scholar]
- Fellegi, I.P.; Sunter, A.B. A theory for record linkage. J. Am. Stat. Assoc. 1969, 64, 1183–1210. [Google Scholar] [CrossRef]
- Bachi, R.; Baron, R.; Nathan, G. Methods of record-linkage and applications in Israel. Bull. Int. Stat. Inst. 1967, 41, 766–785. [Google Scholar]
- Hobbs, M.S.T.; McCall, M.G. Health statistics and record linkage in Australia. J. Chronic Dis. 1970, 23, 375–381. [Google Scholar] [CrossRef]
- Rahm, E.; Do, H.H. Data cleaning: Problems and current approaches. IEEE Data Eng. Bull. 2000, 23, 3–13. [Google Scholar]
- Howmanyofme.com. Available online: http://howmanyofme.com/ (accessed on 24 October 2019).
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. In Proceedings of the American Statistical Association, Section on Survey Research Methods, Anaheim, CA, USA, 6–9 August 1990; American Statistical Association: Alexandria, VA, USA, 1990; pp. 354–359. [Google Scholar]
- Cochinwala, M.; Kurien, V.; Lalk, G.; Shasha, D. Efficient data reconciliation. Inform. Sci. 2001, 137, 1–15. [Google Scholar] [CrossRef]
- Bilenko, M.; Mooney, R.J. 1. On Evaluation and Training-Set Construction for Duplicate Detection. In Proceedings of the KDD-03 Workshop on Data Cleaning, Record Linkage, and Object Consolidation, Washington, DC, USA, 24–27 August 2003; pp. 7–12. [Google Scholar]
- Chen, F.; Gao, B.J.; Doan, A.; Yang, J.; Ramakrishnan, R. Optimizing complex extraction programs over evolving text data. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, Providence, RI, USA, 29 June–2 July 2009; pp. 321–334. [Google Scholar]
- Gupta, R.; Sarawagi, S. Answering table augmentation queries from unstructured lists on the web. Proc. VLDB Endow. 2009, 2, 289–300. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Damerau, F.J. A technique for computer detection and correction of spelling errors. Commun. ACM 1964, 7, 171–176. [Google Scholar] [CrossRef]
- Martinez-Gil, J. CoTO: A novel approach for fuzzy aggregation of semantic similarity measures. Cogn. Syst. Res. 2016, 40, 8–17. [Google Scholar] [CrossRef] [Green Version]
- Liseo, B.; Tancredi, A. Some Advances on Bayesian Record Linkage and Inference for Linked Data 2013. Available online: http://www.ine.es/e/essnetdi_ws2011/ppts/Liseo_Tancredi.pdf (accessed on 16 September 2020).
- Steorts, R.C.; Hall, R.; Fienberg, S.E. A Bayesian approach to graphical record linkage and deduplication. J. Am. Stat. Assoc. 2016, 111, 1660–1672. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, L.; Stoové, M.; Boyle, D.; Callander, D.; McManus, H.; Asselin, J.; Guy, R.; Donovan, B.; Hellard, M.; El-Hayek, C. Privacy-Preserving Record Linkage of Deidentified Records Within a Public Health Surveillance System: Evaluation Study. J. Med. Internet Res. 2020, 22, e16757. [Google Scholar] [CrossRef]
- Morgan, K.; Page, N.; Brown, R.; Long, S.; Hewitt, G.; Del Pozo-Banos, M.; John, A.; Murphy, S.; Moore, G. Sources of potential bias when combining routine data linkage and a national survey of secondary school-aged children: A record linkage study. BMC Med Res. Methodol. 2020, 20, 1–13. [Google Scholar] [CrossRef]
- Smartystreets. Available online: https://smartystreets.com/pricing (accessed on 24 October 2019).
- Goldstein, H.; Harron, K. Record linkage: A missing data problem. In Methodological Developments in Data Linkage; Harron, K., Goldstein, H., Dibben, C., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2015; pp. 109–124. [Google Scholar]
- Ong, T.C.; Mannino, M.V.; Schilling, L.M.; Kahn, M.G. Improving record linkage performance in the presence of missing linkage data. J. Biomed. Inf. 2014, 52, 43–54. [Google Scholar] [CrossRef] [Green Version]
- Resnick, D.; Asher, J. Measurement of Type I and Type II Record Linkage Error. In Proceedings of the American Statistical Association, Government Statistics Section, Denver, CO, USA, 1 August 2019; American Statistical Association: Arlington, VA, USA, 2019; pp. 293–311. [Google Scholar]
- Karr, A.F.; Taylor, M.T.; West, S.L.; Setoguchi, S.; Kou, T.D.; Gerhard, T.; Horton, D.B. Comparing record linkage software programs and algorithms using real-world data. PLoS ONE 2019, 14. [Google Scholar] [CrossRef] [PubMed]
- Enamorado, T.; Fifield, B.; Imai, K. Using a probabilistic model to assist merging of large-scale administrative records. Am. Polit. Sci. Rev. 2019, 113, 353–371. [Google Scholar] [CrossRef]
- Vatsalan, D.; Christen, P.; Verykios, V.S. A taxonomy of privacy-preserving record linkage techniques. Inform. Syst. 2013, 38, 946–969. [Google Scholar] [CrossRef]
- Privacy Preserving Record Linkage. Available online: https://github.com/data61/anonlink (accessed on 21 September 2020).
- Linkwise: A Modern Privacy Preserving Record Linkage Software. Available online: https://policywise.com/2018/03/15/linkwise/ (accessed on 31 December 2019).
- PPRL: Privacy Preserving Record Linkage. Available online: https://cran.r-project.org/web/packages/PPRL/index.html (accessed on 31 December 2019).
- Lariscy, J.T. Differential record linkage by Hispanic ethnicity and age in linked mortality studies: Implications for the epidemiologic paradox. J. Aging Health 2011, 23, 1263–1284. [Google Scholar] [CrossRef] [Green Version]
- Lariscy, J.T. Black–white disparities in adult mortality: Implications of differential record linkage for understanding the mortality crossover. Popul. Res. Pol. Rev. 2017, 36, 137–156. [Google Scholar] [CrossRef] [Green Version]
- del Pilar Angeles, M.; Bailón-Miguel, N. Performance of Spanish Encoding Functions during Record Linkage. In Data Analytics 2016, Proceedings of the Fifth International Conference on Data Analytics, Venice, Italy, 9–13 October 2016; Bhulai, S., Semanjski, I., Eds.; IARIA: Wilmington, DE, USA, 2016; pp. 1–7. [Google Scholar]
- Munkhjargal, Z.; Bella, G.; Chagnaa, A.; Giunchiglia, F. Named entity recognition for Mongolian language. In Proceedings of the International Conference on Text, Speech, and Dialogue, Pilsen, Czech Republic, 14–17 September 2015; Král, P., Matoušek, V., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 243–251. [Google Scholar] [CrossRef] [Green Version]
- Ma, B.; Yang, Y.; Zhou, X.; Wang, L. Graph-based short text entity linking: A data integration perspective. In Proceedings of the 2016 International Conference on Asian Language Processing (IALP), Tainan, Taiwan, 21–23 November 2016; Institute of Electrical and Electronics Engineers (IEEE) Xplore Digital Library: Piscataway, NJ, USA, 2016; pp. 193–197. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Field 1: First Name | Field 2: Last Name | Field 3: Date of Birth | Field 4: Address | Field 5: Gender |
|---|---|---|---|---|
| Jana | Asher | 10/17/1970 | 603 Brook Court | F |
| Jane | Asher | 10/17/1970 | 1111 Jackson Ave | F |
| m1 = 0.95 | m2 = 0.99 | m3 = 0.97 | m4 = 0.95 | m5 = 0.99 |
| u1 = 0.001 | u2 = 0.00004 | u3 = 0.001 | u4 = 0.01 | u5 = 0.48 |
| log2((1 − m1)/(1 − u1)) = −4.32 | log2(m2/u2) = 14.60 | log2(m3/u3) = 9.92 | log2((1 − m4)/(1 − u4)) = −4.31 | log2(m5/u5) = 1.31 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asher, J.; Resnick, D.; Brite, J.; Brackbill, R.; Cone, J. An Introduction to Probabilistic Record Linkage with a Focus on Linkage Processing for WTC Registries. Int. J. Environ. Res. Public Health 2020, 17, 6937. https://doi.org/10.3390/ijerph17186937
Asher J, Resnick D, Brite J, Brackbill R, Cone J. An Introduction to Probabilistic Record Linkage with a Focus on Linkage Processing for WTC Registries. International Journal of Environmental Research and Public Health. 2020; 17(18):6937. https://doi.org/10.3390/ijerph17186937
Chicago/Turabian StyleAsher, Jana, Dean Resnick, Jennifer Brite, Robert Brackbill, and James Cone. 2020. "An Introduction to Probabilistic Record Linkage with a Focus on Linkage Processing for WTC Registries" International Journal of Environmental Research and Public Health 17, no. 18: 6937. https://doi.org/10.3390/ijerph17186937
APA StyleAsher, J., Resnick, D., Brite, J., Brackbill, R., & Cone, J. (2020). An Introduction to Probabilistic Record Linkage with a Focus on Linkage Processing for WTC Registries. International Journal of Environmental Research and Public Health, 17(18), 6937. https://doi.org/10.3390/ijerph17186937