Measuring Mental Effort for Creating Mobile Data Collection Applications

 ,
,  , , , , and
, , , , and 
Abstract
:1. Introduction
2. Material and Methods
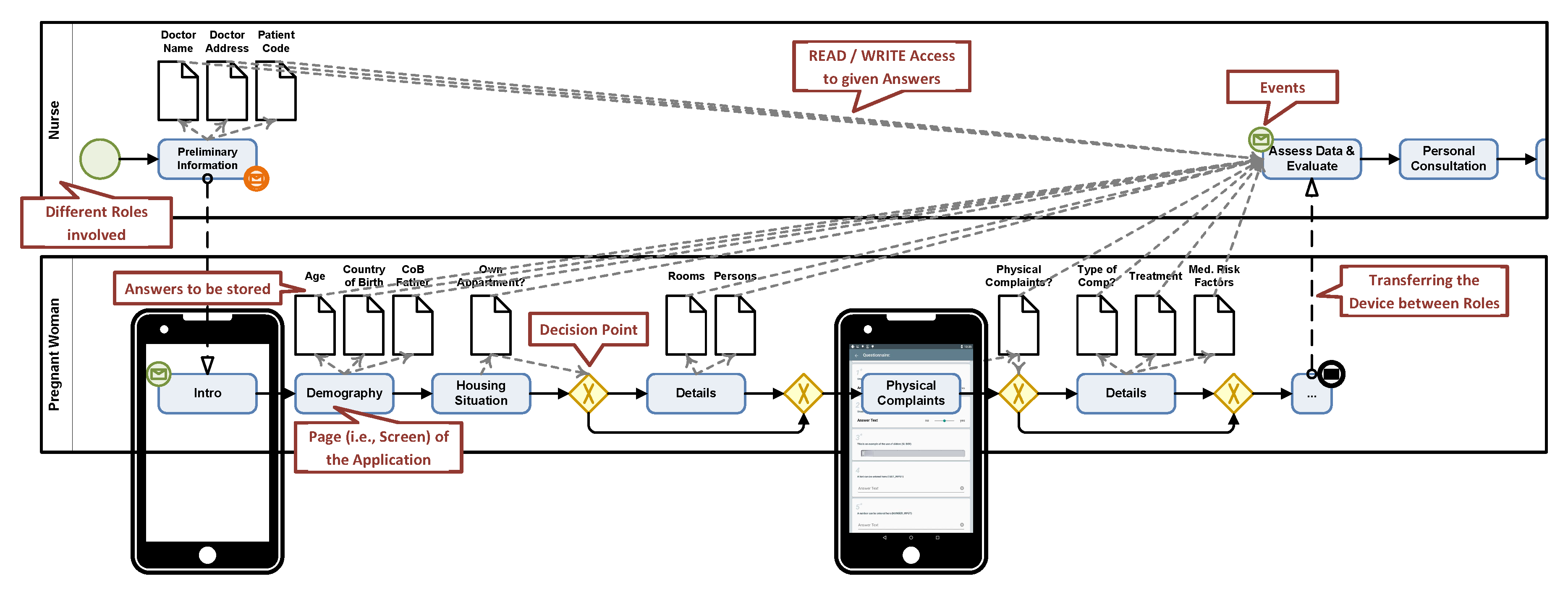
2.1. QuestionSys Framework Background Information
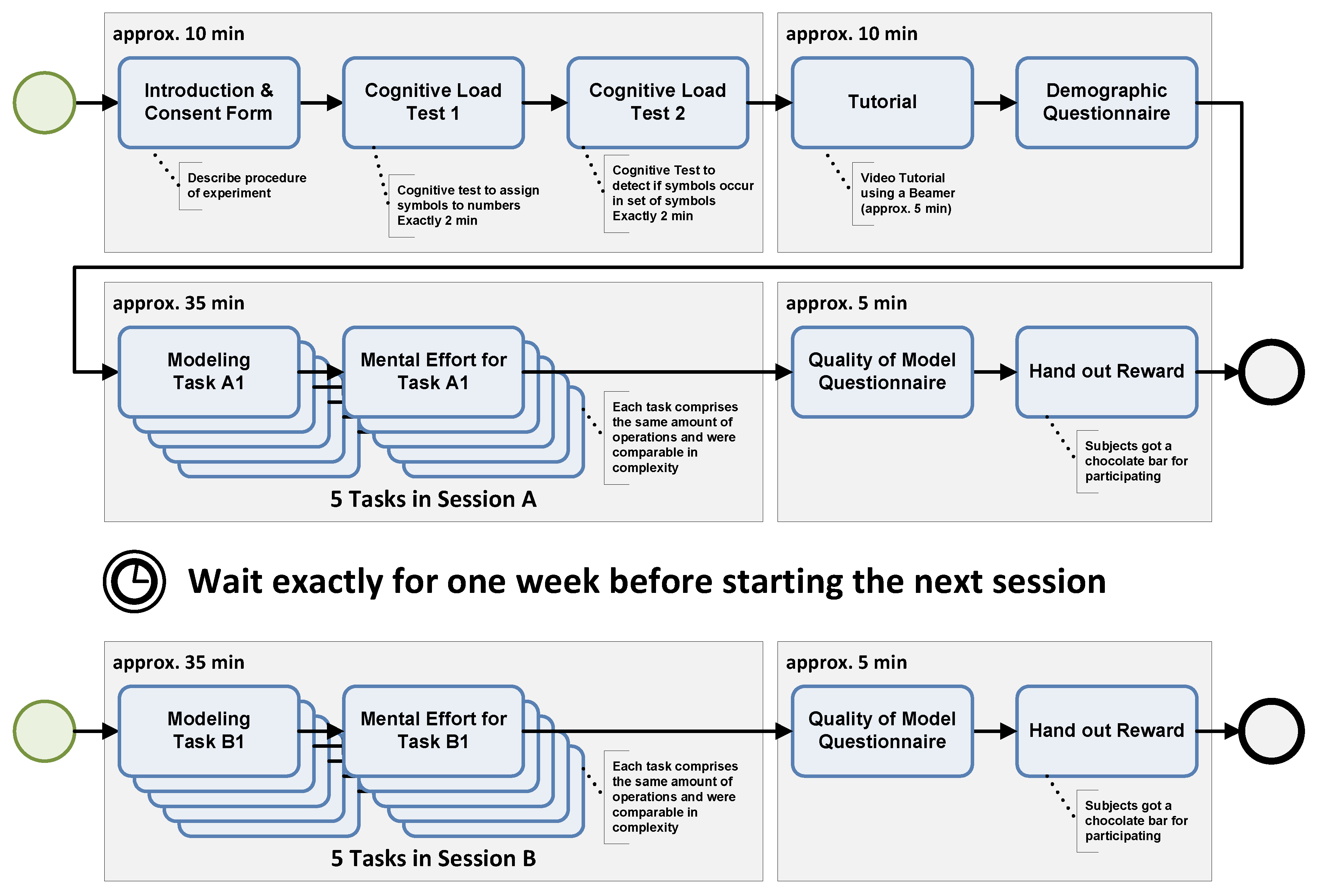
2.2. Study Procedure
2.3. Participants
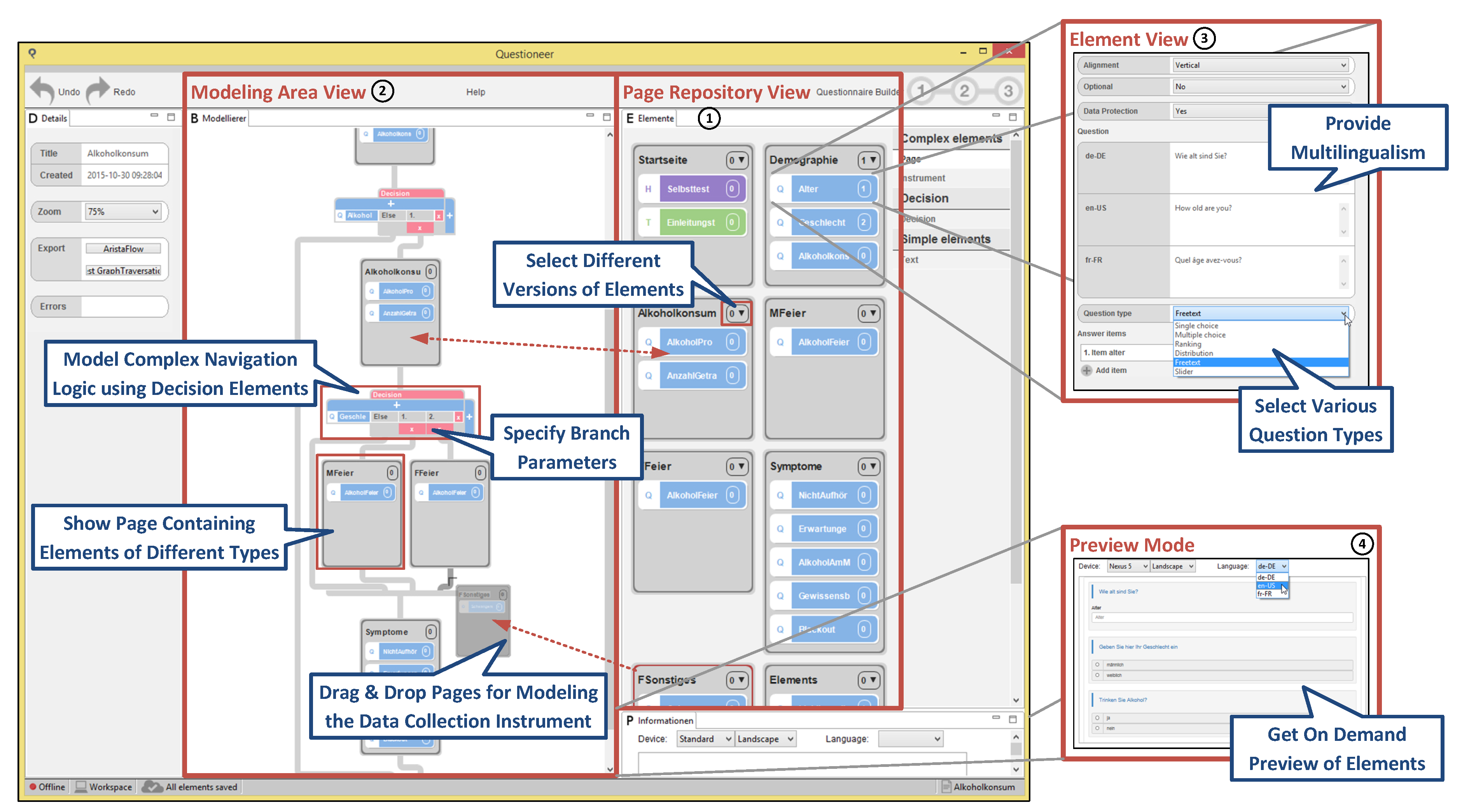
2.4. Configurator Component
2.5. Performance Measures
2.5.1. Time
2.5.2. Operations
2.5.3. Errors
2.6. Tutorial
2.7. Tasks
2.8. Questionnaires
2.9. Statistics
2.10. Data Availability
3. Results
3.1. Results for RQ 1
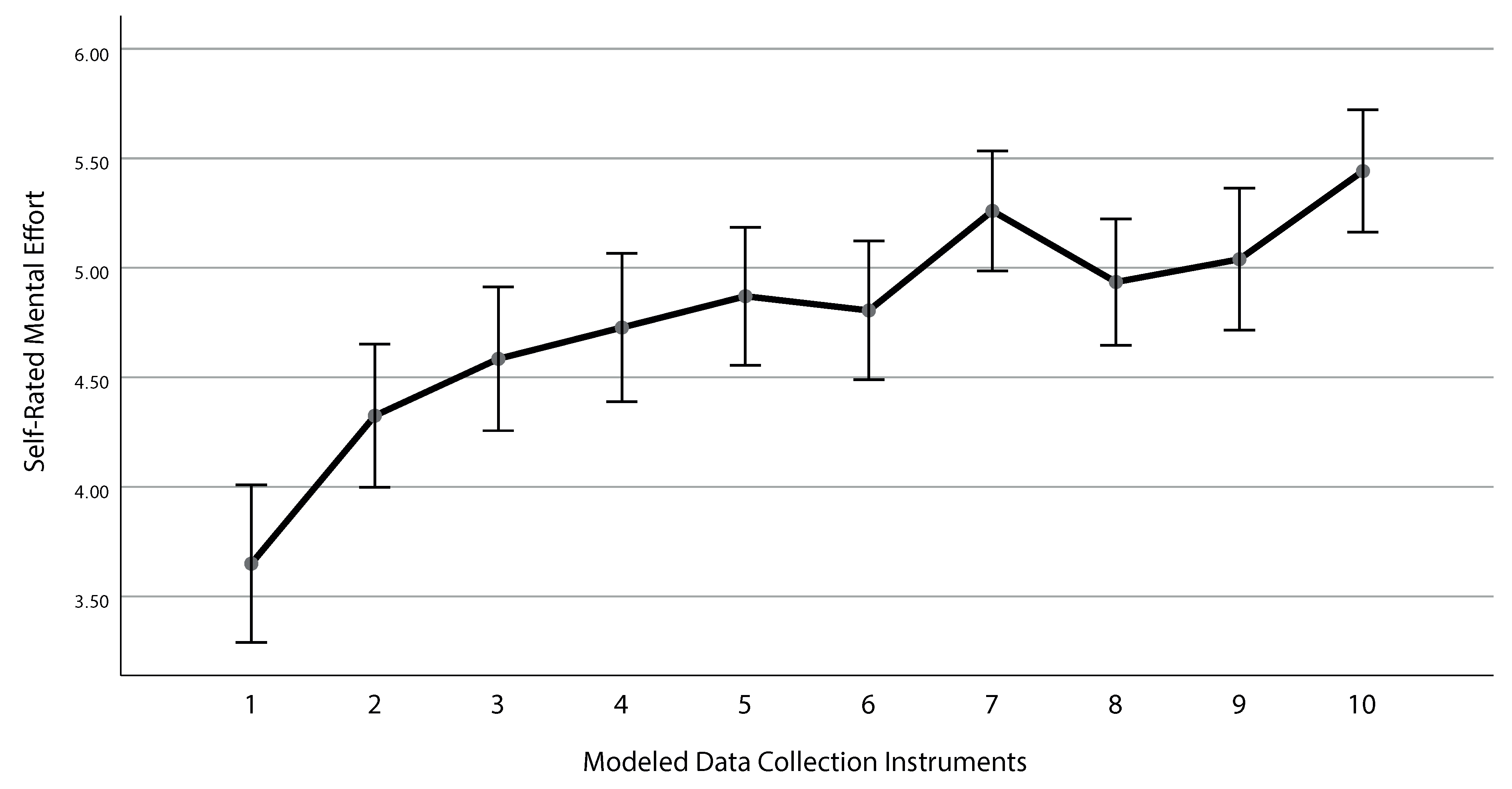
3.2. Results for RQ 2
3.3. Results for RQ 3
4. Discussion
Supplementary Materials
Supplementary File 1Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fernandez-Ballesteros, R. Self-report questionnaires. Compr. Handb. Psychol. Assess. 2004, 3, 194–221. [Google Scholar]
- Pavlović, I.; Kern, T.; Miklavčič, D. Comparison of paper-based and electronic data collection process in clinical trials: Costs simulation study. Contemp. Clin. Trials 2009, 30, 300–316. [Google Scholar] [CrossRef] [PubMed]
- Carlbring, P.; Brunt, S.; Bohman, S.; Austin, D.; Richards, J.; Öst, L.G.; Andersson, G. Internet vs. paper and pencil administration of questionnaires commonly used in panic/agoraphobia research. Comput. Hum. Behav. 2007, 23, 1421–1434. [Google Scholar] [CrossRef]
- Palermo, T.M.; Valenzuela, D.; Stork, P.P. A randomized trial of electronic versus paper pain diaries in children: Impact on compliance, accuracy, and acceptability. Pain 2004, 107, 213–219. [Google Scholar] [CrossRef]
- Marcano Belisario, J.S.; Jamsek, J.; Huckvale, K.; O’Donoghue, J.; Morrison, C.P.; Car, J. Comparison of self-administered survey questionnaire responses collected using mobile apps versus other methods. Cochrane Database Syst. Rev. 2015. [Google Scholar] [CrossRef]
- Pryss, R.; Reichert, M.; Schickler, M.; Bauer, T. Context-Based Assignment and Execution of Human-centric Mobile Services. In Proceedings of the 2016 IEEE International Conference on Mobile Services (MS), San Francisco, CA, USA, 27 June–2 July 2016; pp. 119–126. [Google Scholar]
- O’Reilly, A.M.; Slevin, P.; Ward, T.; Caulfield, B. A Wearable Sensor-Based Exercise Biofeedback System: Mixed Methods Evaluation of Formulift. JMIR MHealth UHealth 2018, 6, e33. [Google Scholar] [CrossRef] [Green Version]
- Lane, S.J.; Heddle, N.M.; Arnold, E.; Walker, I. A review of randomized controlled trials comparing the effectiveness of hand held computers with paper methods for data collection. BMC Med. Inform. Decis. Mak. 2006, 6, 1. [Google Scholar] [CrossRef] [Green Version]
- Aljaaf, A.J.; Van Tonder, L.; Mallucci, C.; Al-Jumeily, D.; Hussain, A.; Alloghani, M. Patients Attitude to Technology. J. Med. Syst. 2019, 43, 295. [Google Scholar] [CrossRef]
- Layton, A.M.; Whitworth, J.; Peacock, J.; Bartels, M.N.; Jellen, P.A.; Thomashow, B.M. Feasibility and acceptability of utilizing a smartphone based application to monitor outpatient discharge instruction compliance in cardiac disease patients around discharge from hospitalization. Int. J. Telemed. Appl. 2014, 2014, 415868. [Google Scholar] [CrossRef] [Green Version]
- Anhøj, J.; Møldrup, C. Feasibility of collecting diary data from asthma patients through mobile phones and SMS (short message service): Response rate analysis and focus group evaluation from a pilot study. J. Med. Internet Res. 2004, 6, e42. [Google Scholar] [CrossRef]
- Pryss, R.; Reichert, M.; Bachmeier, A.; Albach, J. BPM to Go: Supporting Business Processes in a Mobile and Sensing World; BPM Everywhere: Internet of Things, Process of Everything; Future Strategies Inc.: Lighthouse Point, FL, USA, 2015; pp. 167–182. [Google Scholar]
- Luxton, D.D.; McCann, R.A.; Bush, N.E.; Mishkind, M.C.; Reger, G.M. mHealth for mental health: Integrating smartphone technology in behavioral healthcare. Prof. Psychol. Res. Pract. 2011, 42, 505–512. [Google Scholar] [CrossRef] [Green Version]
- Probst, T.; Pryss, R.; Langguth, B.; Schlee, W. Emotion dynamics and tinnitus: Daily life data from the “TrackYourTinnitus” application. Sci. Rep. 2016, 6, 31166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahman, A.Q.; Janmohamed, T.; Pirbaglou, M.; Ritvo, P.; Heffernan, M.J.; Clarke, H.; Katz, J. Patterns of User Engagement With the Mobile App, Manage My Pain: Results of a Data Mining Investigation. JMIR MHealth UHealth 2017, 5, e96. [Google Scholar] [CrossRef]
- Gaggioli, A.; Pioggia, G.; Tartarisco, G.; Baldus, G.; Corda, D.; Cipresso, P.; Riva, G. A mobile data collection platform for mental health research. Pers. Ubiquitous Comput. 2013, 17, 241–251. [Google Scholar] [CrossRef]
- Mirkovic, J.; Kaufman, D.R.; Ruland, C.M. Supporting cancer patients in illness management: Usability evaluation of a mobile app. JMIR MHealth UHealth 2014, 2, e33. [Google Scholar] [CrossRef]
- Boonstra, T.W.; Werner-Seidler, A.; O’Dea, B.; Larsen, M.E.; Christensen, H. Smartphone App to Investigate the Relationship between Social Connectivity and Mental Health. arXiv 2017, arXiv:1702.02644. [Google Scholar]
- Cafazzo, J.A.; Casselman, M.; Hamming, N.; Katzman, D.K.; Palmert, M.R. Design of an mHealth app for the self-management of adolescent type 1 diabetes: A pilot study. J. Med. Internet Res. 2012, 14, e70. [Google Scholar] [CrossRef]
- Mosa, A.S.M.; Yoo, I.; Sheets, L. A systematic review of healthcare applications for smartphones. BMC Med. Inform. Decis. Mak. 2012, 12, 67. [Google Scholar] [CrossRef] [Green Version]
- Keedle, H.; Schmied, V.; Burns, E.; Dahlen, H. The Design, Development, and Evaluation of a Qualitative Data Collection Application for Pregnant Women. J. Nurs. Scholarsh. 2017. [Google Scholar] [CrossRef] [Green Version]
- Ehrler, F.; Wipfli, R.; Teodoro, D.; Sarrey, E.; Walesa, M.; Lovis, C. Challenges in the implementation of a mobile application in clinical practice: Case study in the context of an application that manages the daily interventions of nurses. JMIR MHealth UHealth 2013, 1. [Google Scholar] [CrossRef]
- Park, E.A.; Lee, S. Multidimensionality: Redefining the digital divide in the smartphone era. Info 2015, 17, 80–96. [Google Scholar] [CrossRef]
- Ubhi, H.K.; Kotz, D.; Michie, S.; van Schayck, O.C.; West, R. A comparison of the characteristics of iOS and Android users of a smoking cessation app. Transl. Behav. Med. 2017, 7, 166–171. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schobel, J.; Probst, T.; Reichert, M.; Schickler, M.; Pryss, R. Enabling Sophisticated Lifecycle Support for Mobile Healthcare Data Collection Applications. IEEE Access 2019, 7, 61204–61217. [Google Scholar] [CrossRef]
- Schobel, J.; Pryss, R.; Schlee, W.; Probst, T.; Gebhardt, D.; Schickler, M.; Reichert, M. Development of Mobile Data Collection Applications by Domain Experts: Experimental Results from a Usability Study. In Proceedings of the International Conference on Advanced Information Systems Engineering, Essen, Germany, 12–16 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 60–75. [Google Scholar]
- Schobel, J.; Schickler, M.; Pryss, R.; Maier, F.; Reichert, M. Towards Process-Driven Mobile Data Collection Applications: Requirements, Challenges, Lessons Learned. In Proceedings of the 10th International Conference on Web Information Systems and Technologies (WEBIST 2014), Barcelona, Spain, 3–5 April 2014. [Google Scholar]
- Pryss, R.; Reichert, M.; Langguth, B.; Schlee, W. Mobile Crowd Sensing Services for Tinnitus Assessment, Therapy and Research. In Proceedings of the IEEE 4th International Conference on Mobile Services, New York, NY, USA, 27 June–2 July 2015. [Google Scholar]
- Ruf-Leuschner, M.; Pryss, R.; Liebrecht, M.; Schobel, J.; Spyridou, A.; Reichert, M.; Schauer, M. Preventing further trauma: KINDEX mum screen—Assessing and reacting towards psychosocial risk factors in pregnant women with the help of smartphone technologies. In Proceedings of the Congress of European Society of Traumatic Stress Studies (ESTSS) Conference, Bologna, Italy, 6–9 June 2013. [Google Scholar]
- Schobel, J.; Pryss, R.; Reichert, M. Using Smart Mobile Devices for Collecting Structured Data in Clinical Trials: Results From a Large-Scale Case Study. In Proceedings of the 28th IEEE International Symposium on Computer-Based Medical Systems, Sao Carlos, Brazil, 22–25 June 2015. [Google Scholar]
- Wilker, S.; Pfeiffer, A.; Kolassa, S.; Elbert, T.; Lingenfelder, B.; Ovuga, E.; Papassotiropoulos, A.; De Quervain, D.; Kolassa, I.T. The role of FKBP5 genotype in moderating long-term effectiveness of exposure-based psychotherapy for posttraumatic stress disorder. Transl. Psychiatry 2014, 4, e403. [Google Scholar] [CrossRef]
- Isele, D.; Ruf-Leuschner, M.; Pryss, R.; Schauer, M.; Reichert, M.; Schobel, J.; Schindler, A.; Elbert, T. Detecting adverse childhood experiences with a little help from tablet computers. In Proceedings of the Congress of European Society of Traumatic Stress Studies (ESTSS) Conference, Bologna, Italy, 6–9 June 2013. [Google Scholar]
- Holzinger, A.; Kosec, P.; Schwantzer, G.; Debevc, M.; Hofmann-Wellenhof, R.; Frühauf, J. Design and development of a mobile computer application to reengineer workflows in the hospital and the methodology to evaluate its effectiveness. J. Biomed. Inform. 2011, 44, 968–977. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Cheow, E.; Ho, C.S.; Ng, B.Y.; Ho, R.; Cheok, C.C.S. Application of low-cost methodologies for mobile phone app development. JMIR MHealth UHealth 2014, 2, e55. [Google Scholar] [CrossRef]
- Vankipuram, A.; Vankipuram, M.; Ghaemmaghami, V.; Patel, V.L. A Mobile Application to Support Collection and Analytics of Real-Time Critical Care Data. Comput. Methods Programs Biomed. 2017, 151, 45–55. [Google Scholar] [CrossRef]
- Rieger, C.; Kuchen, H. A process-oriented modeling approach for graphical development of mobile business apps. Comput. Lang. Syst. Struct. 2018, 53, 43–58. [Google Scholar] [CrossRef]
- Reichert, M.; Dadam, P. ADEPTflex—Supporting Dynamic Changes of Workflows Without Losing Control. J. Intell. Inf. Syst. 1998, 10, 93–129. [Google Scholar] [CrossRef]
- Schobel, J.; Pryss, R.; Schickler, M.; Ruf-Leuschner, M.; Elbert, T.; Reichert, M. End-User Programming of Mobile Services: Empowering Domain Experts to Implement Mobile Data Collection Applications. In Proceedings of the IEEE 5th International Conference on Mobile Services, San Francisco, CA, USA, 27 June–2 July 2016. [Google Scholar]
- Paternò, F. End user development: Survey of an emerging field for empowering people. ISRN Softw. Eng. 2013, 2013, 532659. [Google Scholar] [CrossRef] [Green Version]
- Scaffidi, C.; Shaw, M.; Myers, B. Estimating the numbers of end users and end user programmers. In Proceedings of the 2005 IEEE Symposium on Visual Languages and Human-Centric Computing, Dallas, TX, USA, 21–24 September 2005; pp. 207–214. [Google Scholar]
- Klopfer, E.; Yoon, S.; Um, T. Teaching complex dynamic systems to young students with StarLogo. J. Comput. Math. Sci. Teach. 2005, 24, 157–178. [Google Scholar]
- Begel, A.; Klopfer, E. Starlogo TNG: An Introduction to Game Development. J. E-Learn. 2007, 53, 146–160. [Google Scholar]
- Weintrop, D.; Wilensky, U. Comparing block-based and text-based programming in high school computer science classrooms. ACM Trans. Comput. Educ. (TOCE) 2017, 18, 3. [Google Scholar] [CrossRef]
- Cappiello, C.; Matera, M.; Picozzi, M. A UI-centric approach for the end-user development of multidevice mashups. ACM Trans. Web (TWEB) 2015, 9, 11. [Google Scholar] [CrossRef] [Green Version]
- Chang, K.S.P.; Myers, B.A. Creating interactive web data applications with spreadsheets. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; pp. 87–96. [Google Scholar]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Schobel, J.; Pryss, R.; Schickler, M.; Reichert, M. A Configurator Component for End-User Defined Mobile Data Collection Processes. In Proceedings of the 14th International Conference on Service Oriented Computing, Banff, AB, Canada, 10–13 October 2016. [Google Scholar]
- Schobel, J.; Pryss, R.; Probst, T.; Schlee, W.; Schickler, M.; Reichert, M. Learnability of a Configurator Empowering End Users to Create Mobile Data Collection Instruments: Usability Study. JMIR MHealth UHealth 2018, 6, e148. [Google Scholar] [CrossRef] [Green Version]
- Cook, T.D.; Campbell, D.T.; Day, A. Quasi-Experimentation: Design & Analysis Issues for Field Settings; Houghton Mifflin: Boston, MA, USA, 1979; Volume 351. [Google Scholar]
- Höst, M.; Regnell, B.; Wohlin, C. Using Students as Subjects—A Comparative Study of Students and Professionals in Lead-Time Impact Assessment. Empir. Softw. Eng. 2000, 5, 201–214. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Collection Scenario | Country | CN | Duration | Versions | Processed Instruments |
|---|---|---|---|---|---|
| Study on Tinnitus Research [28] | World-Wide | ∘ | 5 + | 5 | ≥45,000 |
| Risk Factors during Pregnancy [29] | Germany | ∘ | 5 + | 5 | ≥1500 |
| Risk Factors after Pregnancy | Germany | ∘ | 2 + | 1 | ≥500 |
| Posttraumatic Stress Disorder in War Regions [30] | Burundi | • | 4 + | 5 | ≥2200 |
| Posttraumatic Stress Disorder in War Regions [31] | Uganda | ∘ | 1 + | 1 | ≥200 |
| Adverse Childhood Experiences [32] | Germany | • | 2 + | 3 | ≥150 |
| Learning Deficits among Medical Students | Germany | • | 1 + | 3 | ≥200 |
| Supporting Parents after Accidents of Children | EU | ∘ | 3 + | 6 | ≥5000 |
| Overall | 29 | ≥54,750 | |||
| CN = Complex Navigation | |||||
| # | Modeling a Questionnaire … | Pages | Decisions |
|---|---|---|---|
| 1 | …to collect information about flight passengers. | 5 | 2 |
| 2 | …to help customers selecting an appropriate smartphone. | 5 | 2 |
| 3 | …to help collecting required information for travel expense reports. | 5 | 2 |
| 4 | …to order food and drinks online. | 5 | 2 |
| 5 | …to support customers selecting a movie and booking cinema tickets. | 5 | 2 |
| 6 | …to help customers selecting an appropriate laptop computer. | 5 | 2 |
| 7 | …to support customers book seats for a theater play. | 5 | 2 |
| 8 | …to inform patients regarding their upcoming surgery. | 5 | 2 |
| 9 | …to guide customers through the process of purchasing a new coffee machine and equipment. | 5 | 2 |
| 10 | …to collect required data to conclude a contract in a gym. | 5 | 2 |
| Variable | Novices (N = 45) | Experts (N = 35) | Significance Value |
|---|---|---|---|
| Gender n (%) | (FET) | ||
| female | 31 (68.9) | 12 (34.3) | |
| male | 14 (31.1) | 23 (65.7) | |
| Age n (%) | 21.20 (2.63) | 22.72 (2.97) | (FET) |
| <25 years | 29 (64.4) | 17 (48.6) | |
| 25–35 years | 16 (35.6) | 18 (51.4) | |
| Highest Education n (%) | (FET) | ||
| High School | 13 (28.9) | 2 (5.7) | |
| Bachelor | 32 (71.1) | 32 (91.4) | |
| Master | 0 (0.0) | 1 (2.9) | |
| Current Field of Study n (%) # | (FET) | ||
| Economics | 14 (32.6) | 12 (40.0) | |
| Media Computer Science | 0 (0.0) | 8 (26.7) | |
| Computer Science | 1 (2.3) | 6 (20.0) | |
| International Business | 0 (0.0) | 1 (3.3) | |
| Chemistry | 2 (4.7) | 0 (0.0) | |
| Psychology | 26 (60.5) | 3 (10.0) | |
| Processing Speed Test 1: Digit Symbol-Coding | |||
| Correct Answers M (SD) | 84.33 (21.76) | 81.11 (21.89) | |
| Wrong Answers M (SD) | 0.07 (0.25) | 0.06 (0.24) | |
| Processing Speed Test 2: Symbol-Search | |||
| Correct Answers M (SD) | 41.93 (7.77) | 38.91 (8.53) | |
| Wrong Answers M (SD) | 1.73 (1.98) | 1.63 (1.50) | |
| Novices | Experts | |||||||
|---|---|---|---|---|---|---|---|---|
| T | S | Operations | Time | Errors | Operations | Time | Errors | |
| 1 | 1 | Mental Effort (higher values indicate less mental effort) | −0.126 | −0.213 | −0.345 * | −0.290 | −0.336 * | −0.389 * |
| 2 | 1 | −0.254 | −0.289 | −0.360 * | −0.434 ** | −0.483 ** | −0.276 | |
| 3 | 1 | −0.235 | −0.209 | −0.303 * | −0.213 | −0.42 * | −0.091 | |
| 4 | 1 | −0.326 * | −0.326 * | −0.478 * | −0.361 * | −0.288 | 0.043 | |
| 5 | 1 | −0.083 | 0.022 | −0.379 * | −0.132 | −0.082 | −0.213 | |
| 6 | 2 | −0.344 * | −0.273 | −0.294 | −0.356 * | −0.100 | −0.125 | |
| 7 | 2 | −0.581 ** | −0.654 ** | −0.395 ** | 0.078 | −0.139 | 0.048 | |
| 8 | 2 | −0.575 ** | −0.271 | −0.382* | −0.109 | −0.245 | −0.051 | |
| 9 | 2 | −0.527 ** | −0.532 ** | −0.369 * | −0.233 | −0.426 * | −0.112 | |
| 10 | 2 | −0.767 ** | −0.678 ** | −0.332 * | −0.360 * | −0.105 | −0.446 ** | |
| Parameter | Estimate | SE | df | t | p | ||
|---|---|---|---|---|---|---|---|
| Operations | Novices | Intercept | 20.26 | 0.86 | 445 | 23.60 | <0.001 |
| ME | −1.64 | 0.18 | 445 | −9.01 | <0.001 | ||
| Experts | Intercept | 20.02 | 1.26 | 340 | 15.86 | <0.001 | |
| ME | −1.55 | 0.24 | 340 | −6.51 | <0.001 | ||
| Time | Novices | Intercept | 399,922.55 | 22,369.82 | 445 | 17.88 | <0.001 |
| ME | −43,497.32 | 4749.41 | 445 | −9.16 | <0.001 | ||
| Experts | Intercept | 402,457.16 | 31,110.13 | 340 | 12.94 | <0.001 | |
| ME | −42,536.92 | 5884.83 | 340 | −7.23 | <0.001 | ||
| Errors | Novices | Intercept | 2.92 | 0.24 | 445 | 12.17 | <0.001 |
| ME | −0.43 | 0.05 | 445 | −8.53 | <0.001 | ||
| Experts | Intercept | 0.88 | 0.17 | 335 | 5.25 | <0.001 | |
| ME | −0.11 | 0.03 | 335 | −3.50 | <0.001 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schobel, J.; Probst, T.; Reichert, M.; Schlee, W.; Schickler, M.; Kestler, H.A.; Pryss, R. Measuring Mental Effort for Creating Mobile Data Collection Applications. Int. J. Environ. Res. Public Health 2020, 17, 1649. https://doi.org/10.3390/ijerph17051649
Schobel J, Probst T, Reichert M, Schlee W, Schickler M, Kestler HA, Pryss R. Measuring Mental Effort for Creating Mobile Data Collection Applications. International Journal of Environmental Research and Public Health. 2020; 17(5):1649. https://doi.org/10.3390/ijerph17051649
Chicago/Turabian StyleSchobel, Johannes, Thomas Probst, Manfred Reichert, Winfried Schlee, Marc Schickler, Hans A. Kestler, and Rüdiger Pryss. 2020. "Measuring Mental Effort for Creating Mobile Data Collection Applications" International Journal of Environmental Research and Public Health 17, no. 5: 1649. https://doi.org/10.3390/ijerph17051649
APA StyleSchobel, J., Probst, T., Reichert, M., Schlee, W., Schickler, M., Kestler, H. A., & Pryss, R. (2020). Measuring Mental Effort for Creating Mobile Data Collection Applications. International Journal of Environmental Research and Public Health, 17(5), 1649. https://doi.org/10.3390/ijerph17051649