
A Weakly-Supervised Named Entity Recognition Machine Learning Approach for Emergency Medical Services Clinical Audit

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Methods
2.1. Data Preparation and Preprocessing
2.2. Weakly-Supervised Labelling
2.3. Model Training
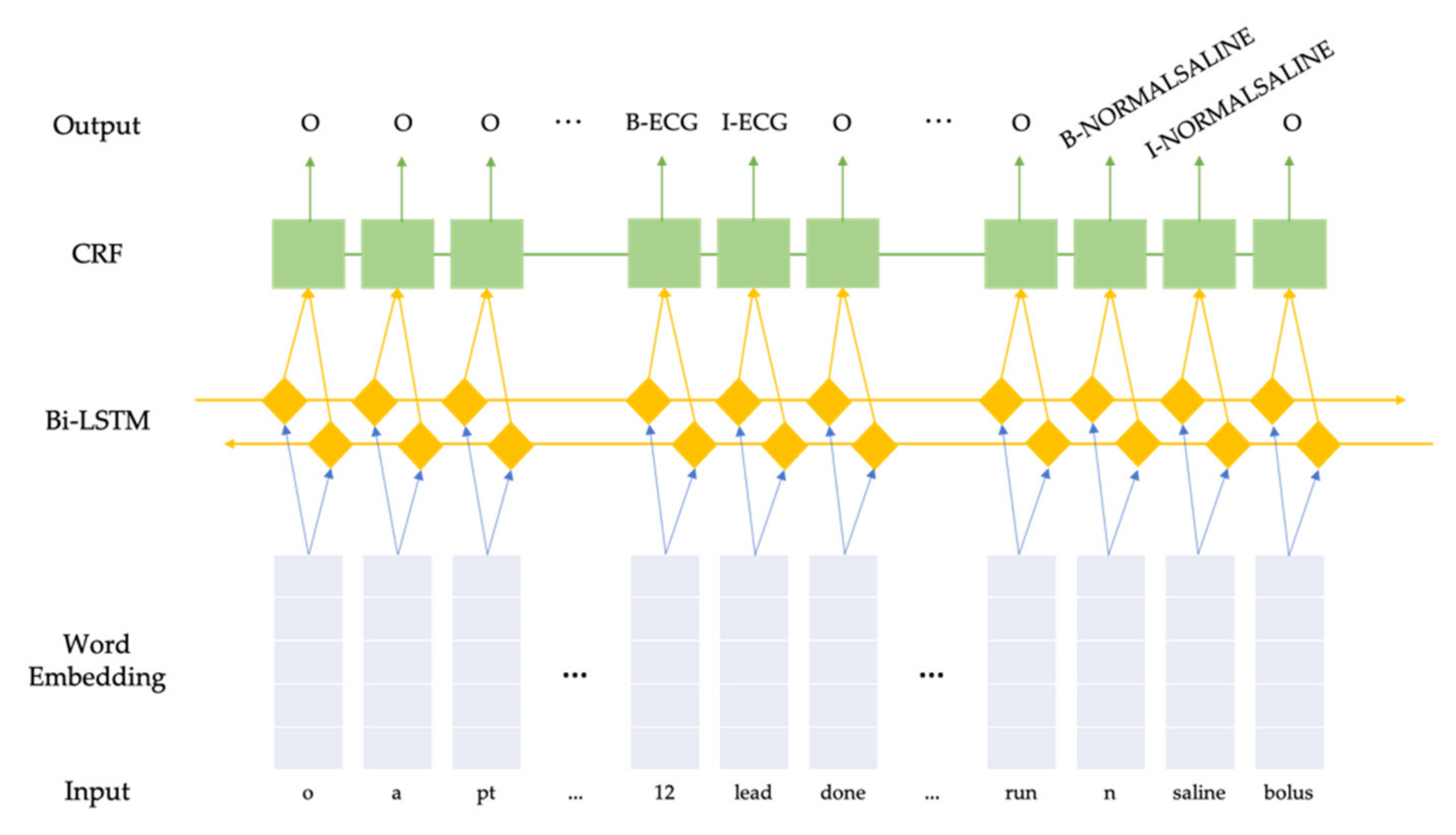
2.3.1. Bidirectional Long Short-Term Memory + Conditional Random Fields
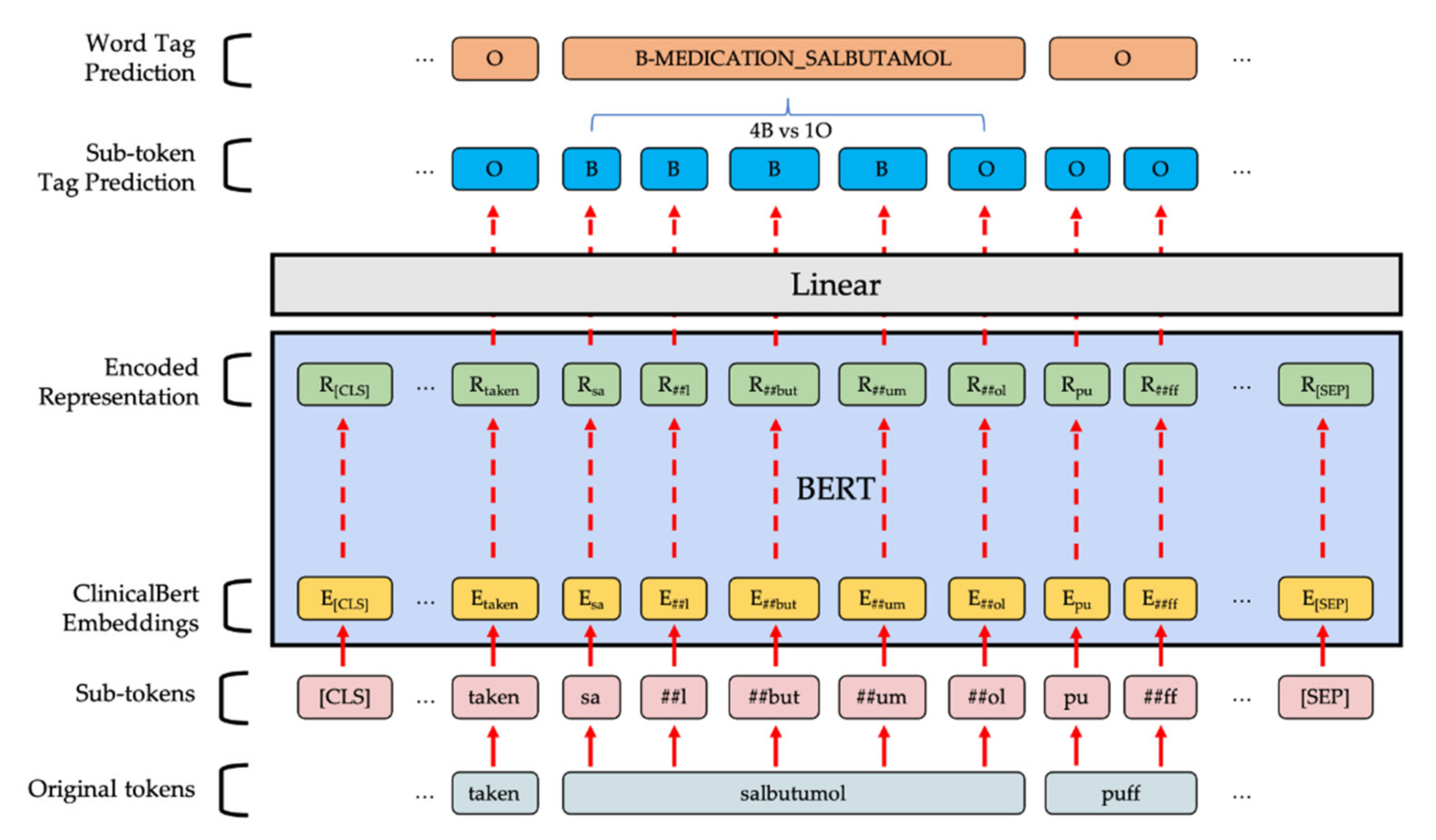
2.3.2. BERT-Based Token Classifier
2.4. Model Evaluation
2.4.1. Token Class Level
2.4.2. Entity Level
- Correct (COR): the system’s output is the same as the gold-standard annotation.
- Incorrect (INC): the system’s output has nothing in common with the gold-standard annotation.
- Partial (PAR): the system’s output shares some overlapping text with the gold-standard annotation.
- Missing (MIS): a gold-standard annotation is not captured by the system.
- Spurius (SPU): the system labels an entity which does not exist in the gold-standard annotation.
- Possible (POS): the number of annotations in the gold-standard which contribute to the final score.
- Actual (ACT): the total number of annotations produced by the system.
- Precision: the percentage of entities found by the system that are correct.
- Recall: the percentage of entities present in the data that are found by the system.
- F1-score: the harmonic mean of precision and recall.
2.5. Web Demo
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Paton, J.Y.; Ranmal, R.; Dudley, J. Clinical audit: Still an important tool for improving healthcare. Arch. Dis. Child. Educ. Pr. Ed. 2014, 100, 83–88. [Google Scholar] [CrossRef] [PubMed]
- Munk, M.-D.; White, S.D.; Perry, M.L.; Platt, T.E.; Hardan, M.S.; Stoy, W.A. Physician medical direction and clinical performance at an established emergency medical services system. Prehospital Emerg. Care 2009, 13, 185–192. [Google Scholar] [CrossRef] [PubMed]
- McClelland, G.; Flynn, D.; Rodgers, H.; Price, C. Positive predictive value of stroke identification by ambulance clinicians in North East England: A service evaluation. Emerg. Med. J. 2020, 37, 474–479. [Google Scholar] [CrossRef] [PubMed]
- Pocock, H.; Jadzinski, P.; Taylor-Jones, C.; King, P.; England, E.; Fogg, C. A clinical audit of the electronic data capture of dementia in ambulance service patient records. Br. Paramedic J. 2018, 2, 10–18. [Google Scholar] [CrossRef]
- Ashman, H.; Rigg, D.; Moore, F. The assessment and management of thermal burn injuries in a UK ambulance service: A clinical audit. Br. Paramedic J. 2020, 5, 52–58. [Google Scholar] [CrossRef]
- Johnston, G.; Crombie, I.K.; Alder, E.M.; Davies, O.H.T.; Millard, A. Reviewing audit: Barriers and facilitating factors for effective clinical audit. Qual. Health Care 2000, 9, 23–36. [Google Scholar] [CrossRef] [PubMed]
- SCDF Emergency Medical Services. SCDF. Available online: https://www.scdf.gov.sg/home/about-us/information/scdf-emergency-medical-services (accessed on 29 February 2021).
- Ng, Q.; Yeung, W.; Tay, J.; Arulanandam, S. Use of technology to aid clinical audit in an Asian emergency medical services department. Healthcare 2021, 9, 491. [Google Scholar] [CrossRef]
- Aramaki, E.; Miura, Y.; Tonoike, M.; Ohkuma, T.; Mashuichi, H.; Ohe, K. TEXT2TABLE: Medical Text Summarization System Based on Named Entity Recognition and Modality Identification. Proceedings of the BioNLP 2009 Workshop. Boulder, Colorado: Association for Computational Linguistics. 2009, pp. 185–192. Available online: https://www.aclweb.org/anthology/W09-1324 (accessed on 6 May 2021).
- Bodnari, A.; Deleger, L.; Lavergne, T.; Neveol, A.; Zweigenbaum, P. A Supervised Named-Entity Extraction System for Medical Text. 2013. Available online: http://clefpackages.elra.info/clefehealthtask3/workingnotes/CLEFeHealth2013_Lab_Working_Notes/TASK_1/CLEF2013wn-CLEFeHealth-BodnariEt2013.pdf (accessed on 1 July 2021).
- Leaman, R.; Khare, R.; Lu, Z. Challenges in clinical natural language processing for automated disorder normalization. J. Biomed. Inform. 2015, 57, 28–37. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sang, E.F.T.K. Memory-Based Shallow Parsing. arXiv 2002, arXiv:cs/0204049. Available online: http://arxiv.org/abs/cs/0204049 (accessed on 7 May 2021).
- Einat, T. taleinat/fuzzysearch. 2021. Available online: https://github.com/taleinat/fuzzysearch (accessed on 7 May 2021).
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, 28 June–1 July 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 282–2889. [Google Scholar]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003; 2003; pp. 188–191. Available online: https://www.aclweb.org/anthology/W03-0430 (accessed on 7 May 2021).
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. arXiv 2016, arXiv:1603.01360. Available online: http://arxiv.org/abs/1603.01360 (accessed on 7 May 2021).
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. Available online: http://arxiv.org/abs/1508.01991 (accessed on 7 May 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. Available online: http://arxiv.org/abs/1912.01703 (accessed on 13 April 2020).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. Available online: http://arxiv.org/abs/1412.6980 (accessed on 13 April 2020).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. Available online: http://arxiv.org/abs/1810.04805 (accessed on 6 May 2019).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:1910.03771. Available online: http://arxiv.org/abs/1910.03771 (accessed on 12 May 2020).
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. arXiv 2015, arXiv:1506.06724. Available online: http://arxiv.org/abs/1506.06724 (accessed on 18 May 2020).
- Alsentzer, E.; Murphy, J.; Boag, W.; Weng, W.-H.; Jindi, D.; Naumann, T.; McDermott, M.B.A. Publicly Available Clinical BERT Embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 72–78. Available online: https://www.aclweb.org/anthology/W19-1909 (accessed on 12 May 2020).
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.-W.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. Available online: http://arxiv.org/abs/1711.05101 (accessed on 13 May 2020).
- Chinchor, N.; Sundheim, B. MUC-5 Evaluation Metrics. In Proceedings of the Fifth Message Understanding Conference (MUC-5), Baltimore, Maryland, 25–27 August 1993; Available online: https://www.aclweb.org/anthology/M93-1007 (accessed on 13 April 2020).
- Task Description <Extraction of Drug-Drug Interactions from BioMedical Texts. Available online: https://www.cs.york.ac.uk/semeval-2013/task9/ (accessed on 19 April 2020).
- Grinberg, M. Flask Web Development: Developing Web Applications with Python, 1st ed; O’Reilly Media Inc.: Newton, MA, USA, 2014. [Google Scholar]
- Jinja. Pallets. Available online: https://palletsprojects.com/p/jinja/ (accessed on 11 May 2020).
- Cloud Application Platform|Heroku. Available online: https://www.heroku.com/ (accessed on 11 May 2020).
- displaCy spaCy Universe. displaCy. Available online: https://spacy.io/universe/project/displacy (accessed on 7 May 2021).
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. Available online: http://arxiv.org/abs/1609.08144 (accessed on 7 May 2021).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. Available online: http://arxiv.org/abs/1910.01108 (accessed on 7 May 2021).



{kind=link}
{kind=link}
| Category | Original Report | Pre-Processed Report |
|---|---|---|
| Acute coronary syndrome | hx from pt c/o chest pain x 2/7 crushing in nature, non-radiating. no trauma. no fall. o/a pt was sitting, alert, conscious. pt was gtn 1 tab by sn. o/e pt not pallor or diaphoretic. no sob/ giddiness/ nausea/ vomitting. afebrile. given 300 mg aspirin stat dose & 1 gtn spray 0.4 mg with total relieved. 12 lead ecg done: sinus rhythm. no other medical complaints | hx from pt c o chest pain x 2/7 crushing in nature non radiating no trauma no fall o a pt was sitting alert conscious pt was gtn 1 tab by sn o e pt not pallor or diaphoretic no sob giddiness nausea vomitting afebrile given 300 mg aspirin stat dose & 1 gtn spray 0 4 mg with total relieved 12 lead ecg done sinus rhythm no other medical complaints |
| Stroke | hx from helper, @9 m noted pt turns lethargic, but able to enunciate words clearly, @ 12 pm, noted pt slurred speech w slight rt facial droop. @2 pm, tried to feed pt water, and noted dysphagia, drooling. went to see gp @ 310 pm, noted to send to a&e. o/a, pt sitting, gcs 15, slight dementia. no c/o unwell. o/e, noted slight rt facial droop+ slurred speech. no bilateral weakness. pt is off hypertension med for a long time. usual bp @ 115/57 | hx from helper 9 m noted pt turns lethargic but able to enunciate words clearly 12 pm noted pt slurred speech w slight rt facial droop 2 pm tried to feed pt water and noted dysphagia drooling went to see gp 310 pm noted to send to a&e o a pt sitting gcs 15 slight dementia no c o unwell o e noted slight rt facial droop slurred speech no bilateral weakness pt is off hypertension med for a long time usual bp 115 57 |
| Bleeding | o/a- pt sitting conscious alert. hx fr pt- pt fell due to slippery floor, unsure hit what object noted bleeding, no loc. o/e- noted 3 cm laceration active bleeding. noted dislocated rt shoulder, pt claimed numbness but is due to fall 2/12 ago, did not see dr. pt unable to give furthur hx as he does not wish to talk much. | o a pt sitting conscious alert hx fr pt pt fell due to slippery floor unsure hit what object noted bleeding no loc o e noted 3 cm laceration active bleeding noted dislocated rt shoulder pt claimed numbness but is due to fall 2 12 ago did not see dr pt unable to give furthur hx as he does not wish to talk much |
| Category | Entity | Training | Development | Test | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Entiti-es | % of Total | Tokens | ATE * | Entiti-es | % of Total | Tokens | ATE * | Entiti-es | % of Total | Tokens | ATE * | ||
| Clinical Procedure | ECG | 26,688 | 50.6% | 43,661 | 1.64 | 691 | 49.1% | 1160 | 1.68 | 665 | 48.9% | 1101 | 1.66 |
| Clinical Procedure | Stroke Assessment | 6571 | 12.5% | 10,102 | 1.54 | 175 | 12.4% | 273 | 1.56 | 200 | 14.7% | 306 | 1.53 |
| Clinical Procedure | Intravenous Cannulation | 2054 | 3.9% | 2559 | 1.25 | 64 | 4.5% | 83 | 1.30 | 50 | 3.7% | 69 | 1.38 |
| Clinical Procedure | Burns Cooling | 57 | 0.1% | 57 | 1.00 | 4 | 0.3% | 4 | 1.00 | 0 | 0.0% | 0 | NA |
| Clinical Procedure | Valsalva Maneuver | 30 | 0.1% | 44 | 1.47 | 2 | 0.1% | 2 | 1.00 | 0 | 0.0% | 0 | NA |
| Clinical Finding | Bleeding | 7422 | 14.1% | 8785 | 1.18 | 189 | 13.4% | 230 | 1.22 | 182 | 13.4% | 218 | 1.20 |
| Clinical Finding | Signs Of Obvious Death | 323 | 0.6% | 639 | 1.98 | 10 | 0.7% | 18 | 1.80 | 8 | 0.6% | 16 | 2.00 |
| Medication | Nitroglycerin (GTN) | 2648 | 5.0% | 3835 | 1.45 | 72 | 5.1% | 104 | 1.44 | 64 | 4.7% | 102 | 1.59 |
| Medication | Aspirin | 1644 | 3.1% | 1644 | 1.00 | 51 | 3.6% | 51 | 1.00 | 45 | 3.3% | 45 | 1.00 |
| Medication | Normal Saline | 1371 | 2.6% | 4206 | 3.07 | 41 | 2.9% | 115 | 2.80 | 44 | 3.2% | 135 | 3.07 |
| Medication | Penthrox | 568 | 1.1% | 568 | 1.00 | 19 | 1.3% | 19 | 1.00 | 14 | 1.0% | 14 | 1.00 |
| Medication | Dextrose/ Glucose | 447 | 0.8% | 447 | 1.00 | 13 | 0.9% | 13 | 1.00 | 14 | 1.0% | 14 | 1.00 |
| Medication | Adrenaline | 412 | 0.8% | 412 | 1.00 | 14 | 1.0% | 14 | 1.00 | 8 | 0.6% | 8 | 1.00 |
| Medication | Diazepam | 394 | 0.7% | 394 | 1.00 | 8 | 0.6% | 8 | 1.00 | 11 | 0.8% | 11 | 1.00 |
| Medication | Salbutamol | 1794 | 3.4% | 1977 | 1.10 | 50 | 3.6% | 57 | 1.14 | 48 | 3.5% | 55 | 1.15 |
| Medication | Tramadol | 310 | 0.6% | 310 | 1.00 | 5 | 0.4% | 5 | 1.00 | 7 | 0.5% | 7 | 1.00 |
| Medication | Syntometrine | 45 | 0.1% | 45 | 1.00 | 0 | 0.0% | 0 | NA | 1 | 0.1% | 1 | 1.00 |
| Total (% of Total) | 52778 (100%) | 79685 (2.73%) | 1408 (100%) | 2156 (2.81%) | 1361 (100%) | 2102 (2.74%) | |||||||
| Evaluation Mode | Model | MUC-5 Scoring | SemEval’13 Metrics | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| COR | INC | MIS | SPU | POS | ACT | Precision | Recall | F1-Score | ||
| Entity Type Matching | BiLSTM-CRF | 1336 | 0 | 25 | 26 | 1361 | 1362 | 0.981 | 0.982 | 0.981 |
| BERTBASE | 1343 | 0 | 20 | 31 | 1363 | 1374 | 0.977 | 0.985 | 0.981 | |
| ClinicalBERT | 1343 | 0 | 20 | 30 | 1363 | 1373 | 0.978 | 0.985 | 0.982 | |
| Strict Evaluation | BiLSTM-CRF | 1329 | 7 | 25 | 26 | 1361 | 1362 | 0.976 | 0.976 | 0.976 |
| BERTBASE | 1335 | 8 | 20 | 31 | 1363 | 1374 | 0.972 | 0.979 | 0.976 | |
| Clinical-BERT | 1334 | 9 | 20 | 30 | 1363 | 1373 | 0.972 | 0.979 | 0.975 | |
| Model Parameters (in Millions) | Model Checkpoint Size (Mb) | Inference Wall Time (ms) | ||
|---|---|---|---|---|
| BiLSTM-CRF | 3.83 | 15 | 40 | (7.5) |
| BERTBASE | 109.50 | 418 | 274 | (16.2) |
| Clinical-BERT | 108.33 | 414 | 286 | (25.6) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Yeung, W.L.K.; Ng, Q.X.; Tung, A.; Tay, J.A.M.; Ryanputra, D.; Ong, M.E.H.; Feng, M.; Arulanandam, S. A Weakly-Supervised Named Entity Recognition Machine Learning Approach for Emergency Medical Services Clinical Audit. Int. J. Environ. Res. Public Health 2021, 18, 7776. https://doi.org/10.3390/ijerph18157776
Wang H, Yeung WLK, Ng QX, Tung A, Tay JAM, Ryanputra D, Ong MEH, Feng M, Arulanandam S. A Weakly-Supervised Named Entity Recognition Machine Learning Approach for Emergency Medical Services Clinical Audit. International Journal of Environmental Research and Public Health. 2021; 18(15):7776. https://doi.org/10.3390/ijerph18157776
Chicago/Turabian StyleWang, Han, Wesley Lok Kin Yeung, Qin Xiang Ng, Angeline Tung, Joey Ai Meng Tay, Davin Ryanputra, Marcus Eng Hock Ong, Mengling Feng, and Shalini Arulanandam. 2021. "A Weakly-Supervised Named Entity Recognition Machine Learning Approach for Emergency Medical Services Clinical Audit" International Journal of Environmental Research and Public Health 18, no. 15: 7776. https://doi.org/10.3390/ijerph18157776
APA StyleWang, H., Yeung, W. L. K., Ng, Q. X., Tung, A., Tay, J. A. M., Ryanputra, D., Ong, M. E. H., Feng, M., & Arulanandam, S. (2021). A Weakly-Supervised Named Entity Recognition Machine Learning Approach for Emergency Medical Services Clinical Audit. International Journal of Environmental Research and Public Health, 18(15), 7776. https://doi.org/10.3390/ijerph18157776