
Microblog Topic-Words Detection Model for Earthquake Emergency Responses Based on Information Classification Hierarchy

 ,
,  and
and
Abstract
:1. Introduction
2. Data Sources and Data Preprocessing
2.1. Data Sources
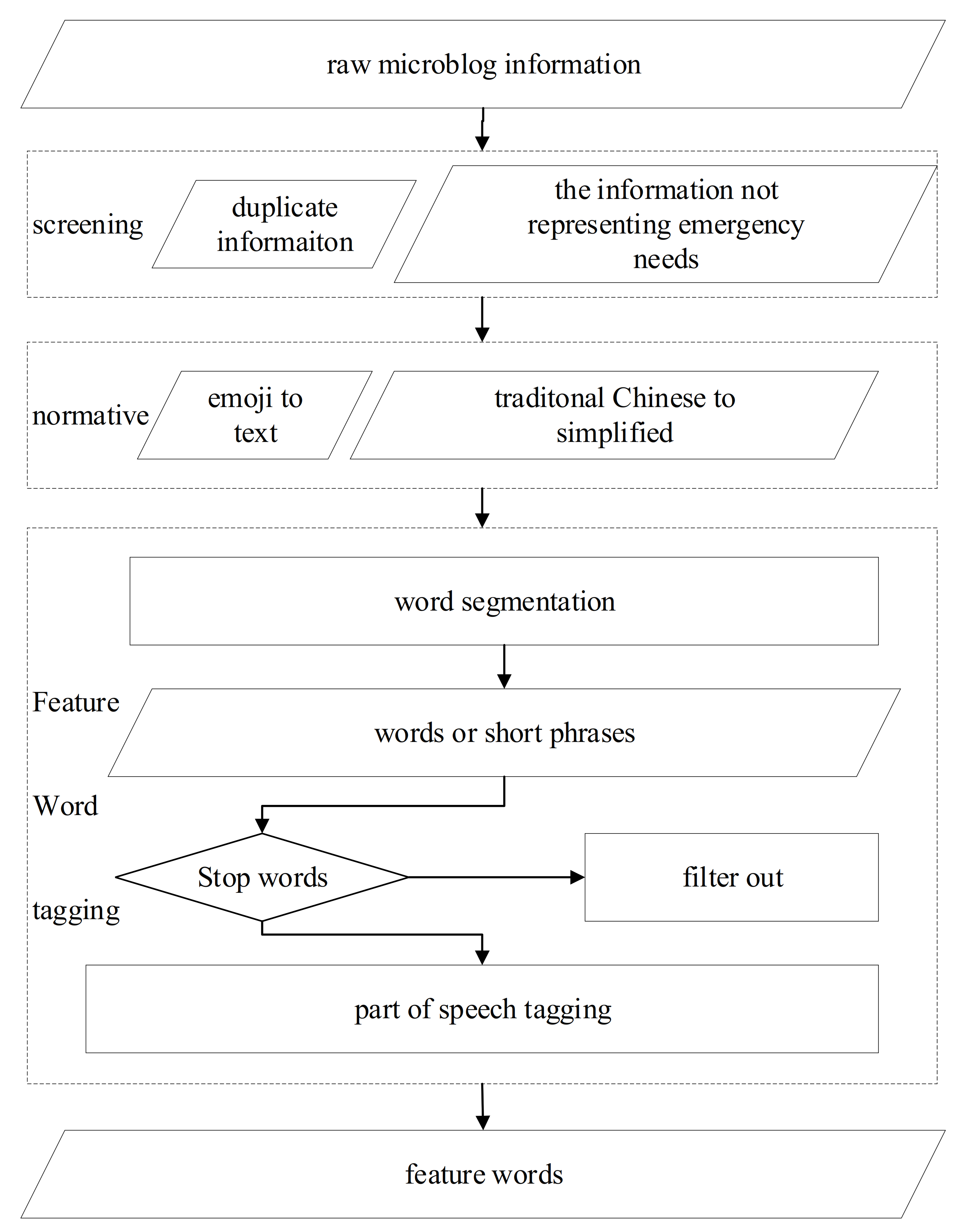
2.2. Data Preprocessing
3. Classification Hierarchy of Earthquake Emergency Information Construction
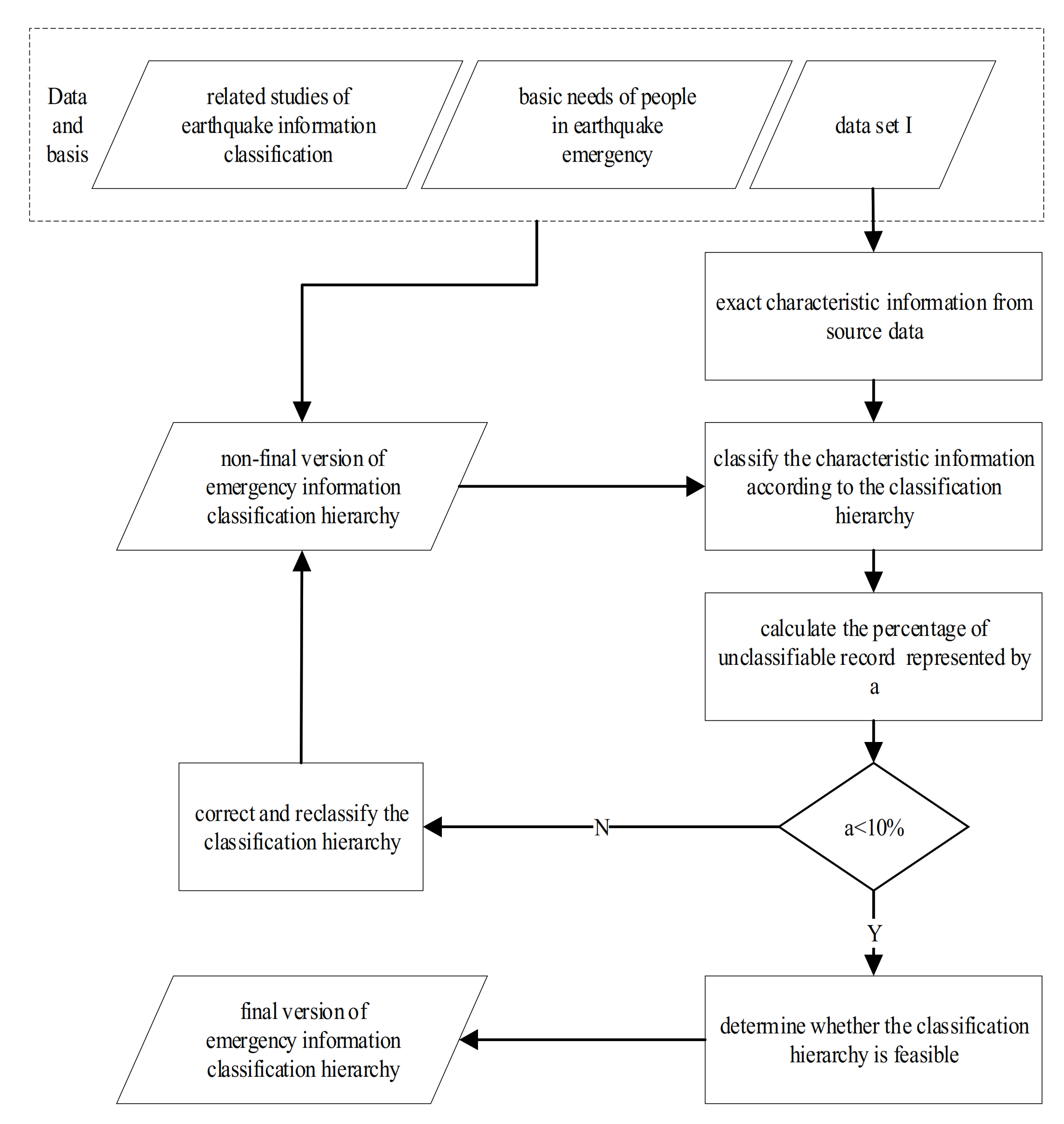
3.1. Process of Establishing the Classification Hierarchy
3.2. Earthquake Emergency Information Classification Hierarchy
4. Earthquake Emergency Information Hierarchy Topic-Words Detection Model
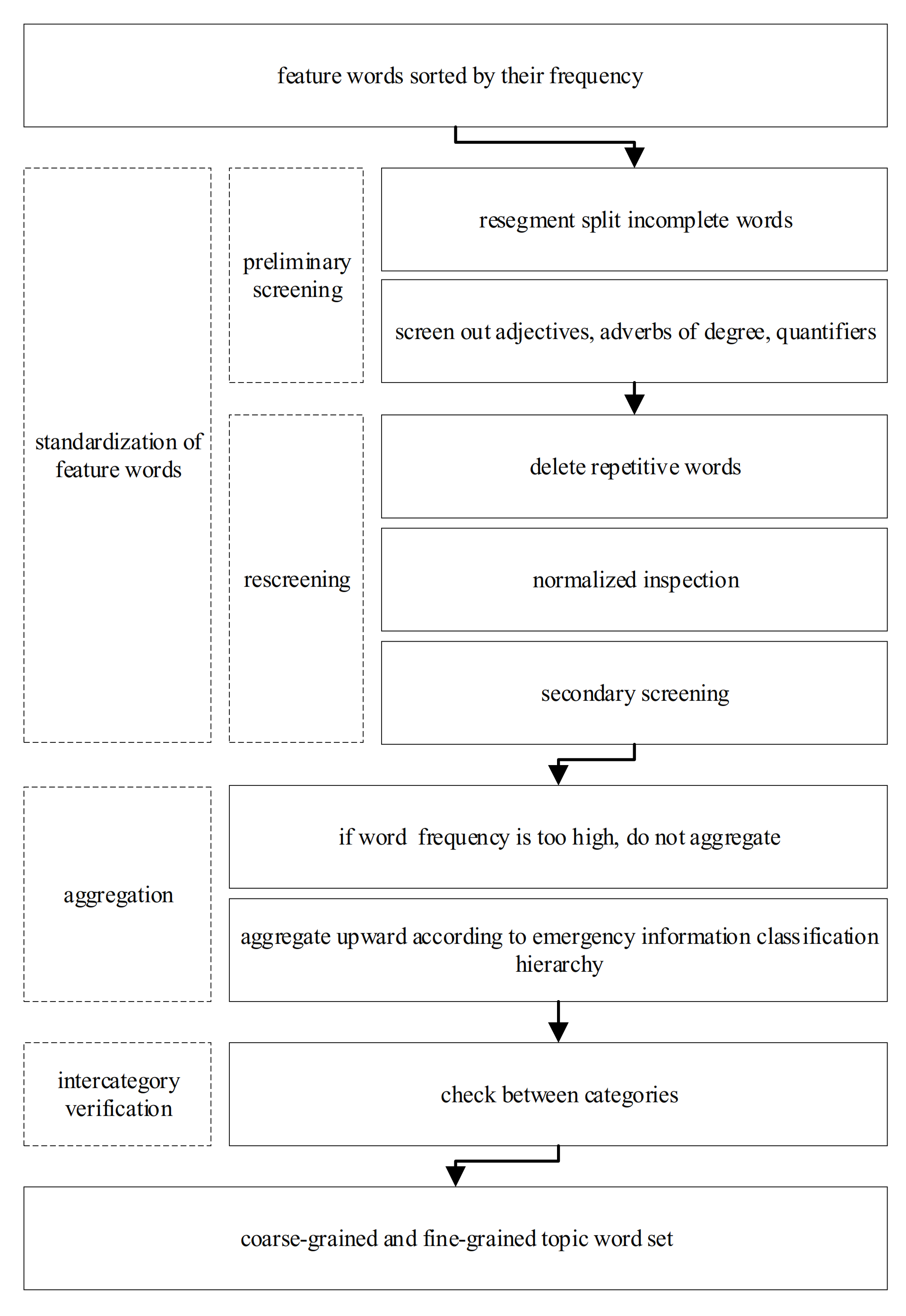
4.1. Topic-Words Detection Model Construction
4.1.1. Aggregating Feature Words in the Same Category
4.1.2. Checking between Categories
4.1.3. Constructing Coarse-Grained and Fine-Grained Feature Word Sets
4.1.4. Fuzzy Feature Word Set Processing
4.2. Model Validation
5. Case Analysis and Discussion
5.1. Coarse-Grained and Fine-Grained Word Sets
5.2. Analysis of the Information Classification Validity
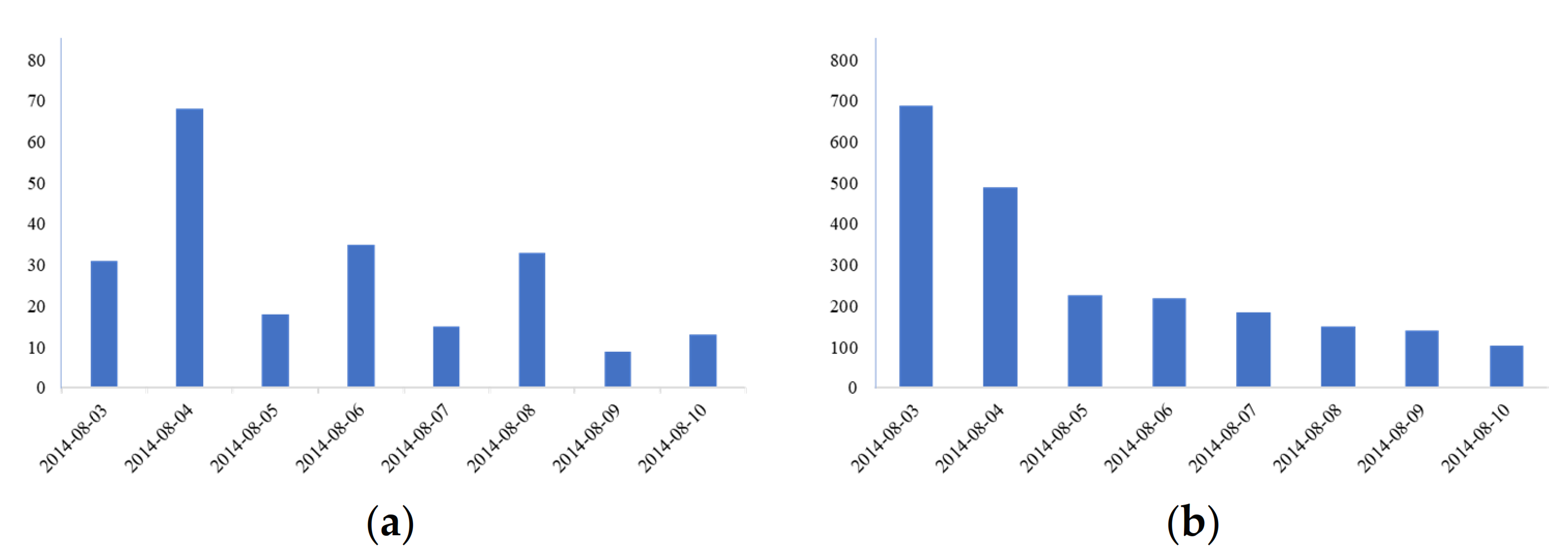
5.3. Analysis of the Information Collection Timeliness
5.4. Analysis on the Validity of Information Collection Based on Topic-words
5.5. Analysis of the Topic-Word Set Completeness
5.6. Hot Topic-Word Application
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Centre for Research on the Epidemiology of Disasters (CRED). EM-DAT, The International Disasterdatabase. Available online: https://www.emdat.be/ (accessed on 1 April 2020).
- Lu, X.; Cheng, Q.; Xu, Z.; Xu, Y.; Sun, C. Real-Time city-scale time-history analysis and its application in resilience-oriented earthquake emergency responses. Appl. Sci. 2019, 9, 3497. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Zhang, H.; Sugumaran, V.; Choo, K.-K.R.; Mei, L.; Zhu, Y. Participatory sensing-based semantic and spatial analysis of urban emergency events using mobile social media. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Xing, Z.; Su, X.; Liu, J.; Su, W.; Zhang, X. Spatiotemporal change analysis of earthquake emergency information based on Microblog Data: A case study of the “8.8” Jiuzhaigou earthquake. ISPRS Int. J. Geo-Inf. 2019, 8, 359. [Google Scholar] [CrossRef] [Green Version]
- Dong, M.; Yang, T. Discussion of earthquake emergency disaster information classification. Technol. Earthq. Disaster Prev. 2014, 4, 937–943. [Google Scholar]
- Xia, C.; Nie, G.; Fan, X.; Zhou, X.; Pang, X. Research on the application of mobile phone location signal data in earthquake emergency work: A case study of Jiuzhaigou earthquake. PLoS ONE 2019, 14, e0215361. [Google Scholar]
- Jung, J.; Moro, M. Multi-level functionality of social media in the aftermath of the great east Japan earthquake. Disasters 2014, 38, 123–143. [Google Scholar] [CrossRef]
- Yates, D.; Paquette, S. Emergency knowledge management and Social Media technologies: A case study of the 2010 Haitian earthquake. Int. J. Inf. Manag. 2011, 31, 6–13. [Google Scholar] [CrossRef]
- Camponovo, M.E.; Freundschuh, S.M. Assessing uncertainty in VGI for emergency response. Cartogr. Geogr. Inf. Sci. 2014, 41, 440–455. [Google Scholar] [CrossRef]
- Liu, S. Crisis crowdsourcing framework: Designing strategic configurations of crowdsourcing for the emergency management domain. Comput. Supported Coop. Work. (CSCW) 2014, 23, 389–443. [Google Scholar] [CrossRef]
- Sui, S.; Elwood, S.; Goodchild, M. Crowdsourcing Geographic Knowledge; Springer: Berlin/Heidelberg, Germany, 2013; pp. 15–120. [Google Scholar]
- Ren, F.; Zhang, Q. An emotion expression extraction method for Chinese microblog sentences. IEEE Access 2020, 8, 69244–69255. [Google Scholar] [CrossRef]
- Dong, R.; Li, L.; Zhang, Q.; Cai, G. Information diffusion on social media during natural disasters. IEEE Trans. Comput. Soc. Systems. 2018, 5, 265–276. [Google Scholar] [CrossRef]
- Su, X.; Zhang, X.; Hu, C.; Zou, Z.; Qiu, X. Research on the extraction of earthquake’s hot topic-words from microblog based on improved TF-PDF algorithm. Geogr. Geo-Inf. Sci. 2018, 34, 90–95. [Google Scholar]
- Zhao, Q.; Chen, Z.; Liu, C.; Luo, N. Extracting and classifying typhoon disaster information based on Volunteered Geographic Information from Chinese Sina Microblog. Concurr. Comput. Pract. Exp. 2018, 31, e4910. [Google Scholar] [CrossRef]
- Yu, J.; Zhao, Q.; Chin, C. Extracting typhoon disaster information from VGI based on machine learning. J. Mar. Sci. Eng. 2019, 7, 318. [Google Scholar] [CrossRef] [Green Version]
- Haworth, B. Implications of Volunteered Geographic Information for disaster management and GIScience: A more complex world of Volunteered Geography. Ann. Am. Assoc. Geogr. 2017, 108, 226–240. [Google Scholar] [CrossRef]
- Zhang, F.; He, H.; Lv, J.; Deng, S.; Bai, F.; Dong, X. Classification and coding of the earthquake-disaster information based on the internet and their preliminary application. J. Seismol. Res. 2016, 39, 664–672. [Google Scholar]
- Ao, J.; Zhang, P.; Cao, Y. Estimating the locations of emergency events from Twitter streams. Procedia Comput. Sci. 2014, 31, 731–739. [Google Scholar] [CrossRef] [Green Version]
- Fang, S.; Li, L.; Zhang, X. The research of topic crawler for Macro-anomalies of earthquake. Technol. Earthq. Disaster Prev. 2013, 8, 475–480. [Google Scholar]
- Li, Q.; Wei, J.; Hai, Y. Microblog hot topics detection based on VSM and HMBTM model fusion. IEEE Access 2019, 7, 120273–120281. [Google Scholar]
- Yu, J.; Qiu, L. ULW-DMM: An effective topic modeling method for Microblog short text. IEEE Access 2019, 7, 884–893. [Google Scholar] [CrossRef]
- Han, X.; Wang, J. Earthquake information extraction and comparison from different sources based on web text. ISPRS Int. J. Geo-Inf. 2019, 8, 252. [Google Scholar] [CrossRef] [Green Version]
- Su, G.; Nie, G.; Gao, J. The characteritics, classifications and the functions of the information for earthquake emergency response. Earthquake 2003, 23, 27–35. [Google Scholar]
- Wang, Y.; Zhu, Y.; Su, Q. Ethnic groups differences in domestic recovery after the catastrophe: A case study of the 2008 magnitude 7.9 earthquake in China. Int. J. Environ. Res. Public Health 2017, 14, 590. [Google Scholar] [CrossRef]
- Bai, X.; Li, Y.; Chen, J.; Dai, Y.; Cao, K.; Cao, Y.; Zhao, H.; Gong, Q. Research on earthquake spot emergency response information classification. J. Seismol. Res. 2010, 33, 111–118. [Google Scholar]
- Jiao, C. Research on Earthquake Disaster Acquisition and Information Classification. Master’s Thesis, Chengdu University of Technology, Chengdu, Sichuan, 2011. [Google Scholar]
- Bai, X.; Liu, X.; Lu, S.; Zhang, X.; Su, W.; Su, X.; Li, L. SEPM: Rapid seism emergency information processing based on social media. Nat. Hazards 2020, 104, 659–679. [Google Scholar] [CrossRef]
- Cheng, Y.; Liao, W.; Cheng, G. Strategy of focused crawler with word embedding clustering weighted in Shark-Search algorithm. Comput. Digit. Eng. 2018, 46, 144–148. [Google Scholar]
- Chang, P.; Ma, H. Efficient short texts keyword extraction method analysis. Comput. Eng. Appl. 2011, 47, 126–128. [Google Scholar]
- Gao, Q.; Abel, F.; Houben, G.F.; Yu, Y. A comparative study of users’ microblogging behavior on Sina Weibo and Twitter. In Proceedings of the 20th International Conference on User Modeling, Adaptation, and Personalization, Montreal, QC, Canada, 16–20 July 2012; pp. 88–101. [Google Scholar]
- Li, Z.; Peng, S.; Wang, T. A sequential sampling method of surrogate model based on k-fold cross validation. Chin. J. Comput. Mech. 2021, 38, 1–8. [Google Scholar]
- Zhu, D.; Xu, J. SMS-based spatio-temporal information collection and management of earthquake disaster. Sci. Surv. Mapp. 2011, 36, 172–174. [Google Scholar]
- Lin, H. Research of Weibo Text Clustering Algorithm Based on K.-Means. Master’s Thesis, Hainan University, Haikou, China, 2016. [Google Scholar]
- Onan, A.; Korukoğlu, S.; Bulut, H. Ensemble of keyword extraction methods and classifiers in text classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Gao, W.; Li, L.; Zhu, X.; Wang, Y. Detecting disaster-related tweets via multi-modal adversarial neural network. IEEE Multimed. 2020, 4, 28–37. [Google Scholar] [CrossRef]
- Huggins, T.J.; Prasanna, R. Information technologies supporting emergency management controllers in New Zealand. Sustainability 2020, 12, 3716. [Google Scholar] [CrossRef]
- Avvenuti, M.; Cresci, S.; Vigna, F.D.; Tesconi, M. Impromptu crisis mapping to prioritize emergency response. Computer 2016, 49, 28–37. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Tang, B.; Yang, H.; Liu, Y.; Chen, X.; Zhang, L. The technical efficiency of earthquake medical rapid response teams following disasters: The case of the 2010 Yushu earthquake in China. Int. J. Environ. Res. Public Health 2015, 12, 4991. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Nie, G.; Liu, W.; Han, Y. Multiple and heterogeneous earthquake disaster information classification and code. J. Catastrophology 2010, 25, 286–290. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
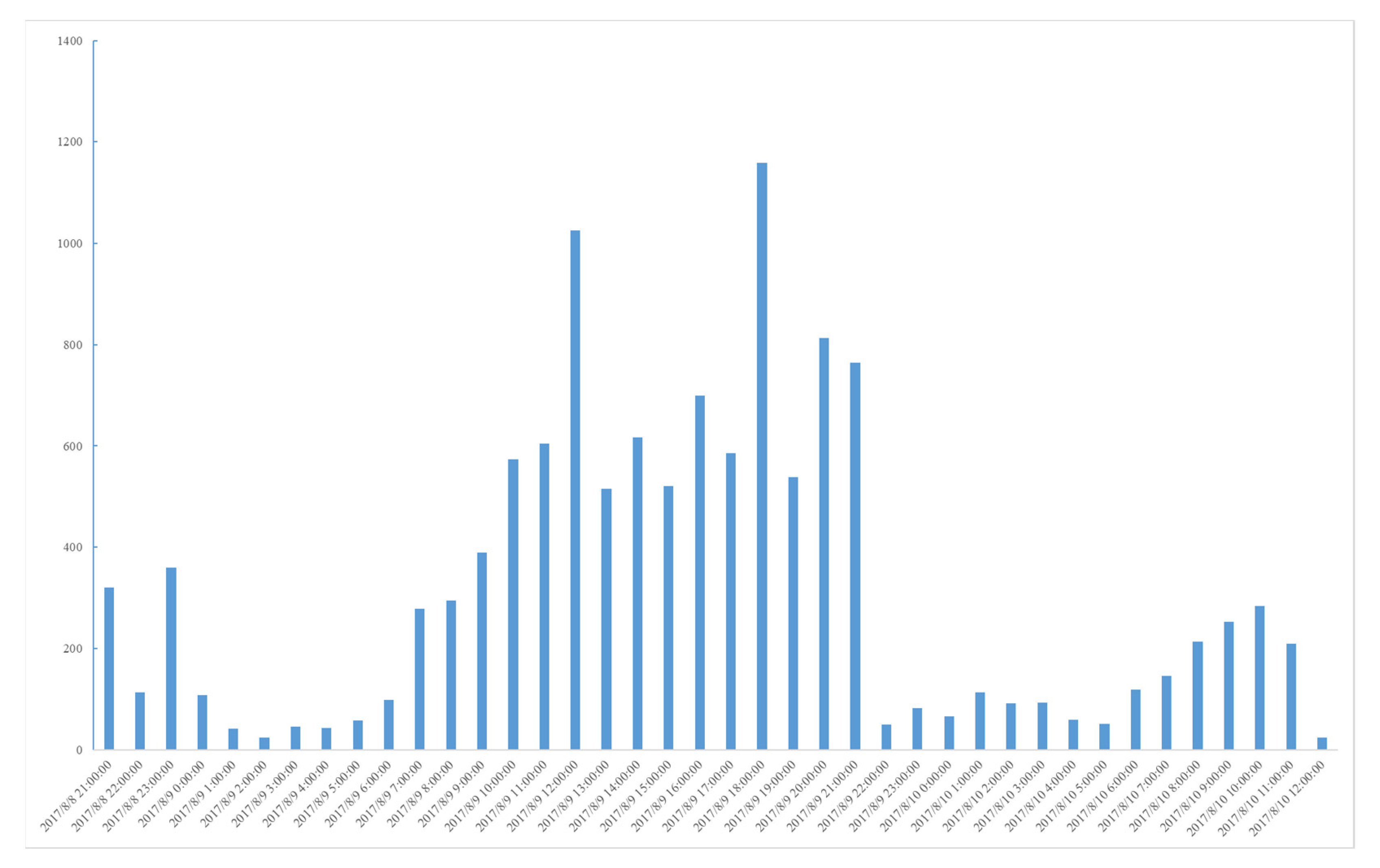{kind=link}
{kind=link}
| Earthquake Cases | Epicenter Location | Date of Occurrence | Magnitude | Focal Depth (KM) | Start Time a | End Time a | Messages b |
|---|---|---|---|---|---|---|---|
| 01YG | Yunnan-Guizhou border | 2012-09-07 | 5.7 | 14 | 2012-09-07 11:19 | 2012-09-14 11:19 | 1515 |
| 02SC | Lushan, Sichuan | 2013-04-20 | 7.0 | 13 | 2013-04-20 08:02 | 2013-05-20 08:02 | 83,456 |
| 03XJ | Hetian, Xinjiang | 2014-02-12 | 7.3 | 12 | 2014-02-12 17:19 | 2014-02-19 17:19 | 176 |
| 04YN | Ludian, Yunnan | 2014-08-03 | 6.5 | 12 | 2014-08-03 16:30 | 2014-08-10 16:30 | 2201 |
| 05SC | Jiuzhaigou, Sichuan | 2017-08-08 | 7.0 | 20 | 2017-08-08 21:19 | 2017-08-11 21:19 | 16,166 |
| Objects | Operation | Reason |
|---|---|---|
| the messages contain ‘[]’ | filter out | the symbol ‘[]’ is used to identify a news headline in microblog |
| the messages contain ‘#’ | filter out | microblog’s title is usually placed between two ‘#’s to start a topic and attract users |
| characters such as line breaks and spaces | replace | no practical meaning and interfere with word segmentation |
| information such as ’Pupil Earthquake’ | delete | similar but unrelated message |
| short text (less than 50 characters) | delete | no practical meaning for emergency work because of its length |
| duplicate information | filter out | different accounts reproduce exactly the same repeated information |
| First-Level (A) | Second-Level (B) | Third-Level (C) | Meanings of the Third-Level |
|---|---|---|---|
| location information | longitude, latitude, and region | ||
| time information | publishing time | message publication time | |
| event time | time described in the message | ||
| disaster investigation | disaster situation | earthquake situation | description information such as magnitude and epicenter |
| sense of earthquake | feelings during an earthquake | ||
| casualties | casualty information | ||
| destruction | damage caused by the earthquake | ||
| abnormal phenomenon | abnormal phenomenon information accompanied by the earthquake | ||
| social public opinion | news propaganda | news notification class | news and notice information during earthquake |
| news propaganda class | education and public information of earthquake emergency knowledge | ||
| social mood | positive | information that contains positive opinion | |
| medium | pertinent emotional information published by people during earthquake emergency | ||
| negative | negative remarks during the earthquake | ||
| supervisory information | information on supervision, reporting and suggestions of relevant measures | ||
| emergency rescue | emergency | information about people in danger, including requests for and implementation of assistance | |
| disaster relief | relevant information on the treatment of secondary disasters and accompanying disasters | ||
| emergency rescue situation | information about disaster relief progress and decision-making | ||
| emergency support | other material | material information that is difficult to classify | |
| warm | clothes | information about clothes | |
| cotton quilt | information of materials used against cold | ||
| living | accommodations | information about materials related to accommodation, such as dispatching and accommodation locations | |
| shelters | information about public shelters, resettlement sites, etc. | ||
| traffic | traffic information | road conditions, traffic control situations, dispatchable vehicle information, etc. | |
| food | ready to eat | information about food that is difficult to transport | |
| storable food | information about the food that is able to being stored and carried | ||
| medical | medical staff | information about professional doctors and nurses | |
| medical equipment | information about medical and aid devices | ||
| medicine | the status of medicines used for rescue | ||
| blood bank | information related to rescue blood bank, blood donations, etc. | ||
| injury situation | injury location, injury cause, etc. | ||
| epidemic prevention | information related to disease protection | ||
| community | electricity | information about electricity | |
| communication | information about the community | ||
| safety and security | information about public security issues and security work | ||
| rescue team | professional team | firefighters, etc. | |
| trained | information about NGOs, voluntary groups | ||
| non-professional | unorganized and spontaneous rescue team information | ||
| seek | searching | information for finding people and objects | |
| services | provides information about finding services | ||
| psychological | information about psychological counselling and abnormal psychology | ||
| non-emergency | support | non-emergency donation or supply information | |
| other | other non-emergency information | ||
| comprehensive classes | fuzzy classification but of great significance to the information acquisition |
| Steps of the Method |
|---|
| 1: μ is the marked feature word in fuzzy classification; E is one of the categories under the earthquake emergency classification hierarchy; Qμ is the word frequency of μ, and δ is the threshold for the coarse-grained and fine-grained sets; |
| 2: if , then classify μ into category E; |
| 3: trace the word frequency of the words retained in the fuzzy classification, if , then classify μ to the comprehensive category of fine-gained feature word sets; otherwise classify μ to the comprehensive category of the coarse-gained feature word set; |
| 4: finally, coarse-grained and fine-grained feature word sets are formed. |
| Coding for Category | Category Name | Topic-Words |
|---|---|---|
| A3B01C01 | earthquake situation | magnitude, earthquake, strong earthquake, record, aftershock, disaster situation, disaster area, photo, earthquake situation, epicentre, disaster- stricken area |
| A3B01C02 | sense of earthquake | tremble, degree, duration, sustained, fall, move, feel, wake up, shake, violent, shake, sharp, obvious, dazzle, crash, break, strong, intense, sound wave, sound, dizziness, fright, rattle, heartbeat, shock, silly, suffocation |
| A3B01C03 | casualties | reports, deaths, destruction, population, numbers, killed, casualties, wounded, injured, lives, missing, died, damaged, dead, sacrifice, crush, earthquake death |
| A3B01C04 | destruction | pulling down, scrapping, collapse, tragic situation, secondary disaster, subsidence, falling, breaking, ruins, landslide, destruction, in danger, boulder, collapse, lycopodium, crack, leakage of rain, falling objects, debris flow, broken, wall, gap, mountain, stone, damaged, rubble, tiles, dangerous houses, dangerous buildings, barrier lakes, smashing, serious disaster, earthquake damage, shatter, shock-off, destroy severely |
| A3B02C00 | abnormal phenomena | wind, dog, flood, cooling, barking, thunder, visibility, temperature, precursor, frogs, lightning, moisture, cave-in, the sky, weather, temperature difference, fog, abnormal signs, fish, rain, cloud |
| ID | Category Name | Topic-Words |
|---|---|---|
| A3 | disaster investigation | magnitude, pulling down, scrapping, reports, collapse, tragic situation, tremble, degree, duration, sustained, fall, subsidence, move, tremble, breaking, ruins, wind, feel, dog, flood, landslide, wake up, shake, destruction, cooling, boulder, violent, barking, lycopodium, thunder, deaths, sharp, crack, obvious, dazzle, visibility, debris flow, crash, broken, temperature, precursor, strong, wall, frogs, gap, population, numbers, killed, mountain, lightning, lives, sound wave, sound, missing, moisture, stone, record, died, damaged, dead, the sky, weather, dizziness, rubble, tiles, dangerous, temperature difference, fog, sacrifice, subsidence, rattle, barrier lakes, abnormal signs, fish, cloud, smashing, photo, suffocation, destroy severely |
| Categories | Records | Percentage |
|---|---|---|
| A1 location information | 1870 | 85% |
| A2 time information | 1267 | 58% |
| A3 disaster investigation—B1 disaster situation | 2201 | 100% |
| A3 disaster investigation—B2 abnormal phenomenon | 1347 | 61% |
| A4 social public opinion—B1 news propaganda | 604 | 27% |
| A4 social public opinion—B2 social mood | 791 | 36% |
| A4 social public opinion—B3 supervisory information | 2 | 0% |
| A5 emergency rescue—B1 emergency | 573 | 26% |
| A5 emergency rescue—B2 disaster relief | 19 | 1% |
| A5 emergency rescue—B3 emergency rescue situation | 866 | 39% |
| A6 emergency support—B1 other material | 193 | 9% |
| A6—B2 warm | 47 | 2% |
| A6—B3 living | 756 | 34% |
| A6—B4 traffic | 1924 | 87% |
| A6—B5 food | 484 | 22% |
| A6—B6 medical | 293 | 13% |
| A6—B7 community | 444 | 20% |
| A6—B8 safety and security | 4 | 0% |
| A6—B9 rescue team | 540 | 25% |
| A6—B10 seek | 21 | 1% |
| A6—B11 psychological | 88 | 4% |
| A7 non-emergency—B1 support | 127 | 6% |
| A7 non-emergency—B2 other | 10 | 0% |
| A8 comprehensive classes | 294 | 13% |
| Method | Keywords | Time (s) | r a | q b |
|---|---|---|---|---|
| b | earthquake | 2470 | 2201 | 281 |
| a | trapped, deploy, evacuate, standby, in place, resume classes, recover, urgent, investigate, clear, rescue, repair, victory, accident, search, advance, orderly, find, support, execute, helicopter, command post | 1913 | 230 | 223 |
| Topic-Word | All the Records | Effective Records | Validity |
|---|---|---|---|
| trapped | 18 | 18 | 100% |
| deploy | 7 | 6 | 86% |
| evacuate | 28 | 27 | 96% |
| standby | 18 | 18 | 100% |
| in place | 11 | 3 | 27% |
| resume classes | 5 | 0 | 0% |
| recover | 25 | 10 | 40% |
| urgent | 91 | 90 | 99% |
| investigate | 4 | 4 | 100% |
| clear (in Chinese “排危”) | 1 | 1 | 100% |
| clear (in Chinese “抢通”) | 27 | 27 | 100% |
| rescue | 46 | 46 | 100% |
| command post | 50 | 50 | 100% |
| repair | 21 | 21 | 100% |
| victory | 15 | 4 | 27% |
| accident | 10 | 2 | 20% |
| trapped | 6 | 5 | 83% |
| evacuate | 3 | 2 | 67% |
| search | 5 | 4 | 80% |
| advance | 6 | 5 | 83% |
| orderly | 29 | 28 | 97% |
| find | 110 | 25 | 23% |
| support | 87 | 87 | 100% |
| execute | 4 | 4 | 100% |
| helicopter | 27 | 24 | 89% |
| total | 654 | 511 | 78% |
| Rank | Word | Part of Speech | Frequency |
|---|---|---|---|
| 1 | Ludian | NS | 1298 |
| 2 | tap | N | 114 |
| 3 | degree | Q | 106 |
| 4 | the Communist Youth League | NT | 95 |
| 5 | the dead | N | 78 |
| 6 | determination | V | 74 |
| 7 | formal | AD | 73 |
| 8 | depth | NS | 70 |
| 9 | huode | N | 59 |
| 10 | name | N | 58 |
| 11 | rest | V | 58 |
| 12 | pray | V | 57 |
| 13 | publish | V | 52 |
| 14 | fund | N | 50 |
| 15 | donation | V | 49 |
| 16 | sibling | N | 46 |
| 17 | zhaoyang | N | 45 |
| 18 | hand | N | 45 |
| 19 | help | V | 44 |
| 20 | century | N | 43 |
| Treatment | New Topic-Words and Their Determination |
|---|---|
| added to the fine-grained word sets | determination (classify to disaster investigation-earthquake situation), depth (classify to disaster investigation-earthquake situation), rest (classify to social public opinion-social mood-positive), pray (classify to social public opinion-social mood-positive), fund (classify to non-emergency-support) present |
| added to a specific set | Ludian |
| added to the secondary stop word set | degree, formal, name, publish, sibling, hand, help, century |
| to be processed | tap, the Communist Youth League, the dead, huode, zhaoyang |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, X.; Ma, S.; Qiu, X.; Shi, J.; Zhang, X.; Chen, F. Microblog Topic-Words Detection Model for Earthquake Emergency Responses Based on Information Classification Hierarchy. Int. J. Environ. Res. Public Health 2021, 18, 8000. https://doi.org/10.3390/ijerph18158000
Su X, Ma S, Qiu X, Shi J, Zhang X, Chen F. Microblog Topic-Words Detection Model for Earthquake Emergency Responses Based on Information Classification Hierarchy. International Journal of Environmental Research and Public Health. 2021; 18(15):8000. https://doi.org/10.3390/ijerph18158000
Chicago/Turabian StyleSu, Xiaohui, Shurui Ma, Xiaokang Qiu, Jiabin Shi, Xiaodong Zhang, and Feixiang Chen. 2021. "Microblog Topic-Words Detection Model for Earthquake Emergency Responses Based on Information Classification Hierarchy" International Journal of Environmental Research and Public Health 18, no. 15: 8000. https://doi.org/10.3390/ijerph18158000
APA StyleSu, X., Ma, S., Qiu, X., Shi, J., Zhang, X., & Chen, F. (2021). Microblog Topic-Words Detection Model for Earthquake Emergency Responses Based on Information Classification Hierarchy. International Journal of Environmental Research and Public Health, 18(15), 8000. https://doi.org/10.3390/ijerph18158000