
Bayesian Sequential Monitoring of Single-Arm Trials: A Comparison of Futility Rules Based on Binary Data

Abstract
:1. Introduction
2. Bayesian Problem Settings
3. Futility Rules Based on Posterior Probabilities
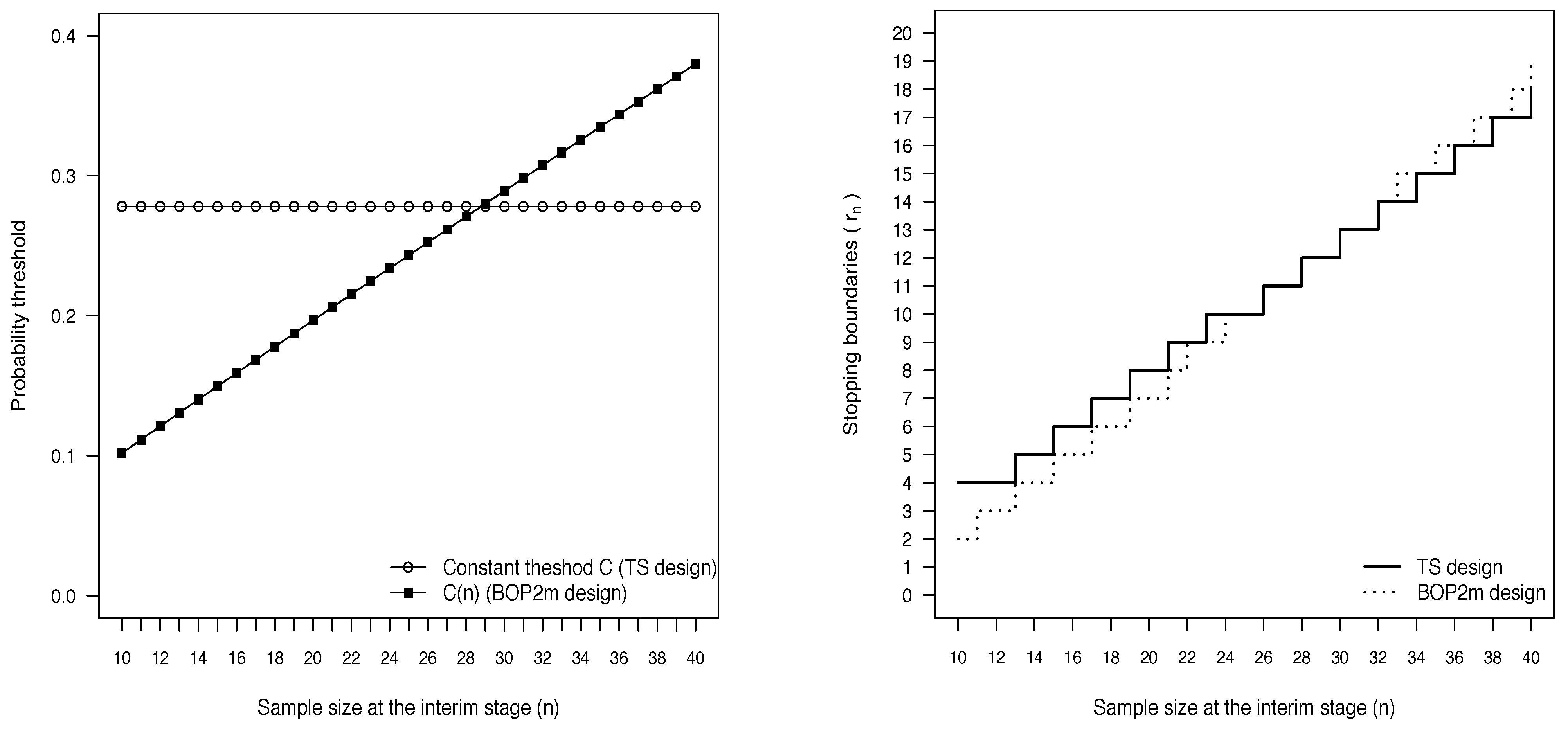
3.1. The Design of Thall and Simon
3.2. The BOP2 Design
- the experimental treatment is considered sufficiently promising if exceeds a constant target ;
- the posterior probability of interest is compared with a threshold that varies with the interim sample size.
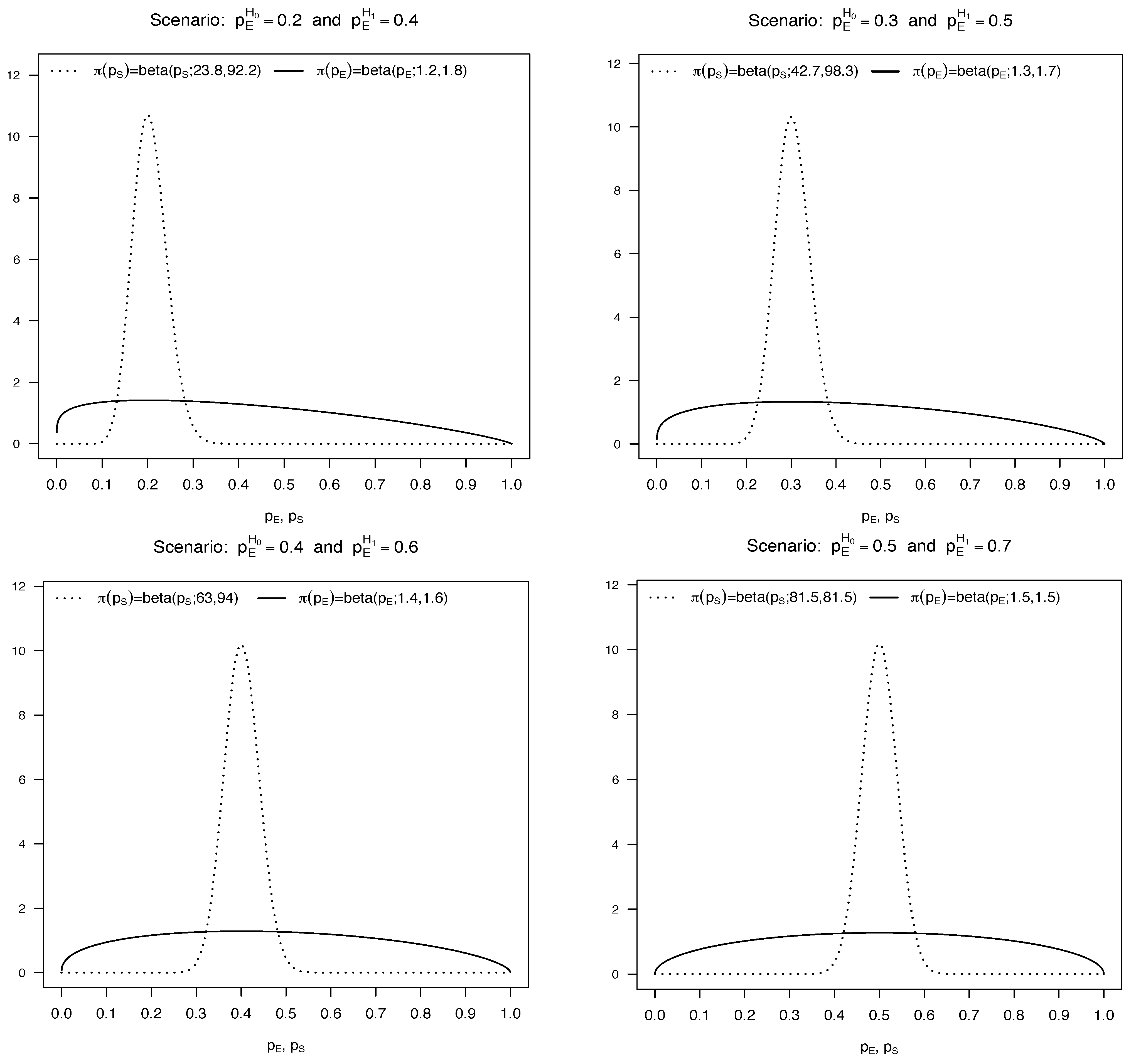
3.2.1. Accounting for Uncertainty on in the BOP2 Design
4. Futility Rules Based on Predictive Probabilities
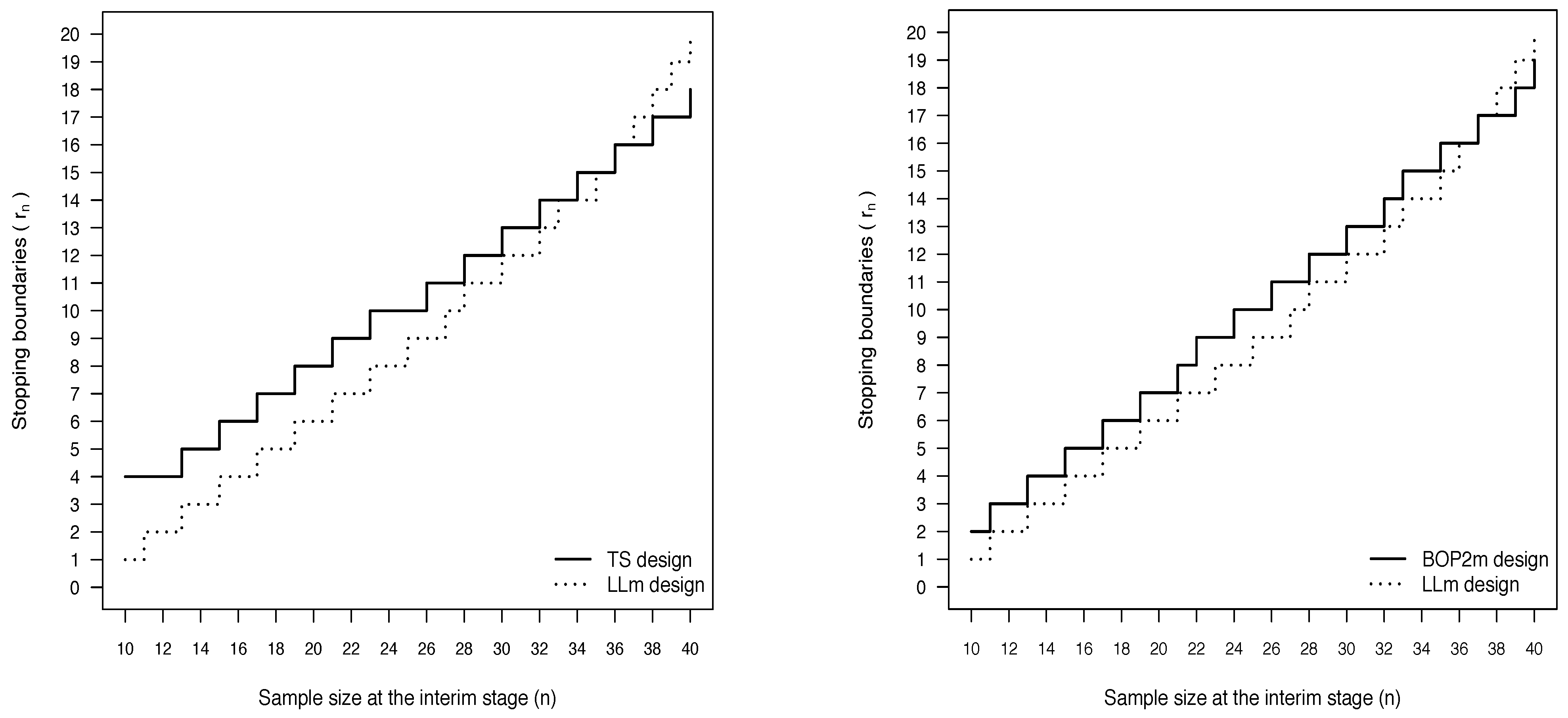
4.1. The Design of Lee and Liu
4.1.1. Accounting for Uncertainty on in the Design of Lee and Liu
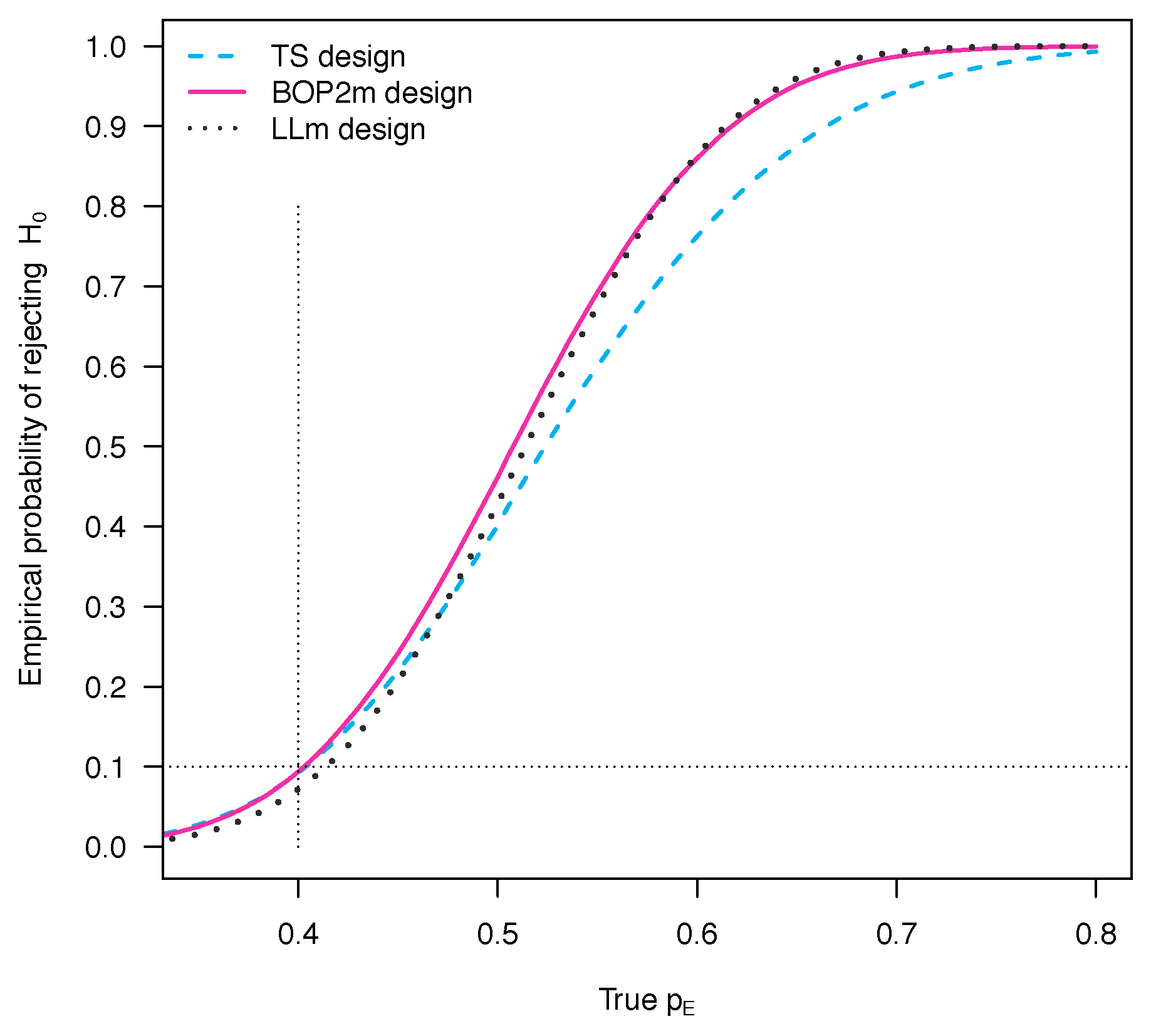
5. Comparison of the Operating Characteristics
6. Discussion
| TS | • Simpler and easier to implement |
| • Lower values of the ASS under | |
| BOP2m | • Takes into account the ratio between n and N |
| • Higher power and lower PET under if compared with TS | |
| LLm | • Takes into account the number of remaining patients |
| • Resembles more closely the clinical decision-making process | |
| • Higher power and lower PET under if compared with TS |
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TS | Design due to Thall and Simon [2] |
| BOP2m | Modified version of the BOP2 design due to Zhou et al. [7] to account for uncertainty in |
| LLm | Modified version of the design of Lee and Liu [11] to account for uncertainty in |
| Proportion of simulated trials where the null hypothesis is rejected | |
| PET | Probability of early termination |
| ASS | Average of the actually achieved sample size |
References
- Zohar, S.; Teramukai, S.; Zhou, Y. Bayesian design and conduct of phase II single-arm clinical trials with binary outcomes: A tutorial. Contemp. Clin. Trials 2008, 29, 608–616. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thall, P.F.; Simon, R. Practical guidelines for phase IIB clinical trials. Biometrics 1994, 50, 337–349. [Google Scholar] [CrossRef] [PubMed]
- Matano, F.; Sambucini, V. Accounting for uncertainty in the historical response rate of the standard treatment in single-arm two-stage designs based on Bayesian power functions. Pharm. Stat. 2016, 15, 517–530. [Google Scholar] [CrossRef]
- Thall, P.F.; Simon, R.; Estey, E.H. Bayesian sequential monitoring designs for single-arm clinical trials with multiple outcomes. Stat. Med. 1995, 14, 357–379. [Google Scholar] [CrossRef] [PubMed]
- Thall, P.F.; Simon, R.; Estey, E.H. New statistical strategy for monitoring safety and efficacy in single-arm clinical trials. J. Clin. Oncol. 1996, 14, 296–303. [Google Scholar] [CrossRef] [PubMed]
- Thall, P.F.; Sung, H.G. Some extensions and applications of a Bayesian strategy for monitoring multiple outcomes in clinical trials. Stat. Med. 1998, 17, 1563–1580. [Google Scholar] [CrossRef]
- Zhou, H.; Lee, J.J.; Yuan, Y. BOP2: Bayesian optimal design for phase II clinical trials with simple and complex endpoints. Stat. Med. 2017, 36, 3302–3314. [Google Scholar] [CrossRef]
- Jiang, L.; Yan, F.; Thall, P.F.; Huang, X. Comparing Bayesian early stopping boundaries for phase II clinical trials. Pharm. Stat. 2020, 19, 928–939. [Google Scholar] [CrossRef]
- Berry, S.M.; Carlin, B.P.; Lee, J.J.; Muller, P. Bayesian Adaptive Methods for Clinical Trials; Chapman and Hall/CRC: Boca Raton, FL, USA, 2011. [Google Scholar]
- Dmitrienko, A.; Wang, M.D. Bayesian predictive approach to interim monitoring in clinical trials. Stat. Med. 2006, 25, 2178–2195. [Google Scholar] [CrossRef]
- Lee, J.J.; Liu, D.D. A predictive probability design for phase II cancer clinical trials. Clin. Trials 2008, 5, 93–106. [Google Scholar] [CrossRef] [Green Version]
- Saville, B.R.; Connor, J.T.; Ayers, G.D.; Alvarez, J. The utility of Bayesian predictive probabilities for interim monitoring of clinical trials. Clin. Trials 2014, 11, 485–493. [Google Scholar] [CrossRef] [Green Version]
- Lin, R.; Lee, J.J. Novel bayesian adaptive designs and their applications in cancer clinical trials. In Computational and Methodological Statistics and Biostatistics; Bekker, A., Chen, D.G., Ferreira, J.T., Eds.; Springer: Cham, Switzerland, 2020; pp. 395–426. [Google Scholar]
- Yin, G.; Chen, N.; Lee, J.J. Phase II trial design with Bayesian adaptive randomization and predictive probability. J. R. Stat. Soc. Ser. C 2012, 61, 219–235. [Google Scholar] [CrossRef]
- Hobbs, B.P.; Chen, N.; Lee, J.J. Controlled multi-arm platform design using predictive probability. Stat. Methods Med. Res. 2018, 27, 65–78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sambucini, V. Bayesian predictive monitoring with bivariate binary outcomes in phase II clinical trials. Comput. Stat. Data Anal. 2019, 132, 18–30. [Google Scholar] [CrossRef]
- Yin, G.; Chen, N.; Lee, J.J. Bayesian Adaptive Randomization and Trial Monitoring with Predictive Probability for Time-to-event Endpoint. Stat. Biosci. 2018, 10, 420–438. [Google Scholar]
- Zhou, M.; Tang, Q.; Lang, L.; Xing, J.; Tatsuoka, K. Predictive probability methods for interim monitoring in clinical trials with longitudinal outcomes. Stat. Med. 2018, 37, 2187–2207. [Google Scholar] [CrossRef] [PubMed]
- Sambucini, V. A Bayesian predictive two-stage design for phase II clinical trials. Stat. Med. 2008, 27, 1199–1224. [Google Scholar] [CrossRef]
- Ibrahim, J.G.; Chen, M.H. Power prior distributions for regression models. Stat. Sci. 2000, 15, 46–60. [Google Scholar]
- De Santis, F. Using historical data for Bayesian sample size determination. J. R. Stat. Soc. Ser. A 2007, 170, 95–113. [Google Scholar] [CrossRef]
- Chen, C.; Chaloner, K. A Bayesian stopping rule for a single arm study: With a case study of stem cell transplantation. Stat. Med. 2006, 25, 2956–2966. [Google Scholar] [CrossRef]
- Mayo, M.S.; Gajewski, B.J. Bayesian sample size calculations in phase II clinical trials using informative conjugate priors. Control Clin Trials 2004, 25, 157–167. [Google Scholar] [CrossRef]
- Gajewski, B.J.; Mayo, M.S. Bayesian sample size calculations in phase II clinical trials using a mixture of informative priors. Stat. Med. 2006, 25, 2554–2566. [Google Scholar] [CrossRef] [PubMed]
- Heitjan, D.F. Bayesian interim analysis of phase II cancer clinical trials. Stat. Med. 1997, 16, 1791–1802. [Google Scholar] [CrossRef]
- Tan, S.B.; Machin, D. Bayesian two-stage designs for phase II clinical trials. Stat. Med. 2002, 21, 1991–2012. [Google Scholar] [CrossRef]
- Ventz, S.; Trippa, L. Bayesian designs and the control of frequentist characteristics: A practical solution. Biometrics 2015, 71, 218–226. [Google Scholar] [CrossRef] [PubMed]
- Sambucini, V. Bayesian vs. Frequentist Power Functions to Determine the Optimal Sample Size: Testing One Sample Binomial Proportion Using Exact Methods. In Bayesian Inference; Tejedor, J.P., Ed.; IntechOpen: Rijeka, Croatia, 2017; pp. 77–95. [Google Scholar]
- Yin, G. Clinical Trial Design: Bayesian and Frequentist Adaptive Methods; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Simon, R. Optimal two-stage designs for phase II clinical trials. Control. Clin. Trials 1989, 10, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Dong, G.; Shih, W.J.; Moore, D.; Quan, H.; Marcella, S. A Bayesian-frequentist two-stage single-arm phase II clinical trial design. Stat. Med. 2012, 31, 2055–2067. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | 10 | 13 | 15 | 17 | 19 | 21 | 23 | 26 | 28 | 30 | 32 | 34 | 36 | 38 | 40 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| n | 10 | 11 | 13 | 15 | 17 | 19 | 21 | 22 | 24 | 26 | 28 | 30 | 32 | 33 | 35 | 37 | 39 | 40 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| n | 10 | 11 | 13 | 15 | 17 | 19 | 21 | 23 | 25 | 27 | 28 | 30 | 32 | 33 | 35 | 36 | 37 | 38 | 39 | 40 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Scenarios | Operating Characteristics When and | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Used to Calibrate | TS | BOP2m | LLm | ||||||||
| True | PET | ASS | PET | ASS | PET | ASS | |||||
| 0.2 | 0.4 | 0.2 | 0.098 | 0.902 | 16.56 | 0.099 | 0.901 | 20.88 | 0.084 | 0.868 | 28.11 |
| 0.3 | 0.475 | 0.525 | 27.04 | 0.540 | 0.460 | 31.79 | 0.548 | 0.364 | 36.68 | ||
| 0.4 | 0.819 | 0.181 | 35.33 | 0.894 | 0.106 | 38.01 | 0.923 | 0.053 | 39.55 | ||
| 0.5 | 0.957 | 0.043 | 38.81 | 0.987 | 0.013 | 39.7 | 0.996 | 0.003 | 39.97 | ||
| 0.3 | 0.5 | 0.3 | 0.091 | 0.898 | 16.52 | 0.099 | 0.901 | 20.44 | 0.097 | 0.872 | 22.43 |
| 0.4 | 0.428 | 0.561 | 26.04 | 0.483 | 0.517 | 30.53 | 0.502 | 0.447 | 32.48 | ||
| 0.5 | 0.786 | 0.212 | 34.54 | 0.860 | 0.140 | 37.42 | 0.882 | 0.103 | 38.16 | ||
| 0.6 | 0.952 | 0.048 | 38.70 | 0.984 | 0.016 | 39.64 | 0.988 | 0.011 | 39.73 | ||
| 0.4 | 0.6 | 0.4 | 0.093 | 0.900 | 15.97 | 0.094 | 0.888 | 20.57 | 0.072 | 0.903 | 25.56 |
| 0.5 | 0.401 | 0.591 | 24.76 | 0.462 | 0.512 | 30.35 | 0.428 | 0.514 | 34.38 | ||
| 0.6 | 0.762 | 0.236 | 33.64 | 0.860 | 0.132 | 37.51 | 0.864 | 0.110 | 39.01 | ||
| 0.7 | 0.943 | 0.057 | 38.37 | 0.987 | 0.013 | 39.72 | 0.992 | 0.006 | 39.94 | ||
| 0.5 | 0.7 | 0.5 | 0.093 | 0.899 | 15.80 | 0.094 | 0.893 | 20.14 | 0.074 | 0.904 | 24.90 |
| 0.6 | 0.405 | 0.587 | 24.69 | 0.463 | 0.516 | 30.09 | 0.433 | 0.519 | 34.06 | ||
| 0.7 | 0.777 | 0.222 | 33.95 | 0.872 | 0.123 | 37.62 | 0.879 | 0.102 | 39.07 | ||
| 0.8 | 0.958 | 0.042 | 38.80 | 0.992 | 0.008 | 39.80 | 0.996 | 0.003 | 39.97 | ||
| Scenarios | Operating Characteristics When and | ||||||||||
| Used to Calibrate | TS | BOP2m | LLm | ||||||||
| True | PET | ASS | PET | ASS | PET | ASS | |||||
| 0.2 | 0.4 | 0.2 | 0.093 | 0.869 | 18.41 | 0.070 | 0.881 | 22.28 | 0.086 | 0.626 | 30.99 |
| 0.3 | 0.499 | 0.467 | 29.10 | 0.487 | 0.436 | 32.53 | 0.553 | 0.157 | 37.99 | ||
| 0.4 | 0.852 | 0.142 | 36.60 | 0.883 | 0.098 | 38.31 | 0.926 | 0.016 | 39.77 | ||
| 0.5 | 0.973 | 0.027 | 39.31 | 0.989 | 0.010 | 39.80 | 0.996 | 0.001 | 39.99 | ||
| 0.3 | 0.5 | 0.3 | 0.098 | 0.878 | 16.92 | 0.096 | 0.826 | 23.89 | 0.097 | 0.815 | 22.70 |
| 0.4 | 0.442 | 0.534 | 26.28 | 0.501 | 0.397 | 33.23 | 0.497 | 0.388 | 32.42 | ||
| 0.5 | 0.783 | 0.212 | 34.19 | 0.886 | 0.088 | 38.51 | 0.875 | 0.095 | 37.90 | ||
| 0.6 | 0.941 | 0.058 | 38.30 | 0.991 | 0.008 | 39.85 | 0.984 | 0.015 | 39.60 | ||
| 0.4 | 0.6 | 0.4 | 0.097 | 0.890 | 16.69 | 0.097 | 0.856 | 21.93 | 0.073 | 0.727 | 28.22 |
| 0.5 | 0.415 | 0.572 | 25.58 | 0.469 | 0.470 | 31.22 | 0.432 | 0.286 | 36.04 | ||
| 0.6 | 0.776 | 0.222 | 34.09 | 0.865 | 0.119 | 37.80 | 0.868 | 0.041 | 39.42 | ||
| 0.7 | 0.947 | 0.053 | 38.46 | 0.989 | 0.011 | 39.78 | 0.993 | 0.002 | 39.97 | ||
| 0.5 | 0.7 | 0.5 | 0.097 | 0.885 | 16.10 | 0.096 | 0.873 | 21.59 | 0.075 | 0.766 | 28.10 |
| 0.6 | 0.408 | 0.575 | 24.85 | 0.469 | 0.489 | 31.06 | 0.439 | 0.319 | 35.98 | ||
| 0.7 | 0.775 | 0.222 | 33.96 | 0.877 | 0.114 | 37.93 | 0.883 | 0.042 | 39.51 | ||
| 0.8 | 0.958 | 0.042 | 38.80 | 0.993 | 0.007 | 39.84 | 0.997 | 0.001 | 39.99 | ||
| Scenarios | Operating Characteristics When and | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Used to Calibrate | TS | BOP2m | LLm | ||||||||
| True | PET | ASS | PET | ASS | PET | ASS | |||||
| 0.2 | 0.4 | 0.2 | 0.099 | 0.901 | 29.02 | 0.095 | 0.905 | 38.91 | 0.065 | 0.910 | 50.73 |
| 0.3 | 0.643 | 0.357 | 59.85 | 0.723 | 0.277 | 69.21 | 0.709 | 0.241 | 75.26 | ||
| 0.4 | 0.926 | 0.074 | 75.22 | 0.979 | 0.021 | 78.93 | 0.989 | 0.008 | 79.75 | ||
| 0.5 | 0.987 | 0.013 | 79.09 | 0.999 | 0.001 | 79.92 | 1.000 | 0.000 | 79.99 | ||
| 0.3 | 0.5 | 0.3 | 0.100 | 0.900 | 27.64 | 0.099 | 0.901 | 37.47 | 0.087 | 0.888 | 51.87 |
| 0.4 | 0.579 | 0.421 | 55.80 | 0.664 | 0.336 | 66.29 | 0.696 | 0.262 | 74.73 | ||
| 0.5 | 0.900 | 0.100 | 73.52 | 0.967 | 0.033 | 78.35 | 0.987 | 0.011 | 79.68 | ||
| 0.6 | 0.983 | 0.017 | 78.81 | 0.998 | 0.002 | 79.89 | 1.000 | 0.000 | 79.98 | ||
| 0.4 | 0.6 | 0.4 | 0.099 | 0.901 | 26.68 | 0.096 | 0.898 | 37.57 | 0.100 | 0.878 | 51.55 |
| 0.5 | 0.548 | 0.452 | 53.46 | 0.639 | 0.355 | 65.59 | 0.693 | 0.273 | 74.20 | ||
| 0.6 | 0.887 | 0.113 | 72.66 | 0.967 | 0.033 | 78.33 | 0.987 | 0.011 | 79.64 | ||
| 0.7 | 0.982 | 0.018 | 78.81 | 0.999 | 0.001 | 79.91 | 1.000 | 0.000 | 79.98 | ||
| 0.5 | 0.7 | 0.5 | 0.098 | 0.902 | 26.26 | 0.100 | 0.893 | 36.87 | 0.098 | 0.884 | 46.84 |
| 0.6 | 0.547 | 0.453 | 53.23 | 0.649 | 0.344 | 65.51 | 0.688 | 0.286 | 72.22 | ||
| 0.7 | 0.896 | 0.104 | 73.17 | 0.973 | 0.027 | 78.58 | 0.987 | 0.012 | 79.48 | ||
| 0.8 | 0.988 | 0.012 | 79.20 | 0.999 | 0.001 | 79.95 | 1.000 | 0.000 | 79.98 | ||
| Scenarios | Operating Characteristics When and | ||||||||||
| Used to Calibrate | TS | BOP2m | LLm | ||||||||
| True | PET | ASS | PET | ASS | PET | ASS | |||||
| 0.2 | 0.4 | 0.2 | 0.098 | 0.895 | 29.59 | 0.082 | 0.887 | 40.49 | 0.066 | 0.794 | 55.39 |
| 0.3 | 0.645 | 0.352 | 60.38 | 0.713 | 0.255 | 70.04 | 0.717 | 0.129 | 76.89 | ||
| 0.4 | 0.929 | 0.071 | 75.44 | 0.979 | 0.020 | 78.96 | 0.991 | 0.003 | 79.89 | ||
| 0.5 | 0.987 | 0.013 | 79.11 | 0.999 | 0.001 | 79.91 | 1.000 | 0.000 | 80.00 | ||
| 0.3 | 0.5 | 0.3 | 0.093 | 0.894 | 28.38 | 0.098 | 0.882 | 42.09 | 0.088 | 0.796 | 55.70 |
| 0.4 | 0.577 | 0.415 | 56.26 | 0.687 | 0.293 | 69.43 | 0.703 | 0.168 | 76.08 | ||
| 0.5 | 0.900 | 0.100 | 73.54 | 0.977 | 0.022 | 78.99 | 0.988 | 0.006 | 79.80 | ||
| 0.6 | 0.982 | 0.018 | 78.78 | 0.999 | 0.001 | 79.95 | 1.000 | 0.000 | 79.99 | ||
| 0.4 | 0.6 | 0.4 | 0.099 | 0.885 | 29.00 | 0.097 | 0.893 | 39.49 | 0.099 | 0.815 | 51.69 |
| 0.5 | 0.571 | 0.420 | 56.22 | 0.644 | 0.346 | 66.67 | 0.690 | 0.212 | 74.20 | ||
| 0.6 | 0.907 | 0.093 | 74.10 | 0.970 | 0.029 | 78.60 | 0.986 | 0.009 | 79.62 | ||
| 0.7 | 0.987 | 0.013 | 79.12 | 0.999 | 0.001 | 79.94 | 1.000 | 0.000 | 79.98 | ||
| 0.5 | 0.7 | 0.5 | 0.093 | 0.896 | 27.21 | 0.082 | 0.880 | 39.39 | 0.099 | 0.800 | 48.58 |
| 0.6 | 0.549 | 0.444 | 54.19 | 0.631 | 0.326 | 67.09 | 0.691 | 0.205 | 72.98 | ||
| 0.7 | 0.904 | 0.096 | 73.82 | 0.977 | 0.022 | 78.98 | 0.988 | 0.009 | 79.54 | ||
| 0.8 | 0.990 | 0.010 | 79.33 | 1.000 | 0.000 | 79.98 | 1.000 | 0.000 | 79.99 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sambucini, V. Bayesian Sequential Monitoring of Single-Arm Trials: A Comparison of Futility Rules Based on Binary Data. Int. J. Environ. Res. Public Health 2021, 18, 8816. https://doi.org/10.3390/ijerph18168816
Sambucini V. Bayesian Sequential Monitoring of Single-Arm Trials: A Comparison of Futility Rules Based on Binary Data. International Journal of Environmental Research and Public Health. 2021; 18(16):8816. https://doi.org/10.3390/ijerph18168816
Chicago/Turabian StyleSambucini, Valeria. 2021. "Bayesian Sequential Monitoring of Single-Arm Trials: A Comparison of Futility Rules Based on Binary Data" International Journal of Environmental Research and Public Health 18, no. 16: 8816. https://doi.org/10.3390/ijerph18168816
APA StyleSambucini, V. (2021). Bayesian Sequential Monitoring of Single-Arm Trials: A Comparison of Futility Rules Based on Binary Data. International Journal of Environmental Research and Public Health, 18(16), 8816. https://doi.org/10.3390/ijerph18168816